Machine Learning机器学习之决策树算法 Decision Tree(附Python代码)
目录
前言:
一、决策树思想
二、经典决策树算法
三、算法应用案列
基于Python 和 Scikit-learn 库实现决策树算法的简单示例代码,用于解决分类问题:
四、总结
算法
决策树算法应用:
决策树算法优缺点:
博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
前言:
决策树是一种经典的机器学习算法,用于解决分类和回归问题。它的基本思想是通过对数据集中的特征进行递归划分,构建一系列的决策规则,从而生成一个树状结构。在决策树中,每个内部节点表示对输入特征的一个测试,每个分支代表一个测试结果,而每个叶子节点表示一个类别或输出值。
决策树的发展历史可以追溯到20世纪50年代和60年代。最早的决策树算法是ID3(Iterative Dichotomiser 3),由Ross Quinlan于1986年提出。之后,C4.5算法和其改进版本C5.0也相继提出,扩展了ID3算法并加入了剪枝等优化方法。此外,还有 CART(Classification and Regression Trees)算法,由Leo Breiman等人于1984年提出,可用于分类和回归问题,并引入了基于基尼系数(Gini impurity)和均方误差(Mean Squared Error)的划分准则。
决策树在机器学习领域得到了广泛的应用,具有许多优点,如易于理解、可解释性强、能够处理混合数据类型等。它适用于多种任务,包括分类、回归、特征选择等。此外,决策树还可以通过集成学习方法(如随机森林、梯度提升树)进一步提升性能,并解决决策树容易过拟合的问题。
总的来说,决策树是一种简单而有效的机器学习算法,为解决分类和回归问题提供了一种直观的方法。随着机器学习领域的发展,决策树算法也在不断地被改进和优化,为各种实际问题提供了强大的工具。
一、决策树思想
决策树的思想原理是通过对数据集中的特征进行递归划分,构建一系列的决策规则,从而生成一个树状结构。其基本思想可以总结如下:
-
选择最佳特征: 首先,从数据集中选择一个最佳的特征作为当前节点的划分标准。通常使用一些准则来评估特征的优劣,例如信息增益、基尼系数、均方误差等。
-
划分数据集: 将数据集根据选择的特征进行划分,生成多个子集,每个子集包含具有相同特征值的样本。
-
递归构建子树: 对每个子集递归地重复步骤1和步骤2,直到满足停止条件。停止条件可以是节点中样本的类别相同、达到最大深度、样本数量小于某个阈值等。
-
生成决策规则: 最终,每个叶子节点都表示一个类别或输出值,而每个内部节点都表示对输入特征的一个测试。通过将树的结构转化为一系列的if-then规则,可以解释数据的分类或预测过程。
-
剪枝优化(可选): 对生成的决策树进行剪枝优化,去除一些不必要的节点,防止过拟合。
通过这种方式,决策树可以根据输入特征对数据进行逐层的划分,构建出一个易于理解和解释的决策模型。决策树的基本思想是根据数据的特征值进行划分,通过划分后的数据集的纯度或者信息增益来选择最佳的划分特征,从而递归地构建出一个树状结构,实现对数据的分类或预测。
开始|V选择最佳特征作为根节点|V划分数据集,生成子集,选择最佳特征作为当前节点的划分标准/ | \/ | \/ | \子集1满足停止条件? 子集2满足停止条件? 子集3满足停止条件?/ | \ / | \ / | \ / | \V V V V V V生成叶子节点 递归构建子树 生成叶子节点 递归构建子树 生成叶子节点| | | | |V V V V V返回 返回 返回 返回 返回| | | | |V V V V V结束
二、经典决策树算法
经典的决策树算法包括ID3(Iterative Dichotomiser 3)、C4.5(Classification and Regression Trees)以及CART(Classification and Regression Trees)。这些算法在构建决策树时采用了不同的思想和策略,下面简要介绍它们的思想和实现步骤:
-
ID3(Iterative Dichotomiser 3):
- 思想: ID3算法是一种基于信息熵的决策树算法,它通过选择使得信息增益最大的特征来进行划分,以减少数据集的不确定性。
- 实现步骤:
- 从所有特征中选择使得信息增益最大的特征作为当前节点的划分标准。
- 根据选定的特征进行划分,生成子集。
- 对每个子集递归地重复步骤1和步骤2,直到满足停止条件。
- 生成叶子节点,表示类别或输出值。
- 返回。
-
C4.5(Classification and Regression Trees):
- 思想: C4.5算法是ID3的改进版本,它在选择划分特征时采用信息增益比来解决ID3算法对取值数目较多特征的偏好。
- 实现步骤:
- 从所有特征中选择使得信息增益比最大的特征作为当前节点的划分标准。
- 根据选定的特征进行划分,生成子集。
- 对每个子集递归地重复步骤1和步骤2,直到满足停止条件。
- 生成叶子节点,表示类别或输出值。
- 返回。
-
CART(Classification and Regression Trees):
- 思想: CART算法是一种同时适用于分类和回归问题的决策树算法,它通过选择使得基尼系数最小的特征来进行划分,以提高树的纯度。
- 实现步骤:
- 从所有特征中选择使得基尼系数最小的特征作为当前节点的划分标准。
- 根据选定的特征进行划分,生成子集。
- 对每个子集递归地重复步骤1和步骤2,直到满足停止条件。
- 生成叶子节点,表示类别或输出值。
- 返回。
这些经典的决策树算法在实现时都采用了递归的思想,通过选择最佳的划分特征来构建树结构,直到满足停止条件为止。每个算法在选择划分特征时都采用了不同的指标,如信息增益、信息增益比、基尼系数等,以达到不同的优化目标。
三、算法应用案列
基于Python 和 Scikit-learn 库实现决策树算法的简单示例代码,用于解决分类问题:
首先我们将使用鸢尾花数据集,并尝试根据花萼和花瓣的长度和宽度来预测鸢尾花的品种。
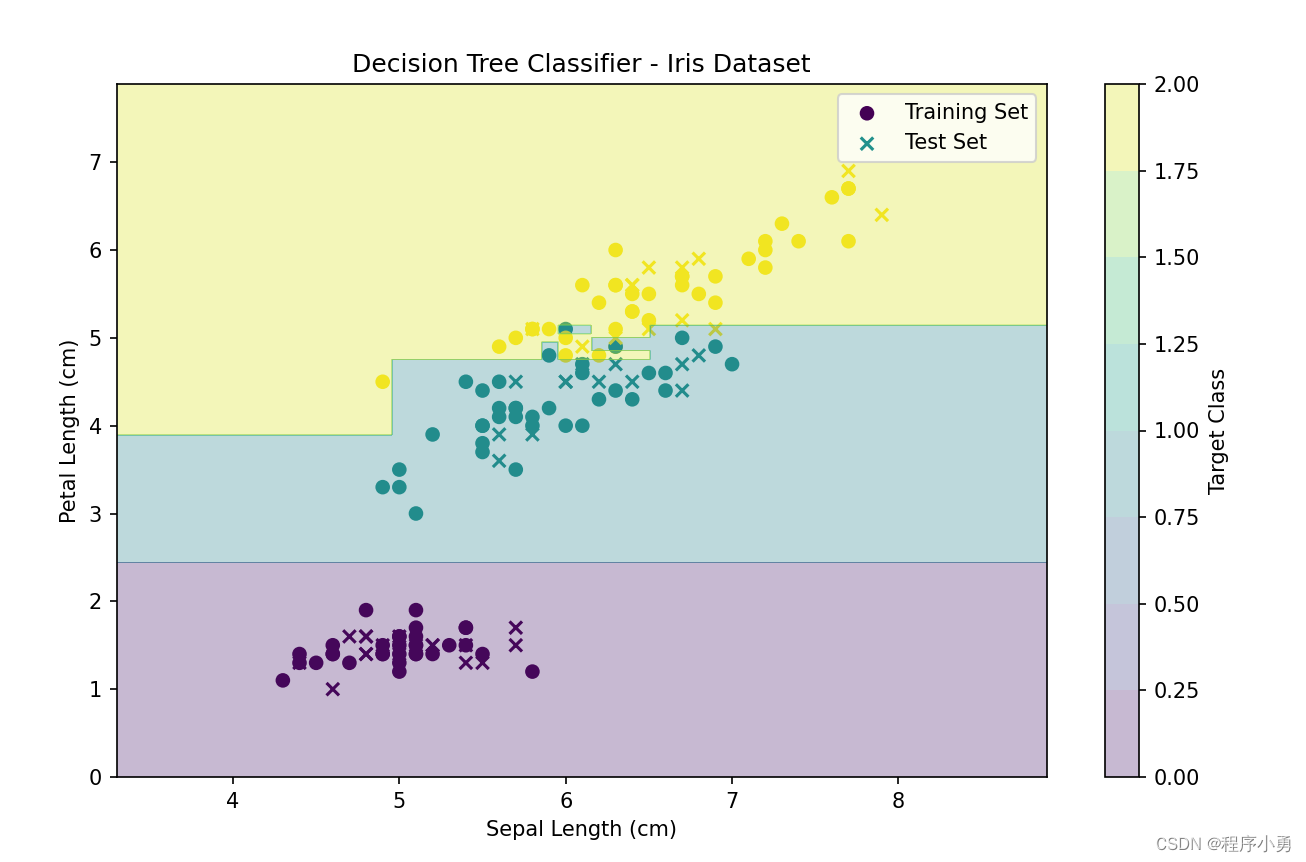
第一步是加载了鸢尾花数据集,并选择花萼长度和花瓣长度作为特征。然后将数据分为训练集和测试集,并创建了一个决策树模型并在训练集上拟合了模型。最后,使用Matplotlib绘制了训练集和测试集的数据点,并在图上绘制了决策边界。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 加载鸢尾花数据集
iris = load_iris()# 选择花萼长度和花瓣长度作为特征
X = iris.data[:, [0, 2]]
y = iris.target# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.29, random_state=42)# 创建决策树模型
model = DecisionTreeClassifier()# 在训练集上拟合模型
model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test)# 计算模型的准确率
accuracy = accuracy_score(y_test, y_pred)
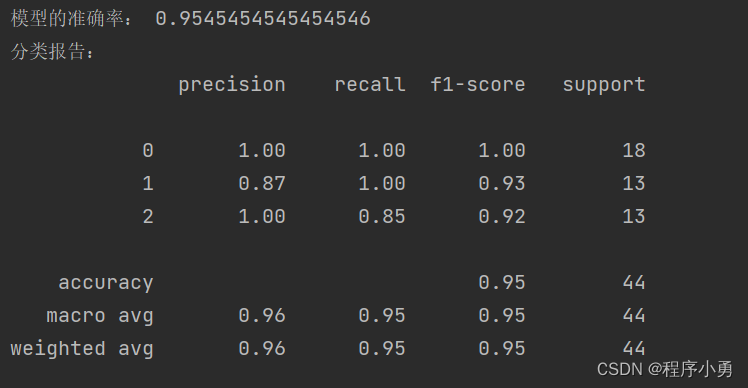
print("模型的准确率:", accuracy)# 打印分类报告
print("分类报告:")
print(classification_report(y_test, y_pred))# 绘制数据变化图
plt.figure(figsize=(10, 6))# 绘制训练集数据点
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', label='Training Set')# 绘制测试集数据点
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap='viridis', marker='x', label='Test Set')# 绘制决策边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),np.arange(y_min, y_max, 0.01))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap='viridis')plt.xlabel('Sepal Length (cm)')
plt.ylabel('Petal Length (cm)')
plt.title('Decision Tree Classifier - Iris Dataset')plt.legend()
plt.colorbar(label='Target Class')plt.show()
执行结果:数据集划分29%测试集,71%训练集。精确率约为95%
 四、总结
四、总结
算法
-
原理简单直观: 决策树基于对数据集中特征的递归划分,生成一系列的决策规则,形成树状结构,易于理解和解释。
-
可解释性强: 决策树模型生成的规则可以直观地解释为基于哪些特征进行分类或预测,为决策过程提供了透明度。
-
能够处理混合数据类型: 决策树算法能够处理包括连续型和离散型特征在内的多种数据类型。
-
适用于多种任务: 决策树可用于分类和回归问题,并且能够进行特征选择和缺失值处理等任务。
-
可扩展性好: 决策树可以与其他算法结合,如随机森林和梯度提升树等,以提高预测性能。
决策树算法应用:
-
医疗诊断: 决策树可用于根据患者的症状和体征进行医学诊断,帮助医生做出治疗决策。
-
金融风险评估: 决策树可用于根据借款人的信用记录和财务状况来评估贷款风险,并决定是否批准贷款。
-
市场营销: 决策树可用于分析客户的行为和偏好,帮助企业制定个性化的营销策略。
-
生态学研究: 决策树可用于分析生态系统中不同因素之间的关系,帮助科学家理解生态系统的结构和功能。
决策树算法优缺点:
优点:
- 简单直观,易于理解和解释。
- 可解释性强,生成的规则直观可见。
- 能够处理混合数据类型,包括连续型和离散型特征。
- 适用于多种任务,包括分类、回归、特征选择等。
- 可扩展性好,能够与其他算法结合提高预测性能。
缺点:
- 容易过拟合,特别是在处理复杂数据集时。
- 对于类别数量较多的特征,决策树倾向于选择类别数较多的特征进行划分。
- 不稳定性高,对输入数据的小变化可能会导致树结构的大变化。
- 在处理连续型数据时可能产生过于复杂的树结构,需要进行剪枝等操作来减少模型复杂度。
相关文章:
Machine Learning机器学习之决策树算法 Decision Tree(附Python代码)
目录 前言: 一、决策树思想 二、经典决策树算法 三、算法应用案列 基于Python 和 Scikit-learn 库实现决策树算法的简单示例代码,用于解决分类问题: 四、总结 算法 决策树算法应用: 决策树算法优缺点: 博主介绍&…...
Mybatis-Plus——09,代码自动生成器
代码自动生成器 一、先创建一个表二、创建一个类,配置代码生成器三、运行方法四、运行主方法,报错了。 一、先创建一个表 二、创建一个类,配置代码生成器 package com.gang;import com.baomidou.mybatisplus.annotation.DbType; import com.…...
Temu api接口 获取商品详情 数据采集
iDataRiver平台 https://www.idatariver.com/zh-cn/ 提供开箱即用的Temu电商数据采集API,供用户按需调用。 接口使用详情请参考Temu接口文档 接口列表 1. 获取商品详情 参数类型是否必填默认值示例值描述apikeystring是idr_***从控制台里复制apikeycountrystrin…...

安捷伦Agilent N1912A功率计
181/2461/8938产品概述: Keysight(原Agilent) N1912A P系列双通道功率计可提供峰值、峰均比、平均功率、上升时间、下降时间、最大功率值、最小功率值以及宽带信号的统计数据。 Keysight(原Agilent) N1912A P系列双通道功率计, 可提供峰值、峰均比、平均功率、上升…...
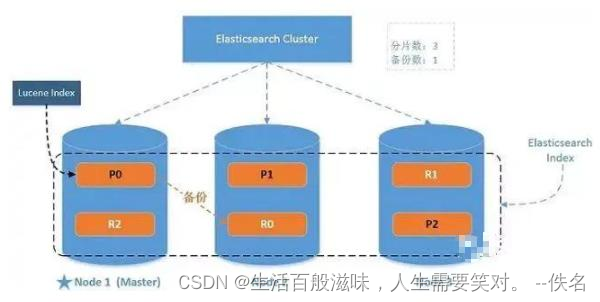
ES 进阶知识
索引Index 一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当我们…...

ChatGPT 对 ELT的理解
本文主要内容来自 ChatGPT 4.0 到底什么是 ETL?在数据库内部,把数据从 ODS 层加工成 DWD,再加工成 DWS,这个过程和 ETL 的关系是什么?带着这些问题,我问了一下 ChatGPT,总结如下。 数据在两个数…...

qt事件机制学习笔记
实现闹钟功能 #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget), speecher(new QTextToSpeech(this)) //给语音播报者实例化空间 {ui->setupUi(this); }Widget::~Widget() {delete …...

网红电商主播培养体系招聘管理制度孵化方案
【干货资料持续更新,以防走丢】 网红电商主播培养体系招聘管理制度孵化方案 部分资料预览 资料部分是网络整理,仅供学习参考。 共120页可编辑(完整资料包含以下内容) 目录 主播团队组建方案 让好主播主动留下 1. 好主播选拔标准…...

Android获取经纬度的最佳实现方式
Android中获取定位信息的方式有很多种,系统自带的LocationManager,以及第三方厂商提供的一些定位sdk,都能帮助我们获取当前经纬度,但第三方厂商一般都需要申请相关的key,且调用量高时,还会产生资费问题。这…...

芒果YOLOv8改进137:主干篇CSPNeXt,小目标检测专用,COCO数据集验证,协调参数量和计算量的均衡,即插即用 | 打造高性能检测
该专栏完整目录链接: 芒果YOLOv8深度改进教程 芒果专栏 本篇基于 CSPNeXt 的改进结构,改进源码教程 | 详情如下🥇 本博客 CSPNeXt 改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 即插即用 结构,博客包括改进所需的 核心结构代码 文件 重点:🔥🔥🔥YOLOv8 …...

【测试开发学习历程】认识Python + 安装Python
目录 1 认识 Python 1.1 Python 的起源 1.2 Python的组成 1.2.1 解释器 1.1.2 Python 的设计目标 1.1.3 Python 的设计哲学 1.2 为什么选择 Python 测试人员选择Python的理由 1.3 Python 特点 面向对象的思维方式 1.4 Python 的优缺点 1.4.1 优点 1.4.2 缺点 3. 安…...

webpack proxy工作原理?为什么能解决跨域?
一、是什么 webpack proxy,即webpack提供的代理服务 基本行为就是接收客户端发送的请求后转发给其他服务器 其目的是为了便于开发者在开发模式下解决跨域问题(浏览器安全策略限制) 想要实现代理首先需要一个中间服务器,webpac…...

ArkTS编写的HarmonyOS原生聊天UI框架
简介 ChatUI,是一个ArkTS编写的HarmonyOS原生聊天UI框架,提供了开箱即用的聊天对话组件。 下载安装 ohpm install changwei/chatuiOpenHarmony ohpm 环境配置等更多内容,请参考如何安装 OpenHarmony ohpm 包 接口和属性列表 接口列表 接…...

uni-app中web-view的使用
1. uni-app中web-view的使用 uni-app中的web-view是一个 web 浏览器组件,可以用来承载网页的容器,uni-app开发的app与web-view实现交互的方式相关简单,应用通过属性message绑定触发事件,然后在web-view的网页向应用 postMessage 触…...

前端跨域概念及解决方法
文章目录 前端跨域概念及解决方法什么是跨域跨域的解决方法JSONP跨域CORS简单请求 非简单请求 Nginx反向代理 前端跨域概念及解决方法 什么是跨域 同源指:两个页面域名、协议、端口均相同。 同源策略是浏览器的一个安全限制,跨域是由浏览器的同源策略造…...

Redis中的事务机制
Redis中的事务机制 概述。 事务表示一组动作,要么全部执行,要么全部不执行。例子如下。 Redis提供了简单的事务功能,讲一组需要一起执行的命令放到multi和exec两个命令之间。multi命令代表事务开始,exec命令代表事务结束&#x…...
从零到一构建短链接系统(八)
1.git上传远程仓库(现在才想起来) git init git add . git commit -m "first commit" git remote add origin OLiyscxm/shortlink git push -u origin "master" 2.开发全局异常拦截器之后就可以简化UserController 拦截器可以…...
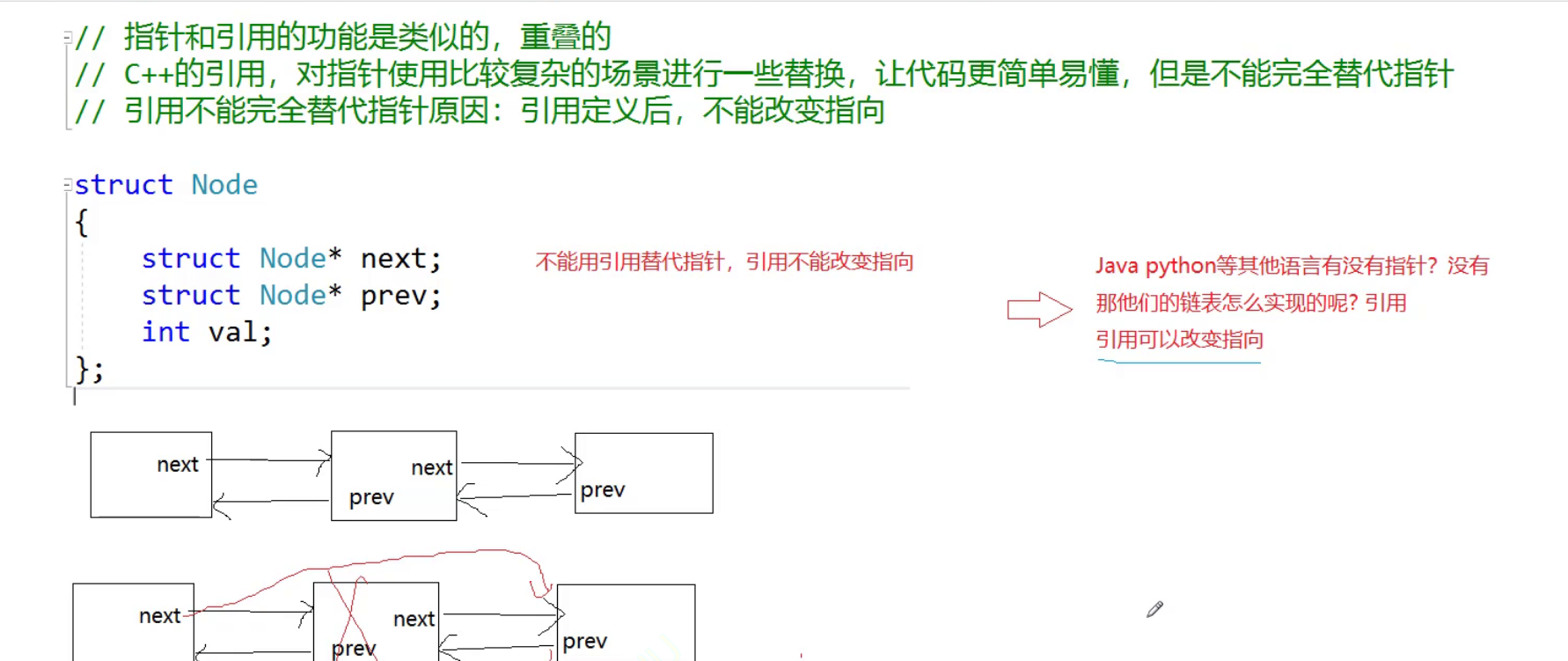
缺省和重载。引用——初识c++
. 个人主页:晓风飞 专栏:数据结构|Linux|C语言 路漫漫其修远兮,吾将上下而求索 文章目录 C输入&输出cout 和cin<<>> 缺省参数全缺省半缺省应用场景声明和定义分离的情况 函数重载1.参数的类型不同2.参数的个数不同3.参数的顺…...
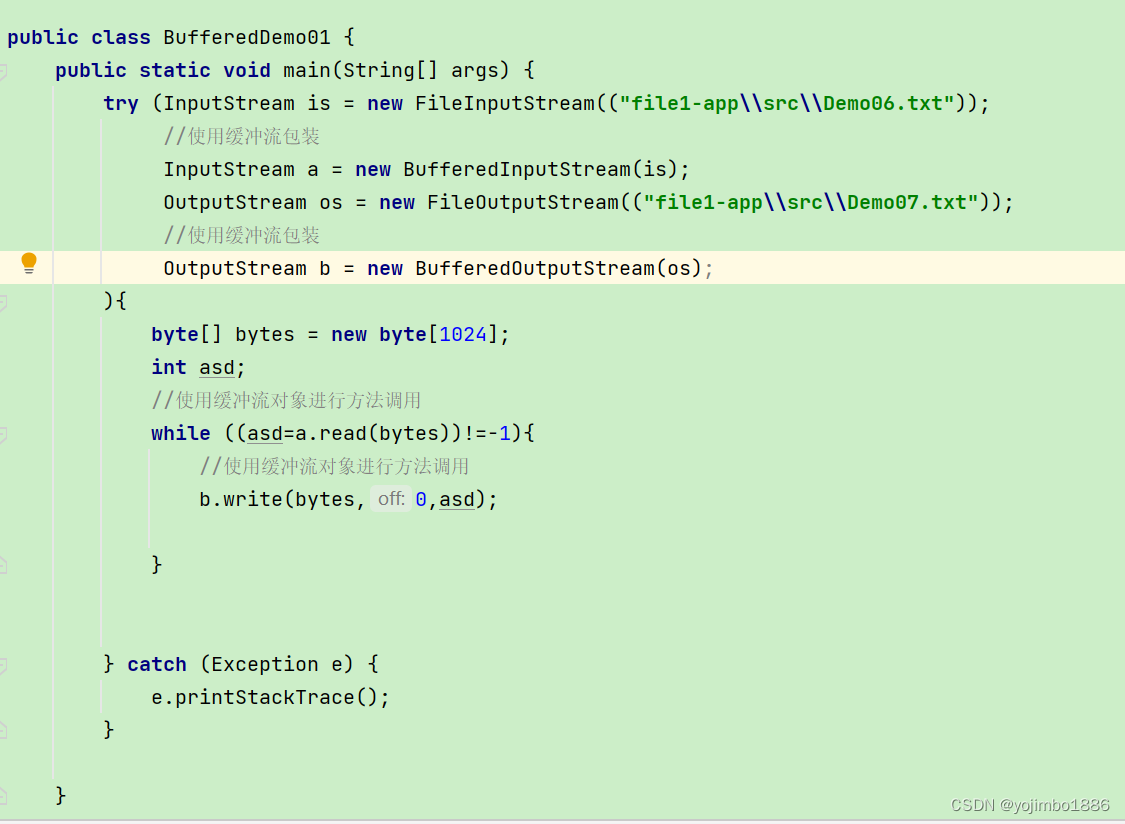
java常用IO流功能——字符流和缓冲流概述
前言: 整理下学习笔记,打好基础,daydayup! 之前说了下了IO流的概念,并整理了字节流,有需要的可以看这篇 java常用应用程序编程接口(API)——IO流概述及字节流的使用 字符流 FileReader(文件字…...

Python中模块的定义、用法
在Python中,模块是一个包含了Python代码的文件。模块可以包含变量定义、函数、类等,并且可以在其他Python脚本中被导入和使用。模块的定义和用法如下所示: 模块的定义: 创建模块文件:在Python中,一个模块就…...

Kerr相干态:从非线性量子光学到光子晶格模拟的实现路径
1. 引言:从经典光场到非线性量子相干态 在量子光学的研究中,相干态是一个基石性的概念。它最初由罗伊格劳伯在1960年代引入,用以描述激光器输出的光场。简单来说,一个理想的单模激光,其量子态就可以用一个相干态来极好…...

软体机器人跳跃:离散弹性杆仿真与动态分岔原理详解
1. 软体机器人跳跃:从生物灵感走向工程现实如果你观察过一只蚂蚱的起跳,或者一只青蛙的弹射,那种瞬间爆发、姿态优雅的运动,背后是自然界亿万年来优化的高效能量转换机制。传统的刚性机器人,靠着电机、齿轮和连杆&…...
)
仅剩72小时!Claude ROI计算模型企业定制版限时开放API对接权限(含AWS/Azure/GCP原生适配器)
更多请点击: https://codechina.net 第一章:Claude ROI计算模型企业定制版核心价值与限时策略 Claude ROI计算模型企业定制版并非通用模板的简单参数调整,而是基于客户实际业务流、成本结构与AI应用成熟度深度耦合的量化决策引擎。其核心价值…...

Windows 11系统下,Fiddler代理端口不是8888?这份Mumu模拟器网络调试避坑指南请收好
Windows 11系统下Fiddler与Mumu模拟器网络调试实战指南在移动应用开发和测试过程中,网络调试工具与模拟器的配合使用是必不可少的环节。许多开发者习惯性地认为Fiddler的默认代理端口就是8888,但在实际配置中,这个假设往往会导致一系列难以排…...

鸿蒙PC:鸿蒙electron跨端框架PC链接雷达实战:把本地收藏夹升级成可巡检的链接管理面板
前言 欢迎加入鸿蒙PC开发者社区,共同打造开发者工具生态:鸿蒙PC开发者社区 :https://harmonypc.csdn.net/ 项目开源地址:https://AtomGit.com/lqjmac/ele_lianjieleida 浏览器收藏夹能保存链接,但不擅长保存判断。 …...
)
AI知识管理不是工具升级,而是教学主权重构:一位特级教师用18个月完成“教案→知识流→认知干预”三级跃迁(全程数据脱敏实录)
更多请点击: https://intelliparadigm.com 第一章:AI知识管理在教育领域的应用 AI知识管理正深刻重塑教育生态,通过智能索引、语义理解与个性化推荐,将碎片化教学资源转化为可检索、可推理、可演化的结构化知识网络。教师可借助自…...

分布式系统测试:验证分布式系统的正确性和性能
分布式系统测试:验证分布式系统的正确性和性能 一、分布式系统测试概述 1.1 分布式系统测试的定义 分布式系统测试是指对分布式系统进行验证和评估的过程,包括功能测试、性能测试、可靠性测试和安全性测试等方面。它确保分布式系统在各种场景下都能正确、…...

如何重塑贴吧体验:贴吧Lite带来的极致纯净浏览革新
如何重塑贴吧体验:贴吧Lite带来的极致纯净浏览革新 【免费下载链接】TiebaLite 贴吧 Lite 项目地址: https://gitcode.com/gh_mirrors/tieb/TiebaLite 厌倦了官方贴吧应用的臃肿体验和无处不在的广告干扰?贴吧Lite作为一款革命性的第三方贴吧客户…...

AI 安全生产管理平台:用数字技术筑牢企业安全防线
传统企业安全生产长期依赖“人工巡检、事后整改”的模式,人工排查存在疲劳漏检、响应滞后、标准不一等痛点,很难全天候守住生产安全底线。而 AI 安全生产管理平台依托人工智能、物联网、边缘计算、大数据等核心技术,彻底打破传统“人防”局限…...

STM32新手必看:用CubeMX图形化配置PLL时钟,5分钟搞定72MHz系统时钟
STM32CubeMX图形化配置PLL时钟实战指南 对于刚接触STM32开发的工程师来说,时钟树配置往往是最令人头疼的环节之一。传统的手动寄存器配置方式需要查阅大量参考手册,理解复杂的时钟路径和分频系数关系。而STM32CubeMX这款图形化工具的出现,彻底…...