文本向量模型BGE与BGE-M3
BGE模型
BGE模型对应的技术报告为《C-Pack: Packaged Resources To Advance General Chinese Embedding》
训练数据
为了训练BGE向量模型,构建了C-MTP数据集,它包括了用来训练文本向量的文本对数据(问答对、两个同义句子、相同主题的两个文档等),为了保证文章向量的泛化性,数据集需要同时满足大规模和多样性,C-MTP包括两个部分:未标注数据C-MTP (unlabeled)和标注数据C-MTP (labeled)。
- C-MTP (unlabeled):数据主要来源是开放网络语料库如Wudao corpus,对于每一篇文章抽取(title, passage)来构成一个文本对;也按同样的处理方式从知乎、百科等抽取了文本对。除了网络开放语料之外,还从以下公开中文数据集中抽取了文本对:
- CSL (scientific literature)
- Amazon-Review-Zh (reviews)
- Wiki Atomic Edits (paraphrases)
- CMRC (machine reading comprehension)
- XLSUM-Zh (summarization)
直接抽取的文本对可能质量不高,使用Text2VecChinese给文本对打分,只保留分数在0.43上的文本对,数据集最终文本对的大小为100M
- C-MTP (labeled):标注文本对来自以下标注数据集,一共838465条:
- T2-Ranking
- DuReader
- mMARCO
- CMedQA-v2
- multi-cpr
- NLI-Zh3
- cmnli
- ocnli
训练流程
BGE模型基于BERT-like架构,使用最后一层的特殊token [CLS]作为文本向量,有三个不同规模的模型组成:
- large (326M参数)
- base (102M参数)
- small (24M 参数)
BGE的训练分为三个部分:1)预训练,2)通用微调(用C-MTP (unlabeled)进行对比学习),3)任务相关微调(用C-MTP (labeled)进行多任务微调学习)。
-
预训练,使用Wudao语料来训练模型,使用RetroMAE中提出的自动编码方式(MAE-stype)来进行预训练。
-
通用微调,将预训练好的模型在C-MTP (unlabeled)数据集上通过对比学习微调。
- m i n . ∑ ( p , q ) − log e < e p , e q > / τ e < e p , e q > / τ + ∑ Q ′ e < e p , e q ′ > / τ min\ . \sum_{(p,q)} -\log\frac{e^{<e_p, e_q>}/\tau} {e^{<e_p, e_q>/\tau}+\sum_{Q^{\prime}}e^{<e_p, e_{q^{\prime}}>/\tau}} min .∑(p,q)−loge<ep,eq>/τ+∑Q′e<ep,eq′>/τe<ep,eq>/τ,式中p和q是文本对, q ′ ∈ Q ′ q^{\prime} \in Q^{\prime} q′∈Q′是负样本, τ \tau τ是温度。
- 负样本仅使用in-batch negative samples,batch size 高达19200。
- 训练时使用gradient checkpointing 和 cross-device embedding sharing的组合策略来使得batch size可以很大
- 任务相关微调,将前一步训练好的向量模型在C-MTP (labeled)数据集上进一步微调。为了协调不同任务,采用如下两个策略:
- 基于指令的微调,对于每一个文本对(p,q),将一个任务相关的指令 I t I_t It添加到query q上: q ′ ← q + I t q^{\prime} \leftarrow q + I_t q′←q+It,指令是一个用来描述任务的prompt,比如"search relevant passages for the query".
- 对于每一个文本对(p,q),挖掘了一个hard negative sample q ′ q^{\prime} q′,挖掘方法是基于ANN挖掘的。
消融实验表明训练的各个阶段对于模型效果提升都有帮助(w.o.Instruct是在第三阶段训练时不使用指令微调,BGE-i是指经过第二阶段通用微调的模型,BGE-i w.o. pre-train是不使用RetroMAE预训练的模型,BGE-f经过全部训练流程的模型)

也做了实验来说明大batch-size对于模型性能的影响,在大多数任务上大batch size对于embedding模型是有益处的,尤其是检索任务效果提升特别明显。

BGE-M3模型
BGE-M3对应的技术报告为《BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation》
BGE-M3的M3是Multi-Linguality,Multi-Functionality, and Multi-Granularity的简称,也就是模型支持多语言、多种能力(稠密检索、稀疏检索、多向量检索),多粒度(最高支持8192长度的输入文本)。

训练数据
BGE-M3的数据构造分为三个部分:从未标注语料得到的无监督数据、从标注语料得到的微调数据、合成微调数据。
-
无监督数据共1.2 billion文本对,包括了194种语言和2655跨语言对。主要从不同的多语言语料库提取titlebody, title-abstract, instruction-output等,数据来源有:
- 多语言语料库:Wikipedia、S2ORC、xP3、mC4、CC-News
- MTP(BGE模型的数据集)
- 翻译相关数据集:NLLB、CCMatrix
-
从标注语料得到的微调数据,数据来源有:
- 英文包括8个数据集:HotpotQA,TriviaQA,NQ,MS MARCO,COLIEE,PubMedQA, SQuAD, NLI。
- 中文包括7个数据集:DuReader,mMARCO-ZH, T 2 T^2 T2-Ranking, LawGPT,CMedQAv2,NLI-zh,LeCaRDv2。
- 其他语言:MIRACL, Mr.TyDi
-
合成数据(MultiLongDoc),从Wiki和MC4数据集中采样了长文章,并从其中随机选择段落,由GPT-5基于这些段落生成问题。生成的问题和段落组成的文本对最终作为微调数据的一部分。
- GPT 3.5使用的prompt为“You are a curious AI assistant, please generate one specific and valuable question based on the following text. The generated question should revolve around the core content of this text, and avoid using pronouns (e.g., “this”). Note that you should generate only one question, without including additional content:”

BGE-M3混合检索实现
BGE-M3的Multi-Functionality是指实现混合检索,具体如下:
- 稠密检索(Dense retrieval),输入query q经过文本编码器的隐状态层 H q \mathbf{H}_q Hq得到,取"[CLS]"的归一化隐状态作为向量: e q = n o r m ( H q [ 0 ] ) e_q = norm(\mathbf{H}_q[0]) eq=norm(Hq[0]),类似地passage p的向量: e p = n o r m ( H p [ 0 ] ) e_p = norm(\mathbf{H}_p[0]) ep=norm(Hp[0])。 query和passage的相关分数由两个向量 e q e_q eq和 e p e_p ep的内积表示: s d e n s e ← ⟨ e p , e q ⟩ s_{dense} \leftarrow \langle e_p, e_q \rangle sdense←⟨ep,eq⟩。
- 词性检索(Lexical Retrieval),输入query的每一元素term t(即 token),term权重为 w q t ← R e l u ( W l e x T H q [ i ] ) w_{q_t} \leftarrow Relu(\mathbf{W}^T_{lex} \mathbf{H}_q[i]) wqt←Relu(WlexTHq[i]),式中的 W l e x ∈ R d × 1 \mathbf{W}_{lex} \in R^{d \times 1} Wlex∈Rd×1是映射隐状态到浮点数的矩阵(如果一个term t在query中出现多次,只保留其最大值)。按照同样的方式计算passage的term权重。query和passage的相关分数由两者共现项(记作 q ∩ p q \cap p q∩p)计算得到: s l e x ← ∑ t ∈ q ∩ p ( w q t ∗ w p t ) s_{lex} \leftarrow \sum_{t \in q \cap p} (w_{q_t} * w_{p_t}) slex←∑t∈q∩p(wqt∗wpt)。
- 多向量检索(Multi-Vector Retrieval),多向量检索使用query和passage的整个输出向量: E q = n o r m ( W m u l T H q ) E_q = norm(\mathbf{W^T_{mul}} \mathbf{H}_q) Eq=norm(WmulTHq), E p = n o r m ( W m u l T H p ) E_p = norm(\mathbf{W^T_{mul}} \mathbf{H}_p) Ep=norm(WmulTHp),式中的 W m u l ∈ R d × d \mathbf{W}_{mul} \in R^{d \times d} Wmul∈Rd×d是可学习映射矩阵。query和passage的相关分数为: s m u l ← 1 N ∑ i = 1 N m a x j = 1 M E q [ i ] ⋅ E p T [ j ] s_{mul} \leftarrow \frac{1}{N} \sum^N_{i=1} max^M_{j=1} E_q[i] \cdot E^T_p[j] smul←N1∑i=1Nmaxj=1MEq[i]⋅EpT[j], N和M分别是query和passage的长度。
因为向量模型的多功能能力,所以可以实现混合检索过程,首先候选结果由每种方法单独得到(多向量检索成本很高,可考虑省略),然后最后检索结果根据各相关分数之和来排序: s r a n k ← s d e n s e + s l e x + s m u l s_{rank} \leftarrow s_{dense} + s_{lex} + s_{mul} srank←sdense+slex+smul。
Self-Knowledge Distillation
向量模型训练是为了将正样本从负样本中区分开,损失函数为如下式所表示的InfoNCE损失函数,式中 p ∗ p^* p∗和 P ′ P^{\prime} P′是query q对应的正样本及负样本。 s ( ⋅ ) s(\cdot) s(⋅) 是 { s d e n s e ( ⋅ ) , s l e x ( ⋅ ) , s m u l ( ⋅ ) } \{s_{dense}(\cdot) , s_{lex}(\cdot) , s_{mul}(\cdot) \} {sdense(⋅),slex(⋅),smul(⋅)}中的任意一个。
L = − log e x p ( s ( q , p ∗ ) / τ ) ∑ p ∈ { p ∗ , P ′ } e x p ( s ( q , p ) / τ ) \mathcal{L} = -\log \frac{exp(s(q, p^*)/\tau)}{\sum_{p \in \{p^*, P^{\prime}\}} exp(s(q,p)/\tau) } L=−log∑p∈{p∗,P′}exp(s(q,p)/τ)exp(s(q,p∗)/τ)
BGE-M3中的三种不同检索方法的目标函数可能会彼此冲突,解决办法是使用Self-Knowledge Distillation。
-
三种检索方法融合的最简单方法是直接求和: s i n t e r ← s d e n s e + s l e x + s m u l s_{inter} \leftarrow s_{dense} + s_{lex} + s_{mul} sinter←sdense+slex+smul。
-
对于每一种检索方法可以使用融合分数 s i n t e r s_{inter} sinter作为teacher,因此其损失函数可修改成: L ∗ ′ ← − p ( s i n t e r ) ∗ log p ( s ∗ ) \mathcal{L}^{\prime}_* \leftarrow -p(s_{inter}) * \log p(s_*) L∗′←−p(sinter)∗logp(s∗)。式中的 p ( ⋅ ) p(\cdot) p(⋅)是softmax激活函数, s ∗ s_* s∗是 { s d e n s e ( ⋅ ) , s l e x ( ⋅ ) , s m u l ( ⋅ ) } \{s_{dense}(\cdot) , s_{lex}(\cdot) , s_{mul}(\cdot) \} {sdense(⋅),slex(⋅),smul(⋅)}中的任意一个。
-
将前一步的损失函数进行融合与归一化: L ′ ← ( L d e n s e ′ + L l e x ′ + L m u l ′ ) / 3 \mathcal{L}^{\prime} \leftarrow (\mathcal{L}^{\prime}_{dense} + \mathcal{L}^{\prime}_{lex}+\mathcal{L}^{\prime}_{mul} )/3 L′←(Ldense′+Llex′+Lmul′)/3
-
Self-Knowledge Distillation最终的损失函数为 L \mathcal{L} L和 L ′ \mathcal{L}^{\prime} L′的线性组合: L f i n a l ← L + L ′ \mathcal{L}_{final} \leftarrow \mathcal{L} + \mathcal{L}^{\prime} Lfinal←L+L′
BGE-M3训练过程
像BGE一样,BGE-M3也是多阶段训练:
-
经过RetroMAE 方法继续预训练的XLM-RoBERTa作为文本编码器。扩充了XLM-RoBERTa的最大位置向量到8192。数据来源为PIle、Wudao、mC4数据集,从中采样了184M数据,覆盖了105种语言。
-
使用无监督数据用对比学习方式预训练,这一阶段只有稠密检索向量被训练。
-
应用Self-Knowledge Distillation技术对向量模型继续微调,标注语料和合成数据都在这个阶段使用,并使用ANN方法挖掘了难负例。

为了保证训练过程中的大batch size 和长本文序列训练,优化了训练过程:
- 根据长度对文本数据进行分组,并从每组中采样数据,确保一个batch内文本长度相对相似,从而减少填充。同时,数据程序会首先从组内采样足够的数据,然后分配给各机器(random seed保持固定),保证不同机器的计算开销尽可能相近。
- 为了减少文本建模时的显存消耗,将一批数据分成多个小批。对于每个小批,我们利用模型编码文本,收集输出的向量同时丢弃所有前向传播中的中间状态,最后汇总向量计算损失。这个方法可以显著增加batch size。
- 不同GPU的embedding向量被广播,允许每台机器在分布式环境里获取到所有向量,可以扩展in-batch 负样本的规模

考虑到用户可能没有足够的资源或者数据来训练长文本模型,提出了一个MCLS策略使得无需训练就能增强模型的长文本能力。这个策略在推理时应用,使用多个CLS token来联合捕获长文本的语义。该策略为每个固定数量的令牌插入一个CLS token(论文使用的是256个token),每个CLS token可以从相邻的令牌获取语义信息。最后通过对所有CLS token的最后隐藏状态求平均值来获得最终的文本向量。
参考资料
-
Xiao, Shitao, Zheng Liu, Peitian Zhang, and Niklas Muennighof. 2023. “C-Pack: Packaged Resources To Advance General Chinese Embedding,” September.
-
Chen, Jianlv, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. n.d. “BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation.”
-
FlagEmbedding github
相关文章:
文本向量模型BGE与BGE-M3
BGE模型 BGE模型对应的技术报告为《C-Pack: Packaged Resources To Advance General Chinese Embedding》 训练数据 为了训练BGE向量模型,构建了C-MTP数据集,它包括了用来训练文本向量的文本对数据(问答对、两个同义句子、相同主题的两个文…...
【黑马头条】-day04自媒体文章审核-阿里云接口-敏感词分析DFA-图像识别OCR-异步调用MQ
文章目录 day4学习内容自媒体文章自动审核今日内容 1 自媒体文章自动审核1.1 审核流程1.2 内容安全第三方接口1.3 引入阿里云内容安全接口1.3.1 添加依赖1.3.2 导入aliyun模块1.3.3 注入Bean测试 2 app端文章保存接口2.1 表结构说明2.2 分布式id2.2.1 分布式id-技术选型2.2.2 雪…...
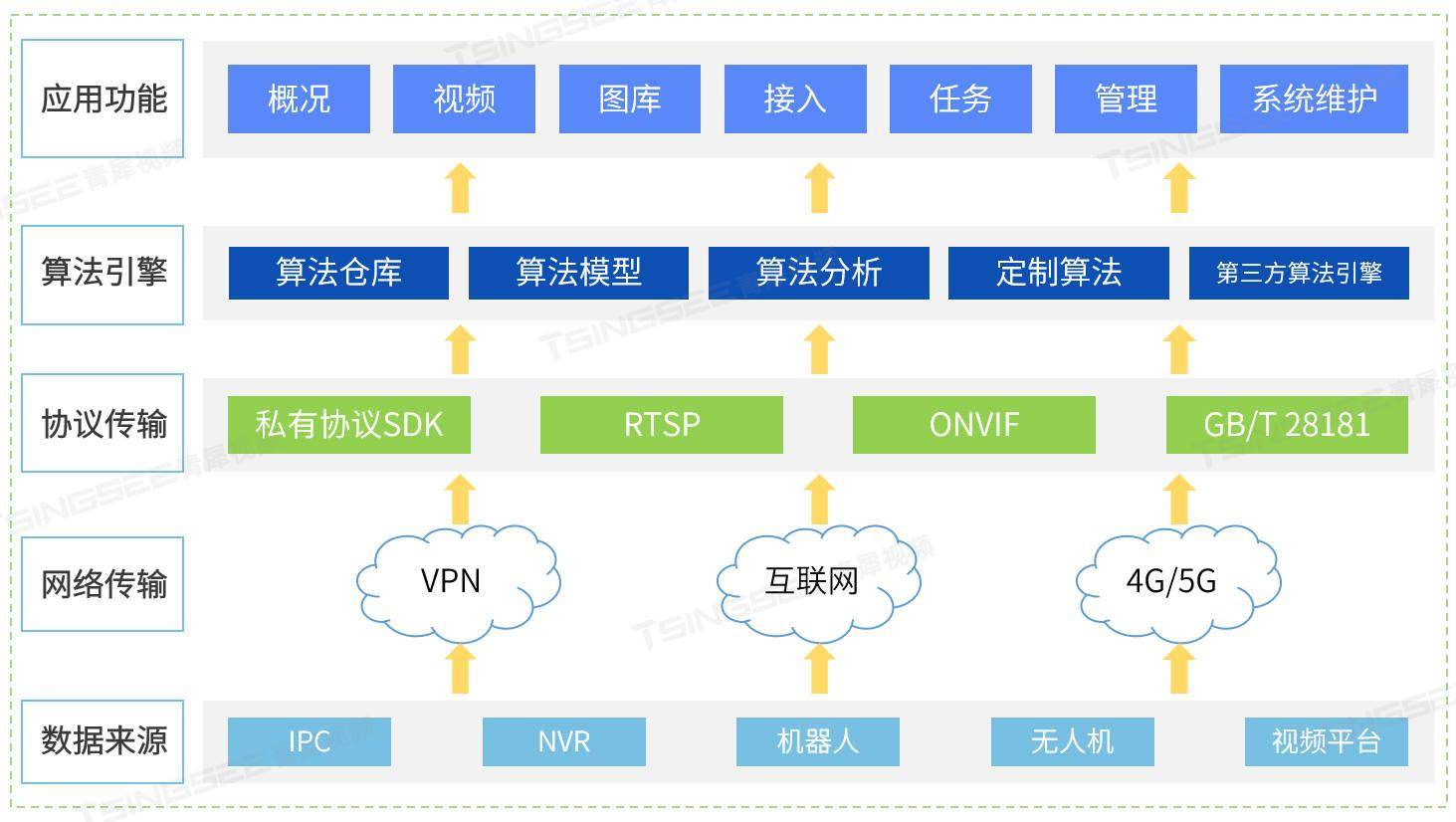
新能源充电桩站场AI视频智能分析烟火检测方案及技术特点分析
新能源汽车充电起火的原因多种多样,涉及技术、设备、操作等多个方面。从技术层面来看,新能源汽车的电池管理系统可能存在缺陷,导致电池在充电过程中出现过热、短路等问题,从而引发火灾。在设备方面,充电桩的设计和生产…...

springboot集成logback-spring.xml文件
彩色日志日志分debug和error文件输出,方便开发人员运维日志限制最大保管天数日志限制总量大小占用量GB日志限制单个文件大小MB日志显示最大保留天数屏蔽没用的日志 <?xml version"1.0" encoding"UTF-8"?> <!--~ Copyright (c) 2020…...

centos7 安装 nginx
一、yum 方式安装 1.安装yum工具 sudo yum install yum-utils 2. 安装epel yum install epel-release 3.安装nginx: yum install nginx 4.查看版本 nginx -v 5.设置开机自启动 systemctl enable nginx nginx 常用命令: 1)启动nginx …...

29. UE5 RPG应用GamplayAbility
前面几篇文章,总算把GE给更新完了,GE的基础应用也算讲清楚了。接下来,我们将更新GA的相应的课程了,首先,这一篇先对GA做一个简单的介绍,然后实现一下如何实现给角色应用一个GA。 简介 GamplayAbility 简称…...

http和https的区别!
HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSLHTTP) 数据传输过程是加密的,安全性较好。 使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) …...
使用AOP实现打印日志
首先创建annotation.SystemLog类: package com.gjh.annotation;import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;Target(ElementType.METHOD…...
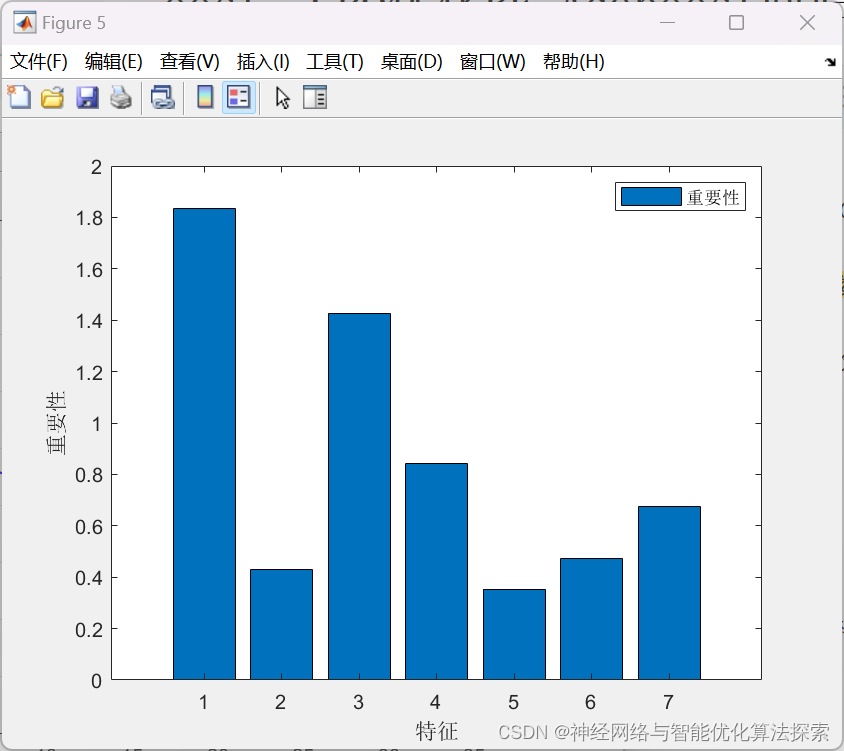
2024年新算法-冠豪猪优化算法(CPO),CPO-RF-Adaboost,CPO优化随机森林RF-Adaboost回归预测-附代码
冠豪猪优化算法(CPO)是一种基于自然界中猪群觅食行为启发的优化算法。该算法模拟了猪群在寻找食物时的集群行为,通过一系列的迭代过程来优化目标函数,以寻找最优解。在这个算法中,猪被分为几个群体,每个群体…...
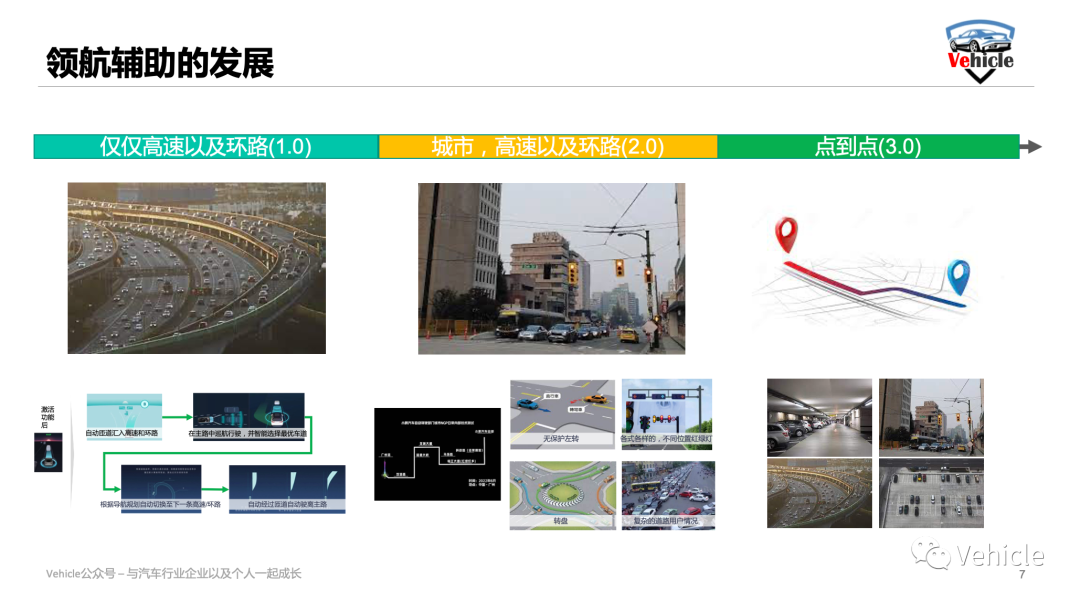
浅谈高阶智能驾驶-NOA领航辅助的技术与发展
浅谈高阶智能驾驶-NOA领航辅助的技术与发展 附赠自动驾驶学习资料和量产经验:链接 2019年在国内首次试驾特斯拉NOA领航辅助驾驶的时候,当时兴奋的觉得未来已来;2020年在试驾蔚来NOP领航辅助驾驶的时候,顿时不敢小看国内新势力了;现在如果哪家…...
大模型 智能体 智能玩具 智能音箱 构建教程 wukong-robot
视频演示 10:27 一、背景 继上文《ChatGPT+小爱音响能擦出什么火花?》可以看出大伙对AI+硬件的结合十分感兴趣,但上文是针对市场智能音响的AI植入,底层是通过轮询拦截,算是hack兼容,虽然官方有提供开发者接口,也免不了有许多局限性(比如得通过特定指令唤醒),不利于我…...

Clickhouse-表引擎探索之MergeTree
引言 前文曾说过,Clickhouse是一个强大的数据库Clickhouse-一个潜力无限的大数据分析数据库系统 其中一个强大的点就在于支持各类表引擎以用于不同的业务场景。 MergeTree MergeTree系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一…...

网络电视盒子哪个好?小编分享电视盒子品牌排行榜
电视盒子使用频率高,功能丰富,价格划算,是我们日常不可或缺的部分,小编经常会被问到与电视盒子相关的问题,考虑到很多朋友并不了解网络电视盒子哪个好,这次我来分享业内权威电视盒子品牌排行榜,…...
)
开源模型应用落地-baichuan2模型小试-入门篇(三)
一、前言 相信您已经学会了如何在Windows环境下以最低成本、无需GPU的情况下运行baichuan2大模型。现在,让我们进一步探索如何在Linux环境下,并且拥有GPU的情况下运行baichuan2大模型,以提升性能和效率。 二、术语 2.1. CentOS CentOS是一种基于Linux的自由开源操作…...

景联文科技高质量大模型训练数据汇总!
3月25日,2024年中国发展高层论坛年会上,国家数据局局长刘烈宏在“释放数据要素价值,助力可持续发展”的演讲中表示,中国10亿参数规模以上的大模型数量已超100个。 当前,国内AI大模型发展仍面临诸多困境。其中ÿ…...

【python】正则表达式
文章目录 正则表达式对象re.RegexObjectre.MatchObject符号说明匹配基础匹配?=、?<=、?!、?<!字符类re模块编译正则表达式compile 函数匹配字符串re.matchre.searchre.findall...

学习vue3第十二节(组件的使用与类型)
1、组件的作用用途 目的: 提高代码的复用度,和便于维护,通过封装将复杂的功能代码拆分为更小的模块,方便管理, 当我们需要实现相同的功能时,我们只需要复用已经封装好的组件,而不需要重新编写相…...
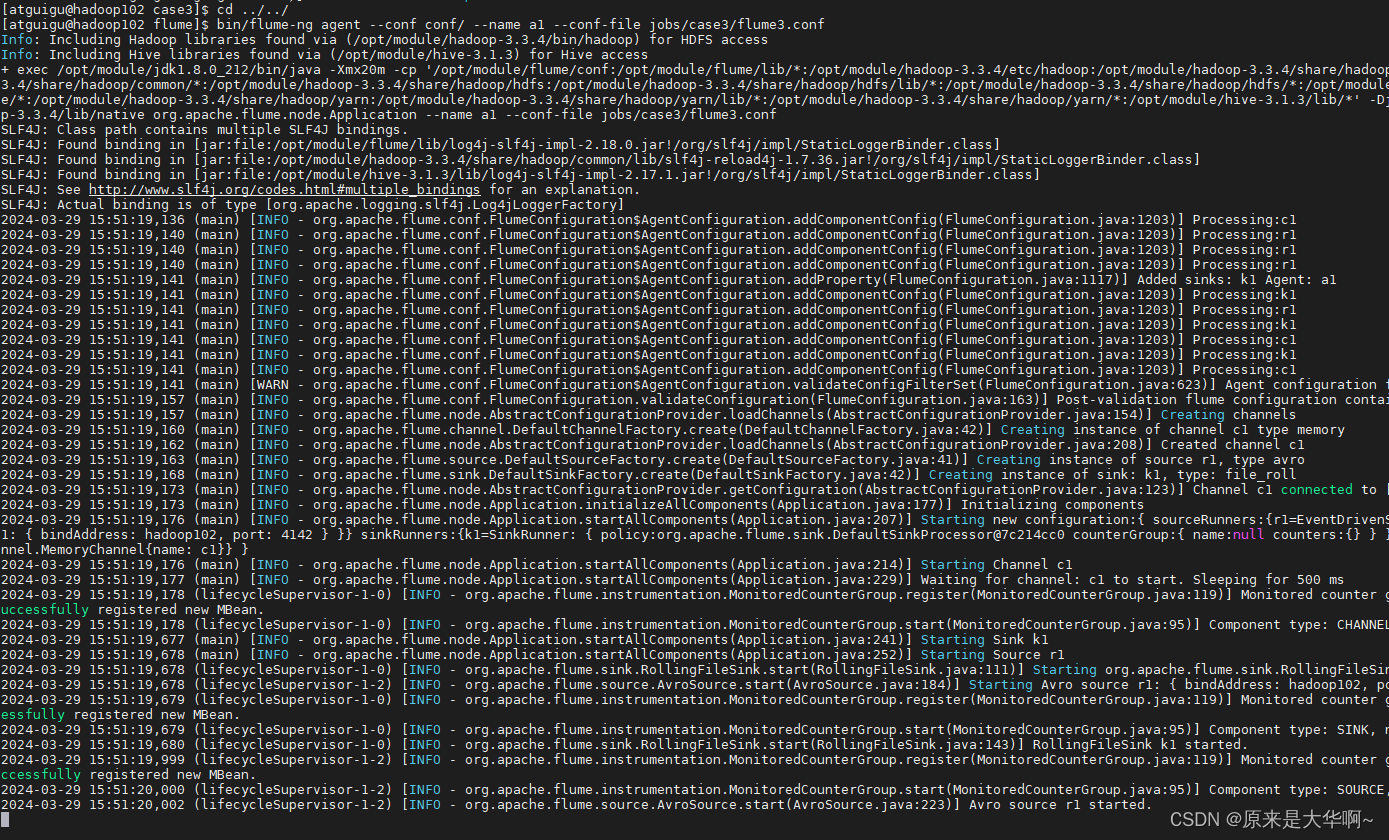
flume配置文件后不能跟注释!!
先总结:Flume配置文件后面,不能跟注释,可以单起一行写注释 报错代码: [ERROR - org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:158)] Unable to deliver event. Exception follows. org.apache.flume.EventDel…...
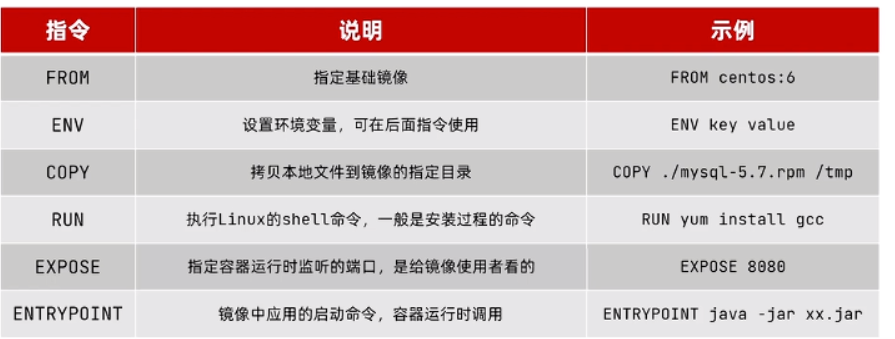
【docker】Dockerfile自定义镜像
📝个人主页:五敷有你 🔥系列专栏:中间件 ⛺️稳中求进,晒太阳 1.Dockerfile自定义镜像 常见的镜像在DockerHub就能找到,但是我们自己写的项目就必须自己构建镜像了。 而要自定义镜像,就…...
webpack项目打包console git分支、打包时间等信息 exec
相关链接 MDN toLocaleString child_process Node.js strftime 格式 代码 buildinfo.js const { execSync, exec } require("child_process"); // exec: 在 Windows 执行 bat 和 cmd 脚本// execSync 同步 // exec 异步// exec 使用方法 // exec(git show -s,…...
到底怎么选)
信息学奥赛新手村:从‘输出绝对值’这道题,聊聊C++里if-else和fabs()到底怎么选
信息学奥赛解题思维:绝对值计算的方案选择与优化 第一次参加信息学奥赛的新手们,往往会在基础题目上陷入"能用就行"的思维定式。就拿"输出绝对值"这道看似简单的题目来说,表面上看只要结果正确就能得分,但当你…...

哔哩下载姬DownKyi:B站视频下载的终极免费解决方案
哔哩下载姬DownKyi:B站视频下载的终极免费解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

如何在Dev-C++中选择TDM-GCC编译器
在Dev-C中选择TDM-GCC编译器的步骤如下:打开编译器设置启动Dev-C,点击顶部菜单栏的 "工具" → "编译器选项"选择编译器在打开的窗口中:切换到 "编译器" 选项卡勾选 "在连接器命令行加入以下命令"在下…...

Kaggle竞赛提分利器:如何用Stacking融合XGBoost、LightGBM和CatBoost模型?
Kaggle竞赛进阶指南:Stacking融合三大梯度提升树的实战策略 在Kaggle竞赛中,当单一模型的性能触及天花板时,模型融合技术往往成为突破瓶颈的关键。不同于教科书式的理论讲解,本文将聚焦竞赛实战中的核心痛点——如何通过Stacking技…...

开源技术如何驱动物联网创新:从硬件到软件的平民化革命
1. 物联网与开源:一场全民工程的序章十年前,如果有人告诉我,一个没有任何电子工程背景的艺术家,能自己动手做一个能联网、能自动浇花、还能在社交媒体上发照片的智能花盆,我大概会觉得他在讲科幻故事。但今天ÿ…...

免费好用的去水印工具推荐:哪个效果最好?免费去水印工具对比 2026 实测
免费好用的去水印工具推荐:哪个效果最好?免费去水印工具对比 2026 实测 去水印这件事,真的是越来越高频了。自媒体剪素材、收藏喜欢的短视频、整理图片资料……一旦碰到带水印的内容,找个顺手的工具就成了刚需。网上工具多&#x…...

新手小白必看!AI大模型自学路线图,从入门到精通_自学AI大模型学习路线推荐
自学AI大模型学习路线推荐 今天,我想和大家分享一条自学AI大模型的学习路线,希望能帮助新手小白们更好地进入这个领域。 1. 打好基础:数学与编程 数学基础 线性代数:理解矩阵、向量、特征值、特征向量等概念。推荐课程:…...

微信聊天记录永久备份完整指南:WeChatExporter开源工具终极教程
微信聊天记录永久备份完整指南:WeChatExporter开源工具终极教程 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心珍贵的微信聊天记录会因为手机丢失…...

Gorilla:让大语言模型学会调用API,从聊天机器人到智能体的关键技术
1. 项目概述:当大语言模型学会“使用工具”如果你在过去一年里深度使用过 ChatGPT、Claude 或者国内的文心一言、通义千问这类大语言模型,你肯定有过这样的体验:模型在聊天、写作、分析上表现惊艳,但一旦你问它“帮我查一下明天的…...

半导体与EDA公司成长路径:从300万到5000万营收的实战指南
1. 从初创到巨头:一场关于半导体与EDA公司成长路径的深度对话如果你正在半导体、EDA(电子设计自动化)或者更广泛的硬科技领域创业,或者你在一家快速成长的科技公司担任核心角色,那么有一个问题你肯定反复思考过&#x…...