生信数据分析——GO+KEGG富集分析
生信数据分析——GO+KEGG富集分析
目录
- 生信数据分析——GO+KEGG富集分析
- 1. 富集分析基础知识
- 2. GO富集分析(Rstudio)
- 3. KEGG富集分析(Rstudio)
1. 富集分析基础知识
1.1 为什么要做功能富集分析?
转录组学数据得到的基因非常多,面对大量的基因无法做到挨个研究其功能,因此为了研究基因所具有的功能,将部分功能相似的基因进行归类,这样具有相似功能的基因就被放在一起,构成了一个通路,从而减少工作量,并可以实现功能和表型相关联。
1.2 什么是富集分析?
富集分析是一种数据分析方法,主要用于理解基因集合或其他生物学实体在特定实验条件或生物学背景下的功能、通路或特定生物学过程的富集程度。其基本原理是,如果某个基因集合在特定条件下显著富集于某个功能类别或通路中,那么这些基因可能共同参与了某种特定的生物学过程或具有某种共同的功能特性
看上方的描述是不是感觉晦涩难懂,简单地说:所谓富集分析,本质上就是对分布的检验,如果基因分布集中在某一个区域(通路),则认为富集。
举个栗子: 做完差异后,得到了一堆差异基因,现在对这部分差异基因归归类,部分功能相似的基因可能被划分到了炎症通路上,有的基因被划分到了代谢通路上,这样就能大致知道筛选出来的差异基因与哪些功能相关。
1.3 富集分析有几种类型?
(1)GO富集分析
GO富集分析会从三个方面描述基因潜在的功能,分别是:
- 分子功能(Molecular Function,MF)——即基因是否富集到分子相关的通路上
- 细胞组分(Cellular Component,CC)——即基因定位在细胞的哪个位置上
- 参与的生物过程(Biological Process,BP)——即基因参与哪些生物学过程
举个栗子:离子通道活性的GO term是GO:0005216,如果差异基因富集到该term上,那么所研究的基因可能与离子通道的激活与抑制有关联。
(2)KEGG富集分析
京都基因与基因组百科全书(KEGG)是了解高级功能和生物系统(如细胞、生物和生态系统)、用于研究通路的数据库之一。KEGG 通路分析是借助 KEGG 数据库(Kyoto Encyclopedia of Genes and Genomes),对所有鉴定到的基因进行通路注释,并分析这些基因参与的主要代谢和信号转导途径。
简单说: 使用KEGG数据库中通路的注释信息,将基因与已知的代谢通路和功能进行关联
(3)GSEA富集分析
(4)GSVA富集分析
在这个分析点中重点关注GO富集分析和KEGG富集分析,GSEA和GSVA会在后面分析点中介绍。
2. GO富集分析(Rstudio)
本项目以 ADAMTS2, ADAMTS4, AGRN, COL5A1, CTSB, FMOD, LAMB3, LAMB4, LOXL2, MATN1, MEP1A, MMP1, MMP2, NTN1, PTN, SPARCL1, SPON1, TGFBI, THBS4, TNC, VTN, ITGB6, PTPRF, UNC5A 为例展示GO富集分析过程
物种:人类(Homo sapiens)
R版本:4.2.2
R包:tidyverse,clusterProfiler,org.Hs.eg.db
废话不多说,代码如下:
设置工作空间:
rm(list = ls()) # 删除工作空间中所有的对象
setwd('/XX/XX/XX') # 设置工作路径
if(!dir.exists('./02_GO+KEGG_enrichment')){dir.create('./02_GO+KEGG_enrichment')
} # 判断该工作路径下是否存在名为02_GO+KEGG_enrichment的文件夹,如果不存在则创建,如果存在则pass
setwd('./02_GO+KEGG_enrichment/') # 设置路径到刚才新建的02_GO+KEGG_enrichment下
加载包:
library(clusterProfiler)
library(org.Hs.eg.db)
library(tidyverse)
导入要富集分析的基因
gene <- c('ADAMTS2', 'ADAMTS4', 'AGRN', 'COL5A1', 'CTSB', 'FMOD', 'LAMB3', 'LAMB4', 'LOXL2',
'MATN1', 'MEP1A', 'MMP1', 'MMP2', 'NTN1', 'PTN', 'SPARCL1', 'SPON1', 'TGFBI', 'THBS4', 'TNC',
'VTN', 'ITGB6', 'PTPRF', 'UNC5A')
设置数据库(注意:由于本项目分析的是人类基因,因此选用的是org.Hs.eg.db,如果是其他物种,需要用其他数据库)
GO_database <- 'org.Hs.eg.db' # GO是org.Hs.eg.db数据库
gene ID转换(因为导入的是基因名(symbol),但是用官方的编号,也就是ENTREZID会比较专业一些,因此首先要将基因名转换成官方ENTREZID)
gene <- bitr(gene, fromType = 'SYMBOL', toType = 'ENTREZID', OrgDb = GO_database)
知识拓展: bitr函数不仅能将symbol转成ENTREZID,还能将ENTREZID转回symbol,甚至还能转换成其他形式,具体可以自行查看官方说明!
gene 如下图所示,第一列就是基因名(symbol),而第二列就是官方的ENTREZID编号
(注意:用bitr做转换的时候,很有可能会出现基因没有对应的ENTREZID编号,这是一个正常现象,不用过多焦虑,合理解释就行!)

GO富集分析并将富集分析结果转成数据框,enrichGO函数常用参数介绍如下:
- gene参数——是要输入的基因(一般用基因的ENTREZID编号)
- OrgDb 参数——指定要用到的数据库,人类是:org.Hs.eg.db(当然还有别的物种,可自行查询)
- keyType参数——设定读取的gene ID类型,本教程用的是ENTREZID编号所以用“ENTREZID”
- ont参数——指定输出的通路类型,前面也说了GO富集分析会从bp,cc,mf三个层次描述基因的功能,这里用ALL就会直接包括这三个部分,当然也可以只指定一种类型。
- pvalueCutoff 参数——设定p值阈值
- qvalueCutoff 参数——设定q值阈值(这个q值就是矫正后的p值)
- readable参数——当readable设置为TRUE时,函数的输出会以一种更易于阅读和理解的方式呈现
(enrichGO函数中比较关注的参数就是上述的这些,当然还有其他参数,如果想深入了解可自行查看官方说明文档)
GO <- enrichGO(gene = gene$ENTREZID, # 导入基因的ENTREZID编号OrgDb = GO_database, # 用到的数据库(人类是:org.Hs.eg.db)keyType = "ENTREZID", # 设定读取的gene ID类型ont = "ALL", # (ont为ALL因此包括 Biological Process,Cellular Component,Mollecular Function三部分)pvalueCutoff = 0.5, # 设定p值阈值qvalueCutoff = 0.5, # 设定q值阈值readable = T)
go_res <- data.frame(GO) # 将GO结果转为数据框
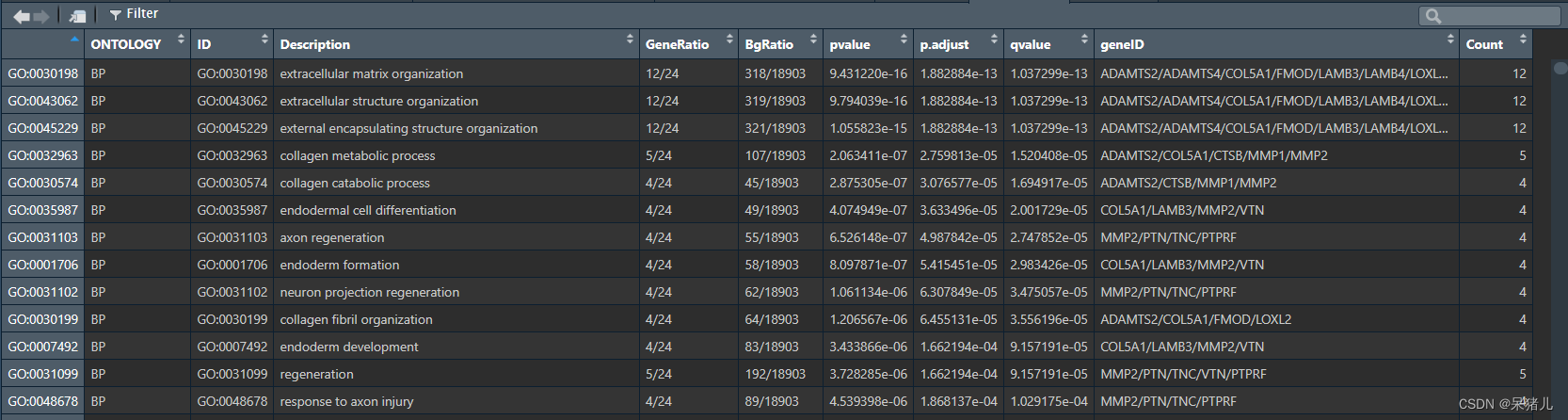
go_res 如下图所示:
- ONTOLOGY——指示该通路属于哪个类别,即生物过程(Biological Process, BP)、分子功能(Molecular Function, MF)还是细胞组分(Cellular Component, CC)
- ID——这是GO通路的唯一标识符,用于在GO数据库中唯一地标识一个通路(可以理解成身份证)
- Description——对通路的简单描述,通常通过这一列就得知该通路具有哪些功能
- GeneRatio——是富集到该通路上的基因数量与所有输入到富集分析中的基因数量的比值。它反映了在特定基因集合中,与该通路相关的基因所占的比例。
- BgRatio——是在整个背景数据集(通常是整个基因组或某个参考数据集)中,与该通路相关的基因数量与背景数据集中所有基因数量的比值。它反映了在整个基因组中,与该通路相关的基因所占的比例。
- pvalue,p.adjust,qvalue——都是GO富集结果的显著性pvalue是常规p值,另外两个是调整后的p值,通常只需要pvalue < 0.05即可。
- geneID——是富集到该通路上的基因名
- Count——是富集到该通路上的基因数目
给go_res 添加新的一列——richFactor
- RichFactor——是一个重要的指标,用于衡量差异表达的转录本中位于特定通路的转录本数目与所有有注释转录本中位于该通路的转录本总数的比值。
简单说:RichFactor越大,表示富集的程度越大,其评价富集的效果要比单纯的GeneRatio或Count要好
go_res <- mutate(go_res, richFactor = Count / as.numeric(sub("/\\d+", "", BgRatio)))
最后筛选p值显著的通路,并保存结果
go_res <- go_res[go_res$pvalue<0.05, ]write.csv(go_res, file = "./GO_res.csv")
3. KEGG富集分析(Rstudio)
分析与GO类似,这里同样是从头开始展示
本项目以 ADAMTS2, ADAMTS4, AGRN, COL5A1, CTSB, FMOD, LAMB3, LAMB4, LOXL2, MATN1, MEP1A, MMP1, MMP2, NTN1, PTN, SPARCL1, SPON1, TGFBI, THBS4, TNC, VTN, ITGB6, PTPRF, UNC5A 为例展示GO富集分析过程
物种:人类(Homo sapiens)
R版本:4.2.2
R包:tidyverse,clusterProfiler,org.Hs.eg.db
设置工作空间:
rm(list = ls()) # 删除工作空间中所有的对象
setwd('/XX/XX/XX') # 设置工作路径
if(!dir.exists('./02_GO+KEGG_enrichment')){dir.create('./02_GO+KEGG_enrichment')
} # 判断该工作路径下是否存在名为02_GO+KEGG_enrichment的文件夹,如果不存在则创建,如果存在则pass
setwd('./02_GO+KEGG_enrichment/') # 设置路径到刚才新建的02_GO+KEGG_enrichment下
加载包:
library(clusterProfiler)
library(org.Hs.eg.db)
library(tidyverse)
导入要富集分析的基因
gene <- c('ADAMTS2', 'ADAMTS4', 'AGRN', 'COL5A1', 'CTSB', 'FMOD', 'LAMB3', 'LAMB4', 'LOXL2',
'MATN1', 'MEP1A', 'MMP1', 'MMP2', 'NTN1', 'PTN', 'SPARCL1', 'SPON1', 'TGFBI', 'THBS4', 'TNC',
'VTN', 'ITGB6', 'PTPRF', 'UNC5A')
设置数据库(注意:这里和前面区别就在于要指定KEGG数据库,即hsa(人种))
GO_database <- 'org.Hs.eg.db' # GO是org.Hs.eg.db数据库
KEGG_database <- 'hsa' # KEGG是hsa数据库
同样是gene ID转换
gene <- bitr(gene, fromType = 'SYMBOL', toType = 'ENTREZID', OrgDb = GO_database)
gene 如下图所示,第一列就是基因名(symbol),而第二列就是官方的ENTREZID编号
接下来就是KEGG富集分析,enrichGO函数常用参数介绍如下
- gene参数——是要输入的基因(一般用基因的ENTREZID编号)
- keyType参数——指定了基因ID的类型,用于匹配KEGG数据库中的条目
- organism参数——指定了进行富集分析的目标物种的KEGG数据库,由于基因用的是人类的,所以前面设置的“hsa”。
- pAdjustMethod参数——指定了用于调整p值的统计方法,以控制假阳性率
- pvalueCutoff 参数——设定p值阈值
- qvalueCutoff 参数——设定q值阈值(这个q值就是矫正后的p值)
KEGG <- enrichKEGG(gene = gene$ENTREZID,keyType = "kegg",organism = KEGG_database,pAdjustMethod = "BH",pvalueCutoff = 0.5,qvalueCutoff = 0.5)
KEGG 如下图所示,是一个列表,里面在这里比较重要的是gene那里,可以看到那里不是常规的基因名,因此不能直接将KEGG的结果转换成数据框,多了一个基因ID转换的过程。
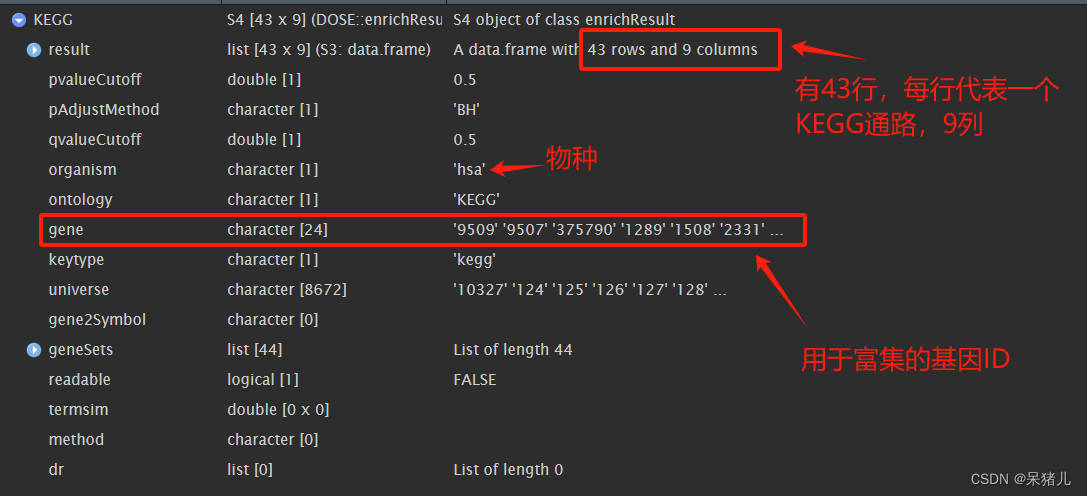
将KEGG结果中基因ID转成基因名,之后将KEGG结果转成数据框
kegg_res <- setReadable(KEGG, OrgDb = org.Hs.eg.db, keyType="ENTREZID")
kegg_res <- data.frame(kegg_res)
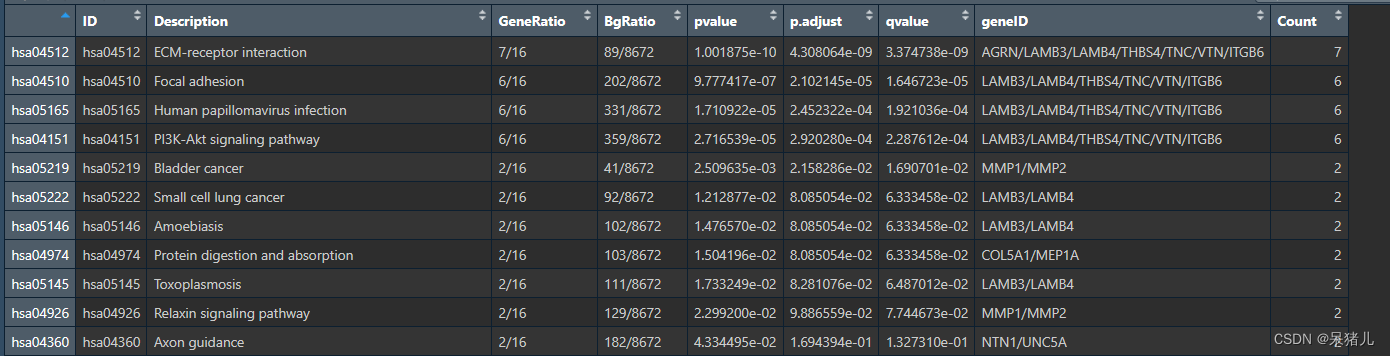
kegg_res 结果如下图所示:
- ID——这是KEGG通路的唯一标识符,用于在KEGG数据库中唯一地标识一个通路(可以理解成身份证)
- Description——对通路的简单描述,通常通过这一列就得知该通路具有哪些功能
- GeneRatio——是富集到该通路上的基因数量与所有输入到富集分析中的基因数量的比值。它反映了在特定基因集合中,与该通路相关的基因所占的比例。
- BgRatio——是在整个背景数据集(通常是整个基因组或某个参考数据集)中,与该通路相关的基因数量与背景数据集中所有基因数量的比值。它反映了在整个基因组中,与该通路相关的基因所占的比例。
- pvalue,p.adjust,qvalue——都是GO富集结果的显著性pvalue是常规p值,另外两个是调整后的p值,通常只需要pvalue < 0.05即可。
- geneID——是富集到该通路上的基因名
- Count——是富集到该通路上的基因数目
同样给kegg_res 添加新的一列——richFactor
kegg_res <- mutate(kegg_res , richFactor = Count / as.numeric(sub("/\\d+", "", BgRatio)))
最后筛选p值显著的通路,并保存结果
kegg_res <- kegg_res [kegg_res $pvalue<0.05, ]write.csv(kegg_res , file = "./KEGG_res.csv")
结语:
以上就是GO+KEGG富集分析的所有过程,如果有什么需要补充或不懂的地方,大家可以私聊我或者在下方评论。
如果觉得本教程对你有所帮助,点赞关注不迷路!!!
- 目录部分跳转链接:零基础入门生信数据分析——导读
相关文章:
生信数据分析——GO+KEGG富集分析
生信数据分析——GOKEGG富集分析 目录 生信数据分析——GOKEGG富集分析1. 富集分析基础知识2. GO富集分析(Rstudio)3. KEGG富集分析(Rstudio) 1. 富集分析基础知识 1.1 为什么要做功能富集分析? 转录组学数据得到的基…...

微服务(基础篇-007-RabbitMQ)
目录 初识MQ(1) 同步通讯(1.1) 异步通讯(1.2) MQ常见框架(1.3) RabbitMQ快速入门(2) RabbitMQ概述和安装(2.1) 常见消息模型(2.2) 快速入门ÿ…...

汇总:五个开源的Three.js项目
Three.js 是一个基于 WebGL 的 JavaScript 库,它提供了一套易于使用的 API 用来在浏览器中创建和显示 3D 图形。通过抽象和简化 WebGL 的复杂性,Three.js 使开发者无需深入了解 WebGL 的详细技术就能够轻松构建和渲染3D场景、模型、动画、粒子系统等。 T…...

JavaScript(一)---【js的两种导入方式、全局作用域、函数作用域、块作用域】
一.JavaScript介绍 1.1什么是JavaScript JavaScript简称“js”,js与java没有任何关系。 js是一种“轻量级、解释型、面向对象的脚本语言”。 二.JavaScript的两种导入方式 2.1内联式 在HTML文档中使用<script>标签直接引用。 <script>console.log…...

部署云原生边缘计算平台kubeedge
文章目录 1、kubeedge架构2、基础服务提供 负载均衡器 metallb2.1、开启ipvc模式中的strictARP2.2、部署metalb2.2.1、创建IP地址池2.2.2、开启二层转发,实现在k8s集群节点外访问2.2.3、测试 3、部署cloudcore3.1、部署cloudcore3.2、修改cloudcore的网络类型 4、部…...

Java设计模式:单例模式详解
设计模式:单例详解 文章目录 设计模式:单例详解一、单例模式的原理二、单例模式的实现推荐1、饿汉模式2、静态内部类 三、单例模式的案例四、单例模式的使用场景推荐总结 一、单例模式的原理 单例模式听起来很高大上,但其实它的核心思想很简…...

Qt5.14.2 定时器黑魔法,一键唤醒延时任务
在图形界面程序的世界里,有这么一个需求无处不在:在特定的时间间隔后,执行一段特殊的代码。比如说30秒后自动保存文档、500毫秒后更新UI界面等等。作为资深Qt程序员,我相信各位一定也曾为实现这种"延时任务"而绞尽脑汁。今天&#…...

C++项目——集群聊天服务器项目(九)客户端异常退出业务
服务器端应检测到客户端是否异常退出,因此本节来实现客户端异常退出,项目流程见后文 一、客户端异常退出业务流程 (1)在业务模块定义处理客户端异常退出的函数 (2)集群聊天服务器项目(八)提到…...

STM32CubeIDE基础学习-HC05蓝牙模块和手机通信
STM32CubeIDE基础学习-HC05蓝牙模块和手机通信 文章目录 STM32CubeIDE基础学习-HC05蓝牙模块和手机通信前言第1章 硬件连接第2章 工程配置第3章 代码编写3.1 手机指令控制LED 第4章 实验现象总结 前言 前面的文章学习了串口通过轮询和中断的简单使用方法,现在就来用…...
npm mongoose包下载冲突解决之道
我在新电脑下载完项目代码后,运行 npm install --registryhttps://registry.npm.taobao.org 1运行就报错: npm ERR! code ERESOLVE npm ERR! ERESOLVE unable to resolve dependency tree npm ERR! npm ERR! While resolving: lowcode-form-backend1.0.0 npm …...
26. UE5 RPG同步面板属性(二)
在上一篇,我们解析了UI属性面板的实现步骤: 首先我们需要通过c去实现创建GameplayTag,这样可以在c和UE里同时获取到Tag创建一个DataAsset类,用于设置tag对应的属性和显示内容创建AttributeMenuWidgetController实现对应逻辑 并且…...

五、postman基础使用案例
postman基础使用 相关案例【传递查询参数】【提交表单数据】【提交JSON数据】 注:postman⼀款⽀持调试和测试的⼯具,开发、测试⼯程师都可以使⽤。方法一般统一为:方法→请求头→请求体→断言 相关案例 【传递查询参数】 访问TPshop搜索商品的…...
Git合并利器:Vimdiff使用指南
使用 vimdiff 作为 Git 的合并工具确实可能会让新手感到困惑,但它是一个功能强大的工具,一旦掌握了它,就可以非常高效地进行代码合并和比较。以下是一个简短的教程,旨在帮助理解 vimdiff 的基本用法以及如何利用它来进行 Git 合并…...
阿里云2核4G服务器租用价格_30元3个月_165元一年_199元
阿里云2核4G服务器租用优惠价格,轻量2核4G服务器165元一年、u1服务器2核4G5M带宽199元一年、云服务器e实例30元3个月,活动链接 aliyunfuwuqi.com/go/aliyun 活动链接如下图: 阿里云2核4G服务器优惠价格 轻量应用服务器2核2G4M带宽、60GB高效…...
<QT基础(2)>QScrollArea使用笔记
项目需要设置单个检查的序列图像预览窗口,采用QScrollArea中加入QWidget窗口,每个窗口里面用Qlabel实现图像预览。 过程涉及两部分内容 引入QWidget 引入label插入图像(resize) 引入布局 组织 scrollArea内部自带Qwidget&#…...
springboot企业级抽奖项目业务四 (缓存预热)
缓存预热 为什么要做预热: 当活动真正开始时,需要超高的并发访问活动相关信息 必须把必要的数据提前加载进redis 预热的策略: 在msg中写一个定时任务 每分钟扫描一遍card_game表 把(开始时间 > 当前时间)&& (开始时间 < 当前时间1分钟)的活动及相…...
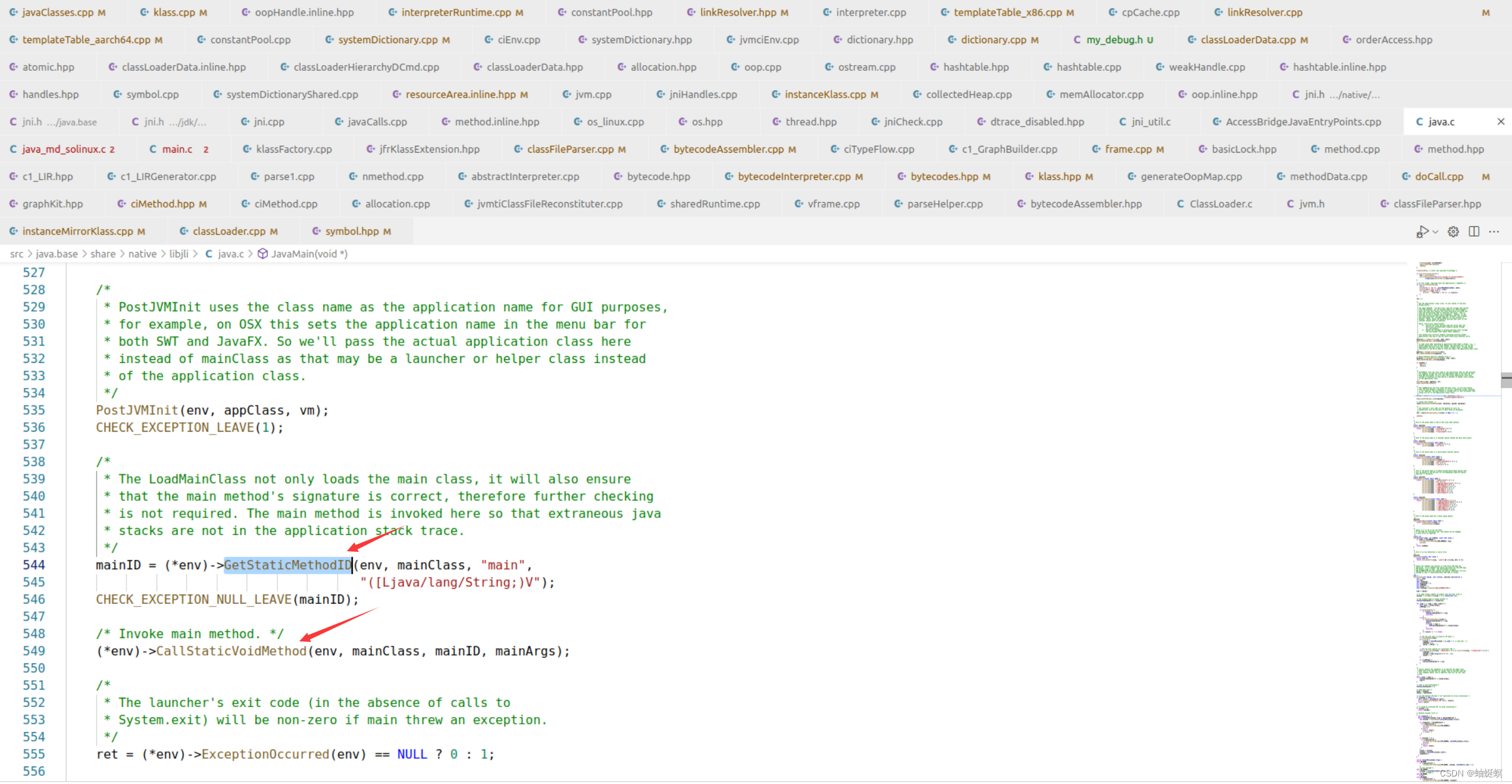
opejdk11 java 启动流程 java main方法怎么被jvm执行
java启动过程 java main方法怎么被jvm执行 java main方法是怎么被jvm调用的 1、jvm main入口 2、执行JLI_Launch方法 3、执行JVMInit方法 4、执行ContinueInNewThread方法 5、执行CallJavaMainInNewThread方法 6、创建线程执行ThreadJavaMain方法 7、执行ThreadJavaMain方法…...
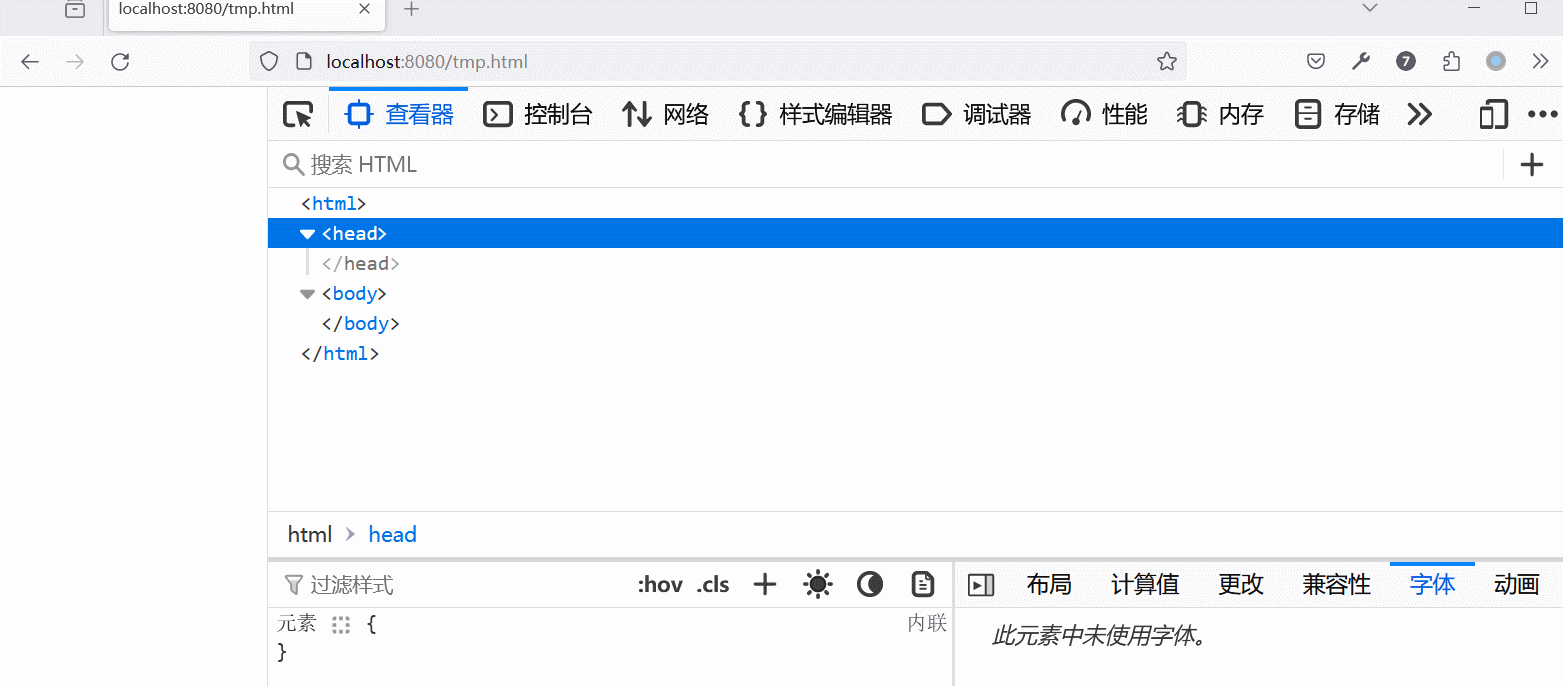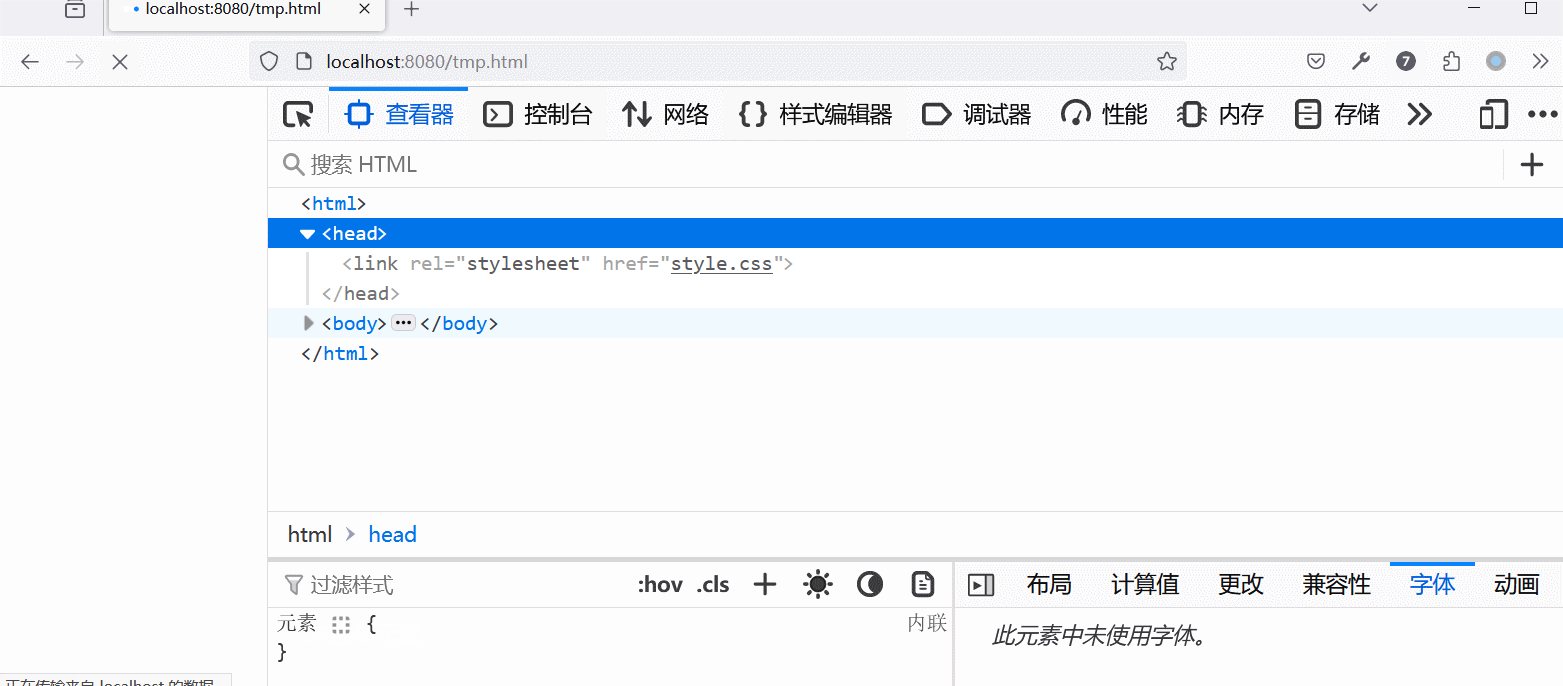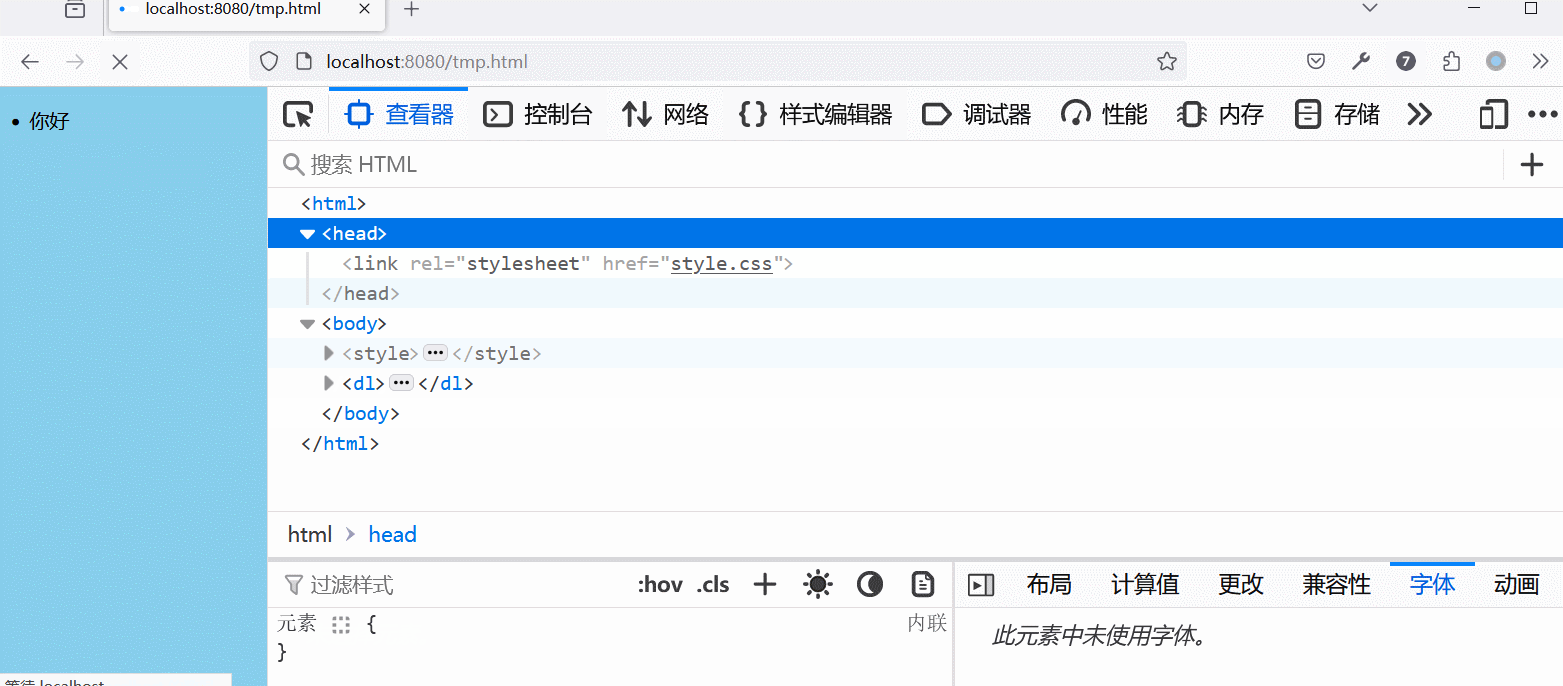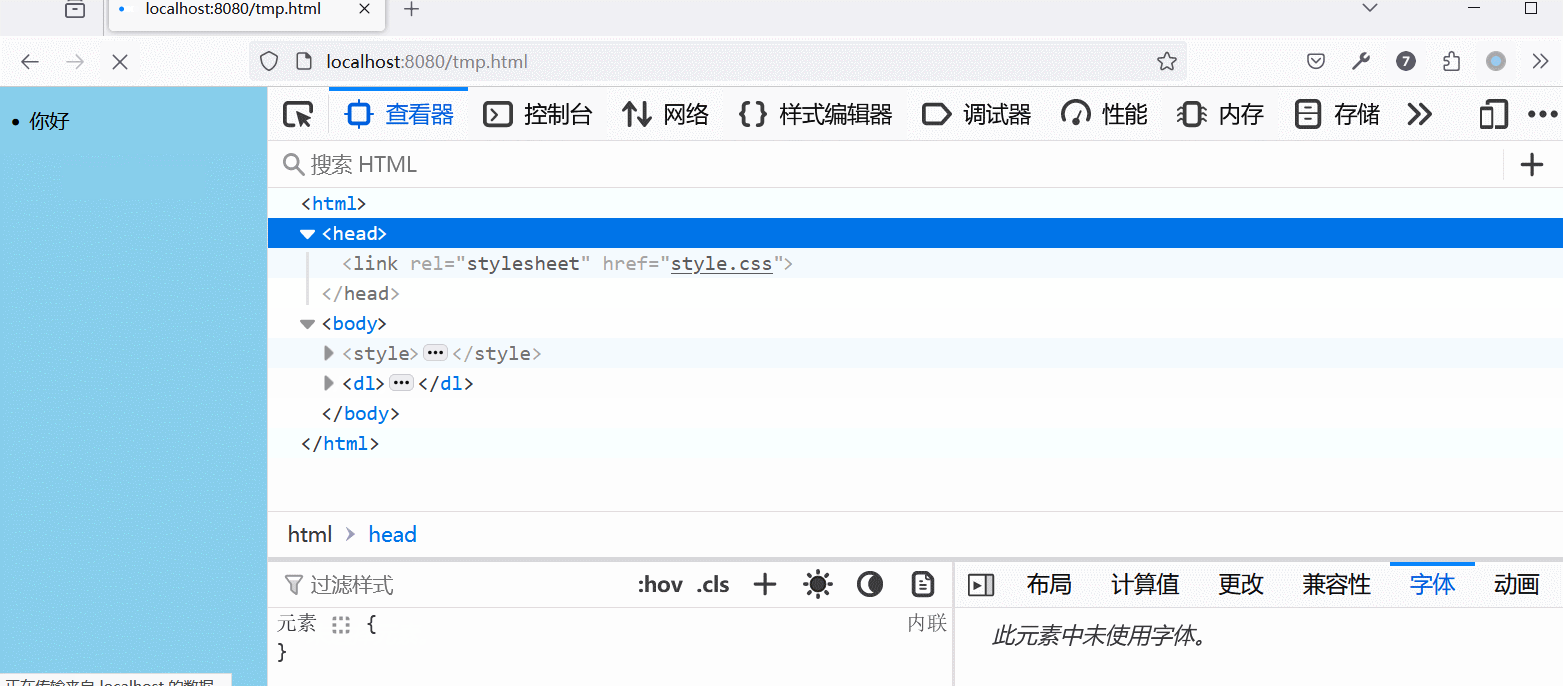
link 样式表是否会阻塞页面内容的展示?取决于浏览器,edge 和 chrome 会,但 firefox 不会。
经过实测: 在 head 中 link 一个 1M 大小的样式表。设置网络下载时间大概为 10 秒。 edge 和 chrome 只有在下载完样式表后,页面上才会出现内容。而 firefox 可以直接先显示内容,然后等待样式表下载完成后再应用样式。 DOMContentLoaded 事…...
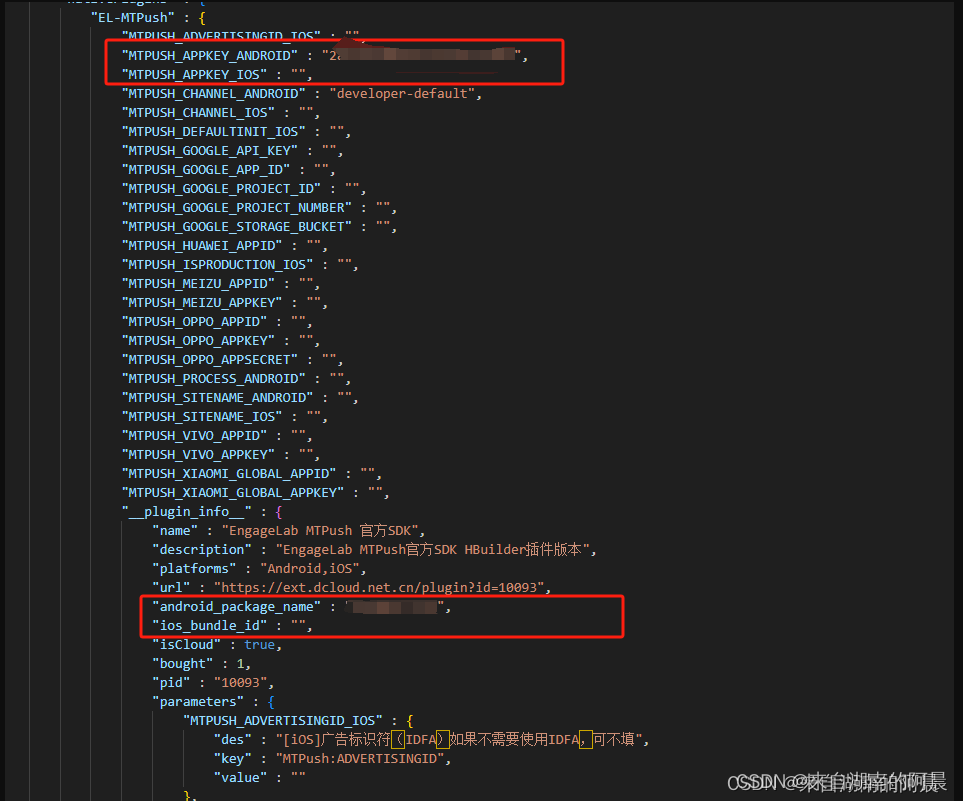
uniapp对接极光推送(国内版以及海外版)
勾选push,但不要勾选unipush 国内版 网址:极光推送-快速集成消息推送功能,提升APP运营效率 (jiguang.cn) 进入后台,并选择对应应用开始配置 配置安卓包名 以及ios推送证书,是否将生产证书用于开发环境选择是 ios推送证书…...

智慧城市数字孪生,综合治理一屏统览
现代城市作为一个复杂系统,牵一发而动全身,城市化进程中产生新的矛盾和社会问题都会影响整个城市系统的正常运转。智慧城市是应对这些问题的策略之一。城市工作要树立系统思维,从构成城市诸多要素、结构、功能等方面入手,系统推进…...

突破内容采集瓶颈:XHS-Downloader的5大行业解决方案与效率提升指南
突破内容采集瓶颈:XHS-Downloader的5大行业解决方案与效率提升指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、…...

Boomer:轻量高效的Linux屏幕放大镜工具
Boomer:轻量高效的Linux屏幕放大镜工具 【免费下载链接】boomer Zoomer application for Linux 项目地址: https://gitcode.com/gh_mirrors/boo/boomer 当你需要精准查看屏幕细节时是否常感到操作繁琐?无论是设计工作中的像素级调整、编程时的代码…...

用Python+Pandas搞定校园单车数据清洗:从‘200+’到精准分布表的保姆级教程
用PythonPandas搞定校园单车数据清洗:从‘200’到精准分布表的保姆级教程 校园单车数据清洗是数据分析实战中的经典场景。想象一下这样的情境:你拿到一份包含15个停车点、7个时间段的校园单车统计表,却发现数据里混杂着"200"这样的…...

本日我的《宅男神探》为当当电子书【玄幻/惊悚】榜第六名
本日我的《宅男神探》为当当电子书【玄幻/惊悚】榜第六名! 地址http://e.dangdang.com/products/1901322470.html 杨赞是一名热爱推理的年轻人,平时喜欢用逻辑思维分析生活中的各类 问题。大学毕业后,他在母校附近开了一家小书店࿰…...

Synopsys AXI VIP实战:如何用reorder和delay配置模拟真实SoC总线行为
Synopsys AXI VIP实战:用reorder与delay构建高保真SoC总线模拟环境 在SoC验证领域,AXI总线协议的复杂性常常成为验证工程师面临的主要挑战。当CPU通过Cache访问低速外设时,总线上的竞争、延迟和乱序响应会形成难以预测的行为模式。Synopsys A…...

小白也能懂:将SPIRAN ART SUMMONER图像生成API封装成IDEA插件
小白也能懂:将SPIRAN ART SUMMONER图像生成API封装成IDEA插件 1. 为什么需要这个插件? 作为一名开发者,我经常遇到这样的场景:正在编写游戏角色设定文档时,突然需要一张概念图;设计UI界面时,想…...

Windows上Rust报错找不到link.exe?别急着装VS,试试这几种更轻量的解决方案
Windows上Rust报错找不到link.exe?别急着装VS,试试这几种更轻量的解决方案 刚接触Rust的Windows开发者经常会遇到一个经典问题:运行cargo build时出现link.exe not found报错。传统解决方案是安装庞大的Visual Studio,但这对于只…...

Z-Image Turbo用户反馈:实际使用体验总结
Z-Image Turbo用户反馈:实际使用体验总结 本文基于真实用户反馈,全面总结Z-Image Turbo绘图工具的实际使用体验,涵盖性能表现、功能效果、易用性等维度,为潜在用户提供参考。 1. 核心体验概述 Z-Image Turbo是一款基于Gradio和Di…...

LosslessCut:解锁无损视频编辑的5个专业技巧
LosslessCut:解锁无损视频编辑的5个专业技巧 【免费下载链接】lossless-cut The swiss army knife of lossless video/audio editing 项目地址: https://gitcode.com/gh_mirrors/lo/lossless-cut 在数字内容创作领域,视频质量与处理效率往往难以兼…...

CANoe Trace中的Time列:从基础定义到高级时序分析实战
1. CANoe Trace中的Time列基础解析 第一次打开CANoe的Trace窗口时,那排密密麻麻的数据确实让人头皮发麻。但别担心,咱们先来搞定最左边那个看似简单却至关重要的Time列。这个时间戳就像车载网络的"心电图"记录仪,精确到微秒级别地记…...