【网络爬虫】(1) 网络请求,urllib库介绍
各位同学好,今天开始和各位分享一下python网络爬虫技巧,从基本的函数开始,到项目实战。那我们开始吧。
1. 基本概念
这里简单介绍一下后续学习中需要掌握的概念。
(1)http 和 https 协议。http是超文本传输,接收HTML页面的方法,服务器80端口。https是http协议的加密版本,服务端口是443端口。
(2)URL 统一资源定位符。形如:scheme://host:port/path/?query-string=xxx#anchor
以 https://www.bilibili.com/video/BV1eT4y1Z7NB?p=3 为例
scheme:访问协议,一般为 http 或 https。
host:主机名,域名。上面的 www.bilibili.com
path:查找路径。video/BV1eT4y1Z7NB 就是 path
port:端口号,访问网站时浏览器默认 80 端口
query-string:查询字符串。如上面的 ?p=3,如有多个,用&分隔
anchor:锚点。后台不用管,是前端用来做页面定位的。相当于现在停留的位置是网页的第几个小节。
注:在浏览器中请求一个url,浏览器会对url进行编码。除英文字母,数字和部分符号外,其他全部使用百分号和十六进制码值进行编码。中文字词需要重新编码后再发送给服务器
(3)常用的请求方法
GET 请求。只从服务器获取数据下来(下载文件),并不会对服务器资源产生任何影响的时候使用GET请求。
POST 请求。向服务器发送数据(登录),上传文件等,会对服务器资源产生影响时使用POST请求
2. urllib 库
urllib 库是 python3 中自带的网络请求库,可以模拟浏览器的行为,向服务器发送一个请求,并可以保存服务器返回的数据。
2.1 urlopen 函数
用于打开一个远程的 url 连接,并且向这个连接发出请求,获取响应结果。返回的结果是一个 https 响应对象,这个响应对象中记录了本次 https 访问的响应头和响应体。
使用方法为:
urllib.request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False,context=None)参数:
url: 需要打开的网址
data:字节流编码格式,可以用 urllib.parse.urlencode() 和 bytes() 方法转换参数格式,如果要设置了data参数,则请求方式为POST
timeout: 设置网站的访问超时时间,单位:秒。若不指定,则使用全局默认时间。若请求超时,则会抛出urllib.error.URLError异常。
返回值:
http.client.HTTPResponse对象: 返回类文件句柄对象,有read(size),readline,readlines,getcode方法。read(size)若不指定size,则全部读出来。readline读取第一行。readlines返回值以多行的形式读出来。
getcode(): 获取响应状态。返回200,表示请求成功,返回404,表示网址未找到。
geturl(): 返回请求的url。
from urllib import request# 打开网站,返回响应对象resp
resp = request.urlopen('https://www.baidu.com')# 通过.read()读取这个网页的源代码,相当于在百度页面右键检查
print(resp.read())
# 返回网页信息print(resp.getcode()) #状态码
# 200resp.read() 返回类似如下信息,这里只显示部分
b'<html>\r\n<head>\r\n\t<script>\r\n\t\tlocation.replace(location.href.replace("https://","http://"));
\r\n\t</script>\r\n</head>\r\n<body>\r\n\t<noscript><meta http-equiv="refresh" content="0;
url=http://www.baidu.com/"></noscript>\r\n</body>\r\n</html>'2.2 urlretrieve 函数
直接将远程数据下载到本地,方法如下:
rlretrieve(url, filename=None, reporthook=None, data=None)参数:
url:下载链接地址
filename:指定了保存本地路径,若参数未指定,urllib 会生成一个临时文件保存数据。
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
data:指 POST 导服务器的数据,该方法返回一个包含两个元素的( filename,headers ) 元组,filename 表示保存到本地的路径,header 表示服务器的响应头
# 将百度的首页下载到本地
from urllib import request# 下载某一张图片,传入图像的url和保存路径
request.urlretrieve('https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fnimg.ws.126.net%2F%3Furl%3Dhttp%253A%252F%252Fdingyue.ws.126.net%252F2021%252F1010%252F90f82dafj00r0q72d001jc000hs009uc.jpg%26thumbnail%3D650x2147483647%26quality%3D80%26type%3Djpg&refer=http%3A%2F%2Fnimg.ws.126.net&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1642840179&t=888aee0d4f561d7238b290c9da876362', 'C:/Users/admin/Documents/Downloads/test1.jpg')# 下载成功后返回:
('C:/Users/admin/Documents/Downloads/test1.jpg',<http.client.HTTPMessage at 0x26b86c85a60>)2.3 urlencode 函数
用浏览器发送请求时,如果 url 中包含了中文或其他特殊字符,那么浏览器会自动进行编码。
如果使用代码发送请求,必须手动进行编码,这时需要 urlencode 函数实现。urlencode 把字典数据转换为url编码的数据
方法如下:
urllib.parse.urlencode( 字典 )下面,对张三使用%和十六进制重新编码,键和键之间使用&号连接,空格使用+号连接
from urllib import parse
# 自定义一个字典,后续用于重新编码
params = {'name':'张三','age':18, 'greet':'hello world'}
# 对字典编码
result = parse.urlencode(params)
print(result)
# 除英文和数字外都使用 %号和十六进制来编码# 打印结果
name=%E5%BC%A0%E4%B8%89&age=18&greet=hello+world实际使用:
如果网址中有中文,需要先将中文从中分割出来,以字典的方式重新编码转换后,再拼接到网址中。
from urllib import parse# url = 'https://www.baidu.com/s?wd=周杰伦' # 直接用于网络请求时,ascii码不能识别# 使用方法
url = 'https://www.baidu.com/s'# 定义一个字典
params = {'wd':'周杰伦'}
# 对中文编码
qs = parse.urlencode(params)
print(qs) #打印编码结果# 拼接到网址url后面
url = url + '?' + qs
print(url)# 网络请求,得到网页中的数据
resp = request.urlopen(url)
print(resp.read())打印结果分别为
wd=%E5%91%A8%E6%9D%B0%E4%BC%A6https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6b'<html>\r\n<head>\r\n\t<script>\r\n\t\tlocation.replace(location.href.replace("https://","http://"));
\r\n\t</script>\r\n</head>\r\n<body>\r\n\t<noscript><meta http-equiv="refresh" content="0;
url=http://www.baidu.com/"></noscript>\r\n</body>\r\n</html>'2.4 parse_qs 函数
将经过编码后的 url 参数解码,返回字典类型,方法如下:
urllib.parse.urlencode( url )应用:
from urllib import parse# 先对中文进行编码
params = {'name:':'张三','age':18,'greet':'hello world'}
qs = parse.urlencode(params)
print('编码后:',qs)# 对编码后的结果解码
result = parse.parse_qs(qs)
print('解码后:', result)打印结果如下:
编码后: name%3A=%E5%BC%A0%E4%B8%89&age=18&greet=hello+world解码后: {'name:': ['张三'], 'age': ['18'], 'greet': ['hello world']}2.4 urlparse 和 urlsplit 函数
分割 url 中的各个组成部分,分割成 scheme,host,path,params,query-string,anchor,具体含义看最上面。
这两个函数的区别是:urlsplit 不返回 params,但是这个参数params基本用不到。
(1)urlparse 方法
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)urlstring: 待解析的URL,必填项
scheme: 默认的协议,如 http 或 https 等。
allow_fragments: 即是否忽略fragment。若设为 False,fragment 部分就会被忽略,它会被解析为 path、parameters 或 query 的一部分,而 fragment 部分为空。
返回值为所有分割后的结果
# 使用 urlparse 方法from urllib import parse# 给出一个url网址
url = 'https://blog.csdn.net/dgvv4?spm=1001.5501#1'# 使用 urlparse 解析分割 url 中的组成部分
result = parse.urlparse(url)print(result) # 获取所有属性print('scheme:', result.scheme) # 获取指定属性返回值如下:
ParseResult(scheme='https', netloc='blog.csdn.net', path='/dgvv4', params='', query='spm=1001.5501', fragment='1')scheme: https(2)urlsplit 方法
# 使用 urlsplit 方法from urllib import parse# 给出一个url网址
url = 'https://blog.csdn.net/dgvv4?spm=1001.5501#1'# 使用 urlparse 解析分割 url 中的组成部分
result = parse.urlsplit(url)print(result)print('scheme:', result.scheme)
返回值如下,返回结果没有params参数
SplitResult(scheme='https', netloc='blog.csdn.net', path='/dgvv4', query='spm=1001.5501', fragment='1')scheme: https2.5 Request 函数
如果在请求时增加一些请求头,防止网页发现是爬虫,避免爬虫失败。那么就必须使用resquest.Resquest() 类来实现。比如要增加一个User-Agent。
from urllib import request, parse# 输入请求
url = 'http://www.acga......com/'# 输入浏览器页面的User-Agent请求头,使请求头更加像这个浏览器
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62','Refer':'http://www.acganime.com/'}# data需要经过urlencode重新编码后才能传进去
data = {'first' : True,'pn' : 1, #第几页'kd' : 'cos' }
# 重新编码
data = parse.urlencode(data)
# 编码类型转换成utf-8
data = data.encode('utf-8')# 使用request.Request,添加请求头,只是定义好了一个类,并没有发送请求
req = request.Request(url, headers=headers, data=data, method='POST') #请求方式为get # 使用 urlopen 方法获取网页信息
resp = request.urlopen(req) #传入添加请求头后的类
print(resp.read().decode('utf-8')) # 转换成utf-8显示结果返回爬取的网页数据:
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta name="renderer" content="webkit">
<!-- <meta name="referrer" content="no-referrer" /> --><meta name="viewport" content="initial-scale=1.0,maximum-scale=5,width=device-width,viewport-fit=cover">
.........................................................推广,发起网络请求的计算机的IP地址,可从如下活动获得:

相关文章:
【网络爬虫】(1) 网络请求,urllib库介绍
各位同学好,今天开始和各位分享一下python网络爬虫技巧,从基本的函数开始,到项目实战。那我们开始吧。 1. 基本概念 这里简单介绍一下后续学习中需要掌握的概念。 (1)http 和 https 协议。http是超文本传输…...
yolov9目标检测可视化图形界面GUI源码
该系统是由微智启软件工作室基于yolov9pyside6开发的目标检测可视化界面系统 运行环境: window python3.8 安装依赖后,运行源码目录下的wzq.py启动 程序提供了ui源文件,可以拖动到Qt编辑器修改样式,然后通过pyside6把ui转成python…...

美团2024届秋招笔试第二场编程真题
要么是以0开头 要么以1开头 选择最小的答案累加 import java.util.Scanner; import java.util.*; // 注意类名必须为 Main, 不要有任何 package xxx 信息 public class Main {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和…...
Server-u配置FTP 多用户访问多目录图解
目录 一、 本案例目录环境 二、实现目标 三、实现方法 1、新建ftp域名 2、目录设置 3、用户创建 上篇文章【Server-U搭建FTP共享文件】很多朋友都私信我,希望深入了解Server-U的多用户设置,因此对多用户的访问设置进行了如下的总结。 一、...
)
ARM IHI0069F GIC architecture specification (1)
CH1.1 关于通用中断控制器 (GIC) GICv3 架构设计用于与 Armv8-A 和 Armv8-R 兼容的处理元件、PE 一起运行。 通用中断控制器 (GIC) 架构定义: • 处理连接到GIC 的任何PE 的所有中断源的架构要求。 • 适用于单处理器或多处理器系统的通用中断控制器编程接口。 GIC …...

golang+vue微服务电商系统
golangvue微服务电商系统 文章目录 golangvue微服务电商系统一、项目前置准备二、项目简介三、代码GItee地址 golang、vue redis、mysql、gin、nacos、es、kibana、jwt 一、项目前置准备 环境的搭建 官方go开发工程师参考地址:https://blog.csdn.net/qq23001186/cat…...

2024年大模型面试准备(三):聊一聊大模型的幻觉问题
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。 合集在这…...
微信小程序实战:无痛集成腾讯地图服务
在移动互联网时代,地图服务无疑是应用程序中最常见也最实用的功能之一。无论是导航定位、附近搜索还是路线规划,地图服务都能为用户提供极大的便利。在微信小程序开发中,我们可以轻松集成腾讯地图服务,为小程序赋能增值体验。本文将详细介绍如何在微信小程序中集成使用腾讯地图…...
[flask]flask的路由
路由的基本定义 路由就是一种映射关系。是绑定应用程序(视图)和url地址的一种一对一的映射关系!在开发过程中,编写项目时所使用的路由往往是指代了框架/项目中用于完成路由功能的类,这个类一般就是路由类,…...

javaWeb项目-快捷酒店信息管理系统功能介绍
开发工具:IDEA 、Eclipse 编程语言: Java 数据库: MySQL5.7 框架:ssm、Springboot 前端:Vue、ElementUI 关键技术:springboot、SSM、vue、MYSQL、MAVEN 数据库工具:Navicat、SQLyog 项目关键技术 1、JSP技术 JSP(Java…...
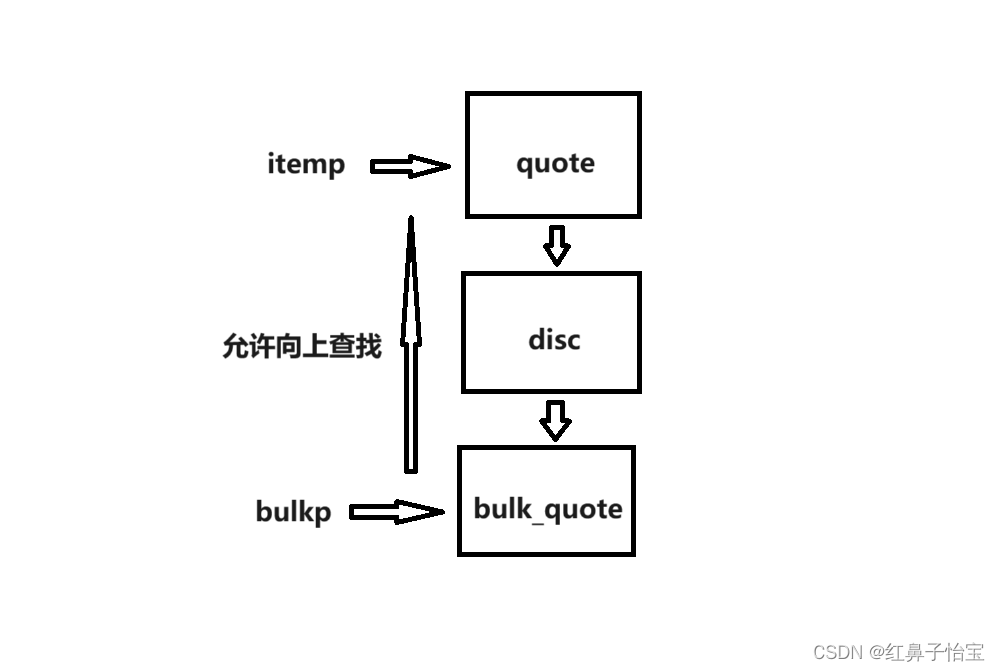
C++ primer 第十五章
1.OPP:概述 面向对象程序设计的核心思想是数据抽象、继承和动态绑定。 通过继承联系在一起的类构成一种层次关系,在层次关系的根部的是基类,基类下面的类是派生类 基类负责定义在层次关系中所有类共同拥有的成员,而每个派生类定义各自特有…...
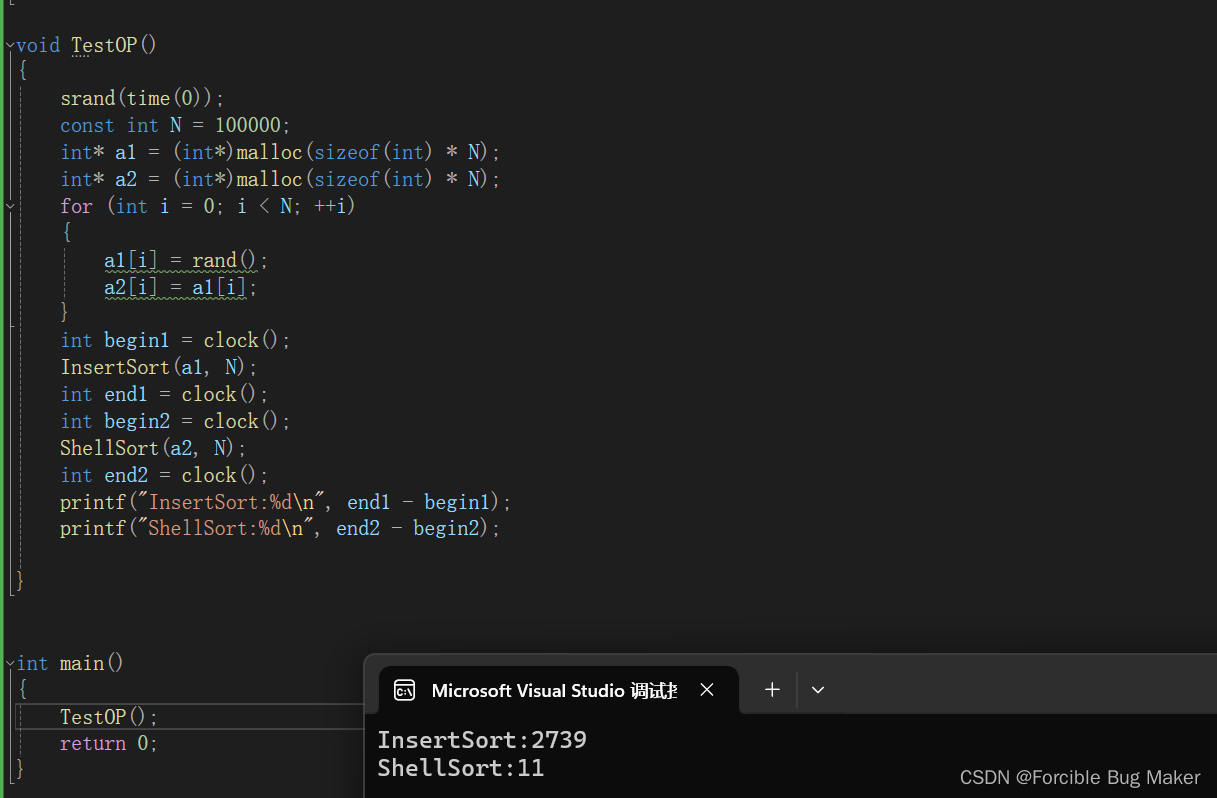
【数据结构与算法】直接插入排序和希尔排序
引言 进入了初阶数据结构的一个新的主题——排序。所谓排序,就是一串记录,按照其中的某几个或某些关键字的大小(一定的规则),递增或递减排列起来的操作。 排序的稳定性:在一定的规则下,两个值…...

HQL,SQL刷题,尚硅谷
目录 相关表数据: 题目及思路解析: 多表连接 1、课程编号为"01"且课程分数小于60,按分数降序排列的学生信息 2、查询所有课程成绩在70分以上 的学生的姓名、课程名称和分数,按分数升序排列 3、查询该学生不同课程的成绩…...

随机生成用户名、密码、注册时间【Excel】
1.1简介 最近想虚拟一些数据,看下有没有自动生成的工具。百度看了下,大概有这么几种方法 1.excel内置公式函数处理 2.使用使用VBA宏生成随机 3.下载方方格子,emm工具是个好工具,蛮多功能的,每月8块 4.Java函数实现…...

C++函数模板详解(结合代码)
目录 1. 模板概念 2. 函数模板语法 3. 函数模板注意事项 4. 函数模板案例 5. 普通函数与函数模板的区别 6. 普通函数与函数模板的调用规则 7. 模板的局限性 1. 模板概念 在C中,模板是一种通用的程序设计工具,它允许我们处理多种数据类型而不是固…...

Nest学习随笔
一、Middleware(中间件)、Interceptor(拦截器)、ExceptionFilter(异常过滤器) 执行顺序 接口调用正常:Middleware > Interceptor接口调用异常:Middleware > ExceptionFilter 二、访问静态文件 使用 nestjs/serve-static 依赖 配置方法&#x…...
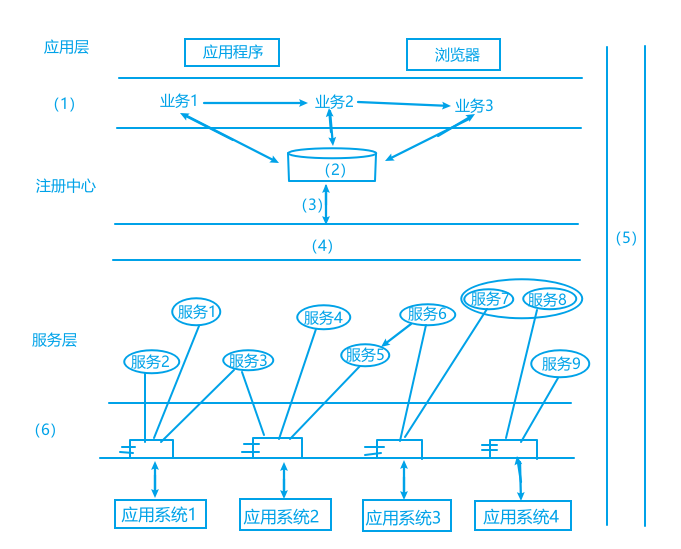
二十二、软考-系统架构设计师笔记-真题解析-2018年真题
软考-系统架构设计师-2018年上午选择题真题 考试时间 8:30 ~ 11:00 150分钟 1.在磁盘调度管理中,应先进行移臂调度,再进行旋转调度。假设磁盘移动臂位于21号柱面上,进程的请求序列如下表所示。如果采用最短移臂调度算法,那么系统…...

2024最新最全Selenium自动化测试面试题!
1、什么是自动化测试、自动化测试的优势是什么? 通过工具或脚本代替手工测试执行过程的测试都叫自动化测试。 自动化测试的优势: 1、减少回归测试成本 2、减少兼容性测试成本 3、提高测试反馈速度 4、提高测试覆盖率 5、让测试工程师做更有意义的…...
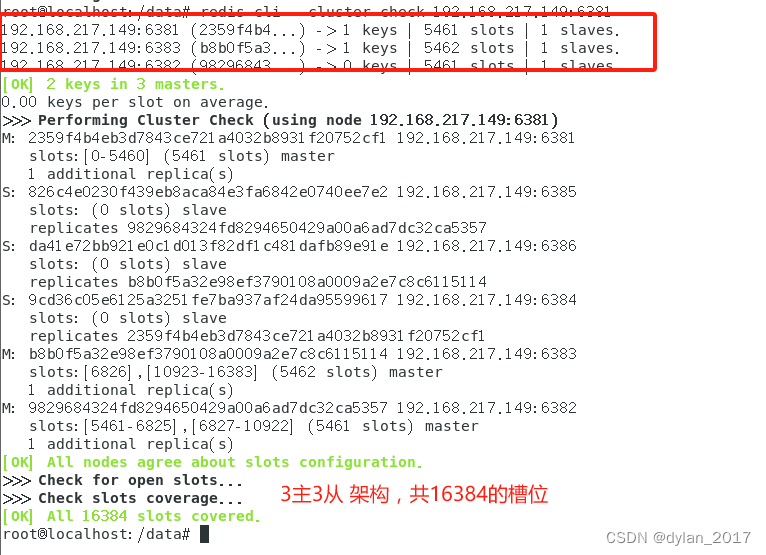
Docker 搭建Redis集群
目录 1. 3主3从架构说明 2. 3主3从Redis集群配置 2.1关闭防火墙启动docker后台服务 2.2 新建6个docker容器实例 2.3 进去任意一台redis容器,为6台机器构建集群关系 2.4 进去6381,查看集群状态 3. 主从容错切换迁移 3.1 数据读写存储 3.1.1 查看…...
spring boot商城、商城源码 欢迎交流
一个基于spring boot、spring oauth2.0、mybatis、redis的轻量级、前后端分离、防范xss攻击、拥有分布式锁,为生产环境多实例完全准备,数据库为b2b2c设计,拥有完整sku和下单流程的商城 联系: V-Tavendor...

张量网络机器学习:从平均风险下界看量子模型泛化极限
1. 项目概述:当张量网络遇见机器学习如果你和我一样,既对量子多体物理中的张量网络着迷,又对机器学习模型的泛化能力充满好奇,那么“张量网络机器学习模型平均风险的理论分析”这个课题,无疑是一个能将两者完美结合的宝…...

CFD湍流模型不确定性量化:特征空间扰动框架原理与应用
1. 项目概述与核心挑战在计算流体力学(CFD)的工程实践中,我们常常面临一个核心困境:如何高效且可靠地预测复杂湍流?雷诺平均纳维-斯托克斯(RANS)模型因其在计算成本和工程实用性之间的绝佳平衡&…...

LogExpert实战指南:5大核心功能深度探索Windows日志分析高效方案
LogExpert实战指南:5大核心功能深度探索Windows日志分析高效方案 【免费下载链接】LogExpert Windows tail program and log file analyzer. 项目地址: https://gitcode.com/gh_mirrors/lo/LogExpert LogExpert是一款专为Windows平台设计的图形化日志分析工具…...

3分钟免费激活Windows和Office:开源KMS激活脚本终极指南
3分钟免费激活Windows和Office:开源KMS激活脚本终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否正在为电脑屏幕上那个"Windows未激活"的水印而烦恼…...
)
保姆级教程:用AKShare+Backtrader+quantstats搭建你的第一个本地量化回测环境(避坑指南)
从零搭建本地量化回测系统:AKShare数据抓取Backtrader策略开发quantstats绩效分析实战指南第一次尝试量化投资的开发者常会遇到这样的困境:在线回测平台担心策略泄露,本地搭建环境又卡在依赖安装、数据格式转换等基础环节。本文将用最简化的方…...

基于MultiFold无分箱反卷积的轻子-喷注方位角不对称性测量
1. 项目概述与核心物理动机在粒子物理的高能前沿,我们常常通过“撞击”基本粒子来窥探其内部结构,深度非弹性散射(DIS)就是其中最经典、最有力的探针之一。想象一下,你用一束极高能量的电子(或正电子&#…...

kNN×KDE算法:基于相似性的数据填补原理与天文数据应用
1. 项目概述:当系外行星数据遇上“最像的邻居”在系外行星学这个领域,我们每天都在和数据“捉迷藏”。想象一下,你手里有一本记录了数千颗系外行星的“花名册”,但翻开一看,很多关键信息栏是空白的:这颗行星…...

PotPlayer字幕翻译插件:5分钟实现外语影视无障碍观看的终极免费方案
PotPlayer字幕翻译插件:5分钟实现外语影视无障碍观看的终极免费方案 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 还在为…...

BabelDOC:智能PDF翻译神器,完美保留原版格式与布局的终极方案
BabelDOC:智能PDF翻译神器,完美保留原版格式与布局的终极方案 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为PDF文档翻译后格式错乱而烦恼吗?BabelDO…...

阴阳师自动化脚本终极指南:一键解放双手的智能游戏助手
阴阳师自动化脚本终极指南:一键解放双手的智能游戏助手 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为阴阳师中重复繁琐的日常任务而烦恼吗?每天需…...