【大数据】五、yarn基础
Yarn
Yarn 是用来做分布式系统中的资源协调技术
MapReduce 1.x
对于 MapReduce 1.x 的版本上:
由 Client 发起计算请求,Job Tracker 接收请求之后分发给各个TaskTrack进行执行
在这个阶段,资源的管理与请求的计算是集成在 mapreduce 上的,这种架构会导致 mapreduce 的功能过于臃肿,也会衍生出一系列的问题。
而 YARN 的出现及时的对这个问题作出了改变,YARN 就类似于一个操作系统,mapreduce 就类似于运行在 YARN 这个操作系统上的实际程序
YARN 同时也支持 Spark、Flink、Taz 等分布式计算技术,这使得 YARN 进一步被发扬光大
YARN 基础
Yarn 的基础原理就是将资源管理 与 作业调度(监视)功能进行拆分,由 ResourceManager 进行资源管理,由 ApplicationMaster 进行作业调度与监视功能
ResourceManager
NodeManager
NodeManager
…
Client 将作业提交给 ResourceManager 进行资源调度
YARN 基础配置
ResourceManager 会将任务分配给一个个的 NodeManager 每个NodeManager 中都有一个个的Contaniner,这一个个的 Container中就保存着一个个的任务的计算,同时,NodeManager 中也保存着一个个任务的 Application Master、每一个 Container 的计算完成后会汇报给 Application Master 其结束的信息,Application Master 会及时向 Resource Manager 汇报其情况信息。
修改 mapred-site.xml:
在最后添加;
<configuration><!-- 指定Mapreduce 的作业执行时,用yarn进行资源调度 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/export/server/hadoop-3.3.6</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/export/server/hadoop-3.3.6</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/export/server/hadoop-3.3.6</value></property>
</configuration>
修改 yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><!-- 设置ResourceManager --><property><name>yarn.resourcemanager.hostname</name><value>node1</value></property><!--配置yarn的shuffle服务--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property>
</configuration>在 hadoop-env.sh 中添加:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
之后将修改好的这几个文件分发给其他节点
scp mapred-site.xml yarn-site.xml hadoop-env.sh node2:$PWD
scp mapred-site.xml yarn-site.xml hadoop-env.sh node3:$PWD
之后就可以打开 yarn.sh:
start-yarn.sh
之后在对应的 8088 端口就可以找到对应的可视化网页信息了
进行词频统计(wordcount)的测试:
hadoop jar /export/server/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input /output1
就可以顺利调用对应的东西了。
另外,如果我们希望查看日志信息,还需要再 mapred-site.xml 中继续进行配置:
<property><name>MapReduce.jobhistory.address</name><value>node1:10020</value></property><property><name>MapReduce.jobhistory.webapp.address</name><value>node1:19888</value></property>
继续在 yarn.xml 中配置:
<!-- 添加如下配置 --><!-- 是否需要开启⽇志聚合 --><!-- 开启⽇志聚合后,将会将各个Container的⽇志保存在yarn.nodemanager.remote-app-logdir的位置 --><!-- 默认保存在/tmp/logs --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 历史⽇志在HDFS保存的时间,单位是秒 --><!-- 默认的是-1,表示永久保存 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value></property>
YARN 的任务提交流程

-
MapReduce 程序运行 Job 任务,创建出一个 JobCommiter,再由 JobCommiter 进行任务提交等工作。
-
JobCommiter 会将自己要执行的任务提交给 ResourceManager,申请一个应用ID
-
若资源足够,ResourceManager 会分配给 MapReduce 一个应用ID,这个时候,Mapreduce 会将自己的程序上传到 HDFS,再由需要程序的节点下载对应的程序来进行运算
-
JobCommitter 正式向 ResourceManager 提交作业任务,
-
ResourceManager 会找到一个负载较小的 NodeManager,指定其完成这个任务
-
这个被指定的 NodeManager 会创建一个 Container,并创建一个 AppMaster 用来监控这个任务并调度资源(这个 AppMaster 会从 HDFS 上接收对应的信息(分片信息、任务程序)对应每一个分片都对应一个 MapTask)
-
在明确了需要的空间之后,这个 AppMaster 会向 ResourceManager 申请资源,ResourceManager 会根据 NodeManager 上的负载情况为其分配对应的 NodeManager
-
对应的 Node Manager 会向 HDFS 上下载对应的程序,进行真正的任务计算,并在执行的时候向 APPMaster 进行汇报,例如在成功的时候向 appMaster 进行报告。
YARN 的命令
查看当前在 yarn 中运行的任务:
yarn top
测试一下执行:
hadoop jar /export/server/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 10 10
使用 yarn application 可以查看运行的任务信息
yarn application -list -appStates ALL # 查看所有任务信息
yarn application -list -appStates FINISHED / RUNNING # 查看所有已完成的 / 正在运行的
我们也可以根据查看出来的 APPID 直接杀死进程:
yarn application -kill xxxxxxxxxxx
被杀死的任务会被标记为 KILLED,我们可以使用 yarn application -list -appStates KILLED 来进行查看
YARN 调度器
先进先出调度器
如题,先来的先处理,存在饥饿问题哪怕你只需要一毫秒的运行也需要一直等
容量调度器
会开辟两个空间,其中 80% 的资源会用来像 FIFO 一样进行处理,另有 20% 等待处理其他问题,这样就在一定程度上规避了小型任务饥饿问题,但其存在资源浪费问题,因为可能有 20% 的资源始终没有使用
公平调度器
公平调度器会为每个任务分配相同的资源,当有任务执行结束时,其会将其所占有的资源分配给其他任务
YARN 的队列
YARN 默认使用的是 只有一个队列的容量调度器,其实也就是 FIFO,但这里我们可以进行配置,一般情况下,会创建两个队列,一个用来处理主任务,另一个用来处理小任务
这里需要修改配置文件:
修改 etc/hadoop 中的 capacity-scheduler.xml:
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
-->
<configuration><!-- yarn 允许的提交任务的最大数量 --><property><name>yarn.scheduler.capacity.maximum-applications</name><value>10000</value><description>Maximum number of applications that can be pending and running.</description></property><!-- Application Master 允许占集群的资源比例,0.1 代表 10% --><property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.1</value><description>Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent runningapplications.</description></property><!-- 队列类型 --><property><name>yarn.scheduler.capacity.resource-calculator</name><value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value><description>The ResourceCalculator implementation to be used to compare Resources in the scheduler.The default i.e. DefaultResourceCalculator only uses Memory whileDominantResourceCalculator uses dominant-resource to compare multi-dimensional resources such as Memory, CPU etc.</description></property><!-- 默认只有一个 default 队列,这里再添加一个 small 队列来处理小任务 --><property><name>yarn.scheduler.capacity.root.queues</name><value>default,small</value><description>The queues at the this level (root is the root queue).</description></property><!-- 这里是每个队列占用的资源百分比 --><property><name>yarn.scheduler.capacity.root.default.capacity</name><value>70</value><description>Default queue target capacity.</description></property><property><name>yarn.scheduler.capacity.root.small.capacity</name><value>30</value><description>Default queue target capacity.</description></property><!-- 用户可以占用的资源的比例 --><property><name>yarn.scheduler.capacity.root.default.user-limit-factor</name><value>1</value><description>Default queue user limit a percentage from 0.0 to 1.0.</description></property><property><name>yarn.scheduler.capacity.root.small.user-limit-factor</name><value>1</value><description>Default queue user limit a percentage from 0.0 to 1.0.</description></property><!-- 每个队列最多占用整体资源的比例 --><property><name>yarn.scheduler.capacity.root.default.maximum-capacity</name><value>100</value><description>The maximum capacity of the default queue. </description></property><property><name>yarn.scheduler.capacity.root.small.maximum-capacity</name><value>100</value><description>The maximum capacity of the default queue. </description></property><!-- 队列的状态 RUNNING 表示该队列是启用的状态 --><property><name>yarn.scheduler.capacity.root.default.state</name><value>RUNNING</value><description>The state of the default queue. State can be one of RUNNING or STOPPED.</description></property><property><name>yarn.scheduler.capacity.root.small.state</name><value>RUNNING</value><description>The state of the default queue. State can be one of RUNNING or STOPPED.</description></property><!-- 权限管理 允许哪些用户向队列中提交任务 --><property><name>yarn.scheduler.capacity.root.default.acl_submit_applications</name><value>*</value><description>The ACL of who can submit jobs to the default queue.</description></property><property><name>yarn.scheduler.capacity.root.small.acl_submit_applications</name><value>*</value><description>The ACL of who can submit jobs to the default queue.</description></property><property><name>yarn.scheduler.capacity.root.default.acl_administer_queue</name><value>*</value><description>The ACL of who can administer jobs on the default queue.</description></property><property><name>yarn.scheduler.capacity.root.small.acl_administer_queue</name><value>*</value><description>The ACL of who can administer jobs on the default queue.</description></property><property><name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name><value>*</value><description>The ACL of who can submit applications with configured priority.For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}]</description></property><property><name>yarn.scheduler.capacity.root.small.acl_application_max_priority</name><value>*</value><description>The ACL of who can submit applications with configured priority.For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}]</description></property><property><name>yarn.scheduler.capacity.root.default.maximum-application-lifetime</name><value>-1</value><description>Maximum lifetime of an application which is submitted to a queuein seconds. Any value less than or equal to zero will be considered asdisabled.This will be a hard time limit for all applications in thisqueue. If positive value is configured then any application submittedto this queue will be killed after exceeds the configured lifetime.User can also specify lifetime per application basis inapplication submission context. But user lifetime will beoverridden if it exceeds queue maximum lifetime. It is point-in-timeconfiguration.Note : Configuring too low value will result in killing applicationsooner. This feature is applicable only for leaf queue.</description></property><property><name>yarn.scheduler.capacity.root.small.maximum-application-lifetime</name><value>-1</value><description>Maximum lifetime of an application which is submitted to a queuein seconds. Any value less than or equal to zero will be considered asdisabled.This will be a hard time limit for all applications in thisqueue. If positive value is configured then any application submittedto this queue will be killed after exceeds the configured lifetime.User can also specify lifetime per application basis inapplication submission context. But user lifetime will beoverridden if it exceeds queue maximum lifetime. It is point-in-timeconfiguration.Note : Configuring too low value will result in killing applicationsooner. This feature is applicable only for leaf queue.</description></property><property><name>yarn.scheduler.capacity.root.default.default-application-lifetime</name><value>-1</value><description>Default lifetime of an application which is submitted to a queuein seconds. Any value less than or equal to zero will be considered asdisabled.If the user has not submitted application with lifetime value then thisvalue will be taken. It is point-in-time configuration.Note : Default lifetime can't exceed maximum lifetime. This feature isapplicable only for leaf queue.</description></property><property><name>yarn.scheduler.capacity.root.small.default-application-lifetime</name><value>-1</value><description>Default lifetime of an application which is submitted to a queuein seconds. Any value less than or equal to zero will be considered asdisabled.If the user has not submitted application with lifetime value then thisvalue will be taken. It is point-in-time configuration.Note : Default lifetime can't exceed maximum lifetime. This feature isapplicable only for leaf queue.</description></property><property><name>yarn.scheduler.capacity.node-locality-delay</name><value>40</value><description>Number of missed scheduling opportunities after which the CapacityScheduler attempts to schedule rack-local containers.When setting this parameter, the size of the cluster should be taken into account.We use 40 as the default value, which is approximately the number of nodes in one rack.Note, if this value is -1, the locality constraint in the container requestwill be ignored, which disables the delay scheduling.</description></property><property><name>yarn.scheduler.capacity.rack-locality-additional-delay</name><value>-1</value><description>Number of additional missed scheduling opportunities over the node-locality-delayones, after which the CapacityScheduler attempts to schedule off-switch containers,instead of rack-local ones.Example: with node-locality-delay=40 and rack-locality-delay=20, the scheduler willattempt rack-local assignments after 40 missed opportunities, and off-switch assignmentsafter 40+20=60 missed opportunities.When setting this parameter, the size of the cluster should be taken into account.We use -1 as the default value, which disables this feature. In this case, the numberof missed opportunities for assigning off-switch containers is calculated based onthe number of containers and unique locations specified in the resource request,as well as the size of the cluster.</description></property><property><name>yarn.scheduler.capacity.queue-mappings</name><value></value><description>A list of mappings that will be used to assign jobs to queuesThe syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*Typically this list will be used to map users to queues,for example, u:%user:%user maps all users to queues with the same nameas the user.</description></property><property><name>yarn.scheduler.capacity.queue-mappings-override.enable</name><value>false</value><description>If a queue mapping is present, will it override the value specifiedby the user? This can be used by administrators to place jobs in queuesthat are different than the one specified by the user.The default is false.</description></property><property><name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name><value>1</value><description>Controls the number of OFF_SWITCH assignments allowedduring a node's heartbeat. Increasing this value can improvescheduling rate for OFF_SWITCH containers. Lower values reduce"clumping" of applications on particular nodes. The default is 1.Legal values are 1-MAX_INT. This config is refreshable.</description></property><property><name>yarn.scheduler.capacity.application.fail-fast</name><value>false</value><description>Whether RM should fail during recovery if previous applications'queue is no longer valid.</description></property><property><name>yarn.scheduler.capacity.workflow-priority-mappings</name><value></value><description>A list of mappings that will be used to override application priority.The syntax for this list is[workflowId]:[full_queue_name]:[priority][,next mapping]*where an application submitted (or mapped to) queue "full_queue_name"and workflowId "workflowId" (as specified in application submissioncontext) will be given priority "priority".</description></property><property><name>yarn.scheduler.capacity.workflow-priority-mappings-override.enable</name><value>false</value><description>If a priority mapping is present, will it override the value specifiedby the user? This can be used by administrators to give applications apriority that is different than the one specified by the user.The default is false.</description></property></configuration>若我们在提交任务时不指定队列,默认会被提交到 default 队列里,另外我们也可以指定我们将队列提交到哪里:
# 默认:
hadoop jar /export/server/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 10 10# 指定队列:
hadoop jar /export/server/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount -Dmapreduce.job.queuename=small /input /output3
另外,如果我们希望修改默认提交到的队列,需要在 mapred-site.xml 文件中添加如下配置:
<property><name>mapreduce.job.queuename</name><value>small</value>
</property>
相关文章:
【大数据】五、yarn基础
Yarn Yarn 是用来做分布式系统中的资源协调技术 MapReduce 1.x 对于 MapReduce 1.x 的版本上: 由 Client 发起计算请求,Job Tracker 接收请求之后分发给各个TaskTrack进行执行 在这个阶段,资源的管理与请求的计算是集成在 mapreduce 上的…...
语义分割实战项目(从原理到代码环境配置)
语义分割(Semantic Segmentation) 先看结果: 是计算机视觉和深度学习领域的一项核心任务,它主要致力于对图像中的每一个像素进行分类,赋予每个像素一个类别标签,以达到理解图像内容的目的。换句话说&#…...
基于python+vue 的一加剧场管理系统的设计与实现flask-django-nodejs-php
二十一世纪我们的社会进入了信息时代,信息管理系统的建立,大大提高了人们信息化水平。传统的管理方式对时间、地点的限制太多,而在线管理系统刚好能满足这些需求,在线管理系统突破了传统管理方式的局限性。于是本文针对这一需求设…...

【Entity Framework】 EF中DbContext类详解
【Entity Framework】 EF中DbContext类详解 一、概述 DbContext类是实体框架的重要组成部分。它是应用域或实例类与数据库交互的桥梁。 从上图可以看出DbContext是负责与数据交互作为对象的主要类。DbContext负责以下活动: EntitySet:DbContext包含…...

智能风扇的新篇章:唯创知音WTK6900G语音识别芯片引领行业革新
随着科技浪潮的推进,智能化技术逐渐渗透到生活的每一个角落,家电领域尤为明显。风扇,这一夏日清凉神器,也通过智能化改造,焕发出前所未有的光彩。其中,智能语音控制功能的加入,为风扇的使用带来…...

[json.exception.type_error.316] invalid UTF-8 byte报错
[json.exception.type_error.316] invalid UTF-8 byte at index 1: 解决方法重新编译程序即可。...

深度强化学习(九)(改进策略梯度)
深度强化学习(九)(改进策略梯度) 一.带基线的策略梯度方法 Theorem: 设 b b b 是任意的函数, b b b与 A A A无关。把 b b b 作为动作价值函数 Q π ( S , A ) Q_\pi(S, A) Qπ(S,A) 的基线, 对策略梯度没有影响: ∇ θ J …...

Oracle修改Number类型精度报错:ORA-01440
修改Number类型的字段的精度SQL ALTER TABLE XXXX MODIFY RATE NUMBER(30,6); 如果表已经存在数据,报错信息如下: ORA-01440: column to be modified must be empty to decrease precision or scale 废话不多说,解决方案如下:…...

美团到店-后端开发一面
1. 介绍一下spring的两大核心思想 2. 介绍一下java的代理,以及动态代理和静态代理的区别 3. spring动态代理是如何生成的,jdk动态代理和cglib的区别 4. 介绍一下synchronized关键字、以及synchronized锁和lock的区别 5. 讲一下java中synchronized的锁升级…...

面试算法-77-括号生成
题目 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”] 解 class Solution {publ…...

webpack5零基础入门-12搭建开发服务器
1.目的 每次写完代码都需要手动输入指令才能编译代码,太麻烦了,我们希望一切自动化 2.安装相关包 npm install --save-dev webpack-dev-server 3.添加配置 在webpack.config.js中添加devServer相关配置 /**开发服务器 */devServer: {host: localhos…...

opengl日记10-opengl使用多个纹理示例
文章目录 环境代码CMakeLists.txt文件内容不变。fragmentShaderSource.fsvertexShaderSource.vsmain.cpp 总结 环境 系统:ubuntu20.04opengl版本:4.6glfw版本:3.3glad版本:4.6cmake版本:3.16.3gcc版本:10.…...
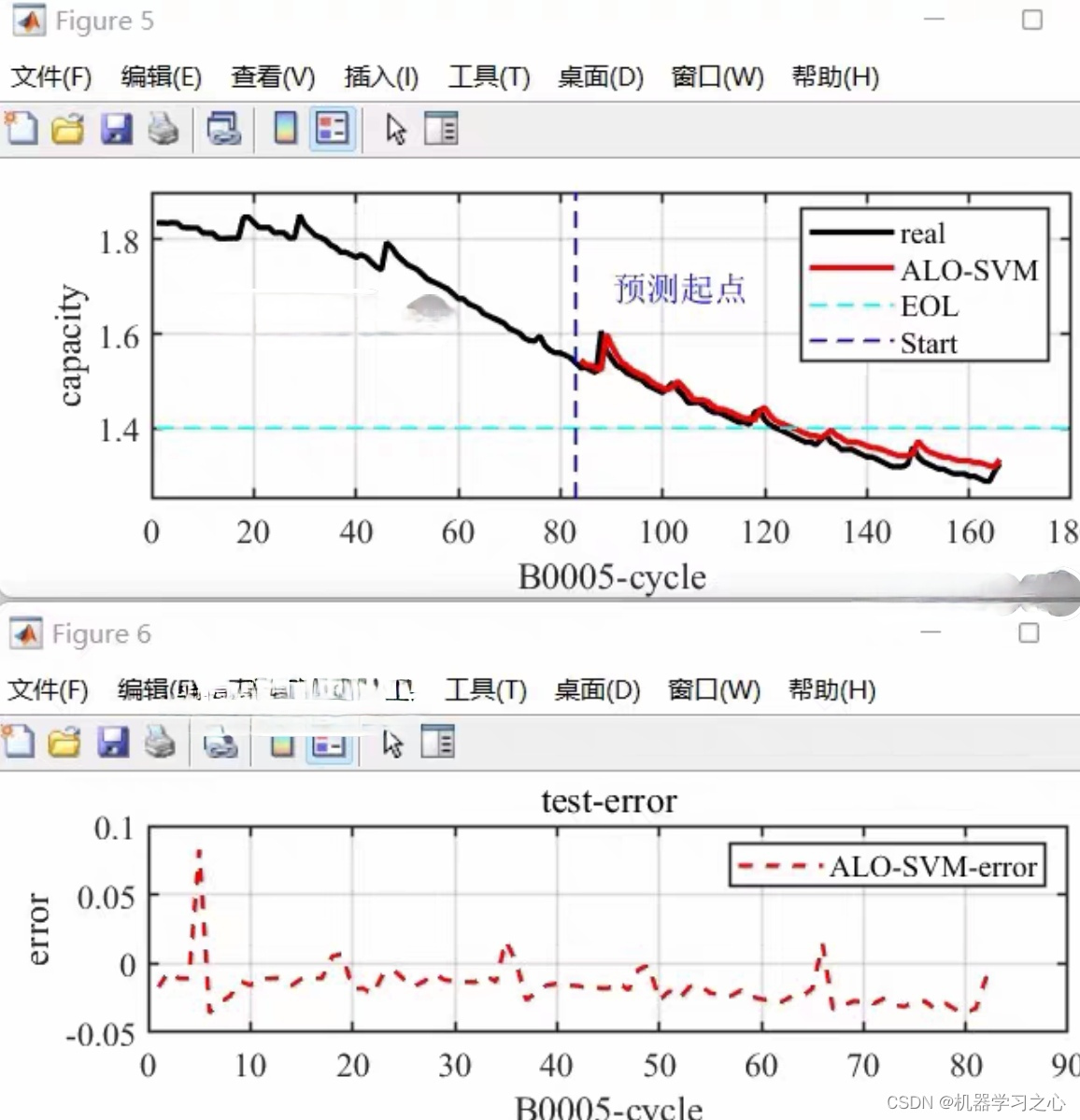
锂电池寿命预测 | Matlab基于ALO-SVR蚁狮优化支持向量回归的锂离子电池剩余寿命预测
目录 预测效果基本介绍程序设计参考资料 预测效果 基本介绍 锂电池寿命预测 | Matlab基于ALO-SVR蚁狮优化支持向量回归的锂离子电池剩余寿命预测 基于蚁狮优化和支持向量回归的锂离子电池剩余寿命预测: 1、提取NASA数据集的电池容量,以历史容量作为输入,…...

动态规划15 | ● 392.判断子序列 ● *115.不同的子序列
392.判断子序列 https://programmercarl.com/0392.%E5%88%A4%E6%96%AD%E5%AD%90%E5%BA%8F%E5%88%97.html 考点 子序列问题 我的思路 dp[i][j]的含义是,两个序列分别取到下标为i和j的时候,他们是否满足前者是后者的子序列,满足为True&#x…...

APP UI自动化测试思路总结
首先想要说明一下,APP自动化测试可能很多公司不用,但也是大部分自动化测试工程师、高级测试工程师岗位招聘信息上要求的,所以为了更好的待遇,我们还是需要花时间去掌握的,毕竟谁也不会跟钱过不去。 接下来,…...
)
Codeforces Round 936 (Div. 2)
C. Tree Cutting 题意:给定一棵树,需要删除 k 条边,使得 k1 个联通块中的最小结点数最大。求出这个最大值 思路:求最小值最大--想到二分答案--然后深搜满足条件的连通块是否大于k即可 #include<iostream> #include<al…...
yolov6实现遥感影像目标识别|以DIOR数据集为例
1 目标检测是计算机视觉领域中的一项重要任务,它的目标是在图像或视频中检测出物体的位置和类别。YOLO(You Only Look Once)是一系列经典的目标检测算法,最初由Joseph Redmon等人于2016年提出。YOLO算法具有快速、简单、端到端的特…...

stable-diffusion-electron-clickstart 支持windows AMD显卡
前言 使用vue3 vite electron element-plus构建,正好学习下electrongithub stable-diffusion “画境导航者” 启动器 简介 stable-diffusion “画境导航者” 启动器支持功能 一键启动打开文件夹(tmp、txt2img-images)等模型所在文件夹&…...

ES进程除了kill之外,有什么优雅关闭的方式吗?
问题 Linux环境中,Elasticsearch 8的进程除了kill之外,有什么优雅关闭的方式吗? 具体实施方式 在Linux环境中,Elasticsearch(ES)进程可以通过多种方式实现优雅关闭,这种方式允许它完成必要的…...
院子摄像头的监控
院子摄像头的监控和禁止区域入侵检测相比,多了2个功能:1)如果检测到有人入侵,则把截图保存起来,2)如果检测到有人入侵,则向数据库插入一条事件数据。 打开checkingfence.py,添加如下…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...