使用 Amazon SageMaker 微调 Llama 2 模型

本篇文章主要介绍如何使用 Amazon SageMaker 进行 Llama 2 模型微调的示例。
这个示例主要包括:
Llama 2 总体介绍
Llama 2 微调介绍
Llama 2 环境设置
Llama 2 微调训练
前言
随着生成式 AI 的热度逐渐升高,国内外各种基座大语言竞相出炉,在其基础上衍生出种类繁多的应用场景。训练优异的基座大语言模型在通用性方面表现较好,但模型可能并未涉及到特定领域的专业术语、领域内的特定用语或上下文等。采用微调技术可以通过在领域特定数据上进行训练,使模型更好地适应目标领域的特殊语言模式和结构;结合基座模型的通用性和领域特定性,使得模型更具实际应用价值。
Llama 2 总体介绍
Llama 2 是 META 最新开源的 LLM,包括 7B、13B 和 70B 三个版本,训练数据集超过了 Llama 2 的 40%,达到 2 万亿 token;上下文长度也提升到 4K,可以极大扩展多轮对话的轮数、提示词输入数据;与此同时,Llama 2 Chat 模型使用基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),针对对话场景进行了大幅优化,达到了非常出色的有用性和安全性基准。HuggingFace 的 TGI 和 vLLM 等框架均有针对 Llama 2 的推理优化,进一步强化了 Llama 2 的可用性。
Llama 2 被认为是开源界大语言模型的首选,众多的垂类大模型均采用 Llama 2 作为基座大模型,在此基础上添加行业数据进行模型的预训练或者微调,适配更多的行业场景。
Llama 2 微调介绍
模型微调主要分为 Full Fine-Tune 和 PEFT (Performance-Efficient Fine-Tune),前者模型全部参数都会进行更新,训练时间较长,训练资源较大;而后者会冻结大部分参数、微调训练网络结构,常见的方式是 LoRA 和 P-Tuning v2。
PEFT 微调方式由于参数更新较少,可能导致模型无法学习到全部领域知识,对于特定任务或领域来说会出现推理不稳定的情况,因此大多数生产系统均使用全参数方式进行模型的微调。基于上述原因,本文会以全参数微调方式介绍 Llama 2 在 Amazon SageMaker 上的微调。
Llama 2 环境设置
备注:项目中的示例代码均保存于代码仓库,地址如下:
https://github.com/aws-samples/llm-workshop-on-amazon-sagemaker
1. 升级 Python SDK
pip install -U sagemaker2. 获取运行时资源,包括区域、角色、账号、S3 桶等
import boto3
import sagemaker
from sagemaker import get_execution_rolesess = sagemaker.Session()
role = get_execution_role()
sagemaker_default_bucket = sess.default_bucket()account = sess.boto_session.client("sts").get_caller_identity()["Account"]
region = sess.boto_session.region_nameLlama 2 微调训练
微调准备
克隆代码
采用 lm-sys 团队发布的 FastChat 平台进行 Llama 2 的微调,FastChat 也用于训练了知名的 Vicuna 模型,具有良好的代码规范和性能优化。
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
git reset --hard 974537efbd82093b45e64d07904efe7728193a52下载 Llama 2 原始模型
from huggingface_hub import snapshot_download
from pathlib import Pathlocal_cache_path = Path("./model")
local_cache_path.mkdir(exist_ok=True)model_name = "TheBloke/Llama-2-13B-fp16"# Only download pytorch checkpoint files
allow_patterns = ["*.json", "*.pt", "*.bin", "*.model", "*.py"]model_download_path = snapshot_download(repo_id=model_name,cache_dir=local_cache_path,allow_patterns=allow_patterns,revision='b2e65e8ad4bb35e5abaee0170ebd5fc2134a50bb'
)# Get the model files path
import os
from glob import globlocal_model_path = Nonepaths = os.walk(r'./model')
for root, dirs, files in paths:for file in files:if file == 'config.json':print(os.path.join(root,file))local_model_path = str(os.path.join(root,file))[0:-11]print(local_model_path)
if local_model_path == None:print("Model download may failed, please check prior step!")拷贝模型和数据到 Amazon S3
chmod +x ./s5cmd
./s5cmd sync ${local_model_path} s3://${sagemaker_default_bucket}/llm/models/llama2/TheBloke/Llama-2-13B-fp16/
rm -rf model模型微调
模型的微调使用全参数模型,以实现微调后模型的稳定性。
模型的微调使用开源框架 DeepSpeed 进行加速。
准备基础镜像
使用 Amazon SageMaker 定制的深度学习训练镜像作为基础镜像,再安装 Llama 2 训练所需的依赖包。Dockerfile 如下:
%%writefile Dockerfile
## You should change below region code to the region you used, here sample is use us-west-2
From 763104351884.dkr.ecr.us-west-2.amazonaws.com/huggingface-pytorch-training:1.13.1-transformers4.26.0-gpu-py39-cu117-ubuntu20.04 ENV LANG=C.UTF-8
ENV PYTHONUNBUFFERED=TRUE
ENV PYTHONDONTWRITEBYTECODE=TRUERUN pip3 uninstall -y deepspeed \&& pip3 install deepspeed==0.10.0 \&& pip3 install transformers==4.30.2## Make all local GPUs visible
ENV NVIDIA_VISIBLE_DEVICES="all"模型微调代码
模型微调源代码较多,细节可以参考上述 git 仓库。
微调参数
为了节省显存,采用 DeepSpeed Stage-3
训练过程开启 bf16,实现整数范围和精度的平衡
训练数据集采用官方提供的 dummy_conversation.json,也就是典型的 {"instruction"、"input"、"output"} 的格式,同时可以支持多轮对话
DEEPSPEED_OPTS="""FastChat/fastchat/train/train_mem.py --deepspeed ds.json --model_name_or_path "/tmp/llama_pretrain/" --data_path FastChat/data/dummy_conversation.json --output_dir "/tmp/llama_out" --num_train_epochs 1 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --gradient_accumulation_steps 4 --evaluation_strategy "no" --save_strategy "no" --save_steps 2000 --save_total_limit 1 --learning_rate 2e-5 --weight_decay 0. --warmup_ratio 0.03 --lr_scheduler_type "cosine" --logging_steps 1 --cache_dir '/tmp' --model_max_length 2048 --gradient_checkpointing True --lazy_preprocess True --bf16 True --tf32 True --report_to "none"
"""微调脚本
微调使用 torchrun + DeepSpeed 进行分布式训练
%%writefile ./src/ds-train-dist.sh
#!/bin/bash
CURRENT_HOST="${SM_CURRENT_HOST}"IFS=',' read -ra hosts_array <<< "${SM_HOSTS}"
NNODES=${#hosts_array[@]}
NODE_RANK=0for i in "${!hosts_array[@]}"; doif [[ "${hosts_array[$i]}" == *${CURRENT_HOST}* ]]; thenecho "host index:$i"NODE_RANK="$i" fi
doneMASTER_PORT="13579"
export NCCL_SOCKET_IFNAME="eth0"#Configure the distributed arguments for torch.distributed.launch.
GPUS_PER_NODE="$SM_NUM_GPUS"
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE \--nnodes $NNODES \--node_rank $NODE_RANK \--master_addr $MASTER_ADDR \--master_port $MASTER_PORT"chmod +x ./s5cmd
./s5cmd sync s3://$MODEL_S3_BUCKET/llm/models/llama2/TheBloke/Llama-2-13B-fp16/* /tmp/llama_pretrain/CMD="torchrun ${DISTRIBUTED_ARGS} ${DEEPSPEED_OPTS}"
echo ${CMD}
${CMD} 2>&1 if [[ "${CURRENT_HOST}" == "${MASTER_ADDR}" ]]; then ./s5cmd sync /tmp/llama_out s3://$MODEL_S3_BUCKET/llm/models/llama2/output/TheBloke/Llama-2-13B-fp16/$(date +%Y-%m-%d-%H-%M-%S)/
fi启动微调
全参数微调,需要使用至少一台 p4de.12xlarge(8 卡 A100 40GB)作为训练机器。
当微调完成后,训练好的模型自动存储于指定的 S3 桶内,可用于后续的模型部署推理。
import time
from sagemaker.estimator import Estimatorenvironment = {'MODEL_S3_BUCKET': sagemaker_default_bucket # The bucket to store pretrained model and fine-tune model
}base_job_name = 'llama2-13b-finetune'instance_type = 'ml.p4d.24xlarge'estimator = Estimator(role=role,entry_point='ds-train-dist.sh',source_dir='./src',base_job_name=base_job_name,instance_count=1,instance_type=instance_type,image_uri=image_uri,environment=environment,disable_profiler=True,debugger_hook_config=False)estimator.fit()总结
大语言模型方兴未艾,正在以各种方式改变和影响着整个世界。客户拥抱大语言模型,亚马逊云科技团队同样在深耕客户需求和大语言模型技术,可以在未来更好地协助客户实现需求,提升业务价值。
本篇作者

高郁
亚马逊云科技解决方案架构师,主要负责企业客户上云,帮助客户进行云架构设计和技术咨询,专注于智能湖仓、AI/ML 等技术方向。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!

相关文章:
使用 Amazon SageMaker 微调 Llama 2 模型
本篇文章主要介绍如何使用 Amazon SageMaker 进行 Llama 2 模型微调的示例。 这个示例主要包括: Llama 2 总体介绍Llama 2 微调介绍Llama 2 环境设置Llama 2 微调训练 前言 随着生成式 AI 的热度逐渐升高,国内外各种基座大语言竞相出炉,在其基础上衍生出…...
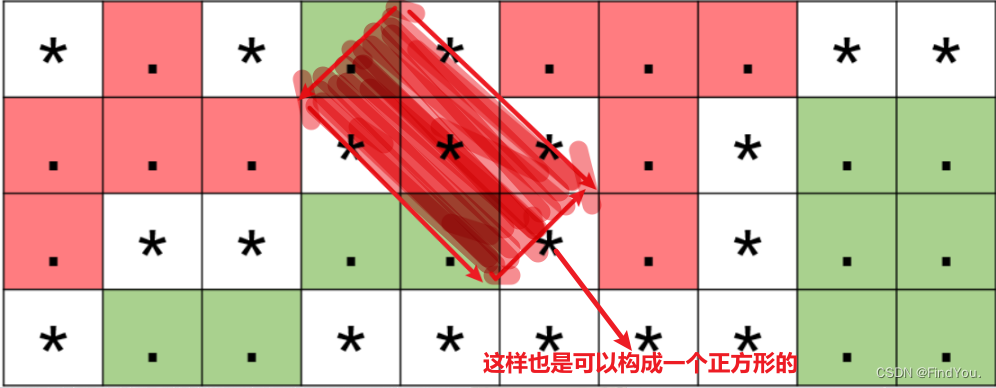
牛客小白月赛86(D剪纸游戏)
题目链接:D-剪纸游戏_牛客小白月赛86 (nowcoder.com) 题目描述: 输入描述: 输入第一行包含两个空格分隔的整数分别代表 n 和 m。 接下来输入 n行,每行包含 m 个字符,代表残缺纸张。 保证: 1≤n,m≤10001 字符仅有 . 和 * 两种字符…...
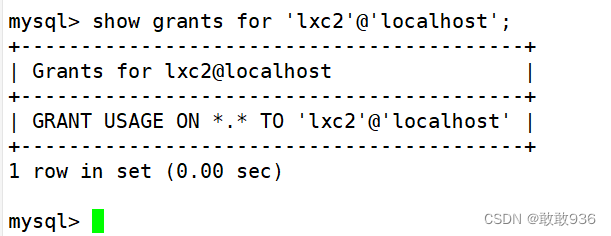
MySQL的基础操作与管理
一.MySQL数据库基本操作知识: 1.SQL语句: 关系型数据库,都是使用SQL语句来管理数据库中的数据。 SQL,即结构化查询语言(Structured Query Language) 。 SQL语句用于维护管理数据库,包括数据查询、数据更新、访问控…...

Pytorch 中的forward 函数内部原理
PyTorch中的forward函数是nn.Module类的一部分,它定义了模型的前向传播规则。当你创建一个继承自nn.Module的类时,你实际上是在定义网络的结构。forward函数是这个结构中最关键的部分,因为它指定了数据如何通过网络流动。 单独设计 forward …...
四、C语言中的数组:如何输入与输出二维数组(数组,完)
本章的学习内容如下 四、C语言中的数组:数组的创建与初始化四、C语言中的数组:数组的输入与元素个数C语言—第6次作业—十道代码题掌握一维数组四、C语言中的数组:二维数组 1.二维数组的输入与输出 当我们输入一维数组时需要一个循环来遍历…...
基于python+vue智慧农业小程序flask-django-php-nodejs
传统智慧农业采取了人工的管理方法,但这种管理方法存在着许多弊端,比如效率低下、安全性低以及信息传输的不准确等,同时由于智慧农业中会形成众多的个人文档和信息系统数据,通过人工方法对知识科普、土壤信息、水质信息、购物商城…...

好用的GPTs:指定主题搜索、爬虫、数据清洗、数据分析自动化
好用的GPTs:指定主题搜索、爬虫、数据清洗、数据分析自动化 Scholar:搜索 YOLO小目标医学方面最新论文Scraper:爬虫自动化数据清洗数据分析 点击 Explore GPTs: Scholar:搜索 YOLO小目标医学方面最新论文 搜索 Scho…...

使用Qt自带windeployqt打包QML的exe
1.在开始菜单输入CMD找到对应的Qt开发版本,我的是Qt5.15.2(MinGW 8.1.0 64-bit)。 2.在控制台输入如下字符串,格式为 windeployqt exe绝对路径 --qmldir 工程的绝对路径 如下是我的打包代码。 我需要打包的exe的绝对路径 D:\Prj\Code\Demo\QML\Ana…...

C代码快速傅里叶变换-分类和推理-常微分和偏微分方程
要点 C代码例程函数计算实现: 线性代数方程解:全旋转高斯-乔丹消元,LU分解前向替换和后向替换,对角矩阵处理,任意矩阵奇异值分解,稀疏线性系统循环三对角系统解,将矩阵从完整存储模式转换为行索…...

计算机组成原理 双端口存储器原理实验
一、实验目的 1、了解双端口静态随机存储器IDT7132的工作特性及使用方法 2、了解半导体存储器怎样存储和读出数据 3、了解双端口存储器怎样并行读写,产生冲突的情况如何 二、实验任务 (1)按图7所示,将有关控制信号和和二进制开关对应接好,…...

[音视频学习笔记]六、自制音视频播放器Part1 -新版本ffmpeg,Qt +VS2022,都什么年代了还在写传统播放器?
前言 参考了雷神的自制播放器项目,100行代码实现最简单的基于FFMPEGSDL的视频播放器(SDL1.x) 不过老版本的代码参考意义不大了,我现在准备使用Qt VS2022 FFmpeg59重写这部分代码,具体的代码仓库如下: …...

GPT-5可能会在今年夏天作为对ChatGPT的“实质性改进”而到来
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
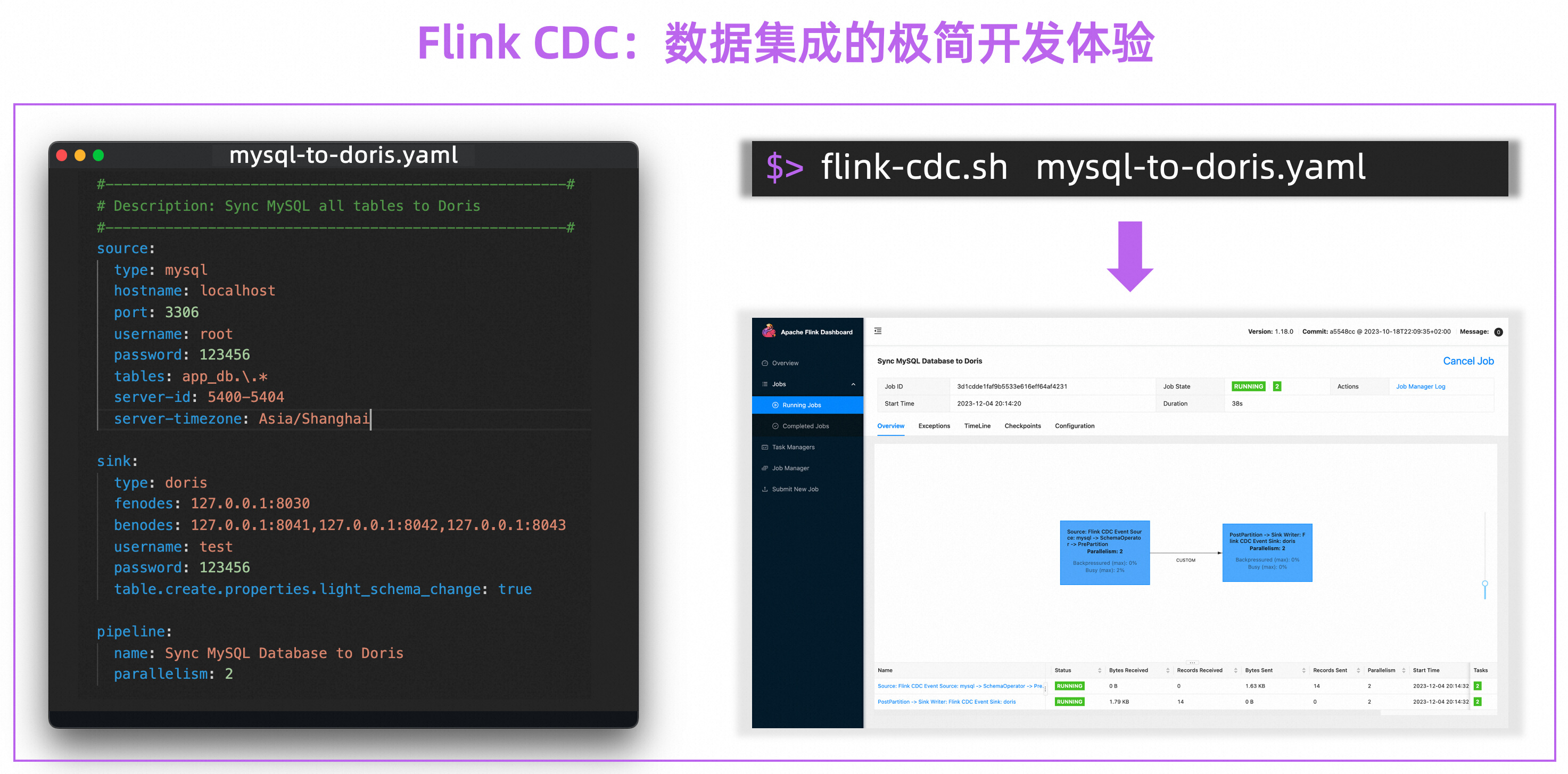
官宣|阿里巴巴捐赠的 Flink CDC 项目正式加入 Apache 基金会
摘要:本文整理自阿里云开源大数据平台徐榜江 (雪尽),关于阿里巴巴捐赠的 Flink CDC 项目正式加入 Apache 基金会,内容主要分为以下四部分: 1、Flink CDC 新仓库,新流程 2、Flink CDC 新定位,新玩法 3、Flin…...

部署单节点k8s并允许master节点调度pod
安装k8s 需要注意的是k8s1.24 已经弃用dockershim,现在使用docker需要cri-docker插件作为垫片,对接k8s的CRI。 硬件环境: 2c2g 主机环境: CentOS Linux release 7.9.2009 (Core) IP地址: 192.168.44.161 一、 主机配…...

Django日志(三)
内置TimedRotatingFileHandler 按时间自动切分的log文件,文件后缀 %Y-%m-%d_%H-%M-%S , 初始化参数: 注意 发送邮件的邮箱,开启SMTP服务 filename when=h 时间间隔类型,不区分大小写 S:秒 M:分钟 H:小时 D:天 W0-W6:星期几(0 = 星期一) midnight:如果atTime未指定,…...
【吾爱破解】Android初级题(二)的解题思路 _
拿到apk,我们模拟器打开看一下 好好,抽卡模拟器是吧😀 jadx反编译看一下源码 找到生成flag的地方,大概逻辑就是 java signatureArr getPackageManager().getPackageInfo(getPackageName(), 64).signaturesfor (int i 0; i &l…...

富格林:谨记可信计策安全做单
富格林悉知,现货黄金由于活跃的行情给投资者带来不少的盈利的机会,吸引着众多的投资者进场做单。但在黄金投资市场中一定要掌握可信的投资方法,提前布局好策略,这样才能增加安全获利的机会。不建议直接进入市场做单,因…...

【工具使用】mingw64编译完成运行可执行文件时出现乱码
一,问题现象: notepad设置的时UTF-8编码: mingw64命令行设置的编码格式为: 二,问题原因: 在执行的时候,windows下的编码格式是GBK 三,解决方法: 编译时࿰…...
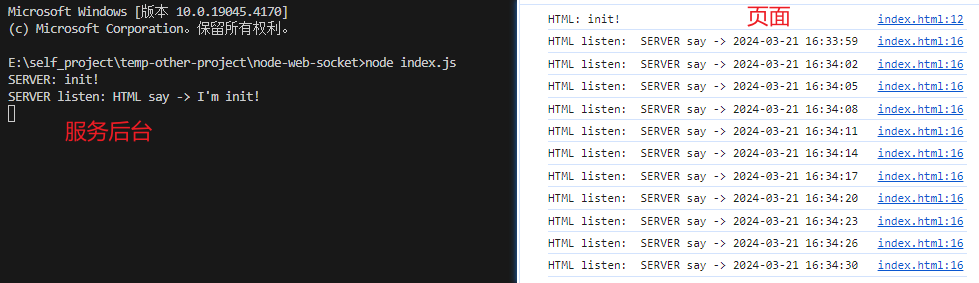
WebSocket 使用示例,后台为nodejs
效果图 页面代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>WebSocket Client</title&g…...

【算法】力扣【树形DP】687. 最长同值路径
【算法】力扣【树形DP】687. 最长同值路径 687. 最长同值路径 文章目录 【算法】力扣【树形DP】687. 最长同值路径题目描述输入输出示例 题解思路代码描述 复杂度分析总结 题目描述 本题要求在给定的二叉树中寻找最长的同值路径,这个路径中的每个节点的值都相同。…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

从《吃豆人》到开放世界:聊聊Unity Navigation里Agent Radius和Cost的那些‘潜规则’
从《吃豆人》到开放世界:Unity Navigation中Agent Radius与Cost的隐藏逻辑1980年诞生的《吃豆人》用简单的迷宫路径定义了早期游戏AI的移动规则——幽灵们沿着固定路线巡逻,遇到转角时随机选择方向。这种设计在当时堪称革命性,但以今天的标准…...

纯硬件实现I2C协议:从逻辑门到传感器通信的深度实践
1. 项目概述:用纯硬件“解剖”I2C总线很多朋友在玩传感器,尤其是温湿度传感器时,都绕不开I2C这个通信协议。市面上绝大多数的教程和方案,都会告诉你:找个单片机(比如Arduino、STM32),…...

白嫖Codex!一行代码不花接入国产DeepSeek-v4-pro,从此告别ChatGPT月费
Codex 如何接入国产模型 DeepSeek-v4-pro 保姆级教程 使用 Claude Code、Codex 已经好几个月了,不得不感叹现在的 AI 工具真的太强大了。目前市面上很多 Claude Code 如何接入大模型的教程,但 Codex 却比较少,一方面因为 Codex 需要 ChatGPT …...