从源码的角度告诉你 spark是怎样完成对文件切片
目录
1.说明
2.怎样设置默认切片数
2.1 RDD默认切片设置
2.2 SparkSQL默认切片设置
3. makeRDD 切片原理
4. textFile 切片原理
4.1 切片规则
4.2 怎样设置切片大小
4.3 测试代码
5.hadoopFile 切片原理
5.1 说明
5.2 切片规则
5.3 怎样设置切片大小
5.4 代码测试
5.5 minPartitions 在 CombineTextInputFormat 中的作用?
5.6 重点关注
1.说明
在spark中为我们提供了用来读取数据的方法
比如 makeRDD、parallelize、textFile、hadoopFile等方法
这些方法按照数据源可以分为两类 文件系统、Driver内存中的集合数据
当我们使用指定的方法读取数据后,会按照指定的切片个数对文件进行切片
2.怎样设置默认切片数
在我们在使用RDD的算子时,经常会遇到可以显式的指定切片个数,或者隐式的使用默认切片个数,下面会告诉我们,怎样设置默认切片个数
2.1 RDD默认切片设置
1.驱动程序中设置
val sparkconf: SparkConf = new SparkConf().setAppName("测试默认切片数").set("spark.default.parallelism","1000").setMaster("local[100]")2.spark-shell或spark-submit 设置
spark-shell \
--master yarn \
--name "spark-shell-tmp" \
--conf spark.default.parallelism=1000 \
--driver-memory 40G \
--executor-memory 40G \
--num-executors 40 \
--executor-cores 6 \3.不指定 spark.default.parallelism 参数时,将使用默认值local模式:local[100] : 100local : 客户端机器核数集群模式(yarn):2 或者 核数总和源码:
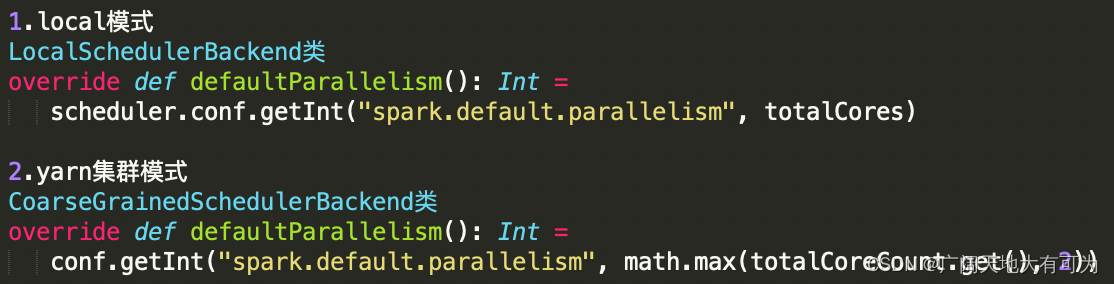
查看默认切片数:
// 获取默认切片数
val parallelism = sc.defaultParallelism2.2 SparkSQL默认切片设置
-- 设置默认切片数
set spark.sql.shuffle.partitions=1000;默认值:当不设置时,默认为200注意:spark.default.parallelism 只有在处理RDD时才会起作用,对SparkSQL的无效spark.sql.shuffle.partitions 则是对sparks SQL专用的设置3. makeRDD 切片原理
可用通过 makeRDD算子 将Driver中序列集合中数据转换成RDD,在转换的过程中,会根据指定的切片个数 和 集合索引对集合切片
切片规则:
根据集合长度和切片数将集合切分成若干子集合(和集合元素内容无关)
示例代码:
test("makeRDD - 切片逻辑") {// 初始化 spark配置实例val sparkconf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("")// 初始化 spark环境对象val sc: SparkContext = new SparkContext(sparkconf)val rdd: RDD[(String, String)] = sc.makeRDD(List(("张飞1", "张飞java scala spark"), ("张飞2", "张飞java scala spark"), ("刘备3", "刘备java spark"), ("刘备4", "刘备java scala spark"), ("刘备5", "刘备scala spark"), ("关羽6", "关羽java scala spark"), ("关羽7", "关羽java scala"), ("关羽8", "关羽java scala spark"), ("关羽9", "关羽java spark")))// 查看每个分区的内容rdd.mapPartitionsWithIndex((i, iter) => {println(s"分区编号$i :${iter.mkString(" ")}");iter}).collect()rdd.getNumPartitionssc.stop()}
结果: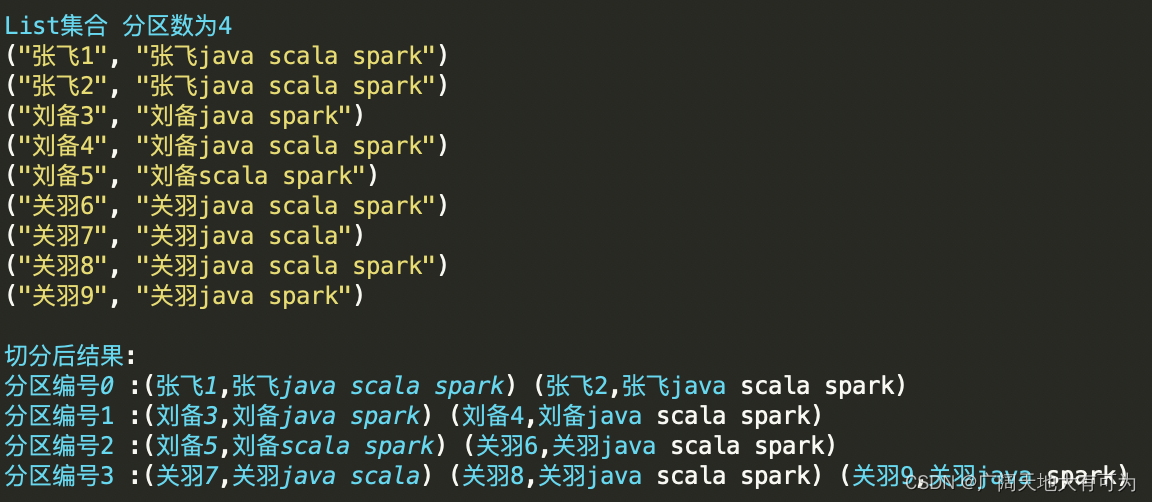
源码阅读:
1. 通过SparkContext创建rdd
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}2. ParallelCollectionRDD类中的 getPartitions方法
override def getPartitions: Array[Partition] = {val slices = ParallelCollectionRDD.slice(data, numSlices).toArrayslices.indices.map(i => new ParallelCollectionPartition(id, i, slices(i))).toArray
}3. ParallelCollectionRDD对象的slice方法(核心切片逻辑)def slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] = {// 对切片数做合法性校验if (numSlices < 1) {throw new IllegalArgumentException("Positive number of partitions required")}// TODO 通过 集合长度和切片数 获取每个切片的位置信息// 从这可以得出 对集合的切片只和 集合索引和切片数相关,和集合内容无关// 将 集合索引按照切片数 切分成若干元素def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {(0 until numSlices).iterator.map { i =>val start = ((i * length) / numSlices).toIntval end = (((i + 1) * length) / numSlices).toInt(start, end)}}// 对集合类型做判断seq match {case r: Range =>positions(r.length, numSlices).zipWithIndex.map { case ((start, end), index) =>// If the range is inclusive, use inclusive range for the last sliceif (r.isInclusive && index == numSlices - 1) {new Range.Inclusive(r.start + start * r.step, r.end, r.step)} else {new Range.Inclusive(r.start + start * r.step, r.start + (end - 1) * r.step, r.step)}}.toSeq.asInstanceOf[Seq[Seq[T]]]case nr: NumericRange[T] =>// For ranges of Long, Double, BigInteger, etcval slices = new ArrayBuffer[Seq[T]](numSlices)var r = nrfor ((start, end) <- positions(nr.length, numSlices)) {val sliceSize = end - startslices += r.take(sliceSize).asInstanceOf[Seq[T]]r = r.drop(sliceSize)}slices.toSeqcase _ =>val array = seq.toArray // To prevent O(n^2) operations for List etcpositions(array.length, numSlices).map { case (start, end) =>array.slice(start, end).toSeq}.toSeq}
}4. textFile 切片原理
textFile使用的MapReduce框架中TextInputFormat类完成对文件切片和读取切片中数据

4.1 切片规则
1.对job输入路径中的每个文件单独切片
2.判断每个文件是否支持切片
true : 按照指定切片大小对文件切片
false: 文件整体作为一个切片
4.2 怎样设置切片大小
// 切片大小计算规则splitSize = Math.max(minSize, Math.min(goalSize, blockSize))// 参数说明1.minSizeset mapreduce.input.fileinputformat.split.minsize=256000000 或 set mapred.min.split.size=256000000默认值 minSize=1L2.goalSizegoalSize=所有文件大小总和/指定的切片个数3.blockSize本地目录32M|HDFS目录128M或256M(看hdfs文件块具体配置)// 需求 1.真实切片大小 < blockSizegoalSize=所有文件大小总和/指定的切片个数 < blockSize 即(创建rdd时调大切片个数)2.真实切片大小 > blockSizeset mapreduce.input.fileinputformat.split.minSize=大于blockSize值4.3 测试代码
test("textFile - 切片逻辑") {// 初始化 spark配置实例val sf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("Test textFile")// 初始化 spark环境对象val sc: SparkContext = new SparkContext(sf)sc.hadoopConfiguration.setInt("mapred.min.split.size", 469000000)// sc.hadoopConfiguration.setInt("mapreduce.input.fileinputformat.split.minsize", 256000000)// 读取目录下的所有文件val rdd: RDD[String] = sc.textFile("src/main/resources/data/dir/dir3/LOL.map", 1000)// 打印分区个数println("切片个数:"+rdd.getNumPartitions)sc.stop()}
执行结果:

5.hadoopFile 切片原理
5.1 说明
def hadoopFile[K, V](path: String,inputFormatClass: Class[_ <: InputFormat[K, V]],keyClass: Class[K],valueClass: Class[V],minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {assertNotStopped()功能:读取HDFS文件或本地文件来创建RDD(使用MapReduce框架中InputFormat类)参数:path: 指定job的输入路径inputFormatClass: 对输入文件切片和读取的实现类keyClass: key的数据类型valueClass: value的数据类型minPartitions: 最小切片数5.2 切片规则
根据指定的切片大小进行切片,允许将多个文件合并成换一个切片对象
5.3 怎样设置切片大小
指定切片大小(默认值Long.MaxValue)
set mapred.max.split.size=切片大小 或
set mapreduce.input.fileinputformat.split.maxsize=切片大小5.4 代码测试
test("spark中使用 CombineTextInputFormat") {// 初始化 spark配置实例val sf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("")// 初始化 spark环境对象val sc: SparkContext = new SparkContext(sf)// 读取目录下的所有文件val input = "src/main/resources/data/dir/dir3"val combineRDD: RDD[(LongWritable, Text)] = sc.hadoopFile[LongWritable, Text, org.apache.hadoop.mapred.lib.CombineTextInputFormat](input, 10000)// val combineRDD: RDD[(LongWritable, Text)] = sc.hadoopFile[LongWritable, Text// , org.apache.hadoop.mapred.TextInputFormat](input, 10000)sc.hadoopConfiguration.setInt("mapred.max.split.size", 128000000)//sc.hadoopConfiguration.setInt("mapreduce.input.fileinputformat.split.maxsize", 128000000)println("切片个数:" + combineRDD.getNumPartitions)//combineRDD.map(_._2.toString).foreach(println(_))//combineRDD.collect()//combineRDD.hadsc.stop()}
执行结果: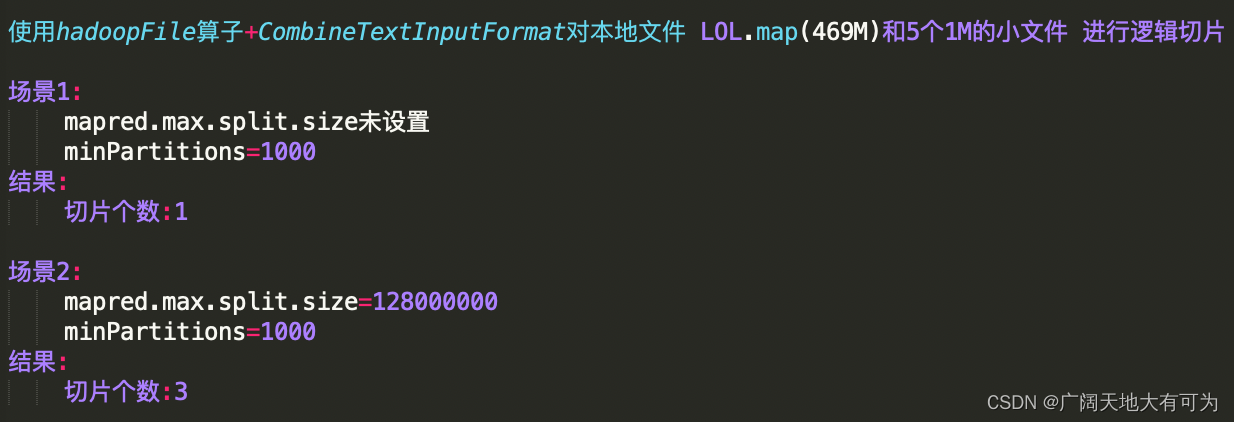
5.5 minPartitions 在 CombineTextInputFormat 中的作用?
CombineTextInputFormat切片逻辑和 最小切片数(minPartitions) 无关
查看 org.apache.hadoop.mapred.lib.CombineTextInputFormat类 getSplits方法
TODO: numSplits指定的切片个数,并没有使用public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException {List<org.apache.hadoop.mapreduce.InputSplit> newStyleSplits =super.getSplits(Job.getInstance(job));InputSplit[] ret = new InputSplit[newStyleSplits.size()];for(int pos = 0; pos < newStyleSplits.size(); ++pos) {org.apache.hadoop.mapreduce.lib.input.CombineFileSplit newStyleSplit = (org.apache.hadoop.mapreduce.lib.input.CombineFileSplit) newStyleSplits.get(pos);ret[pos] = new CombineFileSplit(job, newStyleSplit.getPaths(),newStyleSplit.getStartOffsets(), newStyleSplit.getLengths(),newStyleSplit.getLocations());}return ret;}5.6 重点关注
对计算任务而言,合并小文件是一把双刃剑,合并小文件后 就舍弃了数据本地化,则加了网络IO的开销,需要根据实际情况合理的选择 切片策略
CombineTextInputFormat源码参考:https://blog.csdn.net/wawmg/article/details/17095125
相关文章:
从源码的角度告诉你 spark是怎样完成对文件切片
目录 1.说明 2.怎样设置默认切片数 2.1 RDD默认切片设置 2.2 SparkSQL默认切片设置 3. makeRDD 切片原理 4. textFile 切片原理 4.1 切片规则 4.2 怎样设置切片大小 4.3 测试代码 5.hadoopFile 切片原理 5.1 说明 5.2 切片规则 5.3 怎样设置切片大小 5.4 代码测试…...

剑指 Offer II 019. 最多删除一个字符得到回文
题目链接 剑指 Offer II 019. 最多删除一个字符得到回文 easy 题目描述 给定一个非空字符串 s,请判断如果 最多 从字符串中删除一个字符能否得到一个回文字符串。 示例 1: 输入: s “aba” 输出: true 示例 2: 输入: s “abca” 输出: true 解释: 可以删除 “c”…...

RK3568驱动OV13850摄像头模组调试过程
摄像头介绍品牌:Omnivision型号:CMK-OV13850接口:MIPI像素:1320WOV13850彩色图像传感器是一款低电压、高性能1/3.06英寸1320万像素CMOS图像传感器,使用OmniBSI?技术提供了单-1320万像素(42243136)摄像头的…...
Go项目的目录结构基本布局
前言 随着项目的代码量在不断地增长,不同的开发人员按自己意愿随意布局和创建目录结构,项目维护性就很差,代码也非常凌乱。良好的目录与文件结构十分重要,尤其是团队合作的时候,良好的目录与文件结构可以减少很多不必要…...
CHAPTER 1 Linux Filesystem Management
Linux Filesystem Management1 文件系统是什么2 文件系统的组成3 inode详解1. inode到底是什么2. inode的内容3. inode的大小4. inode的号码5. 硬链接6. 软链接4 存储区域5 常见文件系统的类型1. 根文件系统2. 虚拟文件系统3. 真文件系统4. 伪文件系统5. 网络文件系统1 文件系统…...

RocketMQ架构篇 - 读写队列与生产者如何选择队列
读、写队列 创建主题时,可以指定 writeQueueNums(写队列的个数)、readQueueNums(读队列的个数)。生产者发送消息时,使用写队列的个数返回路由信息;消费者消费消息时,使用读队列的个…...
)
华为OD机试真题Python实现【通信误码】真题+解题思路+代码(20222023)
通信误码 题目 信号传播过程中会出现一些误码,不同的数字表示不同的误码 ID,取值范围为 1~65535,用一个数组记录误码出现的情况,每个误码出现的次数代表误码频度,请找出记录中包含频度最高误码的最小子数组长度。 🔥🔥🔥🔥🔥👉👉👉👉👉👉 华为OD…...

【单目3D目标检测】MonoDDE论文精读与代码解析
文章目录PrefacePros and ConsAbstractContributionsPreliminaryDirect depth estimationDepth from heightPespective-n-point(PnP)PipelineDiverse Depth EstimationsRobust Depth CombinationOutput distributionSelecting and combining reliable de…...
复习 Kotlin 从小白到大牛 第二版 笔记要点
4.2.2 常量和只读变量 常量和只读变量一旦初始化就不能再被修改。在kotlin中,声明常量是在标识符的前面加上val或const val 关键字。 1. val 声明的是运行时变量,在运行时进行初始化 2.const val 声明的是编译时常量,在编译时初始化 val …...
X264简介-Android使用(二)
X264简介-Android使用(二) 4、Ubuntu上安装ffmpeg: 检查更新本地软件包(如果未更新,reboot Vmware): sudo apt update sudo apt upgrade官网下载的source文件安装: http://ffmpe…...
)
【独家】华为OD机试 - 统计差异值大于相似值二元组个数(C 语言解题)
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明本期…...

掌握好Framework 才是王道~
现在面试对Android开发者的要求越来越高了!从最开始的阿里、头条、腾讯等大厂,到现在的互联网车企,面试总喜欢问道 Framework底层原理的相关问题 Android Framework的三大核心功能: 1、View.java:View工作原理,实现包…...
 A — C)
Codeforces Round 856 (Div. 2) A — C
Codeforces Round 856 (Div. 2) 文章目录A. Prefix and Suffix Array题目大意题目分析codeB. Not Dividing题目大意题目分析codeC. Scoring Subsequences题目大意题目分析codeA. Prefix and Suffix Array 题目大意 给出一个字符串所有的非空前后缀,判断原字符串是…...

2022年MathorCup数学建模B题无人仓的搬运机器人调度问题解题全过程文档加程序
2022年第十二届MathorCup高校数学建模 B题 无人仓的搬运机器人调度问题 原题再现 本题考虑在无人仓内的仓库管理问题之一,搬运机器人 AGV 的调度问题。更多的背景介绍请参看附件-背景介绍。对于无人仓来说,仓库的地图模型可以简化为图的数据结构。 仓库…...

开源项目的演进会遇到哪些“坑”?KubeVela 从发起到晋级 CNCF 孵化的全程回顾
作者:孙健波、曾庆国 点击查看:「开源人说」第五期《KubeVela:一场向应用交付标准的冲锋》 2023 年 2 月,**KubeVela [ 1] ** 经过全体 ToC 投票成功进入 CNCF Incubation,是云原生领域首个晋级孵化的面向应用的交付…...
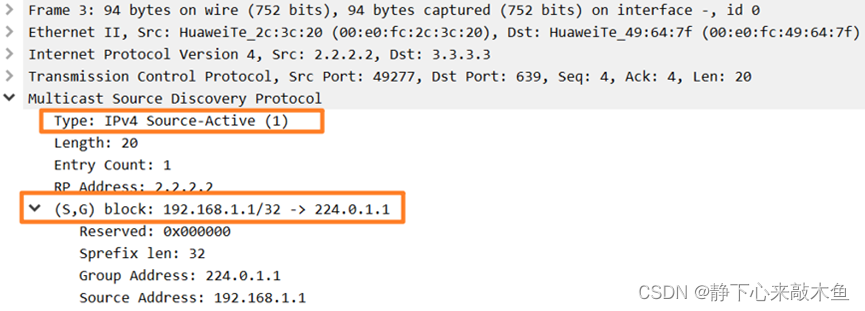
MSDP实验配置
目录 配置MSDP 配置PIM SM协议 配置各PIM SM域内的静态RP 配置MSDP对等体 配置域内的MSDP对等体 AR8和AR9建立EBGP邻居 配置域间的MSDP对等体 进行实验验证 什么是MSDP MSDP(Multicast Source Discovery Protocol)组播源发现协议的简称 用来传递…...

惊!初中生也来卷了……
大家好,我是良许。 前两天在抖音直播的时候,突然来了一位不速之客…… 他自称是初中生,一开始我还有点不太相信,直到跟他连麦,听到他还略带一些稚嫩的声音,我才知道,他没有骗我…… 他说他想学…...

kafka相关配置介绍
kafka默认配置 每个kafka broker中配置文件server.properties默认必须配置的属性如下: broker.id0 num.network.threads2 num.io.threads8 socket.send.buffer.bytes1048576 socket.receive.buffer.bytes1048576 socket.request.max.bytes104857600 log.dirs/tmp/…...
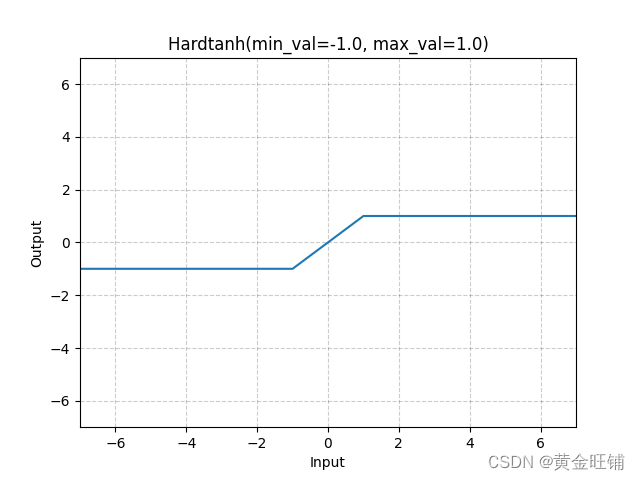
【PyTorch】教程:torch.nn.Hardtanh
torch.nn.Hardtanh 原型 CLASS torch.nn.Hardtanh(min_val- 1.0, max_val1.0, inplaceFalse, min_valueNone, max_valueNone) 参数 min_val ([float]) – 线性区域的最小值,默认为 -1max_val ([float]) – 线性区域的最大值,默认为 1inplace ([bool]) …...

神垕古镇景区5A级十年都没有实现的三大主因
钧 瓷 内 参 第40期(总第371期) 2023年3月5日 神垕古镇景区5A级十年都没有实现的三大主因 这是2013年,禹州市市政府第一次提出创建5A级景区到今年三月份整整十年啊! 目前神垕古镇景区是4A级景区,5A级一直进行中&a…...

API管理平台能力与数据盘点
API管理平台是现代企业IT架构中的核心组件,承担着接口设计、发布、运维、安全管控及生态开放等关键职责。不同平台在功能深度、性能指标和行业实践上各有积累。本文基于公开资料,对五款API管理平台的核心能力与关键数据进行客观梳理,以表格与…...

开源安全工具openclaw-killer:Nginx Lua环境威胁检测与防护实践
1. 项目概述:一个开源安全工具的诞生与使命最近在安全研究圈子里,一个名为openclaw-killer的项目引起了我的注意。这个由nkzprod维护的开源工具,名字就透着一股“杀气”——“OpenClaw杀手”。乍一看,你可能会以为这是某个游戏外挂…...

开源创富的三大支柱:技术、流量与商业化的完美结合
开源创富的三大支柱:技术、流量与商业化的完美结合 关键词:开源项目、技术壁垒、流量运营、商业化闭环、社区生态、价值变现、开源经济学 摘要:很多人对“开源”的理解停留在“免费送代码”,但实际上,开源是一套用技术…...

资源管理器约束设计:从核心原理到YARN/K8s实战配置
1. 项目概述:理解资源管理器约束的核心价值在任何一个复杂的计算或资源管理系统中,资源管理器(Resource Manager, 简称RM)都扮演着“交通警察”或“调度中心”的角色。它的核心职责是公平、高效地分配有限的系统资源&a…...
)
【Midjourney批量生成黄金工作流】:20年AI工程实战总结的7步标准化流水线(附可复用Prompt模板库)
更多请点击: https://intelliparadigm.com 第一章:Midjourney批量生成工作流的底层逻辑与范式演进 Midjourney 的批量生成并非简单重复调用 /imagine,其本质是围绕提示工程(Prompt Engineering)、状态管理(…...

如何打造高转化率的Primer CSS营销链接:CTA与导航链接设计指南
如何打造高转化率的Primer CSS营销链接:CTA与导航链接设计指南 【免费下载链接】css Primer is GitHubs design system. This is the CSS implementation 项目地址: https://gitcode.com/gh_mirrors/cs/css Primer CSS作为GitHub的官方设计系统,提…...

不只是画图:用Design Entry CIS画原理图符号,你真的理解引脚属性吗?
不只是画图:用Design Entry CIS画原理图符号,你真的理解引脚属性吗? 在电子设计自动化(EDA)领域,原理图符号的创建常被视为"简单绘图",但真正影响设计质量的往往是那些被忽视的细节。…...

ARIS:基于技能化工作流的AI自主研究系统设计与实践
1. 项目概述:ARIS,一个让AI在你睡觉时做研究的自主工作流 如果你是一名机器学习或计算机科学领域的研究者,我猜你肯定有过这样的体验:一个绝妙的想法在深夜闪现,你兴奋地爬起来记下几行潦草的笔记,然后第二…...

开源灵巧手OpenClaw:从机械设计到AI抓取的完整实现指南
1. 项目概述:当开源机械爪遇上AI大脑 最近在机器人开源社区里,一个名为“OpenClaw”的项目引起了我的注意。这个由Turbo Labs团队发布的项目,其核心目标非常明确:打造一个低成本、高性能、且完全开源的机器人灵巧手(或…...

技术人的“薪资锚点”策略:第一个报价为什么至关重要?
被低估的“第一印象”在软件测试领域,技术人习惯于与代码、逻辑和数据打交道,往往将薪资谈判视为一种非理性的“讨价还价”。然而,从行为经济学的视角审视,谈判的开局瞬间,其实已经为最终结果划定了无形的边界。那个最…...