python与excel第七节 拆分工作簿
一个工作簿中多个工作表拆分为多个工作簿
假设一个excle工作簿中有多个工作表,现在需要将每个工作表拆分为单独的工作簿。
例子:
import xlwings as xw
# 设置生成文件的路径
path = 'D:\\TEST\\dataIn'
# 源文件的路径
workbook_name = 'D:\\TEST\\dataIn\\产品表.xlsx'
app = xw.App(visible=False, add_book=False)
# 打开源文件
workbook = app.books.open(workbook_name)
# 遍历来源工作簿中的工作表
for i in workbook.sheets:
# 新建一个目标工作簿
workbook_split = app.books.add()
# 选择目标工作簿中的第一个工作表
sheet_split = workbook_split.sheets[0]
# 将来源工作簿中的当前工作表复制到目标工作簿的第一个工作表之前
i.api.Copy(Before=sheet_split.api)
# 输出文件,并命名
workbook_split.save(path + '\\{}.xlsx'.format(i.name))
app.quit()
一个工作表按条件拆分为多个工作表
假设一个工作表中有很多数据,现在需要根据某一列将其分类到不同的sheet里面。
例子:
import xlwings as xw
import pandas as pd
app = xw.App(visible=True,add_book=False)
workbook = app.books.open('D:\\TEST\\dataIn\\产品表.xlsx')
worksheet = workbook.sheets['厨具']
# 读取要拆分的工作表数据
value = worksheet.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').value
# 将数据按照“品牌”拆分,value.groupby()返回的两个参数:组名(str类型),组的内容(DataFrame类型)
data = value.groupby('品牌')
for idx,group in data:
# 以品牌名称为工作簿中新增工作表命名
new_worksheet = workbook.sheets.add(idx)
new_worksheet['A1'].options(index=False).value=group # 数据添加到新增的工作表
workbook.save()
workbook.close()
app.quit()
一个工作表的数据拆分到多个工作簿
假设一个工作表中有很多数据,现在需要根据某一列将其分类到不同的工作簿里面。
例子:
import xlwings as xw
# 读取源表数据到字典中,再根据key分类读取生成工作簿
out_path = 'D:\\TEST\\dataIn\\'
file_path = 'D:\\TEST\\dataIn\\产品表.xlsx'
sheet_name = '厨具'
app = xw.App(visible=True,add_book=False)
workbook = app.books.open(file_path)
worksheet = workbook.sheets[sheet_name]
# 从第二行开始时数据
value = worksheet.range('A2').expand('table').value
data = dict()
for i in range(len(value)):
# 根据第2列进行分类
brand_name = value[i][2]
# 如果字典中没有该名称的产品,就新建一个
if brand_name not in data:
data[brand_name] = []
data[brand_name].append(value[i])
print(data)
for key,value in data.items():
new_workbook = xw.books.add()
# 根据品牌为sheet名创建工作表
new_worksheet = new_workbook.sheets.add(key)
# 先复制列标题到新建工作表中
new_worksheet['A1'].value = worksheet['A1:D1'].value
# 复制数据到新建工作表中
new_worksheet['A2'].value = value
new_workbook.save(out_path + '{}.xlsx'.format(key))
app.quit()
相关文章:

python与excel第七节 拆分工作簿
一个工作簿中多个工作表拆分为多个工作簿 假设一个excle工作簿中有多个工作表,现在需要将每个工作表拆分为单独的工作簿。 例子: import xlwings as xw# 设置生成文件的路径path D:\\TEST\\dataIn# 源文件的路径workbook_name D:\\TEST\\dataIn\\产…...

JS08-DOM节点完整版
DOM节点 查找节点 父节点 <div class="father"><div class="son">儿子</div></div><script>let son = document.querySelector(.son)console.log(son.parentNode);son.parentNode.style.display = none</script>通过…...
【python】python3基础
文章目录 一、安装pycharm 二、输入输出输出 print()文件输出:格式化输出: 输入input注释 三、编码规范四、变量保留字变量 五、数据类型数字类型整数浮点数复数 字符串类型布尔类型序列结构序列属性列表list ,有序多维列表列表推导式 元组tu…...

计算机三级网络技术 选择+大题234笔记
上周停去准备计算机三级的考试啦,在考场上看到题目就知道这次稳了!只有一周的时间,背熟笔记,也能稳稳考过计算机三级网络技术!...

智能合约 之 ERC-721
ERC-721(Non-Fungible Token,NFT)标准 ERC-721是以太坊区块链上的一种代币标准,它定义了一种非同质化代币(Non-Fungible Token,NFT)的标准。NFT是一种加密数字资产,每个代币都具有独…...

== 和 equals 的区别是什么?
和 equals() 在 Java 中都是用于比较两个对象,但它们之间存在显著的差异: 比较的内容: :这是 Java 中的基本比较运算符,对于基本数据类型(如 int, char, double 等),它比较的是值&a…...

VUE:内置组件<Teleport>妙用
一、<Teleport>简介 <Teleport>能将其插槽内容渲染到 DOM 中的另一个位置。也就是移动这个dom。 我们可以这么使用它: 将class为boxB的盒子移动到class为boxA的容器中。 <Teleport to".boxA"><div class"boxB"></div> &…...

ruoyi-nbcio-plus后端里mapstruct-plus和lombok的使用
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 http://122.227.135.243:9666/ 更多nbcio-boot功能请看演示系统 gitee源代码地址 后端代码:…...

企业如何选择一个开源「好」项目?
开源 三句半 需求明确是关键 风险考量要周全 开源虽好不白捡 别忘合规! 显然,开源已成为一股不可阻挡的洪流,企业拥抱开源,积极参与开源项目不仅是响应技术潮流的必然选择,更是实现自身技术创新、市场拓…...
 并查集)
c++算法学习笔记 (14) 并查集
1.合并集合 一共有 n 个数,编号是 1∼n,最开始每个数各自在一个集合中。 现在要进行 m 个操作,操作共有两种: M a b,将编号为 a 和 b 的两个数所在的集合合并,如果两个数已经在同一个集合中,…...

import * as的使用
import * as 是将一个模块的所有导出内容作为一个命名空间对象导入到当前模块中,其中 * 表示导入该模块中的所有导出内容,而 as 则用于指定导入的命名空间对象的名称。 例如:在 formatter 文件中有两个方法导出 const a () > {console.…...

微服务(基础篇-003-Nacos)
目录 Nacos注册中心(1) 认识和安装Nacos(1.1) Nacos快速入门(1.2) 服务注册到Nacos(1.2.1) Nacos服务分级存储模型(1.3) 配置集群(1.3.1) 根据集群修改…...
java数据结构与算法刷题-----LeetCode215. 数组中的第K个最大元素
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 文章目录 解题思路:时间复杂度O( n n n),空间复杂度…...

Springboot 整合 Knife4j (API文档生成工具)
目录 一、Knife4j 介绍 二、Springboot 整合 Knife4j 1、pom.xml中引入依赖包 2、在application.yml 中添加 Knife4j 相关配置 3、打开 Knife4j UI界面 三、关于Knife4j框架中常用的注解 1、Api 2、ApiOperation 3、ApiOperationSupport(order X) 4、ApiImplici…...
C语言---------strlen的使用和模拟实现
字符串是以‘\0’作为结束标志,strlen函数的返回值是‘\0’前面的字符串的个数(不包括‘\0’) 注意 1,参数指向的字符串必须以‘\0’结束 2,函数的返回值必须以size_t,是无符号的 使用代码 #include<stdio.…...
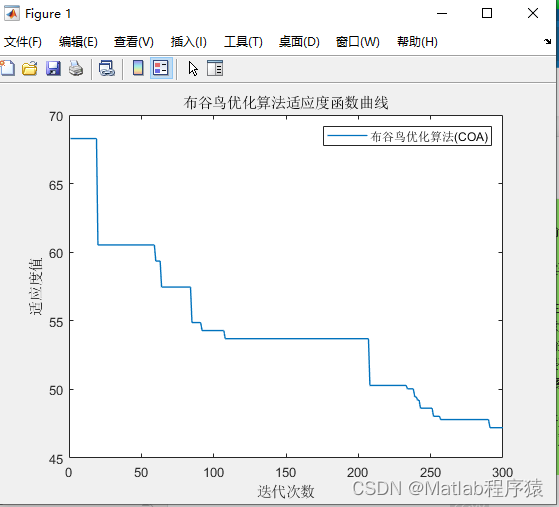
【MATLAB源码-第168期】基于matlab的布谷鸟优化算法(COA)机器人栅格路径规划,输出做短路径图和适应度曲线。
操作环境: MATLAB 2022a 1、算法描述 布谷鸟优化算法(Cuckoo Optimization Algorithm, COA)是一种启发式搜索算法,其设计灵感源自于布谷鸟的独特生活习性,尤其是它们的寄生繁殖行为。该算法通过模拟布谷鸟在自然界中…...
集合深入------理解底层。
集合的使用 前提:栈、堆、二叉树、hashcode、toString()、quesalus()的知识深入和底层理解。 1、什么是集合 集合就是咋们所说的容器 前面我们学习过数组 数组也是容器 容器:装东西的 生活中有多少的容器呀? 水杯 教室 酒瓶 水库 只要是…...

【阅读笔记】《硬笔书法艺术》
硬笔书法基础教程,也介绍了一些实用案例 作者: 万应均 出版社: 湖南人民出版社 笔记 CH1 运笔方式 起笔:起笔、切笔、顺峰、搭峰。 行笔:提笔、按笔、滑笔、转笔、折笔。 收笔:提收、顿收、折收。 CH2 钢笔楷书 “古人善书者…...

5.5.5、【AI技术新纪元:Spring AI解码】使用PGvector设置向量存储及进行相似性搜索
使用PGvector设置向量存储及进行相似性搜索 本节指导您如何设置PGvector VectorStore来存储文档嵌入并执行相似性搜索。 PGvector是一个开源的PostgreSQL扩展,能够支持存储和搜索机器学习生成的嵌入向量,提供查找精确和近似最近邻的功能。它设计得与PostgreSQL的其他特性无…...

EDR下的线程安全
文章目录 前记进程断链回调执行纤程内存属性修改early birdMapping后记reference 前记 触发EDR远程线程扫描关键api:createprocess、createremotethread、void(指针)、createthread 为了更加的opsec,尽量采取别的方式执行恶意代…...

浏览器端音频解密技术:如何让加密音乐在本地重获新生?
浏览器端音频解密技术:如何让加密音乐在本地重获新生? 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目…...

Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑
Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾经因为复杂的视频编辑软件而头疼?想要一个免费、开源且…...

摆脱论文困扰!2026年最值得拥有的专业AI智能降重工具
2026年论文降AI率工具已从“基础改写”升级为多维度智能优化系统,核心评价维度涵盖AI生成内容识别精度、语义逻辑一致性、学术格式合规性、查重适配能力及多语言处理水平。本次测评覆盖6款主流工具,测试场景包括中文与英文论文、全流程与专项功能、免费与…...

HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元
HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器的缓慢加载和频繁卡顿而烦恼吗?你…...

Taotoken的APIKey管理与访问控制功能保障了企业级安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的APIKey管理与访问控制功能保障了企业级安全 当团队开始规模化使用大语言模型时,一个核心挑战随之而来&#…...

混合物理-ML辐射方案:攻克气候模型中次网格云效应的新范式
1. 项目概述与核心挑战在气候模拟这个庞大的数字沙盘中,地球系统模型(ESM)是我们理解未来气候演变的核心工具。然而,这个沙盘有一个长期存在的“颗粒度”难题:受限于计算资源,模型的水平分辨率通常在100到2…...

BetterJoy终极配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy终极配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

用Playwright自动化测试工具,5分钟搞定网站短信验证码接口的批量测试
用Playwright实现短信验证码接口的自动化测试实战指南短信验证码作为现代Web应用的核心安全组件,其稳定性和防护能力直接影响用户体验和系统安全。根据2023年DevOps状态报告,超过60%的线上身份验证故障源于短信服务接口的异常。本文将带你用Playwright这…...

基于堆叠集成学习的脑膜炎早期预警模型:从EHR数据挖掘到临床决策支持
1. 项目概述与核心价值在急诊室(ER)和重症监护室(ICU)里,时间就是生命,而脑膜炎的诊断恰恰是和时间赛跑。这种包裹着大脑和脊髓的脑膜炎症,起病急、进展快,一旦延误,神经…...

Unity背包拖拽实战:三坐标系映射与跨Panel交互原理
1. 这不是“拖一拖就完事”的UI小功能,而是Unity UI系统能力的实战压力测试 在Unity项目里,“背包装备拖拽”这六个字,新手常以为只是给Image加个DragHandler接口、写几行OnBeginDrag/OnDrag/OnEndDrag回调——结果上线前一周,策划…...