NVIDIA NCCL 源码学习(十三)- IB SHARP
背景
之前我们看到了基于ring和tree的两种allreduce算法,对于ring allreduce,一块数据在reduce scatter阶段需要经过所有的rank,allgather阶段又需要经过所有rank;对于tree allreduce,一块数据数据在reduce阶段要上行直到根节点,在broadcast阶段再下行回来,整个流程比较长。
SHARP
因此基于这一点,mellanox提出了SHARP,将计算offload到了IB switch,每个节点只需要发送一次数据,这块数据会被交换机完成规约,然后每个节点再接收一次就得到了完整结果。
如图1展示了一个胖树物理网络拓扑,其中绿色节点为交换机,黄色节点的为host。
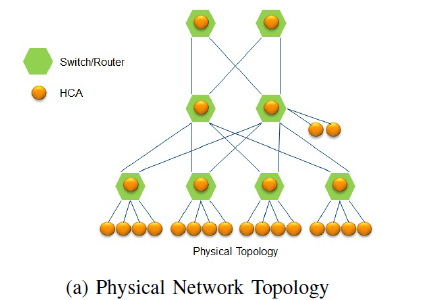
图 1
图2展示了基于图1的物理网络拓扑,这些host节点执行SHARP初始化后得到的SHARP tree,SHARP tree是个逻辑概念,并不要求物理拓扑一定是胖树。
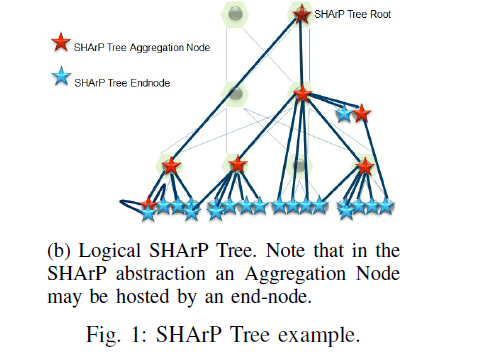
图 2
值得注意的是:
- 其中一个交换机可以位于最多64个SHARP tree中,
- 一个SHARP tree可以建立大量的group,group指的是基于现有的host创建的一个子集
- 支持数百个集合通信api的并发执行
整体流程
本篇还是基于2.7.8介绍,类似tree allreduce,机内仍然是个chain,以两机为例,数据的发送按照图3箭头的方向运行,交换机计算出完整结果后再按照箭头反方向流动。
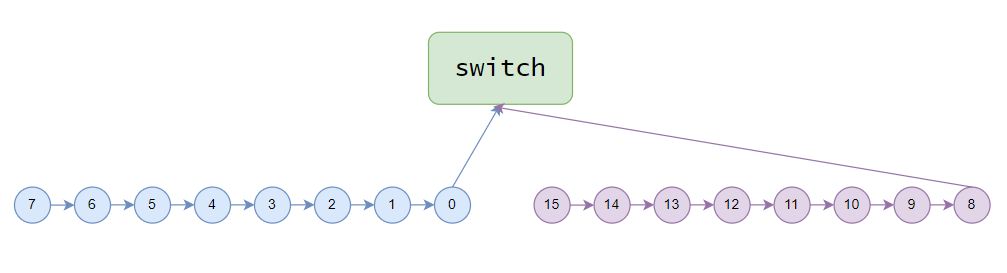
初始化
运行IB SHARP依赖libnccl-net.so,这个代码开源在https://github.com/Mellanox/nccl-rdma-sharp-plugins,本篇基于v2.0.1介绍。
nccl完成bootstrap网络的初始化后,开始初始化数据网络
ncclResult_t initNetPlugin(ncclNet_t** net, ncclCollNet_t** collnet) {void* netPluginLib = dlopen("libnccl-net.so", RTLD_NOW | RTLD_LOCAL);...ncclNet_t* extNet = (ncclNet_t*) dlsym(netPluginLib, STR(NCCL_PLUGIN_SYMBOL));if (extNet == NULL) {INFO(NCCL_INIT|NCCL_NET, "NET/Plugin: Failed to find " STR(NCCL_PLUGIN_SYMBOL) " symbol.");} else if (initNet(extNet) == ncclSuccess) {*net = extNet;ncclCollNet_t* extCollNet = (ncclCollNet_t*) dlsym(netPluginLib, STR(NCCL_COLLNET_PLUGIN_SYMBOL));if (extCollNet == NULL) {INFO(NCCL_INIT|NCCL_NET, "NET/Plugin: Failed to find " STR(NCCL_COLLNET_PLUGIN_SYMBOL) " symbol.");} else if (initCollNet(extCollNet) == ncclSuccess) {*collnet = extCollNet;} return ncclSuccess;}if (netPluginLib != NULL) dlclose(netPluginLib);return ncclSuccess;
}
首先dlopen libnccl-net.so,其中NCCL_PLUGIN_SYMBOL为ncclNetPlugin_v3,NCCL_COLLNET_PLUGIN_SYMBOL为ncclCollNetPlugin_v3,所以就是获取符号ncclNetPlugin_v3赋值给extNet ,获取符号ncclCollNetPlugin_v3赋值给extCollNet。extNet和extCollNet的关系有点像nccl的bootstrap网络和数据网络的关系,extCollNet负责实际数据的通信,元信息,控制信息之类的是通过extNet执行交换的。
然后执行extNet的初始化,extNet支持ib,ucx等多种后端,我们用的是ib,因此之后所有的执行其实都是针对的ibPlugin,ibPlugin的逻辑和nccl的ncclNetIb逻辑很像,初始化即ncclIbInit,就是枚举当前机器所有的网卡,保存到全局数组中。
然后执行initCollNet,即ncclSharpInit,其实也是执行ibPlugin的初始化,之前已经执行过了,所以这里什么也不做。
图搜索
struct ncclTopoGraph collNetGraph;collNetGraph.id = 2; collNetGraph.pattern = NCCL_TOPO_PATTERN_TREE;collNetGraph.collNet = 1; collNetGraph.crossNic = ncclParamCrossNic();collNetGraph.minChannels = collNetGraph.maxChannels = ringGraph.nChannels;NCCLCHECK(ncclTopoCompute(comm->topo, &collNetGraph));
pattern为NCCL_TOPO_PATTERN_TREE,因此机内仍然是ring,不过和NCCL_TOPO_PATTERN_SPLIT_TREE不同的地方在于NCCL_TOPO_PATTERN_TREE的第0个gpu会同时执行网卡的收发,假设搜出来的channel如下:
NET/0 GPU/0 GPU/1 GPU/2 GPU/3 GPU/4 GPU/5 GPU/6 GPU/7 NET/0
channel连接
图搜索完成之后,就开始channel的连接,即记录当前节点的相邻节点
ncclResult_t ncclTopoPreset(struct ncclComm* comm,struct ncclTopoGraph* treeGraph, struct ncclTopoGraph* ringGraph, struct ncclTopoGraph* collNetGraph,struct ncclTopoRanks* topoRanks) {int rank = comm->rank;int localRanks = comm->localRanks;int nChannels = comm->nChannels;for (int c=0; c<nChannels; c++) {struct ncclChannel* channel = comm->channels+c;int* collNetIntra = collNetGraph->intra+c*localRanks;for (int i=0; i<localRanks; i++) {if (collNetIntra[i] == rank) {int prev = (i-1+localRanks)%localRanks, next = (i+1)%localRanks;channel->collTreeDn.up = collNetIntra[prev];channel->collTreeDn.down[0] = collNetIntra[next];channel->collTreeUp.down[0] = channel->collTreeDn.down[0];channel->collTreeUp.up = channel->collTreeDn.up;}}}// Duplicate channels rings/treesstruct ncclChannel* channel0 = comm->channels;struct ncclChannel* channel1 = channel0+nChannels;memcpy(channel1, channel0, nChannels*sizeof(struct ncclChannel));return ncclSuccess;
}
假设一共搜索到了10个channel,那么前5个channel用于执行SHARP的上行阶段,即图三箭头方向,后边5个channel用于执行下行阶段,即箭头的反方向。所以每个channel中记录了两组连接关系,即collTreeUp和collTreeDn,前5个上行channel只会用到collTreeUp,后5个下行channel只会用到collTreeDn,但其实collTreeUp和collTreeDn完全一致,后续只介绍collTreeUp。
此时机内channel连接之后如图四所示,箭头指向的是up。
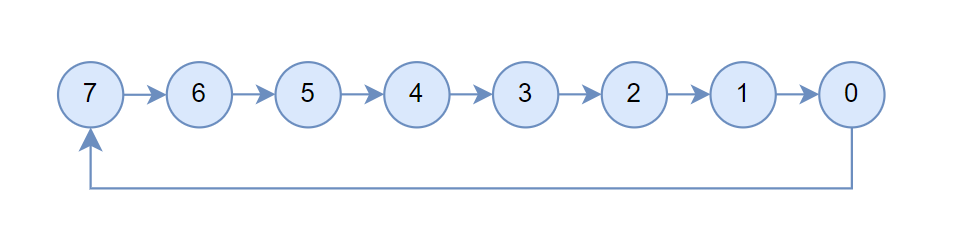
然后开始处理机间的连接,其实就是选出机内负责网络收发的rank,以发送为例,称为sendIndex,需要断掉他的机内连接,以及断掉连到sendIndex的连接。
ncclResult_t ncclTopoConnectCollNet(struct ncclComm* comm, struct ncclTopoGraph* collNetGraph, int rank) {int nranks = comm->nRanks;int depth = nranks/comm->nNodes;int sendIndex = collNetGraph->pattern == NCCL_TOPO_PATTERN_TREE ? 0 : 1; // send GPU index depends on topo patternint sendEndIndex = (sendIndex+comm->localRanks-1)%comm->localRanks;for (int c=0; c<comm->nChannels/2; c++) {struct ncclChannel* channel = comm->channels+c;// Set root of collTree to id nranksif (rank == collNetGraph->intra[sendIndex+c*comm->localRanks]) { // is masterchannel->collTreeUp.up = channel->collTreeDn.up = nranks;} if (rank == collNetGraph->intra[sendEndIndex+c*comm->localRanks]) { // is bottom of intra-node chainchannel->collTreeUp.down[0] = channel->collTreeDn.down[0] = -1; } channel->collTreeUp.depth = channel->collTreeDn.depth = depth;INFO(NCCL_GRAPH, "CollNet Channel %d rank %d up %d down %d", c, rank, channel->collTreeUp.up, channel->collTreeUp.down[0]);}int recvIndex = 0; // recv GPU index is always 0int recvEndIndex = (recvIndex+comm->localRanks-1)%comm->localRanks;for (int c=0; c<comm->nChannels/2; c++) {struct ncclChannel* channel = comm->channels+comm->nChannels/2+c;// Set root of collTree to id nranksif (rank == collNetGraph->intra[recvIndex+c*comm->localRanks]) { // is masterchannel->collTreeUp.up = channel->collTreeDn.up = nranks;} if (rank == collNetGraph->intra[recvEndIndex+c*comm->localRanks]) { // is bottom of intra-node chainchannel->collTreeUp.down[0] = channel->collTreeDn.down[0] = -1; } channel->collTreeUp.depth = channel->collTreeDn.depth = depth;INFO(NCCL_GRAPH, "CollNet Channel %d rank %d up %d down %d", comm->nChannels/2+c, rank, channel->collTreeDn.up, channel->collTreeDn.down[0]);}return ncclSuccess;
}这里选择的sendIndex就是chain中的第一个,sendEndIndex就是chain中的最后一个,因为最后一个会连接到sendIndex,所以要断掉这俩的连接,然后遍历上行channel,将sendIndex的up设置为nranks,将sendEndIndex的down设置为-1,同理对下行channel。此时channel如图五所示:

通信链接的建立
然后开始建立机内和机间的通信链接。
if (comm->nNodes > 1 && ncclParamCollNetEnable() == 1 && collNetSupport() && collNetGraph.nChannels) {int logicChannels = comm->nChannels/2;int collNetSetupFail = 0; const int recvIndex = 0; // recv GPU index is always 0const int sendIndex = collNetGraph.pattern == NCCL_TOPO_PATTERN_TREE ? 0 : 1; // send GPU index depends on topo patternfor (int c=0; c<logicChannels; c++) {struct ncclChannel* channelRecv = comm->channels+logicChannels+c;struct ncclChannel* channelSend = comm->channels+c;NCCLCHECK(ncclTransportP2pSetup(comm, &collNetGraph, channelRecv, 1, &channelRecv->collTreeDn.up, 1, channelRecv->collTreeDn.down));NCCLCHECK(ncclTransportP2pSetup(comm, &collNetGraph, channelSend, 1, channelSend->collTreeUp.down, 1, &channelSend->collTreeUp.up));const int recvMaster = collNetGraph.intra[c*comm->localRanks+recvIndex];const int sendMaster = collNetGraph.intra[c*comm->localRanks+sendIndex];if (collNetSetup(comm, &collNetGraph, channelRecv, rank, nranks, recvMaster, sendMaster, comm->nNodes, 1) != 1)collNetSetupFail = 1; else if (collNetSetup(comm, &collNetGraph, channelSend, rank, nranks, sendMaster, recvMaster, comm->nNodes, 0) != 1)collNetSetupFail = 1; } // Verify CollNet setup across ranksNCCLCHECK(checkCollNetSetup(comm, rank, collNetSetupFail));}以上行channel为例,即channelSend,通过ncclTransportP2pSetup建立机内的连接,由于sendIndex和sendEndIndex的up/down被设置为了nranks或-1,所以只会建立起图五中箭头所示的连接。
然后开始建立机间的通信链接,每个机器上的第一个rank负责网络收发,这个rank称为这个节点的master,然后开始建立sharp通信组,sharp通信组只包含了每个节点的master。
static int collNetSetup(struct ncclComm* comm, struct ncclTopoGraph* collNetGraph, struct ncclChannel* channel, int rank, int nranks, int masterRank, int masterPeer, int nMasters, int type) {int rankInCollNet = -1;int supported = 0;int isMaster = (rank == masterRank) ? 1 : 0;struct {int collNetRank;ncclConnect connect;} sendrecvExchange;// check if we can connect to collnet, whose root is the nranks-th rankstruct ncclPeerInfo *myInfo = comm->peerInfo+rank, *peerInfo = comm->peerInfo+nranks;peerInfo->rank = nranks;int ret = 1;if (isMaster) {NCCLCHECK(collNetTransport.canConnect(&ret, comm->topo, collNetGraph, myInfo, peerInfo));}// send master receives connect info from peer recv master...// selectstruct ncclPeer* root = channel->peers+nranks;struct ncclConnector* conn = (type == 1) ? &root->recv : &root->send;struct ncclTransportComm* transportComm = (type == 1) ? &(collNetTransport.recv) : &(collNetTransport.send);conn->transportComm = transportComm;// setupstruct ncclConnect myConnect;if (isMaster && ret > 0) {NCCLCHECK(transportComm->setup(comm->topo, collNetGraph, myInfo, peerInfo, &myConnect, conn, channel->id));}...
}
先看下对recvMaster执行collNetSetup,isMaster表示当前这个节点是不是recvMater;然后设置peerInfo,这里的peerInfo用的是comm中的第nranks个ncclPeerInfo;然后通过canConnect判断是否可以通过collNet连接,这里直接返回1,表示可以连接。
然后执行transportComm->setup初始化通信相关资源。
ncclResult_t collNetRecvSetup(struct ncclTopoSystem* topo, struct ncclTopoGraph* graph, struct ncclPeerInfo* myInfo, struct ncclPeerInfo* peerInfo, struct ncclConnect* connectInfo, struct ncclConnector* recv, int channelId) {struct collNetRecvResources* resources;NCCLCHECK(ncclCalloc(&resources, 1));recv->transportResources = resources;NCCLCHECK(ncclTopoGetNetDev(topo, myInfo->rank, graph, channelId, &resources->netDev));NCCLCHECK(ncclTopoCheckGdr(topo, myInfo->busId, resources->netDev, 0, &resources->useGdr));NCCLCHECK(ncclCudaHostCalloc(&resources->hostSendMem, 1));resources->devHostSendMem = resources->hostSendMem;int recvSize = offsetof(struct ncclRecvMem, buff);for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) recvSize += recv->comm->buffSizes[p];if (resources->useGdr) {NCCLCHECK(ncclCudaCalloc((char**)(&resources->devRecvMem), recvSize));}NCCLCHECK(ncclCudaHostCalloc((char**)&resources->hostRecvMem, recvSize));resources->devHostRecvMem = resources->hostRecvMem;NCCLCHECK(ncclIbMalloc((void**)&(resources->llData), recv->comm->buffSizes[NCCL_PROTO_LL]/2));struct collNetRecvConnectInfo* info = (struct collNetRecvConnectInfo*) connectInfo;NCCLCHECK(collNetListen(resources->netDev, &info->collNetHandle, &resources->netListenComm));return ncclSuccess;
}分配collNetRecvResources resources,然后分配各个协议用到的显存,以及用于同步的head,tail等,最后执行collNetListen。
这里的赋值有点复杂,我们先看下resources的结构在执行完collNetListen之后会变成什么样。collNetRecvResources是nccl这里用到的,最后netListenComm指向一个ncclSharpListenComm,ncclSharpListenComm中的listenCommP2P指向一个ncclIbListenComm,ncclIbListenComm中保存了使用的网卡和socket的fd。
struct collNetRecvResources {void* netListenComm; // ncclSharpListenComm...
};
struct ncclSharpListenComm {int dev;void *listenCommP2P; // ncclIbListenComm
};struct ncclIbListenComm {int dev;int fd;
};
然后我们具体看下。
ncclResult_t ncclSharpListen(int dev, void* opaqueHandle, void** listenComm) {struct ncclSharpListenComm *lComm;ncclResult_t status;NCCLCHECK(ncclIbMalloc((void**)&lComm, sizeof(struct ncclSharpListenComm)));status = NCCL_PLUGIN_SYMBOL.listen(dev, opaqueHandle, &lComm->listenCommP2P);lComm->dev = dev;*listenComm = lComm;return status;
}
collNetListen执行的就是ncclSharpListen,其实就是调用ib_plugin的listen函数,这里可以看到collNetRecvResources的netListenComm被赋值成为了ncclSharpListenComm lComm。
ncclResult_t ncclIbListen(int dev, void* opaqueHandle, void** listenComm) {struct ncclIbListenComm* comm;comm = malloc(sizeof(struct ncclIbListenComm));memset(comm, 0, sizeof(struct ncclIbListenComm));struct ncclIbHandle* handle = (struct ncclIbHandle*) opaqueHandle;NCCL_STATIC_ASSERT(sizeof(struct ncclIbHandle) < NCCL_NET_HANDLE_MAXSIZE, "ncclIbHandle size too large");comm->dev = dev;NCCLCHECK(GetSocketAddr(&(handle->connectAddr)));NCCLCHECK(createListenSocket(&comm->fd, &handle->connectAddr));*listenComm = comm;return ncclSuccess;
}ib_plugin的listen其实就是创建了一个listen socket,然后将网卡号dev,socket fd保存到ncclIbListenComm,ncclSharpListenComm的lComm被赋值成了这个ncclIbListenComm。ip和port保存到了opaqueHandle,即myConnect中。
到这里setup就执行结束了,继续看collNetSetup。
static int collNetSetup(struct ncclComm* comm, struct ncclTopoGraph* collNetGraph, struct ncclChannel* channel, int rank, int nranks, int masterRank, int masterPeer, int nMasters, int type) {...// prepare connect handlesncclResult_t res;struct {int isMaster;ncclConnect connect;} *allConnects = NULL;ncclConnect *masterConnects = NULL;NCCLCHECK(ncclCalloc(&masterConnects, nMasters));if (type == 1) { // recv side: AllGather// all ranks must participateNCCLCHECK(ncclCalloc(&allConnects, nranks));allConnects[rank].isMaster = isMaster;memcpy(&(allConnects[rank].connect), &myConnect, sizeof(struct ncclConnect));NCCLCHECKGOTO(bootstrapAllGather(comm->bootstrap, allConnects, sizeof(*allConnects)), res, cleanup);// consolidateint c = 0;for (int r = 0; r < nranks; r++) {if (allConnects[r].isMaster) {memcpy(masterConnects+c, &(allConnects[r].connect), sizeof(struct ncclConnect));if (r == rank) rankInCollNet = c;c++;}}} else { // send side : copy in connect info received from peer recv masterif (isMaster) memcpy(masterConnects+rankInCollNet, &(sendrecvExchange.connect), sizeof(struct ncclConnect));}// connectif (isMaster && ret > 0) {NCCLCHECKGOTO(transportComm->connect(masterConnects, nMasters, rankInCollNet, conn), res, cleanup);struct ncclPeer* devRoot = channel->devPeers+nranks;struct ncclConnector* devConn = (type == 1) ? &devRoot->recv : &devRoot->send;CUDACHECKGOTO(cudaMemcpy(devConn, conn, sizeof(struct ncclConnector), cudaMemcpyHostToDevice), res, cleanup);}...
}然后开始交换master的信息,分配nMaster个ncclConnect *masterConnects,nMaster就是节点数,然后将myConnect拷贝到masterConnects对应位置,执行allgather拿到所有rank的ncclConnect;然后将allConnects中所有的master对应的ncclConnect拷贝到masterConnects,最后执行transportComm的connect,完成sharp通信组的建立。
同理,我们先看下在执行connect之后resources中数据结构会变成什么样子。collNetRecvComm指向一个ncclSharpCollComm,ncclSharpCollComm中的recvComm和sendComm的作用类似bootstrap网络中连接前后节点,sharpCollContext为sharp context,sharpCollComm为sharp communicator。
struct collNetRecvResources {...void* collNetRecvComm; // ncclSharpCollComm...
};
struct ncclSharpCollComm {...void* recvComm; // ncclIbRecvCommvoid* sendComm; // ncclIbSendComm...struct sharp_coll_context* sharpCollContext;struct sharp_coll_comm* sharpCollComm;
};
ncclResult_t collNetRecvConnect(struct ncclConnect* connectInfos, int nranks, int rank, struct ncclConnector* recv) {// Setup device pointersstruct collNetRecvResources* resources = (struct collNetRecvResources*)recv->transportResources;struct collNetSendConnectInfo* info = (struct collNetSendConnectInfo*)(connectInfos+rank);resources->collNetRank = rank;// Intermediate buffering on GPU for GPU Direct RDMAstruct ncclRecvMem* recvMem = resources->useGdr ? resources->devRecvMem : resources->devHostRecvMem;int offset = 0;for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {recv->conn.buffs[p] = (p == NCCL_PROTO_LL ? resources->devHostRecvMem->buff : recvMem->buff) + offset;offset += recv->comm->buffSizes[p];}recv->conn.direct |= resources->useGdr ? NCCL_DIRECT_NIC : 0;// Head/Tail/Opcount are always on hostrecv->conn.tail = &resources->devHostRecvMem->tail;recv->conn.head = &resources->devHostSendMem->head;// Connect to coll commcollNetHandle_t** handlePtrs = NULL;NCCLCHECK(ncclCalloc(&handlePtrs, nranks));for (int i = 0; i < nranks; i++) {struct collNetRecvConnectInfo* info = (struct collNetRecvConnectInfo*)(connectInfos+i);handlePtrs[i] = &(info->collNetHandle);}ncclResult_t res;NCCLCHECKGOTO(collNetConnect((void**)handlePtrs, nranks, rank, resources->netListenComm, &resources->collNetRecvComm), res, cleanup);// Register buffersNCCLCHECK(collNetRegMr(resources->collNetRecvComm, recv->conn.buffs[NCCL_PROTO_SIMPLE], recv->comm->buffSizes[NCCL_PROTO_SIMPLE],resources->useGdr ? NCCL_PTR_CUDA : NCCL_PTR_HOST, &resources->mhandles[NCCL_PROTO_SIMPLE]));NCCLCHECK(collNetRegMr(resources->collNetRecvComm, resources->llData, recv->comm->buffSizes[NCCL_PROTO_LL]/2,NCCL_PTR_HOST, &resources->mhandles[NCCL_PROTO_LL]));// Create shared info between send and recv proxiesNCCLCHECK(ncclCalloc(&(resources->reqFifo), NCCL_STEPS));// Pass info to send sideinfo->reqFifo = resources->reqFifo;info->collNetComm = resources->collNetRecvComm;for (int p=0; p<NCCL_NUM_PROTOCOLS; p++)info->mhandles[p] = resources->mhandles[p];cleanup:if (handlePtrs != NULL) free(handlePtrs);// Close listen commNCCLCHECK(collNetCloseListen(resources->netListenComm));return res;
}首先将resource中的head,tail,buffer等记录到conn,handlePtrs记录每个master rank的listen ip port,然后执行collNetConnect建立sharp通信组。
ncclResult_t ncclSharpConnect(void* handles[], int nranks, int rank, void* listenComm, void** collComm) {struct ncclSharpListenComm* lComm = (struct ncclSharpListenComm*)listenComm;struct ncclSharpCollComm* cComm;NCCLCHECK(ncclIbMalloc((void**)&cComm, sizeof(struct ncclSharpCollComm)));NCCLCHECK(ncclIbMalloc((void**)&cComm->reqs, sizeof(struct ncclSharpRequest)*MAX_REQUESTS));cComm->nranks = nranks;cComm->rank = rank;if (cComm->rank == -1) {WARN("Could not determine my rank\n");return ncclInternalError;}int next = (cComm->rank + 1) % nranks;NCCLCHECK(NCCL_PLUGIN_SYMBOL.connect(lComm->dev, handles[next], &cComm->sendComm));NCCLCHECK(NCCL_PLUGIN_SYMBOL.accept(lComm->listenCommP2P, &cComm->recvComm)); // From prevstruct ncclSharpInfo* allInfo;pid_t pid = getpid();pthread_t tid = pthread_self();NCCLCHECK(ncclIbMalloc((void**)&allInfo, sizeof(struct ncclSharpInfo)*nranks));allInfo[cComm->rank].hostId = gethostid();allInfo[cComm->rank].jobId = (((uint64_t)allInfo[cComm->rank].hostId << 32) | ((pid ^ tid) ^ rand()));NCCLCHECK(ncclSharpAllGather(cComm, allInfo, sizeof(struct ncclSharpInfo)));// Find my local rank;int localRank = 0;for (int i=0; i<cComm->rank; i++) {if (allInfo[cComm->rank].hostId == allInfo[i].hostId) {localRank++;} }uint64_t jobId = allInfo[0].jobId;free(allInfo);...
}创建ncclSharpCollComm cComm,这个最后会赋值给collNetRecvComm。类似bootstrap网络,这里会通过ib_plugin将所有的master rank首尾相连,这里connect和accept的逻辑和之前的ncclNetIb完全一致,这里不再赘述。然后创建ncclSharpInfo allInfo,记录hostid,随机一个jobId,执行allgather。
ncclResult_t ncclSharpConnect(void* handles[], int nranks, int rank, void* listenComm, void** collComm) {...struct sharp_coll_init_spec init_spec = {0};init_spec.progress_func = NULL;init_spec.job_id = jobId;init_spec.world_rank = cComm->rank;init_spec.world_size = nranks;init_spec.world_local_rank = 0;init_spec.enable_thread_support = 1;init_spec.group_channel_idx = 0;init_spec.oob_colls.barrier = ncclSharpOobBarrier;init_spec.oob_colls.bcast = ncclSharpOobBcast;init_spec.oob_colls.gather = ncclSharpOobGather;init_spec.oob_ctx = cComm;init_spec.config = sharp_coll_default_config;init_spec.config.user_progress_num_polls = 10000000;char devName[MAXNAMESIZE];ncclNetProperties_t prop;ncclSharpGetProperties(lComm->dev, &prop);snprintf(devName, MAXNAMESIZE, "%s:%d", prop.name, prop.port);init_spec.config.ib_dev_list = devName;int ret = sharp_coll_init(&init_spec, &cComm->sharpCollContext);INFO(NCCL_INIT, "Sharp rank %d/%d initialized on %s", cComm->rank, nranks, devName);if (ret < 0) {WARN("NET/IB :SHARP coll init error: %s(%d)\n", sharp_coll_strerror(ret), ret);return ncclInternalError;}struct sharp_coll_comm_init_spec comm_spec;comm_spec.rank = cComm->rank;comm_spec.size = nranks;comm_spec.oob_ctx = cComm;comm_spec.group_world_ranks = NULL;ret = sharp_coll_comm_init(cComm->sharpCollContext, &comm_spec, &cComm->sharpCollComm);if (ret < 0) {WARN("SHARP group create failed: %s(%d)\n", sharp_coll_strerror(ret), ret);return ncclInternalError;}*collComm = cComm;return ncclSuccess;创建sharp_coll_init_spec init_spec用于初始化sharp通信上下文sharpCollContext,初始化init_spec,job_id设置为rank0的job_id,设置rank,size等,设置init_spec.oob_colls的oob_ctx为cComm,设置oob_colls.barrier等,oob_colls就类比于nccl的bootstrap网络,设置使用哪张网卡,然后执行sharp_coll_init,这里会初始化sharp,然后通过sharp_coll_comm_init用sharpCollContext初始化sharpCollComm,到这就完成了sharp通信组的建立。
然后回到ncclSharpConnect之后开始注册内存,会通过sharp_coll_reg_mr注册sharp内存注册,还需要ibv_reg_mr注册rdma内存。最后申请reqFifo,将reqFifo和collNetRecvComm记录到info,之后会发送给send。
ncclResult_t collNetRecvConnect(struct ncclConnect* connectInfos, int nranks, int rank, struct ncclConnector* recv) {...// Register buffersNCCLCHECK(collNetRegMr(resources->collNetRecvComm, recv->conn.buffs[NCCL_PROTO_SIMPLE], recv->comm->buffSizes[NCCL_PROTO_SIMPLE],resources->useGdr ? NCCL_PTR_CUDA : NCCL_PTR_HOST, &resources->mhandles[NCCL_PROTO_SIMPLE]));NCCLCHECK(collNetRegMr(resources->collNetRecvComm, resources->llData, recv->comm->buffSizes[NCCL_PROTO_LL]/2,NCCL_PTR_HOST, &resources->mhandles[NCCL_PROTO_LL]));// Create shared info between send and recv proxiesNCCLCHECK(ncclCalloc(&(resources->reqFifo), NCCL_STEPS));// Pass info to send sideinfo->reqFifo = resources->reqFifo;info->collNetComm = resources->collNetRecvComm;for (int p=0; p<NCCL_NUM_PROTOCOLS; p++)info->mhandles[p] = resources->mhandles[p];cleanup:if (handlePtrs != NULL) free(handlePtrs);// Close listen commNCCLCHECK(collNetCloseListen(resources->netListenComm));return res;
}然后回到collNetSetup,recv端会将info发送给send端,即reqFifo的地址和collNetRecvComm。
static int collNetSetup(struct ncclComm* comm, struct ncclTopoGraph* collNetGraph, struct ncclChannel* channel, int rank, int nranks, int masterRank, int masterPeer, int nMasters, int type) {...// recv side sends connect info to send sideif (isMaster && type == 1) {sendrecvExchange.collNetRank = rankInCollNet;memcpy(&sendrecvExchange.connect, masterConnects+rankInCollNet, sizeof(struct ncclConnect));NCCLCHECKGOTO(bootstrapSend(comm->bootstrap, masterPeer, &sendrecvExchange, sizeof(sendrecvExchange)), res, cleanup);}if (ret > 0) {supported = 1;}
cleanup:if (allConnects != NULL) free(allConnects);if (masterConnects != NULL) free(masterConnects);return supported;
}
然后开始对send端执行collNetSetup,send端比较简单,主要就是显存的分配和注册,然后通过recv发送过来的info,将info中的reqFifo和comm记录到collNetSendResources。
到这里通信的建链就完成了,接下来我们看下api执行的过程
enqueue
如前所述,当用户执行了一个allreduce api之后会执行enqueue的操作。
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {struct ncclColl coll;struct ncclProxyArgs proxyArgs;memset(&proxyArgs, 0, sizeof(struct ncclProxyArgs));NCCLCHECK(computeColl(info, &coll, &proxyArgs));info->comm->myParams->blockDim.x = std::max<unsigned>(info->comm->myParams->blockDim.x, info->nThreads);int nChannels = info->coll == ncclCollSendRecv ? 1 : coll.args.coll.nChannels;int nSubChannels = (info->pattern == ncclPatternCollTreeUp || info->pattern == ncclPatternCollTreeDown) ? 2 : 1;for (int bid=0; bid<nChannels*nSubChannels; bid++) {int channelId = (info->coll == ncclCollSendRecv) ? info->channelId :info->comm->myParams->gridDim.x % info->comm->nChannels;struct ncclChannel* channel = info->comm->channels+channelId;proxyArgs.channel = channel;// Adjust pattern for CollNet based on channel indexif (nSubChannels == 2) {info->pattern = (channelId < info->comm->nChannels/nSubChannels) ? ncclPatternCollTreeUp : ncclPatternCollTreeDown;}NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));info->comm->myParams->gridDim.x++;int opIndex = channel->collFifoTail;struct ncclColl* c = channel->collectives+opIndex;volatile uint8_t* activePtr = (volatile uint8_t*)&c->active;while (activePtr[0] != 0) sched_yield();memcpy(c, &coll, sizeof(struct ncclColl));if (info->coll != ncclCollSendRecv) c->args.coll.bid = bid % coll.args.coll.nChannels;c->active = 1;opIndex = (opIndex+1)%NCCL_MAX_OPS;c->nextIndex = opIndex;channel->collFifoTail = opIndex;channel->collCount++;}info->comm->opCount++;return ncclSuccess;
}通过computeColl将算法,协议等信息记录到coll中,当使用sharp的时候算法为NCCL_ALGO_COLLNET,nChannels设置为搜索出来channel数的一半,pattern设置为ncclPatternCollTreeUp,info->nstepsPerLoop = info-> nchunksPerLoop = 1。
然后将coll记录到所有channel,上行channel的pattern为ncclPatternCollTreeUp,下行channel pattern为ncclPatternCollTreeDown,然后通过ncclProxySaveColl创建ncclProxyArgs。
kernel和proxy
__device__ void ncclAllReduceCollNetKernel(struct CollectiveArgs* args) {const int tid = threadIdx.x;const int nthreads = args->coll.nThreads-WARP_SIZE;const int bid = args->coll.bid;const int nChannels = args->coll.nChannels;struct ncclDevComm* comm = args->comm;struct ncclChannel* channel = comm->channels+blockIdx.x;const int stepSize = comm->buffSizes[NCCL_PROTO_SIMPLE] / (sizeof(T)*NCCL_STEPS);int chunkSize = args->coll.lastChunkSize;const ssize_t minChunkSize = nthreads*8*sizeof(uint64_t) / sizeof(T);const ssize_t loopSize = nChannels*chunkSize;const ssize_t size = args->coll.count;if (loopSize > size) {chunkSize = DIVUP(size, nChannels*minChunkSize)*minChunkSize;}// Compute pointersconst T * __restrict__ thisInput = (const T*)args->sendbuff;T * __restrict__ thisOutput = (T*)args->recvbuff;if (blockIdx.x < nChannels) { // first half of the channels do reducestruct ncclTree* tree = &channel->collTreeUp;ncclPrimitives<UNROLL, 1, 1, T, 1, 1, 0, FUNC> prims(tid, nthreads, tree->down, &tree->up, NULL, stepSize, channel, comm);for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {// Upssize_t offset = gridOffset + bid*chunkSize;int nelem = min(chunkSize, size-offset);if (tree->up == -1) {prims.recvReduceCopy(thisInput+offset, thisOutput+offset, nelem);} else if (tree->down[0] == -1) {prims.send(thisInput+offset, nelem);} else {prims.recvReduceSend(thisInput+offset, nelem);}}}...
}
先看上行过程,nChannels之前有除以2,所以小于nChannels的都是上行channel,如果是sendEndIndex,那么他的down为-1,因此直接通过send将自己的数据发送给下一个rank的buffer,如果是非sendEndIndex,那么需要接收上一个rank发送过来的数据,和自己userbuff里对应数据执行reduce,然后发送给up的buffer。
然后看下proxy的send流程:
ncclResult_t collNetSendProxy(struct ncclProxyArgs* args) {...if (args->state == ncclProxyOpProgress) {int p = args->protocol;int stepSize = args->connector->comm->buffSizes[p] / NCCL_STEPS;char* localBuff = args->connector->conn.buffs[p];void* sendMhandle = resources->sendMhandles[p];void* recvMhandle = resources->recvMhandles[p];args->idle = 1;struct reqSlot* reqFifo = resources->reqFifo;if (args->head < args->end) {int buffSlot = args->tail%NCCL_STEPS;if (args->tail < args->end && args->tail < args->head + NCCL_STEPS&& reqFifo[buffSlot].recvBuff != NULL) {volatile int* sizesFifo = resources->hostRecvMem->sizesFifo;volatile uint64_t* recvTail = &resources->hostRecvMem->tail;if (args->protocol == NCCL_PROTO_LL) {} else if (args->tail < *recvTail) {// Send through networkif (sizesFifo[buffSlot] != -1) {int count = sizesFifo[buffSlot]/ncclTypeSize(args->dtype);NCCLCHECK(collNetIallreduce(resources->collNetSendComm, localBuff+buffSlot*stepSize, (void*)(reqFifo[buffSlot].recvBuff), count, args->dtype, args->redOp, sendMhandle, recvMhandle, args->requests+buffSlot));if (args->requests[buffSlot] != NULL) {sizesFifo[buffSlot] = -1; // Make sure size is reset to zero before we update the head.__sync_synchronize();args->tail += args->sliceSteps;args->idle = 0;} } } } if (args->head < args->tail) {int done, size;int buffSlot = args->head%NCCL_STEPS;NCCLCHECK(collNetTest((void*)(args->requests[buffSlot]), &done, &size));if (done) {TRACE(NCCL_NET, "sendProxy [%d/%d] request %p done, size %d", args->head, buffSlot, args->requests[buffSlot], size);reqFifo[buffSlot].size = size;// Make sure size is updated before we set recvBuff to NULL (from the view of recv proxy, concerning the flush)// (reordered store after store is possible on POWER, though not on x86)__sync_synchronize();reqFifo[buffSlot].recvBuff = NULL; // Notify recvProxyargs->head += args->sliceSteps;resources->hostSendMem->head = args->head;args->idle = 0;} } } if (args->head == args->end) {resources->step = args->end;args->idle = 0;args->state = ncclProxyOpNone;}
}
collNetIallreduce就是将sendbuff,recvbuff和对应的mr填充到sharp_coll_reduce_spec,然后执行sharp_coll_do_allreduce或sharp_coll_do_allreduce_nb,等到执行完成之后,reduce的结果就会填充到recvbuff。
这里sendbuff就是send conn中的buff,recvbuff就是recv conn的buff,SendProxy不知道recv conn中buff哪块可用,这里就是通过reqFifo完成send和recv之间的协调的,所以可以看到这里判断能否发送数据的条件除了常规的判断队列有否有数据之外,还判断对应reqFifo的recvBuff是否为NULL,都满足条件才能发送。
完成发送后将tail加上sliceSteps,如果head小于tail,说明有已发送但未完成的allreduce,那么通过sharp_coll_req_test判断对应的请求是否完成如果完成,将head加上sliceSteps,将对应的recvBuff设置为NULL以通知RecvProxy这个req已经完成了。
然后看下RecvProxy:
ncclResult_t collNetRecvProxy(struct ncclProxyArgs* args) {if (args->head < args->end) {if ((args->tail < args->head + NCCL_STEPS) && (args->tail < (resources->hostSendMem->head) + NCCL_STEPS) && (args->tail < args->end)) {int buffSlot = args->tail%NCCL_STEPS;char* recvBuff = p == NCCL_PROTO_LL ? (char*)resources->llData : localBuff;int recvStepSize = p == NCCL_PROTO_LL ? stepSize/2 : stepSize;reqFifo[buffSlot].recvBuff = recvBuff+buffSlot*recvStepSize;TRACE(NCCL_NET, "recvProxy [%d/%d] posted buffer %p", args->tail, buffSlot, reqFifo[buffSlot].recvBuff);args->tail += args->sliceSteps;args->idle = 0;} if (args->tail > args->head) {int buffSlot = args->head%NCCL_STEPS;if (reqFifo[buffSlot].recvBuff == NULL) { // Buffer is cleared : coll is completeTRACE(NCCL_NET, "recvProxy [%d/%d] done, size %d", args->head, buffSlot, reqFifo[buffSlot].size);args->head += args->sliceSteps;if (args->protocol == NCCL_PROTO_LL) { // ll} else if (args->protocol == NCCL_PROTO_SIMPLE) {if (resources->useGdr) NCCLCHECK(collNetFlush(resources->collNetRecvComm, localBuff+buffSlot*stepSize, reqFifo[buffSlot].size, mhandle));resources->hostRecvMem->tail = args->head;} args->idle = 0;}}}
}
这里可以看到只要队列有空间,那么就下发对应的recvbuf到reqFifo,如果tail大于head,说明有未完成的请求,那么判断对应的recvbuff是否为NULL,如果为NULL说明已经完成,那么将head加上sliceSteps,然后执行collNetFlush保证数据落盘,这里的flush和ncclNetIb一致,都是读本地QP,flush之后将resources->hostRecvMem->tai设置为head,以通知kernel有新数据。
最后看下recv kernel:
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceCollNetKernel(struct CollectiveArgs* args) {...if (blockIdx.x >= nChannels) { // second half of the channels do broadcaststruct ncclTree* tree = &channel->collTreeDn;ncclPrimitives<UNROLL, 1, 1, T, 1, 1, 0, FUNC> prims(tid, nthreads, &tree->up, tree->down, NULL, stepSize, channel, comm);for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {// Downssize_t offset = gridOffset + bid*chunkSize;int nelem = min(chunkSize, size-offset);if (tree->up == -1) {prims.send(thisOutput+offset, nelem);} else if (tree->down[0] == -1) {prims.recv(thisOutput+offset, nelem);} else {prims.recvCopySend(thisOutput+offset, nelem);} } }
}
如果是recvEndIndex,那么只需要recv数据即可,如果不是recvEndIndex,那么通过recvCopySend将数据从up的buffe中接收,copy到自己的user buffer对应位置,并发送给down的buffer。
相关文章:
NVIDIA NCCL 源码学习(十三)- IB SHARP
背景 之前我们看到了基于ring和tree的两种allreduce算法,对于ring allreduce,一块数据在reduce scatter阶段需要经过所有的rank,allgather阶段又需要经过所有rank;对于tree allreduce,一块数据数据在reduce阶段要上行…...
Spark-Scala语言实战(4)
在之前的文章中,我们学习了如何在scala中定义无参,带参以及匿名函数。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。 Spark-Scala语言…...

ffmpeg不常用命令整理
最近做了许多有关音视频方面的工作,接触了一些不常用的命令,整理分享出来。 1.剪辑视频 ffmpeg -ss 1 -to 4 -accurate_seek -i input.mp4 -c:v copy output.mp4指定从视频中的第1秒开始,到第4秒结束的部分剪辑。 ss:指定开始时…...
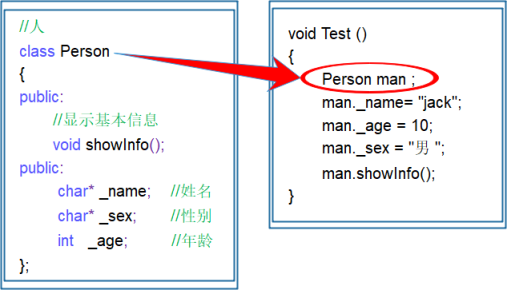
怎么理解面向对象?一文带你全面理解
文章目录 1、类和对象(1)面向过程和面向对象初步认识(2)类的引入(3)类的定义(4)类的访问限定符及封装4.1 访问限定符4.2 封装 (5)类的作用域(6&am…...
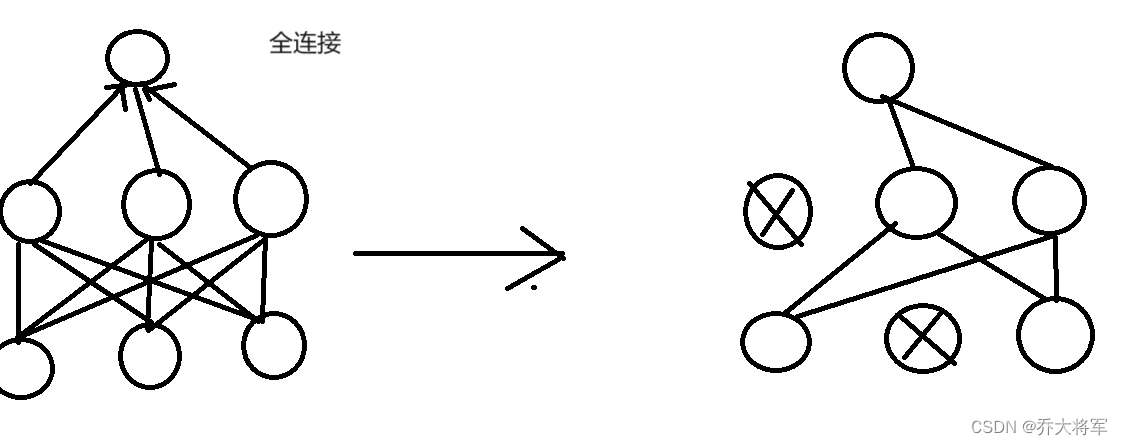
神经网络(深度学习,计算机视觉,得分函数,损失函数,前向传播,反向传播,激活函数)
目录 一、神经网络简介 二、深度学习要解决的问题 三、深度学习的应用 四、计算机视觉 五、计算机视觉面临的挑战 六、得分函数 七、损失函数 八、前向传播 九、反向传播 十、神经元的个数对结果的影响 十一、正则化与激活函数 一、神经网络简介 神经网络是一种有监督…...

Tomcat的Host Manager页面403的原因和解决办法
目录 背景 原因: 解决方案 背景 一直报错 403 Access Denied You are not authorized to view this page.By default the Host Manager is only accessible from a browser running on the same machine as Tomcat. If you wish to modify this restriction, youll need to…...

零基础学华为ip认证难吗?华为认证费用多少?
零基础学华为ip认证难吗? 首先,零基础的学习者可以通过系统的学习,逐步掌握网络基础知识和技能。可以通过阅读教材、参加培训课程、进行实践操作等方式,不断提升自己的知识和技能水平。同时,学习者还可以利用华为提供的…...

[C语言]——内存函数
目录 一.memcpy使用和模拟实现(内存拷贝) 二.memmove 使用和模拟实现 三.memset 函数的使用(内存设置) 四.memcmp 函数的使用 C语言中规定: memcpy拷贝的就是不重叠的内存memmove拷贝的就是重叠的内存但是在VS202…...

QGIS编译(跨平台编译)056:PDAL编译(Windows、Linux、MacOS环境下编译)
点击查看专栏目录 文章目录 1、PDAL介绍2、PDAL下载3、Windows下编译4、linux下编译5、MacOS下编译1、PDAL介绍 PDAL(Point Data Abstraction Library)是一个开源的地理空间数据处理库,它专注于点云数据的获取、处理和分析。PDAL 提供了丰富的工具和库,用于处理激光扫描仪、…...

计算机三级——网络技术(综合题第二题)
路由器工作模式 用户模式 当通过Console或Telnet方式登录到路由器时,只要输入的密码正确,路由器就直接进入了用户模式。在该模式下,系统提示符为一个尖括号(>)。如果用户以前为路由器输入过名称,则该名称将会显示在尖指号的前…...

Python 深度学习第二版(GPT 重译)(二)
四、入门神经网络:分类和回归 本章涵盖 您的第一个真实世界机器学习工作流示例 处理矢量数据上的分类问题 处理矢量数据上的连续回归问题 本章旨在帮助您开始使用神经网络解决实际问题。您将巩固从第二章和第三章中获得的知识,并将所学应用于三个新…...
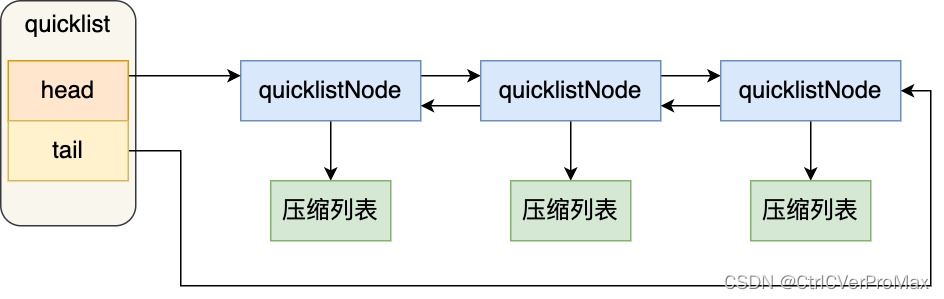
【Redis】Redis常见原理和数据结构
Redis 什么是redis redis是一款基于内存的k-v数据结构的非关系型数据库,读写速度非常快,常用于缓存,消息队列、分布式锁等场景。 redis的数据类型 string:字符串 缓存对象,分布式ID,token,se…...

3个Tips,用“AI”开启新生活
相信最近,很多朋友们都回归到了忙碌的生活节奏中。生活模式的切换,或多或少会带来身体或情绪状况的起伏。新技术正在为人们生活的方方面面带来便利。3个小Tips或许能让你也从新技术中获益,从身到心,用“AI”开启新生活。 关”A…...

【ROS | OpenCV】在ROS中实现多版本OpenCV、cv_bridge共存:安装与配置指南
在 Ubuntu 20.04 中,ROS Noetic 默认安装的 OpenCV 版本为 4.2.0。如果您需要确认系统中已安装的 OpenCV 版本,可以使用以下命令: sudo find / -iname "*opencv*"然而,许多开源算法都是基于 OpenCV 3 编写的࿰…...
Docker容器化技术(docker-compose示例:部署discuz论坛和wordpress博客,使用adminer管理数据库)
安装docker-compose [rootservice ~]# systemctl stop firewalld [rootservice ~]# setenforce 0 [rootservice ~]# systemctl start docker[rootservice ~]# wget https://github.com/docker/compose/releases/download/v2.5.0/docker-compose-linux-x86_64创建目录 [rootse…...

微分学<6>——Taylor公式
索引 Taylor公式Taylor公式的定性分析定理6.1 Taylor公式(Peano余项) Taylor公式的定量分析定理6.2 Taylor公式(Lagrange余项) Taylor公式 Taylor公式的定性分析 定理6.1 Taylor公式(Peano余项) 若函数 f ( x ) f\left ( x \right ) f(x)在 x 0 x_{0} x0处的 n n n阶导数均…...
检索增强生成(RAG)应用的构建:LangChain与LlamaIndex的比较与选择
对于我要做RAG应用,我应该使用两者中的哪一个。或者说还是都使用? 在人工智能领域,检索增强生成(RAG)应用正变得越来越受欢迎,因为它们能够结合大型语言模型(LLMs)的自然语言处理能力…...
免费PDF转换和编辑工具 PDFgear 2.1.4
PDFgear是一款功能强大的 PDF 阅读及转换软件。 它支持多种文件格式的转换和编辑,同时还提供了丰富的功能模块,如签名、表单填写等,方便用户进行多样化的操作。 该软件界面简洁美观,操作简单易懂,适合不同层次的用户…...

uniapp,导航栏(切换项)有多项,溢出采取左滑右滑的形式展示
一、实现效果 当有多项的导航,或者说切换项,超出页面的宽度,我们采取可滑动的方式比较好一些!并且在页面右边加个遮罩,模拟最右边有渐变效果! 二、实现代码 html代码: <!-- 头部导航栏 --…...

计算机网络面经-什么是IPv4和IPv6?
前言 Internet协议(IP)是为连接到Internet网络的每个设备分配的数字地址。它类似于电话号码,是一种独特的数字组合,允许用户与他人通信。IP地址主要有两个主要功能。首先,有了IP,用户能够在Internet上被识别…...
Pixel Mind Decoder 集成ChatGPT实战:构建多轮对话情绪感知智能体
Pixel Mind Decoder 集成ChatGPT实战:构建多轮对话情绪感知智能体 1. 情绪感知智能体的商业价值 在客服、心理咨询和教育陪伴等场景中,对话系统的情绪感知能力直接影响用户体验和业务效果。传统对话系统往往只关注语义理解,而忽视了情绪这一…...

Whisper.cpp实战指南:在本地设备上构建高效离线语音识别系统
Whisper.cpp实战指南:在本地设备上构建高效离线语音识别系统 【免费下载链接】whisper.cpp Port of OpenAIs Whisper model in C/C 项目地址: https://gitcode.com/GitHub_Trending/wh/whisper.cpp 你是否曾想过在完全离线的环境下实现高质量的语音识别&…...

LinkSwift:八大网盘直链下载终极解决方案
LinkSwift:八大网盘直链下载终极解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅雷云…...

Dify权限体系深度拆解:5大高危配置漏洞与7步零信任加固方案
第一章:Dify权限体系核心架构与设计哲学Dify 的权限体系并非简单的 RBAC(基于角色的访问控制)叠加,而是融合了多租户隔离、资源粒度策略、动态上下文评估与声明式策略语言(Rego)的混合型授权模型。其设计哲…...

Windows 10变身简易服务器:低成本搭建多用户远程开发/测试环境全记录
Windows 10变身简易服务器:低成本搭建多用户远程开发/测试环境全记录 在当今快节奏的开发环境中,团队协作和资源共享变得越来越重要。对于小型团队、学生项目组或个人开发者来说,购买专业服务器设备往往意味着高昂的成本投入。而实际上&#…...
)
别再为SQL Server 2012安装报错发愁了!Windows 10/11保姆级避坑指南(含镜像下载)
SQL Server 2012在Windows 10/11上的终极安装避坑指南 每次打开SQL Server安装程序时,那个熟悉的进度条总会让人心跳加速——特别是在Windows 10/11这样的现代系统上安装老版本的SQL Server 2012。作为一名经历过无数次安装失败的老手,我深知那些隐藏在安…...

3分钟快速上手OmenSuperHub:解锁惠普游戏本隐藏性能的终极指南
3分钟快速上手OmenSuperHub:解锁惠普游戏本隐藏性能的终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一款专为惠普游戏…...

WAS Node Suite图像批量处理终极指南:5种高效解决Load Image Batch节点异常的实战方案
WAS Node Suite图像批量处理终极指南:5种高效解决Load Image Batch节点异常的实战方案 【免费下载链接】was-node-suite-comfyui An extensive node suite for ComfyUI with over 210 new nodes 项目地址: https://gitcode.com/gh_mirrors/wa/was-node-suite-comf…...

Linux下certutil与Windows certutil傻傻分不清?一文讲透两者的区别与使用场景
Linux与Windows下的certutil:同名工具的全方位对比与实战指南 第一次在Linux终端输入certutil命令时,我下意识地按照Windows经验操作,结果系统提示"command not found"。这个看似简单的工具名背后,隐藏着两个完全不同的…...

【AGI发展里程碑】:SITS2026官方路线图深度解码——5大技术跃迁节点与3年落地时间表
第一章:SITS2026发布:AGI发展路线图 2026奇点智能技术大会(https://ml-summit.org) SITS2026正式发布了《通用人工智能发展路线图(2026–2035)》,标志着AGI研发从碎片化工程实践转向系统性科学治理。该路线图由全球4…...