SpingBoot集成Rabbitmq及Docker部署
文章目录
- 介绍
- RabbitMQ的特点
- Rabbitmq术语
- 消息发布接收流程
- Docker部署
- 管理界面说明
- Overview: 这个页面显示了RabbitMQ服务器的一般信息,例如集群节点的名字、状态、运行时间等。
- Connections: 在这里,可以查看、管理和关闭当前所有的TCP连接。
- Channels: 这个页面展示了所有当前打开的通道以及它们的详细信息。外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
- Exchanges: 可以在这里查看、创建和删除交换机。
- Queues: 这个页面展示了所有当前的队列以及它们的详细信息。
- Admin: 在这里,可以查看系统中所有的操作用户。
- 延时队列插件下载安装
- rabbitmq.conf配置文件示例
- 1.1 rabbitmq.conf
- 1.2 advanced.config
- 1.3 rabbitmq-env.conf
- Java配置
- Yml完整配置
- RabbitMQ的六种工作模式
- 消费者@RabbitListener注解下的配置内容
- 1.simple简单模式(点对点模式)
- 2.work工作模式(一对多)
- 3.publish/subscribe发布订阅(共享资源)
- 4.routing路由模式
- 5.topic 主题模式(路由模式的一种)
- 6.RPC (基于消息的远程过程调用)
- 延时队列、循环队列、兜底机制、定时任务
- 1.延时队列
- 使用TTL+死信队列组合实现延迟队列的效果。
- 使用RabbitMQ官方延迟插件,实现延时队列效果。
- 2.循环队列
- 3.兜底机制
- 4.定时任务
介绍
RabbitMQ是由Erlang语言开发的AMQP的开源实现
AMQP:Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ的特点
可靠性(Reliablity):使用了一些机制来保证可靠性,比如持久化、传输确认、发布确认。灵活的路由(Flexible Routing):在消息进入队列之前,通过Exchange来路由消息。对于典型的路由功能,Rabbit已经提供了一些内置的Exchange来实现。针对更复杂的路由功能,可以将多个Exchange绑定在一起,也通过插件机制实现自己的Exchange。消息集群(Clustering):多个RabbitMQ服务器可以组成一个集群,形成一个逻辑Broker。高可用(Highly Avaliable Queues):队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。多种协议(Multi-protocol):支持多种消息队列协议,如STOMP、MQTT等。多种语言客户端(Many Clients):几乎支持所有常用语言,比如Java、.NET、Ruby等。管理界面(Management UI):提供了易用的用户界面,使得用户可以监控和管理消息Broker的许多方面。跟踪机制(Tracing):如果消息异常,RabbitMQ提供了消息的跟踪机制,使用者可以找出发生了什么。插件机制(Plugin System):提供了许多插件,来从多方面进行扩展,也可以编辑自己的插件
Rabbitmq术语
-
消费者:订阅某个队列 -
生产者::创建消息,然后发布到队列中(queue),最终将消息发送到监听的消费者。 -
Broker:标识消息队列服务器实体. -
Virtual Host:虚拟主机。标识一批交换机、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个vhost本质上就是一个mini版的RabbitMQ服务器,拥有自己的队列、交换器、绑定和权限机制。vhost是AMQP概念的基础,必须在链接时指定,RabbitMQ默认的vhost是 /。 -
Exchange:交换机,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。 -
Queue:消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。 -
Banding:绑定,用于消息队列和交换机之间的关联。一个绑定就是基于路由键将交换机和消息队列连接起来的路由规则,所以可以将交换机理解成一个由绑定构成的路由表。 -
Channel:通道,多路复用连接中的一条独立的双向数据流通道。通道是建立在真实的TCP连接内的虚拟链接,AMQP命令都是通过通道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过通道完成。因为对于操作系统来说,建立和销毁TCP都是非常昂贵的开销,所以引入了通道的概念,以复用一条TCP连接。 -
Connection:网络连接,比如一个TCP连接。 -
Publisher:消息的生产者,也是一个向交换器发布消息的客户端应用程序。 -
Consumer:消息的消费者,表示一个从一个消息队列中取得消息的客户端应用程序。 -
Message:消息,消息是不具名的,它是由消息头和消息体组成。消息体是不透明的,而消息头则是由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(优先级)、delivery-mode(消息可能需要持久性存储[消息的路由模式])等。
消息发布接收流程
1.发送消息
- 生产者和Broker建立TCP连接。
- 生产者和Broker建立通道。
- 生产者通过通道消息发送给Broker,由Exchange将消息进行转发。
- Exchange将消息转发到指定的Queue(队列)
2.接收消息
- 消费者和Broker建立TCP连接 。
- 消费者和Broker建立通道
- 消费者监听指定的Queue(队列)
- 当有消息到达Queue时Broker默认将消息推送给消费者。
- 消费者接收到消息。
Docker部署
查询rabbitmq最新版本
docker search rabbitmq #查询镜像 已经集成了erlang,无需单独安装erlang
docker pull rabbitmq #拉取镜像 最新版,或指定版本 docker pull rabbitmq:3.13-management 自带管理界面
docker images # 查看拉取的镜像
#启动容器 指定管理界面登陆账号和密码
# 15672 管理界面端口
# 5672 amqp协议端口,程序连接端口
# -v /mnt/data/rabbitmq/conf:/etc/rabbitmq 配置文件目录
# -v /mnt/data/rabbitmq/data:/var/lib/rabbitmq 数据目录
# -v /mnt/data/rabbitmq/log:/var/log/rabbitmq 日志目录
# -e RABBITMQ_DEFAULT_USER=tlmroot 管理界面登陆账号
# -e RABBITMQ_DEFAULT_PASS=123456 管理界面登陆密码
# 最好限制容器内存 --memory 2g
docker run -d --hostname rabbitmq --name rabbitmq --restart=always -v /mnt/data/rabbitmq/conf:/etc/rabbitmq -v /mnt/data/rabbitmq/data:/var/lib/rabbitmq -v /mnt/data/rabbitmq/log:/var/log/rabbitmq -p 15672:15672 -p 5672:5672 -e RABBITMQ_DEFAULT_USER=tlmroot -e RABBITMQ_DEFAULT_PASS=123456 rabbitmq:latest
# docker ps 如果容器启动失败,需要提高日志挂载目录的访问权限后重启服务
chmod 777 /mnt/data/rabbitmq/log
# 进入容器内部安装管理界面插件
docker exec -it rabbitmq /bin/bash
# 容器内部创建管理界面插件 安装完成即可访问 服务器IP加15672,如无法访问 关闭防火墙 systemctl stop firewalld
rabbitmq-plugins enable rabbitmq_management
# 容器内部启用所有功能标志,也可以在管理界面操作(Admin/Feature Flags)
enable all feature flags
#至此创建完成 服务器需要开放15672和5672端口

管理界面说明

Totals 消息数,队列消息、连接数、通道数、交换机数、队列数、消费者数
Nodes:节点信息 进程数、磁盘数据、运行时间、等
Churn statistics: 流失率统计,最后一分钟连接操作、通道操作、队列操作
Ports and contexts: 端口信息及网络环境信息
Export definitions: 导出配置
Import definitions:导入配置

Virtual host: 所属的虚拟主机。Name: 名称。User name: 使用的用户名。State: 当前的状态,running:运行中;idle:空闲。SSL/TLS: 是否使用ssl进行连接。Protocol: 使用的协议。Channels: 创建的channel的总数。From client: 每秒发出的数据包。To client: 每秒收到的数据包。

channel:名称。
Virtual host:所属的虚拟主机。
User name:使用的用户名。
Mode:渠道保证模式。 可以是以下之一,或者不是:C: confirm。T:transactional(事务)。
State :当前的状态,running:运行中;idle:空闲。
Unconfirmed:待confirm的消息总数。
Prefetch:设置的prefetch的个数。
Unacker:待ack的消息总数。
publish:生产端 pub消息的速率。
confirm:生产端确认消息的速率。
deliver/get:消费端获取消息的速率。
ack:消费端 ack消息的速率

Name:名称。Type:exchange type,具体的type可以查看RabbitMq系列之一:基础概念。Features:持久化,D:持久化 I:内部 AD:自动删除Message rate in:消息输入速率。Message rate out:消息输出速率Add a new exchange:Virtual host:属于哪个Virtual host,我这里只有一个所以不显示Name:名字,同一个Virtual host里面的Name不能重复。Durability: 是否持久化,Durable:持久化。Transient:不持久化。Auto delete:当最后一个绑定(队列或者exchange)被unbind之后,该exchange自动被删除。Internal: 是否是内部专用exchange,是的话,就意味着我们不能往该exchange里面发消息。Arguments: 参数,是AMQP协议留给AMQP实现做扩展使用的

Virtual host: 所属的虚拟主机。
Name: 名称。
Features: 功能。(参数参考上述交换机页面)
State: 当前的状态,running:运行中;idle:空闲。
Ready: 待消费的消息总数。
Unacked: 待应答的消息总数。
Total: 总数 Ready+Unacked。
incoming: 消息进入的速率。
deliver/get: 消息获取的速率。
ack: 消息应答的速率。
Add a new queue:Virtual host:属于哪个Virtual hostName:名字,同一个Virtual host里面的Name不能重复。Durability: 是否持久化,Durable:持久化。Transient:不持久化。Auto delete:当最后一个绑定(队列或者exchange)被unbind之后,该 queue 自动被删除。Arguments: 参数,是AMQP协议留给AMQP实现做扩展使用的

Name: 名称。
Tags: 角色标签,只能选取一个。
Can access virtual hosts: 允许进入的vhost。
Has password: 设置了密码。
Virtual Host:虚拟主机
虚拟主机(vhost)提供逻辑分组和资源分离。每一个vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的connection、exchange、queue、binding等,拥有自己的权限。vhost之于RabbitMQ就像虚拟机于物理机一样,他们通过在各个实例间提供逻辑上分离,允许为不同的应用程序安全保密的运行数据。
Feature Flags:功能标志开关
Deprecated Features:已废特性
Policies:策略配置
策略分为“用户策略”和“系统策略”
策略使用的是正则表达匹配规则,按名称匹配一个或多个队列,并将其定义的一些规则(参数)到匹配队列中。换句话说,可以使用策略一次为多个队列配置参数。策略可以理解为给“队列”和“分发器”设置额外的“Arguments”参数。每个“分发器”和“队列”只能生效一个“策略”,并且是是立即生效的。参数:Apply to:指定策略是只匹配队列、还是只匹配交换,或两则两者都匹配。Priority:表示的是策略的优先级、值越大,优先级越高。Definition:才是真正的规则。有四大类,分别是HA(高可用性)、federation(联合)、Queues(队列)、Exchanges(备用分发器)HA(高可用性):表示将队列怎么镜像到节点的策略。ha-mode:选项有三个,分别是“all“(表示同步到所有节点),“exactly”,“nodes”。"exactly"和"nodes"需要结合ha-params才能决定同步策略ha-params:为数值、表示个数ha-sync-mode:(手动(manual)/自动(automatic)同步)
Limits 可以设置最大连接数
Cluster 集群 更改集群名称
延时队列插件下载安装
延时插件链接地址3.13.0,下载版本和rabbitmq版本要一致 我安装的是 3.13.0
# 下载插件到/home/目录,
curl -JL https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases/download/v3.13.0/rabbitmq_delayed_message_exchange-3.13.0.ez -o /home/rabbitmq_delayed_message_exchange-3.13.0.ez
# 可省略,进入容器查询插件目录,三方插件需要放在这里 (ez结尾的文件,/opt/rabbitmq/plugins)
rabbitmq-plugins directories -s
# 容器/opt/rabbitmq/plugins 为插件目录 延时队列插件需要复制到这里
docker cp /home/rabbitmq_delayed_message_exchange-3.13.0.ez rabbitmq:/opt/rabbitmq/plugins
# 进入容器内部查询插件,
docker exec -it rabbitmq /bin/bash
# rabbitmq-plugins list 如下图
rabbitmq-plugins list
# 安装插件命令同安装管理界面命令 rabbitmq-plugins enable 《plugin_name》
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
# 安装完成后 界面Exchanges(交换机),新增的时候就会出现x-delayed-message


rabbitmq.conf配置文件示例
容器运行后,默认没有配置文件,自带的配置足够使用,自行创建放在主机/mnt/data/rabbitmq/conf/目录,或是放在容器/etc/rabbitmq目录,创建容器时已映射
容器内部查询有效配置
rabbitmqctl environment
RabbitMQ 常用的三种自定义服务器的通用方法:配置文件 rabbitmq.conf环境变量文件 rabbitmq-env.conf补充配置文件 advanced.configrabbitmq.conf和rabbitmq-env.conf的位置在二进制安装中路径是在 :安装目录下的/etc/rabbitmq/rpm 安装: /etc/rabbitmq/如果rabbitmq.conf和rabbitmq-env.conf 的两个文件不存在,那么我们可以创建该文件,然后我们可以通过环境变量
指定该文件的位置。补充 :rabbitmqctl rabbitmqctl 是管理虚拟主机和用户权限的工具rabbitmq-plugins 是管理插件的工具
1.1 rabbitmq.conf
| 属性 | 描述 | 默认值 |
|---|---|---|
| listeners | 要监听 AMQP 0-9-1 and AMQP 1.0 的端口 | listeners.tcp.default = 5672 |
| num_acceptors.tcp | 接受tcp连接的erlang 进程数 | num_acceptors.tcp = 10 |
| handshake_timeout | AMQP 0-9-1 超时时间,也就是最大的连接时间,单位毫秒 | handshake_timeout = 10000 |
| listeners.ssl | 启用TLS的协议 | 默认值为none |
| num_acceptors.ssl | 接受基于TLS协议的连接的erlang 进程数 | num_acceptors.ssl = 10 |
| ssl_options | TLS 配置 | ssl_options =none |
| ssl_handshake_timeout | TLS 连接超时时间 单位为毫秒 | ssl_handshake_timeout = 5000 |
| vm_memory_high_watermark | 触发流量控制的内存阈值,可以为相对值(0.5),或者绝对值 vm_memory_high_watermark.relative = 0.6 ,vm_memory_high_watermark.absolute = 2GB | 默认vm_memory_high_watermark.relative = 0.4 |
| vm_memory_calculation_strategy | 内存使用报告策略,assigned:使用Erlang内存分配器统计信息 rss:使用操作系统RSS内存报告。这使用特定于操作系统的方法,并可能启动短期子进程。legacy:使用遗留内存报告(运行时认为将使用多少内存)。这种策略相当不准确。erlang 与legacy一样 是为了向后兼容 | vm_memory_calculation_strategy = allocated |
| vm_memory_high_watermark_paging_ratio | 当内存的使用达到了50%后,队列开始将消息分页到磁盘 | vm_memory_high_watermark_paging_ratio = 0.5 |
| total_memory_available_override_value | 该参数用于指定系统的可用内存总量,一般不使用,适用于在容器等一些获取内存实际值不精确的环境 | 默认未设置 |
| disk_free_limit | Rabbitmq存储数据的可用空间限制,当低于该值的时候,将触发流量限制,设置可参考vm_memory_high_watermark参数 | disk_free_limit.absolute = 50MB |
| log.file.level | 控制记录日志的等级,有info,error,warning,debug | log.file.level = info |
| channel_max | 最大通道数,但不包含协议中使用的特殊通道号0,设置为0表示无限制,不建议使用该值,容易出现channel泄漏 | channel_max = 2047 |
| channel_operation_timeout | 通道操作超时,单位为毫秒 | channel_operation_timeout = 15000 |
| heartbeat | 表示连接参数协商期间服务器建议的心跳超时的值。如果两端都设置为0,则禁用心跳,不建议禁用 | heartbeat = 60 |
| default_vhost | rabbitmq安装后启动创建的虚拟主机 | default_vhost = / |
| default_user | 默认创建的用户名 | default_user = guest |
| default_pass | 默认用户的密码 | default_pass = guest |
| default_user_tags | 默认用户的标签 | default_user_tags.administrator = true |
| default_permissions | 在创建默认用户是分配给默认用户的权限 | default_permissions.configure = .* default_permissions.read = .* default_permissions.write = .* |
| loopback_users | 允许通过回环地址连接到rabbitmq的用户列表,如果要允许guest用户远程连接(不安全)请将该值设置为none,如果要将一个用户设置为仅localhost连接的话,配置loopback_users.username =true(username要替换成用户名) | loopback_users.guest = true(默认为只能本地连接) |
| cluster_formation.classic_config.nodes | 设置集群节点cluster_formation.classic_config.nodes.1 = rabbit@hostname1 | |
| cluster_formation.classic_config.nodes.2 = rabbit@hostname2 | 默认为空,未设置 | |
| collect_statistics | 统计收集模式,none 不发出统计信息事件,coarse每个队列连接都发送统计一次,fine每发一条消息的统计数据 | collect_statistics = none |
| collect_statistics_interval | 统计信息收集间隔,以毫秒为单位 | collect_statistics_interval = 5000 |
| delegate_count | 用于集群内通信的委托进程数。在多核的服务器上我们可以增加此值 | delegate_count = 16 |
| tcp_listen_options | 默认的套接字选项 | tcp_listen_options.backlog = 128 … |
| hipe_compile | 设置为true以使用HiPE预编译RabbitMQ的部分,HiPE是Erlang的即时编译器,启用HiPE可以提高吞吐量两位数,但启动时会延迟几分钟。Erlang运行时必须包含HiPE支持。如果不是,启用此选项将不起作用。HiPE在某些平台上根本不可用,尤其是Windows。 | hipe_compile = false |
| cluster_keepalive_interval | 节点应该多长时间向其他节点发送keepalive消息(以毫秒为单位),keepalive的消息丢失不会被视为关闭 | cluster_keepalive_interval = 10000 |
| queue_index_embed_msgs_below | 消息的字节大小,低于该大小,消息将直接嵌入队列索引中 bytes | queue_index_embed_msgs_below = 4096 |
| mnesia_table_loading_retry_timeout | 等待集群中Mnesia表可用的超时时间,单位毫秒 | mnesia_table_loading_retry_timeout = 30000 |
| mnesia_table_loading_retry_limit | 集群启动时等待Mnesia表的重试次数,不适用于Mnesia升级或节点删除。 | mnesia_table_loading_retry_limit = 10 |
| mirroring_sync_batch_size | 要在队列镜像之间同步的消息的批处理大小 | mirroring_sync_batch_size = 4096 |
| queue_master_locator | 队列主节点的策略,有三大策略 min-masters,client-local,random | queue_master_locator = client-local |
| proxy_protocol | 如果设置为true ,则连接需要通过反向代理连接,不能直连接 | proxy_protocol = false |
| management.listener.port | rabbitmq web管理界面使用的端口 | management.listener.port = 15672 |
1.2 advanced.config
某些配置设置不可用或难以使用sysctl格式进行配置。因此,可以使用Erlang术语格式的其他配置文件advanced.config
它将与rabbitmq.conf 文件中提供的配置合并。
| 属性 | 描述 | 默认值 |
|---|---|---|
| msg_store_index_module | 设置队列索引使用的模块 | {rabbit,[ {msg_store_index_module,rabbit_msg_store_ets_index} ]} |
| backing_queue_module | 队列内容的实现模块。 | {rabbit,[ {backing_queue_module,rabbit_variable_queue} ]} |
| msg_store_file_size_limit | 消息储存的文件大小,现有的节点更改是危险的,可能导致数据丢失 | 默认值16777216 |
| trace_vhosts | 内部的tracer使用,不建议更改 | {rabbit,[ {trace_vhosts,[]} ]} |
| msg_store_credit_disc_bound | 设置消息储存库给队列进程的积分,默认一个队列进程被赋予4000个消息积分 | {rabbit, [{msg_store_credit_disc_bound, {4000, 800}}]} |
| queue_index_max_journal_entries | 队列的索引日志超过该阈值将刷新到磁盘 | {rabbit, [{queue_index_max_journal_entries, 32768}]} |
| lazy_queue_explicit_gc_run_operation_threshold | 在内存压力下为延迟队列设置的值,该值可以触发垃圾回收和减少内存使用,降低该值,会降低性能,提高该值,会导致更高的内存消耗 | {rabbit,[{lazy_queue_explicit_gc_run_operation_threshold, 1000}]} |
| queue_explicit_gc_run_operation_threshold | 在内存压力下,正常队列设置的值,该值可以触发垃圾回收和减少内存使用,降低该值,会降低性能,提高该值,会导致更高的内存消耗 | {rabbit, [{queue_explicit_gc_run_operation_threshold, 1000}]} |
1.3 rabbitmq-env.conf
通过rabbitmq-env.conf 来定义环境变量
RABBITMQ_NODENAME 指定节点名称
| 属性 | 描述 | 默认值 |
|---|---|---|
| RABBITMQ_NODE_IP_ADDRESS | 绑定的网络接口 | 默认为空字符串表示绑定本机所有的网络接口 |
| RABBITMQ_NODE_PORT | 端口 | 默认为5672 |
| RABBITMQ_DISTRIBUTION_BUFFER_SIZE | 节点之间通信连接的数据缓冲区大小 | 默认为128000,该值建议不要使用低于64MB |
| RABBITMQ_IO_THREAD_POOL_SIZE | 运行时用于io的线程数 | 建议不要低于32,linux默认为128 ,windows默认为64 |
| RABBITMQ_NODENAME | rabbitmq节点名称,集群中要注意节点名称唯一 | linux 默认节点名为 rabbit@$hostname |
| RABBITMQ_CONFIG_FILE | rabbitmq 的配置文件路径,注意不要加文件的后缀(.conf) | 默认 $RABBITMQ_HOME/etc/rabbitmq/rabbitmq(二进制安装) /etc/rabbitmq/rabbitmq(rpm 安装) |
| RABBITMQ_ADVANCED_CONFIG_FILE | advanced.config文件路径 | 默认 $RABBITMQ_HOME/etc/rabbitmq/advanced(二进制安装) /etc/rabbitmq/advanced(rpm 安装) |
| RABBITMQ_CONF_ENV_FILE | 环境变量配置文件路径 | 默认 $RABBITMQ_HOME/etc/rabbitmq/rabbitmq-env.conf(二进制安装) /etc/rabbitmq/rabbitmq-env.conf(rpm 安装) |
| RABBITMQ_SERVER_CODE_PATH | 在使用HiPE 模块时需要使用 | 默认为空 |
| RABBITMQ_LOGS | 指定日志文件位置 | 默认为 $RABBITMQ_HOME/etc/var/log/rabbitmq/ |
RABBITMQ_DISTRIBUTION_BUFFER_SIZE 节点间通信缓冲区大小,默认值 128Mb,节点流量比较多的集群中,可以提升该值,建议该值不要低于64MB。
tcp 缓存区大小
下示例将AMQP 0-9-1连接的TCP缓冲区设置为192 KiB:
tcp_listen_options.backlog = 128
tcp_listen_options.nodelay = true
tcp_listen_options.linger.on = true
tcp_listen_options.linger.timeout = 0
tcp_listen_options.sndbuf = 196608
tcp_listen_options.recbuf = 196608
Java配置
<!-- Maven依赖,Springboot默认集成-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
Yml完整配置
spring:rabbitmq:host: 127.0.0.1 #ipport: 5672 #端口username: tlmroot #账号password: 123456 #密码virtualHost: #链接的虚拟主机 ,切换不同环境 dev\test\prodaddresses: 127.0.0.1:5672 #多个以逗号分隔,与host功能一样。requestedHeartbeat: 60 #指定心跳超时,单位秒,0为不指定;默认60spublisherConfirms: true #发布确认机制是否启用publisherReturns: #发布返回是否启用connectionTimeout: #链接超时。单位ms。0表示无穷大不超时### ssl相关ssl:enabled: #是否支持sslkeyStore: #指定持有SSL certificate的key store的路径keyStoreType: #key store类型 默认PKCS12keyStorePassword: #指定访问key store的密码trustStore: #指定持有SSL certificates的Trust storetrustStoreType: #默认JKStrustStorePassword: #访问密码algorithm: #ssl使用的算法,例如,TLSv1.1verifyHostname: #是否开启hostname验证### cache相关cache:channel: size: #缓存中保持的channel数量checkoutTimeout: #当缓存数量被设置时,从缓存中获取一个channel的超时时间,单位毫秒;如果为0,则总是创建一个新channelconnection:mode: #连接工厂缓存模式:CHANNEL 和 CONNECTIONsize: #缓存的连接数,只有是CONNECTION模式时生效### listenerlistener:type: #两种类型,SIMPLE,DIRECT 默认simple## simple类型 simple: # 一对一concurrency: #最小消费者数量maxConcurrency: #最大的消费者数量transactionSize: #指定一个事务处理的消息数量,最好是小于等于prefetch的数量missingQueuesFatal: #是否停止容器当容器中的队列不可用## 与direct相同配置部分autoStartup: #是否自动启动容器acknowledgeMode: #表示消息确认方式,其有三种配置方式,分别是none、manual和auto;默认autoprefetch: #指定一个请求能处理多少个消息,如果有事务的话,必须大于等于transaction数量defaultRequeueRejected: #决定被拒绝的消息是否重新入队;默认是true(与参数acknowledge-mode有关系)idleEventInterval: #container events发布频率,单位ms##重试机制retry: stateless: #有无状态enabled: #是否开启maxAttempts: #最大重试次数,默认3initialInterval: #重试间隔multiplier: #对于上一次重试的乘数maxInterval: #最大重试时间间隔direct: # 一对多consumersPerQueue: #每个队列消费者数量missingQueuesFatal:#...其余配置看上方公共配置## template相关template:mandatory: #是否启用强制信息;默认falsereceiveTimeout: #`receive()`接收方法超时时间replyTimeout: #`sendAndReceive()`超时时间exchange: #默认的交换机routingKey: #默认的路由defaultReceiveQueue: #默认的接收队列## retry重试相关retry: enabled: true #是否重试功能 默认falsemaxAttempts: 3 #最大重试次数 默认为3initialInterval: 1000ms #重试间隔时间 可以使用ms、s、m、h、dmultiplier: #重试乘数,默认为1,即每次重试间隔时间保持不变maxInterval: 10000ms #最大重试间隔时间 与乘数结合使用配置文件
package com.tecloman.cloud.singleton.rabbitmq.config;import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.QueueBuilder;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** @author Administrator*/
@Configuration
@Slf4j
public class RabbitConfig {@Beanpublic RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {final RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);// 序列化配置rabbitTemplate.setMessageConverter(jsonMessageConverter());rabbitTemplate.setMandatory(true);// 推送到server回调rabbitTemplate.setConfirmCallback((correlationData, ack, cause) ->log.info("ConfirmCallback correlationData:{},ack:{},cause:{}",correlationData,ack,cause));// 消息返回给生产者, 路由不到队列时返回给发送者 先returnCallback,再 confirmCallbackrabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {log.info("ReturnCallback message:{},replyCode:{},replyText:{},exchange:{},routingKey:{}",message,replyCode,replyText,exchange,routingKey);});return rabbitTemplate;}@Beanpublic Jackson2JsonMessageConverter jsonMessageConverter() {return new Jackson2JsonMessageConverter();}
}
RabbitMQ的六种工作模式
消费者@RabbitListener注解下的配置内容
@Target({ElementType.TYPE, ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@MessageMapping
@Documented
@Repeatable(RabbitListeners.class)
public @interface RabbitListener {String id() default ""; // 用于为监听器指定一个唯一标识符,不指定则自动生成。String containerFactory() default "";// 指定要使用的消息监听容器工厂 bean 的名称。String[] queues() default {}; // 指定要监听的队列名称。可以是'队列名称','属性占位符键'或'表达式',队列必须存在,queues 属性与 bindings() 和 queuesToDeclare() 属性互斥,不能同时使用Queue[] queuesToDeclare() default {}; // 用于声明要监听的队列,可以通过 @Queue 注解定义队列的属性。与 bindings() 和 queues() 属性互斥,不能同时使用,允许动态声明队列。boolean exclusive() default false; // 指定是否为独占模式,即只有一个消费者可以消费该队列,为true时要求并发数=1。String priority() default ""; // 指定消息的优先级,越大优先级越高。默认为容器优先级,可以为负数。String admin() default ""; // 属性用于指定一个 RabbitAdmin bean 的引用。QueueBinding[] bindings() default {}; // 用于绑定队列和交换机,以便监听指定的交换机中的消息。与 queues() 和 queuesToDeclare() 属性互斥,不能同时使用。String group() default ""; // 指定消费者所属的分组。可以用于实现分组消费,确保同一组内的消费者共享消息。String returnExceptions() default ""; // 定义一个异常处理策略,用于处理消息发送失败时的异常情况。String errorHandler() default ""; // 指定消息监听容器的错误处理器,用于处理在消息处理过程中发生的错误。String concurrency() default ""; // 指定消费者的并发数量,表示同时处理消息的线程数或者并发消费者的数量。String autoStartup() default ""; // 指定容器是否自动启动,如果设置为 true,则容器会在启动时自动开始侦听消息。String executor() default ""; // 定义用于处理消息的执行器,可以指定一个线程池来处理消息的消费逻辑。String ackMode() default ""; // 指定消息确认模式,用于控制消息的确认方式,包括自动、手动、批量确认等。String replyPostProcessor() default ""; // 定义一个后处理器,用于在发送响应时对响应消息进行处理。String messageConverter() default ""; // 指定消息转换器,用于将消息从字节流转换为目标对象,或者将目标对象转换为字节流。String replyContentType() default ""; // 指定回复消息的内容类型。String converterWinsContentType() default "true"; // 指定转换器是否覆盖内容类型。
}1.simple简单模式(点对点模式)
-
消息的生产者将消息放入队列
-
消息的消费者(consumer) 监听 消息队列,如果队列中有消息,就消费掉,消息被拿走后,自动从队列中删除(隐患 消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失)应用场景:聊天(中间有一个过度的服务器;p端,c端)
/*** 配置文件添加,简单模式队列* @return*/@Beanpublic Queue simpleQueue(){//持久化 非独占 非自动删除return QueueBuilder.durable("simpleQueue").build();}/*** 简单模式生产者*/@GetMapping("/simple")public R simple(@RequestParam String msg){Map<String, Object> map = createMsg(msg);// 预先要创建好队列rabbitTemplate.convertAndSend("simpleQueue",map);return R.ok();}/*** 简单模式的消费者** @param message 消息属性* @param channel 通道* @param msg 消息内容* @throws IOException*///使用queuesToDeclare属性,如果不存在则会创建队列@RabbitListener(queuesToDeclare = @Queue(value = "simpleQueue"))public void simple(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();// 这个tag每次服务重启会清0long tag = properties.getDeliveryTag();log.info("简单模式的消费者收到:{}", msg);// 简单模式下,消息其实无需确认// 由于在yml设置手动回执,此处需要手动回执,false不批量签收,回执后才能处理下一批消息channel.basicAck(tag, false);} catch (IOException e) {log.error(this.getClass().getName());}}
2.work工作模式(一对多)
-
消息生产者将消息放入队列消费者可以有多个,消费者1,消费者2,同时监听同一个队列,C1 C2共同争抢当前的消息队列内容,谁先拿到谁负责消费消息(隐患,高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize,与同步锁的性能不一样) 保证一条消息只能被一个消费者使用)
-
应用场景:红包;大项目中的资源调度(任务分配系统不需知道哪一个任务执行系统在空闲,直接将任务扔到消息队列中,空闲的系统自动争抢)

/*** 配置文件添加,Work模式队列work队列 默认是轮询发到消息者,priority="10" 设置消费者优先级,优先级相同轮询* @return*/@Beanpublic Queue workQueue(){//持久化 非独占 非自动删除return QueueBuilder.durable("workQueue").build();}/*** 生产者,一次性生产50条消费,消费者轮询消费,消费者可设置优先级priority="10",越大越优先*/@GetMapping("/work")public R work(@RequestParam String msg) {for (int i = 0; i < 50; i++) {rabbitTemplate.convertAndSend("workQueue", createMsg(i), message -> {MessageProperties messageProperties = message.getMessageProperties();//默认消息持久化,设置消息不持久化messageProperties.setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT);return message;});}return R.ok();}/*** 工作模式的消费者1,group分组属性不会生效** @param message 消息属性* @param channel 通道* @param msg 消息内容* @throws IOException*///使用queuesToDeclare属性,如果不存在则会创建队列@RabbitListener(queuesToDeclare = @Queue(value = "workQueue"))public void work1(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();long tag = properties.getDeliveryTag();log.error("工作模式的消费者1收到:{}", msg);//手动回执,不批量签收,回执后才能处理下一批消息channel.basicAck(tag, false);} catch (IOException e) {log.error(this.getClass().getName());}}/*** 工作模式的消费者2** @param message 消息属性* @param channel 通道* @param msg 消息内容* @throws IOException*///使用queuesToDeclare属性@RabbitListener(queuesToDeclare = @Queue(value = "workQueue"))public void work2(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();long tag = properties.getDeliveryTag();log.error("工作模式的消费者2收到:{}", msg);//手动回执,不批量签收,回执后才能处理下一批消息channel.basicAck(tag, false);} catch (IOException e) {log.error(this.getClass().getName());}}
3.publish/subscribe发布订阅(共享资源)
-
生产者通过fanout扇出交换机群发消息给消费者,同一条消息每一个消费者都可以收到,消息生产者将消息放入交换机,交换机发布订阅把消息发送到所有消息队列中,对应消息队列的消费者拿到消息进行消费
-
相关场景:邮件群发,群聊天,广播(广告)

//------------------方法1:生产者创建交换机,消费者创建队列与监听队列------------------ /*** 配置文件定义交换机** @return*/@Beanpublic Exchange fanout() {//持久化 非自动删除return ExchangeBuilder.fanoutExchange("fanout").build();}//创建初始化RabbitAdmin对象@Beanpublic RabbitAdmin fanoutRabbitAdmin(ConnectionFactory connectionFactory) {RabbitAdmin rabbitAdmin = new RabbitAdmin(connectionFactory);// 只有设置为 true,spring 才会加载 RabbitAdmin 这个类rabbitAdmin.setAutoStartup(true);// 声明交换机 fanoutrabbitAdmin.declareExchange(fanout());return rabbitAdmin;}/** 生产者 发送50条消息,消费者各自消费50条,*/@GetMapping("/fanout")public R fanout(@RequestParam String msg){for (int i = 0; i < 50; i++) {Map<String, Object> map = createMsg(i);// 第二个参数为路由KeyrabbitTemplate.convertAndSend("fanout",null,map);}return R.ok();}/*** 发布订阅模式方法1的消费者1,group分组属性不会生效** @param message 消息属性* @param channel 通道* @param msg 消息内容*/@RabbitListener(// 这里定义随机队列,默认属性: 随机命名,非持久,排他,自动删除// declare = "false":生产者已定义交换机,此处不再声明交换bindings = @QueueBinding(value = @Queue, exchange = @Exchange(name = "fanout", declare = "false")))public void fanout1(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();long tag = properties.getDeliveryTag();log.error("发布订阅模式方法1的消费者1收到:{}", msg);// 手动回执,不批量签收,回执后才能处理下一批消息channel.basicAck(tag, false);} catch (IOException e) {log.error(this.getClass().getName());}}@RabbitListener(// 这里定义随机队列,默认属性: 随机命名,非持久,排他,自动删除// declare = "false":生产者已定义交换机,此处不再声明交换bindings = @QueueBinding(value = @Queue, exchange = @Exchange(name = "fanout", declare = "false")))public void fanout2(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();long tag = properties.getDeliveryTag();log.error("发布订阅模式方法1的消费者2收到:{}", msg);// 手动回执,不批量签收,回执后才能处理下一批消息channel.basicAck(tag, false);} catch (IOException e) {log.error(this.getClass().getName());}}
//------------------方法2:生产者创建队列与交换机,消费者监听队列------------------/*** 定义队列 持久 非排他 非自动删除* @return*/@Beanpublic Queue fanoutQueue1(){return QueueBuilder.durable("fanout-queue1").build();}@Beanpublic Queue fanoutQueue2(){return QueueBuilder.durable("fanout-queue2").build();}/*** 定义扇出交换机 持久 非自动删除* @return*/@Beanpublic FanoutExchange fanoutExchange(){return ExchangeBuilder.fanoutExchange("fanout2").build();}/*** 将队列1与交换机绑定* @return*/@Beanpublic Binding fanoutBinding1(){return BindingBuilder.bind(fanoutQueue1()).to(fanoutExchange());}@Beanpublic Binding fanoutBinding2(){return BindingBuilder.bind(fanoutQueue2()).to(fanoutExchange());}//创建初始化RabbitAdmin对象@Beanpublic RabbitAdmin fanoutRabbitAdmin(ConnectionFactory connectionFactory) {RabbitAdmin rabbitAdmin = new RabbitAdmin(connectionFactory);// 只有设置为 true,spring 才会加载 RabbitAdmin 这个类rabbitAdmin.setAutoStartup(true);// 声明交换机和队列rabbitAdmin.declareExchange(fanoutExchange());rabbitAdmin.declareQueue(fanoutQueue1());rabbitAdmin.declareQueue(fanoutQueue2());return rabbitAdmin;}// 不同消费者绑定在同一个交换机,队列相同,轮询消费,队列不同,各自消费/*** 发布订阅模式方法2的消费者1 ,队列不同,生产者发送50条消息,各自消费50条** @param message 消息属性* @param channel 通道* @param msg 消息内容*///使用queuesToDeclare属性,如果不存在则会创建队列,注:此处声明的队列要和生产者属性保持一致@RabbitListener(queuesToDeclare = @Queue(value = "fanout-queue1"))public void fanout1(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();long tag = properties.getDeliveryTag();log.error("发布订阅模式方法2的消费者1收到:{}", msg);//手动回执,不批量签收,回执后才能处理下一批消息channel.basicAck(tag, false);} catch (IOException e) {log.error(this.getClass().getName());}}@RabbitListener(queuesToDeclare = @Queue(value = "fanout-queue2"))public void fanout2(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();long tag = properties.getDeliveryTag();log.error("发布订阅模式方法2的消费者2收到:{}", msg);//手动回执,不批量签收,回执后才能处理下一批消息channel.basicAck(tag, false);} catch (IOException e) {log.error(this.getClass().getName());}}
4.routing路由模式
-
消息生产者将消息发送给交换机按照路由判断,路由是字符串(info) 当前产生的消息携带路由字符(对象的方法),交换机根据路由的key,只能匹配上路由key对应的消息队列,对应的消费者才能消费消息;
-
根据业务功能定义路由字符串
-
从系统的代码逻辑中获取对应的功能字符串,将消息任务扔到对应的队列中

/*** 定义直流交换机* @return*/@Beanpublic Exchange routeExchange(){//持久化 非自动删除return ExchangeBuilder.directExchange("route").build();}// 创建初始化RabbitAdmin对象@Beanpublic RabbitAdmin RabbitAdminRoute(ConnectionFactory connectionFactory) {RabbitAdmin rabbitAdmin = new RabbitAdmin(connectionFactory);// 只有设置为 true,spring 才会加载 RabbitAdmin 这个类rabbitAdmin.setAutoStartup(true);// 声明直流交换机rabbitAdmin.declareExchange(routeExchange());return rabbitAdmin;}// 消费者发送消息,key=dev,test,prod@GetMapping("/router")public R router(@RequestParam String msg,@RequestParam String routerKey){Map<String, Object> map = createMsg(msg);rabbitTemplate.convertAndSend("route",routerKey,map);return R.ok();}/*** 路由式消费者1** @param message 消息属性* @param channel 通道* @param msg 消息内容*/@RabbitListener(bindings = @QueueBinding(// declare = "false":生产者已定义交换机,此处不再声明交换机value = @Queue, exchange = @Exchange(name = "route", declare = "false"),key = {"prod"}//路由键))public void route1(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();String routingKey = properties.getReceivedRoutingKey();log.error("路由模式方法1的消费者1收到:{},路由键:{}", msg, routingKey);//手动回执,不批量签收,回执后才能处理下一批消息long tag = properties.getDeliveryTag();channel.basicAck(tag, false);} catch (Exception e) {log.error(this.getClass().getName());}}/*** 路由式消费者2** @param message 消息属性* @param channel 通道* @param msg 消息内容*/@RabbitListener(bindings = @QueueBinding(// declare = "false":生产者已定义交换机,此处不再声明交换机value = @Queue, exchange = @Exchange(name = "route", declare = "false"),key = {"dev","test"}//路由键))public void route2(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();String routingKey = properties.getReceivedRoutingKey();log.error("路由模式方法1的消费者2收到:{},路由键:{}", msg, routingKey);//手动回执,不批量签收,回执后才能处理下一批消息long tag = properties.getDeliveryTag();channel.basicAck(tag, false);} catch (Exception e) {log.error(this.getClass().getName());}}
5.topic 主题模式(路由模式的一种)
-
路由功能添加模糊匹配
-
消息生产者生产消息,把消息交给交换机
-
交换机根据key的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
-
topic必须是 星号或#.dev.星号,不能以 molo/pcs/q0/*/data_up 这样匹配不了

/*** 定义主题交换机* @return*/@Beanpublic Exchange themeExchange(){//持久化 非自动删除return ExchangeBuilder.topicExchange("topic").build();}//创建初始化RabbitAdmin对象@Beanpublic RabbitAdmin rabbitAdminTopic(ConnectionFactory connectionFactory) {RabbitAdmin rabbitAdmin = new RabbitAdmin(connectionFactory);// 只有设置为 true,spring 才会加载 RabbitAdmin 这个类rabbitAdmin.setAutoStartup(true);rabbitAdmin.declareExchange(themeExchange());return rabbitAdmin;}// 生产者,routerKey,****.dev.***,*****.test.****,分别走消费者1,和消费者2// 通配符*,#不能和 / 一起@GetMapping("/topic")public R topic(@RequestParam String msg, @RequestParam String routerKey) {Map<String, Object> map = createMsg(msg);rabbitTemplate.convertAndSend("topic", routeKey, map);return R.ok();}/*** 主题方法1的消费者1** @param message 消息属性* @param channel 通道* @param msg 消息内容*/@RabbitListener(bindings = @QueueBinding(// declare = "false":生产者已定义交换机,此处不再声明交换机value = @Queue, exchange = @Exchange(name = "topic", type = ExchangeTypes.TOPIC),key = {"#.dev.*"}))public void topic1(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();String routingKey = properties.getReceivedRoutingKey();log.error("主题模式方法1的消费者1收到:{},路由键:{}", msg, routingKey);//手动回执,不批量签收,回执后才能处理下一批消息long tag = properties.getDeliveryTag();channel.basicAck(tag, false);} catch (Exception e) {log.error(this.getClass().getName());}}/*** 路由式方法1的消费者2* # 号匹配多个 .分隔* @param message 消息属性* @param channel 通道* @param msg 消息内容*/@RabbitListener(bindings = @QueueBinding(// declare = "false":生产者已定义交换机,此处不再声明交换机value = @Queue, exchange = @Exchange(name = "topic", type = ExchangeTypes.TOPIC),key = {"#.molo.*"}))public void topic2(Message message, Channel channel, JSONObject msg) {try {MessageProperties properties = message.getMessageProperties();String routingKey = properties.getReceivedRoutingKey();log.error("主题模式方法1的消费者2收到:{},路由键:{}", msg, routingKey);//手动回执,不批量签收,回执后才能处理下一批消息long tag = properties.getDeliveryTag();channel.basicAck(tag, false);} catch (Exception e) {log.error(this.getClass().getName());}}
6.RPC (基于消息的远程过程调用)
- RPC即客户端远程调用服务端的方法 ,使用MQ可以实现RPC的异步调用,基于Direct交换机实现,流程如下:
- 客户端即是生产者也是消费者,向RPC请求队列发送RPC调用消息,同时监听RPC响应队列。
- 服务端监听RPC请求队列的消息,收到消息后执行服务端的方法,得到方法返回的结果。
- 服务端将RPC方法 的结果发送到RPC响应队列。
- 客户端(RPC调用方)监听RPC响应队列,接收到RPC调用结果。
延时队列、循环队列、兜底机制、定时任务
1.延时队列
使用TTL+死信队列组合实现延迟队列的效果。
TTL 是 RabbitMQ 中一个消息或者队列的属性,表明一条消息或者该队列中的所有消息的最大存活时间,单位是毫秒。换句话说,如果一条消息设置了 TTL 属性或者进入了设置TTL 属性的队列,那么这 条消息如果在TTL 设置的时间内没有被消费,则会成为"死信"。如果同时配置了队列的TTL 和消息的 TTL,那么较小的那个值将会被使用。TTL并不是延时发送的意思。
死信队列(Dead Letter Queue)是 RabbitMQ 中的一种特殊队列,用于存储无法正常被消费的消息。当消息满足一定条件时,例如消息过期、被拒绝或达到最大重试次数等情况,会被发送到死信队列中,以便后续进行处理。
// 消息设置TTLMap<String, Object> message = createMsg(msg);rabbitTemplate.convertAndSend("exchange","routingKey", message,i->{MessageProperties properties = i.getMessageProperties();properties.setExpiration("10000");return i;});// 队列设置TTLQueueBuilder.durable("delayedQueue").withArgument("x-message-ttl",10000).build();
可以在队列指定TTL,但这样并不灵活,所以在生产者那指定TTL
// 配置类public static final String YS_QUEUE ="ys_queue";public static final String YS_EXCHANGE ="ys_exchange";public static final String YS_ROUTING_KEY ="ys_routing_key";// 死信队列、交换机、路由KEYpublic static final String DLX_QUEUE="dlx_queue";public static final String DLX_EXCHANGE="dlx_exchange";public static final String DLX_ROUTING_KEY="dlx_routing_key";// 普通的交换机及队列@Beanpublic Queue normalQueue(){Map map = new HashMap();// message在该队列queue的存活时间最大为10秒//map.put("x-message-ttl", 10000);// x-dead-letter-exchange参数是设置该队列的死信交换器(DLX)map.put("x-dead-letter-exchange", DLX_EXCHANGE);// x-dead-letter-routing-key参数是给这个DLX指定路由键map.put("x-dead-letter-routing-key", DLX_ROUTING_KEY);return new Queue(YS_QUEUE,true,false,false,map);}@Beanpublic DirectExchange normalDirectExchange(){return new DirectExchange(YS_EXCHANGE);}@Beanpublic Binding normalBinding(){return BindingBuilder.bind(normalQueue()).to(normalDirectExchange()).with(YS_ROUTING_KEY);}// 死信交换机及队列@Beanpublic Queue dlxQueue(){return QueueBuilder.durable(DLX_QUEUE).build();}@Beanpublic DirectExchange dlxDirectExchange(){return new DirectExchange(DLX_EXCHANGE);}@Beanpublic Binding dlxBinding(){return BindingBuilder.bind(dlxQueue()).to(dlxDirectExchange()).with(DLX_ROUTING_KEY);}// 生产者 设置setExpiration 消息存活时间,这样更灵活// 超过Time这个时间 就会走到死信队列里面,达到延时效果@GetMapping("/ysmsg")public R ysmsg(String time) {JSONObject msg = new JSONObject();msg.put("msg", "死信交换机 延时发送的消息");msg.put("time", System.currentTimeMillis());rabbitTemplate.convertAndSend(RabbitmqDLXConfig.YS_EXCHANGE,RabbitmqDLXConfig.YS_ROUTING_KEY,msg, i -> {MessageProperties properties = i.getMessageProperties();properties.setExpiration(time);return i;});return R.ok();}
使用RabbitMQ官方延迟插件,实现延时队列效果。
docker部署的时候已经安装了插件,直接使用
不需要死信交换机和死信队列,支持消息延迟投递,消息投递之后没有到达投递时间,是不会投递给队列
而是存储在一个分布式表,当投递时间到达,才会投递到目标队列
public static final String YS_QUEUE_NAME = "YS_queue";public static final String YS_EXCHANGE_NAME = "YS_exchange";public static final String YS_ROUTING_KEY = "YS_routingKey";@Beanpublic Queue delayedQueue(){return new Queue(YS_QUEUE_NAME);}/*** 自定义交换机 定义一个延迟交换机* @return*/@Beanpublic CustomExchange delayedExchange(){Map<String, Object> args = new HashMap<>(1);// 自定义交换机的类型args.put("x-delayed-type", "direct");return new CustomExchange(YS_EXCHANGE_NAME, "x-delayed-message", true, false, args);}@Beanpublic Binding bindingDelayedQueue(){return BindingBuilder.bind(delayedQueue()).to(delayedExchange()).with(YS_ROUTING_KEY).noargs();}// 生产者 由setExpiration改为setDelay,延时,毫秒,消费者监听队列即可@GetMapping("/ysmsg")public R ysmsg(String time) {JSONObject msg = new JSONObject();msg.put("msg", "延时发送的消息");msg.put("time", System.currentTimeMillis());rabbitTemplate.convertAndSend(RabbitmqDLXConfig.YS_EXCHANGE_NAME, RabbitmqDLXConfig.YS_ROUTING_KEY, msg, i ->{i.getMessageProperties().setDelay(Integer.parseInt(time));return i;});return R.ok();}
2.循环队列
Rabbitmq里并没有循环队列的概念,多数都是通过消费者来判断是否重新入队或是转到其它队列
也可以设置消息的重试次数。
手动确认机制下,如果消费者一直不确认消息,RabbitMQ 将会将该消息重新投递给其他消费者或当前消费者。
3.兜底机制
消息重试: 将处理失败的消息重新投递给消费者或其他消费者进行重试。您可以使用 RabbitMQ 的重试机制(例如使用 channel.basicReject()或channel.basicNack())来将消息重新放回队列中,以供后续的处理尝试。
死信队列: 在消息处理失败时,将消息发送到一个专门的死信队列。死信队列是一个存储无法被消费者正常处理的消息的队列。您可以定义一个死信交换机和死信队列,并将处理失败的消息路由到该死信队列。然后,您可以根据需要对死信队列中的消息进行分析、转发或进一步处理。
4.定时任务
定时任务使用延时队列就可以办到
相关文章:
SpingBoot集成Rabbitmq及Docker部署
文章目录 介绍RabbitMQ的特点Rabbitmq术语消息发布接收流程 Docker部署管理界面说明Overview: 这个页面显示了RabbitMQ服务器的一般信息,例如集群节点的名字、状态、运行时间等。Connections: 在这里,可以查看、管理和关闭当前所有的TCP连接。Channels: …...
子组件自定义事件$emit实现新页面弹窗关闭之后父界面刷新
文章目录 需求弹窗关闭之后父界面刷新展示最新数据 实现方案AVUE 大文本默认展开slotVUE 自定义事件实现 父界面刷新那么如何用呢? 思路核心代码1. 事件定义2. 帕斯卡命名组件且在父组件中引入以及注册3. 子组件被引用与父事件监听4.父组件回调函数 5.按钮弹窗事件 需求 弹窗…...
)
【框架】跨端开发框架介绍(Windows/MacOS/Linux/Andriod/iOS/H5/小程序)
1. 跨端框架介绍 跨端框架 基本信息 说明 移动端 (性能:uniapp < ReactNative < Flutter) uniapp 注:weex已经嵌入uniapp 适用范围:Andriod、iOS、H5、国产小程序、快应用 引擎: 所属公司&#x…...

亚马逊云科技 Lambda 运行selenium
有些定时任务需要使用自动化测试的工具,如果使用亚马逊云科技 Lambda来实现这个功能的话,那么就需要图形框架,而我们知道lambda其实是一个虚拟机,而且按照系统级别依赖比较困难。所以这里选择使用容器的形式进行发布。 在dockerf…...
算法——前缀和之除自身以外数组的乘积、和为K的子数组、和可被K整除的子数组、连续数组、矩阵区域和
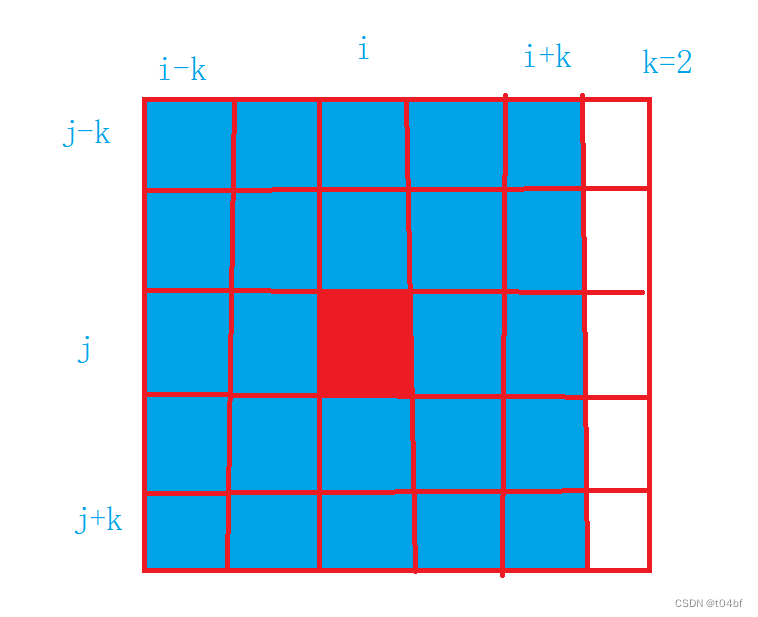
这几道题对于我们前面讲过的一维、二维前缀和进行了运用,包含了面对特殊情况的反操作 目录 4.除自身以外数组的乘积 4.1解析 4.2题解 5.和为K的子数组 5.1解析 5.2题解 6.和可被K整除的子数组 6.1解析 6.2题解 7.连续数组 7.1题解 7.2题解 8.矩阵区域和 8.1解析 …...
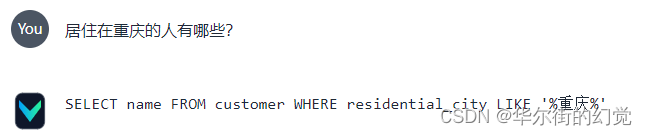
Text-to-SQL 工具Vanna + MySQL本地部署 | 数据库对话机器人
今天我们来重点研究与实测一个开源的Text2SQL优化框架 – Vanna 1. Vanna 简介【Text-to-SQL 工具】 Vanna 是一个基于 MIT 许可的开源 Python RAG(检索增强生成)框架,用于 SQL 生成和相关功能。它允许用户在数据上训练一个 RAG “模型”&a…...

linux最佳入门(笔记)
1、内核的主要功能 2、常用命令 3、通配符:这个在一些启动文件中很常见 4、输入/输出重定向 意思就是将结果输出到别的地方,例如:ls标准会输出文件,默认是输出到屏幕,但是用>dir后,是将结果输出到dir文…...

加速 PyTorch 模型预测常见方法梳理
目录 1. 使用 GPU 加速 2. 批量推理 3. 使用半精度浮点数 (FP16) 4. 禁用梯度计算 5. 模型简化与量化 6. 使用 TorchScript 7. 模型并行和数据并行 结论 在使用 PyTorch 进行模型预测时,可以通过多种方法来加快推理速度。以下是一些加速模型预测的常用方法&…...

【STM32定时器 TIM小总结】
STM32 TIM详解 TIM介绍定时器类型基本定时器通用定时器高级定时器常用名词时序图预分频时序计数器时序图 定时器中断配置图定时器定时 代码调试 TIM介绍 定时器(Timer)是微控制器中的一个重要模块,用于生成定时和延时信号,以及处…...

RISC-V 编译环境搭建:riscv-gnu-toolchain 和 riscv-tools
RISC-V 编译环境搭建:riscv-gnu-toolchain 和 riscv-tools 编译环境搭建以及说明 操作系统:什么系统都可以 虚拟机:VMmare Workstation Pro 17.50.x (版本不限) 编译环境:Ubuntu 18.04.5 CPU:i7-8750h(虚拟机分配4核…...
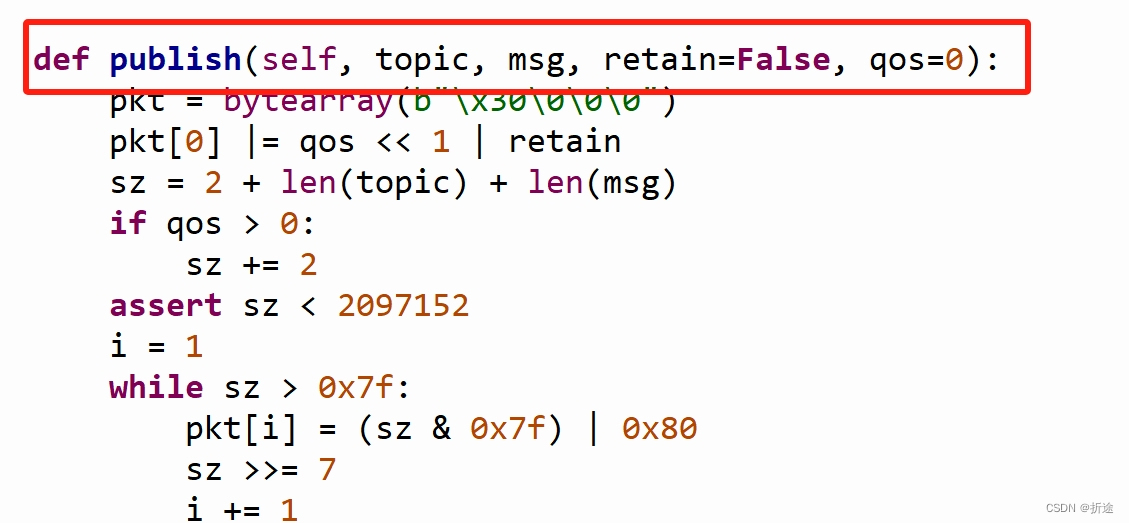
一文速通ESP32(基于MicroPython)——含示例代码
ESP32 简介 ESP32-S3 是一款集成 2.4 GHz Wi-Fi 和 Bluetooth 5 (LE) 的 MCU 芯片,支持远距离模式 (Long Range)。ESP32-S3 搭载 Xtensa 32 位 LX7 双核处理器,主频高达 240 MHz,内置 512 KB SRAM (TCM),具有 45 个可编程 GPIO 管…...

记录一次业务遇到的sql问题
刚开始工作 业务能力比较薄弱 记录一下这几天遇见的一个业务问题 场景 先简单说一下场景,有一批客户(一张表),可以根据这个客户匹配出很多明细数据(另一张表),现在需要删除明细,一个…...

代码分支管理
代码分支管理规范 一、分支管理要求 分支管理 • 将代码提交到适当的分支,遵循分支管理策略。 • 随时可以切换到线上稳定版本代码,确保可以快速回滚到稳定版本。 • 同时进行多个版本的开发工作,确保分支清晰,避免混淆。提交记录的可读性 • 提交描述准确,具有可检索性,…...

uniapp sqlite时在无法读取到已准备好数据的db文件中的数据
问题 {“code”:-1404,“message”:“android.database.sqlite.SQLiteException: no such table: user (Sqlite code 1): , while compiling: select * from user, (OS error - 2:No such file or directory),http://ask.dcloud.net.cn/article/282”} at pages/index/index.vu…...
源码编译部署LAMP
编译部署LAMP 配置apache [rootzyq ~]#: wget https://downloads.apache.org/apr/apr-1.7.4.tar.gz --2023-12-11 14:35:57-- https://downloads.apache.org/apr/apr-1.7.4.tar.gz Resolving downloads.apache.org (downloads.apache.org)... 88.99.95.219, 135.181.214.104…...

Echo框架:高性能的Golang Web框架
Echo框架:高性能的Golang Web框架 在Golang的Web开发领域,选择一个适合的框架是构建高性能和可扩展应用程序的关键。Echo是一个备受推崇的Golang Web框架,以其简洁高效和强大功能而广受欢迎。本文将介绍Echo框架的基本特点、使用方式及其优势…...
)
数据结构--七大排序算法(更新ing)
下面算法编写的均是按照由小到大排序版本 选择排序 思想: 每次遍历待排序元素的最大下标,与待排序元素中最后一个元素交换位置(此时需要设置一个临时变量来存放下标) 时间复杂度--O(n^2) 空间复杂度--O(1) 稳定性--不稳定 代码实…...
202203青少年软件编程(图形化) 等级考试试卷(二级)
第1题:【 单选题】 红框中加入哪个选项积木, 不能阻止气球下落? ( ) A: B: C: D: 【正确答案】: D 【试题解析】 : 第2题:【 单选题】 下图分别是两个角色的初始位置和“黑色圆形”的程序, 点击绿旗后, 角色显示为下列哪个选项?( ) A: B: C: D: 【正确答…...

【智能硬件、大模型、LLM 智能音箱】Emo:基于树莓派 4B DIY 能笑会动的桌面机器人
简介 Emo 是一款个人伴侣机器人,集时尚与创新于一身。他的诞生离不开最新的树莓派 4 技术和先进的设计。他不仅仅是一款机器人,更是一个活生生的存在。与其他机器人不同,他拥有独特的个性和情感,能够俘获你的心灵。 硬件部分 – 树莓派 4B – 微雪 2 英寸 IPS LCD 显示屏…...
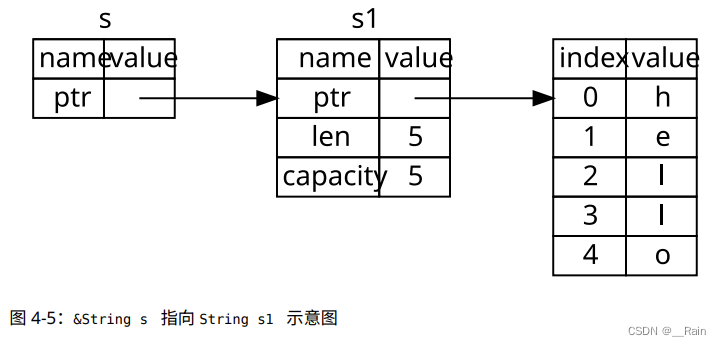
rust学习笔记(1-7)
原文 8万字带你入门Rust 1.包管理工具Cargo 新建项目 1)打开 cmd 输入命令查看 cargo 版本 cargo --version2) 使用 cargo new 项目名 在文件夹,按 shift 鼠标右键 ,打开命令行,运行如下命令,即可创建…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

树莓派Zero离线语音交互实战:TTS与STT引擎部署与优化
1. 项目概述:为什么选择树莓派 Zero 来实现语音功能?如果你玩过 Arduino、ESP32 这类微控制器,也接触过树莓派 4B 这样的单板电脑,那你大概能理解那种“选择困难症”:微控制器实时性强、功耗低,但算力有限&…...
)
DeepSeek注释质量跃迁路径(附12个真实项目对比数据+可复用Prompt模板)
更多请点击: https://codechina.net 第一章:DeepSeek注释质量跃迁路径(附12个真实项目对比数据可复用Prompt模板) 高质量代码注释不再是“锦上添花”,而是模型理解意图、团队高效协同与长期可维护性的核心基础设施。…...

如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练
如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练 【免费下载链接】SoundMind We introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building o…...

GetStoreApp核心功能解析:离线部署Microsoft Store应用的5大优势
GetStoreApp核心功能解析:离线部署Microsoft Store应用的5大优势 【免费下载链接】GetStoreApp 离线下载 Microsoft Store 商店应用 项目地址: https://gitcode.com/gh_mirrors/ge/GetStoreApp GetStoreApp是一款专为Windows用户设计的离线下载工具ÿ…...