RAxML-NG安装与使用-raxml-ng-v1.2.0(bioinfomatics tools-013)
01 背景
1.1 ML树
ML树,或最大似然树,是一种在进化生物学中用来推断物种之间进化关系的方法。最大似然(Maximum Likelihood, ML)是一种统计框架,用于估计模型参数,使得观察到的数据在该模型参数下的概率最大。在进化树的构建中,这意味着选择一棵树(包括其分支长度和模型参数),使得给定的序列数据在该树模型下出现的概率最大。
ML树的特点:
- 模型驱动:ML方法依赖于复杂的统计模型来描述序列进化过程中的变化。这些模型可以包括核苷酸或氨基酸替换的不同速率、遗传密码的变异等。
- 数据适应:最大似然方法能够适应不同类型的分子数据(如DNA、RNA或蛋白质序列),并考虑序列间的进化距离和速率变异。
- 计算密集:相比其他方法(如邻接法或最大简约法),ML方法在计算上更为密集,因为它需要评估多种树形和参数组合下的概率。
ML树的应用:
- 物种分类:帮助科学家理解不同物种间的亲缘关系。
- 进化研究:通过分析物种的遗传变化,研究它们的进化历史。
- 功能预测:通过比较进化上相关的序列,预测未知序列的功能。
- 生态和保护生物学:了解物种的进化关系,有助于生态保护和生物多样性研究。
最大似然树提供了一种强大的方法来推断物种间的进化关系,尽管它在计算上更为要求,但通过提供更准确的估计和适应多样化数据的能力,已成为分子系统发育学中的一个重要工具。
1.2 RAxML-NG
RAxML(Stamatakis,2014年)是一个受欢迎的最大似然(ML)树推断工具,过去15年来一直由Alexey M Kozlov的团队开发和支持。最近,我们还发布了ExaML(Kozlov等人,2015年),这是一个专门用于在超级计算机上分析基因组规模数据集的代码。ExaML实现了RAxML的核心树搜索功能,并且可以扩展到数千个CPU核心。其他广泛使用的ML推断工具包括IQ-Tree(Nguyen等人,2015年),PhyML(Guindon等人,2010年)和FastTree(Price等人,2010年)。
在这里,我们介绍我们的新代码RAxML-NG(RAxML下一代)。它结合了RAxML和ExaML的优势和概念,并提供了我们在下一节中将描述的几项额外改进。
所以,ML建树的最新一代版本软件,横空出世,一代版本一代神,代代版本ML树!
常配合MAFFT使用,详见MAFFT安装及使用-mafft v7.520(bioinfomatics tools-004)
02 参考
https://github.com/amkozlov/raxml-ng #官网03 安装
这里是原码安装,就帮大家省略了hhh,编译好多人服务器可能配置不够
https://github.com/stamatak/standard-RAxML.git
Build RAxML-NG.
PTHREADS version:git clone --recursive https://github.com/amkozlov/raxml-ng
cd raxml-ng
mkdir build && cd build
cmake ..
make下载zip注意解压即可
#下载安装包
wget -c https://github.com/amkozlov/raxml-ng/releases/download/1.2.0/raxml-ng_v1.2.0_linux_x86_64.zip
unzip raxml-ng_v1.2.0_linux_x86_64.zip -d ./raxml-ng
#将raxml-ng_v1.2.0_linux_x86_64.zip文件解压到当前目录下的一个名为raxml-ng的新文件夹里。04 使用
RAxML-NG v. 1.2.0 发布于 2023年5月9日,由 Exelixis Lab 开发。
开发者包括 Alexey M. Kozlov 和 Alexandros Stamatakis。
贡献者有 Diego Darriba, Tomas Flouri, Benoit Morel, Sarah Lutteropp, Ben Bettisworth, Julia Haag, Anastasis Togkousidis。
最新版本可在 https://github.com/amkozlov/raxml-ng 获取。
有问题/问题/建议?请访问:https://groups.google.com/forum/#!forum/raxml系统:Intel(R) Xeon(R) Platinum 8173M CPU @ 2.00GHz,56核,502 GB RAM使用方法:raxml-ng [选项]命令(互斥):--help 显示帮助信息--version 显示版本信息--evaluate 评估一棵树的似然(包含模型+分支长度优化)--search 最大似然(ML)树搜索(默认:10个拟合树 + 10个随机起始树)--bootstrap 引导法(默认:使用引导停止自动检测复制品数量)--all 一体化(ML搜索 + 引导法)--support 计算给定参考树(例如,最佳ML树)的分割支持和一组复制树(例如,来自引导分析的树)--bsconverge 使用autoMRE标准测试引导收敛性--bsmsa 生成引导复制MSAs--terrace 检查树是否位于系统发育露台上--check 检查校正并移除空列/行--parse 解析校正,压缩模式并创建二进制MSA文件--start 生成拟合/随机起始树并退出--rfdist 计算树之间的成对Robinson-Foulds(RF)距离--consense [ STRICT | MR | MR<n> | MRE ] 构建严格、多数规则(MR)或扩展MR(MRE)共识树(默认:MR)例如:--consense MR75 --tree bsrep.nw--ancestral 在所有内节点上重建祖先状态--sitelh 打印每个站点的对数似然值命令快捷方式(互斥):--search1 别名:--search --tree rand{1}--loglh 别名:--evaluate --opt-model off --opt-branches off --nofiles --log result--rf 别名:--rfdist --nofiles --log result输入输出选项:--tree rand{N} | pars{N} | FILE 起始树:rand(随机), pars(拟合) 或用户指定(新克文件)N = 树的数量(默认:rand{10},pars{10})--msa FILE 校正文件--msa-format VALUE 校正文件格式:FASTA, PHYLIP, CATG 或 自动检测(默认)--data-type VALUE 数据类型:DNA, AA, BIN(二进制) 或 自动检测(默认)--tree-constraint FILE 约束树--prefix STRING 输出文件的前缀(默认:MSA文件名)--log VALUE 日志详细程度:ERROR,WARNING,RESULT,INFO,PROGRESS,DEBUG(默认:PROGRESS)--redo 覆盖现有结果文件并忽略检查点(默认:关闭)--nofiles 不创建任何输出文件,仅在终端打印结果--precision VALUE 打印的小数位数(默认:6)--outgroup o1,o2,..,oN 逗号分隔的外群类群名称列表(只是一个绘制选项!)--site-weights FILE MSA列权重文件(仅正整数!) 通用选项:--seed VALUE 伪随机数生成器的种子(默认:当前时间)--pat-comp on | off 校正模式压缩(默认:开启)--tip-inner on | off 尖端-内部案例优化(默认:关闭)--site-repeats on | off 使用站点重复优化,比尖端-内部快10%-60%(默认:开启)--threads VALUE 使用的并行线程数(默认:56)--workers VALUE 并行运行的树搜索数量(默认:1)--simd none | sse3 | avx | avx2 使用的向量指令集(默认:自动检测)--rate-scalers on | off 对每个速率类别使用单独的CLV缩放器(对于>2000物种默认开启)--force [ <CHECKS> ] 禁用安全检查(请三思!)模型选项:--model <name>+G[n]+<Freqs> | FILE 模型规格或分区文件--brlen linked | scaled | unlinked 分区间分支长度链接(默认:scaled)--blmin VALUE 最小分支长度(默认:1e-6)--blmax VALUE 最大分支长度(默认:100)--blopt nr_fast | nr_safe 分支长度优化方法(默认:nr_fast)nr_oldfast | nr_oldsafe --opt-model on | off ML优化所有模型参数(默认:开启)--opt-branches on | off ML优化所有分支长度(默认:开启)--prob-msa on | off 使用概率校正(与CATG和VCF兼容)--lh-epsilon VALUE 优化/树搜索的对数似然epsilon(默认:0.1)拓扑搜索选项:--spr-radius VALUE SPR重新插入半径,快速迭代(默认:自动)--spr-cutoff VALUE | off 下降到子树的相对LH截断(默认:1.0)--lh-epsilon-triplet VALUE 分支长度三元组优化的对数似然epsilon(默认:1000)引导选项:--bs-trees VALUE 引导复制品数量--bs-trees autoMRE{N} 使用基于MRE的引导收敛标准,最多N个复制品(默认:1000)--bs-trees FILE 包含一组引导复制树的Newick文件(与--support一起使用)--bs-cutoff VALUE MRE-based引导停止标准的截断阈值(默认:0.03)--bs-metric fbp | tbe 分支支持度量:fbp = Felsenstein引导(默认),tbe = 转移距离--bs-write-msa on | off 写下所有引导校正(默认:关闭)05 常用命令行
常配合MAFFT使用,详见MAFFT安装及使用-mafft v7.520(bioinfomatics tools-004)
1. 对DNA校正进行树推断(10个随机+10个拟合起始树,通用时间可逆模型,ML估计替换率和核苷酸频率,离散GAMMA异质性率模型,4类):./raxml-ng --msa testDNA.fa --model GTR+G ##这个属于all的一部分2. 进行一体化分析(ML树搜索 + 非参数引导)(10个随机化拟合起始树,固定经验替换矩阵(LG),校正中的经验氨基酸频率,8个离散GAMMA类别,200个引导复制品):./raxml-ng --all --msa testAA.fa --model LG+G8+F --tree pars{10} --bs-trees 200 ##涵盖上述search 就是103. 在固定拓扑上优化分支长度和自由模型参数(使用比例分支长度的多个分区)./raxml-ng --evaluate --msa testAA.fa --model partitions.txt --tree test.tree --brlen scaled ##使用一个合适的枝长参数 evalute一个参数 他有一个优化模式 优化的话,这里就是选择最优模型进行打分判定。需要给定模型集合实际上常用的
./raxml-ng --support --tree bestML.tree --bs-trees bootstraps.tree ##给予一个最好模型的数据,然后在进行,这种本文不予采用##还是需要模型文件,然后筛选最佳模型,然后进行打分,但是模型文件
./raxml-ng/raxml-ng --msa singlecopy.mafft --prefix singlecopy.mafft.ML --threads 20 --bs-trees 1000 --model XXX06 参考文献
Kozlov AM, Darriba D, Flouri T, Morel B, Stamatakis A. RAxML-NG: a fast, scalable and user-friendly tool for maximum likelihood phylogenetic inference. Bioinformatics. 2019 Nov 1;35(21):4453-4455. doi: 10.1093/bioinformatics/btz305. PMID: 31070718; PMCID: PMC6821337.
周颖,祝波,钱冬等. 虾肝肠胞虫感染病理特征、18S rRNA基因序列及系统进化树分析 [J]. 宁波大学学报(理工版), 2022, 35 (02): 8-14.
季梦玮,滕飞翔,周敏等. 原生动物AQPs系统进化树的构建以及结构分析 [J]. 江苏科技信息, 2019, 36 (13): 46-51.
李晓凤. 基于物种系统进化树的已批准天然来源药物物种分布与机制研究[D]. 重庆大学, 2018.
杜鹏程,于伟文,陈禹保等. 利用系统进化树对H7N9大数据预测传播模型的评估 [J]. 中国生物工程杂志, 2014, 34 (11): 18-23. DOI:10.13523/j.cb.20141103.
李玲. 基于线粒体基因组构建生物系统进化树[D]. 内蒙古工业大学, 2014.
相关文章:
)
RAxML-NG安装与使用-raxml-ng-v1.2.0(bioinfomatics tools-013)
01 背景 1.1 ML树 ML树,或最大似然树,是一种在进化生物学中用来推断物种之间进化关系的方法。最大似然(Maximum Likelihood, ML)是一种统计框架,用于估计模型参数,使得观察到的数据在该模型参数下的概率最…...

Tomcat内存马
Tomcat内存马 前言 描述Servlet3.0后允许动态注册组件 这一技术的实现有赖于官方对Servlet3.0的升级,Servlet在3.0版本之后能够支持动态注册组件。 而Tomcat直到7.x才支持Servlet3.0,因此通过动态添加恶意组件注入内存马的方式适合Tomcat7.x及以上。…...

pytorch之诗词生成3--utils
先上代码: import numpy as np import settingsdef generate_random_poetry(tokenizer, model, s):"""随机生成一首诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param s: 用于生成古诗的起始字符串,默认为空串:return: …...

OpenAI的ChatGPT企业版专注于安全性、可扩展性和定制化。
OpenAI的ChatGPT企业版:安全、可扩展性和定制化的重点 OpenAI的ChatGPT在商业世界引起了巨大反响,而最近推出的ChatGPT企业版更是证明了其在企业界的日益重要地位。企业版ChatGPT拥有企业级安全、无限GPT-4访问、更长的上下文窗口以及一系列定制选项等增…...

JS06-class对象
class对象 className 修改样式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content&quo…...
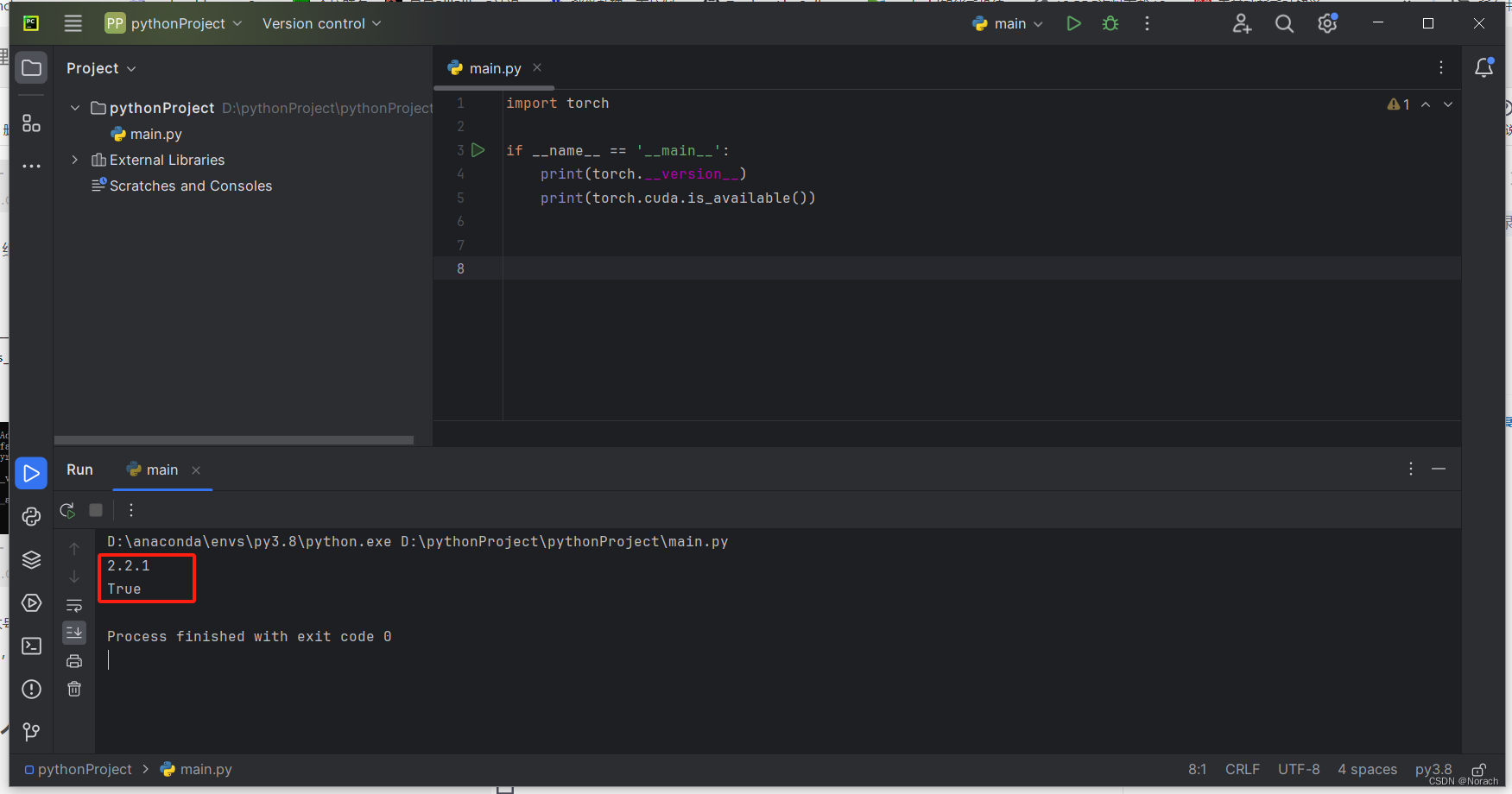
深度学习1650ti在win10安装pytorch复盘
深度学习1650ti在win10安装pytorch复盘 前言1. 安装anaconda2. 检查更新显卡驱动3. 根据pytorch选择CUDA版本4. 安装CUDA5. 安装cuDNN6. conda安装pytorch结语 前言 建议有条件的,可以在安装过程中,开启梯子。例如cuDNN安装时登录 or 注册,会…...
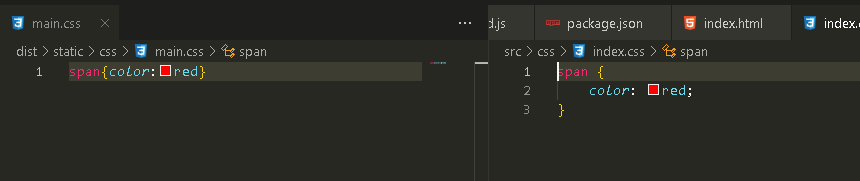
Node.js与webpack(三)
上一节:Node.js与Webpack笔记(二)-CSDN博客 从0来一遍(webpack项目) 将之前的webpack 的纯开发配置,重新创建空白项目,重新做一遍,捋一遍思路防止加入生产模式时候弄混 1.创建文件夹…...

测试覆盖率那些事
在测试过程中,会出现测试覆盖不全的情况,特别是工期紧张的情况下,测试的时间被项目的周期一压再压,测试覆盖概率不全就会伴随而来。 网上冲浪,了解一下覆盖率的文章,其中一篇感觉写的很不错,将…...
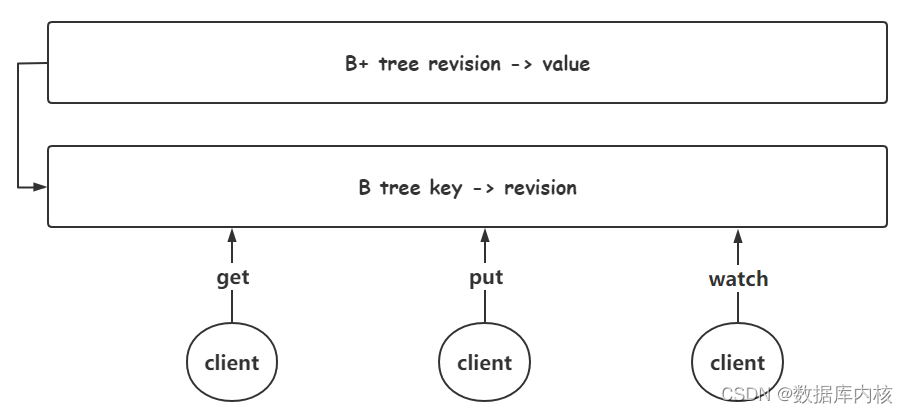
Etcd 介绍与使用(入门篇)
etcd 介绍 etcd 简介 etc (基于 Go 语言实现)在 Linux 系统中是配置文件目录名;etcd 就是配置服务; etcd 诞生于 CoreOS 公司,最初用于解决集群管理系统中 os 升级时的分布式并发控制、配置文件的存储与分发等问题。基…...
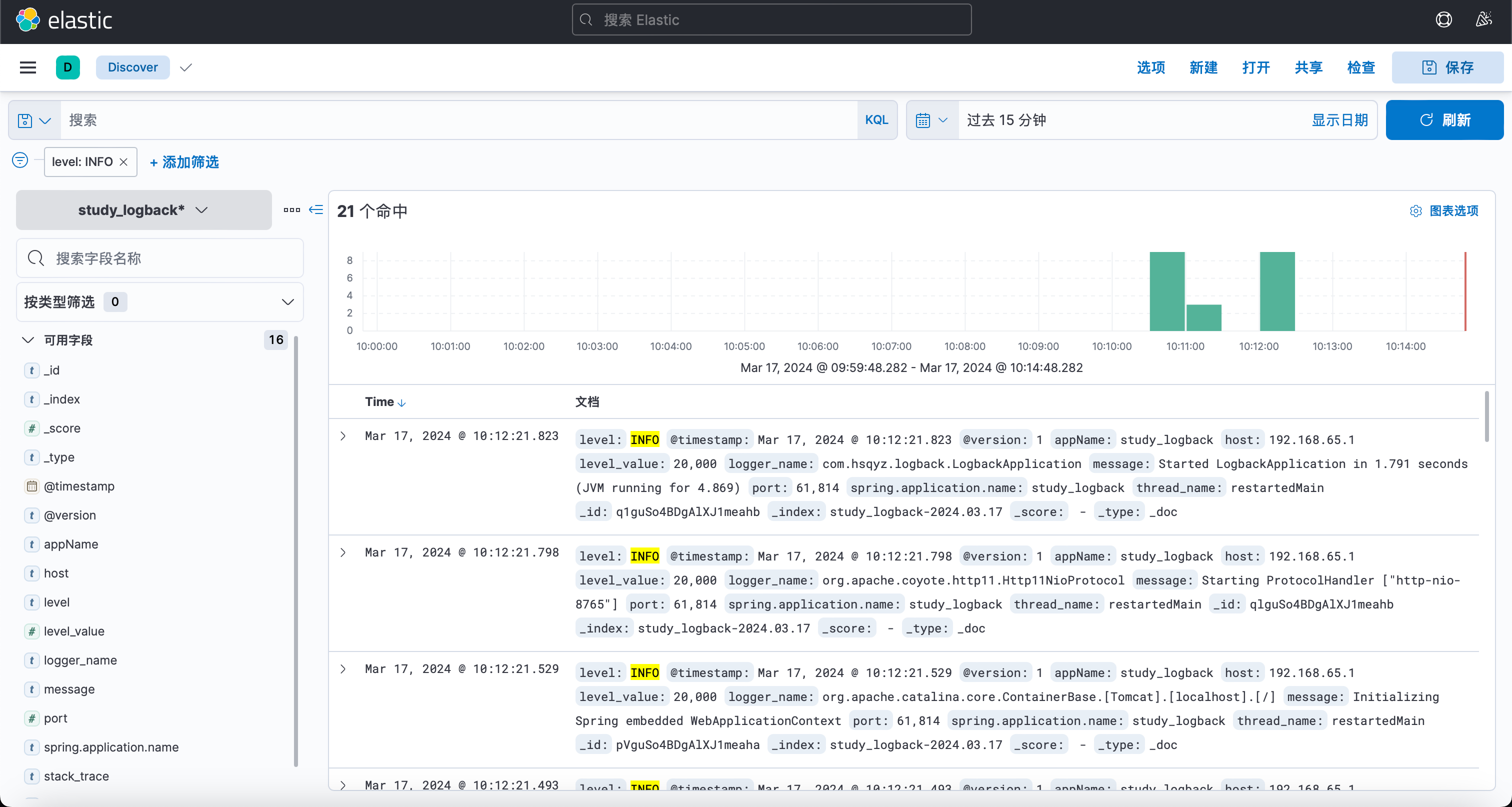
Docker 安装 LogStash
关于LogStash Logstash,作为Elastic Stack家族中的核心成员之一,是一个功能强大的开源数据收集引擎。它专长于从各种来源动态地获取、解析、转换和丰富数据,并将这些结构化或非结构化的数据高效地传输到诸如Elasticsearch等存储系统中进行集…...

Selenium笔记
Selenium笔记 Selenium笔记 Selenium笔记element not interactable页面刷新 element not interactable "element not interactable"是Selenium在执行与网页元素交互操作(如点击、输入等)时抛出的一个常见错误。这个错误意味着虽然找到了对应的…...
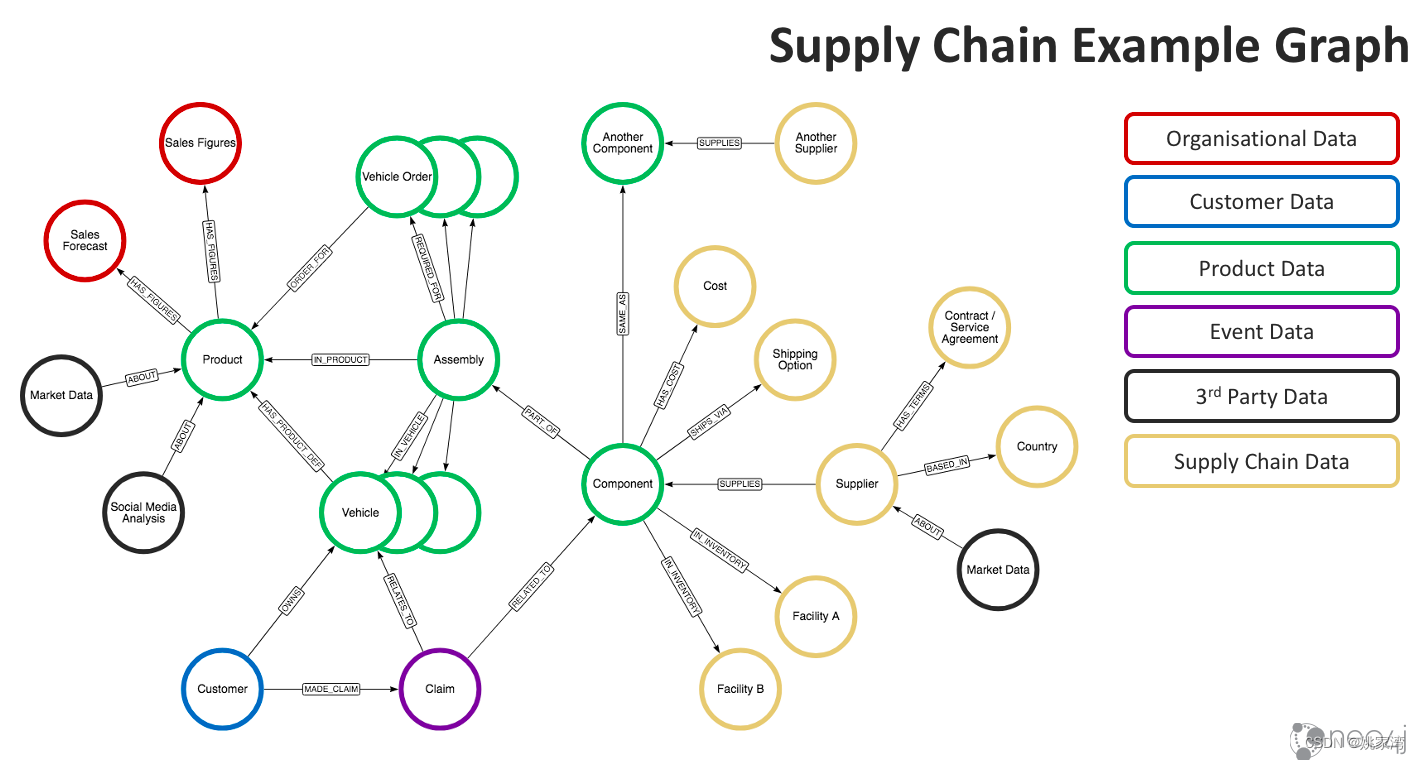
ChatGPT :确定性AI源自于确定性数据
ChatGPT 幻觉 大模型实际应用落地过程中,会遇到幻觉(Hallucination)问题。对于语言模型而言,当生成的文本语法正确流畅,但不遵循原文(Faithfulness),或不符合事实(Factua…...
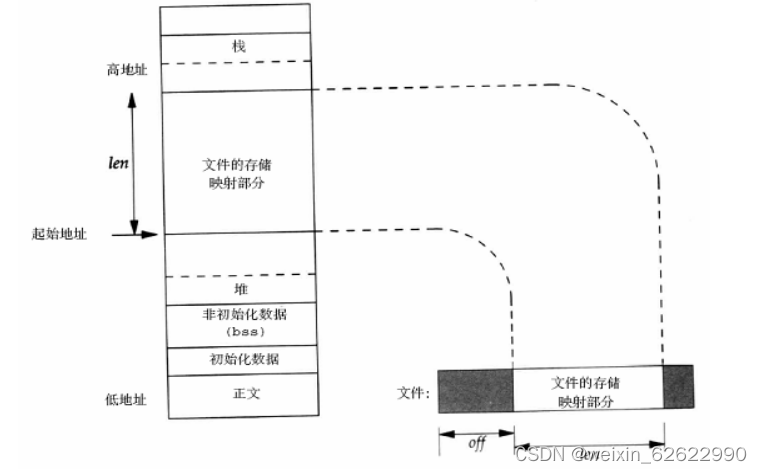
linux驱动开发面试题
1.linux中内核空间及用户空间的区别? 记住“22”,两级分段两级权限。 例如是32位的机器,从内存空间看:顶层1G是内核的,底3G是应用的;从权限看:内核是0级特权,应用是3级特权。 2.用…...

【AI】Ubuntu系统深度学习框架的神经网络图绘制
一、Graphviz 在Ubuntu上安装Graphviz,可以使用命令行工具apt进行安装。 安装Graphviz的步骤相对简单。打开终端,输入以下命令更新软件包列表:sudo apt update。之后,使用命令sudo apt install graphviz来安装Graphviz软件包。为…...
:2024.03.05-2024.03.10—(2))
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.05-2024.03.10—(2)
论文目录~ 1.Debiasing Large Visual Language Models2.Harnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering3.Towards a Psychology of Machines: Large Language Models Predict Human Memory4.Can we obtain significant succ…...

AI解答——DNS、DHCP、SNMP、TFTP、IKE、RIP协议
使用豆包帮助我解答计算机网络通讯问题—— 1、DHCP 服务器是什么? DHCP 服务器可是网络世界中的“慷慨房东”哦🤣 它的全称是 Dynamic Host Configuration Protocol(动态主机配置协议)服务器。 DHCP 服务器的主要任务是为网络中的…...

【TypeScript系列】声明合并
声明合并 介绍 TypeScript中有些独特的概念可以在类型层面上描述JavaScript对象的模型。 这其中尤其独特的一个例子是“声明合并”的概念。 理解了这个概念,将有助于操作现有的JavaScript代码。 同时,也会有助于理解更多高级抽象的概念。 对本文件来讲,“声明合并”是指编…...
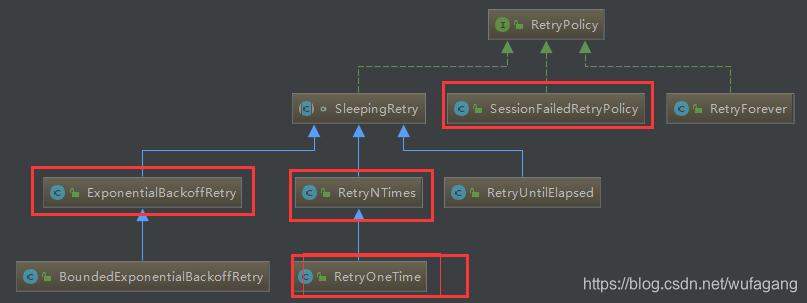
zookeeper基础学习之六: zookeeper java客户端curator
简介 Curator是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等。Patrixck Hunt(Zookeeper)以一句“Guava is to Java…...
表查询)
MySQL数据库操作学习(2)表查询
文章目录 一、表查询1.表字段的操作①查看表结构②字段的增加③字段长度/数据类型的修改④字段名的修改⑤删除字符段⑥清空表数据⑦修改表名⑧删除表 2、表数据查询3、where 字段4、聚合函数 一、表查询 1.表字段的操作 ①查看表结构 desc 表名; # 查看表中的字段类型&#…...
Java学习
目录 treeSet StringBuilder treeSet TreeSet 是 Java 中实现了 Set 接口的一种集合类,它使用红黑树数据结构来存储元素,放到TreeSet集合中的元素: 无序不可重复,但是可以按照元素的大小顺序自动排序。 TreeSet一般会和Iterator迭代器一起使…...
)
市面上有哪些是真正安全的降AIGC网站(轻松压低AI生成疑似率)
最崩溃的不是查重难题,而是查重达标却AI率超标亮红灯!很多工具只会简单同义词替换、浅层改字,根本洗不掉AI专属句式、行文逻辑和高频模板话术,学校AIGC检测一查一个准,论文直接凉凉。 本篇结合全网实测数据,…...

终极解决方案:彻底解决UE4SS DLL劫持导致的系统级应用程序启动错误
终极解决方案:彻底解决UE4SS DLL劫持导致的系统级应用程序启动错误 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/r…...

Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化
Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

代码质量保卫战,从人工Review到DeepSeek自动审查的7天转型全记录
更多请点击: https://kaifayun.com 第一章:代码质量保卫战的范式转移 过去十年,代码质量保障已从“事后拦截”转向“全程共生”。单元测试覆盖率不再是KPI终点,而是开发流程的呼吸节律;静态分析不再停留于CI流水线末尾…...

医用超声图像干扰伪像算法:原理、识别与抑制技术综述
引言 医用超声成像因其无创、实时、低成本等优点,已成为临床诊断不可或缺的工具。然而,超声图像质量极易受到各种物理因素和系统限制的影响,从而产生干扰伪像。这些伪像并非真实的解剖结构,而是由声波传播特性、设备硬件、操作手法等因素导致的虚假或失真的图像信息。准确…...
)
避坑指南:在Unity里用sherpa-onnx做离线TTS,我踩过的那些‘坑’(采样率、尾音、模型选择)
Unity集成sherpa-onnx离线TTS实战避坑指南第一次在Unity里听到自己合成的机械音时,那种兴奋感至今难忘——直到发现所有音频都像上世纪电话录音一样失真。原来sherpa-onnx默认生成的8000Hz采样率音频,在Unity的44100Hz标准环境下直接播放会产生严重的音质…...

3秒解锁微博图片溯源能力:重新定义你的信息追踪体验
3秒解锁微博图片溯源能力:重新定义你的信息追踪体验 【免费下载链接】WeiboImageReverse Chrome 插件,反查微博图片po主 项目地址: https://gitcode.com/gh_mirrors/we/WeiboImageReverse 当你在微博上看到一张惊艳的摄影作品,想要了解…...

在Ubuntu 20.04上从源码编译Spconv 1.2.1:一份给点云感知开发者的避坑指南
在Ubuntu 20.04上从源码编译Spconv 1.2.1:一份给点云感知开发者的避坑指南 对于从事3D点云感知研究的开发者来说,Spconv库的安装往往是搭建开发环境时遇到的第一个"拦路虎"。这个专为稀疏卷积优化的库,虽然在性能上表现出色&#…...

Charles断点调试:HTTP/HTTPS流量精准控制与实战避坑
1. 这不是“抓包”,是精准外科手术式调试 很多人第一次听说 Charles,第一反应是“哦,又一个抓包工具”。但如果你真这么用,大概率会在某次接口联调中卡住两小时,反复刷新页面却始终看不到后端返回的错误码,…...
)
从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建第一个无人机仿真场景(Python控制入门)
从游戏引擎到仿真平台:手把手教你用AirSimUE4搭建第一个无人机仿真场景(Python控制入门)当你第一次看到虚幻引擎4(UE4)那令人惊叹的渲染效果时,可能很难想象这个游戏开发工具正在成为机器人仿真领域的新宠。…...