2024/3/17周报
文章目录
- 摘要
- Abstract
- 文献阅读
- 题目
- 引言
- 模型架构
- 编码器和解码器堆栈
- Attention
- Position-wise Feed-Forward Networks
- Embeddings and Softmax
- Positional Encoding
- 实验数据
- 实验结果
- 深度学习
- Transformer
- Encoder
- Decoder
- 总结
摘要
本周阅读了Transformer的开山之作《Attention Is All You Need》。Transformer完全基于注意力机制,完全免除了递归和卷积。在两个机器翻译任务上的实验表明,Transformer模型在质量上是上级的,同时具有更好的并行性,并且训练时间也更少。此外,还对Transformer模型的原理进行了深入学习和研究。
Abstract
Transformer’s pioneering work , Attention Is All You Need is readed this week. Transformer is completely based on attention mechanism, which completely eliminates recursion and convolution. Experiments on two machine translation tasks show that the Transformer model is superior in quality, with better parallelism and less training time. In addition, the principle of Transformer model is deeply studied.
文献阅读
题目
Attention Is All You Need
引言
递归神经网络LSTM和GRU一直是序列建模和转导问题(如语言建模和机器翻译)的最新方法。这些递归模型生成隐藏状态ht的序列,作为前一个隐藏状态ht-1和位置t的输入的函数,从而导致缺少并行化。虽然最新的相关技术提高了一定程度的并行化,但顺序计算的基本约束仍然存在。
注意力机制已经成为各种任务中引人注目的序列建模和转导模型的组成部分,作者提出的Transformer模型架构能避免复发,完全依赖于注意力机制,以绘制输入和输出之间的全局依赖关系。Transformer支持更高的并行化,在8个P100 GPU上训练12小时后,翻译质量就能达到LSTM和GRU的最新水平。
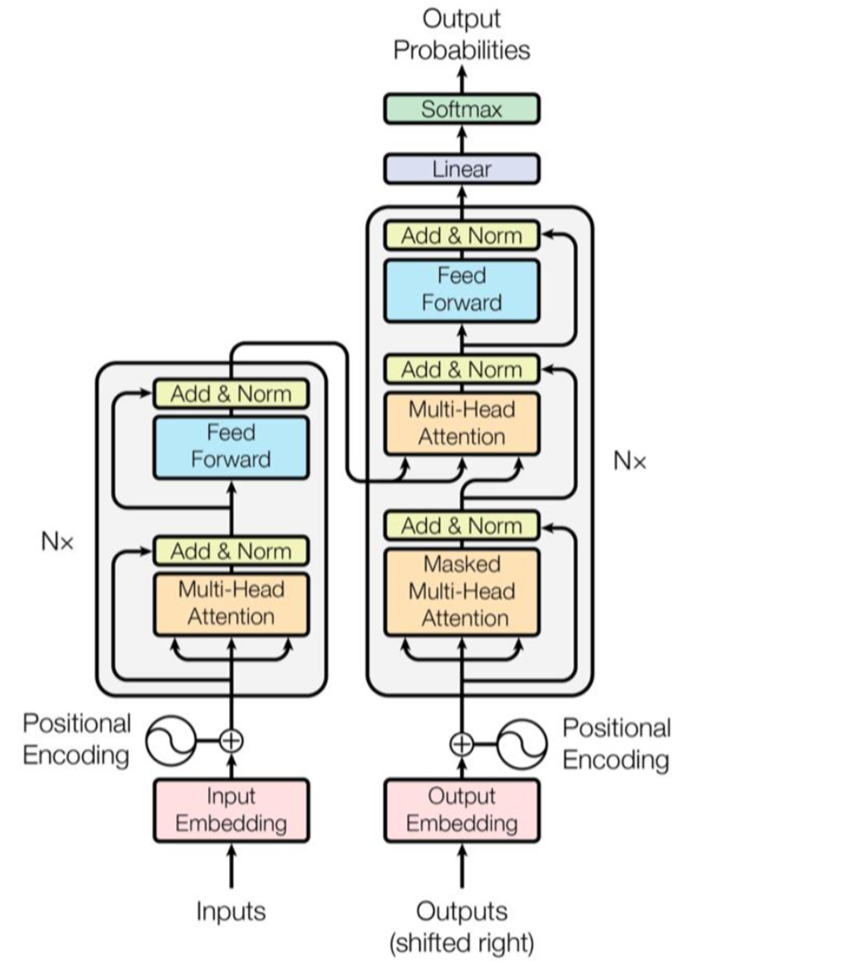
模型架构
Transformer也是由编码器和解码器的结构组成。编码器将符号表示的输入序列(x1,.,xn)转换为连续表示序列z =(z1,…,Zn)。给定z,解码器然后生成输出序列(y1,…,ym)中的每一个。在每一步,该模型是自回归的,在生成下一个符号时,消耗先前生成的符号作为附加输入。
Transformer遵循这种整体架构,编码器和解码器均使用堆叠的自注意和逐点全连接层,分别如下图的左半部分和右半部分所示:

编码器和解码器堆栈
编码器:编码器由N = 6个相同层的堆栈组成。每层有两个子层。第一个是多头自注意机制,第二个是一个简单的全连接前馈网络。两个子层中都使用残差连接,然后进行层归一化。即,每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是子层本身实现的函数。为了促进这些残差连接,模型中的所有子层以及嵌入层都产生维度dmodel = 512的输出。
解码器:解码器也是由一个堆栈的N = 6相同的层。除了每个编码器层中的两个子层之外,解码器还插入第三子层,该第三子层对编码器堆栈的输出执行多头注意。与编码器类似,作者在每个子层周围使用残差连接,然后进行层归一化。作者还修改了解码器堆栈中的自注意子层,以防止模型关注后续位置进行作弊。
Attention
注意力函数可以被描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量,输出计算为值的加权和。其中分配给每个值的权重由查询与对应键的compatibility函数计算。
下图为Scaled Dot-Product Attention(标度点积注意力):
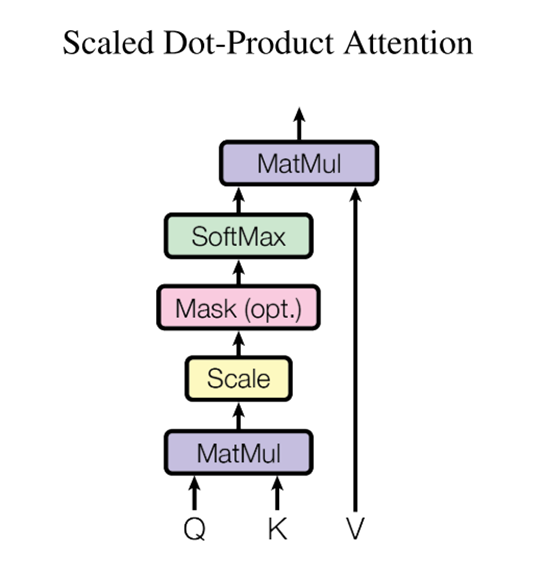
在实际中,同时计算一组查询的注意力函数,这些查询被打包到一个矩阵Q中。键和值被打包到矩阵K和V中。计算的输出矩阵为:

Multi-Head Attention(多头注意):
使用不同的学习线性投影将查询、键和值分别线性投影h次到dk、dk和dv维。并行执行注意力函数,产生dv维度的输出结果,这些数据被连接起来并再次投影,从而得到最终值,如下图所示:
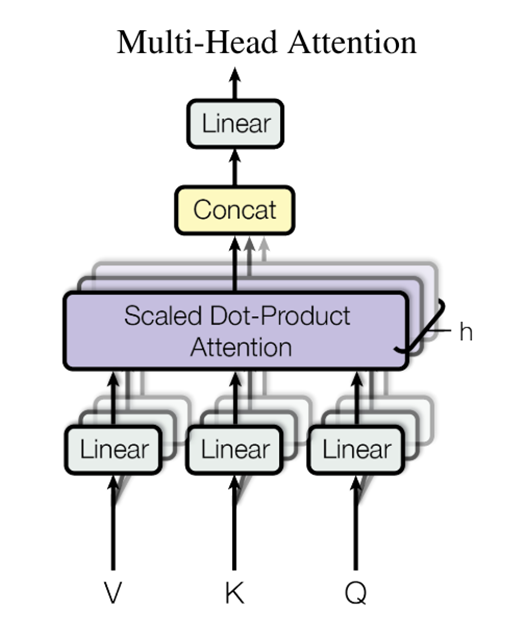
多头注意允许模型在不同的位置联合注意来自不同表示子空间的信息。对于一个单一的注意力头,平均化抑制了这一点。

其中投影是参数矩阵WQi ∈ Rdmodel×dk,WKi ∈ Rdmodel×dk,WVi ∈ Rdmodel×dv和WO ∈ Rdv ×dmodel。
在这项工作中,作者采用h = 8平行注意层(或称为头)。对于其中每一个,作者使用dk = dv = dmodel/h = 64。由于每个头的维数降低,总的计算成本类似于具有全维度的单头注意。
Position-wise Feed-Forward Networks
该层包括两个线性变换,中间有一个ReLU激活:
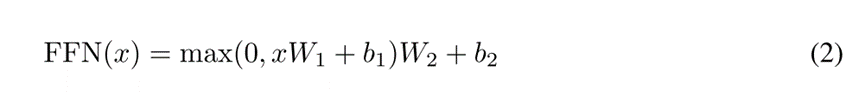
Embeddings and Softmax
与其他序列转换模型类似,该处使用学习的嵌入将输入令牌和输出令牌转换为维度dmodel的向量。作者还使用常用的学习线性变换和softmax函数将解码器输出转换为预测的下一个令牌概率。在该模型中,作者在两个嵌入层和pre-softmax线性变换之间共享相同的权重矩阵,并将这些权重乘以嵌入模型。
Positional Encoding
在编码器和解码器堆栈的底部向输入嵌入添加“位置编码”。位置编码与嵌入具有相同的维度dmodel,因此两者可以相加。
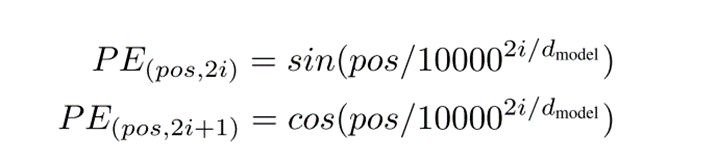
其中pos是位置,i是尺寸。即,位置编码的每个维度对应于正弦曲线。波长形成从2π到10000 · 2π的几何级数。选择正弦版本,因为它可以允许模型外推到比训练期间遇到的更长的序列长度。
实验数据
在标准的WMT 2014英语-德语数据集上进行了训练,该数据集由大约450万个句子对组成。句子使用字节对编码[3]进行编码,它具有大约37000个标记的共享源目标词汇表。对于英语-法语,作者使用了更大的WMT 2014英语-法语数据集,其中包含3600万个句子,并将标记拆分为32000个单词。句子对按近似序列长度分批在一起。每个训练批次包含一组句子对,其中包含大约25000个源标记和25000个目标标记。
使用Adam优化器[20],其中β1 = 0.9,β2 = 0.98,β 2 = 10^−9。根据以下公式在训练过程中改变学习率:
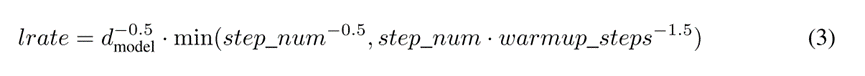
实验结果
机器翻译:
在WMT 2014英语到德语的翻译任务中,大Transformer模型(表2中的Transformer(大))比之前报道的最佳模型(包括集成)的BLEU高出2.0以上,建立了28.4的新的最先进的BLEU分数。
在WMT 2014英语到法语的翻译任务中,我们的大模型达到了41.0的BLEU分数,超过了之前发布的所有单个模型,而训练成本不到之前最先进模型的1/4。
英语选区分析:

表中的结果表明,尽管缺乏特定于任务的调整,Transformer模型表现得令人惊讶地好,产生的结果比所有先前模型都要好,即使只在WSJ训练集的40K句子上训练,Transformer也优于BerkeleyParser。
深度学习
Transformer
Transformer模型是在《Attention is All You Need》中提出的,最初是为了提高机器翻译的效率,它的 Self-Attention 机制和 Position Encoding 可以替代 RNN。因为 RNN 是顺序执行的,t 时刻没有处理完成就不能处理 t+1 时刻,因此很难并行。
Encoder
Encoder组件是由N = 6个同样的Encoder堆叠而成,每一个encoder由一个Multihead attention层和feed forward层(2层前馈网络)组成,同时这两个层都包含残差连接(Residual (short-circuit)connection)和LayerNorm,如下图:
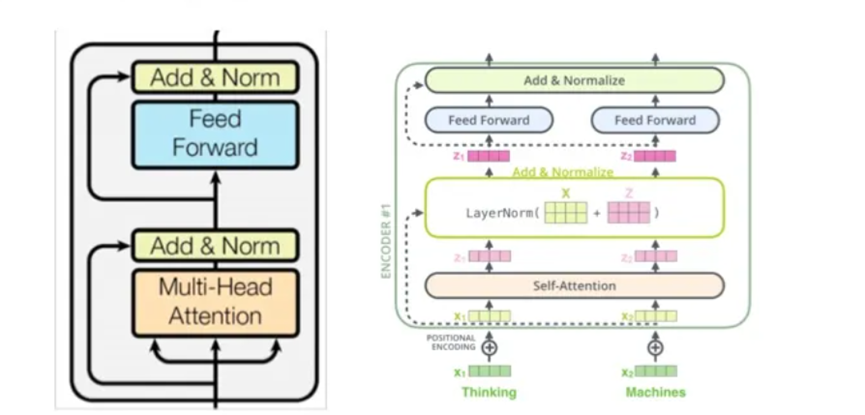
每一个encoder层如下:

作为第一个encoder的输出,还是记为X,作为第二个encoder的输入。
文中设置了6个encoder堆叠,重复上述过程6次,记最后即最上层的encoder为X,作为encoder的输入。
Decoder
Decoder组件也是由6个一样的decoder组成,decoder也有Mutihead attention层和feed forward层,但是在两个子层之间增加了attention层,该层有助于解码器能够关注到输入句子的相关部分,与seq2seq model的Attention作用相似。
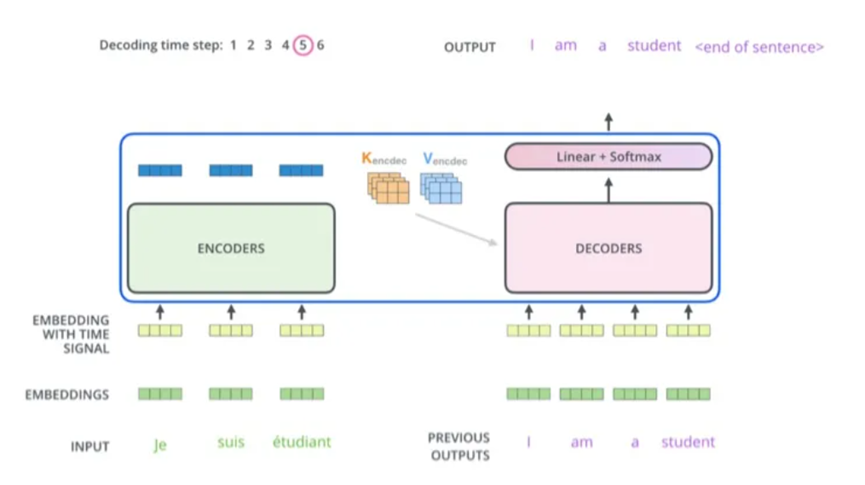
在inference阶段,在每个时刻,decoder有两个输入:

3.位置编码
接下来介绍decoder的详细流程。在模型训练过程中,输出结果即要翻译的结果,仍然记为 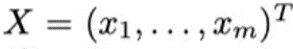 ,虽然记号和encoder一样,但参数并不共享,不是同一个X。
,虽然记号和encoder一样,但参数并不共享,不是同一个X。

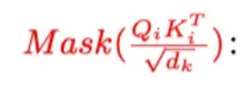 在decoder中用Mask矩阵抹去未来信息。矩阵
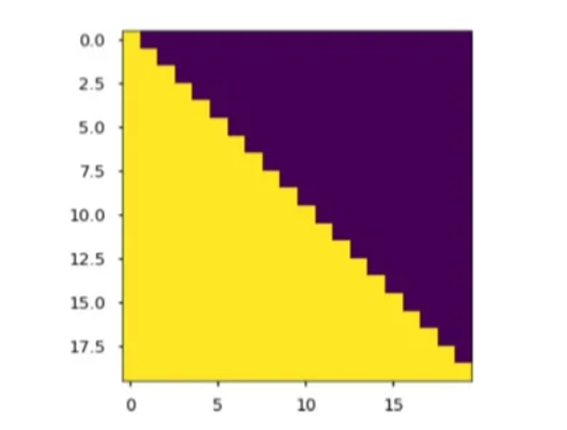
在decoder中用Mask矩阵抹去未来信息。矩阵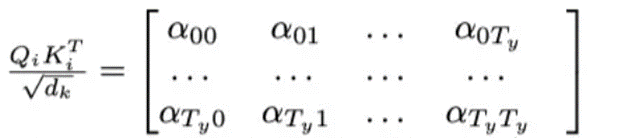 的每个元素aij代表了第i个词与第j个词的内积相似度。用下图所示的下三角矩阵作Mask,黄色部分的值是1,紫色部分的值为0,第0时刻(第0行)只有此时词自己跟自己的相似度,1时刻有和0时刻和1时刻的相似度。
的每个元素aij代表了第i个词与第j个词的内积相似度。用下图所示的下三角矩阵作Mask,黄色部分的值是1,紫色部分的值为0,第0时刻(第0行)只有此时词自己跟自己的相似度,1时刻有和0时刻和1时刻的相似度。

不断重复上述过程,直到输出特殊字符停止。
Transformer的损失函数为交叉熵损失,采用梯度下降法求解参数。
总结
Transformer的优势在于它能够并行计算,从而大大提高了训练和推理的效率。由于自注意力机制的引入,模型能够同时计算每个位置的表示,而不需要像RNN那样逐步处理序列。这使得Transformer能够处理更长的序列,从而在机器翻译等任务中取得了更好的效果。
但Transformer有着较高计算成本和优化难度,模型的复杂性导致在训练和推理过程中需要大量的计算资源,尤其是在处理大规模数据集时,需要大规模并行计算能力。此外,还需要仔细调整学习率、批量大小等超参数,以获得较好的性能。
相关文章:
2024/3/17周报
文章目录 摘要Abstract文献阅读题目引言模型架构编码器和解码器堆栈AttentionPosition-wise Feed-Forward NetworksEmbeddings and SoftmaxPositional Encoding 实验数据实验结果 深度学习TransformerEncoderDecoder 总结 摘要 本周阅读了Transformer的开山之作《Attention Is…...

函数连续性和Lipschitz连续性
摘要: 直观上,Lipschitz连续性的含义是函数图像的变化速度有一个全局的上限,即函数的增长速率不会无限增加。这种性质确保了函数在任何地方都不会过于陡峭,有助于分析函数的行为,并且在优化、动力系统理论、机器学习等…...
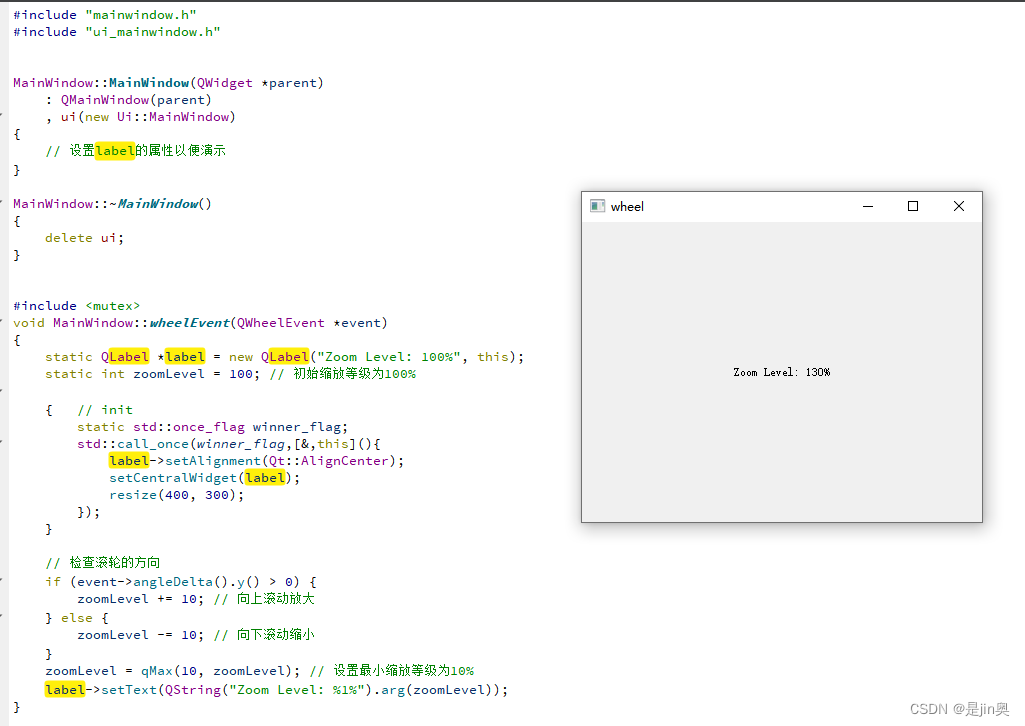
Qt 鼠标滚轮示例
1.声明 void wheelEvent(QWheelEvent *event) override;2.实现(方便复制、测试起见用静态变量) #include <mutex> void MainWindow::wheelEvent(QWheelEvent *event) {static QLabel *label new QLabel("Zoom Level: 100%", this);st…...
【Unity】进度条和血条的三种做法
前言 在使用Unity开发的时候,进度条和血条是必不可少的,本篇文章将简单介绍一下几种血条的制作方法。 1.使用Slider Slider组件由两部分组成:滑动区域和滑块。滑动区域用于显示滑动条的背景,而滑块则表示当前的数值位置。用户可…...
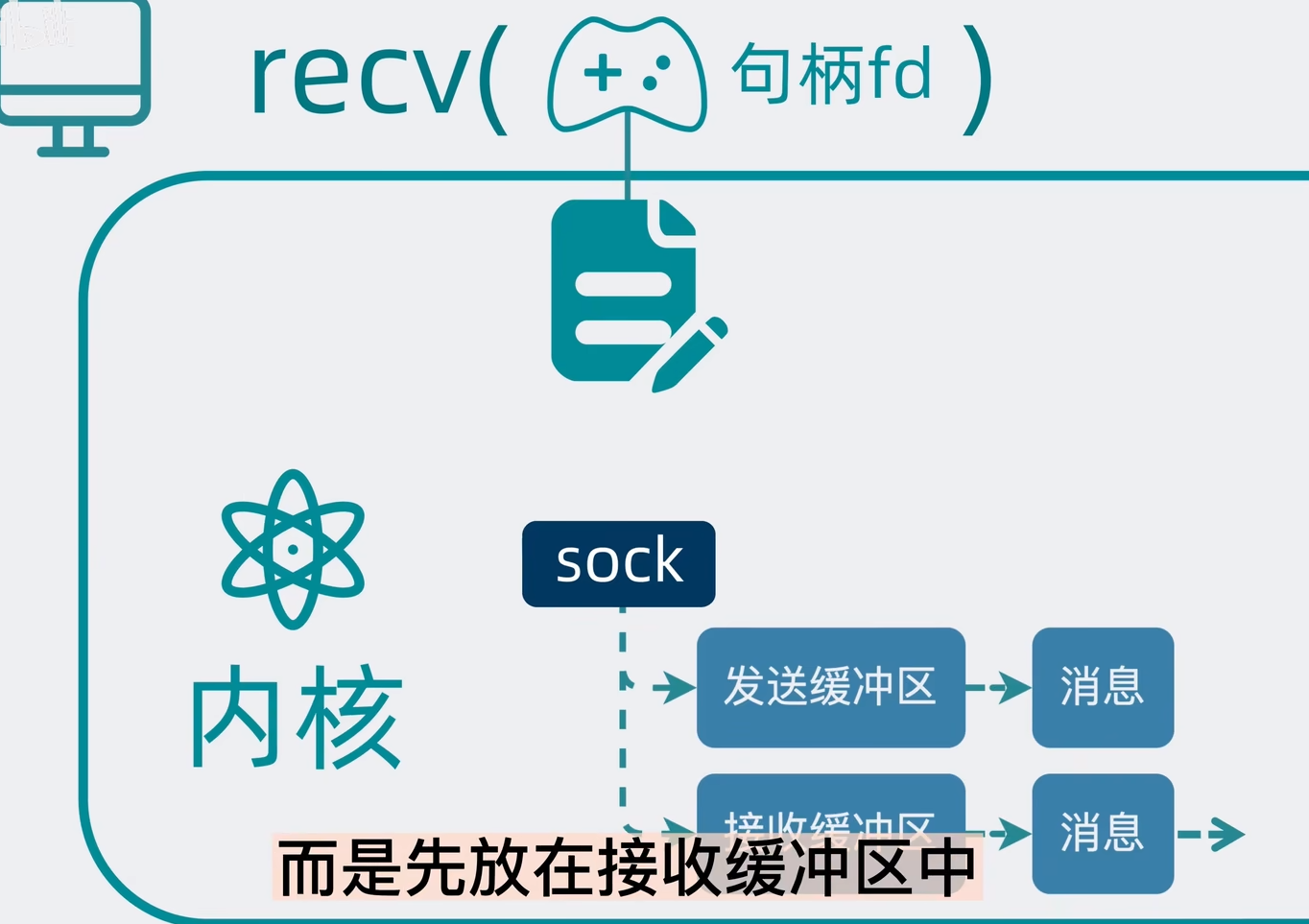
多人聊天室 (epoll - Linux网络编程)
文章目录 零、效果展示一、服务器代码二、客户端代码三、知识点1.connect()2.socket()3.bind()4.send()5.recv() 四、改进方向五、跟练视频 零、效果展示 一个服务器作为中转站,多个客户端之间可以相互通信。至少需要启动两个客户端。 三个客户端互相通信 一、服务…...
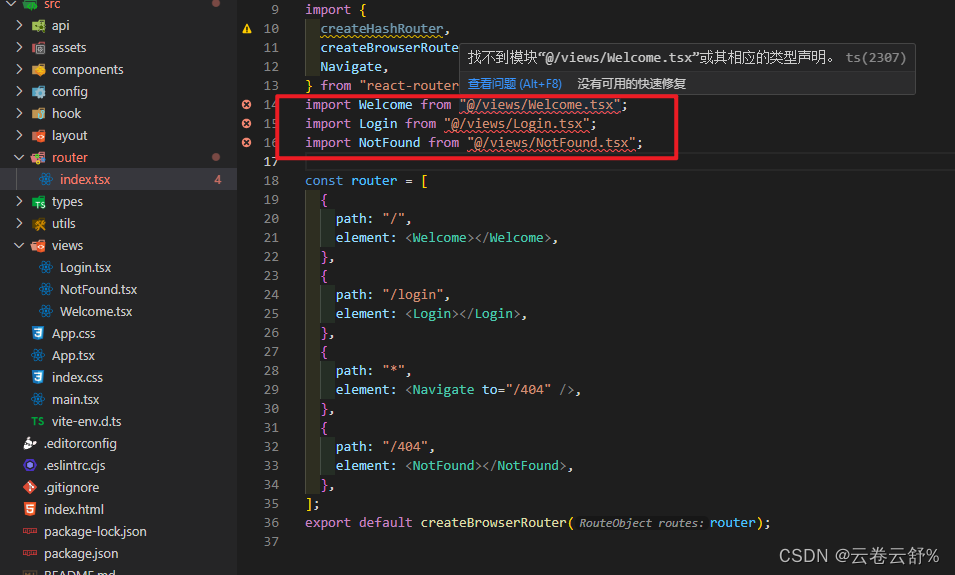
vite配置
"vite": "^5.1.4" resolve.alias:配置别名 1、执行npm install -D types/node 或者 yarn add types/node -D 2、以下配置代表访问src时可以用“”代替 resolve: {alias: {"": path.resolve(__dirname, "./src"),},}, 使…...

服务器生产环境问题解决思路
游戏服务器开发节奏比较快,版本迭代很频繁,有一些项目甚至出现了周更新(每周准时停服更新维护)。由于功能开发时间短,研发人员本身技术能力等原因,线上出现bug很常见。笔者经历过的游戏项目,一年到头没几次更新不出现bug的(当然,配置问题也算bug)。那当出现bug,我们…...

鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Column)
沿垂直方向布局的容器。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 可以包含子组件。 接口 Column(value?: {space?: string | number}) 从API version 9开始,该接口…...
LLM之RAG实战(三十)| 探索RAG语义分块策略
在LLM之RAG实战(二十九)| 探索RAG PDF解析解析文档后,我们可以获得结构化或半结构化的数据。现在的主要任务是将它们分解成更小的块来提取详细的特征,然后嵌入这些特征来表示它们的语义,其在RAG中的位置如图1所示&…...

软件测试-------Web(性能测试 / 界面测试 / 兼容性测试 / 安全性测试)
Web(性能测试 / 界面测试 / 兼容性测试 / 安全性测试) 一、Web性能测试:(压力测试、负载测试、连接速度测试)1、压力测试: 并发测试 (如500人同时登录邮箱) 2、负载测试…...
)
工欲善其事,必先利其器,Markdown和Mermaid的梦幻联动(2)
该文章Github地址:https://github.com/AntonyCheng/typora-notes/tree/master/chapter03-mermaid 在此介绍一下作者开源的SpringBoot项目初始化模板(Github仓库地址:https://github.com/AntonyCheng/spring-boot-init-template & CSDN文…...

STM32基础--使用寄存器点亮流水灯
GPIO 简介 GPIO 是通用输入输出端口的简称,简单来说就是 STM32 可控制的引脚,STM32 芯片的 GPIO 引脚与外部设备连接起来,从而实现与外部通讯、控制以及数据采集的功能。STM32 芯片的 GPIO被分成很多组,每组有 16 个引脚…...
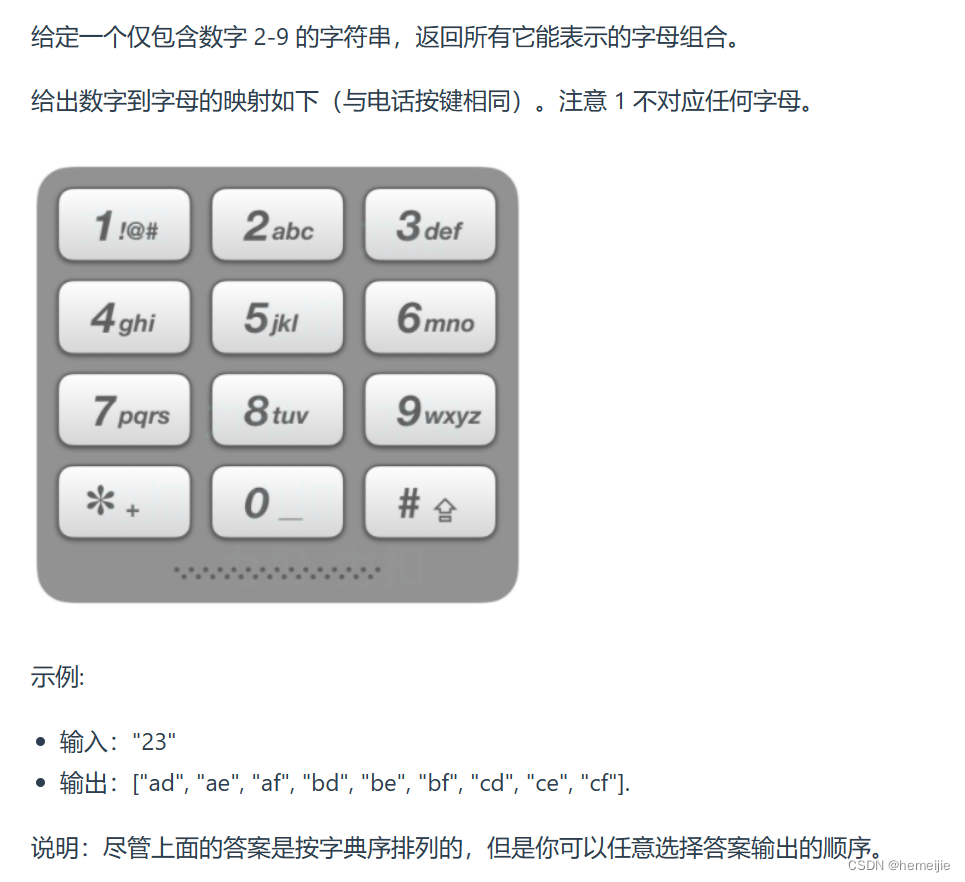
代码随想录训练营Day25:● 216.组合总和III ● 17.电话号码的字母组合
216.组合总和III 题目链接 https://leetcode.cn/problems/combination-sum-iii/description/ 题目描述 思路 自己写的效率会慢一些,而且没有用到剪枝 class Solution {List<List<Integer>> list new ArrayList<>();List<Integer> lis…...

SwiftUI的 特性 - ViewModify
SwiftUI的 特性 - ViewModify 记录一下SwiftUI的 特性 - ViewModify的使用方式 可以通过viewModify来管理视图的样式,结合extension来完成封装达到解偶效果 import SwiftUI/// 我们可以通过viewModify来管理视图的样式,来达到解偶效果 struct DefaultB…...
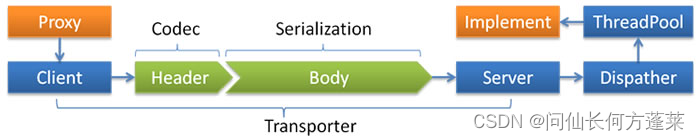
中间件 | RPC - [Dubbo]
INDEX 1 Dubbo 与 web 容器的关系2 注册发现流程3 服务配置3.1 注册方式 & 订阅方式3.2 服务导出3.3 配置参数 4 底层技术4.1 Dubbo 的 spi 机制4.2 Dubbo 的线程池4.3 Dubbo 的负载均衡策略4.3 Dubbo 的协议 1 Dubbo 与 web 容器的关系 dubbo 本质上是一个 RPC 框架&…...

【中等】保研/考研408机试-二叉树相关
目录 一、基本二叉树 1.1结构 1.2前序遍历(注意三种遍历中Visit所在的位置) 1.2中序遍历 1.3后序遍历 二、真题实战 2.1KY11 二叉树遍历(清华大学复试上机题)【较难】 2.2KY212 二叉树遍历二叉树遍历(华中科技大…...
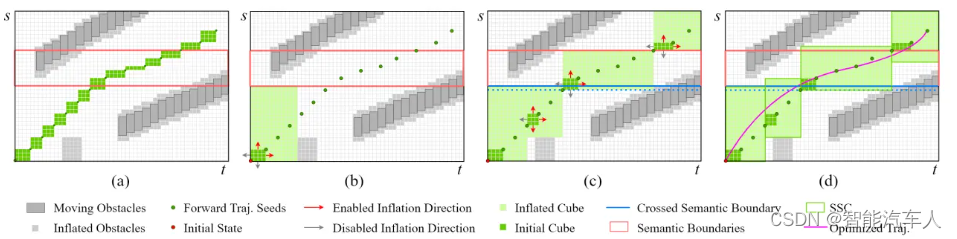
自动驾驶---Motion Planning之构建SLT Driving Corridor
1 背景 在上篇博客《自动驾驶---Motion Planning之Speed Boundary》中,主要介绍了Apollo中Speed Boundary的一些内容,可以构造ST图得到边界信息,最后结合粗糙的速度曲线和路径曲线,即可使用优化的方法求解得到最终的轨迹信息(s,s,s,l,l,l)。 本篇博客笔者主要介绍近…...
本地文件包含漏洞利用
目录 前期信息收集获取网站权限获取服务器权限纵向提权 前期信息收集 拿到目标的资产,先试一下IP能不能访问 探测一下目标的端口运行的是什么服务 nmap -sC -sV xx.xx9.95.185 -Pn获取网站权限 我们可以知道目标的80端口上运行着http服务,服务器是u…...
【docker】docker的常用命令
📝个人主页:五敷有你 🔥系列专栏:中间件 ⛺️稳中求进,晒太阳 常规命令 docker version #查看docker 版本信息docker info #显示docker 的系统信息,包括镜像和容器数量docker --help #查看所有的命…...

jmeter实战
jmeter学习 1,接口在定义时,post请求参数尽量放在body里面,get请求参数尽量放在parameters里面,否则会导致jmeter请求接口报错的问题(jmeter底层有较为严格的请求格式) 2,定义全局变量使用:Config Elemen…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

武汉国电华美串联谐振试验装置,现场用着心里有底
在高压试验现场干了这么多年,这位老师傅常说,一台好的串联谐振装置,就是试验人员的胆。面对GIS、大型变压器、超高压电缆这些大电容试品,没有趁手的谐振设备,交流耐压试验根本没法干。16875kVA/225kV这个规格ÿ…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...

因果推断与机器学习融合:量化分析社会运动中镇压与抗议的动态关系
1. 项目概述:当数据科学遇见社会运动如果你研究过社会运动,尤其是那些看似突然爆发、席卷全国的抗议浪潮,你可能会被一个核心问题困扰:国家机器的镇压,究竟是浇灭火焰的冷水,还是火上浇油的催化剂ÿ…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

WorkshopDL终极指南:无需Steam客户端也能轻松下载创意工坊模组
WorkshopDL终极指南:无需Steam客户端也能轻松下载创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在GOG或Epic Games Store购买了游戏࿰…...