深度学习 精选笔记(13.2)深度卷积神经网络-AlexNet模型
学习参考:
- 动手学深度学习2.0
- Deep-Learning-with-TensorFlow-book
- pytorchlightning
①如有冒犯、请联系侵删。
②已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。
③非常推荐上面(学习参考)的前两个教程,在网上是开源免费的,写的很棒,不管是开始学还是复习巩固都很不错的。
深度学习回顾,专栏内容来源多个书籍笔记、在线笔记、以及自己的感想、想法,佛系更新。争取内容全面而不失重点。完结时间到了也会一直更新下去,已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。所有文章涉及的教程都会写在开头、一起学习一起进步。
学习推荐:
- https://blog.csdn.net/hjkdh/article/details/124565443
- 卷积神经网络的深入理解-基础篇(卷积,激活,池化,误差反传)
1.特征提取的重要性
在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气。但卷积神经网络并没有主导这些领域。这是因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究。
在计算机视觉中,直接将神经网络与其他机器学习方法进行比较也许不公平。这是因为,卷积神经网络的输入是由原始像素值或是经过简单预处理(例如居中、缩放)的像素值组成的。但在使用传统机器学习方法时,从业者永远不会将原始像素作为输入。在传统机器学习方法中,计算机视觉流水线是由经过人的手工精心设计的特征流水线组成的。对于这些传统方法,大部分的进展都来自于对特征有了更聪明的想法,并且学习到的算法往往归于事后的解释。
因此,与训练端到端(从像素到分类结果)系统不同,经典机器学习的流水线看起来更像下面这样:
- 获取一个有趣的数据集。在早期,收集这些数据集需要昂贵的传感器(在当时最先进的图像也就100万像素)。
- 根据光学、几何学、其他知识以及偶然的发现,手工对特征数据集进行预处理。
- 通过标准的特征提取算法,如SIFT(尺度不变特征变换)和SURF(加速鲁棒特征)或其他手动调整的流水线来输入数据。
- 将提取的特征送入最喜欢的分类器中(例如线性模型或其它核方法),以训练分类器。
然而,推动领域进步的是数据特征,而不是学习算法。计算机视觉研究人员相信,从对最终模型精度的影响来说,更大或更干净的数据集、或是稍微改进的特征提取,比任何学习算法带来的进步要大得多。
2.学习表征
(1)另一种预测这个领域发展的方法————观察图像特征的提取方法。在2012年前,图像特征都是机械地计算出来的。事实上,设计一套新的特征函数、改进结果,并撰写论文是盛极一时的潮流。SIFT 、SURF 、HOG(定向梯度直方图)、bags of visual words和类似的特征提取方法占据了主导地位。
(2)另一组研究人员,包括Yann LeCun、Geoff Hinton、Yoshua Bengio、Andrew Ng、Shun ichi Amari和Juergen Schmidhuber,想法则与众不同:他们认为特征本身应该被学习。此外,他们还认为,在合理地复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。在机器视觉中,最底层可能检测边缘、颜色和纹理。事实上,Alex Krizhevsky、Ilya Sutskever和Geoff Hinton提出了一种新的卷积神经网络变体AlexNet。在2012年ImageNet挑战赛中取得了轰动一时的成绩。
有趣的是,在网络的最底层,AlexNet模型学习到了一些类似于传统滤波器的特征抽取器。
AlexNet的更高层建立在这些底层表示的基础上,以表示更大的特征,如眼睛、鼻子、草叶等等。而更高的层可以检测整个物体,如人、飞机、狗或飞盘。最终的隐藏神经元可以学习图像的综合表示,从而使属于不同类别的数据易于区分。尽管一直有一群执着的研究者不断钻研,试图学习视觉数据的逐级表征,然而很长一段时间里这些尝试都未有突破。深度卷积神经网络的突破出现在2012年。突破可归因于两个关键因素:数据和硬件(GPU)。
2.1 缺少的成分:数据
包含许多特征的深度模型需要大量的有标签数据,才能显著优于基于凸优化的传统方法(如线性方法和核方法)。 然而,限于早期计算机有限的存储和90年代有限的研究预算,大部分研究只基于小的公开数据集。
例如,不少研究论文基于加州大学欧文分校(UCI)提供的若干个公开数据集,其中许多数据集只有几百至几千张在非自然环境下以低分辨率拍摄的图像。这一状况在2010年前后兴起的大数据浪潮中得到改善。
2009年,ImageNet数据集发布,并发起ImageNet挑战赛:要求研究人员从100万个样本中训练模型,以区分1000个不同类别的对象。ImageNet数据集由斯坦福教授李飞飞小组的研究人员开发,利用谷歌图像搜索(Google Image Search)对每一类图像进行预筛选,并利用亚马逊众包(Amazon Mechanical Turk)来标注每张图片的相关类别。这种规模是前所未有的。这项被称为ImageNet的挑战赛推动了计算机视觉和机器学习研究的发展,挑战研究人员确定哪些模型能够在更大的数据规模下表现最好。
2.2 缺少的成分:硬件
深度学习对计算资源要求很高,训练可能需要数百个迭代轮数,每次迭代都需要通过代价高昂的许多线性代数层传递数据。这也是为什么在20世纪90年代至21世纪初,优化凸目标的简单算法是研究人员的首选。然而,用GPU训练神经网络改变了这一格局。图形处理器(Graphics Processing Unit,GPU)早年用来加速图形处理,使电脑游戏玩家受益。GPU可优化高吞吐量的 4×4 矩阵和向量乘法,从而服务于基本的图形任务。幸运的是,这些数学运算与卷积层的计算惊人地相似。由此,英伟达(NVIDIA)和ATI已经开始为通用计算操作优化gpu,甚至把它们作为通用GPU(general-purpose GPUs,GPGPU)来销售。
3.AlexNet模型
论文:《ImageNet Classification with Deep ConvolutionalNeural Networks》
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
完整的模型结构:
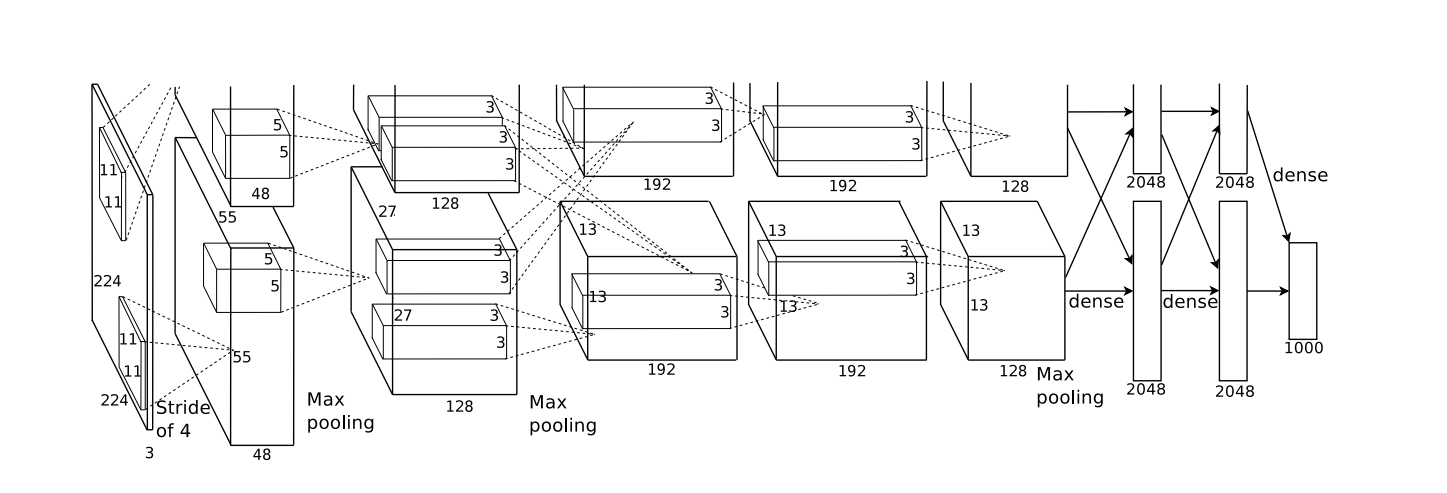
AlexNet和LeNet的架构非常相似,这里提供的是一个稍微精简版本的AlexNet,去除了当年需要两个小型GPU同时运算的设计特点。
AlexNet和LeNet对比:

AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
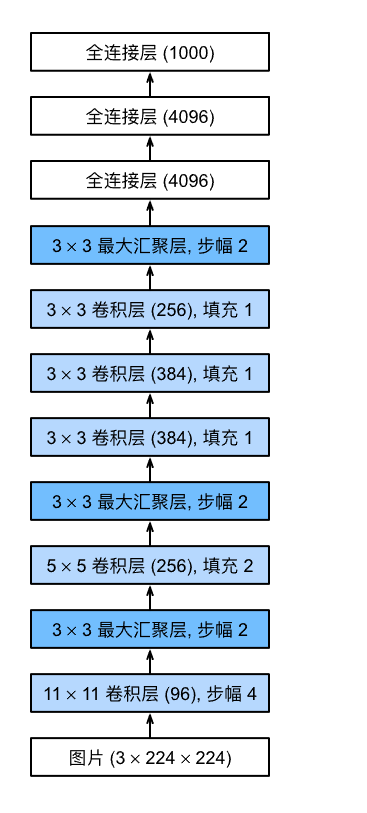
- AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet使用ReLU而不是sigmoid作为其激活函数。
3.1模型设计
在AlexNet的第一层,卷积窗口的形状是 11×11 。 由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。 第二层中的卷积窗口形状被缩减为 5×5
,然后是 3×3 。 此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为 3×3 、步幅为2的最大汇聚层。 而且,AlexNet的卷积通道数目是LeNet的10倍。
在最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。 由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。 幸运的是,现在GPU显存相对充裕,所以现在很少需要跨GPU分解模型。
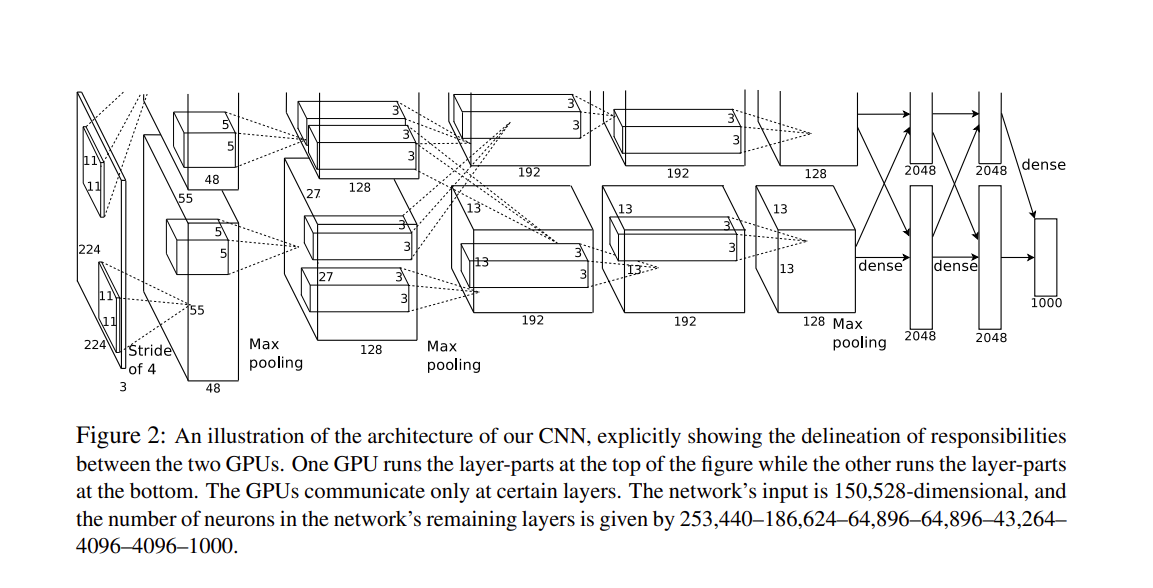
现在只需要简化即可,即取一个GPU中的结构即可。
3.2激活函数
AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。 一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。 另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。 当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。 相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
3.3容量空值和预处理
AlexNet通过暂退法(DropOut)控制全连接层的模型复杂度,而LeNet只使用了权重衰减。 为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。
Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
3.4 模型结构与定义
模型结构:
import tensorflow as tf
from d2l import tensorflow as d2ldef net():return tf.keras.models.Sequential([# 这里使用一个11*11的更大窗口来捕捉对象。# 同时,步幅为4,以减少输出的高度和宽度。# 另外,输出通道的数目远大于LeNettf.keras.layers.Conv2D(filters=96, kernel_size=11, strides=4,activation='relu'),tf.keras.layers.MaxPool2D(pool_size=3, strides=2),# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数tf.keras.layers.Conv2D(filters=256, kernel_size=5, padding='same',activation='relu'),tf.keras.layers.MaxPool2D(pool_size=3, strides=2),# 使用三个连续的卷积层和较小的卷积窗口。# 除了最后的卷积层,输出通道的数量进一步增加。# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度tf.keras.layers.Conv2D(filters=384, kernel_size=3, padding='same',activation='relu'),tf.keras.layers.Conv2D(filters=384, kernel_size=3, padding='same',activation='relu'),tf.keras.layers.Conv2D(filters=256, kernel_size=3, padding='same',activation='relu'),tf.keras.layers.MaxPool2D(pool_size=3, strides=2),tf.keras.layers.Flatten(),# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合tf.keras.layers.Dense(4096, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(4096, activation='relu'),tf.keras.layers.Dropout(0.5),# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000tf.keras.layers.Dense(10)])
构造一个高度和宽度都为224的(单通道数据,来观察每一层输出的形状)。 它与AlexNet架构相匹配。
X = tf.random.uniform((1, 224, 224, 1))
for layer in net().layers:X = layer(X)print(layer.__class__.__name__, 'output shape:\t', X.shape)
Conv2D output shape: (1, 54, 54, 96)
MaxPooling2D output shape: (1, 26, 26, 96)
Conv2D output shape: (1, 26, 26, 256)
MaxPooling2D output shape: (1, 12, 12, 256)
Conv2D output shape: (1, 12, 12, 384)
Conv2D output shape: (1, 12, 12, 384)
Conv2D output shape: (1, 12, 12, 256)
MaxPooling2D output shape: (1, 5, 5, 256)
Flatten output shape: (1, 6400)
Dense output shape: (1, 4096)
Dropout output shape: (1, 4096)
Dense output shape: (1, 4096)
Dropout output shape: (1, 4096)
Dense output shape: (1, 10)
3.5 Fashion-MNIST数据上训练AlexNet
将AlexNet直接应用于Fashion-MNIST的一个问题是,Fashion-MNIST图像的分辨率( 28×28 像素)低于ImageNet图像。
为了解决这个问题,将它们增加到 224×224 (通常来讲这不是一个明智的做法,但在这里这样做是为了有效使用AlexNet架构)。 这里需要使用d2l.load_data_fashion_mnist函数中的resize参数执行此调整。
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
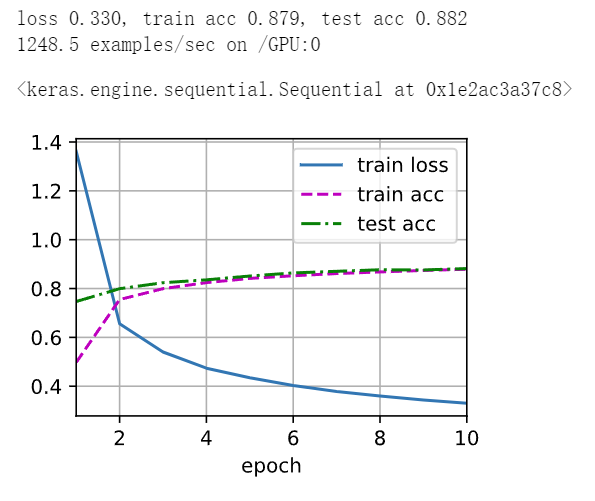
这里使用更小的学习速率训练,这是因为网络更深更广、图像分辨率更高,训练卷积神经网络就更昂贵。
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
3.6一些注意事项
- 在AlexNet中,较大的卷积层和全连接层需要更多的计算资源,因为它们涉及更多的矩阵乘法和加法运算。
- 在AlexNet中,主要占用显存的部分是大型的卷积层和全连接层,这些层通常需要大量的参数和中间计算结果。
- 修改批量大小可以影响训练的速度和模型精度,较大的批量大小通常可以减少训练时间,但也可能导致显存占用较多。需要权衡以获得最佳性能。
- Fashion-MNIST数据集相比于传统的手写数字数据集MNIST更加复杂,但相对于ImageNet这样更大更复杂的数据集,Fashion-MNIST规模较小。AlexNet作为一个大型深度网络对于这样一个小数据集可能会显得过于复杂,容易发生过拟合。
- 增加迭代轮数通常能够使模型在训练集上学习更多的特征,提高泛化能力。与LeNet相比,增加迭代轮数的模型可能会更加精细地学习数据中的模式,产生更好的性能。
- 将Dropout和ReLU应用于LeNet-5可以帮助减轻过拟合问题并加速收敛,提升模型的泛化能力。预处理方法如数据归一化、数据增强等也可以提升模型性能,使其更好地学习数据中的模式。
相关文章:
深度学习 精选笔记(13.2)深度卷积神经网络-AlexNet模型
学习参考: 动手学深度学习2.0Deep-Learning-with-TensorFlow-bookpytorchlightning ①如有冒犯、请联系侵删。 ②已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。 ③非常推荐上面(学习参考&#x…...
【C#图解教程】笔记
文章目录 1. C#和.NET框架.NET框架的组成.NET框架的特点CLRCLICLI的重要组成部分各种缩写 2. C#编程概括标识符命名规则: 多重标记和值格式化数字字符串对齐说明符格式字段标准数字格式说明符标准数字格式说明符 表 3. 类型、存储和变量数据成员和函数成员预定义类型…...
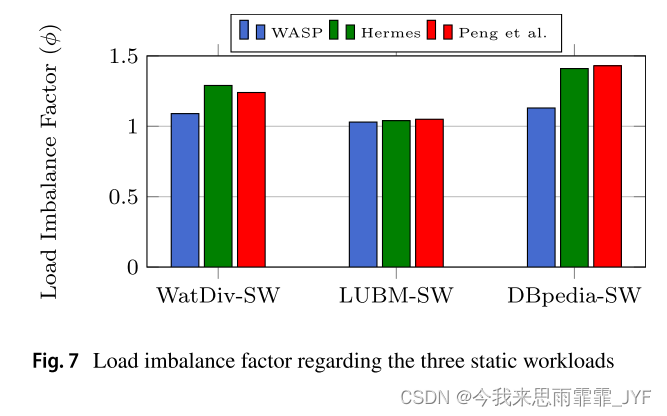
A Workload‑Adaptive Streaming Partitioner for Distributed Graph Stores(2021)
用于分布式图存储的工作负载自适应流分区器 对象:动态流式大图 划分方式:混合割 方法:增量重划分 考虑了图查询算法,基于动态工作负载 考虑了双动态:工作负载动态;图拓扑结构动态 缺点:分配新顶…...

鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Search)
搜索框组件,适用于浏览器的搜索内容输入框等应用场景。 说明: 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 无 接口 Search(options?: { value?: string, placeholder?: Reso…...

GPIO八种工作模式实践总结
到目前为止我还是没搞懂,GPIO口输入输出模式下,PULLUP、PULLDOWN以及NOPULL之间的区别,从实践角度讲,也就是我亲自测试来看,能划分的区别有以下几点: GPIO_INPUT 在输入模式下使用HAL_GPIO_WritePin不能改变…...
ElementUI两个小坑
1.form表单绑定的是一个对象,表单里的一个输入项是对象的一个属性之一,修改输入项,表单没刷新的问题, <el-form :model"formData" :rules"rules" ref"editForm" class"demo-ruleForm"…...

前端基础——HTML傻瓜式入门(2)
该文章Github地址:https://github.com/AntonyCheng/html-notes 在此介绍一下作者开源的SpringBoot项目初始化模板(Github仓库地址:https://github.com/AntonyCheng/spring-boot-init-template & CSDN文章地址:https://blog.c…...
操作系统(AndroidIOS)图像绘图的基本原理
屏幕显示图像的过程 我们知道,屏幕是由一个个物理显示单元组成,每一个单元我们可以称之为一个物理像素点,而每一个像素点可以发出多种颜色。 而图像,就是在不同的物理像素点上显示不同的颜色构成的。 像素点的颜色 像素的颜色是…...
测试用例的设计(2)
目录 1.前言 2.正交排列(正交表) 2.1什么是正交表 2.2正交表的例子 2.3正交表的两个重要性质 3.如何构造一个正交表 3.1下载工具 3.1构造前提 4.场景设计法 5.错误猜测法 1.前言 我们在前面的文章里讲了测试用例的几种设计方法,分别是等价类发,把测试例子划分成不同的类…...

HTML与CSS
前言 Java 程序员一提起前端知识,心情那是五味杂陈,百感交集。 说不学它吧,说不定进公司以后,就会被抓壮丁去时不时写点前端代码说学它吧,HTML、CSS、JavaScript 哪个不得下大功夫才能精通?学一点够不够用…...
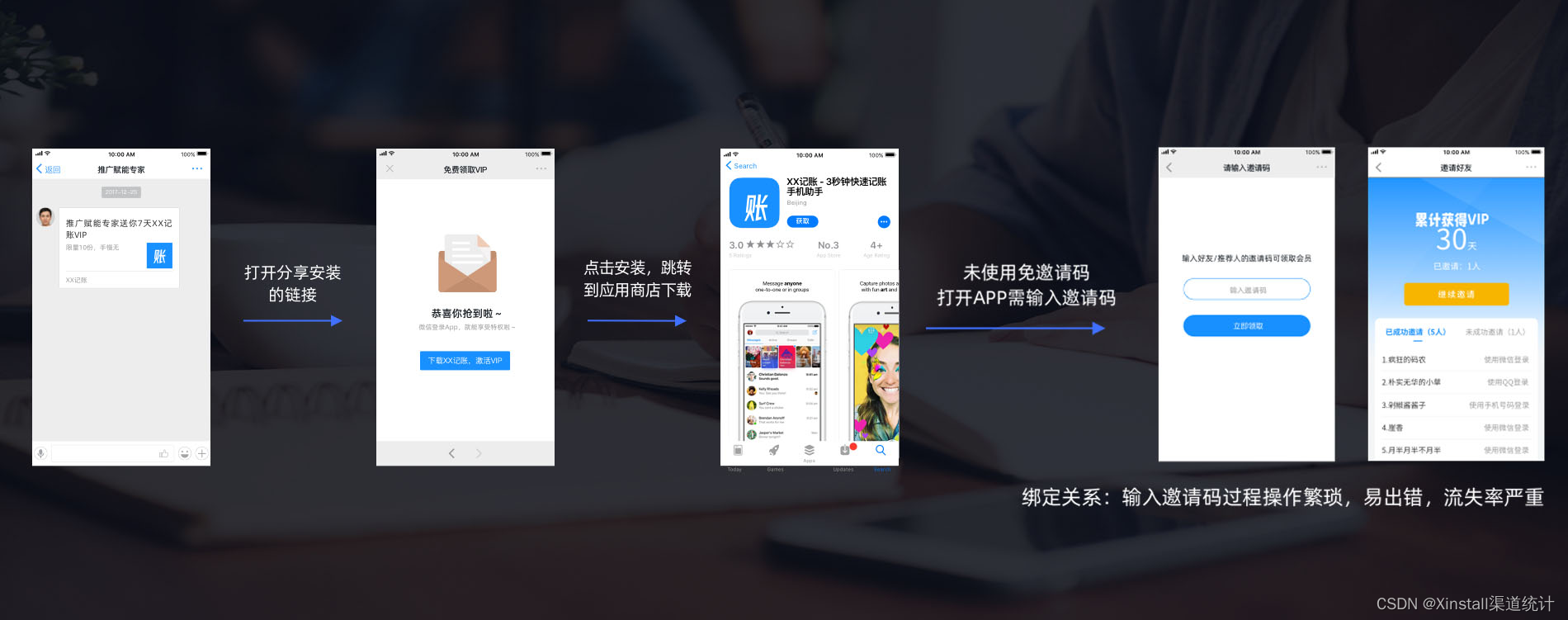
App推广不再难!Xinstall神器助你快速获客,提升用户留存
在如今的移动互联网时代,App推广已经成为了各大应用商家争夺用户的重要手段。然而,面对竞争激烈的市场环境,如何快速提升推广效率,先人一步获得用户呢?这就需要我们借助专业的App全渠道统计服务商——Xinstall的力量。…...

MySQL建表以及excel内容导入
最近自学MySQL的使用,需要将整理好的excel数据导入数据库中,记录一下数据导入流程。 --建立数据库 create table SP_sjk ( --增加列 id NUMBER(20), mc VARCHAR2(300) ) /*表空间储存参数配置。一个数据库从逻辑上来说是由一个或多个表空间所组成&#…...

让el-input与其他组件能够显示在同一行
让el-input与其他组件能够显示在同一行 说明:由于el-input标签使用会默认占满一行,所以在某些需要多个展示一行的时候不适用,因此需要能够跟其他组件显示在同一行。 效果: 1、el-input标签内使用css属性inline 111<el-inp…...
)
学完Efficient c++ (44-45)
条款 44:将与参数无关的代码抽离模板 模板可以节省时间和避免代码重复,编译器会为填入的每个不同模板参数具现化出一份对应的代码,但长此以外,可能会造成代码膨胀(code bloat),生成浮夸的二进制…...
鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:ColumnSplit)
将子组件纵向布局,并在每个子组件之间插入一根横向的分割线。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 可以包含子组件。 ColumnSplit通过分割线限制子组件的高度。初始…...
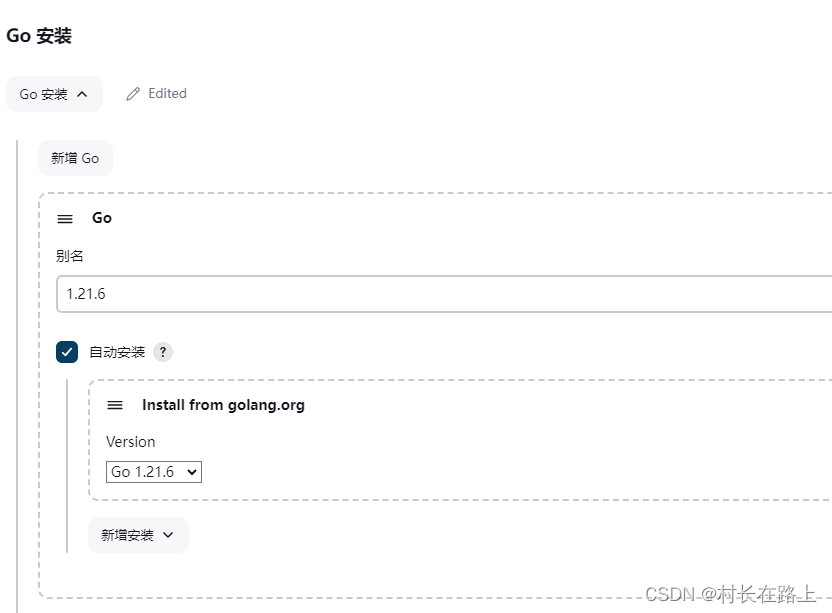
jenkins部署go应用 基于docker-compose
丢弃旧的的构建 github 拉取代码 指定go的编译版本 安装插件 拉取代码是排除指定的配置文件 比如 conf/config.yaml 文件 填写配置文件内容 比如测试环境一些主机信息 等 可以配置里面 构建的时候选择此文件替换开发提交的配置文件。。。。 编写docker-compose 文件 docker…...

【晴问算法】入门篇—贪心算法—整数配对
题目描述 有两个正整数集合S、T,其中S中有n个正整数,T中有m个正整数。定义一次配对操作为:从两个集合中各取出一个数a和b,满足a∈S、b∈T、a≤b,配对的数不能再放回集合。问最多可以进行多少次这样的配对操作。 输入描…...
)
九种背包问题(C++)
0-1背包,背包大小target,占用容积vec[i][0],可以带来的利益是vec[i][1] 一件物品只能取一次,先遍历物品然后遍历背包更新不同容积下最大的利益 int func(vector<vector<int>>&vec,int target){vector<int>dp(target1,…...
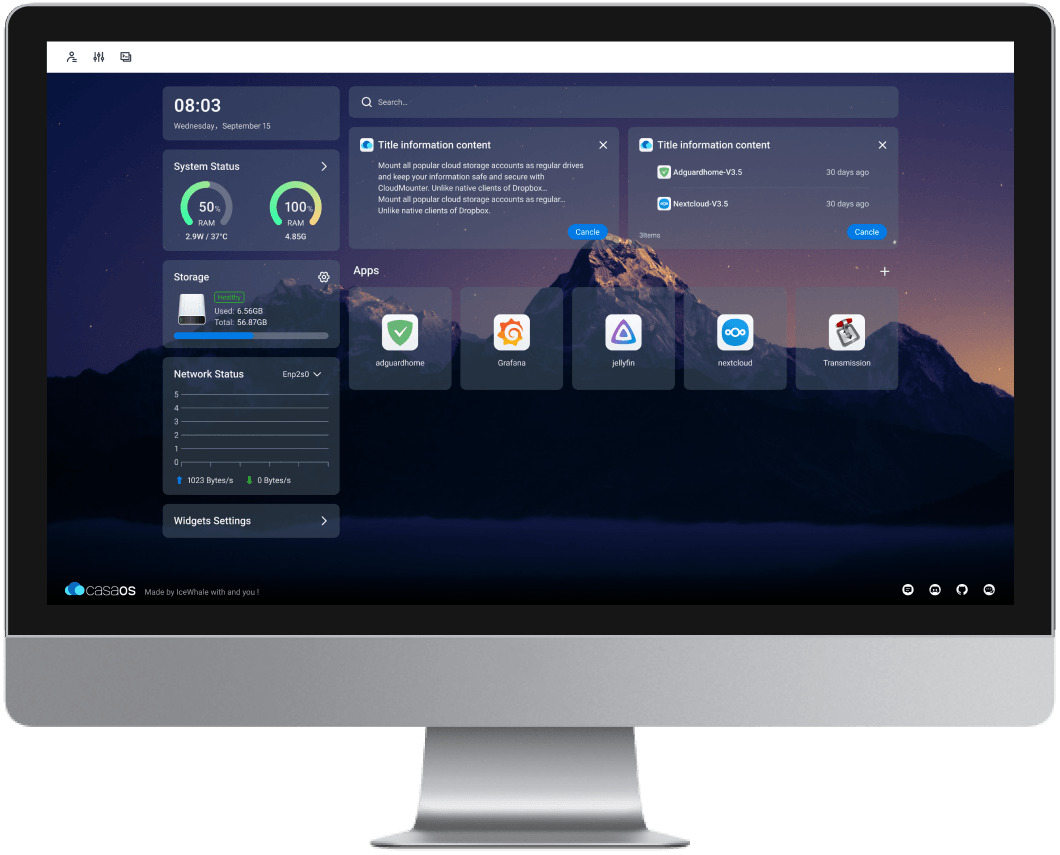
008:安装Docker
安装Docker 如果不太熟悉Linux命令,不想学习Linux命令,可以直接看文末NAS面板章节,通过面板,像使用Window一样操作NAS。 一、安装 Docker 1.安装 Docker wget -qO- https://get.docker.com/ | sh2.启动 Docker 服务 sudo sys…...
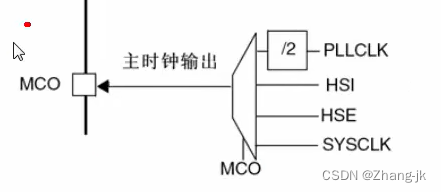
STM32第九节(中级篇):RCC(第一节)——时钟树讲解
目录 前言 STM32第九节(中级篇):RCC——时钟树讲解 时钟树主系统时钟讲解 HSE时钟 HSI时钟 锁相环时钟 系统时钟 SW位控制 HCLK时钟 PCLKI时钟 PCLK2时钟 RTC时钟 MCO时钟输出 6.2.7时钟安全系统(CSS) 小结 前言 从…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式
更多请点击: https://intelliparadigm.com 第一章:揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式 Midjourney V6 在启用云雾(mist/fog/haze)类视觉效果时,…...

终极艾尔登法环存档迁移指南:3分钟学会角色无损转移
终极艾尔登法环存档迁移指南:3分钟学会角色无损转移 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档迁移而烦恼吗?当游戏版本更新后,你辛辛苦苦培…...
)
Unity开发者速查手册:Sora 2模型权重量化适配指南(INT8精度损失<0.3%,已验证于RTX 4090/Apple M3 Ultra)
更多请点击: https://codechina.net 第一章:Sora 2与Unity整合概述 Sora 2 是 OpenAI 推出的下一代视频生成模型,具备高保真时序建模与物理感知能力;而 Unity 作为主流实时3D开发引擎,广泛用于游戏、仿真与数字孪生场…...

保姆级教程:Multisim 14.0 从下载到汉化,手把手教你避开安装过程中的那些坑
Multisim 14.0 终极安装指南:从零开始到完美汉化的全流程解析 对于电子工程和自动化领域的学习者与从业者而言,Multisim 14.0 无疑是一款不可或缺的电路设计与仿真工具。然而,许多用户在初次安装过程中常常遇到各种棘手问题,导致软…...

免费岛屿设计工具终极指南:Happy Island Designer 完整教程 [特殊字符]️
免费岛屿设计工具终极指南:Happy Island Designer 完整教程 🏝️ 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友…...

基于Arduino与ADXL335的自制地震预警系统:从传感器原理到多点联动实现
1. 项目概述与核心思路最近在捣鼓一个挺有意思的玩意儿——一个能自主工作的地震预警系统。这可不是什么高深莫测的科研项目,而是基于一些常见的电子模块,自己动手就能搭建起来的实用装置。它的核心目标很明确:当检测到建筑物出现异常振动时&…...

5.18~5.24补题
牛客周赛Round 144 A.我是谁?牛客周赛Round 144 B.我是清楚姐姐牛客周赛Round 144 C.其实我是小苯 牛客周赛Round 144 D.骗你的,其实我是小红牛客周赛Round 144 E.好吧,我是BingbongSMU Spring 2026 Round 4 ASMU Spring 2026 Round 4 BSMU S…...

从API调用到业务落地:百度OCR车牌识别在智慧园区项目里的实战踩坑记录
从API调用到业务落地:百度OCR车牌识别在智慧园区项目里的实战踩坑记录 在智慧园区这类综合性场景中,车牌识别技术早已超越了简单的"拍照-识别"基础功能,成为连接物理空间与数字系统的关键纽带。我们团队去年承接的某大型科技园区改…...

环境配置助手 For Mac:macOS环境变量可视化管理工具
环境配置助手 For Mac:macOS环境变量可视化管理工具 本文介绍一款适用于 macOS 的环境变量可视化管理工具,聚焦其核心功能与配置逻辑。 工具简介 环境配置助手 是一款专为 macOS 打造的可视化环境变量管理工具。它通过图形化界面替代传统的命令行编辑方…...