Flink基于Hudi维表Join缺陷解析及解决方案
Hudi,这个近年来备受瞩目的数据存储解决方案,无疑是大数据领域的一颗耀眼新星。其凭借出色的性能和稳定性,以及对于数据湖场景的深度适配,赢得了众多企业和开发者的青睐。然而,正如任何一项新兴技术,Hudi在生产环境的落地过程中也暴露出了不少问题,亟待我们共同解决。尽管Hudi在数据处理速度、数据一致性以及查询效率等方面表现优异,但在实际应用中,其稳定性和可靠性仍面临挑战。在生产环境中,数据规模庞大且变化频繁,Hudi需要能够稳定地处理各种复杂场景,但目前来看,其在高并发、大数据量下的表现并不尽如人意。此外,Hudi的生态系统还不够完善,与其他大数据组件的集成度有待提高,这也给生产环境的部署和维护带来了不便。除了技术层面的问题,Hudi在生产落地过程中还面临着诸多非技术性的挑战。例如,企业对于新技术的接受程度、团队的技术水平、以及数据治理的规范程度等,都会影响到Hudi的落地效果。此外,由于Hudi相对较新,相关的文档和社区支持还不够完善,这也增加了企业在使用过程中的学习成本和风险。
本文针对Hudi在生产上常见的SQL Join场景下的衍生问题进行讨论,详见下文。
一 FlinkSQL基于Hudi维表Join场景缺陷问题分析
下面是示例代码,这段代码存在数据质量问题:
-- Hudi订单事实表
create table hudi.dwd_ord_order_info_dd(order_id bigint,product_id bigint,order_amount double,order_time timestamp(3),dt string
) partitioned by(dt)
with ('connector'='hudi','path' ='hdfs://hadoop:8020/dw/dwd_ord_order_info_dd','table.type'='MERGE_ON_READ','hoodie.datasource.write.recordkey.field' = 'order_id','hoodie.datasource.write.precombine.field' = 'order_time',......
);
-- Hudi产品维表
create table hudi.dim_product(product_id bigint,product_name string,category string,create_time timestamp(3),dt string
) partitioned by(dt)
with ('connector'='hudi','path' ='hdfs://hadoop:8020/dw/dim_product','table.type'='MERGE_ON_READ','hoodie.datasource.write.recordkey.field' = 'product_id','hoodie.datasource.write.precombine.field' = 'create_time',......
);
insert into hudi.dwd_ord_order_info_dd select ...;
insert into hudi.dim_product select ...;
-- 维表Join SQL示例(以下SQL会存在数据质量问题)
set table.exec.state.ttl = 8192s;
insert into hudi.dws_ord_order_info_dd
select *
from hudi.dwd_ord_order_info_dd t1
left join hudi.dim_product t2 on t1.product_id = t2.product_id
;上边示例中的sql表示实时订单数据流(hudi.dwd_ord_order_info_dd)关联商品维表的功能,用来补全宽表商品属性(hudi.dim_product)数据。这段SQL在实际生产环境中执行会出现数据丢失的问题,从而导致数据质量不合格。那么问题出现在哪里呢?
-
维表数据只能保存TTL时间范围内变更数据记录有效,而订单流产生交易的商品很可能是去年上架销售商品,在商品state中已经没有该商品记录信息,从而导致关联商品信息失效;
-
如果不设置TTL,那么订单流和商品流都要保存启动全量历史数据状态,这么大的状态对于内存压力巨大,如果商品维表巨大,且周期较长,那么商品维表也无法保留全部历史数据;
这里问题主要原因是订单数据事件时间和对应商品事件时间差异比较大导致的问题。
二 FlinkSQL基于Hudi维表Join场景缺陷解决方案
在章节1中我们分析了代码可能存在的问题原因,那么怎么解决呢?对于FlinkSQL来说,关联维表最好的方式是通过Lookup Join方式关联外部最新维度数据。
1 方案一
针对商品表在hbase创建商品维表,同时装载历史数据,然后通过流写入hudi维表外同时写入Hbase一份数据。伪代码如下:
为什么要创建hbase维表?
hudi表的数据文件从hdfs上看也是普通的parquet或者log格式,这种格式存储数据本质上来说对于批量分析比较友好,但对于向单行数据的快速扫描性能比较低。这一点是由存储结构造成的。
hbase表结构对于单行rowkey访问友好,但对于批处理不友好;
基于上面两点,我们只能选择在存储层通过存储两份不同格式的数据来解决批处理和单行访问之间差异的问题。
-- Hudi订单事实表
create table hudi.dwd_ord_order_info_dd(order_id bigint,product_id bigint,order_amount double,order_time timestamp(3),dt string
) partitioned by(dt)
with ('connector'='hudi','path' ='hdfs://hadoop:8020/dw/dwd_ord_order_info_dd','table.type'='MERGE_ON_READ','hoodie.datasource.write.recordkey.field' = 'order_id','hoodie.datasource.write.precombine.field' = 'order_time',......
);
-- Hudi产品维表
create table hudi.dim_product(product_id bigint,product_name string,category string,create_time timestamp(3),dt string
) partitioned by(dt)
with ('connector'='hudi','path' ='hdfs://hadoop:8020/dw/dim_product','table.type'='MERGE_ON_READ','hoodie.datasource.write.recordkey.field' = 'product_id','hoodie.datasource.write.precombine.field' = 'create_time',......
);
-- Hbase产品维表
create table hbase.dim_product(product_id bigint,product_name string,category string,create_time string,dt string
) partitioned by(dt)
with ('connector'='hbase',......
);
insert into hudi.dwd_ord_order_info_dd select ...;
create view tmp_product as ...;
insert into hudi.dim_product select * from tmp_product;
insert into hbase.dim_product select * from tmp_product;
set table.exec.state.ttl = 8192s;
insert into hudi.dws_ord_order_info_dd
select *
from hudi.dwd_ord_order_info_dd t1
left join hudi.dim_product t2 on t1.product_id = t2.product_id
left join hbase.dim_product for system_time as of t1.order_time t3 on t1.product_id = t3.product_id
;通过订单流数据同时关联hudi.dim_product和以Lookup Join方式关联相同的hbase.dim_product表方式可以解决维度延迟和历史数据关联问题,很好解决由于维度数据状态不全导致数据质量问题。
这种方式有以下两个缺点:
-
存储层面: 维表数据要存储两份数据(hudi本身存储一份全量数据,hbase也需要存储一份全量数据)。
-
ETL层面: ETL代码要多维护一份维度数据写入hbase的关系,对于代码整洁不友好。
2 方案二
这个方案侧重于在存储层解决SQL Join问题,但有个前提,不同子SQL都需要有相同的主键设置才可用,同样,这种方案也涉及源码改造,主要技术点在于Hudi payload的源码改造,具体的实现这里不介绍。
3 方案三
三 总结
在生产上遇到这种SQL 维表Join场景问题,可以采用方案一进行处理,如果团队技术比较强大,那么可以考虑方案二落地,方案三非技术大牛坐镇,不建议改造。这里对方案二三不做详细介绍,待后续更新,敬请关注。
相关文章:

Flink基于Hudi维表Join缺陷解析及解决方案
Hudi,这个近年来备受瞩目的数据存储解决方案,无疑是大数据领域的一颗耀眼新星。其凭借出色的性能和稳定性,以及对于数据湖场景的深度适配,赢得了众多企业和开发者的青睐。然而,正如任何一项新兴技术,Hudi在…...

3.31学习总结
(本次学习总结,总结了目前学习java遇到的一些关键字和零碎知识点) 一.static关键字 static可以用来修饰类的成员方法、类的成员变量、类中的内部类(以及用static修饰的内部类中的变量、方法、内部类),另外可以编写static代码块来优化程序性…...
Android Studio控制台输出中文乱码问题
控制台乱码现象 安卓在调试阶段,需要查看app运行时的输出信息、出错提示信息。 乱码,会极大的阻碍开发者前进的信心,不能及时的根据提示信息定位问题,因此我们需要查看没有乱码的打印信息。 解决步骤: step1: 找到st…...
itextPdf生成pdf简单示例
文章环境 jdk1.8,springboot2.6.13 POM依赖 <dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.5.13</version></dependency><dependency><groupId>com.ite…...

【Linux系列】tree和find命令
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

AI预测福彩3D第23弹【2024年4月1日预测--第4套算法重新开始计算第9次测试】
今天继续对第4套算法进行测试,因为第4套算法已连续多期命中,相对来说还算稳定。好了,废话不多说了,直接上预测的结果吧~ 2024年4月1日福彩3D的七码预测结果如下 第一套: 百位:0 1 …...
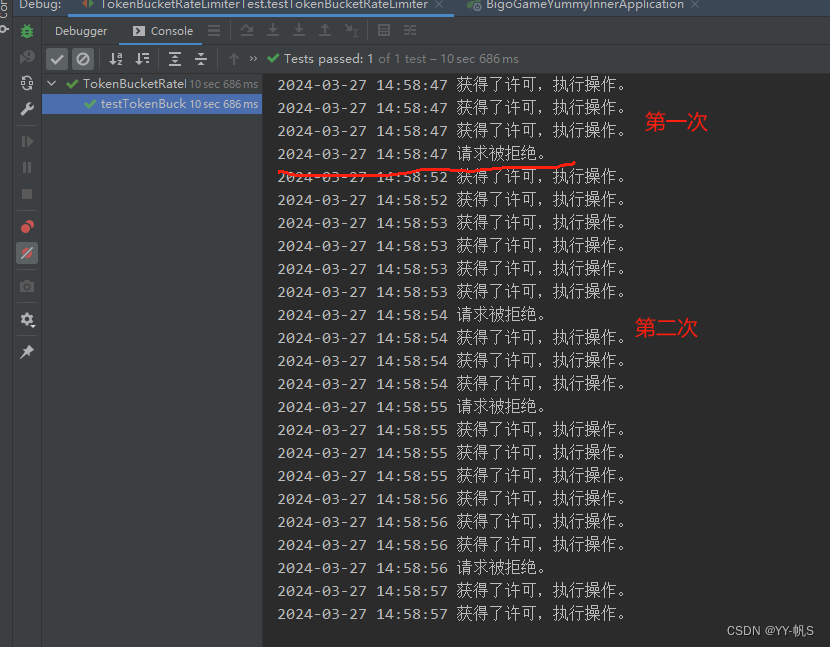
Java常见限流用法介绍和实现
目录 一、现象 二、工具 1、AtomicInteger,AtomicLong 原子类操作 2、RedisLua 3、Google Guava的RateLimiter 1) 使用 2) Demo 3) 优化demo 4、阿里开源的Sentinel 三、算法 1、计数限流 &…...
)
算法——图论:判断二分图(染色问题)
题目:. - 力扣(LeetCode) 方法一:并查集 class Solution { public:vector<int>father;int find(int x){if (father[x] ! x)father[x] find(father[x]);return father[x];}void add(int x1, int x2){int fa1 find(x1), f…...

三步提升IEDA下载速度——修改IDEA中镜像地址
找到IDEA的本地安装地址 D:\tool\IntelliJ IDEA 2022.2.4\plugins\maven\lib\maven3\conf 搜索阿里云maven仓库 复制https://developer.aliyun.com/mvn/guide中红框部分代码 这里也是一样的: <mirror><id>aliyunmaven</id><mirrorOf>*&…...

CentOS7 RPM升级支持BBR TCP/CC的内核版本
列出安装的内核 rpm -qa kernel # yum list installed kernel 删除已安装内核 sudo dnf remove kernel-4.0.4-301.fc22.x86_64 安装内核 rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noar…...

文本向量模型BGE与BGE-M3
BGE模型 BGE模型对应的技术报告为《C-Pack: Packaged Resources To Advance General Chinese Embedding》 训练数据 为了训练BGE向量模型,构建了C-MTP数据集,它包括了用来训练文本向量的文本对数据(问答对、两个同义句子、相同主题的两个文…...
【黑马头条】-day04自媒体文章审核-阿里云接口-敏感词分析DFA-图像识别OCR-异步调用MQ
文章目录 day4学习内容自媒体文章自动审核今日内容 1 自媒体文章自动审核1.1 审核流程1.2 内容安全第三方接口1.3 引入阿里云内容安全接口1.3.1 添加依赖1.3.2 导入aliyun模块1.3.3 注入Bean测试 2 app端文章保存接口2.1 表结构说明2.2 分布式id2.2.1 分布式id-技术选型2.2.2 雪…...
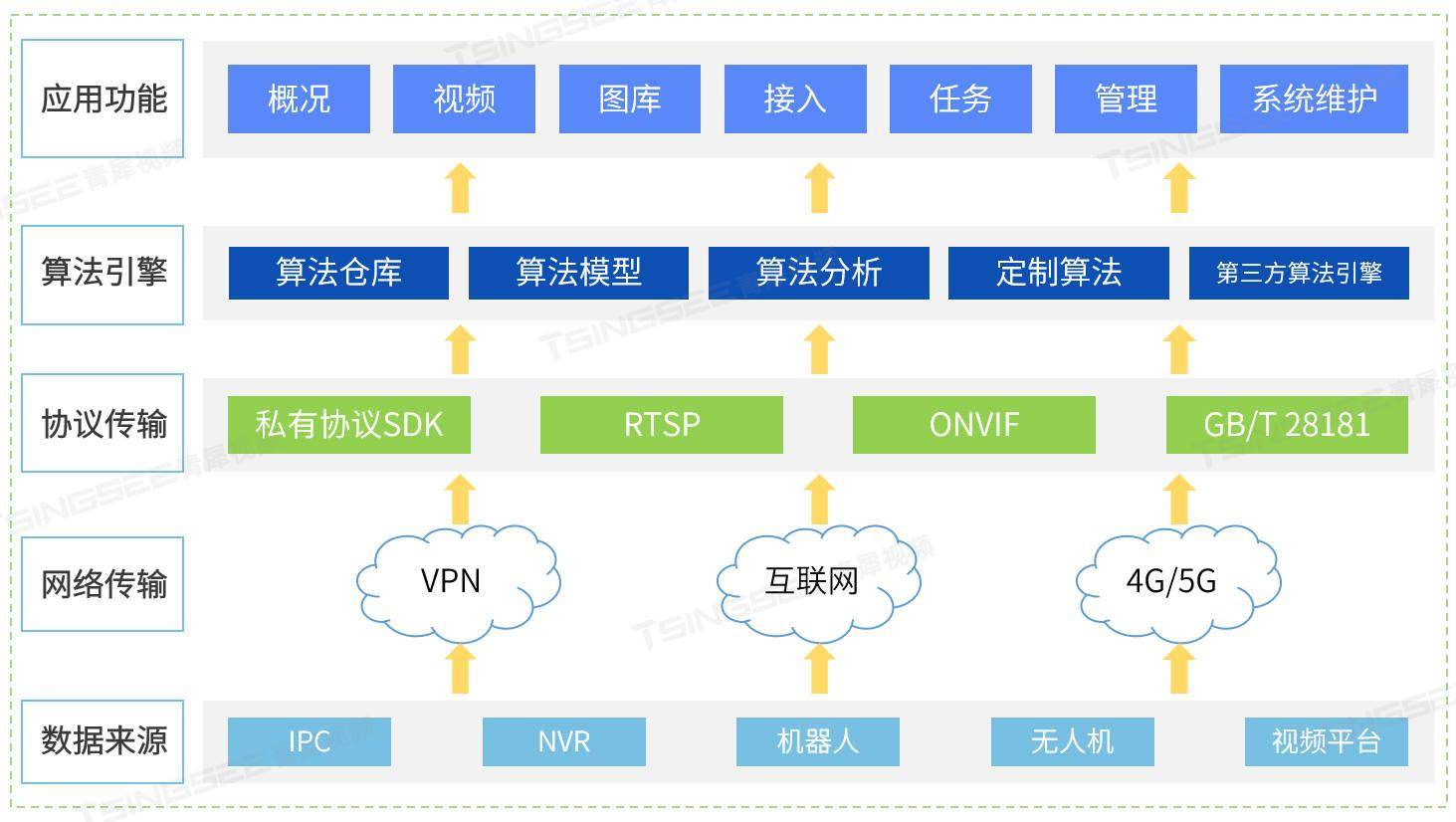
新能源充电桩站场AI视频智能分析烟火检测方案及技术特点分析
新能源汽车充电起火的原因多种多样,涉及技术、设备、操作等多个方面。从技术层面来看,新能源汽车的电池管理系统可能存在缺陷,导致电池在充电过程中出现过热、短路等问题,从而引发火灾。在设备方面,充电桩的设计和生产…...

springboot集成logback-spring.xml文件
彩色日志日志分debug和error文件输出,方便开发人员运维日志限制最大保管天数日志限制总量大小占用量GB日志限制单个文件大小MB日志显示最大保留天数屏蔽没用的日志 <?xml version"1.0" encoding"UTF-8"?> <!--~ Copyright (c) 2020…...

centos7 安装 nginx
一、yum 方式安装 1.安装yum工具 sudo yum install yum-utils 2. 安装epel yum install epel-release 3.安装nginx: yum install nginx 4.查看版本 nginx -v 5.设置开机自启动 systemctl enable nginx nginx 常用命令: 1)启动nginx …...

29. UE5 RPG应用GamplayAbility
前面几篇文章,总算把GE给更新完了,GE的基础应用也算讲清楚了。接下来,我们将更新GA的相应的课程了,首先,这一篇先对GA做一个简单的介绍,然后实现一下如何实现给角色应用一个GA。 简介 GamplayAbility 简称…...

http和https的区别!
HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSLHTTP) 数据传输过程是加密的,安全性较好。 使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) …...
使用AOP实现打印日志
首先创建annotation.SystemLog类: package com.gjh.annotation;import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;Target(ElementType.METHOD…...
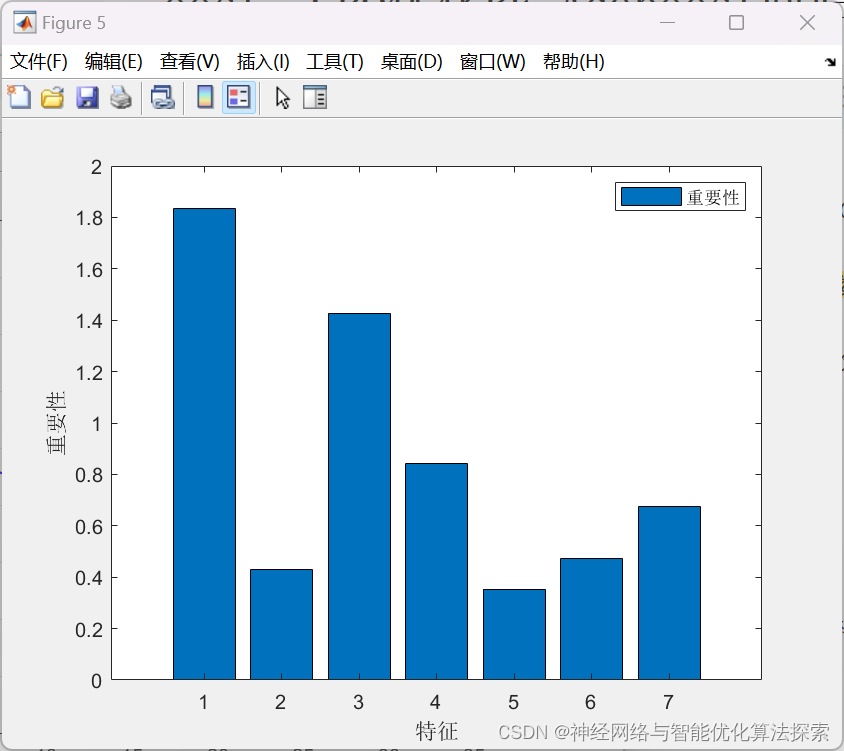
2024年新算法-冠豪猪优化算法(CPO),CPO-RF-Adaboost,CPO优化随机森林RF-Adaboost回归预测-附代码
冠豪猪优化算法(CPO)是一种基于自然界中猪群觅食行为启发的优化算法。该算法模拟了猪群在寻找食物时的集群行为,通过一系列的迭代过程来优化目标函数,以寻找最优解。在这个算法中,猪被分为几个群体,每个群体…...
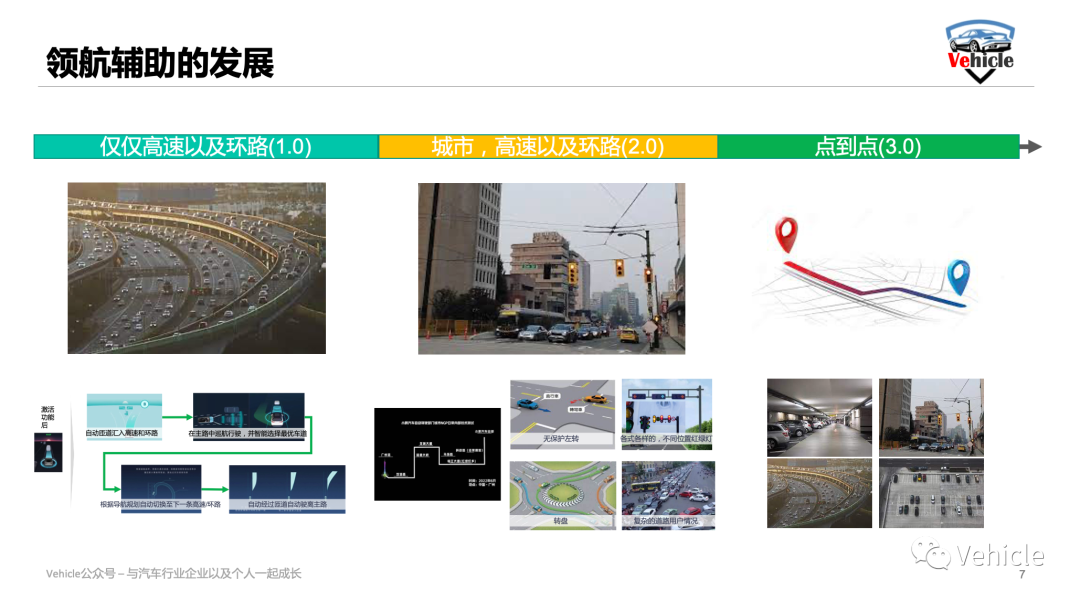
浅谈高阶智能驾驶-NOA领航辅助的技术与发展
浅谈高阶智能驾驶-NOA领航辅助的技术与发展 附赠自动驾驶学习资料和量产经验:链接 2019年在国内首次试驾特斯拉NOA领航辅助驾驶的时候,当时兴奋的觉得未来已来;2020年在试驾蔚来NOP领航辅助驾驶的时候,顿时不敢小看国内新势力了;现在如果哪家…...

Axon:极简AI代理命令行工具,无缝集成自动化工作流
1. 项目概述:一个极简主义的AI代理命令行工具如果你和我一样,对市面上那些动辄需要复杂环境配置、依赖一大堆库、启动缓慢的AI代理工具感到疲惫,那么Axon的出现,绝对会让你眼前一亮。它不是一个运行在后台的守护进程,也…...

Power Automate调用Azure Foundry智能体
Power Automate调用Azure Foundry智能体一、创建Foundry智能体二、发送HTTP请求,调用Foundry智能体三、拓展一、创建Foundry智能体 先从创建开始吧 填好,然后直接审阅并创建就行了。一个资源下可以创建多个项目 转到资源 转到门户 这里有API密钥&…...

PP 蜂窝板挤出成型核心原理与关键设备解析
PP 蜂窝板挤出成型核心原理与关键设备解析一、PP 蜂窝板材料特性与成型难点PP(聚丙烯)蜂窝板兼具质轻、高刚性、耐水防潮、可循环四大优势,在物流、建筑、车厢、包装领域替代传统实心板材趋势明显。 其成型难点集中在:蜂窝芯超薄、…...

032随机链表的复制
随机链表的复制 题目链接:https://leetcode.cn/problems/copy-list-with-random-pointer/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: public Node copyRandomList(Node head) {Node dummy new Node(-1);Node curhead, newCu…...

如何快速掌握LyricsX:macOS终极歌词同步工具完整指南
如何快速掌握LyricsX:macOS终极歌词同步工具完整指南 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的终极歌词应用,能够自动同步音乐…...

Fabric 结合IPFS 链码示例
购买专栏前请认真阅读:《Fabric项目学习笔记》专栏介绍 package mainimport ("bytes""encoding/json""fmt""time""github.com/hyperledger/fabric/core/chaincode/shim"sc "github.com/hyperledger/fabric/protos/pee…...

【电源设计实战】反相BUCK-BOOST:从拓扑原理到PCB布局的完整设计指南
1. 反相BUCK-BOOST拓扑原理深度解析 第一次接触反相BUCK-BOOST电路时,我被它的"负压生成"特性深深吸引。这种拓扑就像电源界的"魔术师",能把正电压巧妙地转换成负电压。在实际项目中,比如为运算放大器供电或驱动某些特殊…...
ImageTrans插件生态:用Python扩展图片OCR与翻译工作流
1. 项目概述:一个为ImageTrans量身定制的插件生态如果你经常需要处理图像中的文字,比如翻译漫画、本地化游戏截图或者处理带文字的UI设计稿,那你很可能听说过或者用过ImageTrans这款工具。它是一款专注于图片文字识别(OCR…...

RAGday13-day15
Day13:RAG 常见问题 & 调优实战检索不到内容原因:分块太小、关键词太偏、没做混合检索解决:换递归 / 父子分块、加上 ES 混合检索、做 Query 改写搜到内容多但答不对原因:检索杂、没重排、没上下文压缩解决:加 Rer…...

Crystal语言Web框架实战:构建高性能API服务的轻量级方案
1. 项目概述:一个轻量级、高性能的Crystal语言Web框架最近在探索一些新兴的编程语言生态时,我注意到了Crystal语言,以及一个名为jvpflum/Crystal的GitHub仓库。乍一看这个标题,可能会让人有些困惑:这究竟是Crystal语言…...