机器学习——GBDT算法
机器学习——GBDT算法
在机器学习领域,梯度提升决策树(Gradient Boosting Decision Trees,简称GBDT)是一种十分强大且常用的集成学习算法。它通过迭代地训练决策树来不断提升模型性能,是一种基于弱学习器的提升算法。本文将详细介绍梯度提升树算法的原理,并与随机森林进行对比,最后给出Python实现的示例代码和总结。
1. 提升树模型
提升树模型是一种基于决策树的集成学习方法,它通过组合多棵决策树来构建一个更强大的模型。提升树模型的基本思想是,将一系列弱学习器(通常是决策树)线性叠加,每一棵树都在尝试修正前一棵树的残差,从而逐步提升整体模型的性能。
2. 梯度提升树
梯度提升树是提升树的一种形式,它通过梯度下降的方法来最小化损失函数。具体来说,梯度提升树使用梯度下降算法来最小化损失函数的负梯度,以此来更新当前模型,使得模型在每一轮迭代中更接近于真实标签。
3. 算法流程
梯度提升树的算法流程如下:
- 初始化模型为一个常数值,通常是训练集标签的均值。
- 对于每一轮迭代:
- 计算当前模型的负梯度,作为残差的近似值。
- 使用负梯度拟合一个回归树模型。
- 将新拟合的树模型与当前模型进行线性组合,更新模型。
- 重复上述步骤直到满足停止条件(如达到最大迭代次数)。
4. 理论公式
梯度提升树的更新公式如下所示:
对于第 i i i轮迭代,模型 F i ( x ) F_i(x) Fi(x),损失函数 L ( y , F i ( x ) ) L(y, F_i(x)) L(y,Fi(x)),学习率 η \eta η,则模型 F i + 1 ( x ) F_{i+1}(x) Fi+1(x)的更新公式为:
F i + 1 ( x ) = F i ( x ) + η h i ( x ) F_{i+1}(x) = F_i(x) + \eta h_i(x) Fi+1(x)=Fi(x)+ηhi(x)
其中, h i ( x ) h_i(x) hi(x)是第 i i i棵树的预测结果。
5. 随机森林与GBDT的区别与联系
随机森林和梯度提升树都是基于决策树的集成学习方法,它们有一些相似之处,也有一些显著的区别。
-
相似之处:
- 都是通过组合多个决策树来构建强大的模型。
- 都可以用于分类和回归问题。
-
区别:
- 随机森林是一种自助聚合技术,它通过随机抽样生成多个不同的训练集,并在每个训练集上训练一个决策树,最后通过投票或平均来获得最终结果。而梯度提升树是一种串行技术,它通过迭代地训练决策树,每个决策树都在尝试修正前一棵树的残差。
- 随机森林中的每棵树是相互独立的,而梯度提升树中的每棵树是依次构建的,每一棵树都在尝试修正前一棵树的错误。
- 随机森林中每棵树的预测结果是通过投票或平均来决定的,而梯度提升树中每棵树的预测结果是通过加权求和来决定的。
6. Python实现算法
以下是Python实现梯度提升树算法的示例代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from matplotlib.colors import ListedColormap# 加载数据集
iris = load_iris()
X, y = iris.data[:, :2], iris.target # 取前两个特征# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建梯度提升树模型
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
clf.fit(X_train, y_train)# 在测试集上进行预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Gradient Boosting Accuracy:", accuracy)# 绘制分类结果
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):markers = ('s', 'x', 'o', '^', 'v')colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')cmap = ListedColormap(colors[:len(np.unique(y))])x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),np.arange(x2_min, x2_max, resolution))Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)Z = Z.reshape(xx1.shape)plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)plt.xlim(xx1.min(), xx1.max())plt.ylim(xx2.min(), xx2.max())for idx, cl in enumerate(np.unique(y)):plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],alpha=0.8, c=[cmap(idx)],marker=markers[idx], label=cl)# 可视化分类结果
plt.figure(figsize=(10, 6))
plot_decision_regions(X_test, y_test, classifier=clf)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend(loc='upper left')
plt.title('Gradient Boosting Classification Result on Test Set')
plt.show()

7. 总结
本文介绍了梯度提升树(Gradient Boosting Decision Trees,GBDT)算法的原理、算法流程、理论公式,并与随机森林进行了对比。梯度提升树是一种基于决策树的集成学习方法,通过迭代地训练决策树来不断提升模型性能。相比于随机森林,梯度提升树是一种串行技术,每个决策树都在尝试修正前一棵树的残差,因此在某些情况下可能会更加灵活和有效。通过Python实现了梯度提升树算法,并在鸢尾花数据集上进行了模型训练和评估。
相关文章:
机器学习——GBDT算法
机器学习——GBDT算法 在机器学习领域,梯度提升决策树(Gradient Boosting Decision Trees,简称GBDT)是一种十分强大且常用的集成学习算法。它通过迭代地训练决策树来不断提升模型性能,是一种基于弱学习器的提升算法。…...
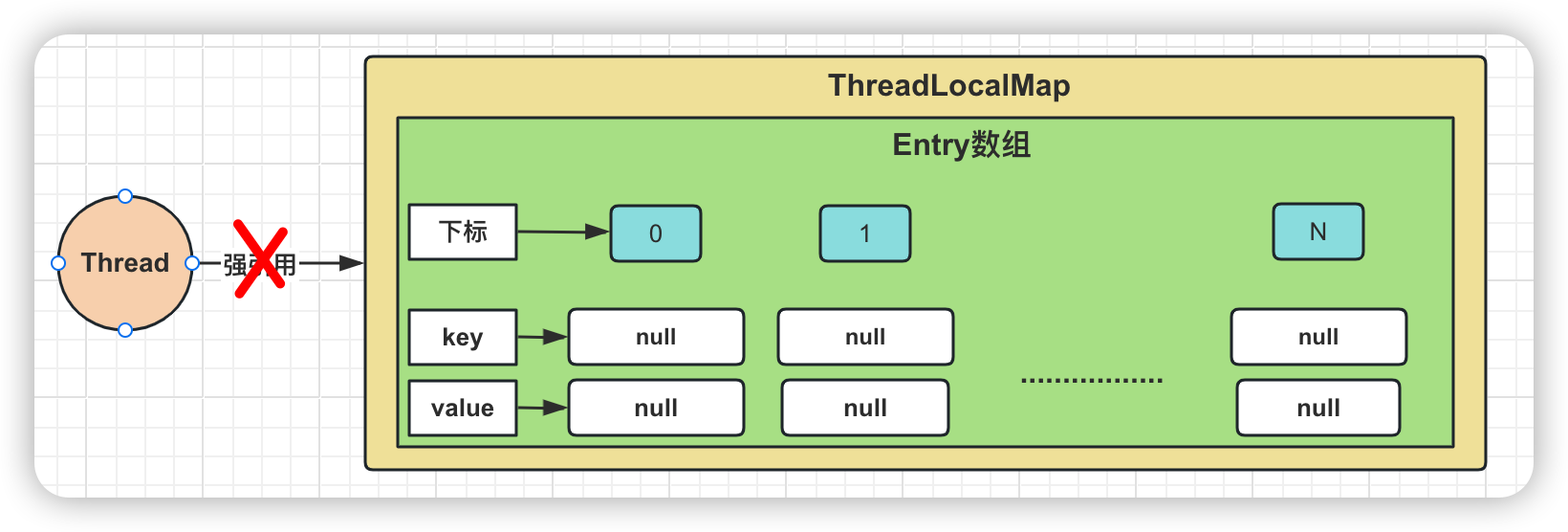
阿里二面:谈谈ThreadLocal的内存泄漏问题?问麻了。。。。
引言 ThreadLocal在Java多线程编程中扮演着重要的角色,它提供了一种线程局部存储机制,允许每个线程拥有独立的变量副本,从而有效地避免了线程间的数据共享冲突。ThreadLocal的主要用途在于,当需要为每个线程维护一个独立的上下文…...

IOS面试题编程机制 46-50
46. 阐述 Method Swizzle(黑魔法),什么情况下会使用?1). 在没有一个类的实现源码的情况下,想改变其中一个方法的实现,除了继承它重写、和借助类别重名方法暴力抢先之外,还有更加灵活的方法 Method Swizzle。 2). Method Swizzle 指的是改变一个已存在的选择器对应的实现…...
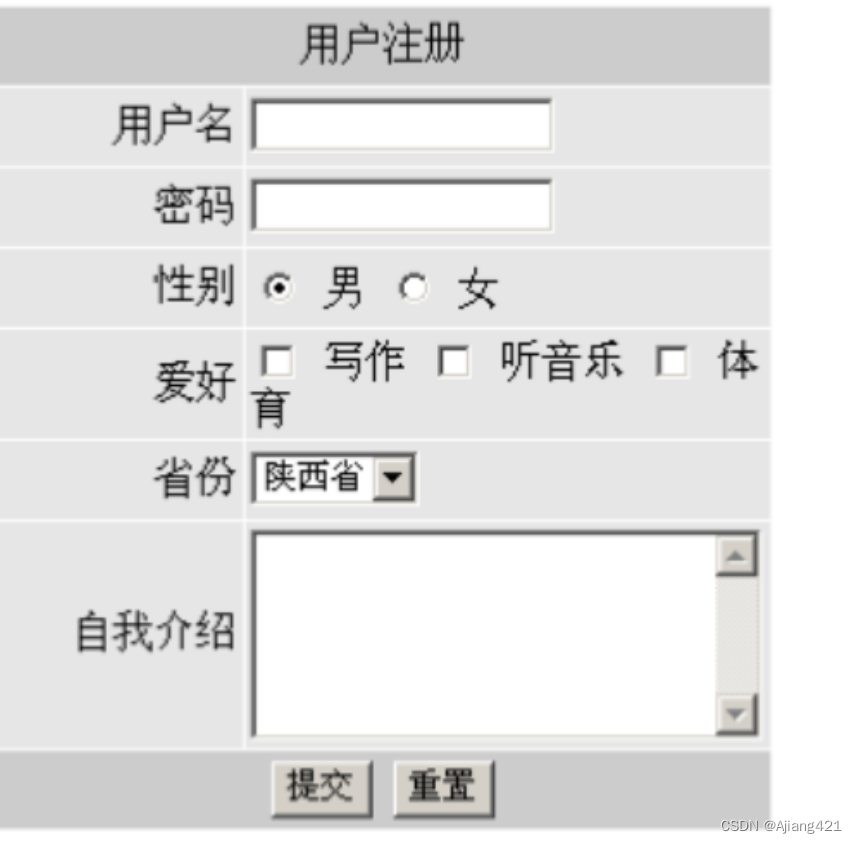
web表单标签与练习(3.18)
一、表单域 表单域是一个包含表单元素的区域。 在HTML标签中,< form >标签用于定义表单域,以实现用户信息和传递。 < form >会把它范围内的表单元素信息提交给服务器。 表单属性 action url地址 用于指定接收并处理表单数据的服务器程序的…...
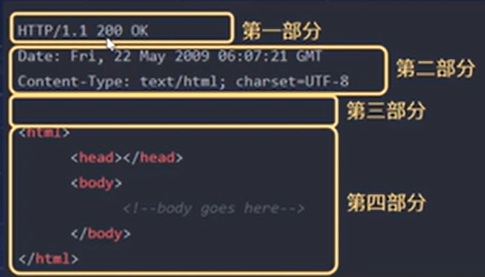
【协议-HTTP】
HTTP协议 HTTP协议(超文本传输协议HyperText Transfer Protocol),它是基于TCP协议的应用层传输协议。http协议定义web客户端如何才能够web服务器请求web页面,以及服务器如何把web页面传送给客户端。 HTTP 是一种无状态 (stateless) 协议, HTTP协议本身…...

VUE3v-text、v-html、:style的理解
在Vue 3中,v-text、v-html和:style是三个常用的指令,它们各自具有不同的功能和用途。 v-text: v-text用于操作元素中的纯文本内容。它接受一个表达式,并将该表达式的值设置为元素的文本内容。如果元素原本有文本内容,…...
的简介、安装、案例应用之详细攻略)
Dataset之UCI_autos_cars:UCI_autos_imports-85(汽车进口数据集)的简介、安装、案例应用之详细攻略
Dataset之UCI_autos_cars:UCI_autos_imports-85(汽车进口数据集)的简介、安装、案例应用之详细攻略 目录 UCI_autos_imports-85的简介 UCI_autos_imports-85的安装 UCI_autos_imports-85的案例应用 1、训练一个简单的线性回归模型来预测汽车的价格 UCI_autos_i…...
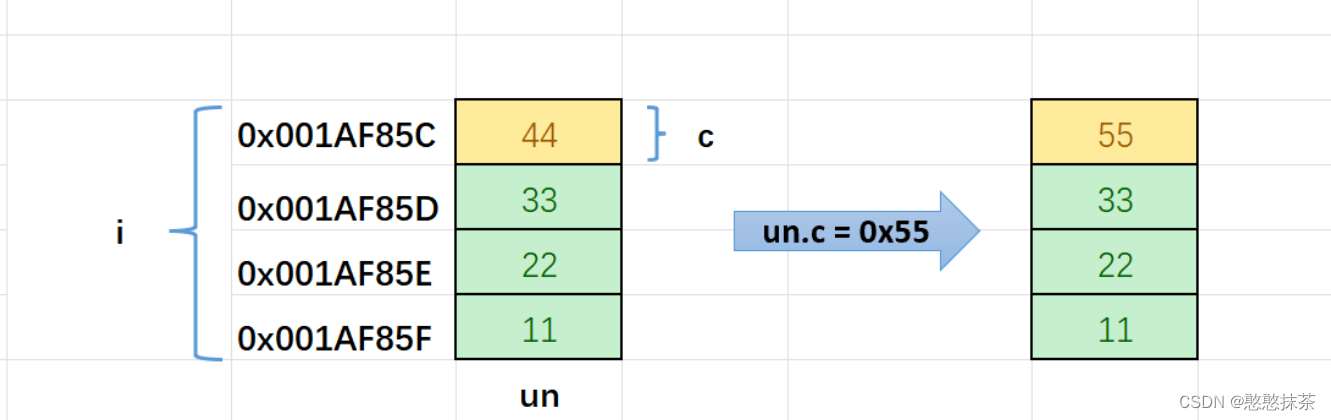
结构体类型详细讲解(附带枚举,联合)
前言: 如果你还对结构体不是很了解,那么本篇文章将会从 为什么存在结构体,结构体的优点,结构体的定义,结构体的使用与结构体的大小依次介绍,同样会附带枚举与联合体 目录 为什么存在结构体: 结构…...

编程生活day1--个位数统计、考试座位号、A-B、计算阶乘和
个位数统计 题目描述: 定一个 k 位整数 Ndk−110k−1⋯d1101d0 (0≤di≤9, i0,⋯,k−1, dk−1>0),请编写程序统计每种不同的个位数字出现的次数。例如:给定 N100311,则有 2 个 0,3 个 1,和 …...
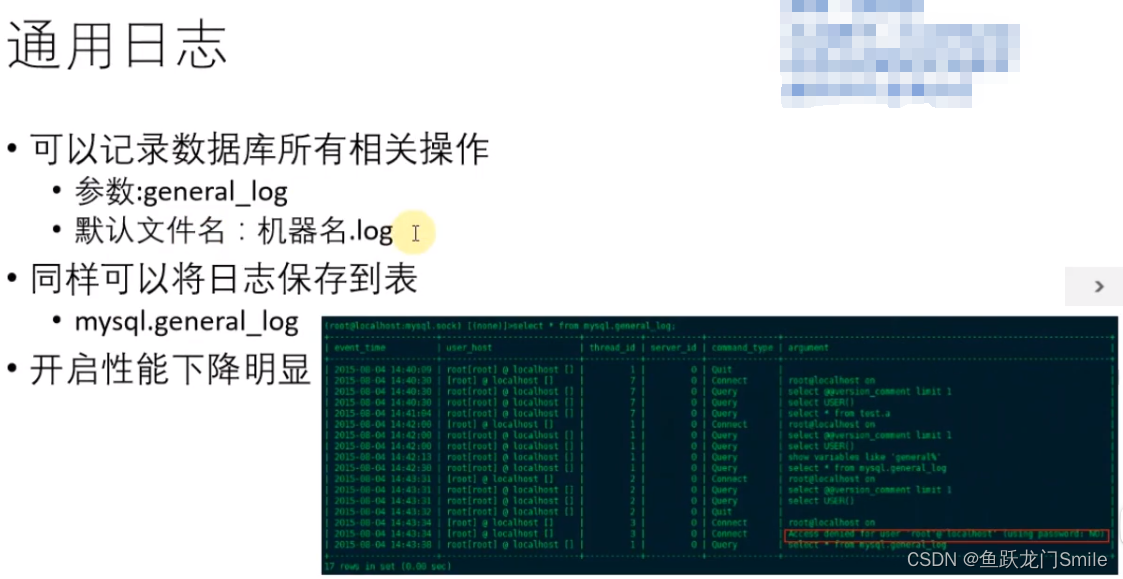
mysql体系结构及主要文件
目录 1.mysql体系结构 2.数据库与数据库实例 3.物理存储结构编辑 4.mysql主要文件 4.1数据库配置文件 4.2错误日志 4.3表结构定义文件 4.4慢查询日志 4.4.1慢查询相关参数 4.4.2慢查询参数默认值 4.4.3my.cnf中设置慢查询参数 4.4.4slow_query_log参数 4.4.…...
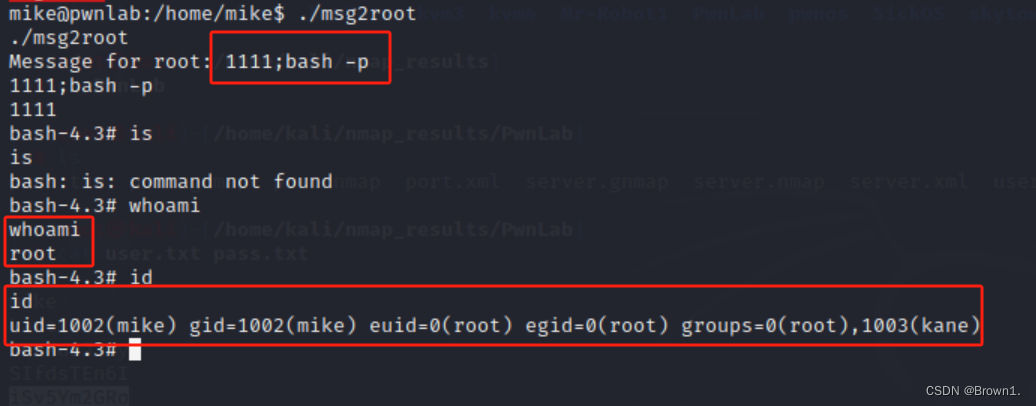
PwnLab靶场PHP伪协议OSCP推荐代码审计命令劫持命令注入
下载链接:PwnLab: init ~ VulnHub 安装: 打开vxbox直接选择导入虚拟电脑即可 正文: 先用nmap扫描靶机ip nmap -sn 192.168.1.1/24 获取到靶机ip后,对靶机的端口进行扫描,并把结果输出到PwnLab文件夹下,命名…...

涉密信息系统集成资质八大类别办理条件是什么?
涉密资质分为八个不同类别,那每个类别的申报条件有哪些?让我们一起来看看吧: 涉密资质申报条件 依据《涉密信息系统集成资质管理办法》的有关规定,申请涉密信息系统集成资质的企事业单位,除符合《涉密信息系统集成资…...
)
Shell脚本总结-反引号-${}-$()
反引号 反引号的作用就是将输出结果显示出来。 [rootldpbzhaonan bash]$ echo $a ldpbzhaonan${} ${}引用变量,包含自定义的和环境变量。 [rootldpbzhaonan bash]$ a1 [rootldpbzhaonan bash]$ echo ${a} 1$() $()和反引号,返回的是一个指令或者程序…...

Spring MVC入门(4)
请求 获取Cookie/Session 获取Cookie 传统方式: RequestMapping("/m11")public String method11(HttpServletRequest request, HttpServletResponse response) {//获取所有Cookie信息Cookie[] cookies request.getCookies();//打印Cookie信息StringBuilder build…...
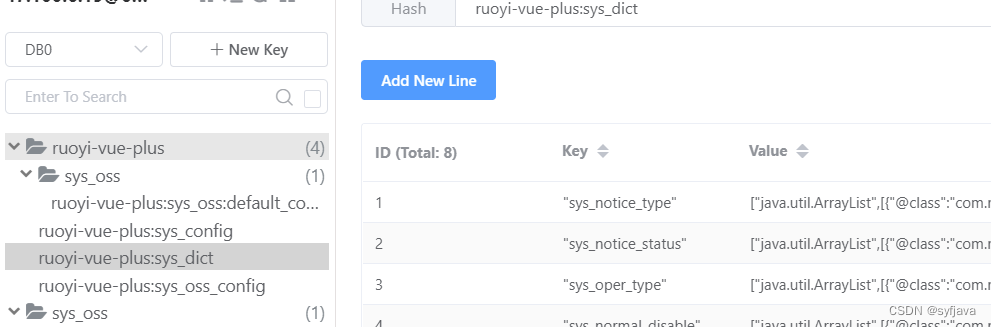
RuoYi-Vue-Plus(基础知识点jackson、mybatisplus、redis)
一、JacksonConfig 全局序列化反序列化配置 1.1yml中配置 #时区 spring.jackson.time-zoneGMT8 #日期格式 spring.jackson.date-formatyyyy-MM-dd HH:mm:ss #默认转json的属性,这里设置为非空才转json spring.jackson.default-property-inclusionnon_null #设置属性…...

使用verillog编写KMP字符串匹配算法
设计思路如下: 定义模块的输入输出信号:包括时钟信号clk、复位信号rst、模式串pattern、文本串text以及输出信号match。定义所需寄存器和变量:使用寄存器来存储状态机的状态以及其他控制变量,如模式串数组P、失配函数数组F、模式串位置p_index、文本串位置t_index等。在时钟…...
)
《每天十分钟》-红宝书第4版-对象、类与面向对象编程(五)
对象迭代 在 JavaScript 有史以来的大部分时间内,迭代对象属性都是一个难题。ECMAScript 2017 新增了两个静态方法,用于将对象内容转换为序列化的——更重要的是可迭代的——格式。这两个静态方法Object.values()和 Object.entries()接收一个对象&#…...
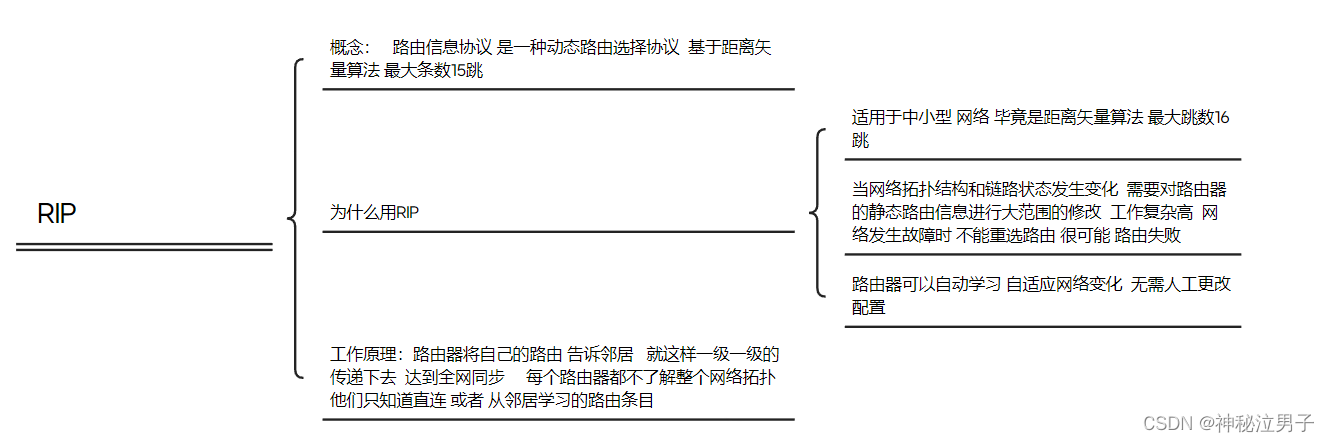
华为ensp中rip动态路由协议原理及配置命令(详解)
CSDN 成就一亿技术人! 作者主页:点击! ENSP专栏:点击! CSDN 成就一亿技术人! ————前言————— RIP(Routing Information Protocol,路由信息协议)是一种距离矢…...

学习要不畏难
我突然发现,畏难心是阻碍我成长的最大敌人。事未难,心先难,心比事都难,是我最大的毛病。然而一念由心生,心不难时,则真难事也不再难。很多那些自认为很难的事,硬着头皮做下来的时候,…...
mysql迁移达梦数据库 Java踩坑合集
达梦数据库踩坑合集 文章目录 安装达梦设置大小写不敏感Spring boot引入达梦驱动(两种方式)将jar包打入本地maven仓库使用国内maven仓库(阿里云镜像) 达梦驱动yml配置springboot mybatis-plus整合达梦,如何避免指定数据库名&…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

为Claude Code配置稳定API源并解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置稳定API源并解决访问限制 Claude Code 作为一款强大的 AI 编程辅助工具,其原生服务在某些情况下可能…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...