PyTorch|Dataset与DataLoader使用、构建自定义数据集
文章目录
- 一、Dataset与DataLoader
- 二、自定义Dataset类
- (一)\_\_init\_\_函数
- (二)\_\_len\_\_函数
- (三)\_\_getitem\_\函数
- (四)全部代码
- 三、将单个样本组成minibatch(DataLoader)
- (一)PyTorch的DataLoader源码
- 1、DataLoader的参数
- 2、init函数
- 3、iter函数
- (二)使用DataLoader遍历
一、Dataset与DataLoader
PyTorch提供的两个常用数据API:
- torch.utils.data.Dataset:用于处理单个训练样本,读取数据特征、size、标签等,并且包括数据转换等;
- torch.utils.data.DataLoader:DataLoader在Dataset周围重载一个可迭代对象,以便轻松访问样本。
官方案例: Fashion-MNIST数据集
torchvision:torch的一个视觉库,将torchvision中的datasets导入进来,就能获得其中的各种数据集
FashionMNIST图像存储在目录img_dir中,标签存储在CSV文件annotations_file中
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plttraining_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor()
)test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor()
)
对上述数据集进行可视化:
labels_map = {0: "T-Shirt",1: "Trouser",2: "Pullover",3: "Dress",4: "Coat",5: "Sandal",6: "Shirt",7: "Sneaker",8: "Bag",9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):sample_idx = torch.randint(len(training_data), size=(1,)).item()img, label = training_data[sample_idx]figure.add_subplot(rows, cols, i)plt.title(labels_map[label])plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")
plt.show()
二、自定义Dataset类
- 构建自定义的Dataset类,需要继承TensorFlow的官方dataset类
- 自定义Dataset类必须实现三个函数:__init__,__len__和__getitem__
pytorch中的dataset类是在pytorch的torch下的utils之下的data文件夹里有一个dataset.py

(一)__init__函数
包含图像、注释文件和两个转换:
- annotations_file:标注文件
- img_dir:图像目录
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file) #标签存储在CSV文件annotations_file中self.img_dir = img_dir #FashionMNIST图像存储在目录img_dir中self.transform = transform #图像转换self.target_transform = target_transform
(二)__len__函数
返回数据集的样本数(就是img_labels的长度)
def __len__(self):return len(self.img_labels)
(三)__getitem_\函数
输入索引index,getitem函数从数据集中加载并返回对应index的一个样本:
def __getitem__(self, idx):#img_labels的第index行第0列标注了对应的照片文件名称img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path) #使用read_image将图像转换为张量label = self.img_labels.iloc[idx, 1] #从self中的csv数据中检索相应的标签#调用转换函数if self.transform: image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label #返回张量图像和相应的标签
(四)全部代码
import os
import pandas as pd
from torchvision.io import read_imageclass CustomImageDataset(Dataset):def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transformdef __len__(self):return len(self.img_labels)def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path)label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label
三、将单个样本组成minibatch(DataLoader)
(一)PyTorch的DataLoader源码
1、DataLoader的参数
DataLoader通常是在torch.utils.data下

常用的参数有:
- dataset(数据集):需要提取数据的数据集,Dataset对象
- batch_size(批大小):每一次装载样本的个数,int型
- shuffle:是否打乱数据顺序
- sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
- num_workers:进行数据加载时使用单个进程还是多进程进行加载,多进程意为加载速度更快,一般默认为0,表示使用主进程进行加载
- collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数,一般用于对于一个batch进行后处理
- pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中
- drop_last:当样本数不能被batchsize整除时, 是否舍弃最后一批数据
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
2、init函数
主要做了三件事:构建sampler、构建batch_sampler、构建collate_fn
定义属性:

如果设置了自定义的sampler然后又设置了shuffle=true,这种情况是没有意义的:
(shuffle是官方自定义的一个随机sampler)

设置了batch_sampler的情况下,就不需要设置batch_size、shuffle、sampler和drop_last了:

如果没有设置sampler,则先判断数据集类型,如果使用的是map-style(else逻辑),就根据是否设置shuffle来选择pytorch内置的sampler:

设置了batch_size但是没有设置batch_sampler时,会使用内置的BatchSampler:

如果没有设置collate_fn,就判断auto_collation是否设置(auto_collation是根据batch_sampler是否是None来设置的,如果batch_sampler不是none,auto_collation就是true),default_collate是将batch作为输入,batch输出,并没有对数据做额外处理:

3、iter函数
iter函数返回的是get_iterator的值:

get_iterator根据num_workers的设置选择对应的内置DataLoaderIter:

所以可知,iter函数最终返回的是一个dataloaderiter对象,以SingleProcessDataLoaderIter为例,类里有next_data函数:

SingleProcessDataLoaderIter类是继承了BaseDataLoaderIter类,BaseDataLoaderIter类中的next函数就是使用了子类中的next_data:

(二)使用DataLoader遍历
根据上述源码分析,就可以对dataloader去迭代iter之后调用next函数来获得每一批次的数据:
- 通过DataLoader实现对于数据集的遍历,每次遍历会得到一个batch的数据,这里设置batch_size为64:
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
- iter函数将train_dataloader变成一个迭代器,使用next函数可以以此从迭代器中生成一个一个的批次:
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
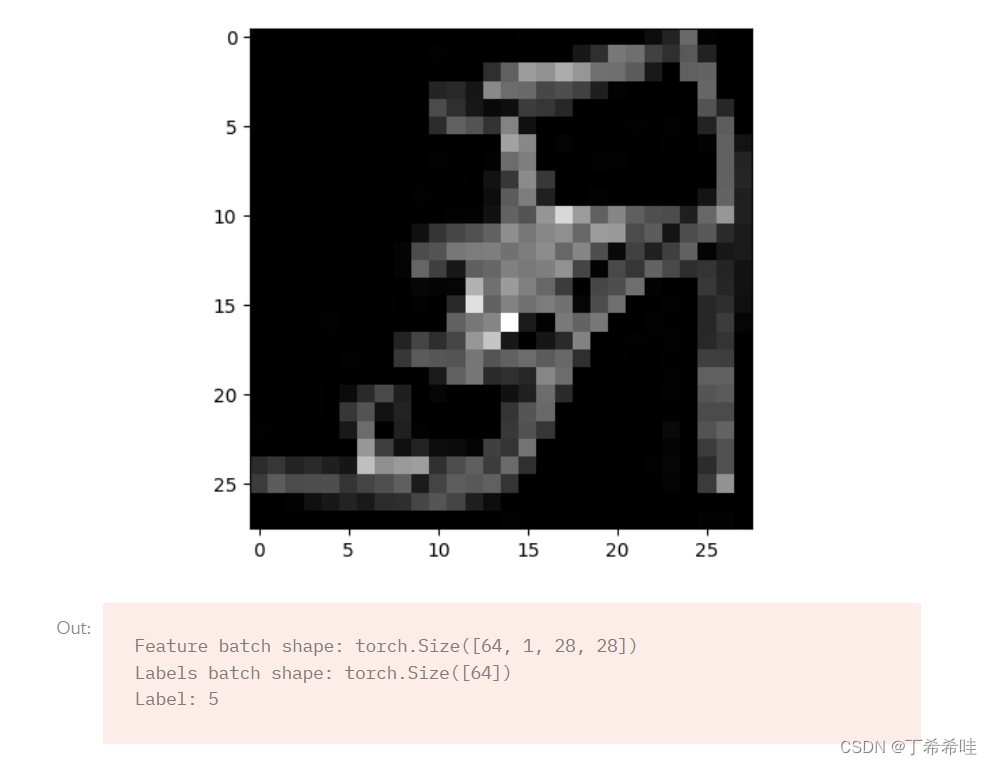 由于batch_size=64,因此最终返回的Feature batch shape以及Labels batch shape均为64。
由于batch_size=64,因此最终返回的Feature batch shape以及Labels batch shape均为64。
参考:
PyTorch官方文档:Datasets & DataLoaders
5、深入剖析PyTorch DataLoader源码
相关文章:
PyTorch|Dataset与DataLoader使用、构建自定义数据集
文章目录 一、Dataset与DataLoader二、自定义Dataset类(一)\_\_init\_\_函数(二)\_\_len\_\_函数(三)\_\_getitem\_\函数(四)全部代码 三、将单个样本组成minibatch(Data…...
4.6(信息差)
🌍 山西500千伏及以上输电线路工程首次采用无人机AI自主验收 🌋 中国与泰国将开展国际月球科研站等航天合作 ✨ 网页版微软 PowerPoint 新特性:可直接修剪视频 🍎 特斯拉开始在德国超级工厂生产出口到印度的右舵车 1.马斯克&…...

关于C#操作SQLite数据库的一些函数封装
主要功能:增删改查、自定义SQL执行、批量执行(事务)、防SQL注入、异常处理 1.NuGet中安装System.Data.SQLite 2.SQLiteHelper的封装: using System; using System.Collections.Generic; using System.Data.SQLite; using System.…...

LeetCode-79. 单词搜索【数组 字符串 回溯 矩阵】
LeetCode-79. 单词搜索【数组 字符串 回溯 矩阵】 题目描述:解题思路一:回溯 回溯三部曲。这里比较关键的是给board做标记,防止之后搜索时重复访问。解题思路二:回溯算法 dfs,直接看代码,很容易理解。visited哈希,防止…...
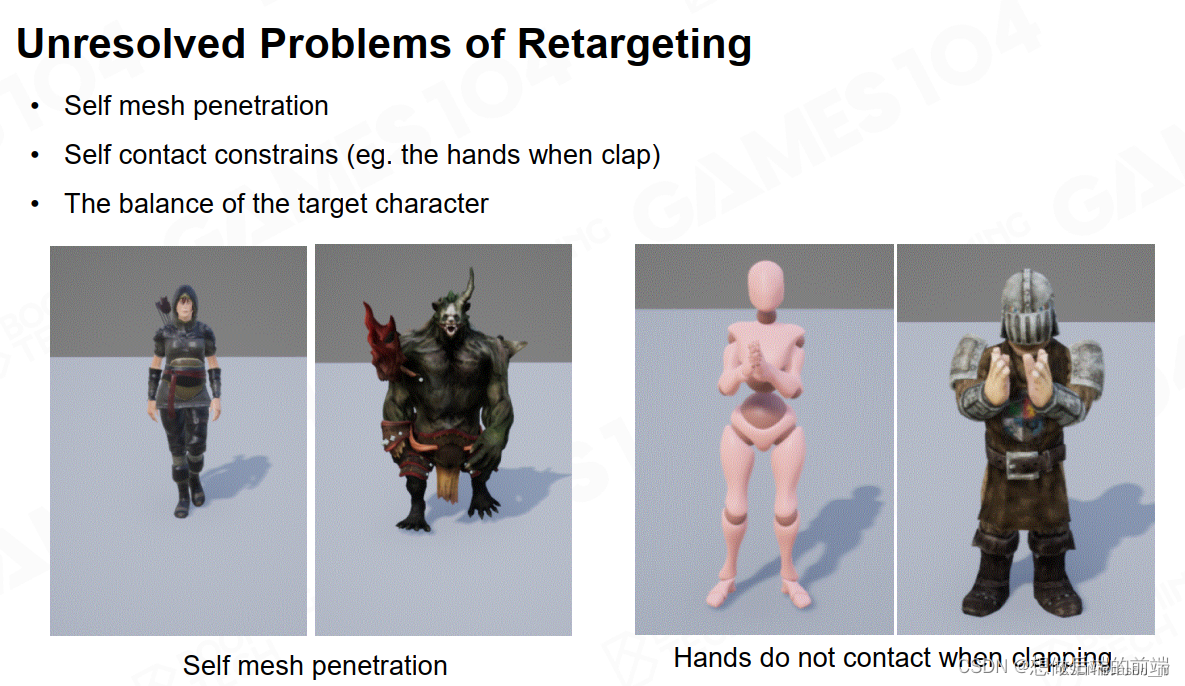
游戏引擎之高级动画技术
一、动画混合 当我们拥有各类动画素材(clips)时,要将它们融合起来成为一套完整的动画。 最经典的例子就是从走的动画自然的过渡到跑的动画。 1.1 线性插值 不同于上节课的LERP(同一个clip内不同pose之间)ÿ…...
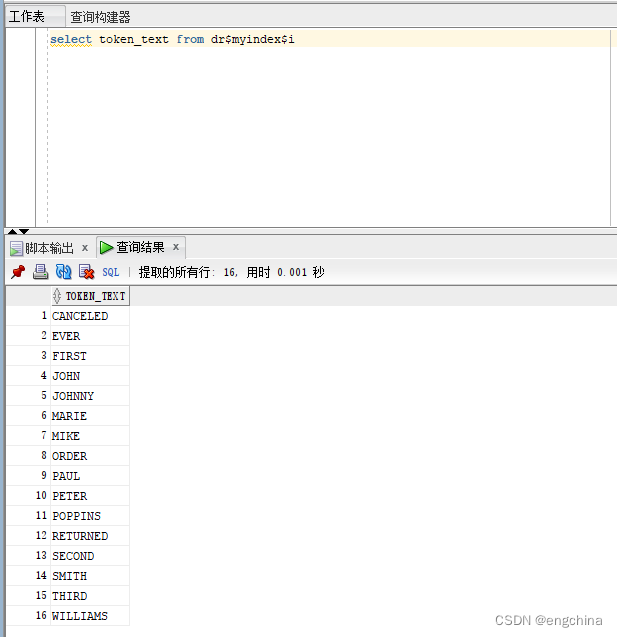
Oracle 数据库中的全文搜索
Oracle 数据库中的全文搜索 0. 引言1. 整体流程2. 创建索引2-1. 创建一个简单的表2-2. 创建文本索引2-3. 查看创建的基础表 3. 运行查询3-1. 运行文本查询3-2. CONTAINS 运算符3-3. 混合查询3-4. OR 查询3-5. 通配符3-6. 短语搜索3-7. 模糊搜索(Fuzzy searches&…...

代码随想录阅读笔记-二叉树【二叉搜索树中的众数】
题目 给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。 假定 BST 有如下定义: 结点左子树中所含结点的值小于等于当前结点的值结点右子树中所含结点的值大于等于当前结点的…...

AcWing-游戏
1388. 游戏 - AcWing题库 所需知识:博弈论,区间dp 由于双方都采取最优的策略来取数字,所以结果为确定的,有可能会有多个不同的过程,但是我们只需要关注最终结果就行了。 方法一: 定义dp[i][j] 表示区间…...

Mybatis——一对一映射
一对一映射 预置条件 在某网络购物系统中,一个用户只能拥有一个购物车,用户与购物车的关系可以设计为一对一关系 数据库表结构(唯一外键关联) 创建两个实体类和映射接口 package org.example.demo;import lombok.Data;import …...

Web 安全之 SSL 剥离攻击详解
目录 SSL/TLS简介 SSL 剥离攻击原理 SSL 剥离攻击的影响 SSL 剥离攻击的防范措施 小结 SSL 剥离攻击(SSL Stripping Attack)是一种针对安全套接层(SSL)或传输层安全性(TLS)协议的攻击手段,…...
)
数据结构——顺序表(C语言)
目录 一、顺序表概念 二、顺序表分类 1.静态顺序表 2.动态顺序表 三、顺序表的实现 1.顺序表的结构体定义 2. 顺序表初始化 3.顺序表销毁 4.顺序表的检验 5.顺序表打印 6.顺序表扩容 7.顺序表尾插与头插 8.尾删与头删 9.在pos处插入数据 10.在pos处删除数据 11.查找数据 …...
利用Idea实现Ajax登录(maven工程)
一、新建一个maven工程(不会建的小伙伴可以参考Idea引入maven工程依赖(保姆级)-CSDN博客),工程目录如图 js文件可以上up网盘提取 链接:https://pan.baidu.com/s/1yOFtiZBWGJY64fa2tM9CYg?pwd5555 提取码&…...

环信IM集成教程——Web端UIKit快速集成与消息发送
写在前面: 千呼万唤始出来,环信Web端终于出UIKit了!🎉🎉🎉 文档地址:https://doc.easemob.com/uikit/chatuikit/web/chatuikit_overview.html 环信单群聊 UIKit 是基于环信即时通讯云 IM SDK 开…...

Anaconda如何切换国内镜像源
一、anaconda如何切换阿里镜像源 在Anaconda中切换到阿里云镜像源可以通过以下步骤进行: 1、打开终端(Windows)或者命令行界面(macOS/Linux)。 2、执行以下命令来配置阿里云镜像源: conda config --add…...

Android 14.0 添加自定义服务,并生成jar给第三方app调用
1.概述 在14.0系统ROM产品定制化开发中,由于需要新增加自定义的功能,所以要增加自定义服务,而app上层通过调用自定义服务,来调用相应的功能,所以系统需要先生成jar,然后生成jar 给上层app调用,接下来就来分析实现的步骤,然后来实现相关的功能 从而来实现所需要的功能 …...

解决沁恒ch592单片机在tmos中使用USB总线时,接入USB Hub无法枚举频繁Reset的问题
开发产品时采用了沁恒ch592,做USB开发时遇到了一个奇葩的无法枚举问题。 典型症状 使用USB线直连电脑时没有问题,可以正常使用。 如果接入某些特定方案的USB Hub(例如GL3510、GL3520),可能会出现以下2种情况…...
nvm保姆级安装使用教程
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 开发环境篇 ✨特色专栏: M…...

大语言模型LLM《提示词工程指南》学习笔记02
文章目录 大语言模型LLM《提示词工程指南》学习笔记02设计提示时需要记住的一些技巧零样本提示少样本提示链式思考(CoT)提示自我一致性生成知识提示 大语言模型LLM《提示词工程指南》学习笔记02 设计提示时需要记住的一些技巧 指令 您可以使用命令来指…...
【realme x2手机解锁BootLoader(简称BL)】
realme手机解锁常识 https://www.realme.com/cn/support/kw/doc/2031665 realme手机解锁支持型号 https://www.realmebbs.com/post-details/1275426081138028544 realme x2手机解锁实践 参考:https://www.realmebbs.com/post-details/1255473809142591488 1 下载apk…...

攻防世界 wife_wife
在这个 JavaScript 示例中,有两个对象:baseUser 和 user。 baseUser 对象定义如下: baseUser { a: 1 } 这个对象有一个属性 a,其值为 1,没有显式指定原型对象,因此它将默认继承 Object.prototype。 …...

3款精选工具:重新定义你的星露谷物语体验
3款精选工具:重新定义你的星露谷物语体验 【免费下载链接】StardewMods Mods for Stardew Valley using SMAPI. 项目地址: https://gitcode.com/gh_mirrors/st/StardewMods 你是否曾在《星露谷物语》中为重复性的农场劳作感到疲惫?是否因为繁琐的…...

3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南
3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.…...

AI工作流编排利器:OpenClaw Workflow Kit 模块化设计与实战
1. 项目概述:一个为AI工作流打造的“瑞士军刀”最近在GitHub上看到一个挺有意思的项目,叫leilong611-ai/openclaw-workflow-kit。光看这个名字,你可能会有点懵:“OpenClaw”是啥?“Workflow Kit”又是干嘛的࿱…...

颠覆性网络拓扑可视化:基于Vue+SVG的一站式轻量级解决方案
颠覆性网络拓扑可视化:基于VueSVG的一站式轻量级解决方案 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 在复杂的网络架构设计和运维管理中,网络工程师和开发人员经常…...

百度网盘Mac破解终极方案:解锁SVIP高速下载体验
百度网盘Mac破解终极方案:解锁SVIP高速下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 作为Mac用户,你是否曾因百度网盘…...

Compass Design
Compass Design 圆规设计...

HS2-HF_Patch深度解析:Honey Select 2终极增强补丁实战指南
HS2-HF_Patch深度解析:Honey Select 2终极增强补丁实战指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是一款专为Honey Select 2游…...
)
AI全领域热点速递(2026年5月11日)
💌 关心家人,从每日报平安开始。万年历提醒微信小程序,您值得体验。📰 每日整理AI领域核心动态,精选有价值资讯,精简可读,适合收藏备查。🤖 AI全领域热点速递(2026年5月1…...

浏览器扩展开发实战:KeepChatGPT会话保持原理与实现
1. 项目概述:一个浏览器扩展的诞生与使命 最近在和一些做AI应用开发的朋友交流时,大家普遍反映了一个痛点:在使用一些大型语言模型(LLM)的在线服务时,对话经常会被意外中断。这种中断可能源于网络波动、服…...

收藏!小白也能入行:AI训练师是什么?值不值?怎么学?
AI冲击重复性岗位,但AI训练师需求激增347%。本文解读AI训练师(非程序员)的工作内容(数据标注、Prompt设计等)、市场数据(薪资60k、缺口百万)、适合人群(内容创作者、白领、应届生&am…...