Kafka总结问题
Kafka
- Kafka
Kafka
Kafka的核心概念/ 结构
-
topoic
- Topic 被称为主题,在 kafka 中,使用一个类别属性来划分消息的所属类,划分消息的这个类称为 topic。topic 相当于消息的分配标签,是一个逻辑概念。主题好比是数据库的表,或者文件系统中的文件夹。
-
partition
- partition 译为分区,topic 中的消息被分割为一个或多个的 partition,它是一个物理概念,对应到系统上的就是一个或若干个目录,一个分区就是一个
提交日志。消息以追加的形式写入分区,先后以顺序的方式读取。 - 注意:由于一个主题包含无数个分区,因此无法保证在整个 topic 中有序,但是单个 Partition 分区可以保证有序。消息被迫加写入每个分区的尾部。Kafka 通过分区来实现数据冗余和伸缩性
- 分区可以分布在不同的服务器上,也就是说,一个主题可以跨越多个服务器,以此来提供比单个服务器更强大的性能。
- partition 译为分区,topic 中的消息被分割为一个或多个的 partition,它是一个物理概念,对应到系统上的就是一个或若干个目录,一个分区就是一个
-
producer
- 生产者,即消息的发布者,其会将某 topic 的消息发布到相应的 partition 中。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。
-
consumer
- 消费者,即消息的使用者,一个消费者可以消费多个 topic 的消息,对于某一个 topic 的消息,其只会消费同一个 partition 中的消息
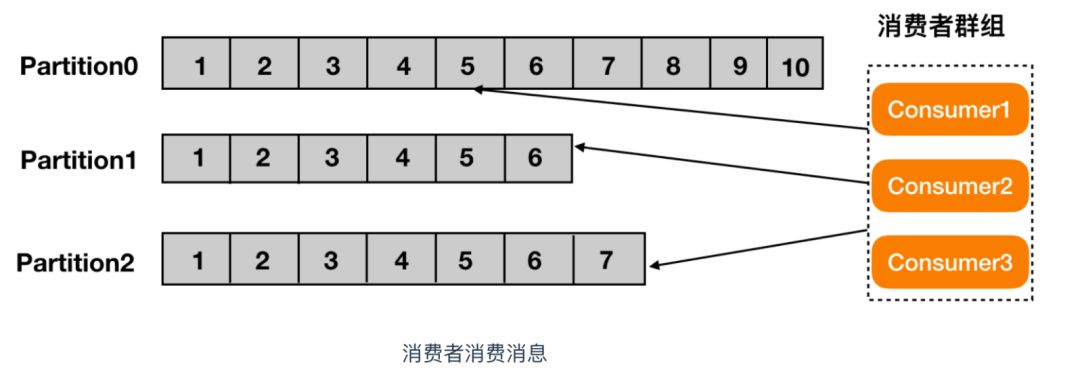
-
broker
-
Kafka 集群包含一个或多个服务器,每个 Kafka 中服务器被称为 broker。broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
broker 是集群的组成部分,每个集群中都会有一个 broker 同时充当了
集群控制器(Leader)的角色,它是由集群中的活跃成员选举出来的。每个集群中的成员都有可能充当 Leader,Leader 负责管理工作,包括将分区分配给 broker 和监控 broker。集群中,一个分区从属于一个 Leader,但是一个分区可以分配给多个 broker(非Leader),这时候会发生分区复制。这种复制的机制为分区提供了消息冗余,如果一个 broker 失效,那么其他活跃用户会重新选举一个 Leader 接管。
-
Kafka的应用场景
- 作为mq, 异步解耦削峰
- 活动跟踪, 实时检测, 将用户活动发布到中心topic上, 然后使用检测技术检测用户行为
- 日志聚合, 收集日志后, 提取出来进行流处理, 这样我们就可以自定义流来抽象我们的日志消息流
kafka为什么快
-
磁盘顺序读, 使得磁盘顺序寻址, 减少了时间
-
零拷贝 ->这个地方貌似还比较重要, 之后单独写一篇文章研究一下
-
消息可以分批发送,减少了网络传输和磁盘IO读写
- 在生产者生辰的时候, 消息不会立刻发送到kafka, 而是发送到生产者缓冲区, 封装成一个批次batch, 之后sender线程会从缓存中取出这些批次, 发送给kafka(batch有三个参数进行控制 : 累计消息数量+累计时间间隔+累计数据大小)
- 消费者消费的时候pull模式也可以自主决定是否批量从kafk拉取数据(但是如果kafka本身现在没有消息, 这个时候消费者会空转, kafka提供了参数可以让consumer阻塞直到新消息到达)
-
消息批量压缩
-
分区分段+索引
Kafaka中的Topic如何分区放置到不同的Broker
首先第一个分区放置的位置是从BrokerList中随机选择的
其他分区的位置, 会依次在这个位置向后偏移
Kafka中的topic中的partition数据是如何存储到磁盘
Topic中的partition是以文件夹的形式保存到Broker, 每个分区号从0递增, 且消息有序, Partition文件下有多个Segment(xxx.index, xxx.log), 分段, segment文件的大小和配置文件大小一致, 如果大小大于了1G, 就会滚动一个新的segment并且以上一个segment最后一条消息的偏移量命名
kafka为什么分区
- 方便在集群中扩展, 每个partiotion可以通过调整适应所在的机器, 而一个topic可以由多个partition组成, 所以整个集群可以适应任意大小的数据
- 提高并发, 因为可以通过partition为单位进行读写
- 为了提高Kafka处理消息吞吐量。假如同一个topic下有n个分区、n个消费者,每个分区会发送消息给对应的一个消费者,这样n个消费者就可以负载均衡地处理消息。同时生产者会发送消息给不同分区,每个分区分给不同的brocker处理,让集群平坦压力,这样大大提高了Kafka的吞吐量。
Consumer如何消费指定分区消息
Consumer消费消息的时候,可以发出fetch请求消费特定分区, 而且可以通过指定消息在日志中的偏移量offset, 可以从这个地方开始消费消息, 也可以消费以前消费过的消息, 甚至跳过一部分消息
kafka的ack的三种机制
request.required.acks有三个值0 1 -1(all)
1(默认):这意味着producer在ISR的leader已成功收到数据并得到确认,如果Leader宕机,则会丢失数据
0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但数据可靠性是最低的。
-1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失。比如当ISR中只有leader时,(ISR的成员由于某些情况会增加也会减少,最后就剩下一个leader),这样就变成ack=1的情况。
Kafka的手动提交和异步提交
partition中的offset用来记录我们消费的消息, 假设某一个消费者挂了, 这时候它所订阅的分区分摊给其他消费者, 如果分区中的offset因为没来得及消费就提交了offset或者消费了还没来得及提交offset, 就会导致消息重复消费/消息丢失
所以决定提交的时刻是十分重要的
-
自动提交偏移量
- 当enable.auto.commit被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动把从poll()方法接收的最大偏移量提交上去:
- 如果刚好到了5秒时提交了最大偏移量,此时正在消费中的消费者客户端崩溃了,就会导致消息丢失
- 如果成功消费了,下一秒应该自动提交,但此时消费者客户端奔溃了提交不了,就会导致其他分区的消费者重复消费
- Spring中使用commitSync()提交偏移量,commitSync()将会提交poll返回的最新的偏移量,所以在处理完所有记录后要确保调用了commitSync()方法。
-
手动提交
- 当enable.auto.commit被设置为false可以有以下三种提交方式
-
提交当前偏移量(同步提交) : 在broker对请求做出回应之前,客户端会一直阻塞,这样的话限制应用程序的吞吐量
-
异步提交 : 不会有吞吐量的问题。不过发送给broker偏移量之后,不会管broker有没有收到消息, 如果服务器返回提交失败,异步提交不会进行重试。如果同时存在多个异步提交,进行重试可能会导致位移覆盖。所以异步提交不会进行重试
-
同步和异步组合提交
先异步提交, 如果失败, 就trycatch兜底使用同步提交, 保证offset准确
kafka生产者生产过程, 消费模式
-
生产过程
- 消息首先会被封装成一个ProduceRecord对象
- 然后对消息进行序列化处理
- 对消息进行分区处理, 决定消息发向哪个主题的哪个分区
- 分好区后在Batch缓存中等待
- Sender线程启动将缓存中的数据批量发送到kafka---->发送的时候也是分为同步发送和异步发送的, 同步发送会等待结果, 异步发送会调用回调(异步回调可以在消息发送失败的时候记录日志)
-
消费模式
- 当Producer将消息推送到Broker之后, Consumer就会从Broker中获取消息
- 设置ConsumerConfig.DEFAULT_FETCH_MAX_WAIT_MS_CONFIG 阻塞等待消息
kafka怎么保证消息顺序性
Kafka分布式的单位是partition,同一个partition用一个write ahead log组织,所以可以保证FIFO的顺序。
不同partition之间不能保证顺序。因为同一个key的Message可以保证只发送到同一个partition。
Kafka中发送1条消息的时候,可以指定(topic, partition, key) 3个参数。partiton和key是可选的。如果你指定了partition,那就是所有消息发往同1个partition,就是有序的。
并且在消费端,Kafka保证,1个partition只能被1个consumer消费。或者你指定key(比如order id),具有同1个key的所有消息,会发往同1个partition。
Kafka如何实现延迟队列
-
使用kafka本身做延迟队列
- kafka本身没有延迟功能, 只是使用offset当作记录消息消费的位置
- 可以通过不断消费, 检测延时的时间有没有到达, 到达就消费数据, 没到达就把消息重新投递到partition中
- 但是这个消费不准确, 如果partiotion中的数据很多, 重新投递到分区的消息再次消费的时候可能远比设置的时间更久了
-
另外的方法并不是基于kafka本身实现的延迟队列
- 比如使用时间轮+kafka实现
- kafka+java delayqueue实现
- kafka+rockdb
Kafka的消息不漏发是如何实现的
- 个人认为消息完全不漏发是很难保证的, 毕竟从生产者到消费者消费的整个过程中, 存在着很多不确定因素
- 但是上面所说的, offset机制, 为了保证offset准确性而提到的手动提交,手动异步提交+同步提交
-
如果生产者发送到服务端kafka的时候, 失败了, 如何解决?
- 生产者使用异步回调, 记录失败的消息
- 使用消息确认机制, 确认所有partition的leader副本同步到消息之后, 才认为本次生产者发送消息成功
- 并且需要设置消息失败后生产者重试次数
- 本地也可以通过异常来定义消息日志表, 定期扫描这个表作为补偿
-
服务端broker如何保证消息不丢失?
- 服务端会将消息数据持久化保存到磁盘, 一般是先写入缓存然后刷盘, 如果刷盘失败, 消息丢失
- 这个时候可以使用同步刷盘(当生产者发送消息到broker端的时候,需要等待broker端把消息进行落盘之后,才会返回响应结果给生产者), 但是影响性能
- partition副本机制, 确保不止一个partition保存了消息
-
消费者端使用自动提交offset, 导致offset错误
- 设置手动提交
- 同时消费者端也需要进行幂等处理,防止重复消费 ->比如设置业务在数据库中的唯一约束, 或者在业务层面给消息加一个id, 作为去重
- 这里我们再想一个问题, 假如我整个kafka作为消息队列都挂了怎么办?那消息不是全部丢了吗?
- 这个时候一般会临时增加降级存储, 比如先起一个缓存, 把这些消息存储起来, 这个时候不断重试将消息推送到kafka中, 这样能够保证kafka能够第一时间消费到消息
相关文章:
Kafka总结问题
Kafka Kafka Kafka Kafka的核心概念/ 结构 topoic Topic 被称为主题,在 kafka 中,使用一个类别属性来划分消息的所属类,划分消息的这个类称为 topic。topic 相当于消息的分配标签,是一个逻辑概念。主题好比是数据库的表࿰…...

【RPG Maker MV 仿新仙剑 战斗场景UI (八)】
RPG Maker MV 仿新仙剑 战斗场景UI 八 状态及装备场景代码效果 状态及装备场景 本计划在战斗场景中直接制作的,但考虑到在战斗场景中加入太多的窗口这不太合适,操作也繁琐,因此直接使用其他场景。 代码 Pal_Window_EquipStatus.prototype.…...
【PyQt】18 -菜单等顶层操作
顶层界面的使用 前言一、菜单栏1.1 代码1.2 运行结果 二、工具栏2.1 代码几种显示方法 2.2 运行结果 三、状态栏3.1 代码3.2 运行结果 总结 前言 1、介绍顶层菜单栏目的使用,但没有陆续绑定槽函数。 2、工具栏 3、状态栏 一、菜单栏 1.1 代码 #Author :…...

线性代数基础概念和在AI中的应用
基本概念 线性代数是数学的一个分支,专注于向量、向量空间(也称为线性空间)、线性变换和矩阵的研究。这些概念在数据科学、人工智能、工程学和物理学等多个领域都有广泛应用。以下是这些基本概念的详细解释和它们在数据处理和AI中的应用。 …...
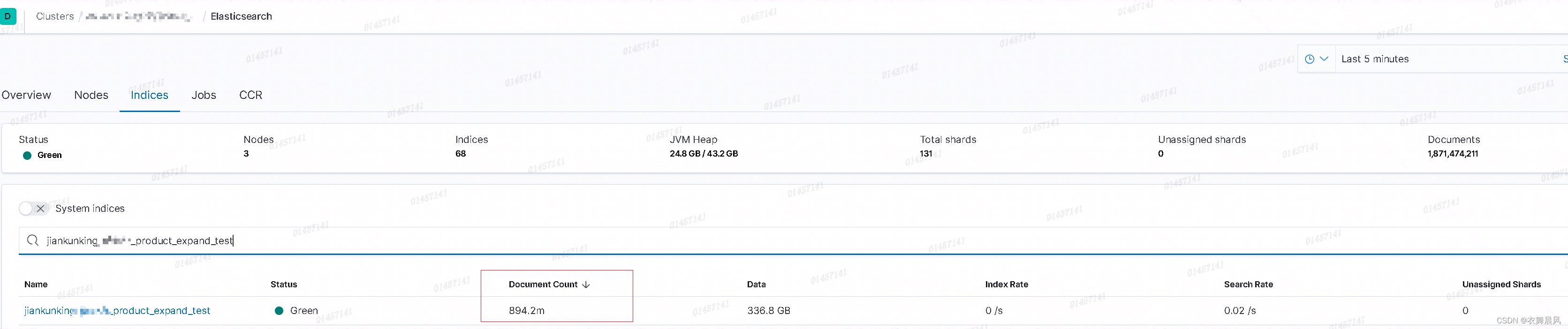
elasticsearch _cat/indices docs.count is different than <index>/_count
今天遇到一个问题,kibana中看到文档数与下面语句查询到的不同 GET /_cat/count/jiankunking_xxxxx_product_expand_test?v GET /jiankunking_xxxxx_product_expand_test/_search?track_total_hitstrue语句查询结果 epoch timestamp count 1711433785 06:16…...

关系型数据库mysql(7)sql高级语句
目录 一.MySQL常用查询 1.按关键字(字段)进行升降排序 按分数排序 (默认为升序) 按分数升序显示 按分数降序显示 根据条件进行排序(加上where) 根据多个字段进行排序 编辑 2.用或(or&…...

计算机网络——网络基础1
网络基础一 1.初识网络 网卡也是一种文件,所以对于网络的编程也是一种文件操作; 早期由于不同的计算机之间要根据数据进行协作,但是计算机之间是独立的,所以使用了光驱或者软盘之类的进行协作;对于将计算机连…...

ERDUnet: An Efficient Residual Double-codingUnet for Medical Image Segmentation
ERDUnet:一种用于医学图像分割的高效残差双编码单元 摘要 医学图像分割在临床诊断中有着广泛的应用,基于卷积神经网络的分割方法已经能够达到较高的准确率。然而,提取全局上下文特征仍然很困难,而且参数太大,无法临床应用。为此,我们提出了一种新的网络结构来改进传统的…...

vue响应式基础
声明响应式状态 ref() 在组合式 API 中,推荐使用 ref() 函数来声明响应式状态: import { ref } from vueconst count ref(0) ref() 接收参数,并将其包裹在一个带有 .value 属性的 ref 对象中返回: const count ref(0)c…...
每天上万简历,录取不到1%!阿里腾讯的 offer 都给了哪些人?
三月天杨柳醉春烟~正是求职好时节~ 与去年秋招的冷淡不同,今年春招市场放宽了许多,不少企业纷纷抛出橄榄枝,各大厂的只差把“缺人”两个字写在脸上了。 字节跳动技术方向开放数10个类型岗位,研发需求占比60%,非研发新增…...

外包干了20天,技术退步明显.......
先说一下自己的情况,大专生,21年通过校招进入杭州某软件公司,干了接近2年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落! 而我已经在一个企业干了2年的功能测试…...
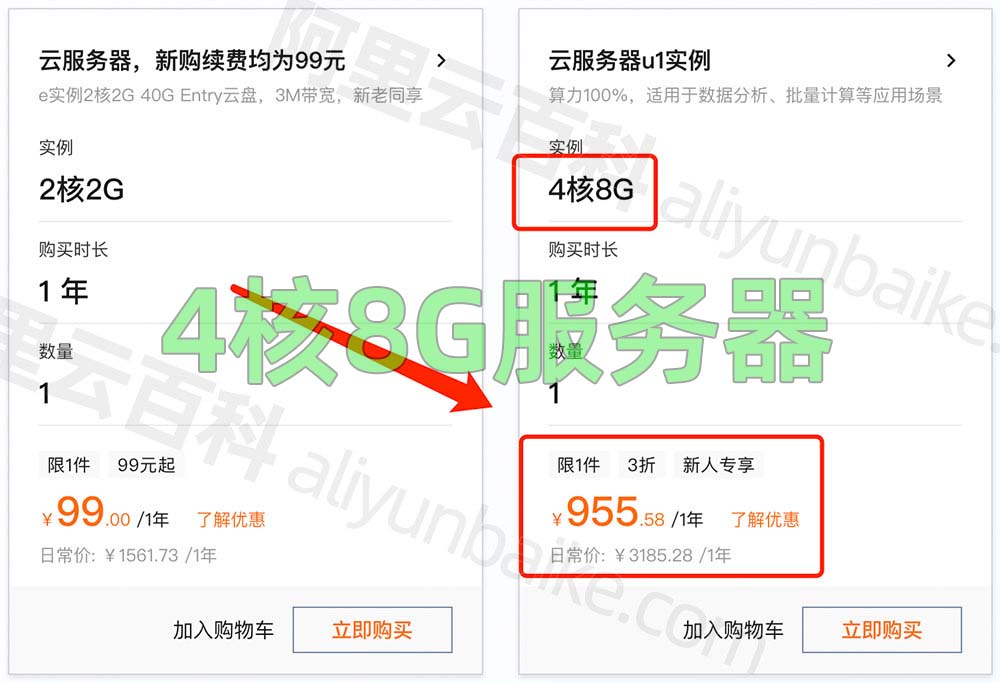
4核8G云服务器,阿里云要多少钱?
阿里云4核8G服务器优惠价格955元一年,配置为ECS通用算力型u1实例(ecs.u1-c1m2.xlarge)4核8G配置、1M到3M带宽可选、ESSD Entry系统盘20G到40G可选,CPU采用Intel(R) Xeon(R) Platinum处理器,阿里云活动链接 aliyunfuwuq…...

数学分析复习:振荡型级数的收敛判别
文章目录 振荡型级数的收敛判别 本篇文章适合个人复习翻阅,不建议新手入门使用 振荡型级数的收敛判别 直观上,振荡型级数说的是级数各项有正有负,求和的时候可以相互抵消,故可能收敛 命题:Abel求和公式 设复数列 { …...

阿里CICD流水线Docker部署,将阿里镜像私仓中的镜像部署到服务器中
文章目录 阿里CICD流水线Docker部署,将阿里镜像私仓中的镜像部署到服务器中一、CICD流水线的初步使用可以看我之前的两篇文章二、添加部署任务,进行Docker部署,创建一个阿里的试用主机1、选择主机部署,并添加服务主机2、创建免费体…...
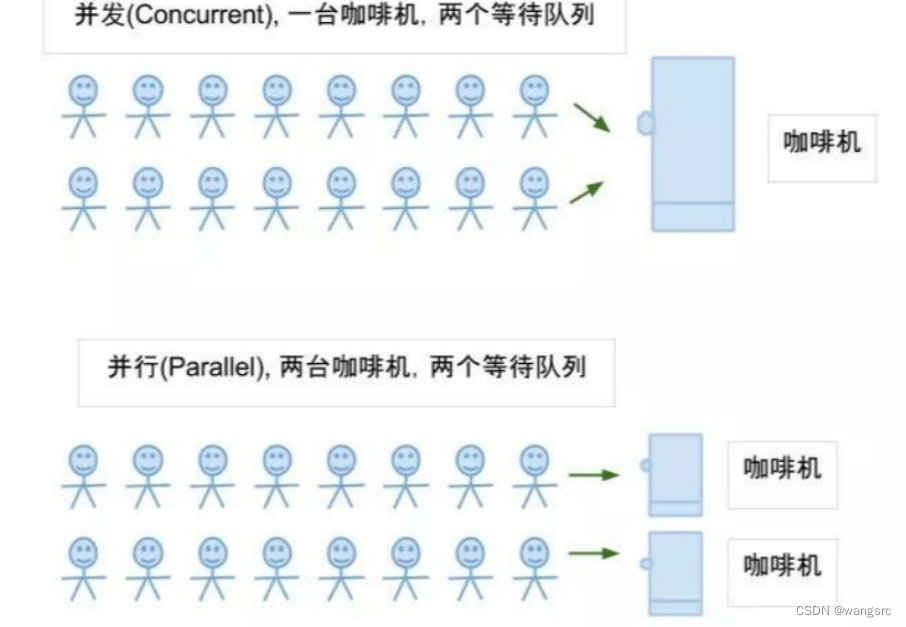
并发VS并行
参考文章 面试必考的:并发和并行有什么区别? 并发:一个人同时做多件事(射击游戏队友抢装备) 并行:多人同时处理同一件事(射击游戏敌人同时射击对方)...
 --- 进制A+B、网购、及格分数、最高分数、计算一元二次方程)
C语言经典例题(8) --- 进制A+B、网购、及格分数、最高分数、计算一元二次方程
文章目录 1.进制AB2.网购3.及格分数4.最高分数5.计算一元二次方程 1.进制AB 题目描述: 输入一个十六进制数a,和一个八进制数b,输出ab的十进制结果(范围-231~231-1)。 输入描述: 一行,一个十六…...
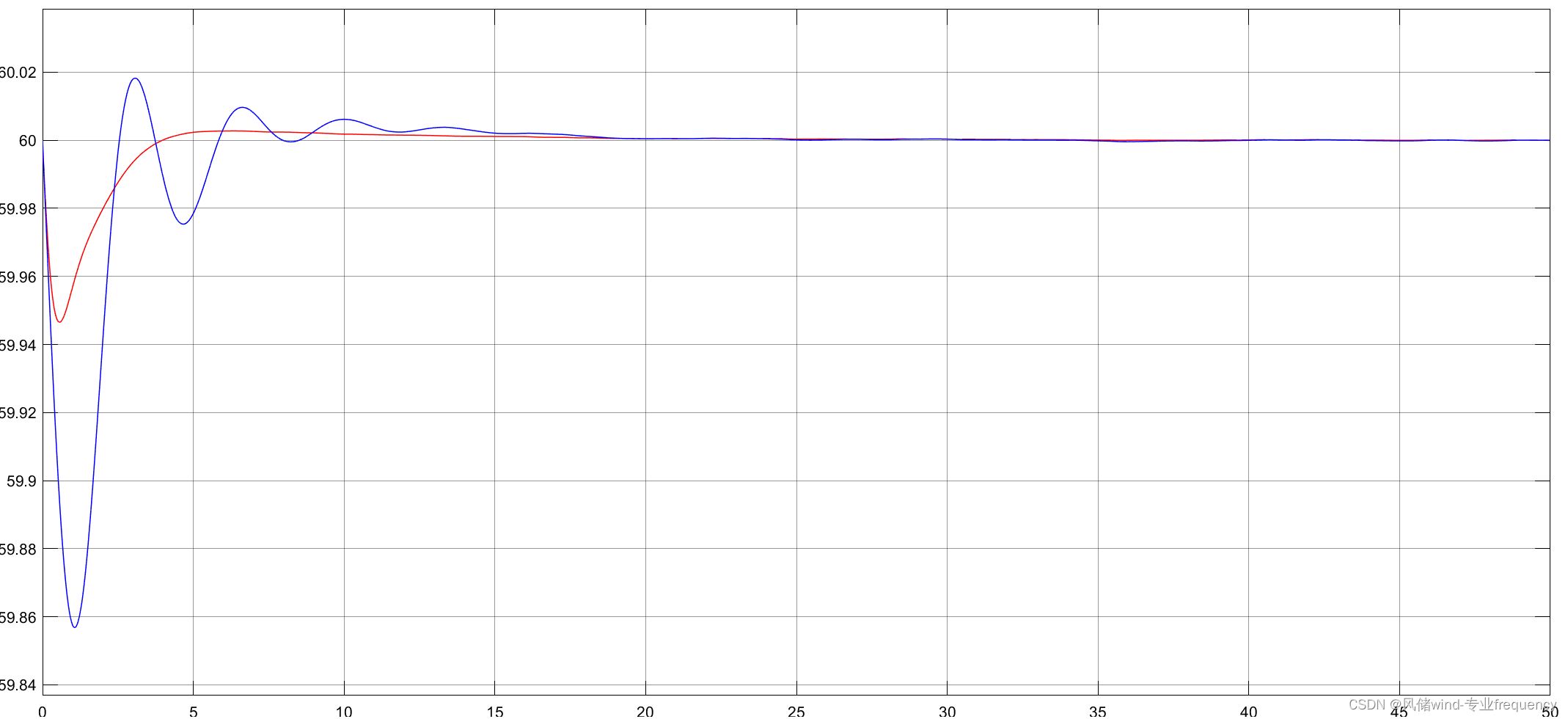
两区域二次调频风火机组,麻雀启发式算法改进simulink与matlab联合
区域1结果 区域2结果 红色曲线为优化后结果〔风火机组二次调频〕...

自动驾驶国际标准ISO文件
Coordinate system:Road vehicles — Vehicle dynamics and road-holding ability — Vocabulary...
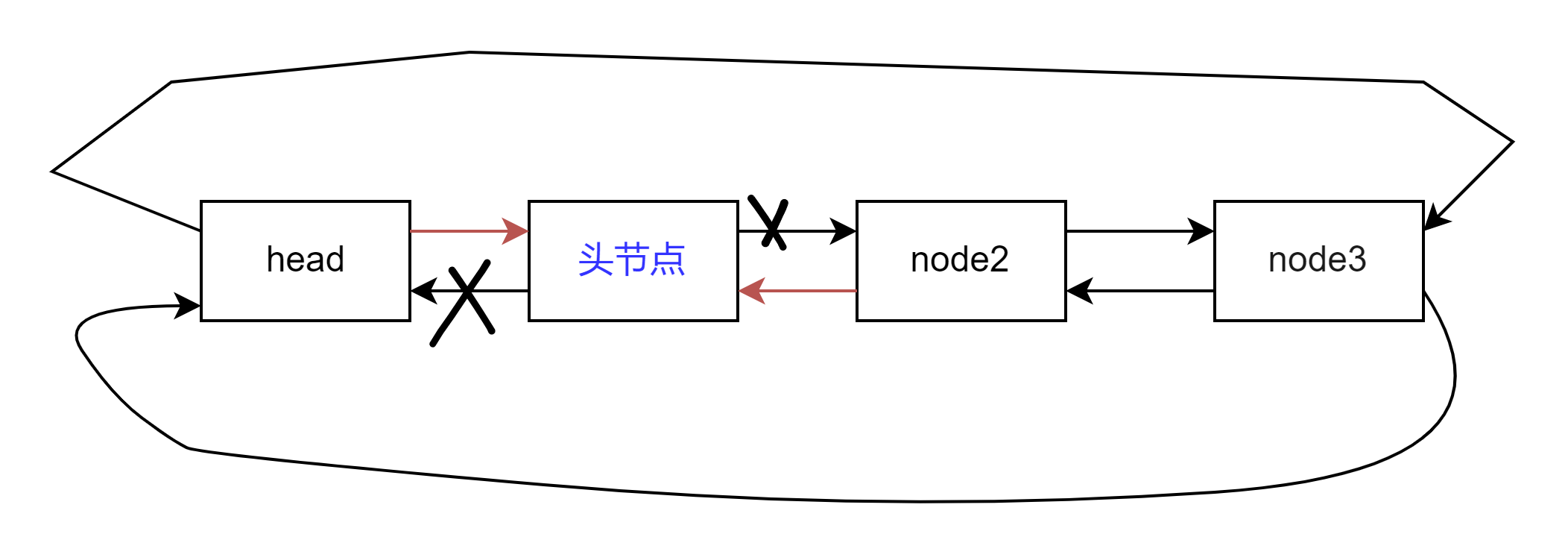
【数据结构】双向奔赴的爱恋 --- 双向链表
关注小庄 顿顿解馋๑ᵒᯅᵒ๑ 引言:上回我们讲解了单链表(单向不循环不带头链表),我们可以发现他是存在一定缺陷的,比如尾删的时候需要遍历一遍链表,这会大大降低我们的性能,再比如对于链表中的一个结点我们是无法直接…...

【Redis】高频面试题
提供五种常见的数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合) 文章目录 1、为什…...

《离别的最后》的内容入口:收尾场景如何被记住
从内容传播角度看,《离别的最后》的入口在“最后”这个收束动作。它不是笼统告别,而是写到一段关系、一个阶段或一次转身即将落下尾音的时刻。这首歌不适合被写成普通伤感推荐。更准确的角度,是把它放在收尾场景里:删掉草稿、收起…...

机器学习篇---图像分割
图像分割是计算机视觉的基础任务,简单说就是把图像划分成多个有意义的区域。经过多年发展,它已形成一套成熟的方法体系,大致可分为经典传统方法和现代深度学习方法两大流派。📜 经典传统方法:基于数学与物理规则在深度…...
)
14000华夏之光永存:开源:华为五大全栈硬核技术揭榜课题完整梳理(预刊抽取篇)
开源:华为五大全栈硬核技术揭榜课题完整梳理(预刊抽取篇) 摘要 本文完整收录黄大年茶思屋珠峰会战第八期5项前沿技术揭榜难题,原样保留技术背景、技术挑战、现有方案、现存缺陷与量化技术诉求,不做内容删减与篡改。本文…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan安装保姆级分享
2026年京东云OpenClaw/Hermes Agent配置Token Plan安装保姆级分享、OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具…...
 心智模型导览——《Designing Data-Intensive Applications》书介绍导航)
《设计数据密集型应用》(DDIA, 2nd ed.) 心智模型导览——《Designing Data-Intensive Applications》书介绍导航
《设计数据密集型应用》(DDIA, 2nd ed.) 心智模型导览——《Designing Data-Intensive Applications》书介绍导航写给:还没读过这本书、想先在脑子里有张地图的读者 目的:装上 6 个内容枢纽——不只是抽象概念,每个枢纽下面挂着这本书真正讲的…...

【AI Agent数据分析实战指南】:20年专家亲授5大落地场景、3类避坑红线与实时决策增效方案
更多请点击: https://intelliparadigm.com 第一章:AI Agent数据分析应用的演进逻辑与核心价值 AI Agent在数据分析领域的应用并非技术堆叠的结果,而是由数据复杂度跃升、业务响应时效压缩、以及人机协同范式重构三重力量共同驱动的系统性演进…...

内网离线部署RPA:打包EXE+本地激活+数据零上云方案
领导给了一周,我前三天全耗在这个报错上:无法连接到 activation.xxx.com 请检查网络连接后重试2024年5月,我用的蓝印RPA物理隔离内网部,处理核心业务数据,要求"数据不出本机,流程不外传,审…...

Agent怎样做到在信创环境全栈兼容?2026企业级智能体信创适配技术全解析
进入2026年,随着信创(信息技术应用创新)产业进入深水区,企业数字化转型已不再仅仅是简单的“去IOE”或系统迁移,而是演变为以AI Agent(智能体)为核心的新型生产力重构。在这一背景下,…...

unplugin-dts完整指南:从vite-plugin-dts迁移到通用插件
unplugin-dts完整指南:从vite-plugin-dts迁移到通用插件 【免费下载链接】unplugin-dts An unplugin for generating declaration (dts) files. 项目地址: https://gitcode.com/gh_mirrors/vi/unplugin-dts unplugin-dts是一款功能强大的通用插件,…...

军规零外源设备要求,无感定位完全替代UWB硬件堆叠方案
军规零外源设备要求,无感定位完全替代UWB硬件堆叠方案军队营区管控、战备执勤、野外演训、涉密阵地等场景,严格遵循军规装备管理准则,奉行零外源附加设备硬性管控标准,严禁额外加装大量外置终端、基站、线缆类附属设施。传统UWB定…...