pytorch之诗词生成3--utils
先上代码:
import numpy as np
import settingsdef generate_random_poetry(tokenizer, model, s=''):"""随机生成一首诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param s: 用于生成古诗的起始字符串,默认为空串:return: 一个字符串,表示一首古诗"""# 将初始字符串转成tokentoken_ids = tokenizer.encode(s)# 去掉结束标记[SEP]token_ids = token_ids[:-1]while len(token_ids) < settings.MAX_LEN:# 进行预测,只保留第一个样例(我们输入的样例数只有1)的、最后一个token的预测的、不包含[PAD][UNK][CLS]的概率分布output = model(np.array([token_ids, ], dtype=np.int32))_probas = output.numpy()[0, -1, 3:]del output# print(_probas)# 按照出现概率,对所有token倒序排列p_args = _probas.argsort()[::-1][:100]# 排列后的概率顺序p = _probas[p_args]# 先对概率归一p = p / sum(p)# 再按照预测出的概率,随机选择一个词作为预测结果target_index = np.random.choice(len(p), p=p)target = p_args[target_index] + 3# 保存token_ids.append(target)if target == 3:breakreturn tokenizer.decode(token_ids)def generate_acrostic(tokenizer, model, head):"""随机生成一首藏头诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param head: 藏头诗的头:return: 一个字符串,表示一首古诗"""# 使用空串初始化token_ids,加入[CLS]token_ids = tokenizer.encode('')token_ids = token_ids[:-1]# 标点符号,这里简单的只把逗号和句号作为标点punctuations = [',', '。']punctuation_ids = {tokenizer.token_to_id(token) for token in punctuations}# 缓存生成的诗的listpoetry = []# 对于藏头诗中的每一个字,都生成一个短句for ch in head:# 先记录下这个字poetry.append(ch)# 将藏头诗的字符转成token idtoken_id = tokenizer.token_to_id(ch)# 加入到列表中去token_ids.append(token_id)# 开始生成一个短句while True:# 进行预测,只保留第一个样例(我们输入的样例数只有1)的、最后一个token的预测的、不包含[PAD][UNK][CLS]的概率分布output = model(np.array([token_ids, ], dtype=np.int32))_probas = output.numpy()[0, -1, 3:]del output# 按照出现概率,对所有token倒序排列p_args = _probas.argsort()[::-1][:100]# 排列后的概率顺序p = _probas[p_args]# 先对概率归一p = p / sum(p)# 再按照预测出的概率,随机选择一个词作为预测结果target_index = np.random.choice(len(p), p=p)target = p_args[target_index] + 3# 保存token_ids.append(target)# 只有不是特殊字符时,才保存到poetry里面去if target > 3:poetry.append(tokenizer.id_to_token(target))if target in punctuation_ids:breakreturn ''.join(poetry)
我们首先看第一个函数generate_random_poetry,用于随机生成古诗。
def generate_random_poetry(tokenizer, model, s=''):"""随机生成一首诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param s: 用于生成古诗的起始字符串,默认为空串:return: 一个字符串,表示一首古诗"""tokenizer是一个分词器,用于将文本转化为模型可以理解的token序列。
# 将初始字符串转成tokentoken_ids = tokenizer.encode(s)# 去掉结束标记[SEP]token_ids = token_ids[:-1]是将我们传入的字符串转化为id序列。并使用切片操作切除token序列的最后一个元素。这个元素是用来标记结束标志[SEP]的。
我们接着看:
while len(token_ids) < settings.MAX_LEN:# 进行预测,只保留第一个样例(我们输入的样例数只有1)的、最后一个token的预测的、不包含[PAD][UNK][CLS]的概率分布output = model(np.array([token_ids, ], dtype=np.int32))_probas = output.numpy()[0, -1, 3:]del output这里我们就可以看出为什么我们要对最后一个 token进行切片处理了,是为了控制预测的长度。
之后我们进行预测,通过model模型对当前的token_ids序列进行预测,model接受一个形状为(batch_size,sequence_length)的输入,这里batch_size为1,sequence_length为token_ids的长度。因此,我们将token_ids包装成一个形状为(1,sequence_length)的numpy数组,并将其传递给model进行预测。
输出的结果是一个3D数组,形状为(1,sequence_length,vocab_size)。其中vocab_size是词汇表,得到的是对下一个词的预测。
然后通过output.numpy()将输出转化为numpy数组,由于我们只关注当前序列的最后一个token的预测结果,所以使用[0,-1,3:]来获取这部分概率分布。具体的,[0,-1]表示获取第一个样例的最后一个token的预测,而[3:]表示去除前三个token,即[PAD],[UNK]和[CLS]。
最后,通过del output释放output变量所占用的内存空间,这样做是为了及时释放内存,避免内存占用过多。
解释一下四个特殊的token在自然语言处理任务中的不同作用。
- [PAD](填充):在序列中用于填充长度不足的部分,使得序列长度统一,在很多深度学习模型中,要求输入的序列长度是相同的,因此当序列长度不足时,可以使用[PAD]进行填充,使得序列达到统一的长度。
- [UNK](未知):用于表示模型未见过的或者无法识别的词汇,当模型在处理文本时遇到不在词汇表中的词汇,就会用[UNK]表示,这样可以避免模型对于未知词汇的处理错误。
- [CLS](分类):在自然语言处理中的一些任务中,例如文本分类,文本语义相似度等,[CLS]被用作特殊的起始标记。模型会将[CLS]作为整个序列的表示,并用于后续任务的处理。例如:对于文本分类任务,模型可以根据[CLS]表示进行预测分类标签。
- [SEP](分隔符):用于表示序列的分隔,常见于处理多个句子或多个文本之间的任务。他可以用来分隔句子,句子对,文本片段等,在一些任务中,如文本对分类,问答系统等,输入可能包含多个句子或文本片段,模型可以通过识别[SEP]来理解不同句子之间的关系。另外,[SEP]还可以用于标记序列的结束,在一些 情况下,序列的长度是固定的,使用[SEP]标记还可以表示序列的结束。
继续看我们的代码:
# 按照出现概率,对所有token倒序排列p_args = _probas.argsort()[::-1][:100]# 排列后的概率顺序p = _probas[p_args]# 先对概率归一p = p / sum(p)# 再按照预测出的概率,随机选择一个词作为预测结果target_index = np.random.choice(len(p), p=p)target = p_args[target_index] + 3# 保存token_ids.append(target)首先,通过argsort()函数对得到的所有outputs进行从小到大的排序,然后经过[::-1]将排序结果进行反转,这样就变成了从大到小的排序,[:100]表示只选择排名前100的token。返回的是_probas中元素从小到大排序的索引数组。
得到索引数组之后,我们通过p=_probas[p_args],根据排名靠前的token的索引p_args,从预测的概率分布_probas中获取对应的概率值,这样得到的p就是排列后的概率顺序(概率值从大到小)。
之后对概率进行归一化,将概率值除以概率之和,使其概率和为1。
target_index = np.random.choice(len(p), p=p)根据参数p(给定的概率分布)在长度为len(p)的范围内进行随机选择,并返回选择的索引target_index。(显然,元素对应的p值越大,被选择的概率就越高)。
后面的target = p_args[target_index] + 3,其中+3是必不可少的,我刚刚因为没有+3就运行报错了,因为我们得到的target是对应于token_ids的索引,而token_ids的前三项是特殊字符,为了和实际中的模型相对应,我们需要将预测的token编号做一些偏离处理。
最后我们将我们的预测列表中加上我们预测的词的索引值,也就是target。
看着一段:
if target == 3:break return tokenizer.decode(token_ids)
如果生成的target的值是3,表示生成的token是特殊的[CLS]标记,这意味着生成的序列已结束。
返回我们解码之后的结果也就是生成的诗词。等于3的情况是存在的,3意味着结束标志SPE,当句子的长度合适时,其预测的下一个词很可能是3,我们规定3也属于可预测范围。
看生成藏头诗的代码:
def generate_acrostic(tokenizer, model, head):"""随机生成一首藏头诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param head: 藏头诗的头:return: 一个字符串,表示一首古诗"""# 使用空串初始化token_ids,加入[CLS]token_ids = tokenizer.encode('')token_ids = token_ids[:-1]# 标点符号,这里简单的只把逗号和句号作为标点punctuations = [',', '。']punctuation_ids = {tokenizer.token_to_id(token) for token in punctuations}# 缓存生成的诗的listpoetry = []# 对于藏头诗中的每一个字,都生成一个短句for ch in head:# 先记录下这个字poetry.append(ch)# 将藏头诗的字符转成token idtoken_id = tokenizer.token_to_id(ch)# 加入到列表中去token_ids.append(token_id)# 开始生成一个短句while True:# 进行预测,只保留第一个样例(我们输入的样例数只有1)的、最后一个token的预测的、不包含[PAD][UNK][CLS]的概率分布output = model(np.array([token_ids, ], dtype=np.int32))_probas = output.numpy()[0, -1, 3:]del output# 按照出现概率,对所有token倒序排列p_args = _probas.argsort()[::-1][:100]# 排列后的概率顺序p = _probas[p_args]# 先对概率归一p = p / sum(p)# 再按照预测出的概率,随机选择一个词作为预测结果target_index = np.random.choice(len(p), p=p)target = p_args[target_index] + 3# 保存token_ids.append(target)# 只有不是特殊字符时,才保存到poetry里面去if target > 3:poetry.append(tokenizer.id_to_token(target))if target in punctuation_ids:breakreturn ''.join(poetry)
我们看一下tokenizer.id_to_token(3,2,1,0)
这段代码和上面的随机生成古诗类似,不同的是:
上面的是完整生成一首古诗,其中就算遇到“,”或者“。”不会中断,直到遇到结束符号[SEP]才会中止。
而我们生成的藏头诗是对每一个字进行生成,这里遇到“,”,“。”就进行下一个字的继续生成。然后将每个字的自动生成进行拼接。得到完整的诗句。(当然,遇到[SEP]也是进行终止的,保证了句式的协调)。
return ''.join(poetry)
作用是将我们的peotry中的内容(短句),连接成一个字符串。并将其作为函数值返回。
如果不加join函数的话,输出是一个列表:
相关文章:
pytorch之诗词生成3--utils
先上代码: import numpy as np import settingsdef generate_random_poetry(tokenizer, model, s):"""随机生成一首诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param s: 用于生成古诗的起始字符串,默认为空串:return: …...

OpenAI的ChatGPT企业版专注于安全性、可扩展性和定制化。
OpenAI的ChatGPT企业版:安全、可扩展性和定制化的重点 OpenAI的ChatGPT在商业世界引起了巨大反响,而最近推出的ChatGPT企业版更是证明了其在企业界的日益重要地位。企业版ChatGPT拥有企业级安全、无限GPT-4访问、更长的上下文窗口以及一系列定制选项等增…...

JS06-class对象
class对象 className 修改样式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content&quo…...
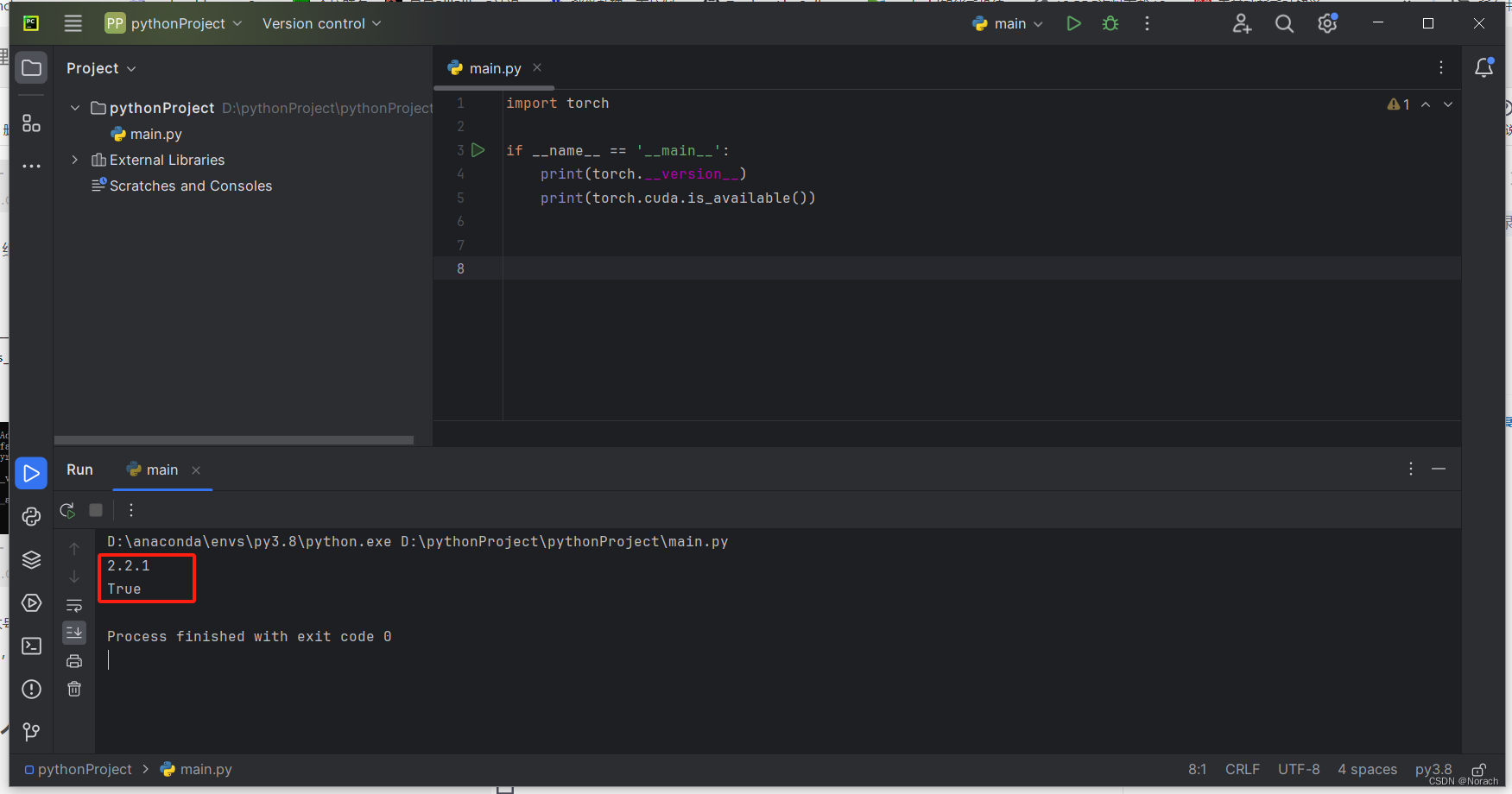
深度学习1650ti在win10安装pytorch复盘
深度学习1650ti在win10安装pytorch复盘 前言1. 安装anaconda2. 检查更新显卡驱动3. 根据pytorch选择CUDA版本4. 安装CUDA5. 安装cuDNN6. conda安装pytorch结语 前言 建议有条件的,可以在安装过程中,开启梯子。例如cuDNN安装时登录 or 注册,会…...
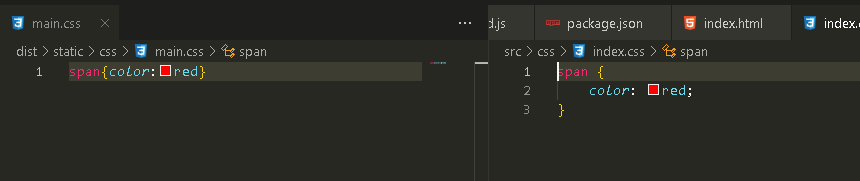
Node.js与webpack(三)
上一节:Node.js与Webpack笔记(二)-CSDN博客 从0来一遍(webpack项目) 将之前的webpack 的纯开发配置,重新创建空白项目,重新做一遍,捋一遍思路防止加入生产模式时候弄混 1.创建文件夹…...

测试覆盖率那些事
在测试过程中,会出现测试覆盖不全的情况,特别是工期紧张的情况下,测试的时间被项目的周期一压再压,测试覆盖概率不全就会伴随而来。 网上冲浪,了解一下覆盖率的文章,其中一篇感觉写的很不错,将…...
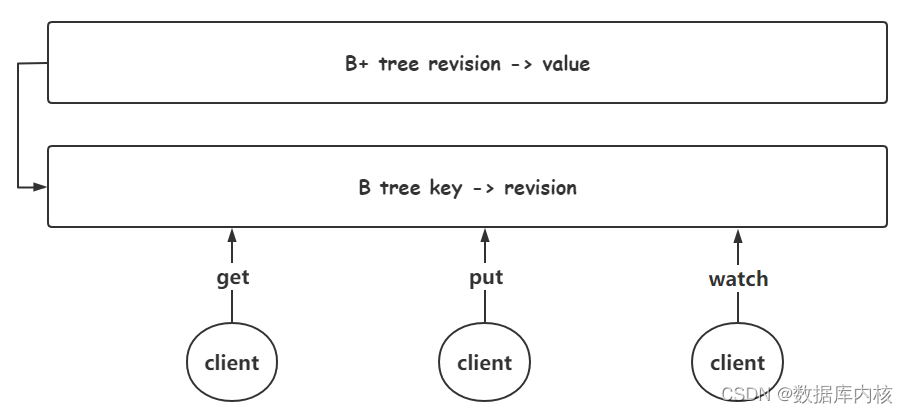
Etcd 介绍与使用(入门篇)
etcd 介绍 etcd 简介 etc (基于 Go 语言实现)在 Linux 系统中是配置文件目录名;etcd 就是配置服务; etcd 诞生于 CoreOS 公司,最初用于解决集群管理系统中 os 升级时的分布式并发控制、配置文件的存储与分发等问题。基…...
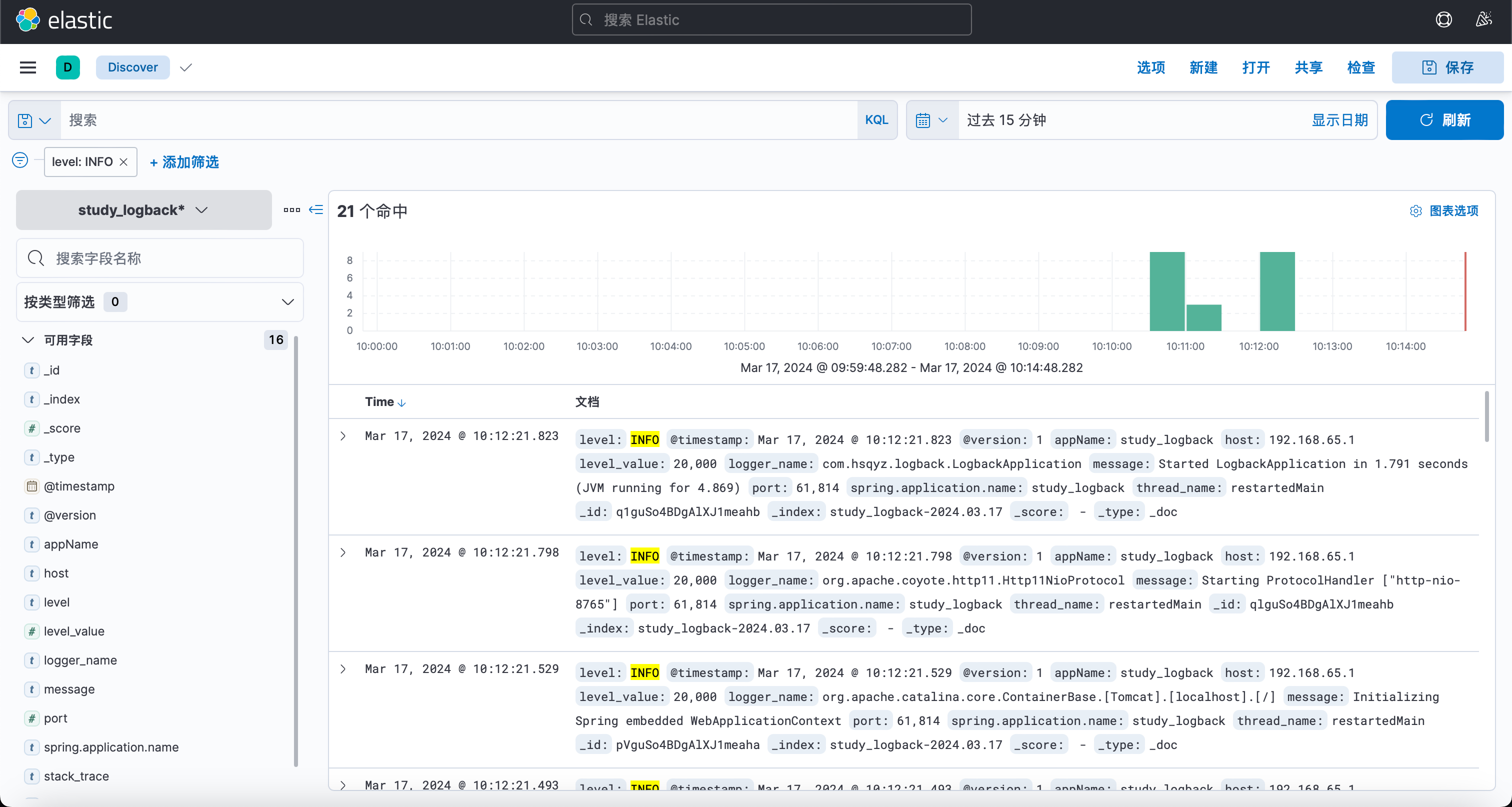
Docker 安装 LogStash
关于LogStash Logstash,作为Elastic Stack家族中的核心成员之一,是一个功能强大的开源数据收集引擎。它专长于从各种来源动态地获取、解析、转换和丰富数据,并将这些结构化或非结构化的数据高效地传输到诸如Elasticsearch等存储系统中进行集…...

Selenium笔记
Selenium笔记 Selenium笔记 Selenium笔记element not interactable页面刷新 element not interactable "element not interactable"是Selenium在执行与网页元素交互操作(如点击、输入等)时抛出的一个常见错误。这个错误意味着虽然找到了对应的…...
ChatGPT :确定性AI源自于确定性数据
ChatGPT 幻觉 大模型实际应用落地过程中,会遇到幻觉(Hallucination)问题。对于语言模型而言,当生成的文本语法正确流畅,但不遵循原文(Faithfulness),或不符合事实(Factua…...
linux驱动开发面试题
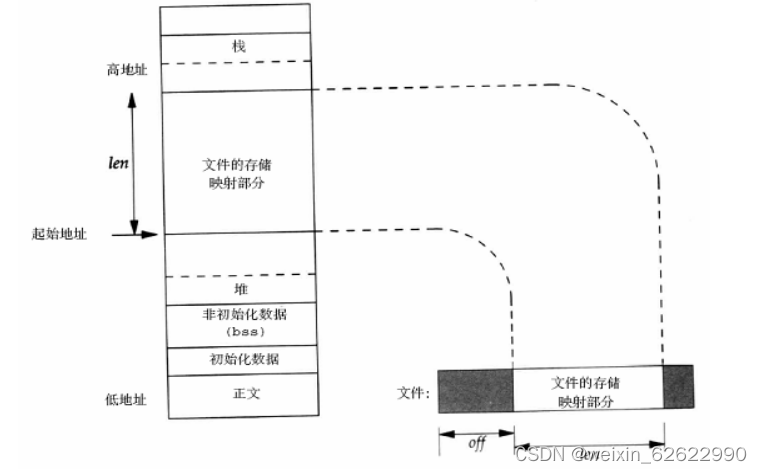
1.linux中内核空间及用户空间的区别? 记住“22”,两级分段两级权限。 例如是32位的机器,从内存空间看:顶层1G是内核的,底3G是应用的;从权限看:内核是0级特权,应用是3级特权。 2.用…...

【AI】Ubuntu系统深度学习框架的神经网络图绘制
一、Graphviz 在Ubuntu上安装Graphviz,可以使用命令行工具apt进行安装。 安装Graphviz的步骤相对简单。打开终端,输入以下命令更新软件包列表:sudo apt update。之后,使用命令sudo apt install graphviz来安装Graphviz软件包。为…...
:2024.03.05-2024.03.10—(2))
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.05-2024.03.10—(2)
论文目录~ 1.Debiasing Large Visual Language Models2.Harnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering3.Towards a Psychology of Machines: Large Language Models Predict Human Memory4.Can we obtain significant succ…...

AI解答——DNS、DHCP、SNMP、TFTP、IKE、RIP协议
使用豆包帮助我解答计算机网络通讯问题—— 1、DHCP 服务器是什么? DHCP 服务器可是网络世界中的“慷慨房东”哦🤣 它的全称是 Dynamic Host Configuration Protocol(动态主机配置协议)服务器。 DHCP 服务器的主要任务是为网络中的…...

【TypeScript系列】声明合并
声明合并 介绍 TypeScript中有些独特的概念可以在类型层面上描述JavaScript对象的模型。 这其中尤其独特的一个例子是“声明合并”的概念。 理解了这个概念,将有助于操作现有的JavaScript代码。 同时,也会有助于理解更多高级抽象的概念。 对本文件来讲,“声明合并”是指编…...
zookeeper基础学习之六: zookeeper java客户端curator
简介 Curator是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等。Patrixck Hunt(Zookeeper)以一句“Guava is to Java…...
表查询)
MySQL数据库操作学习(2)表查询
文章目录 一、表查询1.表字段的操作①查看表结构②字段的增加③字段长度/数据类型的修改④字段名的修改⑤删除字符段⑥清空表数据⑦修改表名⑧删除表 2、表数据查询3、where 字段4、聚合函数 一、表查询 1.表字段的操作 ①查看表结构 desc 表名; # 查看表中的字段类型&#…...
Java学习
目录 treeSet StringBuilder treeSet TreeSet 是 Java 中实现了 Set 接口的一种集合类,它使用红黑树数据结构来存储元素,放到TreeSet集合中的元素: 无序不可重复,但是可以按照元素的大小顺序自动排序。 TreeSet一般会和Iterator迭代器一起使…...

C#八皇后算法:回溯法 vs 列优先法 vs 行优先法 vs 对角线优先法
目录 1.八皇后算法(Eight Queens Puzzle) 2.常见的八皇后算法解决方案 (1)列优先法(Column-First Method): (2)行优先法(Row-First Method)&a…...

springboot整合swagger,postman,接口规范
一、postman介绍 1.1概述 工具下载 Postman(发送 http 请求的工具) 官网(下载速度比较慢):Download Postman | Get Started for Free 网盘下载:百度网盘 请输入提取码 1.2Http 请求格式 请求地址请求方法状…...

从SIM800到BK A7670E:4G Cat.1模块硬件平替转接板设计全解析
1. 项目概述:从2G到4G的硬件平替升级 手头有个老项目,用的还是SIM800这种经典的2G模块,现在网络环境变了,2G退网是大势所趋,信号覆盖越来越差,项目得活下去,升级到4G成了刚需。但问题来了&#…...

让B站缓存视频重获自由:一个简单实用的格式转换工具
让B站缓存视频重获自由:一个简单实用的格式转换工具 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还记得那个周末的下午吗…...

Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑
Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾经因为复杂的视频编辑软件而头疼?想要一个免费、开源且…...

开源合规生死线,DeepSeek协议识别错误率高达63%?2024企业级扫描避坑清单全公开
更多请点击: https://intelliparadigm.com 第一章:开源合规生死线,DeepSeek协议识别错误率高达63%?2024企业级扫描避坑清单全公开 近期第三方审计机构对主流AI增强型开源扫描工具开展交叉验证测试,结果显示DeepSeek-R…...

告别烧录烦恼:用Etcher三步打造完美启动盘的终极指南
告别烧录烦恼:用Etcher三步打造完美启动盘的终极指南 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 你是否曾因烧录系统镜像而误删硬盘数据…...

C语言--day19
第十章 内存管理当./a.out 运行起来后,系统会给a.out分配一段内存区域1、code ,存放编写好的c语言代码。 只读特性,在运行期间不能修改2、data 数据段。 存储全局变量,和被static 修改的变量细分:data 数据段ÿ…...

告别手动分类!用Python+ArcPy批量处理DEM,一键生成坡度坡向等高线报告
用PythonArcPy实现DEM地形分析全自动化:从数据到报告的智能工作流 第一次接手山区风电项目的地形分析任务时,我花了整整三天时间在ArcGIS界面里反复点击同样的按钮——加载DEM、计算坡度坡向、生成等高线、调整分类阈值、导出图片。当第五个区域的报告终…...

终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签
终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 还在为满屏混乱的Chrome书…...

Hearthstone-Script终极指南:如何用开源炉石脚本实现智能自动对战
Hearthstone-Script终极指南:如何用开源炉石脚本实现智能自动对战 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为炉石传说繁琐的日常…...

为什么你的Windows快捷键突然失效?3分钟找出罪魁祸首
为什么你的Windows快捷键突然失效?3分钟找出罪魁祸首 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否经历…...