关于正则表达式的讲解
以下内容源于《linux命令行与shell脚本编程大全【第三版】》一书的整理。
在shell脚本中成功运用sed编辑器和gawk程序的关键,在于熟练地使用正则表达式。
一、正则表达式的简介
1、正则表达式的定义
正则表达式(regular expression)是一个模板,linux工具(比如sed编辑器、gawk程序)可以利用这个模板来过滤文本。
换句话说,在处理数据时,可以利用正则表达式对数据进行模式匹配。如果数据匹配模式,则数据会被接受并进一步处理;如果数据不匹配模式,则数据会被过滤掉。
正则表达式包含有文本或特殊字符,可以使用不同的特殊字符来定义特定的数据过滤模板。
我们平常说的“匹配模板”,或者“正则表达式”,或者“正则表达式模板”,都是这个意思。
2、正则表达式的类型
一个正则表达式写出来后,谁来负责解释这个正则表达式,并利用它进行文本匹配呢?
Linux中有一套底层软件负责完成这部分工作,我们把这套底层软件叫做“正则表达式引擎”。
Linux中有两种流行的正则表达式引擎:POSIX基础正则表达式引擎(简称BRE引擎)、POSIX扩展正则表达式引擎(简称ERE引擎)。不同引擎下正则表达式的写法不同。
sed编辑器能识别BRE引擎下的正则表达式,不能识别ERE引擎下的正则表达式(即在sed编辑器中不能使用ERE引擎下正则表达式的写法);gawk程序可以识别ERE引擎下的正则表达式(也可以识别BRE引擎下的正则表达式),自身也提供了一些额外的过滤功能,因此gawk在处理数据流时通常比较慢。
接下来讲述在不同引擎下,如何编写一个正则表达式。
二、BRE引擎下正则表达式的写法
1、普通的文本字符
最基础的BRE模板,是匹配数据流中的普通文本字符。
在sed编辑器的替换命令s(见sed命令)中我们已经尝试过这种写法,比如下面例子中,单词test就是一个正则表达式模板。
xjh@ubuntu:~/iot/tmp$ cat data1.txt
This is a test
xjh@ubuntu:~/iot/tmp$ sed 's/test/big test/' data1.txt
This is a big test
xjh@ubuntu:~/iot/tmp$2、特殊的文本字符
有一些文本字符有特殊的含义,比如.*[ ]^$()\+?|()等等。
如果要在文本模式中使用这些字符,就必须转义,也就是在它们前面添加反斜杠\,告诉正则表达式引擎把它当做普通的文本字符。
举个例子,如果要查找文本中的美元符号,需要在它前面添加反斜杆\。
xjh@ubuntu:~/iot/tmp$ cat data6.txt
The dog costs me $66.00
The cat costs me $45.00
xjh@ubuntu:~/iot/tmp$ sed '/\$/s/\$/RMB/' data6.txt
The dog costs me RMB66.00
The cat costs me RMB45.00
xjh@ubuntu:~/iot/tmp$ 3、锚字符
默认情况下,与正则表达式匹配的地方,可以是某一行的行首、行尾或者行中间某处地方,只要正则表达式与某一行内容的任何地方匹配上,则会将该行的内容传回Linux工具。
我们也可以利用两个特殊的字符,即脱字符(^)与美元符($),以满足只匹配行首或者只匹配行尾的需求,其中脱字符(^)表示只检测行首的内容是否符合正则表达式,美元符($)表示只检测行尾的内容是否符合正则表达式。
xjh@ubuntu:~/iot/tmp$ echo "the book store" | sed -n '/^book/p' #^book表示检测行首是否符合正则表达式book,这里行首是the而非book,因此匹配不上而没有输出
xjh@ubuntu:~/iot/tmp$ echo "book are great" | sed -n '/^book/p' #^book表示检测行首是否符合正则表达式book,这里行首就是book,匹配得上而输出
book are great
xjh@ubuntu:~/iot/tmp$ echo "This is a good book" | sed -n '/book$/p' #book$表示检测行尾是否符合正则表达式book,这里行尾就是book,因此匹配得上而输出
This is a good book
xjh@ubuntu:~/iot/tmp$ echo "This book is good" | sed -n '/book$/p'#book$表示检测行尾是否符合正则表达式book,这里行尾不是book,匹配不上而没有输出
xjh@ubuntu:~/iot/tmp$我们也可以用组合锚点(^与$组合使用),来寻找包含特定文本模式的数据行。
xjh@ubuntu:~/iot/tmp$ cat data.txt
this is a test of using both anchors
I said this is a test
this is a test
I am sure this is a test
xjh@ubuntu:~/iot/tmp$ sed -n '/^this test$/p' data.txt
xjh@ubuntu:~/iot/tmp$ sed -n '/^this is a test$/p' data.txt
this is a test
xjh@ubuntu:~/iot/tmp$下面是利用组合锚点并结合删除命令d,来删除文档中空白行的例子。
xjh@ubuntu:~/iot/tmp$ cat data.txt
I said this is a test#这里有一行空行
I am sure this is a test
xjh@ubuntu:~/iot/tmp$ sed '/^$/d' data.txt
I said this is a test
I am sure this is a test
xjh@ubuntu:~/iot/tmp$4、点号字符
点号字符是上面第2点写到的特殊字符的其中一种,它用来匹配任意单个字符(除了换行符之外)。值得注意的是,点号必须要匹配一个字符,如果在点号的位置没有字符,则就不符合该模式。
xjh@ubuntu:~/iot/tmp$ cat data1.txt
This is a test of a line.
The cat is sleeping.
That is a very nice hat.
This test is at line four. #at前面是空格,它也是一个字符,因此匹配的上
at ten o'clock we'll go home. #at前面没有任何字符,因此不匹配
xjh@ubuntu:~/iot/tmp$ sed -n '/.at/p' data1.txt
The cat is sleeping.
That is a very nice hat.
This test is at line four.
xjh@ubuntu:~/iot/tmp$5、字符组
上面的点符号表示匹配任意字符。如果想要限定待匹配的具体字符范围(也就是说,模板给出了一组字符,待匹配的数据无论出现这组字符中的哪一个字符,都算匹配上),该如何表示呢?
可以用方括号[ ]来定义一组字符。
xjh@ubuntu:~/iot/tmp$ cat data1.txt
This is a test of a line.
The cat is sleeping.
That is a very nice hat.
This test is at line four.
at ten o'clock we'll go home.
xjh@ubuntu:~/iot/tmp$ sed -n '/[ch]at/p' data1.txt
The cat is sleeping.
That is a very nice hat.
xjh@ubuntu:~/iot/tmp$ echo "Yes" | sed -n '/[Yy]es/p'
Yes
xjh@ubuntu:~/iot/tmp$ echo "yes" | sed -n '/[Yy]es/p'
yes
xjh@ubuntu:~/iot/tmp$ echo "yes" | sed -n '/[Yy][Ee][Ss]/p'
yes
xjh@ubuntu:~/iot/tmp$ echo "yEs" | sed -n '/[Yy][Ee][Ss]/p'
yEs
xjh@ubuntu:~/iot/tmp$ echo "yES" | sed -n '/[Yy][Ee][Ss]/p'
yES
xjh@ubuntu:~/iot/tmp$ echo "ABCDyesEFG" | sed -n '/[Yy][Ee][Ss]/p'
ABCDyesEFG
xjh@ubuntu:~/iot/tmp$注意,正则表达式可以匹配数据流文本的任何位置,行首、行尾或者行中。这意味着,与正则表达式匹配的数据所在的行,它的内容刚好就是正则表达式匹配到的内容,但更多的情形,是正则表达式匹配到的内容,只是一行内容中的某个部分。如果要限定匹配的位置、匹配的字符数,则需要用到锚字符^与$,比如明确匹配6位的邮政编码、11位的电话号码等等。
xjh@ubuntu:~/iot/tmp$ cat data.txt
60644
24533
xjh34234is
588978
380
6738546
267385hutu
xjh@ubuntu:~/iot/tmp$ sed -n '
> /[0123456789][0123456789][0123456789][0123456789][0123456789]/p
> ' data.txt #这种写法下,只有380不符合
60644
24533
xjh34234is
588978
6738546
267385hutu
xjh@ubuntu:~/iot/tmp$ sed -n '
> /^[0123456789][0123456789][0123456789][0123456789][0123456789]$/p
> ' data.txt #这种写法,限定了开头与结尾的内容,并显示了匹配的字符数目为5个
60644
24533
xjh@ubuntu:~/iot/tmp$6、排除型字符组
如果使用排除型字符组会,在进行匹配时,会匹配(排除型字符组中的字符之外的)任意字符。
排除型字符组必须要匹配一个字符,如果在排除型字符组的位置没有字符,就不符合该模式。
排除型字符组的用法,是在字符组的方括号里面,在字符组前面加一个脱字符。
xjh@ubuntu:~/iot/tmp$ cat data1.txt
This is a test of a line.
The cat is sleeping.
That is a very nice hat.
This test is at line four.
at ten o'clock we'll go home.
xjh@ubuntu:~/iot/tmp$ sed -n '/[^ch]at/p' data1.txt
This test is at line four.
xjh@ubuntu:~/iot/tmp$7、区间
可以用单破折号在字符组中表示字符区间。只需要指定区间的第一个字符、单破折号以及区间的最后一个字符就行了。
这个方式可以用来定义数字区间,也可以用来定义字母区间,还可以定义不连续的区间。
xjh@ubuntu:~/iot/tmp$ cat data.txt
60644
24533
xjh34234is
588978
380
6738546
267385hutu
xjh@ubuntu:~/iot/tmp$ sed -n '
> /^[0-9][0-9][0-9][0-9][0-9]$/p
> ' data.txt
60644
24533
xjh@ubuntu:~/iot/tmp$ cat data1.txt
This is a test of a line.
The cat is sleeping.
That is a very nice hat.
This test is at line four.
at ten o'clock we'll go home.
xjh@ubuntu:~/iot/tmp$ sed -n '/[c-h]at/p' data1.txt
The cat is sleeping.
That is a very nice hat.
xjh@ubuntu:~/iot/tmp$ sed -n '/[a-ch-m]at/p' data1.txt
The cat is sleeping.
That is a very nice hat.
xjh@ubuntu:~/iot/tmp$ 8、特殊的字符组
除了定义自己的字符组,BRE还包括一些特殊的字符组,用来匹配特定类型的字符。
| 字符组 | 描述 |
| [[:alpha:]] | 匹配任意字母字符,无论大小写 |
| [[:alnum:]] | 匹配任意字母数字字符0~9、A~Z、a~z |
| [[:blank:]] | 匹配空格或制表符 |
| [[:digit:]] | 匹配0~9之间的数字 |
| [[:lower:]] | 匹配小写字母a~z |
| [[:upper:]] | 匹配大写字母A~Z |
| [[:print:]] | 匹配任意可打印字符 |
| [[:punct:]] | 匹配标点符号 |
| [[:space:]] | 匹配任意空白字符:空格、制表符、NL、FF、VT、CR |
xjh@ubuntu:~/iot/tmp$ echo "abc" | sed -n '/[[:digit:]]/p'
xjh@ubuntu:~/iot/tmp$ echo "abc" | sed -n '/[[:alpha:]]/p'
abc
xjh@ubuntu:~/iot/tmp$ echo "abc123" | sed -n '/[[:digit:]]/p'
abc123
xjh@ubuntu:~/iot/tmp$ echo "this is , a test" | sed -n '/[[:punct:]]/p'
this is , a test
xjh@ubuntu:~/iot/tmp$ 9、星号
正则表达式中,在某个字符后面添加星号,则表示这个字符必须在与正则表达式匹配的文本中出现0次或者多次,也就是说,可以没有这个字符,也可以有一个这个字符或者多个这字符。
这个正则表达式一般用在有常见拼写错误或者在不同语言中有拼写变化的单词。
xjh@ubuntu:~/iot/tmp$ echo "the color is beautiful" | sed -n '/colou*r/p'
the color is beautiful
xjh@ubuntu:~/iot/tmp$ echo "the colour is beautiful" | sed -n '/colou*r/p'
the colour is beautiful
xjh@ubuntu:~/iot/tmp$另外,将点号与星号组合起来,可以匹配任意数量的任意字符。
xjh@ubuntu:~/iot/tmp$ echo "thisi is a regular pattern expression"|sed -n '
> /regula.*ession/p'
thisi is a regular pattern expression
xjh@ubuntu:~/iot/tmp$星号也可以用在字符组上,如下所示。
xjh@ubuntu:~/iot/tmp$ echo "bt" | sed -n '/b[ae]*t/p'
bt
xjh@ubuntu:~/iot/tmp$ echo "bat" | sed -n '/b[ae]*t/p'
bat
xjh@ubuntu:~/iot/tmp$ echo "bet" | sed -n '/b[ae]*t/p'
bet
xjh@ubuntu:~/iot/tmp$ echo "beat" | sed -n '/b[ae]*t/p'
beat
xjh@ubuntu:~/iot/tmp$ echo "bekat" | sed -n '/b[ae]*t/p'
xjh@ubuntu:~/iot/tmp$ 三、ERE引擎下正则表达式的写法
因为sed编辑器不支持ERE引擎的正则表达式的写法,因此接下来的内容不会出现sed命令。
gawk同时支持BRE引擎与ERE引擎,因此上面第二节的内容,也可以用在gawk命令中。
1、问号
问号的作用有点类似星号,但问号表示前面的内容可以出现0次或者1次,不能匹配多次。
另外可以将问号与字符组一起使用。
xjh@ubuntu:~/iot/tmp$ echo "bt" | gawk '/be?t/{print $0}'
bt
xjh@ubuntu:~/iot/tmp$ echo "bet" | gawk '/be?t/{print $0}'
bet
xjh@ubuntu:~/iot/tmp$ echo "beet" | gawk '/be?t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "beeet" | gawk '/be?t/{print $0}'
xjh@ubuntu:~/iot/tmp$xjh@ubuntu:~/iot/tmp$ echo "bt" | gawk '/b[ea]?t/{print $0}'
bt
xjh@ubuntu:~/iot/tmp$ echo "bet" | gawk '/b[ea]?t/{print $0}'
bet
xjh@ubuntu:~/iot/tmp$ echo "bat" | gawk '/b[ea]?t/{print $0}'
bat
xjh@ubuntu:~/iot/tmp$ echo "beat" | gawk '/b[ea]?t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bot" | gawk '/b[ea]?t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "beet" | gawk '/b[ea]?t/{print $0}'
xjh@ubuntu:~/iot/tmp$2、加号
加号的作用与星号类似,但加号表示前面的字符可以出现1次或者多次,但至少出现1次。如果该字符没有出现,则不符合该模式。
另外可以将加号与字符组一起使用。
xjh@ubuntu:~/iot/tmp$ echo "beeet" | gawk '/be+t/{print $0}'
beeet
xjh@ubuntu:~/iot/tmp$ echo "beet" | gawk '/be+t/{print $0}'
beet
xjh@ubuntu:~/iot/tmp$ echo "bet" | gawk '/be+t/{print $0}'
bet
xjh@ubuntu:~/iot/tmp$ echo "bt" | gawk '/be+t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bt" | gawk '/b[ae]+t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bat" | gawk '/b[ae]+t/{print $0}'
bat
xjh@ubuntu:~/iot/tmp$ echo "bet" | gawk '/b[ae]+t/{print $0}'
bet
xjh@ubuntu:~/iot/tmp$ echo "baet" | gawk '/b[ae]+t/{print $0}'
baet
xjh@ubuntu:~/iot/tmp$ echo "beat" | gawk '/b[ae]+t/{print $0}'
beat
xjh@ubuntu:~/iot/tmp$ echo "beeeaeat" | gawk '/b[ae]+t/{print $0}'
beeeaeat
xjh@ubuntu:~/iot/tmp$ echo "beedeaeat" | gawk '/b[ae]+t/{print $0}'
xjh@ubuntu:~/iot/tmp$3、花括号
在正则表达式中,可以在某字符之后使用花括号{ },表示匹这个字符出现次数的上下限。
可以用两种方式表示上下限区间:{m},字符准确出现m次;{m,n},字符至少出现m次,至多出现n次。
使用gawk时,要添加选项“--re-interval”。
另外,花括号可以与字符组一起使用。
xjh@ubuntu:~/iot/tmp$ echo "bt" | gawk --re-interval '/be{1}t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bet" | gawk --re-interval '/be{1}t/{print $0}'
bet
xjh@ubuntu:~/iot/tmp$ echo "beet" | gawk --re-interval '/be{1}t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bt" | gawk --re-interval '/be{1,2}t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bet" | gawk --re-interval '/be{1,2}t/{print $0}'
bet
xjh@ubuntu:~/iot/tmp$ echo "beet" | gawk --re-interval '/be{1,2}t/{print $0}'
beet
xjh@ubuntu:~/iot/tmp$ echo "beeet" | gawk --re-interval '/be{1,2}t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bt" | gawk --re-interval '/b[ae]{1,2}t/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bat" | gawk --re-interval '/b[ae]{1,2}t/{print $0}'
bat
xjh@ubuntu:~/iot/tmp$ echo "bet" | gawk --re-interval '/b[ae]{1,2}t/{print $0}'
bet
xjh@ubuntu:~/iot/tmp$ echo "baet" | gawk --re-interval '/b[ae]{1,2}t/{print $0}'
baet
xjh@ubuntu:~/iot/tmp$ echo "beat" | gawk --re-interval '/b[ae]{1,2}t/{print $0}'
beat
xjh@ubuntu:~/iot/tmp$ echo "beeat" | gawk --re-interval '/b[ae]{1,2}t/{print $0}'
xjh@ubuntu:~/iot/tmp$4、管道符号
可以用管道符号|连接两个或者多个正则表达式,只要任何一个正则表达式与数据流匹配,则说明匹配成功,如果所有正则表达式与数据流都不匹配,则说明匹配失败。
注意,正则表达式与管道符号之间不能有空格,否则空格也会被看做是正则表达式的一部分。
xjh@ubuntu:~/iot/tmp$ echo "the cat is asleep" | gawk '/cat|dog/{print $0}'
the cat is asleep
xjh@ubuntu:~/iot/tmp$ echo "the dog is asleep" | gawk '/cat|dog/{print $0}'
the dog is asleep
xjh@ubuntu:~/iot/tmp$ echo "the sheep is asleep" | gawk '/cat|dog/{print $0}'
xjh@ubuntu:~/iot/tmp$5、表达式分组
用括号将内容包围起来,表示一组,这一组就相当于一个普通的字符。
此时可以给该组使用特殊字符,比如问号(上面写到,问号表示该字符至多出现1次),表示这组至多出现1次。
将分组与管道符号组合起来创建正则表达式,是很常见的用法。分组表示一个字符(所以用到括号),但这个字符可以用两个正则表达式产生(所以用到管道)。
xjh@ubuntu:~/iot/tmp$ echo "Sat" | gawk '/Sat(urday)?/{print $0}'
Sat
xjh@ubuntu:~/iot/tmp$ echo "Saturday" | gawk '/Sat(urday)?/{print $0}'
Saturday
xjh@ubuntu:~/iot/tmp$ echo "Saturdayhhh" | gawk '/Sat(urday)?/{print $0}'
Saturdayhhh
xjh@ubuntu:~/iot/tmp$ echo "Saturdayurday" | gawk '/Sat(urday)?/{print $0}'
Saturdayurday #这里居然可以输出?xjh@ubuntu:~/iot/tmp$ #将分组与管道符号组合起来创建正则表达式,是很常见的用法。
xjh@ubuntu:~/iot/tmp$ echo "cat" | gawk '/(c|b)a(b|t)/{print $0}'
cat
xjh@ubuntu:~/iot/tmp$ echo "cab" | gawk '/(c|b)a(b|t)/{print $0}'
cab
xjh@ubuntu:~/iot/tmp$ echo "bat" | gawk '/(c|b)a(b|t)/{print $0}'
bat
xjh@ubuntu:~/iot/tmp$ echo "bab" | gawk '/(c|b)a(b|t)/{print $0}'
bab
xjh@ubuntu:~/iot/tmp$ echo "tab" | gawk '/(c|b)a(b|t)/{print $0}'
xjh@ubuntu:~/iot/tmp$ echo "bac" | gawk '/(c|b)a(b|t)/{print $0}'
xjh@ubuntu:~/iot/tmp$四、正则表达式的实战
见本人博客《shell编程100例》相关部分。
相关文章:

关于正则表达式的讲解
以下内容源于《linux命令行与shell脚本编程大全【第三版】》一书的整理。 在shell脚本中成功运用sed编辑器和gawk程序的关键,在于熟练地使用正则表达式。 一、正则表达式的简介 1、正则表达式的定义 正则表达式(regular expression)是一个…...

贝塞尔曲线与B样条曲线
文章目录0.参考1.问题起源与插值法的曲线拟合1.1.问题起源1.2.拉格朗日插值1.3.“基”的概念1.4.插值存在的Runge现象2.贝塞尔曲线2.1.控制点的思想2.2.由控制点生成贝塞尔曲线2.3.多个控制点时的贝塞尔曲线公式2.4.贝塞尔曲线的递推公式2.5.贝塞尔曲线的性质3.B样条曲线3.1.B样…...

C语言-基础了解-24-C头文件
C头文件 一、C 头文件 头文件是扩展名为 .h 的文件,包含了 C 函数声明和宏定义,被多个源文件中引用共享。有两种类型的头文件:程序员编写的头文件和编译器自带的头文件。 在程序中要使用头文件,需要使用 C 预处理指令 #include…...
The 19th Zhejiang Provincial Collegiate Programming Contest vp
和队友冲了这场,极限6题,重罚时铁首怎么说,前面的A题我贡献了太多的罚时,然后我的G题最短路调了一万年,因为太久没写了,甚至把队列打成了优先队列,没把head数组清空完全,都是我的锅呜…...

用于<分类>的卷积神经网络、样本不平衡问题的解决
输入图像——卷积层——池化层——全连接层——输出 卷积层:核心,用来提取特征。 池化层:对特征降维。实际的主要作用是下采样,减少参数量来提高计算速度。 卷积神经网络的训练:前向传播(分类识别…...
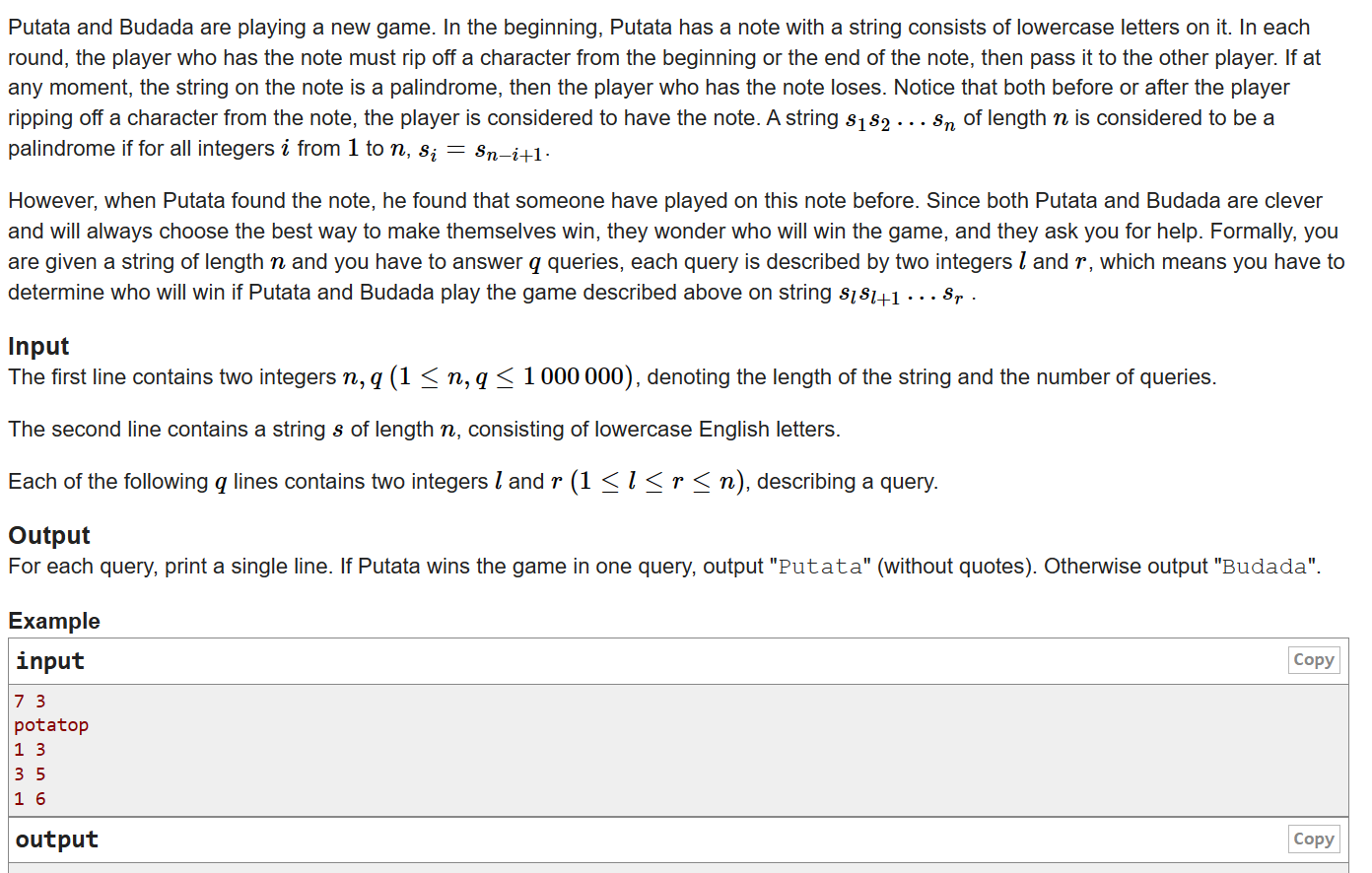
网上订餐管理系统的设计与实现
技术:Java、JSP等摘要:随着信息技术的广泛使用,电子商务对于提高管理和服务水平发挥着关键的作用。越来越多的商家开始着手于电子商务建设。电子商务的发展为人们的生活提供了极大的便利,也成为现实社会到网络社会的真实体现。当今…...

Httpclient测试
在IDEA中有一个非常方便的http接口测试工具httpclient,下边介绍它的使用方法,后边我们会用它进行接口测试。如果IDEA版本较低没有自带httpclient,需要安装httpclient插件1.插件2.controller进入controller类,找到http接口对应的方…...
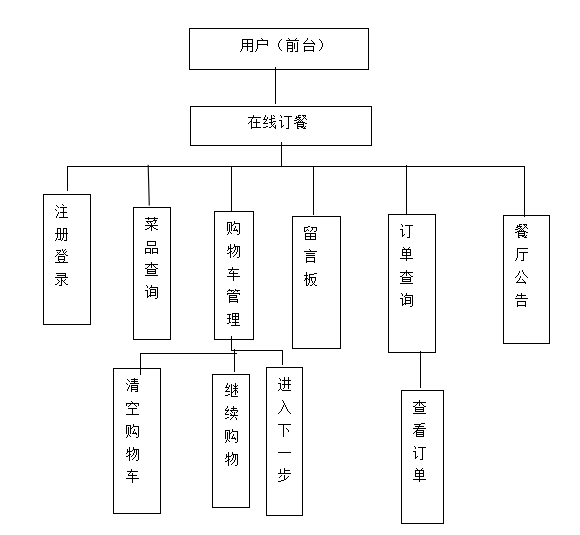
EXCEL里的各种奇怪计算问题:数字后面自动多了 0.0001, 数字后面位数变成000,以及一些取整,数学函数
1 公式计算后的数,用只粘贴数值后,后面自动多了 0.0001,导致不再是整数的问题 问题入戏 见第1个8400,计算时就出现了问题,按正常,这里8400应该是整数,而不应该带小数,但是确实就计…...

PHP CRUL请求GET、POST
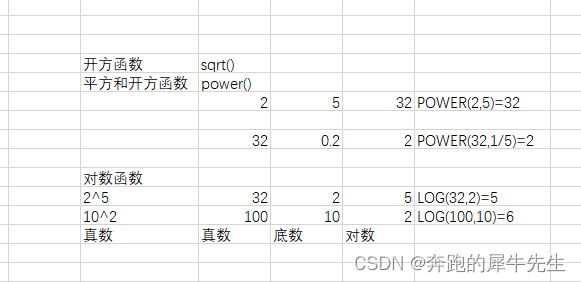
// GET请求 public function curlGet($url,$header){ $ch curl_init(); curl_setopt($ch, CURLOPT_HTTPHEADER, $header); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE); curl_s…...

Oracle技术分享 exp导数据时报错ORA-01578 ORA-01110
问题描述:exp导数据时报错ORA-01578 ORA-01110,如下所示: 数据库:oracle 19.12 多租户 1、异常重现 [oracledbserver ~]$ exp ora1/ora1orclpdbfileemp.dmp tablesemp logexp.log Export: Release 19.0.0.0.0 - Production onS…...
Maven学习笔记
目录1 概述1.1 Maven是什么1.2 作用1.2.1 构建1.3 jar包是什么2 下载及配置2.1 下载2.2 配置环境变量3 基本概念3.1 仓库3.2 坐标3.2.1 概念3.2.2 如何获取指定jar包的坐标3.3 项目结构3.3.1 普通java项目的目录结构3.3.2 java web项目的目录结构3.4 项目构建命令4 IDEA中创建M…...
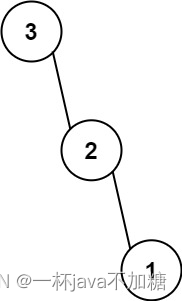
654. 最大二叉树
题目 leetcode题目地址 给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值。 递归地在最大值 左边 的 子数组前缀上 构建左子树。 递归地在最大值 右边 的 子数组后缀上 构建右子树。 返…...
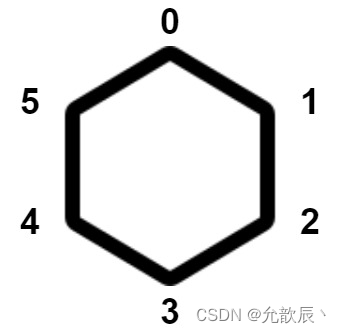
快速幂----快速求解底数的n次幂
目录 一.快速幂 1.问题的引入 2.快速幂的介绍 3.核心思想 4.代码实现 2.猴子碰撞的方法数 1.题目描述 2.问题分析 3.代码实现 一.快速幂 1.问题的引入 问题:求解num的n次幂,结果需要求余7 对于这个问题我们可能就是直接调用函数pow(a,b)来直接求解a的b次幂问题,但是如果…...
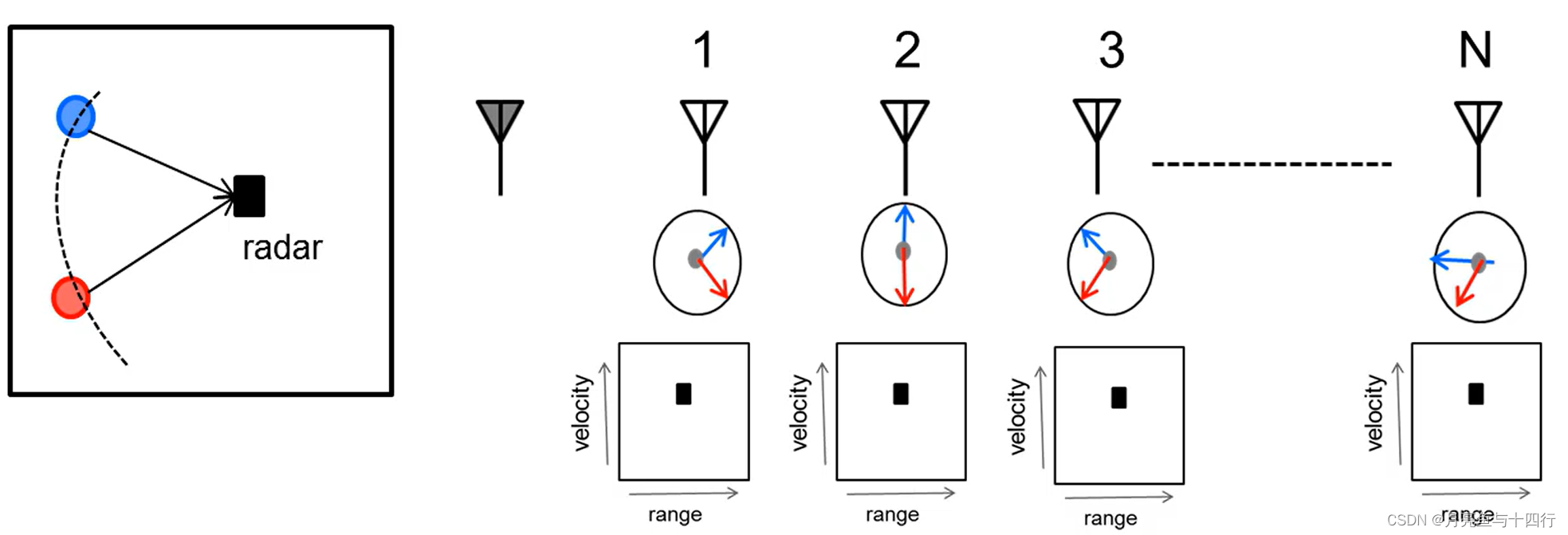
【FMCW 04】测角-Angle FFT
在之前的文章中,我们已经详尽讨论过FMCW雷达测距和测速的原理,现在来讲最后一块内容,测角。测角对于硬件设备具有要求,即要求雷达具有多发多收结构,从而形成多个空间信道(channel),我…...

Linux操作系统学习(线程同步)
文章目录线程同步条件变量生产者与消费者模型信号量环形队列应用生产者消费者模型线程同步 现实生活中我们经常会遇到同一个资源多个人都想使用的问题,例如游乐园过山车排队,玩完的游客还想再玩,最好的办法就是玩完的游客想再玩就去重新排…...

了解动态规划算法:原理、实现和优化指南
动态规划 详细介绍例子斐波那契数列最长回文子串优化指南优化思路斐波那契数列优化最长回文子串优化详细介绍 动态规划(Dynamic Programming,简称 DP)是一种通过将原问题拆分成子问题并分别求解这些子问题来解决复杂问题的算法思想。 它通常用于求解优化问题,它的核心思想…...

《NFL橄榄球》:明尼苏达维京人·橄榄1号位
明尼苏达维京人(英语:Minnesota Vikings)是一支职业美式足球球队,位于明尼苏达州的明尼阿波利斯。他们现时在国家橄榄球联合会北区参与国家美式足球联盟比赛。该球队本为美国美式足球联盟(AFL)的球队。但是…...
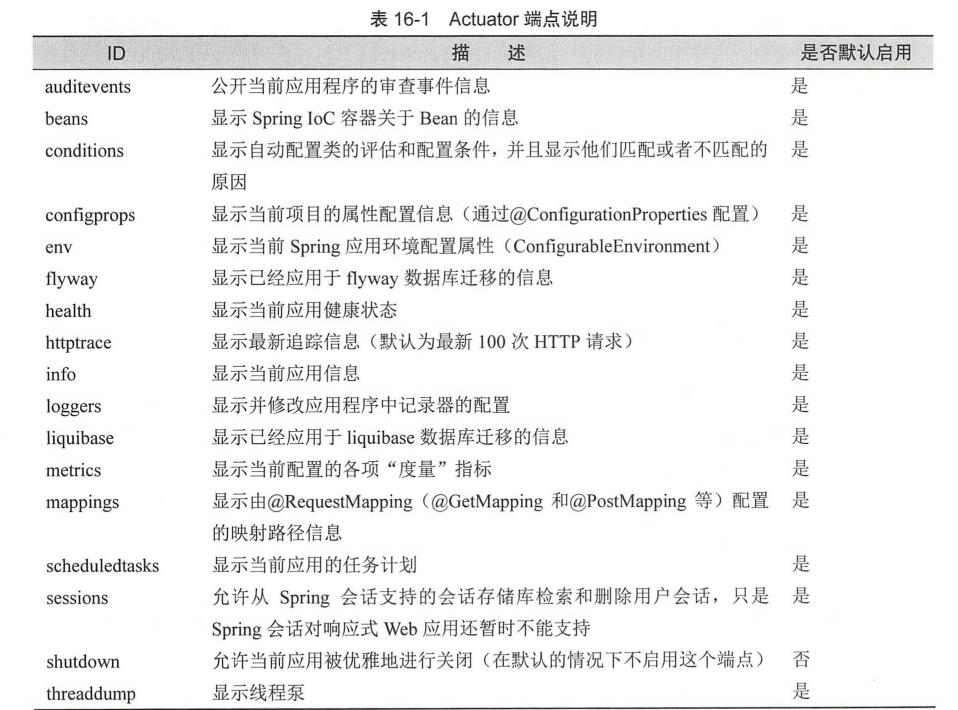
sheng的学习笔记-Actuator健康监控
前言在微服务系统里,对微服务程序的运行状况的跟踪和监控是必不可少的;例如GPE,TelegrafinfluxDB都提供了微服务体系监控的方案, ZIPKIN, Skywalking都提供了微服务云体系的APM的方案; 这些解决方案功能全面…...

初次使用ESP32-CAM记录
模块的配置和图片 摄像头:8225N V2.0 171026 模块esp-32s 参考资料:https://docs.ai-thinker.com/esp32 配置环境 参考:https://blog.csdn.net/weixin_43794311/article/details/128622558 简单使用需要注意的地方 基本的环境配置和串口…...
)
华为OD机试真题Python实现【最长连续交替方波信号】真题+解题思路+代码(20222023)
最长连续交替方波信号 题目 输入一串方波信号,求取最长的完全连续交替方波信号,并将其输出, 如果有相同长度的交替方波信号,输出任一即可,方波信号高位用1标识,低位用0标识 如图: 说明: 一个完整的信号一定以0开始然后以0结尾, 即 010 是一个完整的信号,但101,101…...

开源灵巧手OpenClaw:从机械设计到AI抓取的完整实现指南
1. 项目概述:当开源机械爪遇上AI大脑 最近在机器人开源社区里,一个名为“OpenClaw”的项目引起了我的注意。这个由Turbo Labs团队发布的项目,其核心目标非常明确:打造一个低成本、高性能、且完全开源的机器人灵巧手(或…...
)
从DC到DCG:手把手教你搭建物理感知综合流程(含DEF文件处理避坑指南)
从DC到DCG:物理感知综合全流程实战指南 在28nm以下工艺节点,传统逻辑综合工具已难以应对复杂的物理效应。我们团队在最近一次5nm芯片项目中,由于初期忽视物理感知综合的约束设置,导致时序收敛多耗费三周时间。本文将分享从Design …...

如何在Linux上快速配置开源打印机驱动:foo2zjs完整实用指南
如何在Linux上快速配置开源打印机驱动:foo2zjs完整实用指南 【免费下载链接】foo2zjs A linux printer driver for QPDL protocol - copy of http://foo2zjs.rkkda.com/ 项目地址: https://gitcode.com/gh_mirrors/fo/foo2zjs 在Linux系统中遇到打印机兼容性…...

AI工作流引擎设计:从Prompt工程到可编程组件的系统化实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫jmagly/aiwg。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它其实是一个关于“AI写作指南”或“AI工作流生成器”的雏形。这类项目在当前AI应用爆发…...

如何轻松解包网易游戏资源:unnpk工具完整使用指南
如何轻松解包网易游戏资源:unnpk工具完整使用指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否曾好奇网易热门游戏如《阴阳师》、《魔法禁书目录》中…...

kill-doc文档下载工具终极指南:轻松获取30+平台免费文档资源
kill-doc文档下载工具终极指南:轻松获取30平台免费文档资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是…...

开源漏洞情报自动化分诊系统:从数据采集到智能响应的工程实践
1. 项目概述:一个为开源安全情报而生的“智能爪子”如果你和我一样,长期混迹在开源软件和网络安全社区,那你一定对“漏洞情报”这个词不陌生。每天,成千上万的开源项目在更新,新的漏洞(CVE)在发…...

电机选型与控制实战指南:从直流、步进到伺服电机
1. 电机选型:从理解需求开始选电机,听起来像是硬件工程师或者资深创客的活儿,但只要你玩过Arduino小车、做过3D打印机,或者想给家里的模型加个能动的部件,这事儿就绕不开。我刚开始接触项目时,也犯过迷糊&a…...

AI代理环境交互SDK:TypeScript实现标准化观察与动作接口
1. 项目概述:一个为AI代理构建交互式环境的TypeScript SDK如果你正在尝试构建一个能够与现实世界应用(比如浏览器、IDE、甚至操作系统)进行交互的AI代理,那么你很可能已经遇到了一个核心难题:如何让代理“看见”并“操…...

【C++ AI 大模型接入 SDK】 - 环境搭建
大家好,我是Halcyon.平安 欢迎文末添加好友交流,共同进步! 一、更新软件源二、安装编译工具链三、安装 JsonCpp四、安装 SQLite3五、安装 OpenSSL 开发库六、安装 spdlog 日志库七、安装 gflags八、获取 cpp-httplib九、安装 fmt 库十、依赖总…...