大规模预训练语言模型的可解释性研究与实践
1. 背景介绍
随着深度学习技术的发展,大规模预训练语言模型(Large-scale Pre-trained Language Models, LPLMs)在自然语言处理领域取得了显著的成果。这些模型通常通过在大规模文本语料库上进行无监督预训练,然后微调到特定任务上,如文本分类、机器翻译、问答等。然而,这些模型的决策过程往往缺乏可解释性,这限制了它们在需要透明度和可解释性的应用场景中的应用。因此,研究大规模预训练语言模型的可解释性具有重要意义。
2. 核心概念与联系
2.1 预训练语言模型
预训练语言模型是一种基于神经网络的模型,通过在大规模文本语料库上进行无监督预训练,学习语言的通用特征。常见的预训练语言模型包括BERT、GPT、XLNet等。
2.2 可解释性
可解释性是指模型决策过程的可理解性和透明度。在自然语言处理领域,可解释性对于模型的可信度和应用场景至关重要。例如,在医疗诊断、法律判决等领域,模型的可解释性直接影响到模型的可靠性和应用前景。
2.3 关联性
大规模预训练语言模型的可解释性研究旨在揭示模型在处理自然语言时的内部机制,提高模型的透明度和可信度。这有助于推动预训练语言模型在需要可解释性的应用场景中的应用。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 核心算法原理
3.1.1 注意力机制
注意力机制是大规模预训练语言模型的核心组件之一,它允许模型在处理输入序列时关注到重要的部分。注意力机制的数学公式为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中,Q、K、V 分别表示查询(Query)、键(Key)和值(Value)向量,d_k 是键向量的维度。
3.1.2 Transformer架构
Transformer架构是大规模预训练语言模型的典型代表,它采用自注意力机制和多头注意力机制来捕捉输入序列的依赖关系。Transformer架构的数学公式为:
MultiHead ( Q , K , V ) = Concat ( h e a d 1 , . . . , h e a d h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(head_1, ..., head_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中,head_i 表示第i个注意力头的输出,W^O 是一个可学习的权重矩阵。
3.2 具体操作步骤
3.2.1 预训练阶段
- 准备大规模文本语料库。
- 将文本序列转化为模型可以处理的输入格式,如词嵌入。
- 使用Transformer架构进行自注意力计算。
- 计算预测目标,如下一个词或句子生成任务。
- 使用梯度下降算法进行模型参数优化。
3.2.2 微调阶段
- 将预训练模型应用于特定任务,如文本分类或问答。
- 准备任务相关的数据集。
- 将数据集输入预训练模型,并计算预测目标。
- 使用梯度下降算法进行模型参数优化。
4. 具体最佳实践:代码实例和详细解释说明
4.1 代码实例
以下是一个使用Python和TensorFlow实现的大规模预训练语言模型的简单示例:
import tensorflow as tf# 定义Transformer模型
class Transformer(tf.keras.Model):def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, pe_input, pe_target, rate=0.1):super(Transformer, self).__init__()self.embedding = tf.keras.layers.Embedding(input_vocab_size, d_model)self.pos_encoding = tf.keras.layers.PositionalEncoding(pe_input, dtype='float32')self.transformer_layers = [TransformerLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]self.final_layer = tf.keras.layers.Dense(target_vocab_size)def call(self, inp, tar, training, mask):# 嵌入层inp_embed = self.embedding(inp)tar_embed = self.embedding(tar)# 位置编码inp_pos_encoded = self.pos_encoding(inp_embed)tar_pos_encoded = self.pos_encoding(tar_embed)# Transformer层for i in range(self.transformer_layers):out = self.transformer_layers[i](inp_pos_encoded, tar_pos_encoded, training, mask)# 输出层final_output = self.final_layer(out)return final_output# 定义Transformer层
class TransformerLayer(tf.keras.layers.Layer):def __init__(self, d_model, num_heads, dff, rate=0.1):super(TransformerLayer, self).__init__()self.mha = MultiHeadAttention(d_model, num_heads)self.ffn = tf.keras.Sequential([Dense(dff, activation='relu'),Dense(d_model)])self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)self.dropout1 = tf.keras.layers.Dropout(rate)self.dropout2 = tf.keras.layers.Dropout(rate)def call(self, x, y, training, mask):attn_output, attn_weights = self.mha(x, y, y, training, mask)attn_output = self.dropout1(attn_output, training=training)out1 = self.layernorm1(x + attn_output)ffn_output = self.ffn(out1)ffn_output = self.dropout2(ffn_output, training=training)out2 = self.layernorm2(out1 + ffn_output)return out2, attn_weights
4.2 详细解释说明
- 首先,我们定义了一个Transformer模型,它包含嵌入层、位置编码层和多个Transformer层。
- 在Transformer模型中,我们使用了自注意力机制和多头注意力机制来捕捉输入序列的依赖关系。
- 在Transformer层中,我们使用了多头注意力机制和前馈神经网络来增强模型的表达能力。
- 最后,我们定义了一个简单的训练循环,用于训练模型并生成预测结果。
5. 实际应用场景
大规模预训练语言模型的可解释性研究在实际应用场景中具有重要意义。以下是一些具体的应用场景:
5.1 文本分类
在文本分类任务中,模型的可解释性可以帮助我们理解模型如何根据文本内容进行分类。这有助于提高模型的可信度和应用场景的可靠性。
5.2 问答系统
在问答系统中,模型的可解释性可以帮助我们理解模型如何根据问题生成答案。这有助于提高模型的可信度和用户体验。
5.3 文本生成
在文本生成任务中,模型的可解释性可以帮助我们理解模型如何根据给定的输入生成文本。这有助于提高模型的可控性和应用场景的可靠性。
6. 工具和资源推荐
以下是一些用于大规模预训练语言模型的可解释性研究的工具和资源:
6.1 开源框架
- TensorFlow:一个开源的机器学习框架,支持大规模预训练语言模型的训练和推理。
- PyTorch:一个开源的机器学习框架,支持大规模预训练语言模型的训练和推理。
6.2 预训练模型
- Hugging Face’s Transformers:一个开源库,提供了多种预训练语言模型的实现和预训练权重。
- OpenAI GPT-3:一个开源的预训练语言模型,支持多种自然语言处理任务。
6.3 可解释性工具
- SHAP:一个开源库,提供了多种可解释性算法的实现,如基于梯度的可解释性方法。
- LIME:一个开源库,提供了基于局部可解释性模型的可解释性方法。
7. 总结:未来发展趋势与挑战
大规模预训练语言模型的可解释性研究是一个新兴领域,具有广泛的应用前景和挑战。以下是一些未来的发展趋势和挑战:
7.1 发展趋势
- 发展更有效的可解释性算法,提高模型的透明度和可信度。
- 探索新的模型架构,如基于图神经网络的模型,以提高模型的可解释性。
- 结合领域知识,开发针对特定应用场景的可解释性模型。
7.2 挑战
- 如何在保持模型性能的同时提高可解释性?
- 如何处理大规模文本数据的可解释性分析?
- 如何将可解释性模型应用于实际应用场景中?
8. 附录:常见问题与解答
8.1 问题1:大规模预训练语言模型的可解释性研究有哪些应用场景?
答:大规模预训练语言模型的可解释性研究在文本分类、问答系统、文本生成等实际应用场景中具有重要意义。
8.2 问题2:如何提高大规模预训练语言模型的可解释性?
答:提高大规模预训练语言模型的可解释性可以通过发展更有效的可解释性算法、探索新的模型架构和结合领域知识来实现。
8.3 问题3:大规模预训练语言模型的可解释性研究有哪些挑战?
答:大规模预训练语言模型的可解释性研究面临的挑战包括如何在保持模型性能的同时提高可解释性、处理大规模文本数据的可解释性分析和将可解释性模型应用于实际应用场景中。
相关文章:

大规模预训练语言模型的可解释性研究与实践
1. 背景介绍 随着深度学习技术的发展,大规模预训练语言模型(Large-scale Pre-trained Language Models, LPLMs)在自然语言处理领域取得了显著的成果。这些模型通常通过在大规模文本语料库上进行无监督预训练,然后微调到特定任务上…...
)
Rust常用库之序列化和反序列化库serde(使用 Serde 处理json)
文章目录 Rust常用库之序列化和反序列化库serde(使用 Serde 处理json)什么是serde库设计使用 Serde 处理jsonr# 的使用 参考 Rust常用库之序列化和反序列化库serde(使用 Serde 处理json) 什么是serde库 官网:https:/…...
java设计模式(2)---六大原则
设计模式之六大原则 这篇博客非常有意义,希望自己能够理解的基础上,在实际开发中融入这些思想,运用里面的精髓。 先列出六大原则:单一职责原则、里氏替换原则、接口隔离原则、依赖倒置原则、迪米特原则、开闭原则。 一、单一职…...
)
数学建模(层次分析法 python代码 案例)
目录 介绍: 模板: 例题:从景色、花费、饮食,男女比例四个方面去选取目的地 准则重要性矩阵: 每个准则的方案矩阵: 一致性检验: 特征值法求权值: 完整代码: 运行结果: 介绍:...

Gitlab介绍
1.什么是Gitlab GitLab是一个流行的版本控制系统平台,主要用于代码托管、测试和部署。 GitLab是基于Git的一个开源项目,它提供了一个用于仓库管理的Web服务。GitLab使用Ruby on Rails构建,并提供了诸如wiki和issue跟踪等功能。它允许用户通…...

Amuse .NET application for stable diffusion
Amuse github地址:https://github.com/tianleiwu/Amuse .NET application for stable diffusion, Leveraging OnnxStack, Amuse seamlessly integrates many StableDiffusion capabilities all within the .NET eco-system Welcome to Amuse! Amuse is a profes…...

【机器学习-05】模型的评估与选择
在前面【机器学习-01】机器学习基本概念与建模流程的文章中我们已经知道了机器学习的一些基本概念和模型构建的流程,本章我们将介绍模型训练出来后如何对模型进行评估和选择等 1、 误差与过拟合 学习器对样本的实际预测结果与真实值之间的差异,我们称之…...
【11】工程化
一、为什么需要模块化 当前端工程到达一定规模后,就会出现下面的问题: 全局变量污染 依赖混乱 上面的问题,共同导致了代码文件难以细分 模块化就是为了解决上面两个问题出现的 模块化出现后,我们就可以把臃肿的代码细分到各个小文件中,便于后期维护管理 前端模块化标准…...

Python中requests、aiohttp、httpx性能对比
在Python中,有许多用于发送HTTP请求的库,其中最受欢迎的是requests、aiohttp和httpx。这三个库的性能和功能各不相同,因此在选择使用哪个库时,需要考虑到自己的需求和应用场景。 首先,让我们来了解一下这三个库的基本…...
网络原理(5)——IP协议(网络层)
目录 一、IP协议报头介绍 1、4位版本 2、4位首部长度 3、8位服务器类型 4、16位总长度 5、16位标识位 6、3位标志位 7、13位偏移量 8、8位生存空间 9、8位协议 10、16位首部检验和 11、32位源IP地址 12、32位目的IP地址 二、IP协议如何管理地址? 1、动…...

GE IS200AEPAH1BKE IS215WEPAH2BB是两种不同的压力测量模块
GE IS200AEPAH1BKE和IS215WEPAH2BB是两种不同的压力测量模块,它们都属于GE(通用电气)公司的产品。 具体来说,以下是这两种模块的一些特点和应用: IS200AEPAH1BKE:这款模块适用于需要高性价比的压力测量应用…...

Rust 与 C++ ,孰优孰劣?
Rust 与 C 是两种高级系统级编程语言,它们都在追求性能、控制底层硬件细节的同时强调安全性。以下是两者的详细对比: 目标与理念 Rust:由 Mozilla 主导开发,目标是构建一种既快速又安全的系统级编程语言,特别是解决 C…...

MySQL、Oracle的时间类型字段自动更新:insert插入、update更新时,自动更新时间戳
1.MySQL 支持的字段类型:DATETIME、TIMESTAMP drop table if exists test_time_auto_update; create table test_time_auto_update (id bigint auto_increment primary key comment 自增id,name varchar(8) …...
Testng框架集成新业务
总体框架设计见我另一篇博客:httpclienttestng接口自动化整体框架设计 <block:表示测试用例块> block后面是 测试用例的名称 ||接口名,该接口名在URL.txt里维护接口 ||get\post:表示请求的方法 get_1\2\3\4:代表加密 get: …...

springboot 单元测试
Spring Boot 单元测试是确保代码质量的重要部分,它允许我们在不实际启动整个应用的情况下测试我们的代码。在Spring Boot中,我们通常使用Spring Test模块和JUnit测试框架来编写单元测试。以下是一个简单的Spring Boot单元测试的详细代码介绍:…...

LeetCode---126双周赛
题目列表 3079. 求出加密整数的和 3080. 执行操作标记数组中的元素 3081. 替换字符串中的问号使分数最小 3082. 求出所有子序列的能量和 一、求出加密整数的和 按照题目要求,直接模拟即可,代码如下 class Solution { public:int sumOfEncryptedInt…...

[python] ETL 工作流程 Prefect
Prefect 是一个用于构建、调度和监控数据流程的 Python 库。它提供了一种简单而强大的方式来管理 ETL(Extract, Transform, Load)工作流程。下面是一个简单的示例,演示了如何使用 Prefect 来创建和运行一个简单的任务: 首先&…...
html第一次作业
常用标签 0, 骨架(!tap) <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><t…...
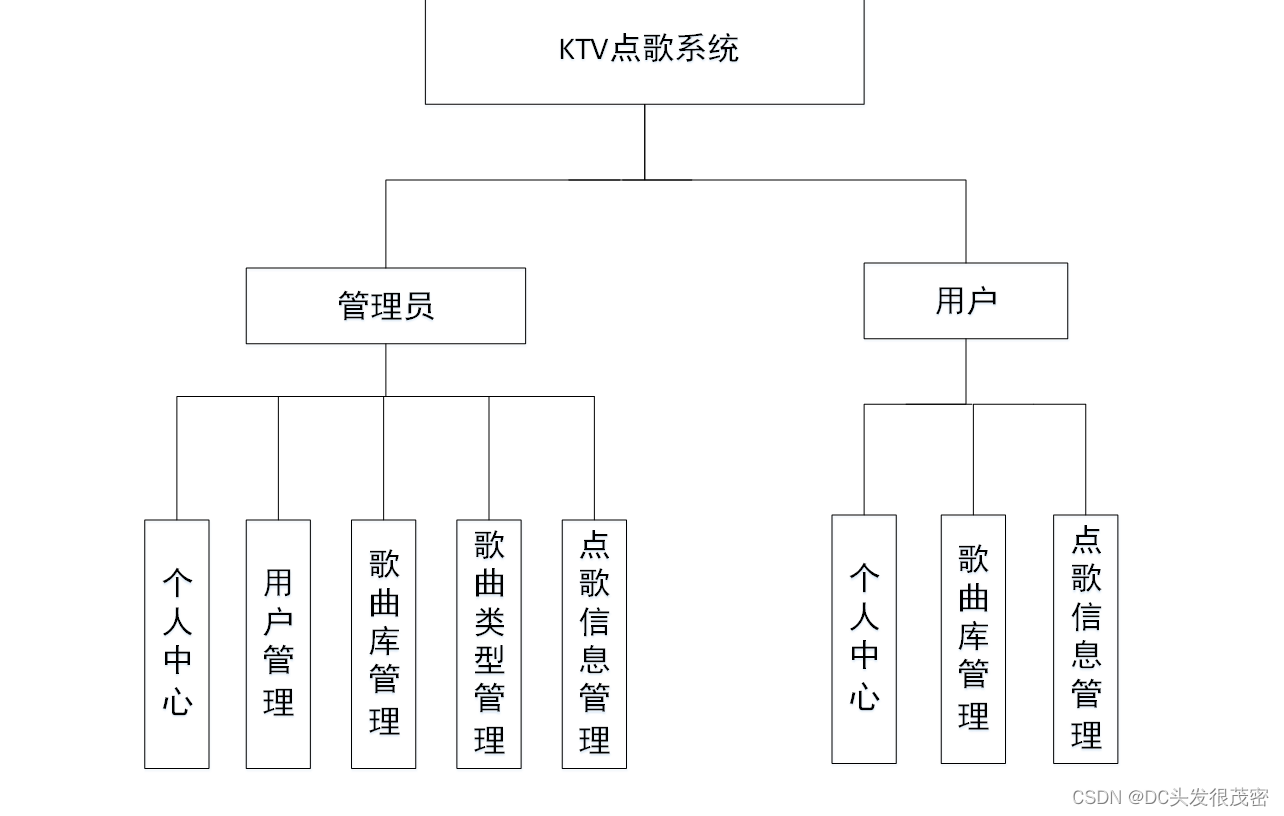
基于java实现的KTV点歌系统
开发语言:Java 框架:ssm 技术:JSP JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:eclipse/myeclip…...

GPT+向量数据库+Function calling=垂直领域小助手
引言 将 GPT、向量数据库和 Function calling 结合起来,可以构建一个垂直领域小助手。例如,我们可以使用 GPT 来处理自然语言任务,使用向量数据库来存储和管理领域相关的数据,使用 Function calling 来实现领域相关的推理和计算规…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...