python爬虫实战——抖音
目录
1、分析主页作品列表标签结构
2、进入作品页前 判断作品是视频作品还是图文作品
3、进入视频作品页面,获取视频
4、进入图文作品页面,获取图片
5、完整参考代码
6、获取全部作品的一种方法
本文主要使用 selenium.webdriver(Firefox)、BeautifulSoup等相关库,在 centos 系统中,以无登录状态 进行网页爬取练习。仅做学习和交流使用。
安装和配置 driver 参考:
[1]: Linux无图形界面环境使用Python+Selenium最佳实践 - 知乎
[2]: 错误'chromedriver' executable needs to be in PATH如何解 - 知乎
1、分析主页作品列表标签结构

# webdriver 初始化
driver = webdriver.Firefox(options=firefox_options)# 设置页面加载的超时时间为6秒
driver.set_page_load_timeout(6)# 访问目标博主页面
# 如 https://www.douyin.com/user/MS4wLjABAAAAnq8nmb35fUqerHx54jlTx76AEkfq-sMD3cj7QdgsOiM
driver.get(target)# 分别等待 class='e6wsjNLL' 和 class='niBfRBgX' 的元素加载完毕再继续执行
#(等ul.e6wsjNLL加载完就行了)
# WebDriverWait(driver, 6) 设置最长的等待事间为 6 秒
WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'e6wsjNLL')))
WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'niBfRBgX')))# 在浏览器中执行脚本,滚动页面到最底部,有可能会显示更多的作品
driver.execute_script('document.querySelector(".wcHSRAj6").scrollIntoView()')
sleep(1)# 使用 beautifulsoup 解析页面源代码
html = BeautifulSoup(driver.page_source, 'lxml')# 关闭driver
driver.quit()# 获取作品列表
ul = html.find(class_='e6wsjNLL')# 获取每一个作品
lis = ul.findAll(class_='niBfRBgX')2、进入作品页前 判断作品是视频作品还是图文作品

element_a = li.find('a')
# a 标签下如果能找到 class = 'TQTCdYql' 的元素,
# 则表示该作品是图文,如果没有(则为None),则表示该作品是视频
is_pictures = element_a.find(class_='TQTCdYql')if (not is_pictures) or (not is_pictures.svg):# 视频作品pass
else:# 图文作品pass
3、进入视频作品页面,获取视频
# 拼接作品地址
href = f'https://www.douyin.com{element_a["href"]}'# 使用 webdriver 访问作品页面
temp_driver = webdriver.Firefox(options=firefox_options)
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)# 等待 class='D8UdT9V8' 的元素显示后再执行(该元素的内容是作品的发布日期)
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8')))html_v = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()# 获取该作品的发布时间
publish_time = html_v.find(class_='D8UdT9V8').string[5:]video = html_v.find(class_='xg-video-container').video
source = video.find('source')# 为该作品创建文件夹(一个作品一个文件夹)
# 以该作品的 发布时间 加 作品类型来命名文件夹
path = create_dir(f'{publish_time}_video')# 下载作品
download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')4、进入图文作品页面,获取图片

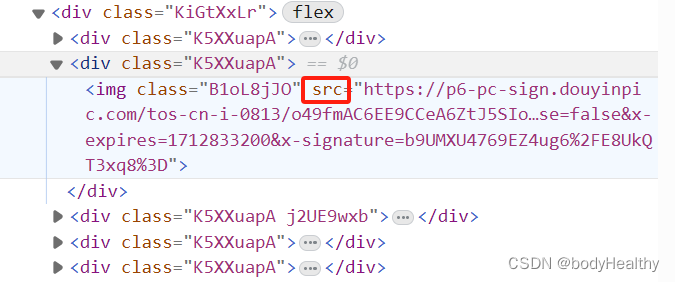
# 拼接作品页地址
href = f'https:{element_a["href"]}'# 使用webdriver访问作品页面
temp_driver = webdriver.Firefox(options=firefox_options)
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)# 等待包含作品发表时间的标签加载完成
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))# 获取当前页面的源代码,关闭webdriver,交给beautifulsoup来处理
# (剩下的任务 继续使用webdriver也能完成)
html_p = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()# 获取该作品的发布时间
publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]# 图片列表
img_ul = html_p.find(class_='KiGtXxLr')
imgs = img_ul.findAll('img')# 为该作品创建文件夹,以作品的发布时间+作品类型+图片数量(如果是图片类型作品)
path = create_dir(f'{publish_time}_pictures_{len(imgs)}')# 遍历图片,获取url 然后下载
for img in imgs:download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')5、完整参考代码
# -*- coding: utf-8 -*-import threading,requests,os,zipfile
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from pyvirtualdisplay import Display
from time import sleep
from bs4 import BeautifulSoup
from selenium.common.exceptions import WebDriverExceptiondisplay = Display(visible=0, size=(1980, 1440))
display.start()firefox_options = Options()
firefox_options.headless = True
firefox_options.binary_location = '/home/lighthouse/firefox/firefox'# 获取当前时间
def get_current_time():now = datetime.now()format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")return format_time# 设置一个根路径,作品文件以及日志文件都保留在此
ABS_PATH = f'/home/resources/{get_current_time()}'# 创建目录,dir_name 是作品的发布时间,格式为:2024-02-26 16:59,需要进行处理
def create_dir(dir_name):dir_name = dir_name.replace(' ', '-').replace(':', '-')path = f'{ABS_PATH}/{dir_name}'try:os.makedirs(path)except FileExistsError:print(f'试图创建已存在的文件, 失败({path})')else:print(f'创建目录成功 {path}')finally:return path# 下载 目录名称,当前文件的命名,下载的地址
def download_works(dir_name, work_name, src):response = requests.get(src, stream=True)if response.status_code == 200:with open(f'{dir_name}/{work_name}', mode='wb') as f:for chunk in response.iter_content(1024):f.write(chunk)# 判断作品是否已经下载过
def test_work_exist(dir_name):dir_name = dir_name.replace(' ', '-').replace(':', '-')path = f'{ABS_PATH}/{dir_name}'if os.path.exists(path) and os.path.isdir(path):if os.listdir(path):return Truereturn Falsedef get_all_works(target):try:driver = webdriver.Firefox(options=firefox_options)driver.set_page_load_timeout(6)# 目标博主页面driver.get(target)WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'e6wsjNLL')))WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'niBfRBgX')))driver.execute_script('document.querySelector(".wcHSRAj6").scrollIntoView()')sleep(1)html = BeautifulSoup(driver.page_source, 'lxml')driver.quit()# 作品列表ul = html.find(class_='e6wsjNLL')# 每一个作品lis = ul.findAll(class_='niBfRBgX')for li in lis:element_a = li.find('a')is_pictures = element_a.find(class_='TQTCdYql')if (not is_pictures) or (not is_pictures.svg):href = f'https://www.douyin.com{element_a["href"]}'temp_driver = webdriver.Firefox(options=firefox_options)temp_driver.set_page_load_timeout(6)temp_driver.get(href)WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8')))# 不是必须,剩余内容webdriver也能胜任html_v = BeautifulSoup(temp_driver.page_source, 'lxml')temp_driver.quit()# 获取该作品的发布时间publish_time = html_v.find(class_='D8UdT9V8').string[5:]# if test_work_exist(f'{publish_time}_video'):# continuevideo = html_v.find(class_='xg-video-container').videosource = video.find('source')# 为该作品创建文件夹path = create_dir(f'{publish_time}_video')# 下载作品download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')else:href = f'https:{element_a["href"]}'temp_driver = webdriver.Firefox(options=firefox_options)temp_driver.set_page_load_timeout(6)temp_driver.get(href)WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))# 使用 beautifulsoup 不是必须html_p = BeautifulSoup(temp_driver.page_source, 'lxml')temp_driver.quit()publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]# 图片列表img_ul = html_p.find(class_='KiGtXxLr')imgs = img_ul.findAll('img')# if test_work_exist(f'{publish_time}_pictures_{len(imgs)}'):# continuepath = create_dir(f'{publish_time}_pictures_{len(imgs)}')for img in imgs:download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')display.stop()print('##### finish #####')except WebDriverException as e: print(f"捕获到 WebDriverException: {e}") except Exception as err:print("捕获到其他错误 get_all_works 末尾")print(err)finally:driver.quit()display.stop()# 将目录进行压缩
def zipdir(path, ziph):# ziph 是 zipfile.ZipFile 对象for root, dirs, files in os.walk(path):for file in files:ziph.write(os.path.join(root, file),os.path.relpath(os.path.join(root, file), os.path.join(path, '..')))def dy_download_all(target_url):get_all_works(target_url)directory_to_zip = ABS_PATH # 目录路径output_filename = f'{ABS_PATH}.zip' # 输出ZIP文件的名称with zipfile.ZipFile(output_filename, 'w', zipfile.ZIP_DEFLATED) as zipf:zipdir(directory_to_zip, zipf)return f'{ABS_PATH}.zip' # 返回下载地址if __name__ == '__main__':# 简单测试url = input('请输入博主主页url:')path = dy_download_all(url)print('下载完成')print(f'地址:{path}')测试结果:

6、获取全部作品的一种方法
上述的操作是在无登录状态下进行的,即使在webdriver中操作让页面滚动,也只能获取到有限的作品,大约是 20 项左右。对此提出一个解决方案。
以登录状态(或者有cookies本地存储等状态)访问目标博主页面,滚动到作品最底部,然后在控制台中执行JavaScript脚本,获取全部作品的信息(在这里是作品链接以及作品类型),然后写出到文本文件中。

JavaScript 代码:
let ul = document.querySelector('.e6wsjNLL');// 存放结果
works_list = [];// 遍历,每一次都加入一个对象,包括作品页的地址、作品是否为图片作品
ul.childNodes.forEach((e)=>{let href = e.querySelector('a').href;let is_pictures = e.querySelector('a').querySelector('.TQTCdYql') ? true : false;works_list.push({href, is_pictures})
})// 创建一个Blob对象,包含要写入文件的内容
var content = JSON.stringify(works_list);
var blob = new Blob([content], {type: "text/plain;charset=utf-8"}); // 创建一个链接元素
var link = document.createElement("a"); // 设置链接的href属性为Blob对象的URL
link.href = URL.createObjectURL(blob); // 设置链接的下载属性,指定下载文件的名称
link.download = "example.txt"; // 触发链接的点击事件,开始下载文件
link.click();写出结果:
列表中的每一个元素都是一个对象,href 是作品的地址,is_pictures 以 boolean 值表示该作品是否为图片作品
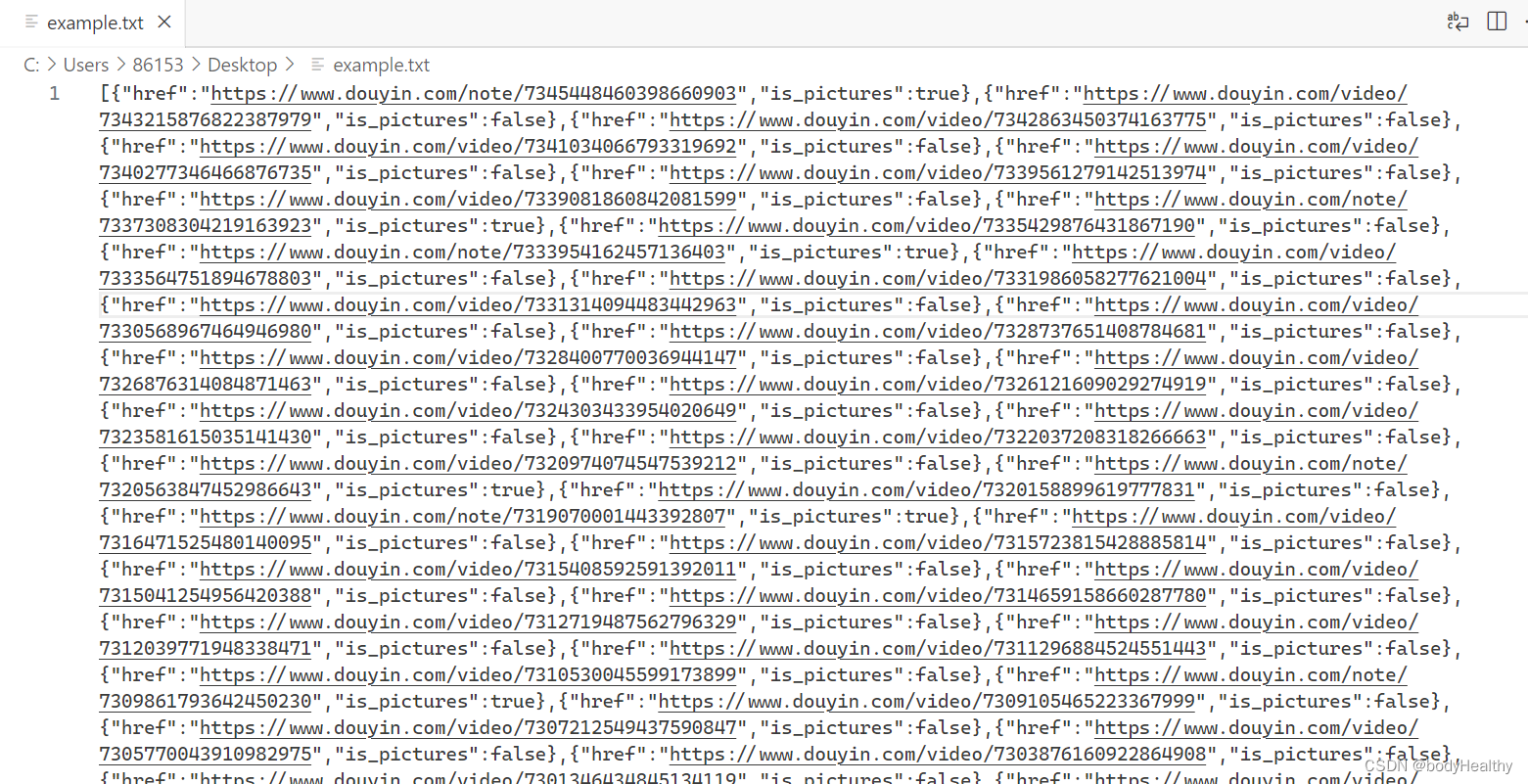
然后在 python 中读入该文件,使用 json 解析,转成字典列表的形式,遍历列表,对每一个字典(就是每一个作品)进行处理即可。
示例代码:
win 环境下
import json
import threading,requests,os
from bs4 import BeautifulSoup
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from datetime import datetime
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait# 获取当前时间
def get_current_time():now = datetime.now()format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")return format_time# 设置一个根路径,作品文件以及日志文件都保留在此
ABS_PATH = f'F:\\{get_current_time()}'# 创建目录,dir_name 是作品的发布时间,格式为:2024-02-26 16:59,需要进行处理
def create_dir(dir_name):dir_name = dir_name.replace(' ', '-').replace(':', '-')path = f'{ABS_PATH}/{dir_name}'try:os.makedirs(path)except FileExistsError:print(f'试图创建已存在的文件, 失败({path})')else:print(f'创建目录成功 {path}')finally:return path# 下载 目录名称,当前文件的命名,下载的地址
def download_works(dir_name, work_name, src):response = requests.get(src, stream=True)if response.status_code == 200:with open(f'{dir_name}/{work_name}', mode='wb') as f:for chunk in response.iter_content(1024):f.write(chunk)# 判断作品是否已经下载过
def test_work_exist(dir_name):dir_name = dir_name.replace(' ', '-').replace(':', '-')path = f'{ABS_PATH}/{dir_name}'if os.path.exists(path) and os.path.isdir(path):if os.listdir(path):return Truereturn False# 下载一个作品
def thread_task(ul):for item in ul:href = item['href']is_pictures = item['is_pictures']if is_pictures:temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(6)temp_driver.get(href)WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))# 使用 beautifulsoup 不是必须html_p = BeautifulSoup(temp_driver.page_source, 'lxml')temp_driver.quit()publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]# 图片列表img_ul = html_p.find(class_='KiGtXxLr')imgs = img_ul.findAll('img')# if test_work_exist(f'{publish_time}_pictures_{len(imgs)}'):# continuepath = create_dir(f'{publish_time}_pictures_{len(imgs)}')for img in imgs:download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')else:temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(6)temp_driver.get(href)WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8')))# 不是必须,剩余内容webdriver也能胜任html_v = BeautifulSoup(temp_driver.page_source, 'lxml')temp_driver.quit()# 获取该作品的发布时间publish_time = html_v.find(class_='D8UdT9V8').string[5:]# if test_work_exist(f'{publish_time}_video'):# continuevideo = html_v.find(class_='xg-video-container').videosource = video.find('source')# 为该作品创建文件夹path = create_dir(f'{publish_time}_video')# 下载作品download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')if __name__ == '__main__':content = ''# 外部读入作品链接文件with open('../abc.txt', mode='r', encoding='utf-8') as f:content = json.load(f)length = len(content)if length <= 3 :thread_task(content)else:# 分三个线程ul = [content[0: int(length / 3) + 1], content[int(length / 3) + 1: int(length / 3) * 2 + 1],content[int(length / 3) * 2 + 1: length]]for child_ul in ul:thread = threading.Thread(target=thread_task, args=(child_ul,))thread.start()相关文章:
python爬虫实战——抖音
目录 1、分析主页作品列表标签结构 2、进入作品页前 判断作品是视频作品还是图文作品 3、进入视频作品页面,获取视频 4、进入图文作品页面,获取图片 5、完整参考代码 6、获取全部作品的一种方法 本文主要使用 selenium.webdriver(Firef…...

Day1-力扣刷题学习打卡
1、两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以…...

C语言的位操作与位字段
C语言中的位操作允许程序员直接在整型变量的单个位或位组上进行操作。这种操作在许多低级编程任务中非常有用,尤其是在嵌入式系统编程中,如硬件操作、设备驱动及性能优化等场景。位操作主要使用以下几种位操作符: & (按位与&a…...

应用实战|从头开始开发记账本1:如何获取BaaS服务
本期视频开始,我们将通过一系列教程,来详细讲解MemFire Cloud BaaS服务的使用方法,通过这一系列的教程,你将学会如何只使用前端技术完成一个生产级应用的开发和上线。 以下是本期视频主要章节: BaaS服务介绍用户如何…...

el-form v-for循环列表的表单如何校验
1、普通的表单校验直接在最外层<el-form> :model"数据" :rules"规则" ,再在<el-form-item>层设置prop值与model里数据定义的key保持一致即可。 <el-form-item label"名称" prop"ruleName" :rules"[{r…...

笔记:《NCT全国青少年编程能力等级测试教程Python语言编程三级》
NCT全国青少年编程能力等级测试教程Python语言编程三级 ISBN:9787302574859 绪论 专题1 序列和元组 考查方向 考点清单 考点1 组合数据类型 序列类型(字符串、列表、元组);集合类型;映射类型。 考点2 元组类型 (一)元组类型…...
地平线旭日x3派部署yolov5--全流程
地平线旭日x3派部署yolov5--全流程 前言一、深度学习环境安装二、安装docker三、部署3.1、安装工具链镜像3.2、配置天工开物OpenExplorer工具包3.3、创建深度学习虚拟空间,安装依赖:3.4、下载yolov5项目源码并运行3.5、pytorch的pt模型文件转onnx3.6、最…...

【Golang星辰图】Go语言云计算SDK全攻略:深入Go云存储SDK实践
Go语言云计算和存储SDK全面指南 前言 在当今数字化时代,云计算和存储服务扮演着至关重要的角色,为应用程序提供高效、可靠的基础设施支持。本文将介绍几种流行的Go语言SDK,帮助开发者与AWS、Google Cloud、Azure、MinIO、 阿里云和腾讯云等…...
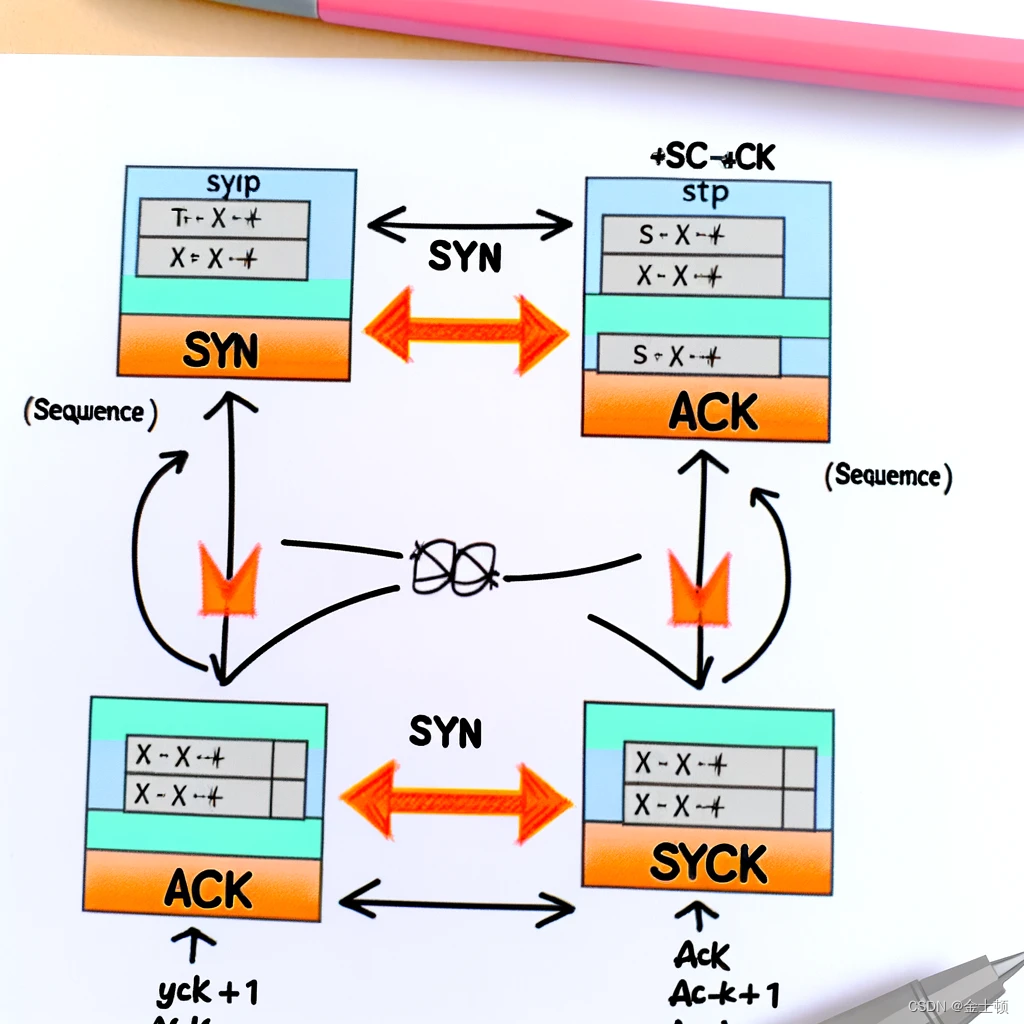
深入理解TCP:序列号、确认号和自动ACK的艺术
深入理解TCP:序列号、确认号和自动ACK的艺术 在计算机网络的世界里,TCP(传输控制协议)扮演着至关重要的角色。它确保了数据在不可靠的网络环境中可靠地、按顺序地传输。TCP的设计充满智慧,其中序列号(Seq&a…...

家电工厂5G智能制造数字孪生可视化平台,推进家电工业数字化转型
家电5G智能制造工厂数字孪生可视化平台,推进家电工业数字化转型。随着科技的飞速发展,家电行业正迎来一场前所未有的数字化转型。在这场制造业数字化转型中,家电5G智能制造工厂数字孪生可视化平台扮演着至关重要的角色。本文将从数字孪生技术…...
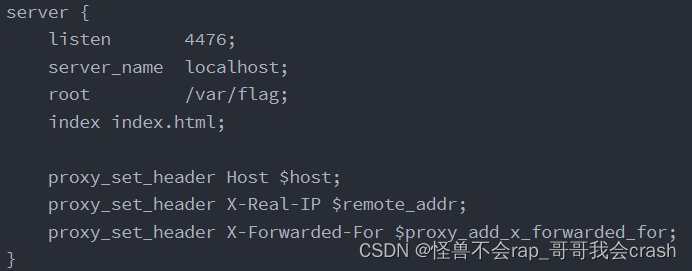
ctf_show笔记篇(web入门---代码审计)
301:多种方式进入 从index.php页面来看 只需要访问index.php时session[login]不为空就能访问 那么就在访问index.php的时候上传login 随机一个东西就能进去从checklogin页面来看sql注入没有任何过滤 直接联合绕过 密码随意 还有多种方式可以自己去看代码分析 30…...

c语言的字符串函数详解
文章目录 前言一、strlen求字符串长度的函数二、字符串拷贝函数strcpy三、链接或追加字符串函数strcat四、字符串比较函数strcmp五、长度受限制字符函数六、找字符串2在字符串1中第一次出现的位置函数strstr七、字符串切割函数strtok(可以切割分隔符)八、…...

HarmonyOS NEXT应用开发—折叠屏音乐播放器方案
介绍 本示例介绍使用ArkUI中的容器组件FolderStack在折叠屏设备中实现音乐播放器场景。 效果图预览 使用说明 播放器预加载了歌曲,支持播放、暂停、重新播放,在折叠屏上,支持横屏悬停态下的组件自适应动态变更。 实现思路 采用MVVM模式进…...
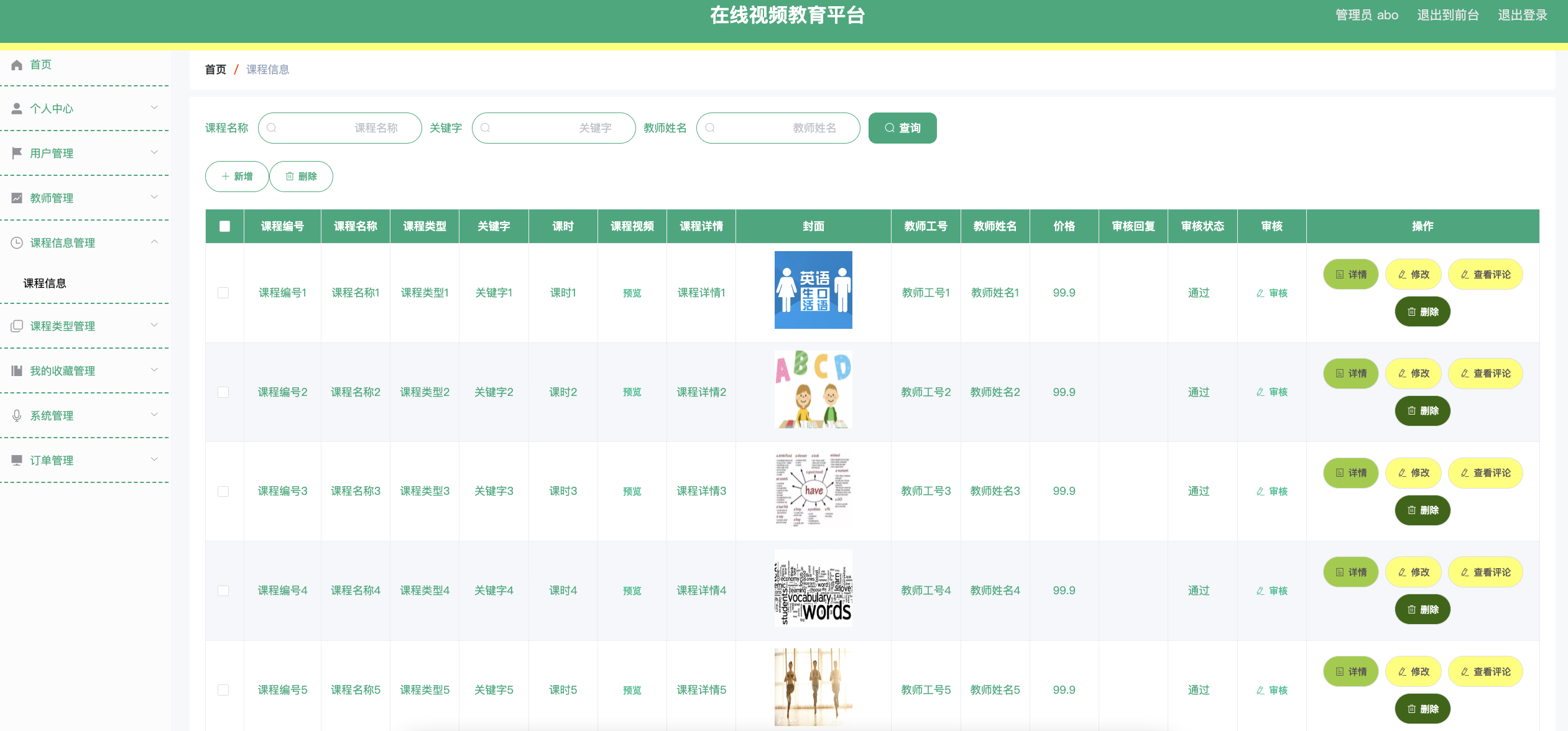
Java项目:55 springboot基于SpringBoot的在线视频教育平台的设计与实现015
作者主页:舒克日记 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 项目介绍 在线视频教育平台分为管理员和用户、教师三个角色的权限模块。 管理员所能使用的功能主要有:首页、个人中心、用户管理、教师管理、课程信…...
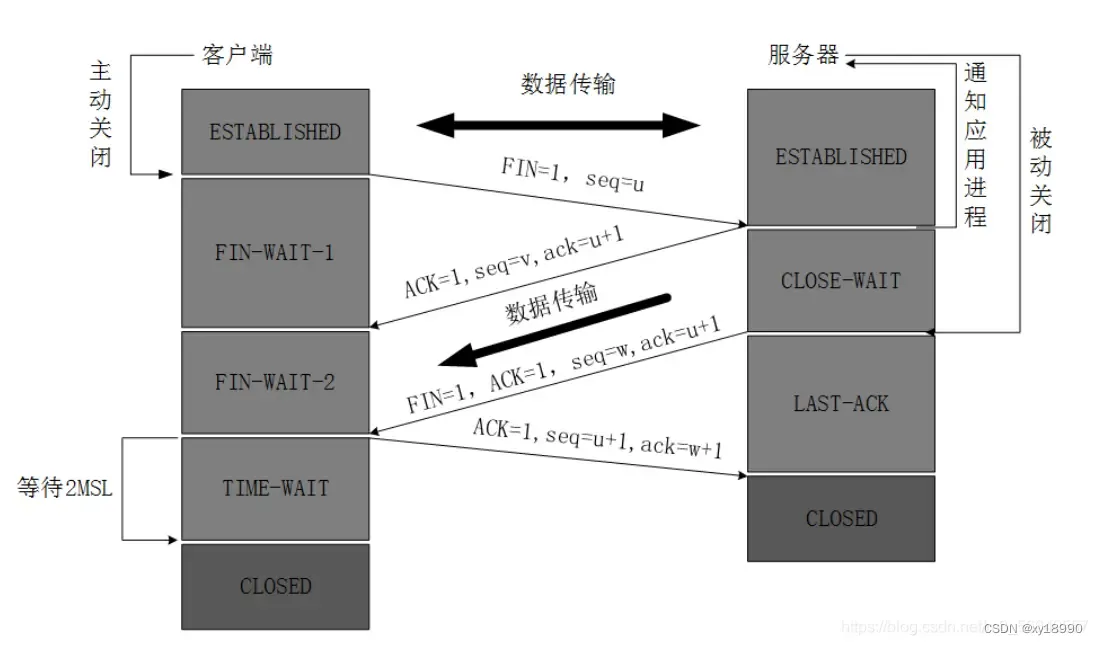
说下你对TCP以及TCP三次握手四次挥手的理解?
参考自简单理解TCP三次握手四次挥手 什么是TCP协议? TCP( Transmission control protocol )即传输控制协议,是一种面向连接、可靠的数据传输协议,它是为了在不可靠的互联网上提供可靠的端到端字节流而专门设计的一个传输协议。 面向连接&a…...

wsl-oracle 安装 omlutils
wsl-oracle 安装 omlutils 1. 安装 cmake 和 gcc-c2. 安装 omlutils3. 使用 omlutils 创建 onnx 模型 1. 安装 cmake 和 gcc-c sudo dnf install -y cmake gcc-c2. 安装 omlutils pip install omlutils-0.10.0-cp312-cp312-linux_x86_64.whl不需要安装 requirements.txt&…...

Python类属性和对象属性大揭秘!
在Python中,对象和类紧密相连,它们各自拥有一些属性,这些属性在我们的编程中起着至关重要的作用。那么,什么是类属性和对象属性呢?别急,让我慢慢给你解释。 类属性 首先,类属性是定义在类本…...

北斗卫星在桥隧坡安全监测领域的应用及前景展望
北斗卫星在桥隧坡安全监测领域的应用及前景展望 北斗卫星系统是中国独立研发的卫星导航定位系统,具有全球覆盖、高精度定位和海量数据传输等优势。随着卫星导航技术的快速发展,北斗卫星在桥隧坡安全监测领域正发挥着重要的作用,并为相关领域…...
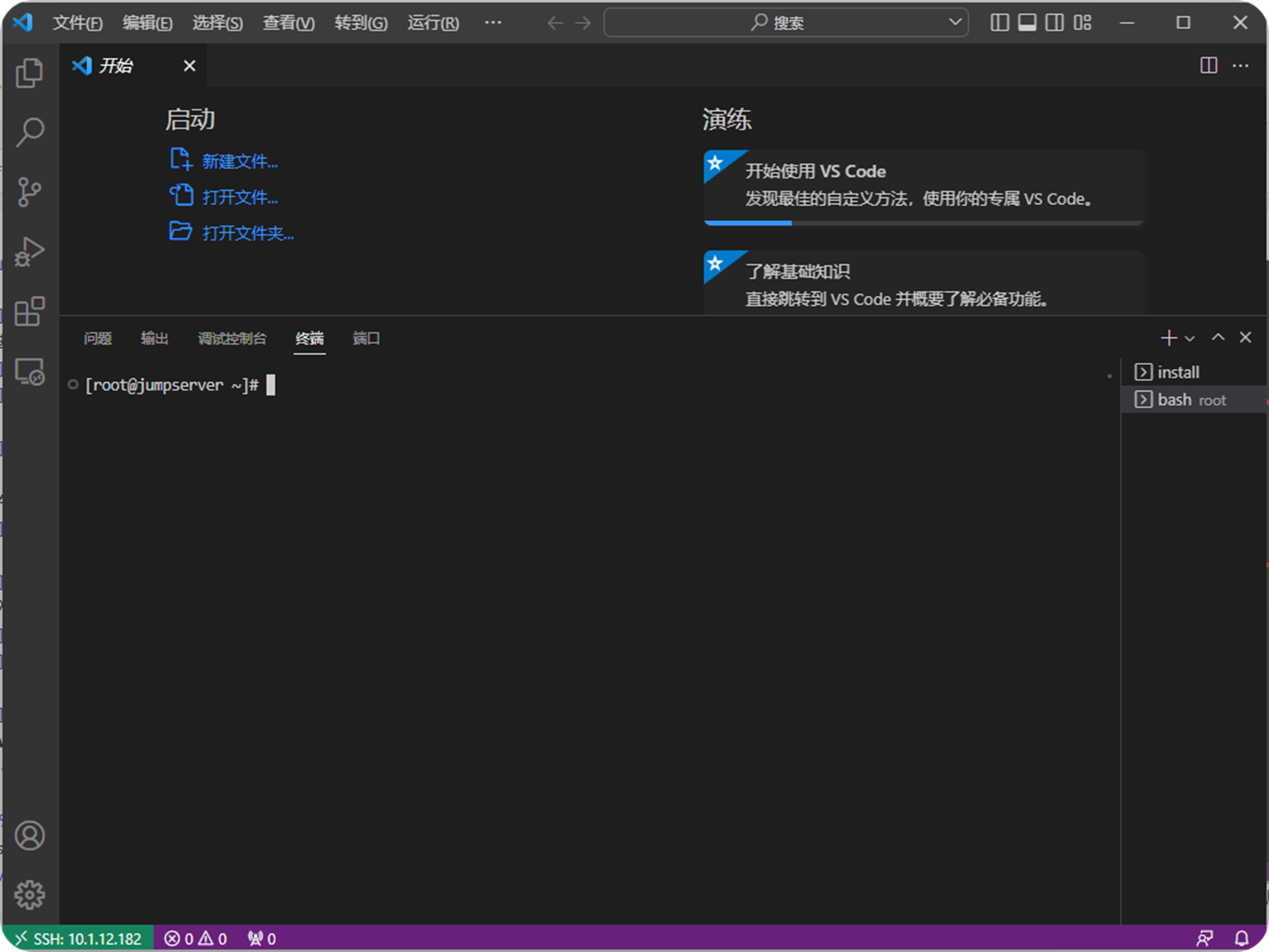
如何通过堡垒机JumpServer使用VisualCode 连接服务器进行开发
前言:应用场景 我们经常会碰到需要远程登录到内网服务器进行开发的场景,一般的做法都是通过VPN登录回局域网,然后配置ftp或者ssh使用开发工具链接到服务器上进行开发。如果没有出现问题,那么一切都正常,但到了出现问题…...

【Linux】进程优先级
🌎进程的优先级 文章目录: 进程状态 优先级相关 什么是优先级 为什么要有优先级 进程的优先级 调整进程优先级 调整优先级 优先级极限测试 Linux的调度与切换 总结 前言: 进程…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

收藏|2026年AI大模型就业爆发!岗位暴涨12倍、月薪6W+,小白零基础入门指南
2026年,AI已从“科技热点”彻底变为职场“刚需赛道”!脉脉高聘人才智库最新发布的《2026年1-2月中高端人才求职招聘洞察》,用硬核数据揭示行业真相:AI人才成招聘市场顶流,岗位量、薪资双双爆发式增长。尤其对零基础小白…...

2026上海GEO生成式引擎优化服务商综合实力测评:谁在真正帮品牌进入AI答案
当企业在讨论“上海生成式引擎优化公司哪家好”时,这个问题本身就反映了市场一个关键的转折。两三年前,企业营销的主战场还是搜索引擎排名和官网访问量。现在,决策者开始频繁向DeepSeek、豆包、通义千问等AI工具提问,而这些生成式…...