论文笔记:Llama 2: Open Foundation and Fine-Tuned Chat Models
导语
Llama 2 是之前广受欢迎的开源大型语言模型 LLaMA 的新版本,该模型已公开发布,可用于研究和商业用途。本文记录了阅读该论文的一些关键笔记。
- 链接:https://arxiv.org/abs/2307.09288
1 引言
大型语言模型(LLMs)在多个领域表现出卓越的能力,尤其是在需要复杂推理和专业知识的任务中,例如编程和创意写作。LLMs通过直观的聊天界面与人类互动,导致了它们在公众中的快速普及。LLMs通常通过自回归式的Transformer在大量自监督数据上进行预训练,然后通过诸如人类反馈的强化学习(RLHF)等技术进行微调,使其更符合人类偏好。尽管训练方法相对简单,但高计算要求限制了LLMs的发展。已有公开发布的预训练LLMs在性能上可以与GPT-3和Chinchilla等闭源模型相媲美,但这些模型并不适合作为诸如ChatGPT、BARD、Claude这样的闭源“产品”LLMs的替代品。
本文开发并发布了Llama 2和Llama 2-Chat,以供研究和商业使用,这是一系列预训练和微调的LLMs,模型规模最大可达70亿参数。Llama 2-Chat在有用性和安全性方面的测试中普遍优于现有的开源模型,并且在人类评估中与一些闭源模型相当。本文还采取了提高模型安全性的措施,包括特定的数据注释和调整,红队测试,以及迭代评估。同时作者强调,虽然LLMs是一项新技术,可能带来潜在风险,但如果安全地进行,公开发布LLMs将对社会有益。作者提供了负责任使用指南和代码示例,以促进Llama 2和Llama 2-Chat的安全部署。

2 预训练
2.1 预训练数据
- 数据来源:训练数据来自公开可用的源,排除了来自 Meta 产品或服务的数据。
- 数据清洗:移除了已知包含大量个人信息的网站数据。
- 训练token数:训练了2万亿(2T)token的数据,以获得良好的性能和成本平衡。


2.2 训练细节
- 使用标准Transformer架构
- 使用RMSNorm而不是原始的LayerNorm
- 使用SwiGLU激活函数
- 相对于LLaMA的2k上下文长度,LLaMA2增加到了4k上下文长度
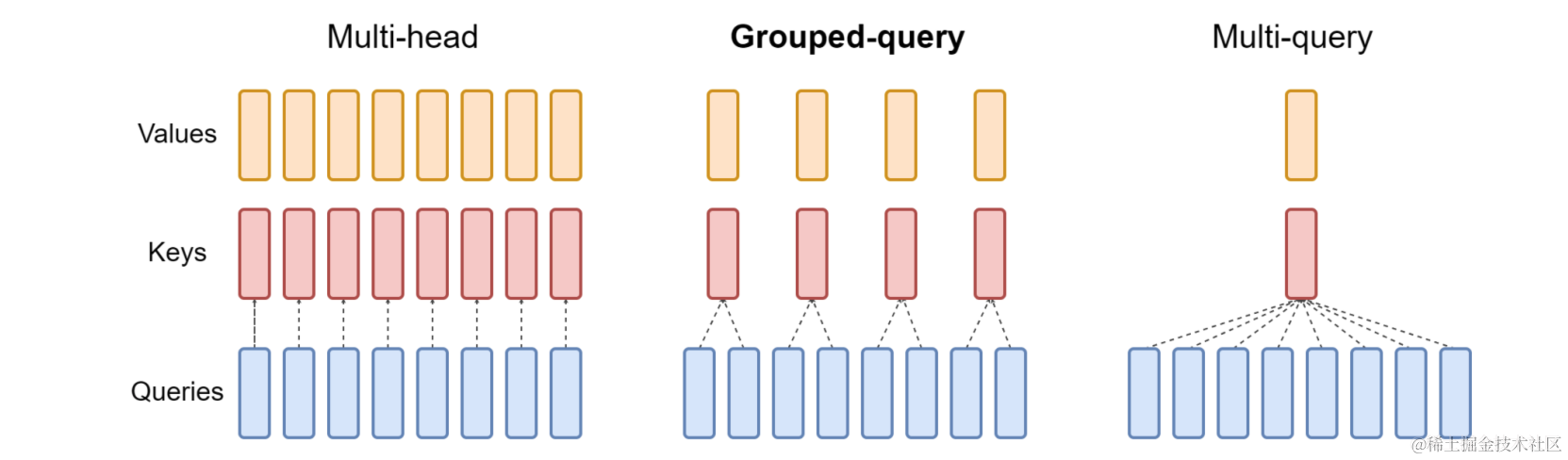
- 使用了Grouped-Query Attention (GQA),而不是之前的MQA、MHA
- 使用了RoPE方式进行位置编码,使用旋转矩阵来编码位置信息,直接融合到自注意力的计算中
RMSNorm
原始的LayerNorm需要计算均值和方差,然后再进行归一化:


而RMSNorm(Root Mean Square Normalization)是LayerNorm的一种变体,其通过计算层中所有神经元输出的均方根(Root Mean Square)来归一化这些输出。这样可以减少不同层输出分布的差异,有助于加速训练并提高模型的稳定性。

SwiGLU
SwiGLU(Sigmoid-Weighted Linear Unit)是一种神经网络中的激活函数,它是 Gated Linear Unit (GLU) 的一种变体,由两部分组成:一个线性变换和一个 sigmoid 函数。输入先通过一个线性变换,然后用 sigmoid 函数的输出加权。
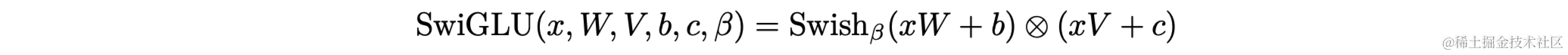
GQA
GQA则是介于Multi-query和Multi-head之间的一种中间形式,传统的Multi-head Self-attention中每个Head都有各自的Q,K,V;而Multi-Query Self-attention中,各个头之间共享一个K、V;而GQA则是介于两者之间,即对头进行分块,每块中的若干头使用同样的K,V。
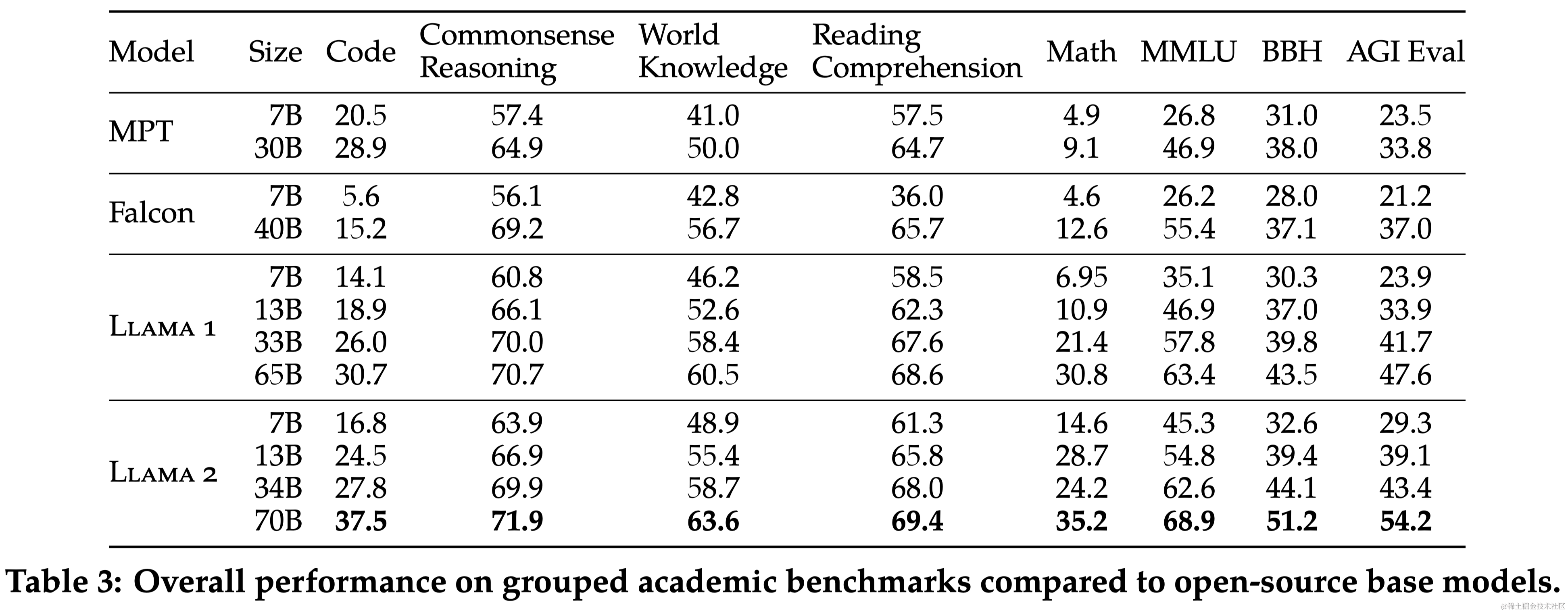
2.3 Llama 2 预训练模型评估
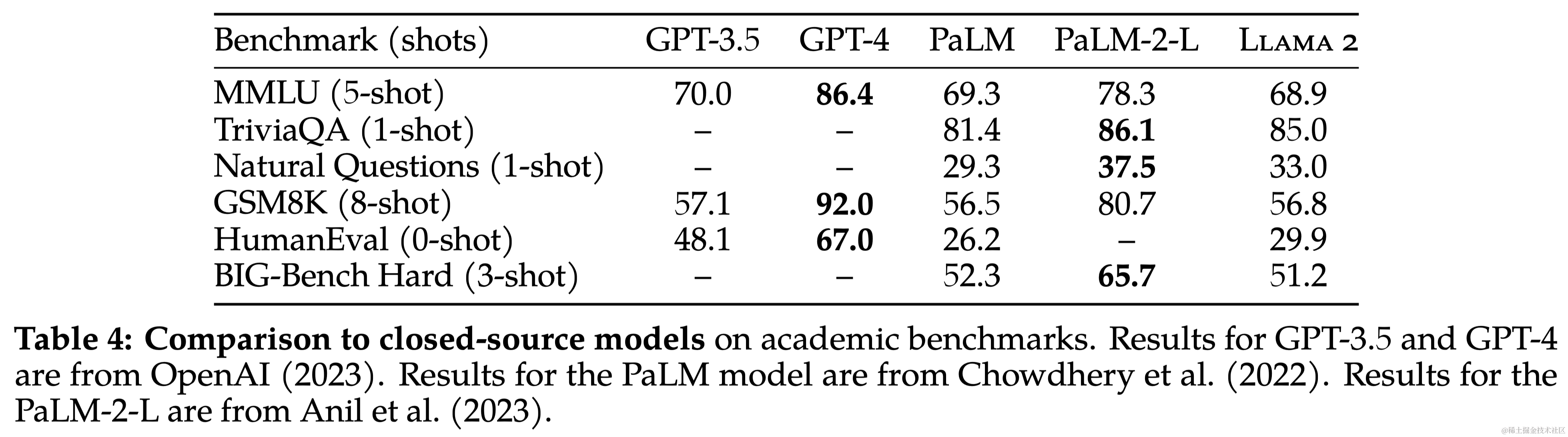
本文对Llama 2 模型在一系列标准学术基准测试中的性能进行了报告。与其他模型相比,Llama 2 模型不仅超过了 Llama,还在多个分类基准上超过了其他开源模型和某些闭源模型。在长上下文(Long-context)数据集上效果比Llama提升显著。

3 微调
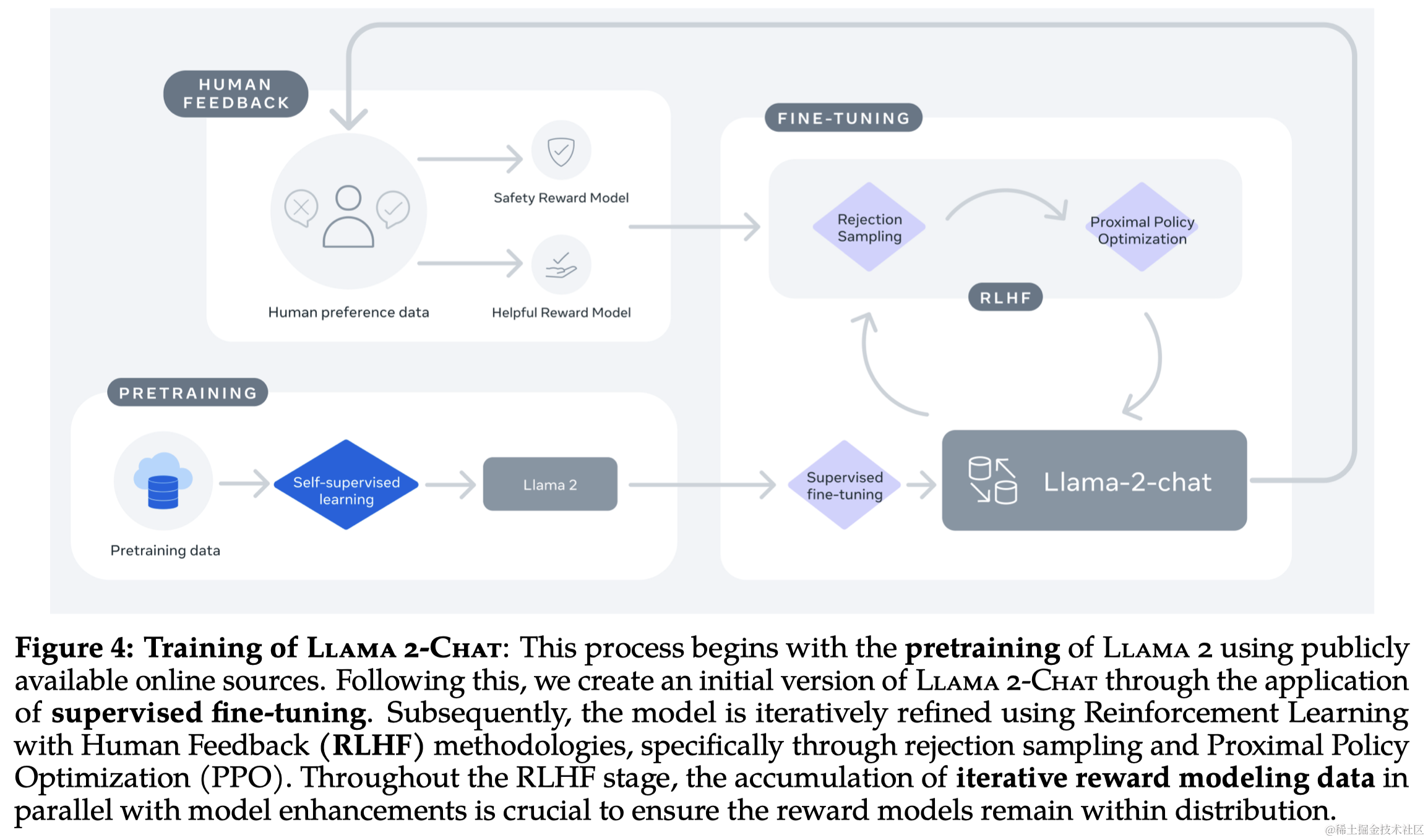
Llama 2-Chat 的开发涉及了多次迭代应用的对齐技术,包括指令调整和人类反馈的强化学习(RLHF)。这个过程需要大量的计算资源和注释工作。
3.1 监督式微调 (SFT)
- 初始步骤:使用公开可用的指令微调数据作为 SFT 的起点。
- 数据质量:重点放在收集高质量的 SFT 数据上,因为作者发现许多第三方数据质量和多样性不足。通过放弃第三方数据集中的数百万个示例,并使用基于供应商的标注工作中更少但质量更高的示例,结果显著提高。作者发现数万级别的 SFT 标注就足以达到高质量结果,本文收集了总共27,540个标注。
- 训练细节:训练时,prompt和答案拼接在一起,使用特殊的 token 来分开这两个部分。采用自回归损失并设置prompt不参与反向传播(即Prompt部分不计算loss)。

3.2 强化学习与人类反馈 (RLHF)
3.2.1 人类偏好数据收集
在 Llama 2-Chat 模型的 RLHF 过程中,首先进行了人类偏好数据的收集,这些数据用于后续的奖励建模,收集了超过一百万个基于人类指定指南的二元比较的大型数据集,这些数据的特点是对话轮次更多,平均长度更长:
- 二元比较:使用二元比较方法(即只需判断哪一个更好,不需要对各自进行打分)来收集偏好数据,主要是为了最大化收集的prompt的多样性。
- 标注过程:注释者首先编写提示,然后在两个模型响应中选择一个,同时标记他们对所选响应的偏好程度(significantly better, better, slightly better, or negligibly better/ unsure)。
- 注重有用性和安全性:在收集偏好数据时,重点放在模型响应的有用性和安全性上。
- 安全标签收集:在安全阶段,额外收集安全标签,将响应分为三个类别:安全、双方均安全、双方均不安全。
- 数据分布和奖励模型:每周收集偏好数据(即每次都使用本周最新的模型进行响应然后收集偏好数据)。因为没有充足的新偏好样本分布,会导致奖励模型效果退化。

3.2.2 奖励建模(Reward Modeling)
奖励模型将模型响应及其相应的提示(包括来自前一个回合的上下文)作为输入,并输出一个标量分数来指示模型生成的质量(例如,有用性和安全性)。利用这样的反应分数作为奖励,可以在RLHF期间优化Llama 2-Chat,以更好地调整人类的偏好,提高帮助和安全性。
之前的研究发现有用性和安全性存在一个Trade-off,为此本文训练了两个奖励模型分别单独考虑有用性和安全性。奖励模型和chat模型初始化于同样的预训练checkpoint,这样可以保证两个模型从同样的预训练中获得一样的知识。两个模型的结构和超参数都保持一致,只是替换了模型的分类头/回归头。
训练目标 采用二元排序损失(binary ranking loss):
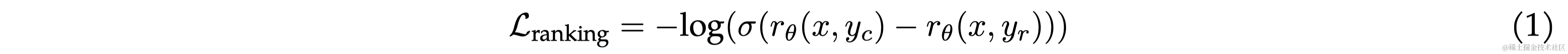
由于本文采用了4个不同的偏好等级(significantly better, better, slightly better, or negligibly better/ unsure),所以作者对原始的loss进行了一些修改,引入 m ( r ) m(r) m(r)代表偏好等级的离散函数(discrete function)。
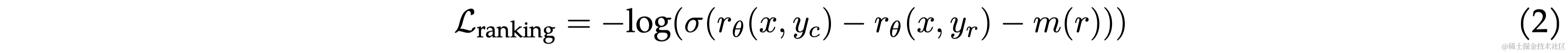
数据组合 Helpfulness奖励模型最终在所有Meta Helpfulness数据上进行训练,并结合从Meta Safety和开源数据集中统一采样的同等部分剩余数据。Meta Safety奖励模型在所有Meta Safety和Anthropic无害数据上进行训练,并以90/10的比例混合Meta Helpfulness和开源有用数据。作者发现,10%有用数据的设置特别有利于样本的准确性,其中选择和拒绝的回答都被认为是安全的。
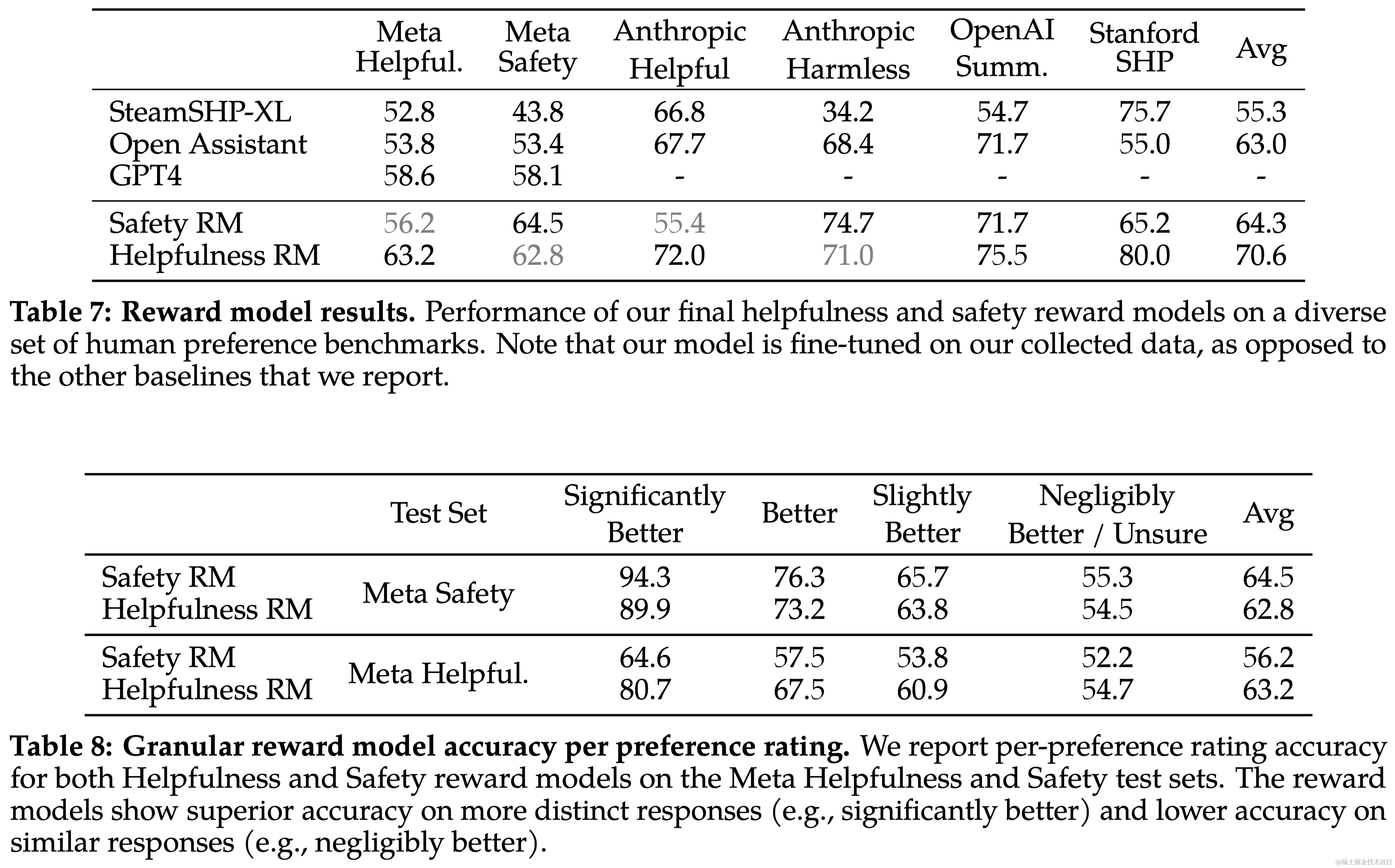
训练细节 对训练数据进行了一个epoch的训练(防止过拟合)。使用与基础模型相同的优化器参数。70B 参数 Llama 2-Chat 的最大学习率为 5 × 10^−6,其他模型为 1 × 10^−5。学习率根据余弦学习率策略逐渐减小。
奖励模型的结果 Llama 2-Chat 的奖励模型在内部测试集上表现最佳,尤其是在有用性和安全性测试集上。Llama 2-Chat 的奖励模型在准确率上优于所有基线模型,包括 GPT-4。而且,GPT-4 在没有针对性训练的情况下也表现出色。由于有用性和安全性之间可能存在张力,因此优化两个分开的模型(有用性和安全性)更为有效。

Scaling趋势 研究了奖励模型在数据量和模型大小方面的扩展趋势,这些模型使用了每周收集的奖励模型数据量逐渐增加。图6显示了预期的结果,即更大的模型对于相似的数据量能获得更高的性能。更重要的是,考虑到用于训练的现有数据注释量,扩展性能尚未达到平台期,这表明随着更多注释的增加,还有改进的空间。注意到,奖励模型的准确性是 Llama 2-Chat 最终性能的最重要代理之一。虽然全面评估生成模型的最佳实践仍是一个开放的研究问题,但奖励的排名任务没有歧义。因此,在其他条件相同的情况下,奖励模型的改进可以直接转化为 Llama 2-Chat 的改进。
3.2.3 迭代式微调(Iterative Fine-Tuning)
随着更多批次的人类偏好数据注释的收集,作者训练了连续版本的 RLHF 模型,在此称为 RLHF-V1、…、RLHF-V5。使用两种主要算法对 RLHF 进行了微调:
- 近端策略优化(Proximal Policy Optimization, PPO),这是 RLHF 文献中的标准算法。
- 拒绝采样微调(Rejection Sampling fine-tuning)。对模型中的 K 个输出进行采样,然后用奖励模型选出最佳候选,这里作者将所选输出用于梯度更新。对于每个提示,获得最高奖励分数的样本被视为新的gold label。
这两种 RL 算法的主要区别在于:
- 广度(Breadth)-- 在拒绝采样算法中,模型会针对给定的提示探索 K 个样本,而 PPO 算法只进行一次生成。
- 深度(Depth) - 在PPO算法中,第 t 步的训练过程中,样本是上一步梯度更新后第 t - 1 步更新模型策略的函数。拒绝采样微调会对模型初始策略下的所有输出进行采样,以收集新的数据集,然后再应用类似于 SFT 的微调。
在 RLHF(V4)之前,只使用了拒绝采样微调,而在此之后,将这两种算法依次结合起来。

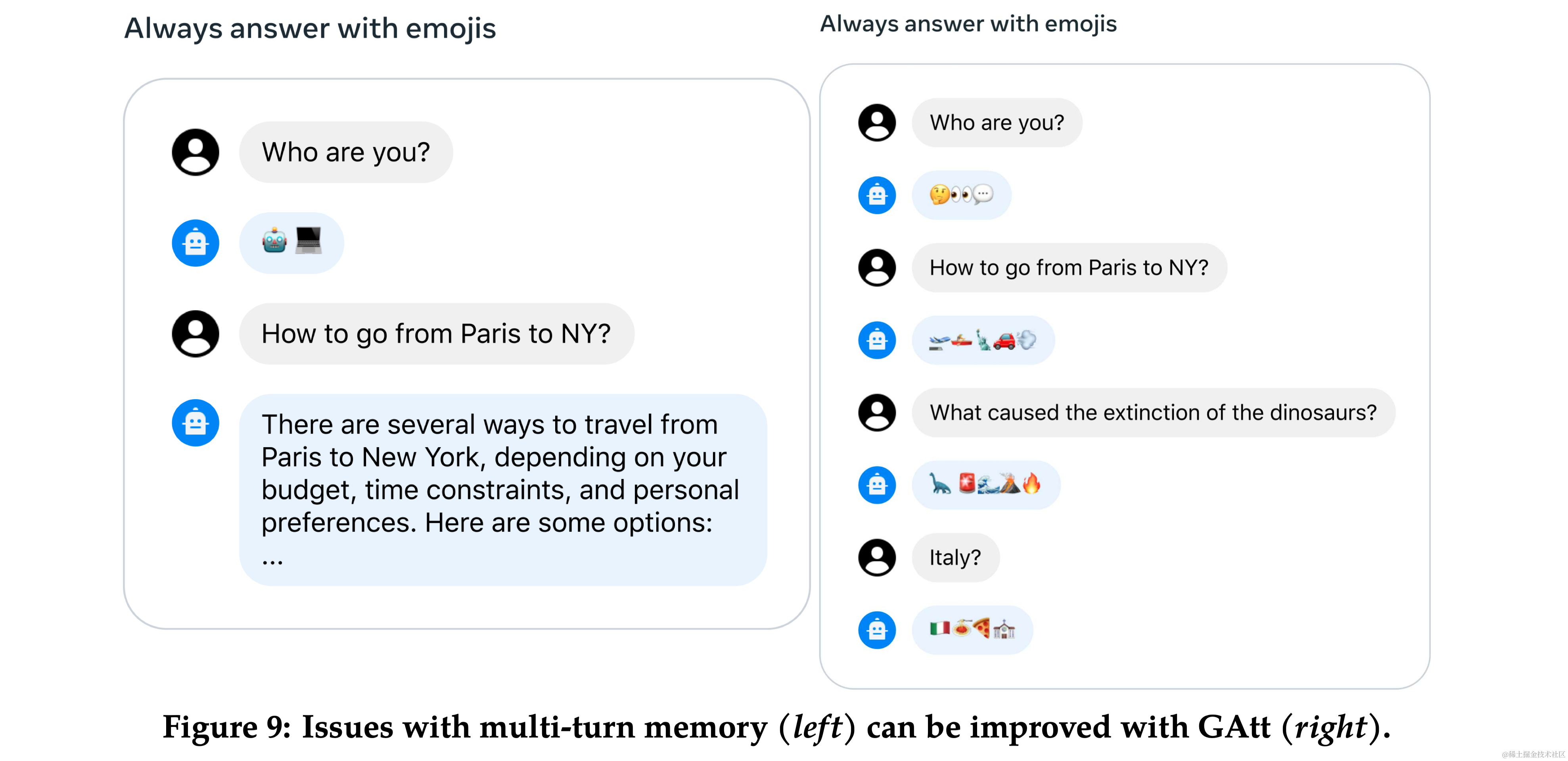
3.3 多轮一致性的系统消息 (System Message for Multi-Turn Consistency)
- Ghost Attention (GAtt):提出了一种新技术 GAtt,帮助控制多轮对话中的对话流。
- 方法:GAtt 通过在微调数据中修改以帮助注意力集中在多阶段的对话上。

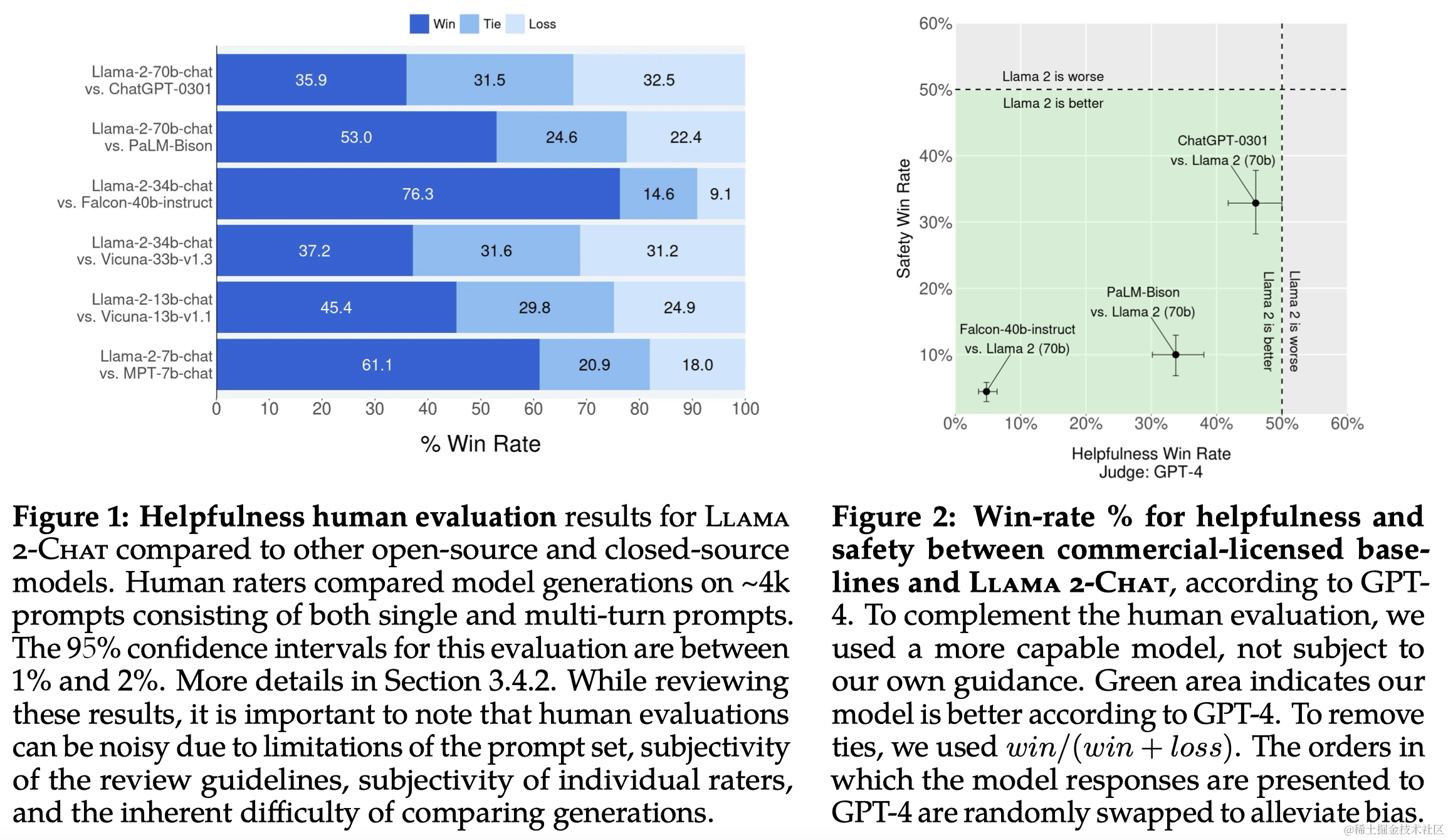
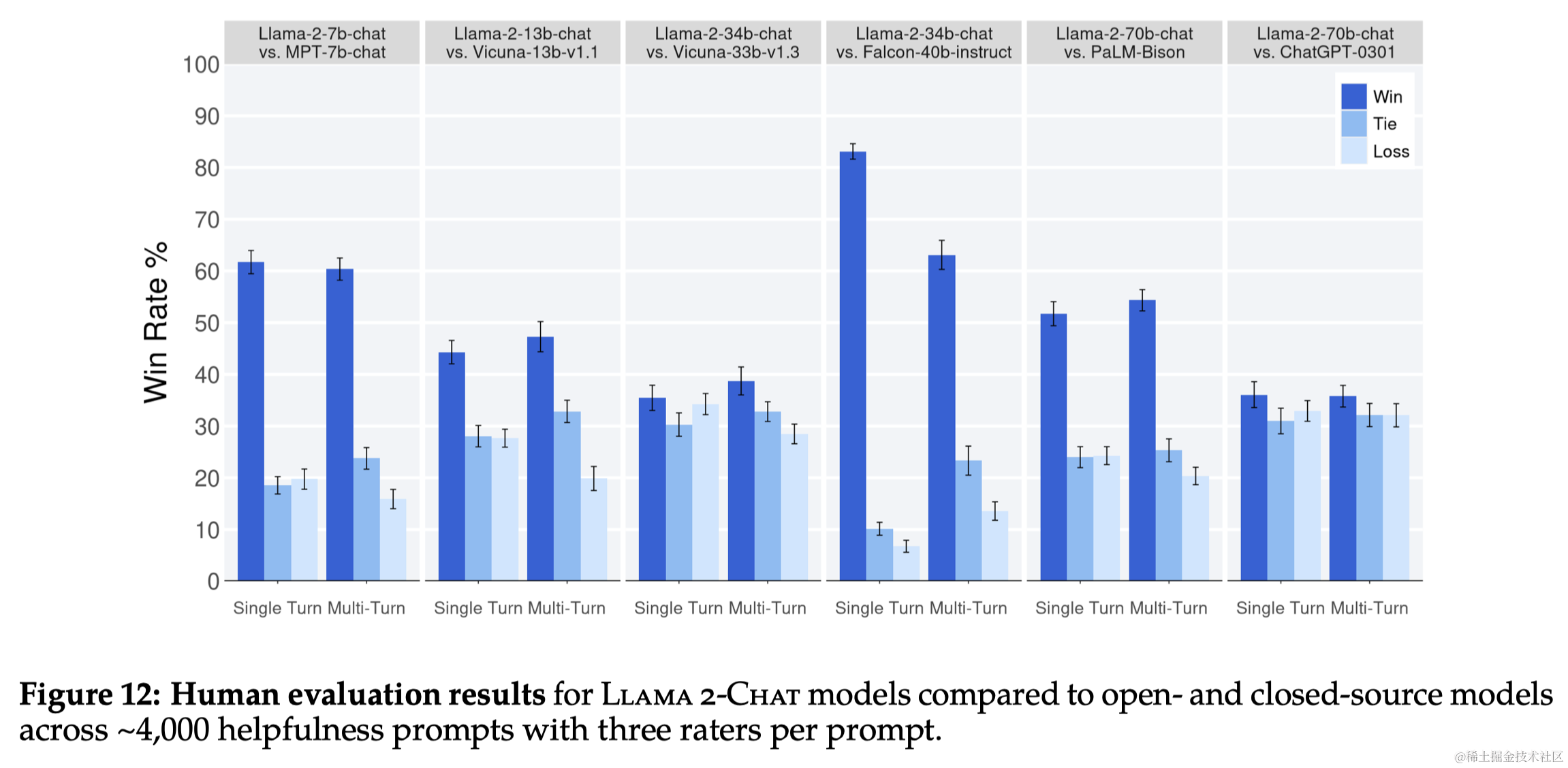
3.4 RLHF 结果
- 模型评估:使用基于模型的评估来选择每次迭代中表现最好的模型。
- 人类评估:通过人类评估来评价模型在有用性和安全性方面的表现。

4-6 安全性、讨论、相关工作
略
7 结论
本研究引入了 Llama 2,这是一个新的预训练和微调模型系列,参数量级为 70 亿到 700 亿。这些模型已经证明了它们与现有开源聊天模型的竞争力,并且在检查的评估集上与一些专有模型相当,尽管它们仍然落后于 GPT-4 等其他模型。本文细致地阐述了实现模型所采用的方法和技术,并着重强调了它们与有用性和安全性原则的一致性。为了对社会做出更大的贡献并促进研究的步伐,作者尽责地开放了“Llama 2”和“Llama 2-Chat”的访问权限。作为对透明度和安全性持续承诺的一部分,作者计划在今后的工作中进一步改进 Llama 2-Chat。
相关文章:
论文笔记:Llama 2: Open Foundation and Fine-Tuned Chat Models
导语 Llama 2 是之前广受欢迎的开源大型语言模型 LLaMA 的新版本,该模型已公开发布,可用于研究和商业用途。本文记录了阅读该论文的一些关键笔记。 链接:https://arxiv.org/abs/2307.09288 1 引言 大型语言模型(LLMsÿ…...
Unity UGUI之Toggle基本了解
在Unity中,Toggle一般用于两种状态之间的切换,通常用于开关或复选框等功能。 它的基本属性如图: 其中, Interactable(可交互):指示Toggle是否可以与用户交互。设置为false时,禁用To…...

鸿蒙Harmony应用开发—ArkTS-全局UI方法(日期滑动选择器弹窗)
根据指定的日期范围创建日期滑动选择器,展示在弹窗上。 说明: 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 本模块功能依赖UI的执行上下文,不可在UI上下文不明确的地方使用&…...

华岳M9制造企业管理软件业务流程 2/4
华岳M9制造企业管理软件业务流程 2/4 步骤3 初始一、应收账款初始余额二、应付账款初始余额三、出纳账项初始余额四、会计账项初始余额五、盘点入库六、存货细目七、存货属性设置八、存货存量控制九、存货价格管理十、月末处理 步骤4 技术一、存货目录二、存货细目三、仓库绑定…...
echarts geo地图加投影两种方法
方法1,geo中加多个地图图形,叠加。缩放时 可能会不一致,需要捕捉georoam事件,使下层的geo随着上层的geo一起缩放拖曳 geo: [{zlevel: 3,//geo显示级别,默认是0 【最顶层图形】map: BJ,//地图名roam: true,scaleLimit: …...

GPT实战系列-LangChain的Prompt提示模版构建
GPT实战系列-LangChain的Prompt提示模版构建 LangChain GPT实战系列-LangChain如何构建基通义千问的多工具链 GPT实战系列-构建多参数的自定义LangChain工具 GPT实战系列-通过Basetool构建自定义LangChain工具方法 GPT实战系列-一种构建LangChain自定义Tool工具的简单方法…...

Docker容器中的mysql自动备份脚本
Docker容器中的mysql自动备份脚本 1. 脚本功能 备份容器中的mysql数据库到宿主机上,自动删除7天前的备份文件 2. 脚本内容 #!/bin/bash # auth Eric source /etc/profile # 设置备份目录和文件名 backup_directory"/app/backup" #测试名字用%Y%m%d%H…...

品精酿啤酒:畅享生活,享受快乐
在现代社会,品牌营销策略对于产品的成功至关重要。Fendi club啤酒之所以能够成为畅享生活、享受时尚的代名词,与其品牌营销策略密不可分。 首先,Fendi club啤酒注重品牌形象的塑造。作为一个时尚品牌,Fendi club啤酒将时尚与品质融…...

进程创建,程序加载运行,以及进程终止,什么是僵尸进程,什么是孤儿进程
进程控制 创建进程,撤销进程,实现进程转换(必须一气呵成,使用原语) 原语不被中断是因为有关中断指令 创建进程 撤销进程 进程创建fork fork()函数会创建一个子进程,子进程会返…...
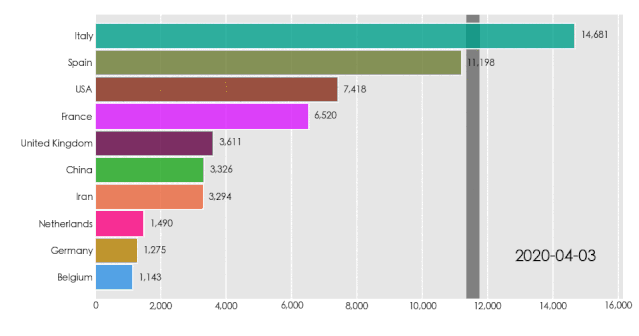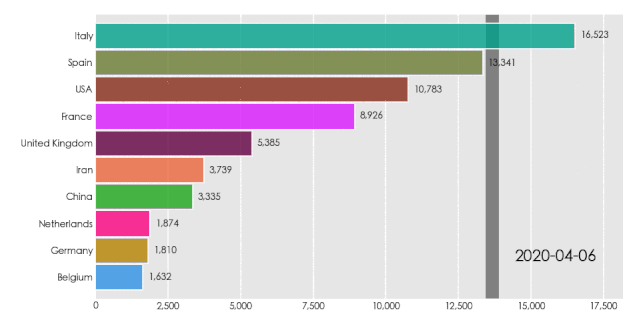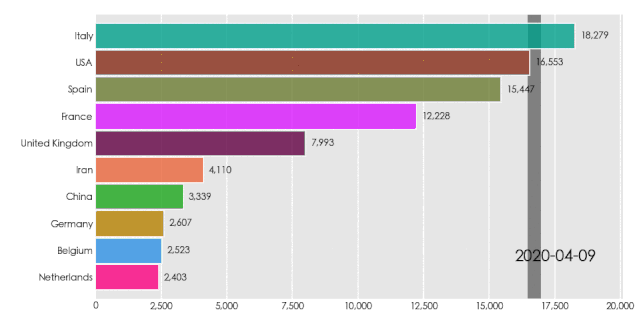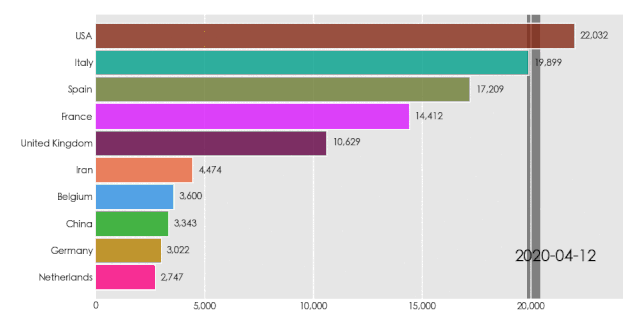
[python]bar_chart_race设置日期格式
1、设置日期标签的时间格式 # 设置日期格式,默认为%Y-%m-%dbcr.bar_chart_race(df, covid19_horiz.gif, period_fmt%b %-d, %Y) 2、更改日期标签为数值 # 设置日期标签为数值bcr.bar_chart_race(df.reset_index(dropTrue), covid19_horiz.gif, interpolate_period…...
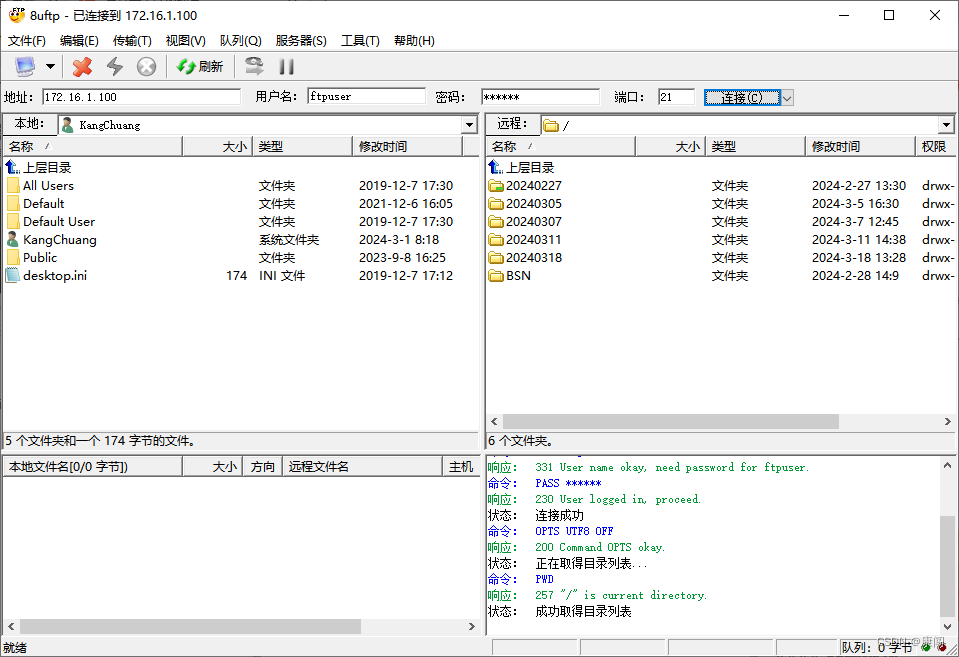
Apache FtpServer在Windows上下载安装与使用
Apache FtpServer在Windows上下载安装与使用 1、Apache Ftp Server下载 进入apache官网 https://mina.apache.org/ftpserver-project/old-downloads.html 下载自己使用的版本。 Apache FtpServer 1.1.1及以下的版本需要JDK1.7的支持 Apache FtpServer 1.1.1以上的版本需要JDK…...

CVE-2024-24112 XMall后台管理系统 SQL 注入漏洞分析
------作者本科毕业设计项目 基于 Spring Boot Vue 开发而成...... [Affected Component] /item/list /item/listSearch /sys/log /order/list /member/list (need time-based blind injection) /member/list/remove 项目下载地址 Exrick/xmall: 基于SOA架构的分布式…...

jwt以及加密完善博客系统
目录 一、背景 二、传统登陆功能&强制登陆功能 1、传统的实现方式 2、session存在的问题 三、jwt--令牌技术 1、实现过程 2、令牌内容 3、生成令牌 4、检验令牌 四、JWT登陆功能&强制登陆功能 1、JWT实现登陆功能 2、强制登陆功能 3、运行效果 五、加密/加…...
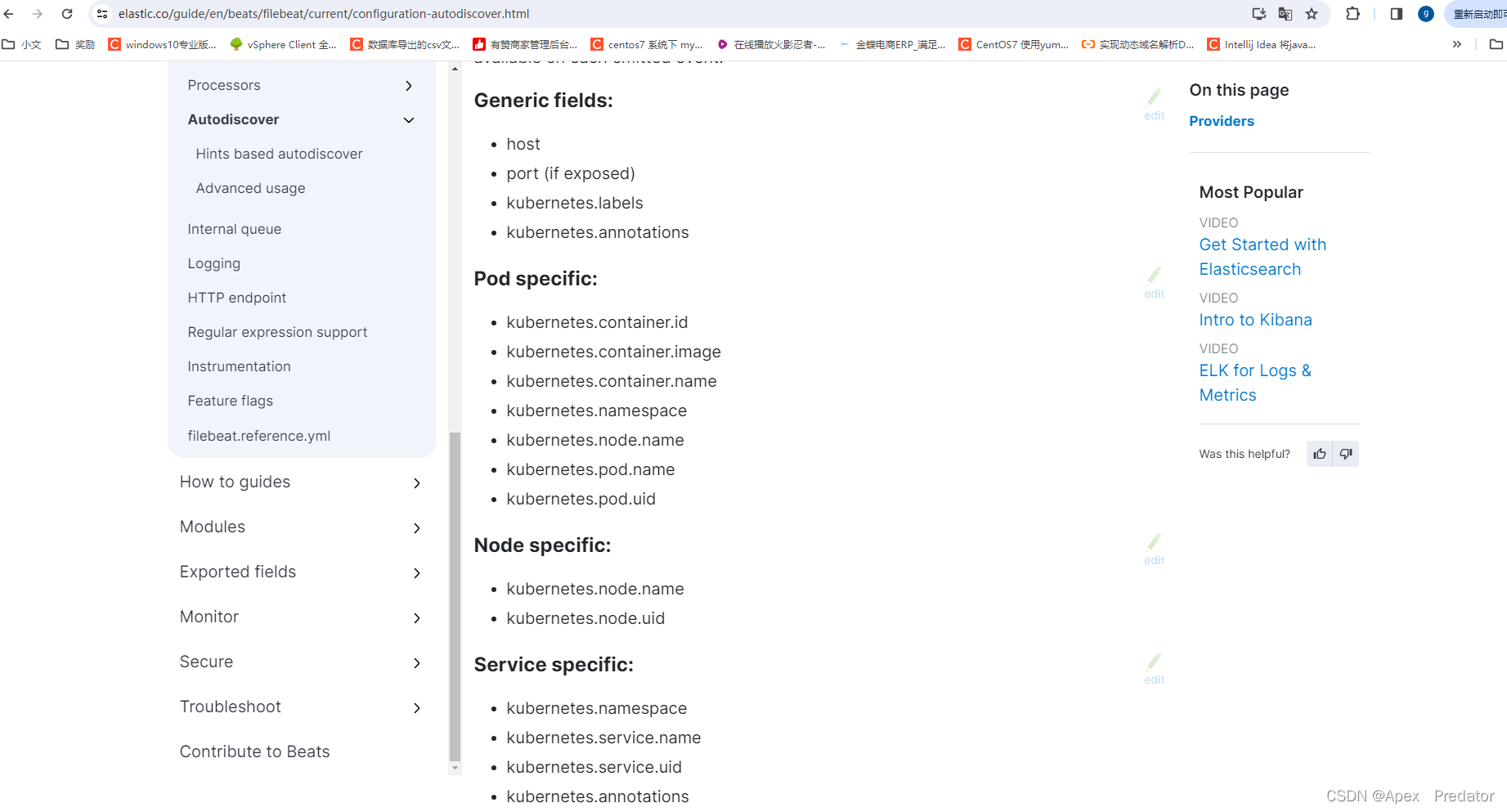
elk收集k8s微服务日志
一、前言 使用filebeat自动发现收集k8s的pod日志,这里分别收集前端的nginx日志,还有后端的服务java日志,所有格式都是用json格式,建议还是需要让开发人员去输出java的日志为json,logstash分割java日志为json格式&#…...
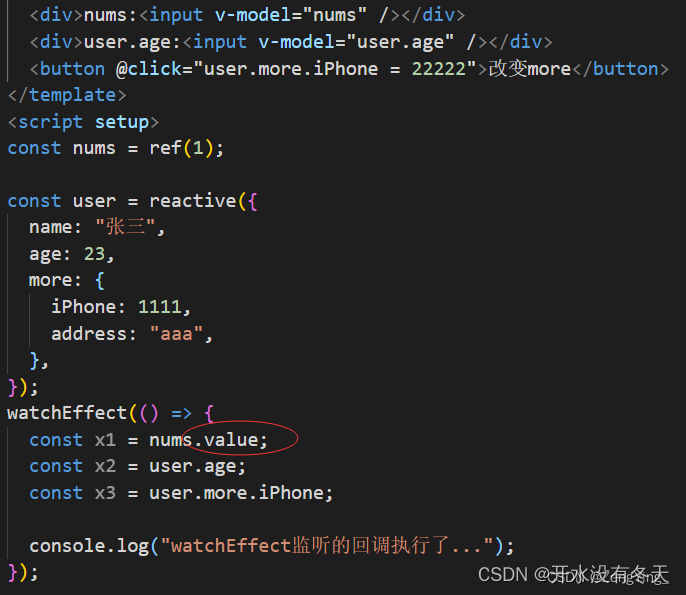
vue3中如何实现多个侦听器(watch)
<body> <div id"app"><input type"button" value"更改名字" click"change"> </div> <script src"vue.js"></script> <script>new Vue({el: #app,data: {food: {id: 1,name: 冰激…...

【深度学习基础知识】IOU、GIOU、DIOU、CIOU
这里简单记录下IOU及其衍生公式。 为了拉通IOU及其衍生版的公式对比,以及方便记忆,这里用一个统一的图示来表示出所有的参数 【A】目标框的区域【B】预测框的区域【C】A与B的交集【ÿ…...

【自用笔记】单词
cognitive 认知formulation 阐述方式nonlinear 非线性nonconvex 非凸,无最优解cumulative return 累计回报propagation 传播optimization 优化objective 目标标准差(standard deviation)正态分布(Normal distribution)…...

Linux之shell条件判断
华子目录 if语句单分支案例 双分支案例 多分支 case多条件判断格式执行过程示例 if语句 单分支 # 语法1: if <条件表达式> then指令 fi#语法2: if <条件表达式>;then指令 fi案例 编写脚本choice1.sh,利用单分支结构实现输入2个整数&#…...

“postinstall“: “patch-package“ 修补安装包补丁
在 package.json 文件里,postinstall 是一个钩子脚本,它在每次运行 npm install 命令后自动执行。当你在该字段中指定 "patch-package" 时,意思是在 npm install 安装所有依赖包之后,自动运行 patch-package 命令。 pa…...

PHP+MySQL开发组合:多端多商户DIY商城源码系统 带完整的搭建教程以及安装代码包
近年来,电商行业的迅猛发展,越来越多的商户开始寻求搭建自己的在线商城。然而,传统的商城系统往往功能单一,无法满足商户个性化、多样化的需求。同时,搭建一个功能完善的商城系统需要专业的技术团队和大量的时间成本&a…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...
)
告别复杂模型:用Python+OpenCV+dlib实现简易驾驶员疲劳监测(附完整代码)
轻量级驾驶员疲劳监测系统:PythonOpenCVdlib实战指南 在长途驾驶或夜间行车时,疲劳是导致交通事故的重要因素之一。传统基于嵌入式设备的疲劳监测系统往往需要专用硬件,增加了开发成本和部署难度。本文将介绍如何利用Python生态中的OpenCV和d…...

星露谷物语SMAPI模组加载器:从新手到专家的完整使用指南
星露谷物语SMAPI模组加载器:从新手到专家的完整使用指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 星露谷物语SMAPI模组加载器是官方推荐的模组API,它为玩家和开发者提供…...

突破本地媒体解码屏障:QQ影音 4K/H.265 硬件加速优化与 DLL 运行库环境修复
突破本地媒体解码屏障:QQ影音 4K/H.265 硬件加速优化与 DLL 运行库环境修复 在日常开发和技术写作中,我们经常需要处理本地音视频文件,或者截取一段高质量的 GIF 动图作为 GitHub PR、CSDN 博客的演示说明。 虽然目前市面上有 PotPlayer、V…...