glibc内存管理ptmalloc
1、前言
今天想谈谈ptmalloc如何为应用程序分配释放内存的,基于以下几点原因才聊它:
- C/C++ 70%的问题是内存问题。了解一点分配器原理对解决应用程序内存问题肯定有帮助。
- C++也在用ptmalloc. 当你在C++中new一个对象时,底层还是依赖glibc中的ptmalloc.
- 虽然市面上还有jemalloc/tcmalloc, 但ptmalloc被glibc内嵌,用的最广.
2、初识ptmalloc
ptmalloc是glibc(GNU C库)中使用的内存分配器,它基于dlmalloc(Doug Lea’s Malloc)的设计。ptmalloc的主要目标是为多线程应用程序提供高效的内存分配和释放,其名称中的“pt”代表“pthreads”,即POSIX线程库。
ptmalloc所有版本的源代码可在Index of /gnu/glibc下载,其中2.26为了增强多线程情况下的性能引入了tcache, 不过为了使讲解简单,我们还是以2.26之前的版本2.17来分析其原理。
相信很多程序员都思考过一个问题而且也知道答案:
free函数释放内存时只有一个参数 -- 要释放内存的指针,那要释放多大的内存哪???
答案就是这块内存前面的8个字节(64bit下,之后默认都是64bit)存了这块内存大小,让我们看个例子快速入门一下:
void *p1= malloc(10);
memset(p1,'a',10);
就像大大小小不同种类的卡车都有个车斗拉东西,ptmalloc的卡车叫malloc chunk用来拉内存, 它有自重,0x602000~0x602010便是自重(大小:0x10字节,有个特例,以后再说),对用户来说浪费掉了不能用来拉东西,还剩0x20-0x10=0x10个字节可以放用户数据,比我们申请的10个字节多一点点,这是故意预留的。

ptmalloc本质就是一个内存缓冲池,缓存的最小单位就是malloc chunk. 之后我们提到chunk或者malloc chunk都是一个东西。即使free的内存实际可能并没有free,而是被ptmalloc管理了起来。
3、卡车的定义 malloc_chunk
通过上面的例子我们看到了卡车的一个零部件:size(卡车大小)。那它有其它零部件吗?让我们看下它的庐山真面目:
struct malloc_chunk
{INTERNAL_SIZE_T prev_size; /* 上一个malloc_chunk的size(如果它是free状态). */INTERNAL_SIZE_T size; /* 本malloc_chunk的size,包括16个字节的自重 */struct malloc_chunk *fd; /* 用来构造双向链表 -- 仅仅用在free的chunk上. */struct malloc_chunk *bk; /* 用来构造双向链表 -- 仅仅用在free的chunk上. *//* 以下两个字段用在large chunk上,以后介绍. */struct malloc_chunk *fd_nextsize; struct malloc_chunk *bk_nextsize;
};正如代码组织所暗示,两两一组, prev_size & size, fd & bk, fd_nextsize & bk_nextsize.
后两组只有在本chunk free的状态下才有意义,不然就存储用户数据。
3.1、prev_size & size 物理相邻的chunk
prev_size表示上个chunk的大小,只有上个chunk是free时才有此意义。size表示本chunk大小,但是最后三位从最不重要的位开始由特别意义分别表示:
- 物理上上个chunk在用(非free, PREV_INUSE)
- 本chunk是由mmap()分配的(IS_MMAPPED)
- 本chunk是属于非主arena的(NON_MAIN_ARENA)
我们着重讲下第一个PREV_INUSE:
所有的chunk在物理上都是相邻的,就像火车车厢一样连在一起,
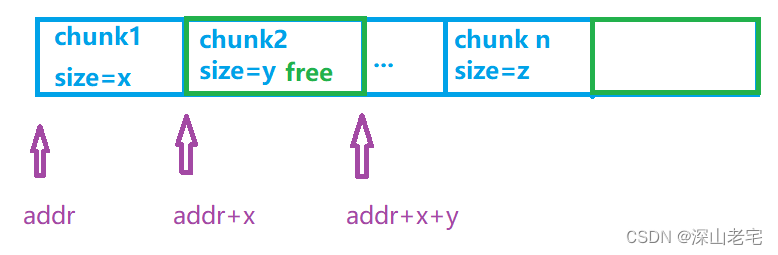 不过与直觉相反的是:不是自己表示自己空不空,而是由下一个chunk表示上一个chunk空不空(原因在下面的总结中)。
不过与直觉相反的是:不是自己表示自己空不空,而是由下一个chunk表示上一个chunk空不空(原因在下面的总结中)。
下面看个例子理解下PREV_INUSE、prev_size:
int main(int argc, char* argv[])
{void *p1= malloc(192); //192是故意的,较小的数字free后会到fastbin中//PREV_INUSE依然保持1,那样达不到演示PREV_INUSE的效果memset(p1,'a',192); //原因在fastbin中介绍void *p2= malloc(20);memset(p2,'b',20);free(p1);
}调试到free但还没free,通过下图理解下p2所在malloc chunk前两个字段的意义。

(gdb) p *(mchunkptr)(p2-16)
$2 = {prev_size = 0, size = 33, fd = 0x6262626262626262, bk = 0x6262626262626262, fd_nextsize = 0x62626262,bk_nextsize = 0x20f11}然后把p1释放,再看下p2 malloc chunk.size:

(gdb) p *(mchunkptr)(p2-16)
$3 = {prev_size = 208, size = 32, fd = 0x6262626262626262, bk = 0x6262626262626262, fd_nextsize = 0x62626262,bk_nextsize = 0x20f11}
这里眼尖的同学可能已经注意到prev_size只有在上个chunk free的状态下有意义,如果上个chunk分配给用户了则什么也没存,浪费掉了!ptmalloc的作者早就想到了这一点:prev_size这8个字节还真可以让渡给上个chunk用来存用户数据,我们把上面程序中的192改成194或者200看一看

总结一下:
1. prev size, prev inuse中的prev指的是物理上相邻的两个chunk的前一个(内存地址小的那个)
2. size字段指本chunk自己的size大小,包括自重(overhead)。size的最不重要的三位(bit)是三个flag,其中最后那个位(bit)表示上个chunk是否free,如果上个chunk是free则prev_size有意义且表示上个chunk的size。为什么要在一个chunk里存上一个chunk的size哪?这是为了方便两者都是free时好合并成一个大的chunk, p - prev_size就指向了上一个chunk。
3. malloc_chunk虽然有这么多数据成员,但只有size永远有意义,为了提高负载率其它字段在某种情况下会被用来放用户数据:a. 本chunk假如分配出去了(malloc),则fd、bk、fd_nextsize、bk_nextsize都无意义,可以用来放用户数据; b. 上个chunk假如分配出去了(malloc)且malloc的大小%8<=8, 则本chunk的prev_size字段会被用来存储上个chunk的用户数据。
3.2、fd & bk 逻辑上把free的chunk串起来
ptmalloc中有个bin的概念,正如字面意思就是回收垃圾用的垃圾桶(放free掉的chunk),bin有如下几类:
fastbin - 单向链表,放小chunk,默认为小到0x20大到0x80大小的,以16字节递进。比如main_arena.fastbinsY[0]指向大小为0x20的chunk链表,main_arena.fastbinsY[1]指向大小为0x30的chunk链表...
unsortedbin - 双向链表,临时垃圾桶,里面的chunk的size不一致。
smallbin - 双向链表,也是放小chunk,但上限到0x3F0, 以16字节递进, 共62个smallbin。
largebin - 双向链表,放大chunk, 63个.(largebin本节不具体展开)
main_arena是一个全局变量,它是一个很好的入口去找到这些bin,如下图示:
4、fastbin
fastbin, 正如它的名字,是用的最频繁的bin。当一块小内存被释放后,极大可能会被放到对应大小的fastbin链条上的,以加快下次分配同样大小的内存。
void* p1 = malloc(10);
free(p1);
void* p2 = malloc(10);上面这段代码,p1 p2应该是相等的。
fastbin是单链表,fd指向下一个;先释放的在链尾,后释放的放在链头。也就是说那些最近别使用过得内存更容易被再次使用;那些很久以前free掉最近都没用过的内存,有较大的概率被swap out了,重新使用的代价可能较大。
下面看个例子:
int main(int argc, char* argv[])
{void *p1= malloc(10);memset(p1,'a',10);void *p2= malloc(10);memset(p2,'b',10);void *p3= malloc(30);memset(p3,'c',10);void *p4= malloc(30);memset(p4,'d',10);free(p1);free(p2);free(p3);free(p4);getchar();
#链接我自己编译出来的glibc
[mzhai]$ gcc fastbin.c -I/usr/local/glibc-2.17/include -L/usr/local/glibc-2.17/lib -Wl,--rpath=/usr/local/glibc-2.17/lib -Wl,--rpath=/lib64 -Wl,--dynamic-linker=/usr/local/glibc-2.17/lib/ld-2.17.so -g
[mzhai]$ gdb ./a.out运行到getchar, 看下fastbinsY[0] & [1],
(gdb) p main_arena
$2 = {mutex = 0, flags = 0, fastbinsY = {0x602020, 0x602070, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x6020a0,last_remainder = 0x0, bins = {0x7ffff7dd7678 <main_arena+88>, 0x7ffff7dd7678 <main_arena+88>,#chunk大小为0x20的链表.
(gdb) p /x *(mchunkptr)0x602020
$7 = {prev_size = 0x0, size = 0x21, fd = 0x602000, bk = 0x6262, fd_nextsize = 0x0, bk_nextsize = 0x31}
(gdb) p /x *(mchunkptr)0x602000
$8 = {prev_size = 0x0, size = 0x21, fd = 0x0, bk = 0x6161, fd_nextsize = 0x0, bk_nextsize = 0x21}#chunk大小为0x30的链表。
(gdb) p /x *(mchunkptr)0x602070
$9 = {prev_size = 0x0, size = 0x31, fd = 0x602040, bk = 0x6464, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p /x *(mchunkptr)0x602040
$10 = {prev_size = 0x0, size = 0x31, fd = 0x0, bk = 0x6363, fd_nextsize = 0x0, bk_nextsize = 0x0}

fastbin共有最多10个链表 ,已由arena.fastbinY[10]限制死,默认7个。用户能通过mallopt(M_MXFAST, value)个性化设置链表个数,但意义不大,最多也就10个。

5、unsortedbin
双向链表,临时垃圾桶,里面的chunk的size不一致。
是第二常用的bin,free时没进fastbin则大概率要进unsortedbin. 之后的malloc可能会把unsortedbin上的chunk挪到smallbin.
int main(int argc, char* argv[])
{void *p1= malloc(200);memset(p1,'a',200);void *temp1= malloc(10); //把p1 p2隔开,防止合并memset(temp1,'b',10);void *p2= malloc(300);memset(p2,'a',300);void *temp2= malloc(10); //把p2 top 隔开,防止合并memset(temp2,'c',10);free(p1);free(p2);getchar();
调试到getchar,
(gdb) p main_arena
$1 = {mutex = 0, flags = 1, fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x602250,
last_remainder = 0x0, bins = {0x6020f0, 0x602000(gdb) p *(mchunkptr)0x6020f0
$4 = {prev_size = 0, size = 321, fd = 0x602000, bk = 0x7ffff7dd7678 <main_arena+88>, fd_nextsize = 0x6161616161616161,
bk_nextsize = 0x6161616161616161}
(gdb) p *(mchunkptr)0x602000
$5 = {prev_size = 0, size = 209, fd = 0x7ffff7dd7678 <main_arena+88>, bk = 0x6020f0, fd_nextsize = 0x6161616161616161,
bk_nextsize = 0x6161616161616161}

6、smallbin
双向链表,也是放小chunk,但上限到0x3F0, 以16字节递进, 共62个smallbin。
smallbin与unsortedbin相似,都是双向链表,不同的是:smallbin每个链上chunk大小相等,这一点与fastbin一致。
free时不会直接往smallbin里扔chunk,而是malloc时把unsortedbin里的chunk整理到对应的smallbin链上。
请看下面的例子:
int main(int argc, char* argv[])
{void *p1= malloc(30);void *temp1= malloc(10);void *p2= malloc(30);void *temp2= malloc(10);void *p3= malloc(30);void *temp3= malloc(10);free(p1);free(p2);free(p3); //fastbin 0x30链表上p3->p2->p1void* large = malloc(1024); //fastbin->unsortedbin->smallbingetchar();
free(p3)后
(gdb) p main_arena
$1 = {mutex = 0, flags = 0, fastbinsY = {0x0, 0x6020a0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x6020f0,
last_remainder = 0x0, bins = {0x7ffff7dd7678 <main_arena+88>, 0x7ffff7dd7678 <main_arena+88>,
0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7698 <main_arena+120>,(gdb) p *(mchunkptr)0x6020a0
$2 = {prev_size = 0, size = 49, fd = 0x602050, bk = 0x0, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p *(mchunkptr)0x602050
$3 = {prev_size = 0, size = 49, fd = 0x602000, bk = 0x0, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p *(mchunkptr)0x602000
$4 = {prev_size = 0, size = 49, fd = 0x0, bk = 0x0, fd_nextsize = 0x0, bk_nextsize = 0x0}
之后要分配1024字节,加上自重共1040个字节,借助这个malloc我们过一下malloc的大体流程:
1. 首先从fastbin中寻找。因为1040大于fastbin的范围(0x20~0x80/0xa0),找不到。
if ((unsigned long)(nb) <= (unsigned long)(get_max_fast ())) 2. 从smallbin中寻找。1040已超过smallbin的范围。
3315 if (in_smallbin_range(nb))
3355 else {
3356 idx = largebin_index(nb);
3357 if (have_fastchunks(av))
3358 malloc_consolidate(av); //fastbin -> unsortedbin //只有要申请的字节数>=1024 且 fastbin不空 才触发 fastbin -> unsortedbin //这才是我们的例子中要申请1024字节的原因
3359 } (gdb) p main_arena
$7 = {mutex = 1, flags = 1, fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x6020f0,
last_remainder = 0x0, bins = {0x602000, 0x6020a0, 0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7688 <main_arena+104>,
0x7ffff7dd7698 <main_arena+120>, 0x7ffff7dd7698 <main_arena+120>, 0x7ffff7dd76a8 <main_arena+136>,(gdb) p *(mchunkptr)0x602000
$8 = {prev_size = 0, size = 49, fd = 0x602050, bk = 0x7ffff7dd7678 <main_arena+88>, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p *(mchunkptr)0x602050
$9 = {prev_size = 0, size = 49, fd = 0x6020a0, bk = 0x602000, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p *(mchunkptr)0x6020a0
$10 = {prev_size = 0, size = 49, fd = 0x7ffff7dd7678 <main_arena+88>, bk = 0x602050, fd_nextsize = 0x0, bk_nextsize = 0x0}fastbin上的3个chunk 已被move到 unsortedbin上
3. 整理unsortedbin上的chunk到smallbin/largebin上
3377 while ( (victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) {
//从unsortedbin的最后一个chunk开始,unsorted_chunks(av)是那个虚拟chunk3422 /* 把victic从unsortedbin上摘下来 */
3423 unsorted_chunks(av)->bk = bck;
3424 bck->fd = unsorted_chunks(av); 3439 /* 把victim放到相应的bin上(smallbin、largebin) */
3440
3441 if (in_smallbin_range(size)) {
3442 victim_index = smallbin_index(size);
3443 bck = bin_at(av, victim_index);
3444 fwd = bck->fd;
3445 }
3446 else {
3447 victim_index = largebin_index(size);
3448 bck = bin_at(av, victim_index);
3449 fwd = bck->fd; 4. 搜索largebin
5. 从top chunk割一块下来
chunk move的过程,fastbin -> unsortedbin -> smallbin/largebin
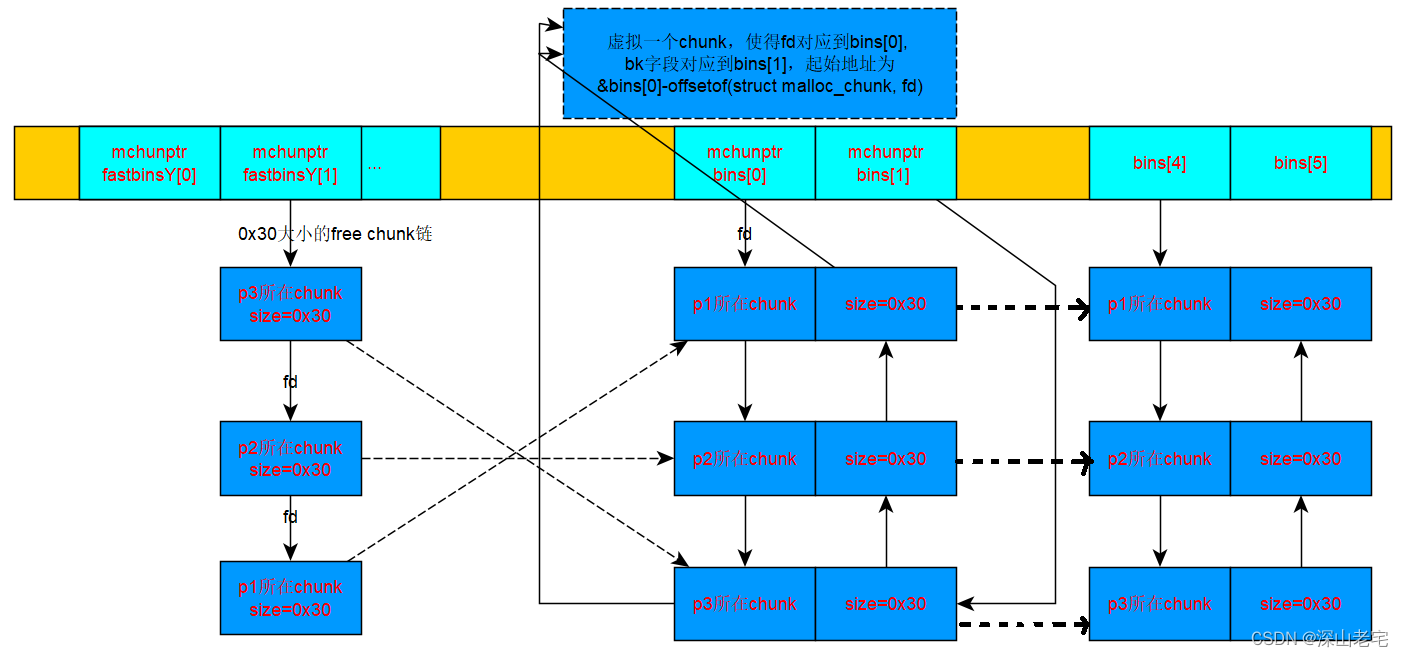
虽然这个例子很好的演示了chunk move的过程,但并没有诠释move的意义:正如malloc_consolidate名字所暗示的,它会合并fastbin中相邻的chunk以减少碎片,要知道fastbin的哲学是期盼同样小的内存申请很快到来,所以它不会合并相邻的chunk,这样时间长了碎片就会很多。看下面这个例子:
int main(int argc, char* argv[])
{void *p1= malloc(30);void *temp1= malloc(10);void *p2= malloc(30);void *temp2= malloc(10);void *p3= malloc(30);void *temp3= malloc(10);free(p1);free(p2);free(p3);void* large = malloc(1024);
(gdb) p main_arena
$1 = {mutex = 0, flags = 1, fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x6024d0,
last_remainder = 0x0, bins = {0x7ffff7dd7678 <main_arena+88>, 0x7ffff7dd7678 <main_arena+88>,
0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7698 <main_arena+120>,
0x7ffff7dd7698 <main_arena+120>, 0x7ffff7dd76a8 <main_arena+136>, 0x7ffff7dd76a8 <main_arena+136>,
0x7ffff7dd76b8 <main_arena+152>, 0x7ffff7dd76b8 <main_arena+152>, 0x7ffff7dd76c8 <main_arena+168>,
0x7ffff7dd76c8 <main_arena+168>, 0x7ffff7dd76d8 <main_arena+184>, 0x7ffff7dd76d8 <main_arena+184>,
0x7ffff7dd76e8 <main_arena+200>, 0x7ffff7dd76e8 <main_arena+200>, 0x602000, 0x602000,(gdb) p *(mchunkptr)0x602000
$2 = {prev_size = 0, size = 145, fd = 0x7ffff7dd76f8 <main_arena+216>, bk = 0x7ffff7dd76f8 <main_arena+216>,
fd_nextsize = 0x0, bk_nextsize = 0x0}
三个相邻的小碎片被 合体了!
相关文章:
glibc内存管理ptmalloc
1、前言 今天想谈谈ptmalloc如何为应用程序分配释放内存的,基于以下几点原因才聊它: C/C 70%的问题是内存问题。了解一点分配器原理对解决应用程序内存问题肯定有帮助。C也在用ptmalloc. 当你在C中new一个对象时,底层还是依赖glibc中的ptma…...
HarmonyOS入门学习
HarmonyOS入门学习 前言快速入门ArkTS组件基础组件Image组件Text组件TextInput 文本输入框Buttonslider 滑动组件 页面布局循环控制ForEach循环创建组件 List自定义组件创建自定义组件Builder 自定义函数 状态管理Prop和LinkProvide和ConsumeObjectLink和Observed ArkUI页面路由…...
【Mock|JS】Mock的get传参+获取参数信息
mockjs的get传参 前端请求 const { data } await axios("/video/childcomments", {params: {sort: 1,start: 2,count: 5,childCount: 6,commenIndex: 0,},});后端获取参数 使用正则匹配url /*** # 根据url获取query参数* param {Url} urlStr get请求获取参数 eg:…...

spring cloud gateway k8s优雅启停
通过配置readiness探针和preStop hook,实现优雅启动和停止(滚动部署) 1. k8s工作负载配置 readinessProbe:httpGet:path: /datetimeport: 8080scheme: HTTPinitialDelaySeconds: 30timeoutSeconds: 1periodSeconds: 30successThreshold: 1fa…...

嵌入式软件面试-linux-中高级问题
Linux系统启动过程: BIOS自检并加载引导程序。引导程序(如GRUB)加载Linux内核到内存。内核初始化硬件,加载驱动,建立内存管理。加载init进程(PID为1),通常是systemd或SysVinit。init…...

css禁用元素指针事件,鼠标穿透,点击下层元素,用`pointer-events:none;`
pointer-events: 对鼠标事件的反应 MDN pointer-events 英文 https://developer.mozilla.org/en-US/docs/Web/CSS/pointer-events 菜鸟教程 CSS pointer-events 属性 https://www.runoob.com/cssref/css3-pr-pointer-events.html 常用取值 auto 和 none pointer-events: aut…...

Eureka的介绍和作用,以及搭建
一、Eureka的介绍和作用 Eureka是Netflix开源的一种服务发现和注册工具,它为分布式系统中的服务提供了可靠的服务发现和故障转移能力。Eureka是Netflix的微服务架构的关键组件之一,它能够实时地监测和管理服务实例的状态和可用性。 在Eureka架构中&…...

shell和linux的关系
Shell 和 Linux 之间存在密切的关系,但它们并不是同一个东西。让我们分别了解一下它们: Linux: Linux 是一个自由和开放源代码的类UNIX操作系统。 Linux 的内核由林纳斯托瓦兹(Linus Torvalds)于1991年首次发布&…...
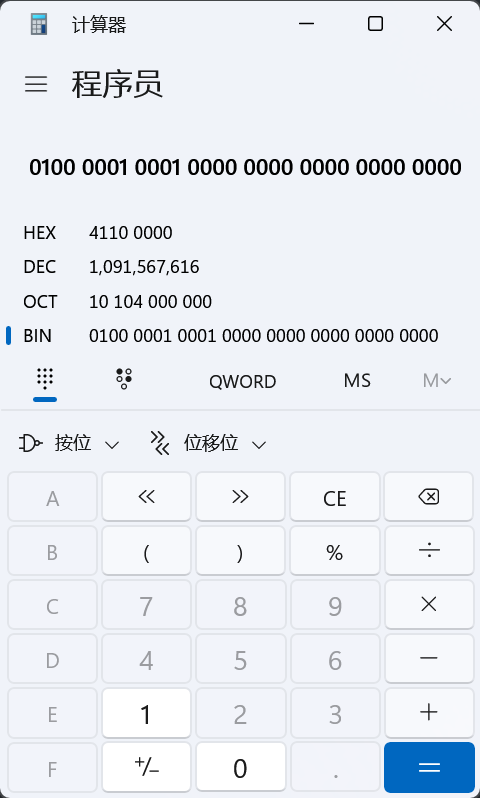
数据在内存的存储
整数在内存中的存储 我们来回顾一下,整数在计算机是以补码的形式进行存储的,整数分为正整数和负整数,正整数的原码、反码和补码是一样的,负整数的原码、反码和补码略有不同(反码是原码除符号位,其他位按位取…...

JavaScript之ES中的类继承与Promise
类 ES5中的类及继承 //人function Person(name,age){this.name name;this.age age;}Person.prototype.eat function () {console.log(this.name "eat");}//程序员,继承,人function Programmer(name,age,language){//构造函数继承Person.…...
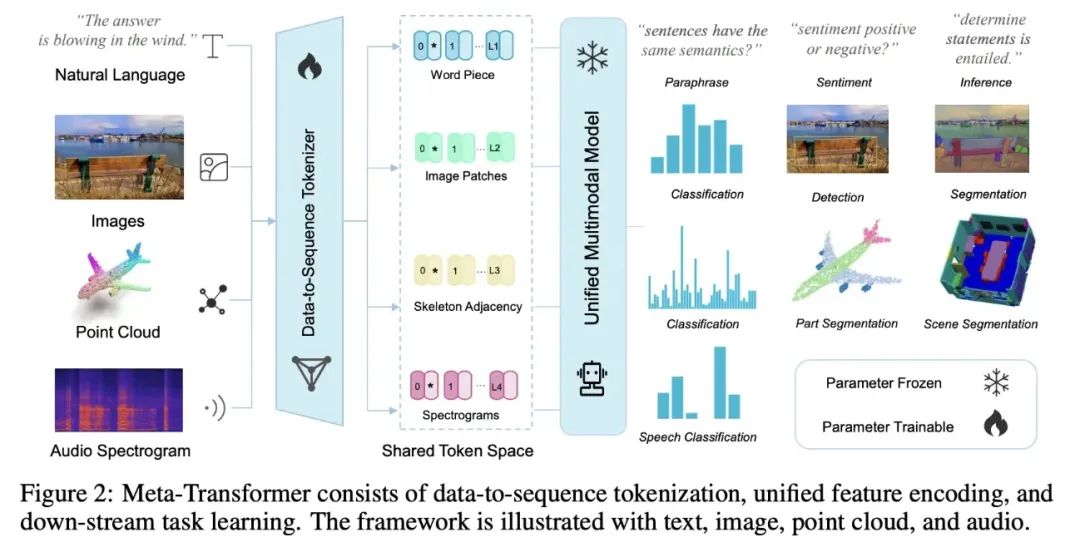
浅析多模态大模型技术路线梳理
前段时间 ChatGPT 进行了一轮重大更新:多模态上线,能说话,会看图!微软发了一篇长达 166 页的 GPT-4V 测评论文,一时间又带起了一阵多模态的热议,随后像是 LLaVA-1.5、CogVLM、MiniGPT-5 等研究工作紧随其后…...

使用 Amazon SageMaker 微调 Llama 2 模型
本篇文章主要介绍如何使用 Amazon SageMaker 进行 Llama 2 模型微调的示例。 这个示例主要包括: Llama 2 总体介绍Llama 2 微调介绍Llama 2 环境设置Llama 2 微调训练 前言 随着生成式 AI 的热度逐渐升高,国内外各种基座大语言竞相出炉,在其基础上衍生出…...
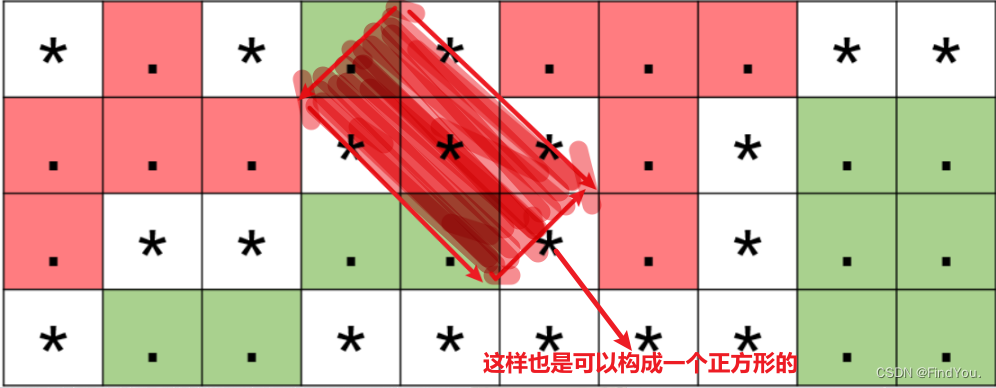
牛客小白月赛86(D剪纸游戏)
题目链接:D-剪纸游戏_牛客小白月赛86 (nowcoder.com) 题目描述: 输入描述: 输入第一行包含两个空格分隔的整数分别代表 n 和 m。 接下来输入 n行,每行包含 m 个字符,代表残缺纸张。 保证: 1≤n,m≤10001 字符仅有 . 和 * 两种字符…...
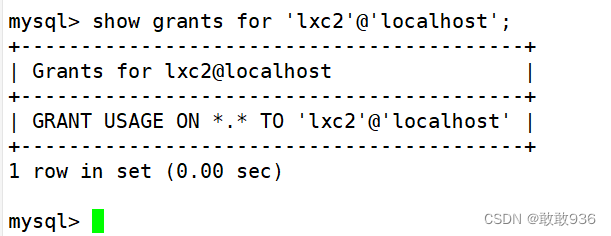
MySQL的基础操作与管理
一.MySQL数据库基本操作知识: 1.SQL语句: 关系型数据库,都是使用SQL语句来管理数据库中的数据。 SQL,即结构化查询语言(Structured Query Language) 。 SQL语句用于维护管理数据库,包括数据查询、数据更新、访问控…...

Pytorch 中的forward 函数内部原理
PyTorch中的forward函数是nn.Module类的一部分,它定义了模型的前向传播规则。当你创建一个继承自nn.Module的类时,你实际上是在定义网络的结构。forward函数是这个结构中最关键的部分,因为它指定了数据如何通过网络流动。 单独设计 forward …...
四、C语言中的数组:如何输入与输出二维数组(数组,完)
本章的学习内容如下 四、C语言中的数组:数组的创建与初始化四、C语言中的数组:数组的输入与元素个数C语言—第6次作业—十道代码题掌握一维数组四、C语言中的数组:二维数组 1.二维数组的输入与输出 当我们输入一维数组时需要一个循环来遍历…...
基于python+vue智慧农业小程序flask-django-php-nodejs
传统智慧农业采取了人工的管理方法,但这种管理方法存在着许多弊端,比如效率低下、安全性低以及信息传输的不准确等,同时由于智慧农业中会形成众多的个人文档和信息系统数据,通过人工方法对知识科普、土壤信息、水质信息、购物商城…...

好用的GPTs:指定主题搜索、爬虫、数据清洗、数据分析自动化
好用的GPTs:指定主题搜索、爬虫、数据清洗、数据分析自动化 Scholar:搜索 YOLO小目标医学方面最新论文Scraper:爬虫自动化数据清洗数据分析 点击 Explore GPTs: Scholar:搜索 YOLO小目标医学方面最新论文 搜索 Scho…...

使用Qt自带windeployqt打包QML的exe
1.在开始菜单输入CMD找到对应的Qt开发版本,我的是Qt5.15.2(MinGW 8.1.0 64-bit)。 2.在控制台输入如下字符串,格式为 windeployqt exe绝对路径 --qmldir 工程的绝对路径 如下是我的打包代码。 我需要打包的exe的绝对路径 D:\Prj\Code\Demo\QML\Ana…...

C代码快速傅里叶变换-分类和推理-常微分和偏微分方程
要点 C代码例程函数计算实现: 线性代数方程解:全旋转高斯-乔丹消元,LU分解前向替换和后向替换,对角矩阵处理,任意矩阵奇异值分解,稀疏线性系统循环三对角系统解,将矩阵从完整存储模式转换为行索…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...

在Hermes Agent项目中接入Taotoken作为自定义模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Hermes Agent项目中接入Taotoken作为自定义模型供应商 基础教程类,针对使用Hermes Agent框架的开发者,详…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...