如何使用 Elasticsearch 作为向量数据库
在今天的文章中,我们将很快地通过 Docker 来快速地设置 Elasticsearch 及 Kibana,并设置 Elasticsearch 为向量搜索。
拉取 Docker 镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.12.2
docker pull docker.elastic.co/kibana/kibana:8.12.2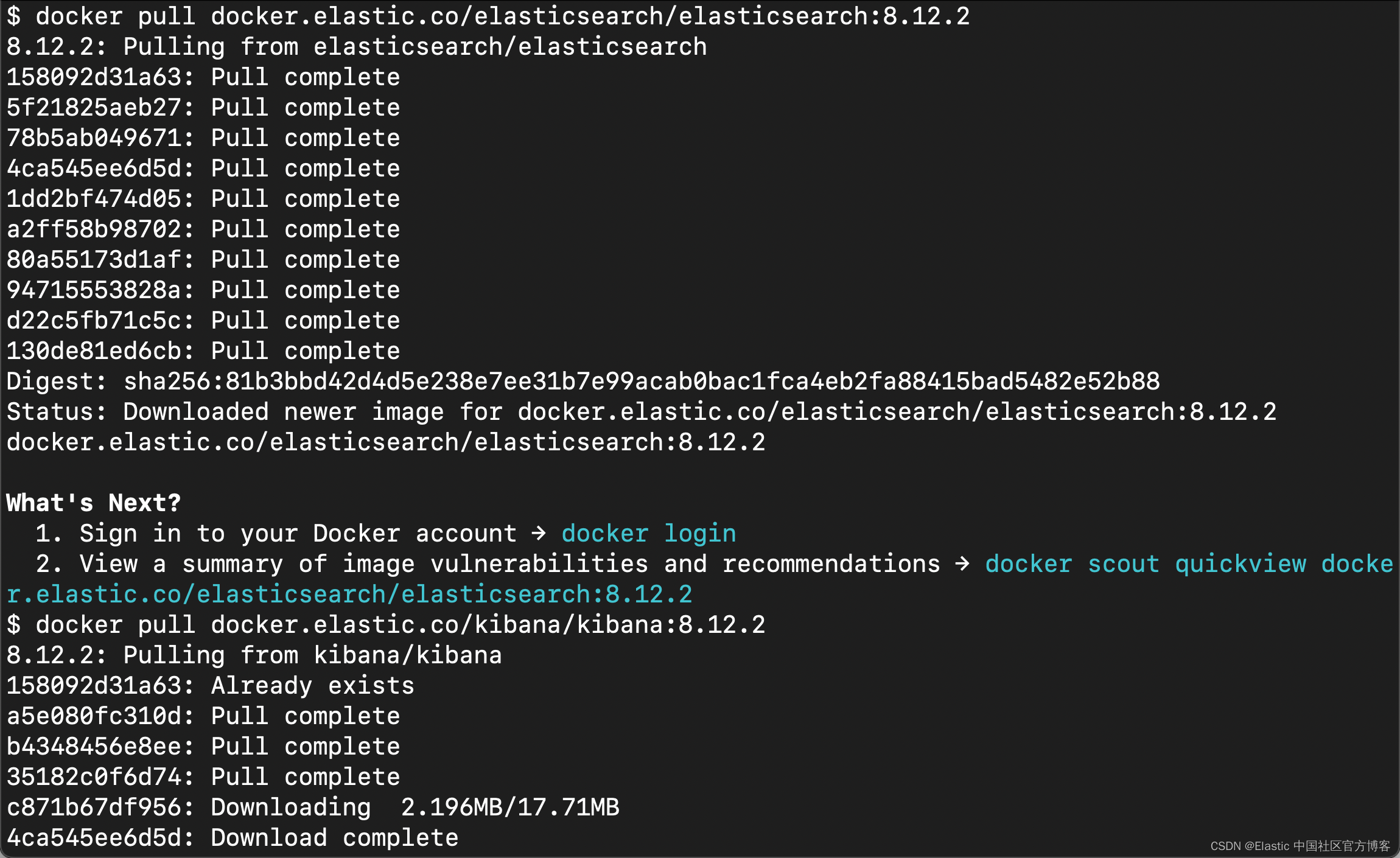
启动 Elasticsearch 及 Kibana 容器
docker network create elasticdocker run -d --name elasticsearch --net elastic -p 9200:9200 -p 9300:9300 -m 1GB -e "discovery.type=single-node" -e "ELASTIC_PASSWORD=password" docker.elastic.co/elasticsearch/elasticsearch:8.12.2docker run -d --name kibana --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.12.2$ docker run -d --name elasticsearch --net elastic -p 9200:9200 -p 9300:9300 -m 1GB -e "discovery.type=single-node" -e "ELASTIC_PASSWORD=password" docker.elastic.co/elasticsearch/elasticsearch:8.12.2
39dc9085f239edb3c963de4fb122f0ec02f78a6311abd8297cf046c025cd2618$ docker run -d --name kibana --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.12.2
2766a300b3fd165f793f5f47b55748b2e9d4b016ea78b5c23565442e2c4cdfb5在上面,我们指定了 elasic 超级用户的密码为 password。这在下面将要使用到。
验证容器是否已启动并正在运行:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2766a300b3fd docker.elastic.co/kibana/kibana:8.12.2 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:5601->5601/tcp kibana
39dc9085f239 docker.elastic.co/elasticsearch/elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 minutes ago Up 3 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch从上面我们可以看到 Elasticsarch 及 Kibana 已经完全运行起来了。我们可以在浏览器中进行验证:
docker exec -it elasticsearch /bin/bash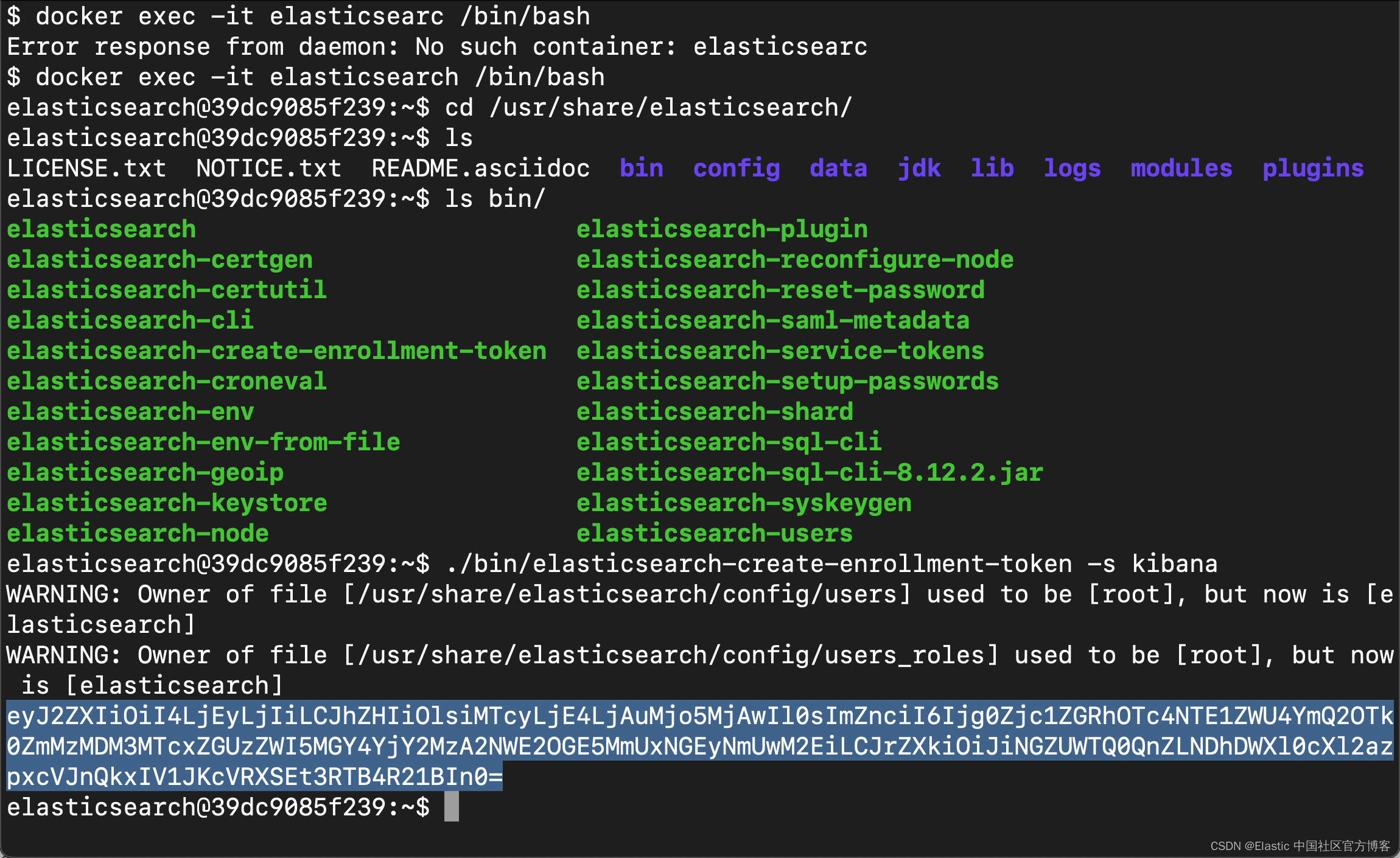
docker logs -f kibana$ docker logs -f kibana
Kibana is currently running with legacy OpenSSL providers enabled! For details and instructions on how to disable see https://www.elastic.co/guide/en/kibana/8.12/production.html#openssl-legacy-provider
{"log.level":"info","@timestamp":"2024-03-22T01:28:37.598Z","log.logger":"elastic-apm-node","ecs.version":"8.10.0","agentVersion":"4.2.0","env":{"pid":7,"proctitle":"/usr/share/kibana/bin/../node/bin/node","os":"linux 6.4.16-linuxkit","arch":"arm64","host":"2766a300b3fd","timezone":"UTC+00","runtime":"Node.js v18.18.2"},"config":{"active":{"source":"start","value":true},"breakdownMetrics":{"source":"start","value":false},"captureBody":{"source":"start","value":"off","commonName":"capture_body"},"captureHeaders":{"source":"start","value":false},"centralConfig":{"source":"start","value":false},"contextPropagationOnly":{"source":"start","value":true},"environment":{"source":"start","value":"production"},"globalLabels":{"source":"start","value":[["git_rev","f5bd489c5ff9c676c4f861c42da6ea99ae350832"]],"sourceValue":{"git_rev":"f5bd489c5ff9c676c4f861c42da6ea99ae350832"}},"logLevel":{"source":"default","value":"info","commonName":"log_level"},"metricsInterval":{"source":"start","value":120,"sourceValue":"120s"},"serverUrl":{"source":"start","value":"https://kibana-cloud-apm.apm.us-east-1.aws.found.io/","commonName":"server_url"},"transactionSampleRate":{"source":"start","value":0.1,"commonName":"transaction_sample_rate"},"captureSpanStackTraces":{"source":"start","sourceValue":false},"secretToken":{"source":"start","value":"[REDACTED]","commonName":"secret_token"},"serviceName":{"source":"start","value":"kibana","commonName":"service_name"},"serviceVersion":{"source":"start","value":"8.12.2","commonName":"service_version"}},"activationMethod":"require","message":"Elastic APM Node.js Agent v4.2.0"}
[2024-03-22T01:28:38.276+00:00][INFO ][root] Kibana is starting
[2024-03-22T01:28:38.320+00:00][INFO ][node] Kibana process configured with roles: [background_tasks, ui]
[2024-03-22T01:28:42.183+00:00][INFO ][plugins-service] Plugin "cloudChat" is disabled.
[2024-03-22T01:28:42.192+00:00][INFO ][plugins-service] Plugin "cloudExperiments" is disabled.
[2024-03-22T01:28:42.193+00:00][INFO ][plugins-service] Plugin "cloudFullStory" is disabled.
[2024-03-22T01:28:42.501+00:00][INFO ][plugins-service] Plugin "profilingDataAccess" is disabled.
[2024-03-22T01:28:42.501+00:00][INFO ][plugins-service] Plugin "profiling" is disabled.
[2024-03-22T01:28:42.587+00:00][INFO ][plugins-service] Plugin "securitySolutionServerless" is disabled.
[2024-03-22T01:28:42.587+00:00][INFO ][plugins-service] Plugin "serverless" is disabled.
[2024-03-22T01:28:42.587+00:00][INFO ][plugins-service] Plugin "serverlessObservability" is disabled.
[2024-03-22T01:28:42.587+00:00][INFO ][plugins-service] Plugin "serverlessSearch" is disabled.
[2024-03-22T01:28:42.929+00:00][INFO ][http.server.Preboot] http server running at http://0.0.0.0:5601
[2024-03-22T01:28:42.996+00:00][INFO ][plugins-system.preboot] Setting up [1] plugins: [interactiveSetup]
[2024-03-22T01:28:43.004+00:00][INFO ][preboot] "interactiveSetup" plugin is holding setup: Validating Elasticsearch connection configuration…
[2024-03-22T01:28:43.019+00:00][INFO ][root] Holding setup until preboot stage is completed.i Kibana has not been configured.Go to http://0.0.0.0:5601/?code=897018 to get started.Your verification code is: 897 018 我们把上面的 enrollment token 及 verification code 填入下面的方框里:
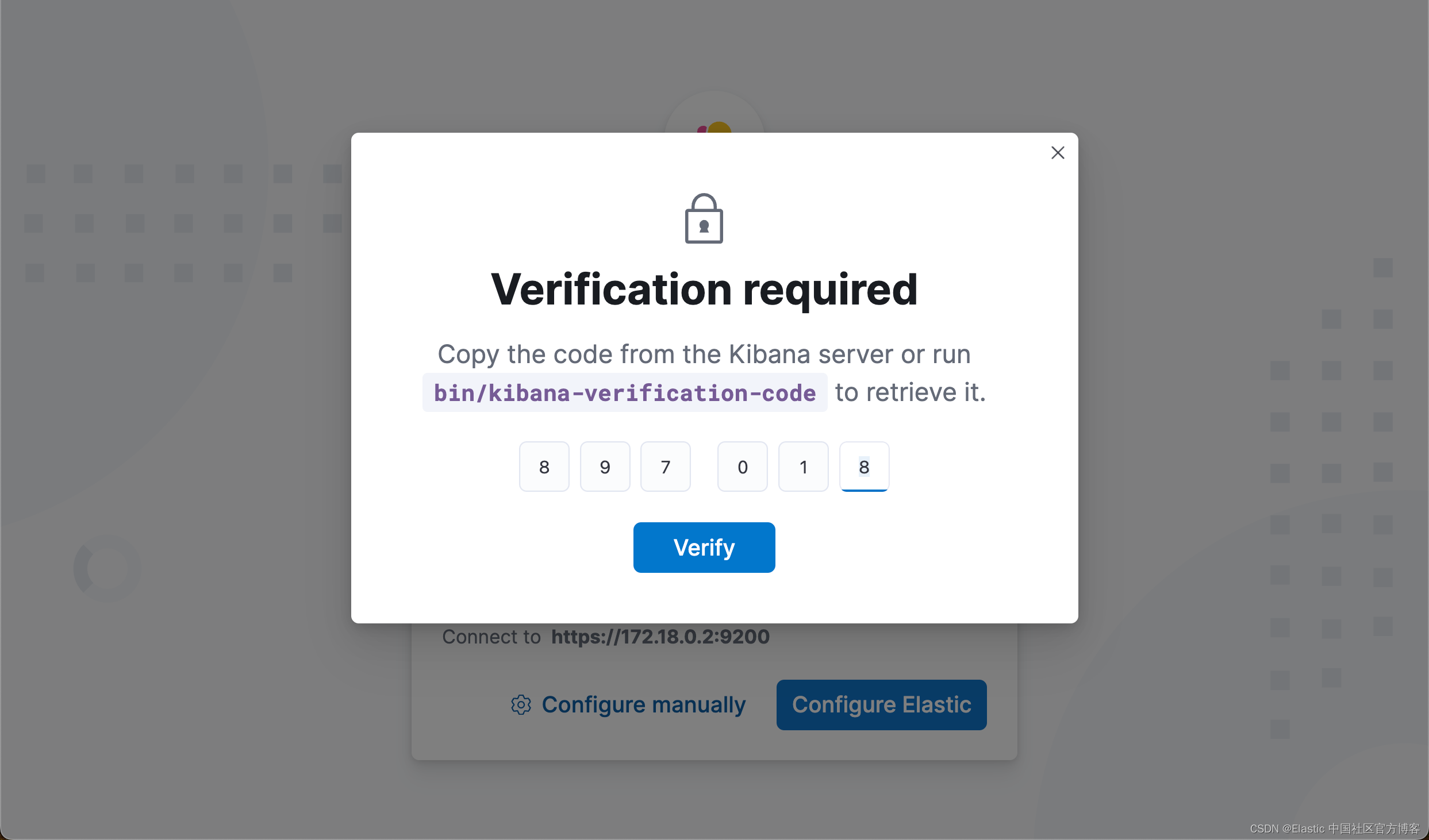
注意:由于一些原因,在上面显示的地址不是 localhost,而是电脑上的另外一个地址,比如 172.18.0.2:9200。这个并不影响我们的配置。
这样我们就成功地登录了。
创建索引
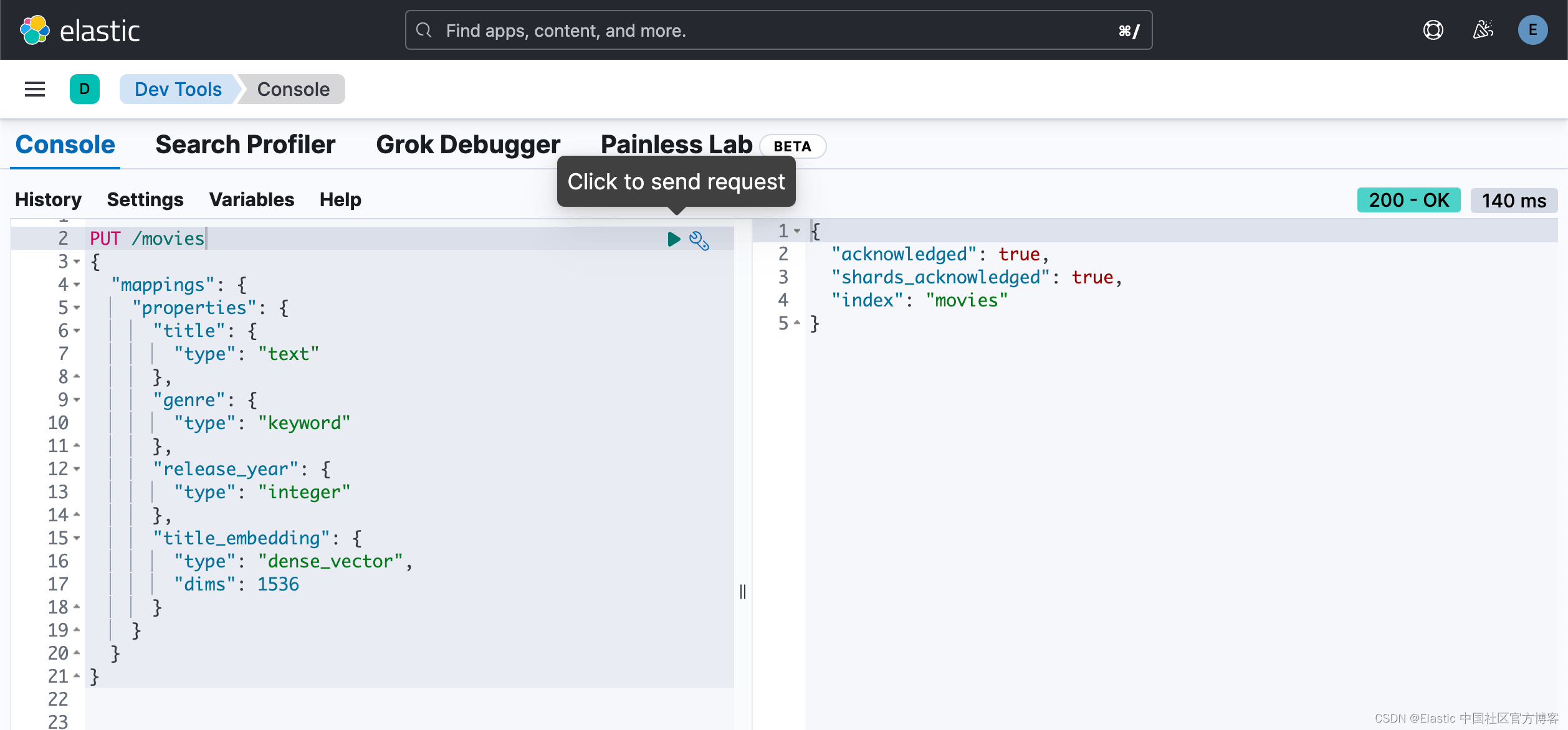
现在,让我们创建 “movies” 索引。 我们将使用 text-embedding-3-small 模型来生成 title 字段的向量嵌入并将其存储为 title_embedding。 该模型生成长度为 1536 的嵌入。因此我们需要将 title_embedding 字段映射指定为具有 1536 维的密集向量。
PUT /movies
{"mappings": {"properties": {"title": {"type": "text"},"genre": {"type": "keyword"},"release_year": {"type": "integer"},"title_embedding": {"type": "dense_vector","dims": 1536}}}
}
让我们使用 Elasticsearch Python 客户端插入一些文档。
Python 客户端需要 `ssl_assert_fingerprint` 才能连接到 Elasticsearch。 让我们使用以下命令来获取它:
openssl s_client -connect localhost:9200 -servername localhost -showcerts </dev/null 2>/dev/null | openssl x509 -fingerprint -sha256 -noout -in /dev/stdin$ openssl s_client -connect localhost:9200 -servername localhost -showcerts </dev/null 2>/dev/null | openssl x509 -fingerprint -sha256 -noout -in /dev/stdinsha256 Fingerprint=20:67:39:6C:33:C0:D6:AC:E2:E3:A5:2E:56:6C:57:4F:91:DC:41:4D:99:9B:7F:0F:1C:20:AD:E2:20:FE:1E:1B写入文档到 Elasticsearch
现在我们可以在电影索引中插入一些文档。
我们现在 terminal 中打入如下的命令:
export OPENAI_API_KEY="YourOpenAiKey"在上面,请填入自己申请的 OpenAI key。
请按照下面的命令来安装所需要的包:
pip3 install elasticsearch python-dotenv我们创建如下的 python 应用:
write_index.py
from elasticsearch import Elasticsearch
from openai import OpenAI
import osOPENAI_API_KEY= os.getenv("OPENAI_API_KEY")es = Elasticsearch("https://localhost:9200",ssl_assert_fingerprint='20:67:39:6C:33:C0:D6:AC:E2:E3:A5:2E:56:6C:57:4F:91:DC:41:4D:99:9B:7F:0F:1C:20:AD:E2:20:FE:1E:1B',basic_auth=("elastic", "password")
)openai = OpenAI(api_key=OPENAI_API_KEY)movies = [{"title": "Inception", "genre": "Sci-Fi", "release_year": 2010},{"title": "The Shawshank Redemption", "genre": "Drama", "release_year": 1994},{"title": "The Godfather", "genre": "Crime", "release_year": 1972},{"title": "Pulp Fiction", "genre": "Crime", "release_year": 1994},{"title": "Forrest Gump", "genre": "Drama", "release_year": 1994}
]# Indexing movies
for movie in movies:movie['title_embedding'] = openai.embeddings.create(input=[movie['title']], model='text-embedding-3-small').data[0].embeddinges.index(index="movies", document=movie)我们使用如下的命令来运行脚本:
python3 write_index.py我们可以在 Kibana 中进行查看:
GET movies/_search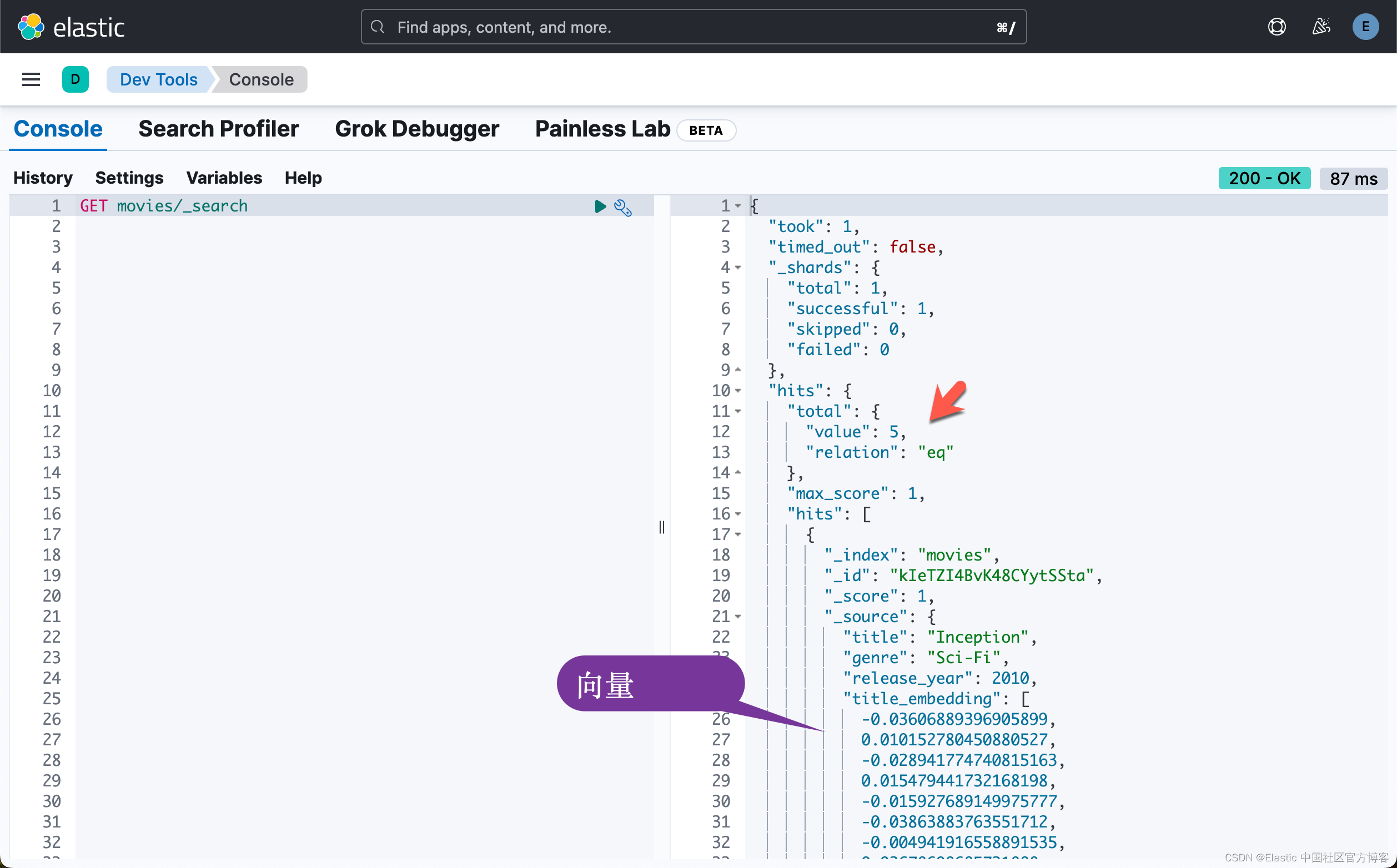
搜索索引
比方说,我们想要搜索与片名《godfather》紧密匹配的电影。 我们可以使用K最近邻(KNN)算法来搜索相关文档。 我们会将搜索限制为仅显示 1 个最接近的匹配结果。
首先我们需要获得单词 Godfather 的向量表示:
vector_value = openai_client.embeddings.create(input=["Godfather"], model='text-embedding-3-small').data[0].embedding现在我们可以搜索电影索引来获取与片名《Godfather》紧密匹配的电影。 在我们的例子中,它应该与标题为《Godfather》的电影文档匹配。
query_string = {"field": "title_embedding","query_vector": vector_value,"k": 1,"num_candidates": 100
}results = es_client.search(index="movies", knn=query_string, source_includes=["title", "genre", "release_year"])print(results['hits']['hits'])完整的 Python 应用如下:
search_index.py
from elasticsearch import Elasticsearch
from openai import OpenAI
import osOPENAI_API_KEY= os.getenv("OPENAI_API_KEY")es = Elasticsearch("https://localhost:9200",ssl_assert_fingerprint='20:67:39:6C:33:C0:D6:AC:E2:E3:A5:2E:56:6C:57:4F:91:DC:41:4D:99:9B:7F:0F:1C:20:AD:E2:20:FE:1E:1B',basic_auth=("elastic", "password")
)openai = OpenAI(api_key=OPENAI_API_KEY)vector_value = openai.embeddings.create(input=["Godfather"], model='text-embedding-3-small').data[0].embeddingquery_string = {"field": "title_embedding","query_vector": vector_value,"k": 1,"num_candidates": 100
}results = es.search(index="movies", knn=query_string, source_includes=["title", "genre", "release_year"])print(results['hits']['hits'])运行上面的代码:
$ python3 search_index.py
[{'_index': 'movies', '_id': 'koeTZI4BvK48CYytTCuI', '_score': 0.8956262, '_source': {'title': 'The Godfather', 'genre': 'Crime', 'release_year': 1972}}]很显然,它找到了 Godfather 这个文档。
很多开发者可能想问,我们是不是也可以使用中文来进行搜索呢?
我们尝试如下的代码:
search_index.py
from elasticsearch import Elasticsearch
from openai import OpenAI
import osOPENAI_API_KEY= os.getenv("OPENAI_API_KEY")es = Elasticsearch("https://localhost:9200",ssl_assert_fingerprint='20:67:39:6C:33:C0:D6:AC:E2:E3:A5:2E:56:6C:57:4F:91:DC:41:4D:99:9B:7F:0F:1C:20:AD:E2:20:FE:1E:1B',basic_auth=("elastic", "password")
)openai = OpenAI(api_key=OPENAI_API_KEY)vector_value = openai.embeddings.create(input=["教父"], model='text-embedding-3-small').data[0].embeddingquery_string = {"field": "title_embedding","query_vector": vector_value,"k": 1,"num_candidates": 100
}results = es.search(index="movies", knn=query_string, source_includes=["title", "genre", "release_year"])print(results['hits']['hits'])在上面的代码中,我们使用 “教父” 而不是 Godfather。运行上面的代码,它显示:
$ python3 search_index.py
[{'_index': 'movies', '_id': 'koeTZI4BvK48CYytTCuI', '_score': 0.6547822, '_source': {'title': 'The Godfather', 'genre': 'Crime', 'release_year': 1972}}]很显然,它也同样找到 Godfather 这个电影。它说明这个大语言模型支持多语言的搜索。
相关文章:
如何使用 Elasticsearch 作为向量数据库
在今天的文章中,我们将很快地通过 Docker 来快速地设置 Elasticsearch 及 Kibana,并设置 Elasticsearch 为向量搜索。 拉取 Docker 镜像 docker pull docker.elastic.co/elasticsearch/elasticsearch:8.12.2 docker pull docker.elastic.co/kibana/kiba…...

高精度AI火灾烟雾检测算法,助力打造更加安全的楼宇环境
一、方案背景 近日,南京居民楼火灾事故导致15人死亡的新闻闹得沸沸扬扬,这一事件又激起了大家对楼宇火灾隐患的进一步担忧。事后我们除了思考政府、消防及物业部门应对此事的解决办法,我们还应该思考如何利用现有的技术帮助人们减少此类事情的…...

node和npm yarn包管理工具
node和包管理工具 今日目标: 1.dos常用指令 2.node的模块化 3.npm包管理工具 4.yarn的常用指令 5.node的内置模块 00-回顾 # Promose:作用:解决ajax请求响应顺序不可控的问题特性:1. Promise是一个构造函数,需要通过new关…...

鸿蒙Harmony应用开发—ArkTS(@Link装饰器:父子双向同步)
子组件中被Link装饰的变量与其父组件中对应的数据源建立双向数据绑定。 说明: 从API version 9开始,该装饰器支持在ArkTS卡片中使用。 概述 Link装饰的变量与其父组件中的数据源共享相同的值。 限制条件 Link装饰器不能在Entry装饰的自定义组件中使用…...
【数据结构】猛猛干7道链表OJ
前言知识点 链表的调试技巧 int main() {struct ListNode* n1(struct ListNode*)malloc(sizeof(struct ListNode));assert(n1);struct ListNode* n2(struct ListNode*)malloc(sizeof(struct ListNode));assert(n2);struct ListNode* n3(struct ListNode*)malloc(sizeof(struc…...

记录C++中,子类同名属性并不能完全覆盖父类属性的问题
问题代码: 首先看一段代码:很简单,就是BBB继承自AAA,然后BBB重写定义了同名属性,然后调用父类AAA的打印函数: #include <iostream> using namespace std;class AAA { public:AAA() {}~AAA() {}void …...
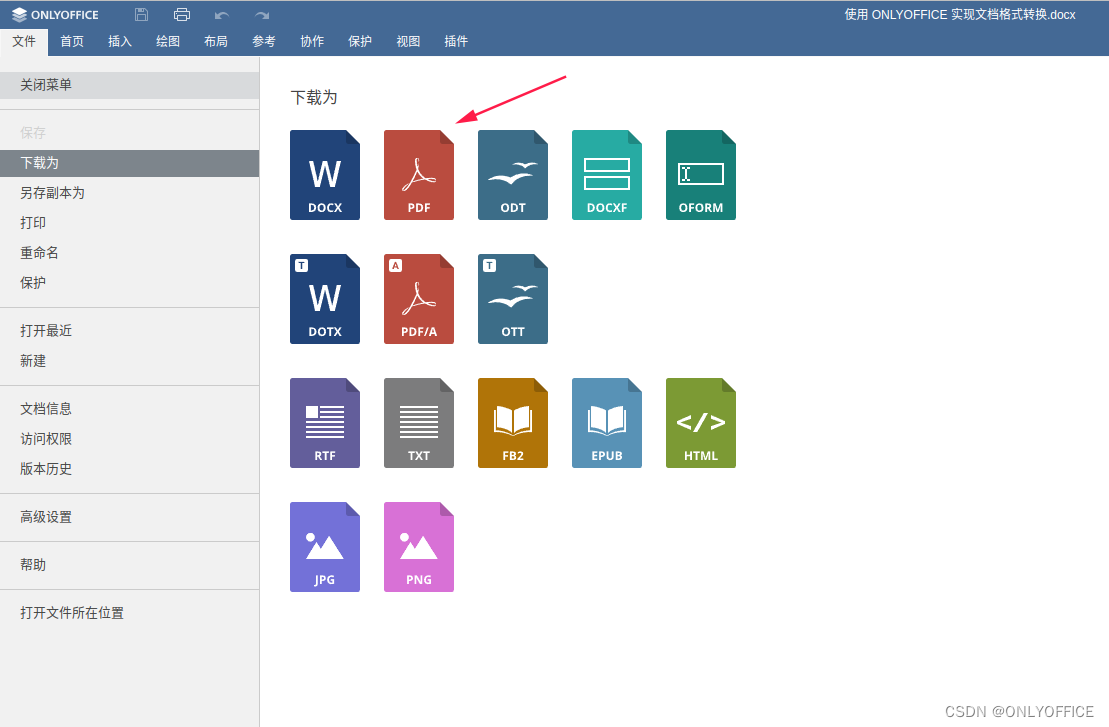
使用 ONLYOFFICE API 构建 Java 转换器,在 Word 和 PDF 之间进行转换
文章作者:ajun 随着文档处理需求的增加,格式转换成为了一个重要的需求点。由于PDF格式具有跨平台、不易被篡改的特性,将Word格式(.docx)转换为PDF格式(.pdf)的需求尤为强烈。ONLYOFFICE作为一个强大的办公套件,提供了这样的转换功…...
SpringCloudAlibaba Nacos配置及应用
Nacos搭建及配置 nacos本机服务搭建 windows上搭建单机nacos: Releases alibaba/nacos GitHub 下载安装包 下载本地,解压,直接运行(保证安装包的绝度路径只有英文字符,有中文会导致运行失败)ÿ…...

#Linux(权限管理)
(一)发行版:Ubuntu16.04.7 (二)记录: (1) (2)-开头代表普通文件 划分为三组: rw- rw- r-- rw-: 文件拥有…...
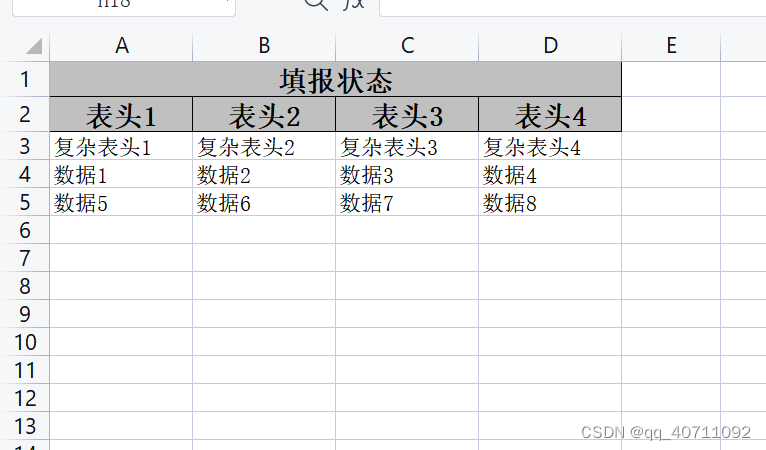
easyExcel复杂表头导出
代码 import com.alibaba.excel.EasyExcel; import com.alibaba.excel.write.style.column.AbstractColumnWidthStyleStrategy; import com.alibaba.excel.write.style.column.LongestMatchColumnWidthStyleStrategy;import java.util.ArrayList; import java.util.Arrays; imp…...

【大数据】五、yarn基础
Yarn Yarn 是用来做分布式系统中的资源协调技术 MapReduce 1.x 对于 MapReduce 1.x 的版本上: 由 Client 发起计算请求,Job Tracker 接收请求之后分发给各个TaskTrack进行执行 在这个阶段,资源的管理与请求的计算是集成在 mapreduce 上的…...
语义分割实战项目(从原理到代码环境配置)
语义分割(Semantic Segmentation) 先看结果: 是计算机视觉和深度学习领域的一项核心任务,它主要致力于对图像中的每一个像素进行分类,赋予每个像素一个类别标签,以达到理解图像内容的目的。换句话说&#…...
基于python+vue 的一加剧场管理系统的设计与实现flask-django-nodejs-php
二十一世纪我们的社会进入了信息时代,信息管理系统的建立,大大提高了人们信息化水平。传统的管理方式对时间、地点的限制太多,而在线管理系统刚好能满足这些需求,在线管理系统突破了传统管理方式的局限性。于是本文针对这一需求设…...

【Entity Framework】 EF中DbContext类详解
【Entity Framework】 EF中DbContext类详解 一、概述 DbContext类是实体框架的重要组成部分。它是应用域或实例类与数据库交互的桥梁。 从上图可以看出DbContext是负责与数据交互作为对象的主要类。DbContext负责以下活动: EntitySet:DbContext包含…...

智能风扇的新篇章:唯创知音WTK6900G语音识别芯片引领行业革新
随着科技浪潮的推进,智能化技术逐渐渗透到生活的每一个角落,家电领域尤为明显。风扇,这一夏日清凉神器,也通过智能化改造,焕发出前所未有的光彩。其中,智能语音控制功能的加入,为风扇的使用带来…...

[json.exception.type_error.316] invalid UTF-8 byte报错
[json.exception.type_error.316] invalid UTF-8 byte at index 1: 解决方法重新编译程序即可。...

深度强化学习(九)(改进策略梯度)
深度强化学习(九)(改进策略梯度) 一.带基线的策略梯度方法 Theorem: 设 b b b 是任意的函数, b b b与 A A A无关。把 b b b 作为动作价值函数 Q π ( S , A ) Q_\pi(S, A) Qπ(S,A) 的基线, 对策略梯度没有影响: ∇ θ J …...

Oracle修改Number类型精度报错:ORA-01440
修改Number类型的字段的精度SQL ALTER TABLE XXXX MODIFY RATE NUMBER(30,6); 如果表已经存在数据,报错信息如下: ORA-01440: column to be modified must be empty to decrease precision or scale 废话不多说,解决方案如下:…...

美团到店-后端开发一面
1. 介绍一下spring的两大核心思想 2. 介绍一下java的代理,以及动态代理和静态代理的区别 3. spring动态代理是如何生成的,jdk动态代理和cglib的区别 4. 介绍一下synchronized关键字、以及synchronized锁和lock的区别 5. 讲一下java中synchronized的锁升级…...

面试算法-77-括号生成
题目 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”] 解 class Solution {publ…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...