RDD算子介绍(三)
1. join
将相同的key的值连接在一起,值的类型可以不同
val rdd1 : RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 : RDD[(String, Int)] = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
val joinRDD : RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
如果有不同的key,则不会连接
val rdd1 : RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 : RDD[(String, Int)] = sc.makeRDD(List(("d", 4), ("c", 6), ("a", 4)))
val joinRDD : RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
相同的key有多个,则会两两匹配(笛卡尔乘积)
val rdd1 : RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 : RDD[(String, Int)] = sc.makeRDD(List(("a", 5), ("c", 6), ("a", 4)))
val joinRDD : RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
类似于SQL中的join,RDD中的join也会出现笛卡尔乘积,所以需要谨慎使用。同样类似于SQL,RDD也有leftOuterJoin和rightOuterJoin。
val rdd1 : RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 : RDD[(String, Int)] = sc.makeRDD(List(("a", 4), ("b", 5)))
val joinRDD : RDD[(String, (Int, Int))] = rdd1.leftOuterJoin(rdd2)
joinRDD.collect().foreach(println)
val rdd1 : RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2)))
val rdd2 : RDD[(String, Int)] = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
val joinRDD : RDD[(String, (Int, Int))] = rdd1.rightOuterJoin(rdd2)
joinRDD.collect().foreach(println) 
2. cogroup
congroup即connect+group,相同的key放在一个组里,然后连接在一起
val rdd1 : RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2)))
val rdd2 : RDD[(String, Int)] = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
val cgRDD : RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
cgRDD.collect().foreach(println)
cogroup的参数可以不止一个rdd,最多可以有三个rdd
3. 案例实操:统计各个省份点击数前三的广告
val dataRDD = sc.textFile("data")// 转换为((省份, 广告), 1)的格式
val mapRDD : RDD[((String, String), Int)] = dataRDD.map(line => {val datas = datas.split(" ")((data(1), data(4)), 1)
})// 聚合
val reduceRDD : RDD[((String, String), Int)] = mapRDD.reduceByKey(_+_)// 转换为(省份, (广告, sum))的格式
val newMapRDD = reduceRDD.map{case((prv, ad), sum) => {(prv, (ad, sum))}
}// 按照key(省份)分组
val groupRDD : RDD[(String, Iterable[(String, Int)])] = newMapRDD.groupByKey()// 按照值的第二个参数降序排序,取前三
val resultRDD = groupRDD.mapValues(iter => {iter.toList.sortBy(_._2)(Ordering.Int.reverse)
}).take(3)resultRDD.collect().foreach(println)4. reduce
上述都是转换算子,接下来介绍行动算子。行动算子会触发作业的执行,底层调用的是runJob方法,会创建ActiveJob,并提交执行。
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val i : Int = rdd.reduce(_+_)
println(i)5. collect
将不同分区的数据按照分区的顺序采集到Driver端内存中,形成数组。
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val i : Array[Int] = rdd.collect()
println(i.mkString(","))![]()
6. count, first, take, takeOrdered
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val i : Int = rdd.count()
println(i)val first : Int = rdd.first()
println(first)val takei : Array[Int]= rdd.take(3)
println(takei.mkString(","))val rdd1 : RDD[Int] = sc.makeRDD(List(4, 2, 3, 1))
val takeOrderedi : Array[Int]= rdd1.takeOrdered(3)
println(takeOrderedi.mkString(","))
7. aggregate、fold
与aggregateByKey类似,传入初始值、分区内计算规则、分区间计算规则,得到计算结果。只不过aggregateByKey需要根据不同的key进行分组,最后得到的是RDD,而aggregate不需要根据key进行分组计算,直接得到计算结果。
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val result : Int = rdd.aggregate(0)(_+_, _+_)
println(result)![]()
另外一个区别就是aggregate的初始值不进会参与分区内计算,还会参与分区间计算,而aggregateByKey的初始值只参与分区内计算,所以下面程序的允许结果为40
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val result : Int = rdd.aggregate(10)(_+_, _+_)
println(result)如果分区内计算规则和分区间计算规则相同,可以使用fold简化
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val result : Int = rdd.fold(10)(_+_)
println(result)8. countByKey、countByValue
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val result : collection.Map[Int, Long] = rdd.countByValue()
println(result)![]()
表示4出现了依次,2出现了依次,1出现了1次,3出现了1次。
val rdd = sc.makeRDD(List(("a", 1), ("a", 1), ("a", 1)))
val result : collection.Map[String, Long] = rdd.countByKey()
println(result)![]()
按照key统计次数,跟值无关,这里a出现了3次。
9. WordCount的多种实现方式
val rdd = sc.makeRDD(List("Hello Scala", "Hello Scala"))
val words : RDD[String] = rdd.flatMap(_.split(" "))
val group : RDD[(String, Iterable[String])] = words.groupBy(word=>word)
val wordCount : RDD[(String, Int)] = group.mapValues(iter=>iter.size)
val rdd = sc.makeRDD(List("Hello Scala", "Hello Scala"))
val words : RDD[String] = rdd.flatMap(_.split(" "))
val wordOne = words.map((_, 1))
val group : RDD[(String, Iterable[Int])] = wordOne.groupByKey()
val wordCount : RDD[(String, Int)] = group.mapValues(iter=>iter.size)
val rdd = sc.makeRDD(List("Hello Scala", "Hello Scala"))
val words : RDD[String] = rdd.flatMap(_.split(" "))
val wordOne = words.map((_, 1))
val wordCount : RDD[(String, Int)] = wordOne.reduceByKey()
val rdd = sc.makeRDD(List("Hello Scala", "Hello Scala"))
val words : RDD[String] = rdd.flatMap(_.split(" "))
val wordOne = words.map((_, 1))
val wordCount : RDD[(String, Int)] = wordOne.aggregateByKey(0)(_+_, _+_)
val rdd = sc.makeRDD(List("Hello Scala", "Hello Scala"))
val words : RDD[String] = rdd.flatMap(_.split(" "))
val wordOne = words.map((_, 1))
val wordCount : RDD[(String, Int)] = wordOne.combineByKey(v=>v)((x : Int, y : Int) => x + y, (x : Int, y : Int) => x + y)
val rdd = sc.makeRDD(List("Hello Scala", "Hello Scala"))
val words : RDD[String] = rdd.flatMap(_.split(" "))
val wordOne = words.map((_, 1))
val wordCount : collection.Map[String, Long] = wordOne.countByKey()
val rdd = sc.makeRDD(List("Hello Scala", "Hello Scala"))
val words : RDD[String] = rdd.flatMap(_.split(" "))
val wordCount : collection.Map[String, Long] = words.countByValue()
val rdd = sc.makeRDD(List("Hello Scala", "Hello Scala"))
val words : RDD[String] = rdd.flatMap(_.split(" "))
val wordMap = word.map(word => {mutable.Map[String, Int]((word, 1))
})
val wordCount = wordMap.reduce((map1, map2) => {map2.foreach{case(word, count) => {val newCount = map1.getOrElse(word, 0L) + countmap1.update(word, newCount)}}map1
})
10. save
save相关的方法主要有saveAsTextFile、saveAsObjectFile、saveAsSequenceFile。其中,saveAsSequenceFile需要数据元素类型为key-value类型。
相关文章:
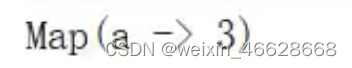
RDD算子介绍(三)
1. join 将相同的key的值连接在一起,值的类型可以不同 val rdd1 : RDD[(String, Int)] sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3))) val rdd2 : RDD[(String, Int)] sc.makeRDD(List(("a", 4), ("b", 5…...

Redis的脑裂问题
Redis 脑裂(Split-brain)问题是指在分布式系统中,特别是基于主从复制和哨兵(Sentinel)模式的Redis集群中,由于网络分区(network partition)而导致部分节点组成了独立可用的服务&…...
【算法】雪花算法生成分布式 ID
SueWakeup 个人中心:SueWakeup 系列专栏:学习Java框架 个性签名:人生乏味啊,我欲令之光怪陆离 本文封面由 凯楠📷 友情赞助播出! 目录 1. 什么是分布式 ID 2. 分布式 ID 基本要求 3. 数据库主键自增 4. UUID 5. S…...
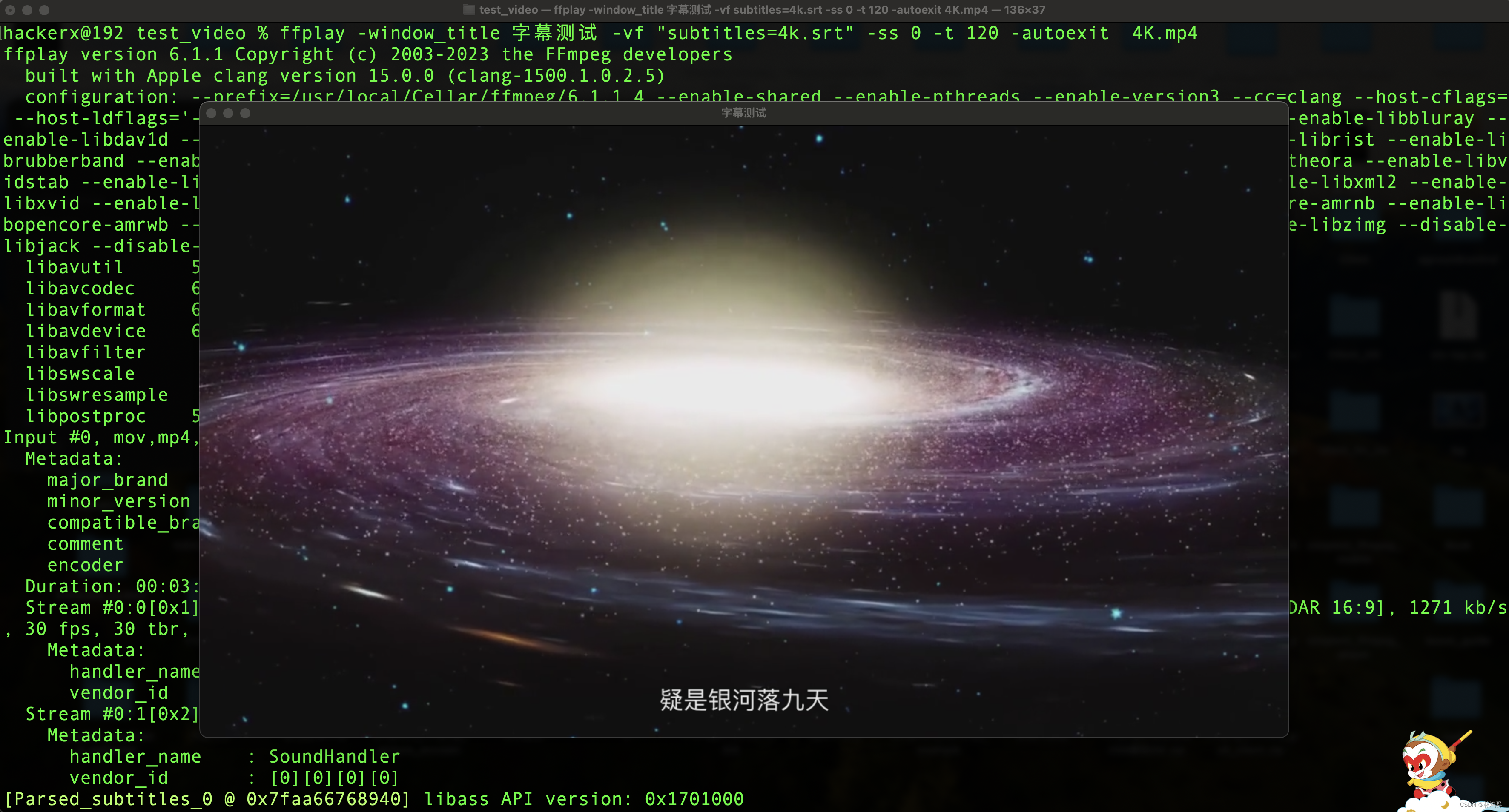
FFplay使用滤镜添加字幕到现有视频显示
1.创建字幕文件4k.srt 4k.srt内容: 1 00:00:01.000 --> 00:00:30.000 日照香炉生紫烟2 00:00:31.000 --> 00:00:60.000 遥看瀑布挂前川3 00:01:01.000 --> 00:01:30.000 飞流直下三千尺4 00:01:31.000 --> 00:02:00.000 疑是银河落九天2.通过使用滤镜显示字幕在视…...
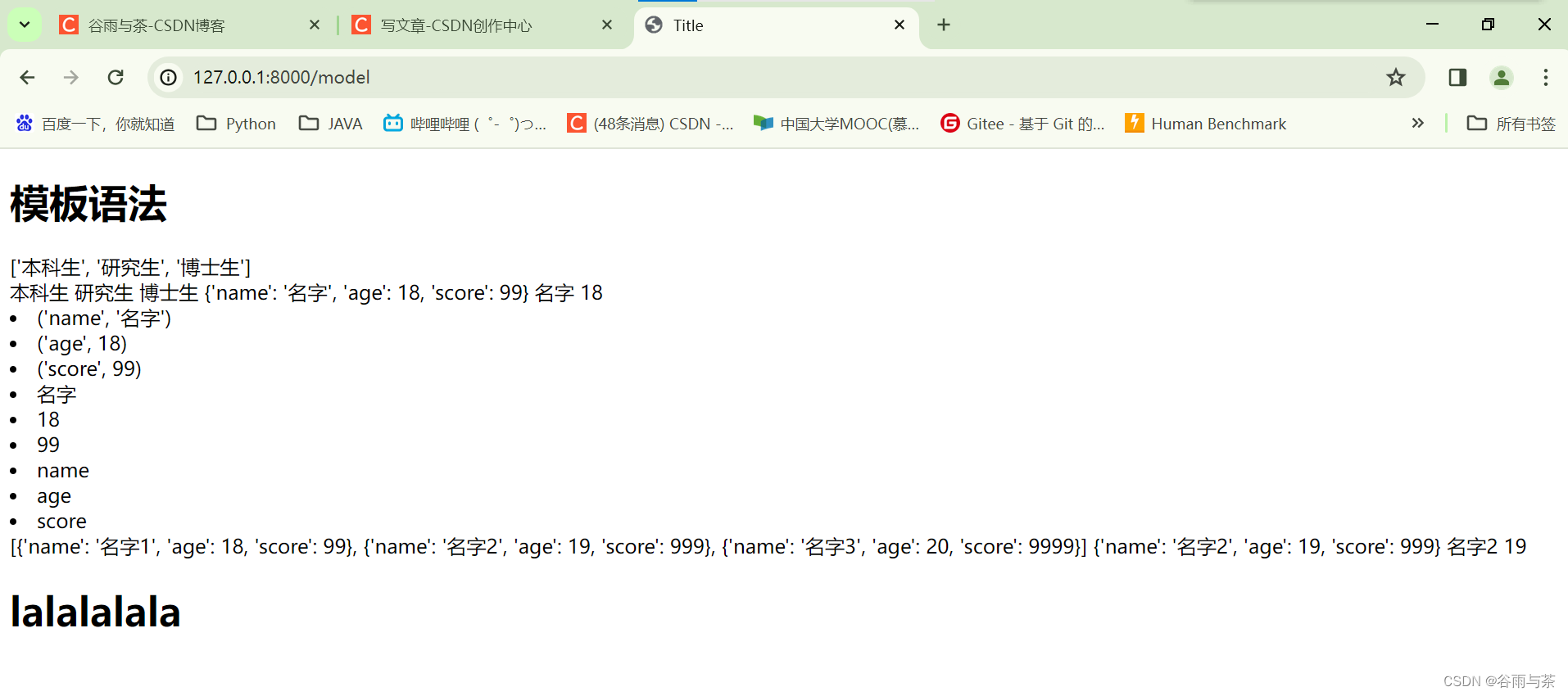
【Python + Django】Django模板语法 + 请求和响应
前言: 现在现在,我们要开始将变量的值展现在页面上面啦! 要是只会显示静态页面,我们的页面也太难看和死板了, 并且数据库的数据也没法展现在页面上。 但是呢,模板语法学习之后就可以啦!&…...

大数据面试总结 四
1、当hadoop集群中某一个节点挂了,内部数据流程是如何进行的? 每一个datanode都会定期向namenode发送heardbeat消息,当一段时间namenode没有接收到某一个datanode的消息,此时namenode就会将该datanode标记为死亡,并不…...

Spring Boot: 使用MongoOperations操作mongodb
一、添加依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4…...

PyTorch 深度学习(GPT 重译)(六)
十四、端到端结节分析,以及接下来的步骤 本章内容包括 连接分割和分类模型 为新任务微调网络 将直方图和其他指标类型添加到 TensorBoard 从过拟合到泛化 在过去的几章中,我们已经构建了许多对我们的项目至关重要的系统。我们开始加载数据…...

MyBatis3源码深度解析(十七)MyBatis缓存(一)一级缓存和二级缓存的实现原理
文章目录 前言第六章 MyBatis缓存6.1 MyBatis缓存实现类6.2 MyBatis一级缓存实现原理6.2.1 一级缓存在查询时的使用6.2.2 一级缓存在更新时的清空 6.3 MyBatis二级缓存的实现原理6.3.1 实现的二级缓存的Executor类型6.3.2 二级缓存在查询时使用6.3.3 二级缓存在更新时清空 前言…...

Go --- Go语言垃圾处理
概念 垃圾回收(GC-Garbage Collection)暂停程序业务逻辑SWT(stop the world)程序根节点:程序中被直接或间接引用的对象集合,能通过他们找出所有可以被访问到的对象,所以Go程序的根节点通常包括…...

力扣每日一题30:串联所有单词的子串
题目描述 给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。 s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。 例如,如果 words ["ab","cd","ef"], 那么 &q…...

vim | vim的快捷命令行
快捷进入shell界面 -> :nnoremap <F8> :sh<CR> -> 绑定到了F8 :nnoremap <F8> :sh<CR> 快捷执行 -> :nnoremap <F5> :wa<CR>:!g % -o a.out && ./a.out<CR> -> 绑定到了F5 :nnoremap <F5> :wa<CR>…...

项目管理平台-01-BugClose 入门介绍
拓展阅读 Devops-01-devops 是什么? Devops-02-Jpom 简而轻的低侵入式在线构建、自动部署、日常运维、项目监控软件 代码质量管理 SonarQube-01-入门介绍 项目管理平台-01-jira 入门介绍 缺陷跟踪管理系统,为针对缺陷管理、任务追踪和项目管理的商业…...
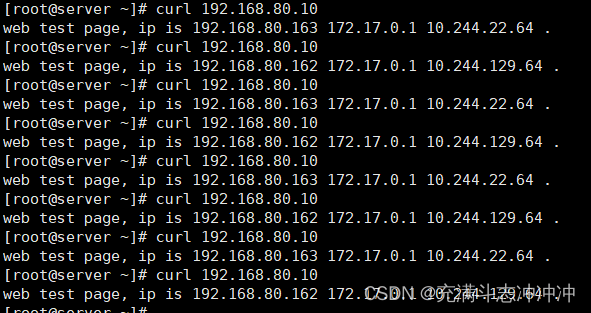
web集群-lvs-DR模式基本配置
目录 环境: 一、配置RS 1、安装常见软件 2、配置web服务 3、添加vip 4、arp抑制 二、配置LVS 1、添加vip 2、安装配置工具 3、配置DR 三、测试 四、脚本方式配置 1、LVS-DR 2、LVS-RS 环境: master lvs 192.168.80.161 no…...

基于深度学习的面部情绪识别算法仿真与分析
声明:以下内容均属于本人本科论文内容,禁止盗用,否则将追究相关责任 基于深度学习的面部情绪识别算法仿真与分析 摘要结果分析1、本次设计通过网络爬虫技术获取了七种面部情绪图片:吃惊、恐惧、厌恶、高兴、伤心、愤怒、自然各若…...
)
C语言经典面试题目(十六)
1、什么是C语言中的指针常量和指针变量?它们有什么区别? 在C语言中,指针常量和指针变量是指针的两种不同类型。它们的区别在于指针的指向和指针本身是否可以被修改。 指针常量:指针指向的内存地址不可变,但指针本身的…...
【C语言】文件操作揭秘:C语言中文件的顺序读写、随机读写、判断文件结束和文件缓冲区详细解析【图文详解】
欢迎来CILMY23的博客喔,本篇为【C语言】文件操作揭秘:C语言中文件的顺序读写、随机读写、判断文件结束和文件缓冲区详细解析【图文详解】,感谢观看,支持的可以给个一键三连,点赞关注收藏。 前言 欢迎来到本篇博客&…...

JAVA八股文面经问题整理第6弹
文章目录 目录 文章目录 提问问题 问题1 问题2 问题3 问题4 问题5 问题6 问题7 问题8 问题9 问题10 问题11 问题12 写在最后 提问问题 介绍一下Linux常⽤命令,例如:Vim快捷键,常⽤查看Log的命令,路径相关&#x…...

pytest相关面试题
pytest是什么?它有什么优点? pytest是一个非常流行的Python测试框架,它具有简洁、易用、高校等优点。他可以帮助测试人员方便地编写和运行测试用例,并且提供了丰富的插件和扩展,支持各种测试需求介绍下pytest常用的库 …...

Keras库搭建神经网络
Keras并非简单的神经网络库,而是一个基于Theano的强大的深度学习库,利用它不仅仅可以搭建普通的神经网络,还可以搭建各种深度学习模型,如自编码器、循环神经网络、递归神经网络、卷积神经网络等。 安装代码: pip ins…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

13456
12356...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...