python 第三方库(PyPinyin\shortuuid\json)
PyPinyin库
简介
PyPinyin库是一个支持中文转拼音输出的Python第三方库,它可以根据词组智能匹配最正确的拼音,并且支持多音字,简单的繁体, 注音,多种不同拼音/注音风格的转换。
安装
(framework-learn) C:\Users\zzg>pip install pypinyin
Collecting pypinyinDownloading pypinyin-0.51.0-py2.py3-none-any.whl.metadata (12 kB)
Downloading pypinyin-0.51.0-py2.py3-none-any.whl (1.4 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.4/1.4 MB 273.9 kB/s eta 0:00:00
Installing collected packages: pypinyin
Successfully installed pypinyin-0.51.0使用
pypin方法
返回列表List,每个元素都是另外成了一个列表,其中包含了每个字的读音( pinyin 方法默认使用了 TONE 的风格,即有声调的风格模式)
# 引入第三方库:PyPinyin
from pypinyin import pinyin# 基本用法
print(pinyin("四月"))词是多音词,需添加 heteronym 参数并设置为 True
温馨提示:这里的多音词并不是指单个字的多音字,而是这个词语本身就有两种读音。
from pypinyin import pinyin# 基本用法
print(pinyin("四月"))# 多音词
print(pinyin("中心", heteronym=True))lazy_pinyin方法
将汉字转换为拼音,返回不包含多音字结果的拼音列表(lazy_pinyin 方法默认使用了 NORMAL,即无声调的风格模式)
# 引入第三方库:PyPinyin
from pypinyin import pinyin
from pypinyin import lazy_pinyin# 基本用法
print(pinyin("四月"))# 多音词
print(pinyin("中心", heteronym=True))# 返回一维列表
print(lazy_pinyin("你是我的眼"))音标风格转换
对转音标结果进行一些风格转换,比如不带声调风格、标准声调风格、声调在拼音之后、声调在韵母之后、注音风格等等
# 引入第三方库:PyPinyin
from pypinyin import pinyin
from pypinyin import lazy_pinyin
from pypinyin import Style# 基本用法
print(pinyin("四月"))# 多音词
print(pinyin("中心", heteronym=True))# 返回一维列表
print(lazy_pinyin("你是我的眼"))# 拼音风格指定:不带声调风格、标准声调风格、声调在拼音之后、声调在韵母之后、注音风格
print(lazy_pinyin("我爱你,我的中国", style=Style.NORMAL))音标风格详解:
#: 普通风格,不带声调。如: 中国 -> ``zhong guo``
NORMAL = 0
#: 标准声调风格,拼音声调在韵母第一个字母上(默认风格)。如: 中国 -> ``zhōng guó``
TONE = 1
#: 声调风格2,即拼音声调在各个韵母之后,用数字 [1-4] 进行表示。如: 中国 -> ``zho1ng guo2``
TONE2 = 2
#: 声调风格3,即拼音声调在各个拼音之后,用数字 [1-4] 进行表示。如: 中国 -> ``zhong1 guo2``
TONE3 = 8
#: 声母风格,只返回各个拼音的声母部分(注:有的拼音没有声母,详见 `#27`_)。如: 中国 -> ``zh g``
INITIALS = 3
#: 首字母风格,只返回拼音的首字母部分。如: 中国 -> ``z g``
FIRST_LETTER = 4
#: 韵母风格,只返回各个拼音的韵母部分,不带声调。如: 中国 -> ``ong uo``
FINALS = 5
#: 标准韵母风格,带声调,声调在韵母第一个字母上。如:中国 -> ``ōng uó``
FINALS_TONE = 6
#: 韵母风格2,带声调,声调在各个韵母之后,用数字 [1-4] 进行表示。如: 中国 -> ``o1ng uo2``
FINALS_TONE2 = 7
#: 韵母风格3,带声调,声调在各个拼音之后,用数字 [1-4] 进行表示。如: 中国 -> ``ong1 uo2``
FINALS_TONE3 = 9
#: 注音风格,带声调,阴平(第一声)不标。如: 中国 -> ``ㄓㄨㄥ ㄍㄨㄛˊ``
BOPOMOFO = 10
#: 注音风格,仅首字母。如: 中国 -> ``ㄓ ㄍ``
BOPOMOFO_FIRST = 11
#: 汉语拼音与俄语字母对照风格,声调在各个拼音之后,用数字 [1-4] 进行表示。如: 中国 -> ``чжун1 го2``
CYRILLIC = 12
#: 汉语拼音与俄语字母对照风格,仅首字母。如: 中国 -> ``ч г``
CYRILLIC_FIRST = 13
PyPinyin异常/错误处理
如果我们输入的语句中,有无法转换成拼音的字符存在,我们就会引入PyPinyin库自带的errors参数
# 引入第三方库:PyPinyin
from pypinyin import pinyin
from pypinyin import lazy_pinyin
from pypinyin import Style# 基本用法
print(pinyin("四月"))# 多音词
print(pinyin("中心", heteronym=True))# 返回一维列表
print(lazy_pinyin("你是我的眼"))# 拼音风格指定:不带声调风格、标准声调风格、声调在拼音之后、声调在韵母之后、注音风格
print(lazy_pinyin("我爱你,我的中国", style=Style.NORMAL))# 拼音异常处理, 遇到无法解析直接默认输出
print(lazy_pinyin("我爱你,我的中国"))errors 不同参数会对应不同的处理结果
1、默认是按照原文输出
2、errors = ignore, 将不能转拼音的字符去掉
# 引入第三方库:PyPinyin
from pypinyin import pinyin
from pypinyin import lazy_pinyin, load_phrases_dict
from pypinyin import Style# 基本用法
print(pinyin("四月"))# 多音词
print(pinyin("中心", heteronym=True))# 返回一维列表
print(lazy_pinyin("你是我的眼"))# 拼音风格指定:不带声调风格、标准声调风格、声调在拼音之后、声调在韵母之后、注音风格
print(lazy_pinyin("我爱你,我的中国", style=Style.NORMAL))# 拼音异常处理, 遇到无法解析直接默认输出
print(lazy_pinyin("我爱你,我的中国"))# 拼音异常处理, 遇到无法解析直接直接过滤
print(lazy_pinyin("我爱你,我的中国", errors="ignore"))3、errors = lambda item:将无法转化的为音标的字符,转换成指定字符
# 引入第三方库:PyPinyin
from pypinyin import pinyin
from pypinyin import lazy_pinyin, load_phrases_dict
from pypinyin import Style# 基本用法
print(pinyin("四月"))# 多音词
print(pinyin("中心", heteronym=True))# 返回一维列表
print(lazy_pinyin("你是我的眼"))# 拼音风格指定:不带声调风格、标准声调风格、声调在拼音之后、声调在韵母之后、注音风格
print(lazy_pinyin("我爱你,我的中国", style=Style.NORMAL))# 拼音异常处理, 遇到无法解析直接默认输出
print(lazy_pinyin("我爱你,我的中国"))# 拼音异常处理, 遇到无法解析直接直接过滤
print(lazy_pinyin("我爱你,我的中国", errors="ignore"))# 拼音异常处理, 遇到无法解析通过lambda 指定输出
print(lazy_pinyin("我爱你,我的中国", errors=lambda item: ''.join(['*' if i == ',' else i for i in item])))自定义拼音
如果对PyPinyin库返回的结果不满意,我们可以自定义自己的拼音库。
from pypinyin import pinyin
from pypinyin import lazy_pinyin, load_phrases_dict
from pypinyin import Style# 基本用法
print(pinyin("四月"))# 多音词
print(pinyin("中心", heteronym=True))# 返回一维列表
print(lazy_pinyin("你是我的眼"))# 拼音风格指定:不带声调风格、标准声调风格、声调在拼音之后、声调在韵母之后、注音风格
print(lazy_pinyin("我爱你,我的中国", style=Style.NORMAL))# 拼音异常处理, 遇到无法解析直接默认输出
print(lazy_pinyin("我爱你,我的中国"))# 拼音异常处理, 遇到无法解析直接直接过滤
print(lazy_pinyin("我爱你,我的中国", errors="ignore"))# 拼音异常处理, 遇到无法解析通过lambda 指定输出
print(lazy_pinyin("我爱你,我的中国", errors=lambda item: ''.join(['*' if i == ',' else i for i in item])))# 自定义拼音
print(lazy_pinyin('大夫'))
personalized_dict = {'大夫': [['da'], ['fu']]
}
load_phrases_dict(personalized_dict)
print(lazy_pinyin('大夫'))shortuuid库
简介
shortuuid库是一个用于简单生成UUID。
安装
(framework-learn) C:\Users\zzg>pip install shortuuid
Collecting shortuuidDownloading shortuuid-1.0.13-py3-none-any.whl.metadata (5.8 kB)
Downloading shortuuid-1.0.13-py3-none-any.whl (10 kB)
Installing collected packages: shortuuid
Successfully installed shortuuid-1.0.13使用
快速生成UUID
# shortuuid uuid 生成工具
import shortuuid# 基础uuid 输出
print(shortuuid.uuid())快速生成UUID 并同时指定命名空间(URL/DNS)
# shortuuid uuid 生成工具
import shortuuid# 基础uuid 输出
print(shortuuid.uuid())# uuid 生成并不指定命名空间
print(shortuuid.uuid(name="www.baidu.com"))
# uuid 生成并指定命名空间
print(shortuuid.uuid(name="https://www.baidu.com"))快速生成UUID,并指定生成长度
# shortuuid uuid 生成工具
import shortuuid# 基础uuid 输出
print(shortuuid.uuid())# uuid 生成并不指定命名空间
print(shortuuid.uuid(name="www.baidu.com"))
# uuid 生成并指定命名空间
print(shortuuid.uuid(name="https://www.baidu.com"))# uuid 生成并指定长度
print(shortuuid.random(length=10))查看UUID生成字母表
import shortuuid# 基础uuid 输出
print(shortuuid.uuid())# uuid 生成并不指定命名空间
print(shortuuid.uuid(name="www.baidu.com"))
# uuid 生成并指定命名空间
print(shortuuid.uuid(name="https://www.baidu.com"))# uuid 生成并指定长度
print(shortuuid.random(length=10))# 查看uuid 生成字母表
print(shortuuid.get_alphabet())
设置UUID字母生成表
# shortuuid uuid 生成工具
import shortuuid# 基础uuid 输出
print(shortuuid.uuid())# uuid 生成并不指定命名空间
print(shortuuid.uuid(name="www.baidu.com"))
# uuid 生成并指定命名空间
print(shortuuid.uuid(name="https://www.baidu.com"))# uuid 生成并指定长度
print(shortuuid.random(length=10))# 查看uuid 生成字母表
print(shortuuid.get_alphabet())# 设置uuid 生成字母表
shortuuid.set_alphabet(alphabet="123456789")print(shortuuid.uuid())快速生成UUID 加密和解密
# shortuuid uuid 生成工具
import shortuuid# 基础uuid 输出
print(shortuuid.uuid())# uuid 生成并不指定命名空间
print(shortuuid.uuid(name="www.baidu.com"))
# uuid 生成并指定命名空间
print(shortuuid.uuid(name="https://www.baidu.com"))# uuid 生成并指定长度
print(shortuuid.random(length=10))# 查看uuid 生成字母表
print(shortuuid.get_alphabet())# 设置uuid 生成字母表
shortuuid.set_alphabet(alphabet="123456789")print(shortuuid.uuid())# uuid 加密encode和解密decode
import uuid
u = uuid.uuid4()
print(u)# 加密
s = shortuuid.encode(u)
print(s)# 解密
print(shortuuid.decode(s))快速生成UUID,对应实现类
# shortuuid uuid 生成工具
import shortuuid# 基础uuid 输出
print(shortuuid.uuid())# uuid 生成并不指定命名空间
print(shortuuid.uuid(name="www.baidu.com"))
# uuid 生成并指定命名空间
print(shortuuid.uuid(name="https://www.baidu.com"))# uuid 生成并指定长度
print(shortuuid.random(length=10))# 查看uuid 生成字母表
print(shortuuid.get_alphabet())# 设置uuid 生成字母表
shortuuid.set_alphabet(alphabet="123456789")print(shortuuid.uuid())# uuid 加密encode和解密decode
import uuid
u = uuid.uuid4()
print(u)# 加密
s = shortuuid.encode(u)
print(s)# 解密
print(shortuuid.decode(s))# uuid 类实例化
su = shortuuid.ShortUUID()# su 调用基础uuid
print(su.uuid())
json库
简介
Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数:
- json.dumps(): 对数据进行编码。
- json.loads(): 对数据进行解码。
安装
Python 默认自带库
使用
Python 数据格式转换为json 格式字符串
import json# 构建json对象
data = {'no': 1,'name': 'Runoob','url': 'http://www.runoob.com'
}
# json.dumps() 将Python数据类型转换为json格式的字符串。
obj = json.dumps(data)
print(type(obj))
print(obj)将json格式的字符串转换为Python数据类型(字典或列表)
#json 工具类
import json# 构建json对象
data = {'no': 1,'name': 'Runoob','url': 'http://www.runoob.com'
}
# json.dumps() 将Python数据类型转换为json格式的字符串。
obj = json.dumps(data)
print(type(obj))
print(obj)# json.loads() 将json格式的字符串转换为Python数据类型(字典或列表)。
di = json.loads(obj)
print(type(di))
print(di)json 格式的字符串取值
import json# 构建json对象
data = {'no': 1,'name': 'Runoob','url': 'http://www.runoob.com'
}
# json.dumps() 将Python数据类型转换为json格式的字符串。
obj = json.dumps(data)
print(type(obj))
print(obj)# json.loads() 将json格式的字符串转换为Python数据类型(字典或列表)。
di = json.loads(obj)
print(type(di))
print(di)
# json 格式字符串取值
print(di['no'])json 格式的字符串赋值
#json 工具类
import json# 构建json对象
data = {'no': 1,'name': 'Runoob','url': 'http://www.runoob.com'
}
# json.dumps() 将Python数据类型转换为json格式的字符串。
obj = json.dumps(data)
print(type(obj))
print(obj)# json.loads() 将json格式的字符串转换为Python数据类型(字典或列表)。
di = json.loads(obj)
print(type(di))
print(di)
# json 格式字符串取值
print(di['no'])# json 格式字符串重新赋值
di['no']= 10print(di)
相关文章:
)
python 第三方库(PyPinyin\shortuuid\json)
PyPinyin库 简介 PyPinyin库是一个支持中文转拼音输出的Python第三方库,它可以根据词组智能匹配最正确的拼音,并且支持多音字,简单的繁体, 注音,多种不同拼音/注音风格的转换。 安装 (framework-learn) C:\Users\zzg>pip …...
)
一文解读ISO26262安全标准:术语(二)
一文解读ISO26262安全标准:术语(二) 本文继续补充一些标准中的术语,方便后续文章内容的有效理解。 分支覆盖率 branch coverage 控制流分支覆盖的比率. 100%分支覆盖率意味着100%语句覆盖率,比如,一个if语句…...
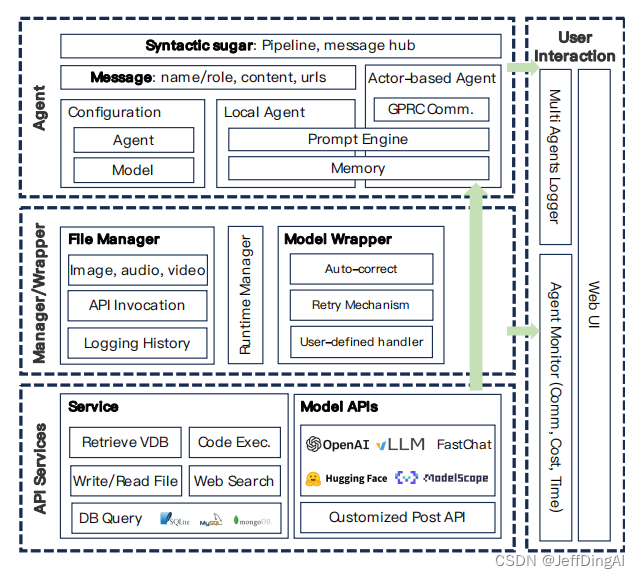
【Datawhale学习笔记】从大模型到AgentScope
从大模型到AgentScope AgentScope是一款全新的Multi-Agent框架,专为应用开发者打造,旨在提供高易用、高可靠的编程体验! 高易用:AgentScope支持纯Python编程,提供多种语法工具实现灵活的应用流程编排,内置…...

QWebEngineView添加自定义网址协议UrlScheme
QWebEngineView可以和js交互需要使用QWebChannel,如果不使用的话,js可以请求自定义网址协议,相当于请求服务器,但是不用Qt专门做服务器,不占用系统端口。 如果结合系统自定义URL注册,可以达到访问自定义UR…...

react中使用腾讯地图
腾讯文档 申请好对应key 配置限额 https://lbs.qq.com/service/webService/webServiceGuide/webServiceQuota 代码 用到的服务端接口 1.逆地址解析 2.关键词输入提示 import React, { Component } from react; import styles from ./map.less import { Form, Row, Col, I…...
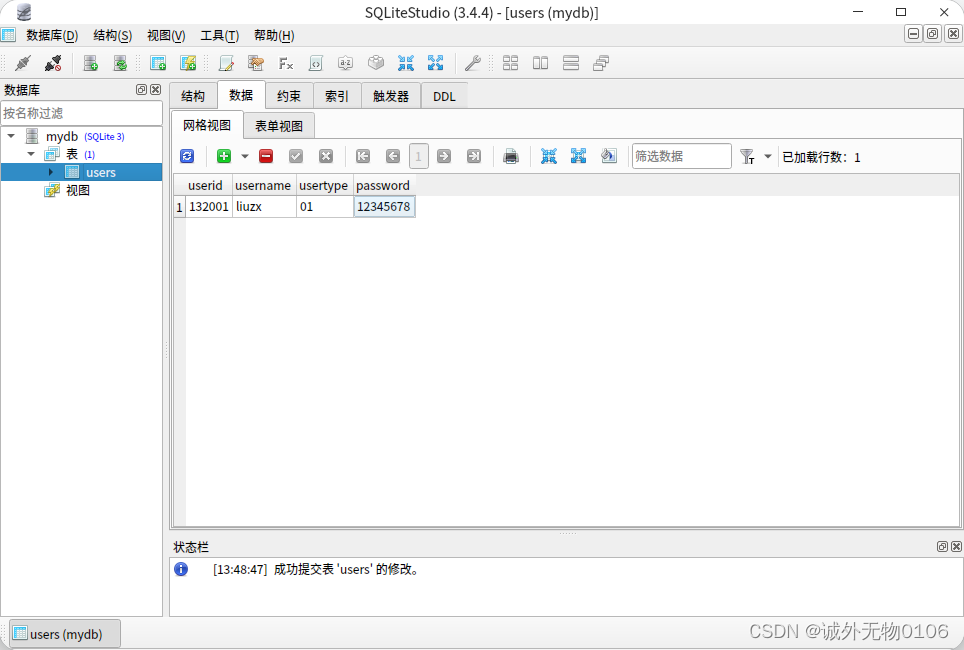
deepin23beta中SQLite3数据库安装与使用
SQLite 是一个嵌入式 SQL 数据库引擎,它实现了一个自包含、无服务器、零配置、事务性 SQL 数据库引擎。 SQLite 的代码属于公共领域,因此可以免费用于任何商业或私人目的。 SQLite 是世界上部署最广泛的数据库,其应用程序数量之多,…...

前后端分离项目环境搭建
1. 使用到的技术和工具 springboot vue项目的搭建 工具 idea,mavennodejs 2. 后端框架搭建 利用maven创建springboot项目 3. 前端项目搭建 1. 安装相关工具 nodejs: 一个开源、跨平台的 JavaScript 运行时环境,可以理解成java当中需要…...

HTML静态网页成品作业(HTML+CSS)——家乡漳州介绍设计制作(1个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有1个页面。 二、作品演示 三、代…...
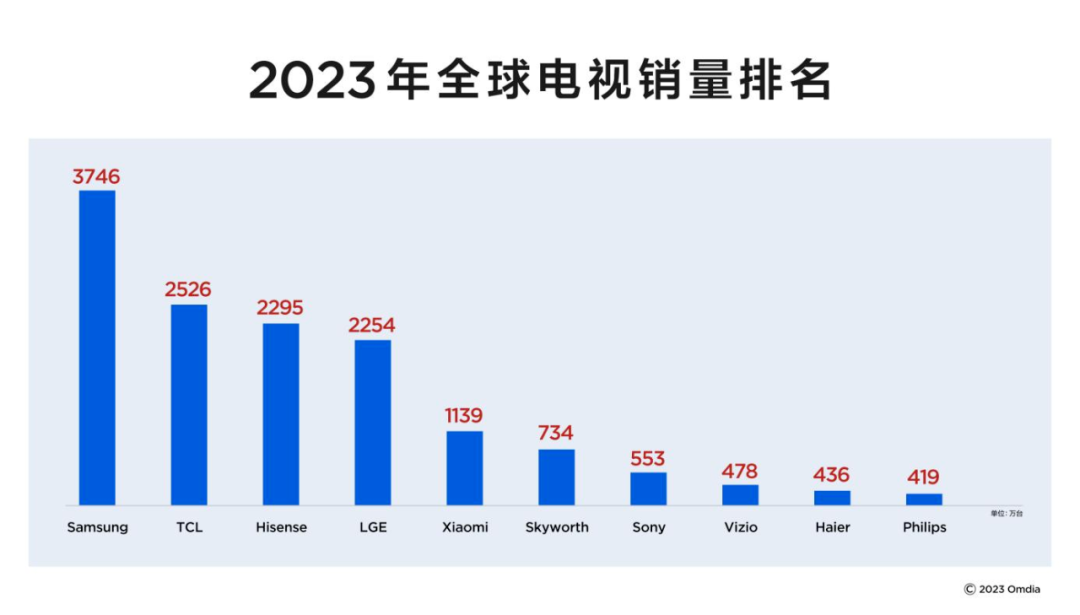
世界第二对海信到底有多重要?
作者 | 辰纹 来源 | 洞见新研社 不久前,全球权威市场研究机构Omdia公布了2023年全球电视销量排名,数据显示TCL电视全球销量达到了2526万台,位居全球第二,中国第一。 可是,同样是根据Omdia的数据,海信的官…...
多站合一的音乐搜索下载助手PHP源码l亲测
源码获取方式 回复:031601 搭建教程: 将源码下载上传至宝塔面板,直接运行即可~ 说明: 该源码进行测试,测试成功源码无加密优化相关其他采集问题。...

webserver烂大街?还有必要做么?
目录 什么是 Web Server? 如何提供 HTTP 服务? HTTP协议 简介 工作原理 工作步骤 HTTP请求报文格式 HTTP响应报文格式 HTTP请求方法 HTTP状态码 总结 都说webserver是C选手人手必备的烂大街项目,那么webserver 还有必要做么&…...

3.Redis命令
Redis命令 Redis 根据命令所操作对象的不同, 可以分为三大类: 对 Redis 进行基础性操作的命令,对 Key 的操作命令,对 Value 的操作命令。 1.1 Redis 首先通过 redis-cli 命令进入到 Redis 命令行客户端,然后再运行下…...

xray问题排查,curl: (35) Encountered end of file(已解决)
经过了好几次排查,都没找到问题,先说问题的排查过程,多次确认了user信息,包括用户id和alterid,都没问题,头大的一逼 问题排查过程 确保本地的xray服务是正常的 [rootk8s-master01 xray]# systemctl stat…...
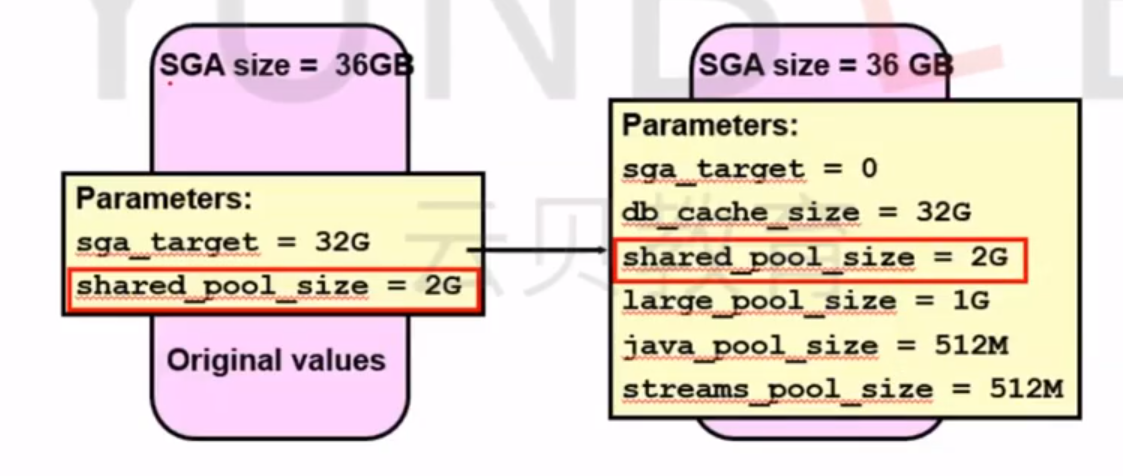
【数据库】Oracle内存结构与参数调优
Oracle内存结构与参数调优 Oracle 内存结构概览oracle参数配置概览重要参数(系统运行前配置):次要参数(可在系统运行后再优化调整): Oracle数据库服务器参数如何调整OLTP内存分配操作系统核心参数配置Disabling ASMM(禁…...

PS学习-抠图-蒙版-冰块酒杯等透明物体
选中图,ctrlA 全选 ctrlC复制 创建一个蒙版图层 选中蒙版Alt 点击进入 ctrlv 复制 ctrli 反转 原图层 ctrldelete填充为白色 添加一个背景,这个方法通用 首选创建一个 拖到最底部 给它填充颜色 这个可能是我图片的原因。视频是这样做的...
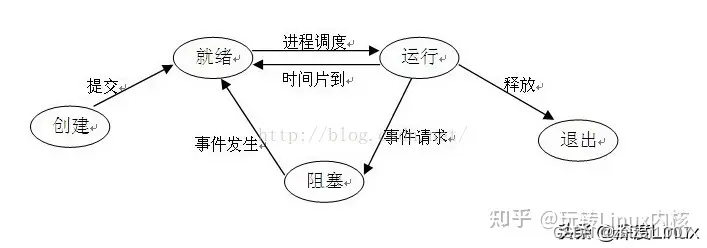
绝赞春招拯救计划 -- 操作系统,组成原理,计网
进程和线程 进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以…...

c语言:于龙加
于龙加 任务描述 于龙同学设计了一个特别的加法规则,加法被重新定义了,我们称为于龙加。 两个非负整数的于龙加的意义是将两个整数按前后顺序连接合并形成一个新整数。 于龙想编程解决于龙加问题,可是对下面的程序他没有思路! …...

AcWing 790:数的三次方根 ← 浮点数二分
【题目来源】https://www.acwing.com/problem/content/792/【题目描述】 给定一个浮点数 n,求它的三次方根。【输入格式】 共一行,包含一个浮点数 n。【输出格式】 共一行,包含一个浮点数,表示问题的解。 注意,结果保留…...

【LLM】LLama2模型(RMSNorm、SwiGLU、RoPE位置编码)
note 预训练语言模型除了自回归(Autoregressive)模型GPT,还有自编码模型(Autoencoding)BERT[1]、编-解码(Encoder-Decoder)模型BART[67],以及融合上述三种方法的自回归填空…...

【力扣白嫖日记】1934.确认率
前言 练习sql语句,所有题目来自于力扣(https://leetcode.cn/problemset/database/)的免费数据库练习题。 今日题目: 1934.确认率 表:Signups 列名类型user_idinttime_stampdatetime User_id是该表的主键。每一行都…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...

3分钟掌握抖音视频批量下载:解放双手的素材收集革命
3分钟掌握抖音视频批量下载:解放双手的素材收集革命 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为一个个手动保存抖音视频而烦恼吗?想要高效收集创作者素材却苦于没有合适的…...

原来专业的赛事专用匹克球厂家有这么多门道?
引言在匹克球运动蓬勃发展的当下,专业赛事专用匹克球的选择至关重要。很多人可能不知道,看似普通的赛事专用匹克球背后,其实隐藏着诸多门道。接下来,我们就一起深入探究专业赛事专用匹克球厂家的秘密。核心技术与材料的门道专业赛…...

你的CI流水线还在忽略圈复杂度?DeepSeek 2.3.0强制拦截策略上线倒计时:最后72小时适配指南
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与行业影响 DeepSeek圈复杂度分析并非简单复用McCabe指标,而是基于AST(抽象语法树)动态路径建模与控制流图(CFG)拓扑…...