数据结构和算法:分治
分治算法
分治(divide and conquer),全称分而治之,是一种非常重要且常见的算法策略。分治通常基于递归实现,包括“分”和“治”两个步骤。
1.分(划分阶段):递归地将原问题分解为两个或多个子问题,直至到达最小子问题时终止。
2.治(合并阶段):从已知解的最小子问题开始,从底至顶地将子问题的解进行合并,从而构建出原问题的解。
“归并排序”是分治策略的典型应用之一:
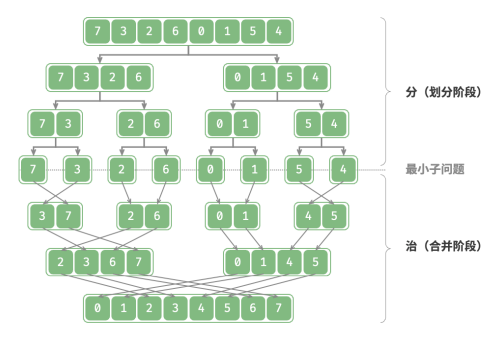
1.分:递归地将原数组(原问题)划分为两个子数组(子问题),直到子数组只剩一个元素(最小子问题);
2.治:从底至顶地将有序的子数组(子问题的解)进行合并,从而得到有序的原数组(原问题的解)。
如何判断分治问题
一个问题是否适合使用分治解决,通常可以参考以下几个判断依据:
1.问题可以分解:原问题可以分解成规模更小、类似的子问题,以及能够以相同方式递归地进行划分。
2.子问题是独立的:子问题之间没有重叠,互不依赖,可以独立解决。
3.子问题的解可以合并:原问题的解通过合并子问题的解得来。
显然,归并排序满足以上三个判断依据。
1.问题可以分解:递归地将数组(原问题)划分为两个子数组(子问题)。
2.子问题是独立的:每个子数组都可以独立地进行排序(子问题可以独立进行求解)。
3.子问题的解可以合并:两个有序子数组(子问题的解)可以合并为一个有序数组(原问题的解)。
通过分治提升效率
分治不仅可以有效地解决算法问题,往往还可以提升算法效率。
在排序算法中,快速排序、归并排序、堆排序相较于选择、冒泡、插入排序更快,就是因为它们应用了分治策略。
1. 操作数量优化
以“冒泡排序”为例,其处理一个长度为 𝑛 的数组需要 𝑂(𝑛^2) 时间。
假设按照下图所示的方式,将数组从中点处分为两个子数组,则划分需要 𝑂(𝑛) 时间,排序每个子数组需要 𝑂((𝑛/2)^2) 时间,合并两个子数组需要 𝑂(𝑛) 时间,总体时间复杂度为:
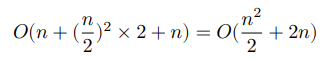
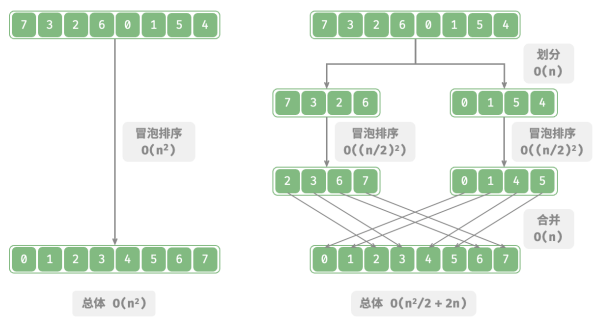
接下来,计算以下不等式,其左边和右边分别为划分前和划分后的操作总数:
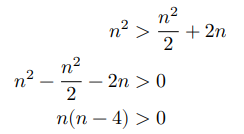
这意味着当 𝑛 > 4 时,划分后的操作数量更少,排序效率应该更高。请注意,划分后的时间复杂度仍然是平方阶 𝑂(𝑛^2) ,只是复杂度中的常数项变小了。
进一步想,如果把子数组不断地再从中点处划分为两个子数组,直至子数组只剩一个元素时停止划分呢?这种思路实际上就是“归并排序”,时间复杂度为 𝑂(𝑛 log 𝑛) 。
再思考,如果多设置几个划分点,将原数组平均划分为 𝑘 个子数组呢?这种情况与“桶排序”非常类似,它非常适合排序海量数据,理论上时间复杂度可以达到 𝑂(𝑛 + 𝑘) 。
2. 并行计算优化
分治生成的子问题是相互独立的,因此通常可以并行解决。也就是说,分治不仅可以降低算法的时间复杂度,还有利于操作系统的并行优化。
并行优化在多核或多处理器的环境中尤其有效,因为系统可以同时处理多个子问题,更加充分地利用计算资源,从而显著减少总体的运行时间。
比如在下图所示的“桶排序”中,将海量的数据平均分配到各个桶中,则可所有桶的排序任务分散到各个计算单元,完成后再合并结果:
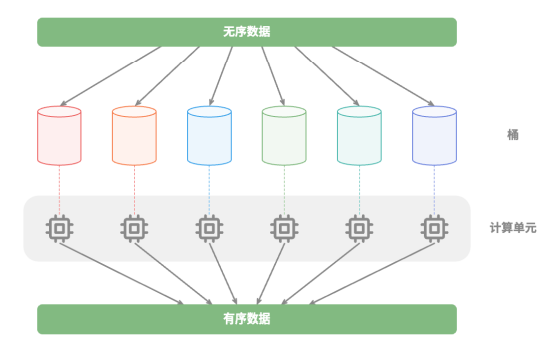
分治常见应用
一方面,分治可以用来解决许多经典算法问题:
寻找最近点对:该算法首先将点集分成两部分,然后分别找出两部分中的最近点对,最后找出跨越两部分的最近点对。
大整数乘法:例如 Karatsuba 算法,它将大整数乘法分解为几个较小的整数的乘法和加法。
矩阵乘法:例如 Strassen 算法,它将大矩阵乘法分解为多个小矩阵的乘法和加法。
汉诺塔问题:汉诺塔问题可以通过递归解决,这是典型的分治策略应用。
求解逆序对:在一个序列中,如果前面的数字大于后面的数字,那么这两个数字构成一个逆序对。求解逆序对问题可以利用分治的思想,借助归并排序进行求解。
另一方面,分治在算法和数据结构的设计中应用得非常广泛:
二分查找:二分查找是将有序数组从中点索引处分为两部分,然后根据目标值与中间元素值比较结果,决定排除哪一半区间,并在剩余区间执行相同的二分操作。
归并排序:。。。。。
快速排序:快速排序是选取一个基准值,然后把数组分为两个子数组,一个子数组的元素比基准值小,另一子数组的元素比基准值大,再对这两部分进行相同的划分操作,直至子数组只剩下一个元素。
桶排序:桶排序的基本思想是将数据分散到多个桶,然后对每个桶内的元素进行排序,最后将各个桶的元素依次取出,从而得到一个有序数组。
树:例如二叉搜索树、AVL 树、红黑树、B 树、B+ 树等,它们的查找、插入和删除等操作都可以视为分治策略的应用。
堆:堆是一种特殊的完全二叉树,其各种操作,如插入、删除和堆化,实际上都隐含了分治的思想。
哈希表:虽然哈希表并不直接应用分治,但某些哈希冲突解决方案间接应用了分治策略,例如,链式地址中的长链表会被转化为红黑树,以提升查询效率。
分治搜索策略
搜索算法分为两大类。
暴力搜索:它通过遍历数据结构实现,时间复杂度为 𝑂(𝑛) 。
自适应搜索:它利用特有的数据组织形式或先验信息,时间复杂度可达到 𝑂(log 𝑛) 甚至 𝑂(1) 。
实际上,时间复杂度为 𝑂(log 𝑛) 的搜索算法通常是基于分治策略实现的,例如二分查找和树。
二分查找的每一步都将问题(在数组中搜索目标元素)分解为一个小问题(在数组的一半中搜索目标元素),这个过程一直持续到数组为空或找到目标元素为止。
树是分治思想的代表,在二叉搜索树、AVL 树、堆等数据结构中,各种操作的时间复杂度皆为 𝑂(log 𝑛)。
二分查找的分治策略如下所示:
问题可以分解:二分查找递归地将原问题(在数组中进行查找)分解为子问题(在数组的一半中进行查找),这是通过比较中间元素和目标元素来实现的。
子问题是独立的:在二分查找中,每轮只处理一个子问题,它不受其他子问题的影响。
子问题的解无须合并:二分查找旨在查找一个特定元素,因此不需要将子问题的解进行合并。当子问题得到解决时,原问题也会同时得到解决。
分治能够提升搜索效率,本质上是因为暴力搜索每轮只能排除一个选项,而分治搜索每轮可以排除一半选项。
1.基于分治实现二分查找
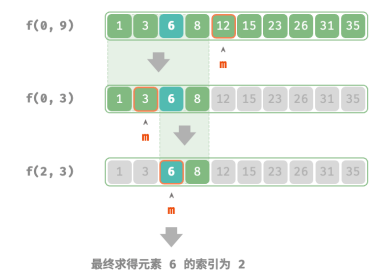
给定一个长度为 𝑛 的有序数组 nums ,其中所有元素都是唯一的,请查找元素 target 。
从分治角度,将搜索区间 [𝑖, 𝑗] 对应的子问题记为 𝑓(𝑖, 𝑗) :
以原问题 𝑓(0, 𝑛 − 1) 为起始点,通过以下步骤进行二分查找。
1.计算搜索区间 [𝑖, 𝑗] 的中点 𝑚 ,根据它排除一半搜索区间。
2.递归求解规模减小一半的子问题,可能为 𝑓(𝑖, 𝑚 − 1) 或 𝑓(𝑚 + 1, 𝑗) ;
3.循环第 1. 步和第 2. 步,直至找到 target 或区间为空时返回。
下图展示了在数组中二分查找元素 6 的分治过程:
/*** File: binary_search_recur.cpp* Created Time: 2023-07-17* Author: krahets (krahets@163.com)*/#include "../utils/common.hpp"/* 二分查找:问题 f(i, j) */
int dfs(vector<int> &nums, int target, int i, int j) {// 若区间为空,代表无目标元素,则返回 -1if (i > j) {return -1;}// 计算中点索引 mint m = (i + j) / 2;if (nums[m] < target) {// 递归子问题 f(m+1, j)return dfs(nums, target, m + 1, j);} else if (nums[m] > target) {// 递归子问题 f(i, m-1)return dfs(nums, target, i, m - 1);} else {// 找到目标元素,返回其索引return m;}
}/* 二分查找 */
int binarySearch(vector<int> &nums, int target) {int n = nums.size();// 求解问题 f(0, n-1)return dfs(nums, target, 0, n - 1);
}/* Driver Code */
int main() {int target = 6;vector<int> nums = {1, 3, 6, 8, 12, 15, 23, 26, 31, 35};// 二分查找(双闭区间)int index = binarySearch(nums, target);cout << "目标元素 6 的索引 = " << index << endl;return 0;
}
构建二叉树问题
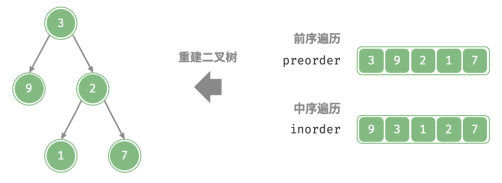
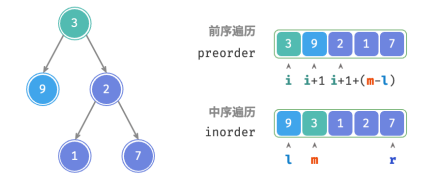
给定一棵二叉树的前序遍历 preorder 和中序遍历 inorder ,请从中构建二叉树,返回二叉树的根节点。假设二叉树中没有值重复的节点(如图所示)。
1.判断是否为分治问题
原问题定义为从 preorder 和 inorder 构建二叉树,是一个典型的分治问题:
问题可以分解:从分治的角度切入,可以将原问题划分为两个子问题:构建左子树、构建右子树,加上一步操作:初始化根节点。而对于每棵子树(子问题),仍然可以复用以上划分方法,将其划分为更小的子树(子问题),直至达到最小子问题(空子树)时终止;
子问题是独立的:左子树和右子树是相互独立的,它们之间没有交集。在构建左子树时,只需关注中序遍历和前序遍历中与左子树对应的部分。右子树同理。
子问题的解可以合并:一旦得到了左子树和右子树(子问题的解),我们就可以将它们链接到根节点上,得到原问题的解。
2.如何划分子树
根据以上分析,这道题可以使用分治来求解,但如何通过前序遍历 preorder 和中序遍历 inorder 来划分左子树和右子树呢?
根据定义,preorder 和 inorder 都可以划分为三个部分。
前序遍历:[ 根节点 | 左子树 | 右子树 ] ,例如图 12‑5 的树对应 [ 3 | 9 | 2 1 7 ] 。
中序遍历:[ 左子树 | 根节点 | 右子树 ] ,例如图 12‑5 的树对应 [ 9 | 3 | 1 2 7 ] 。
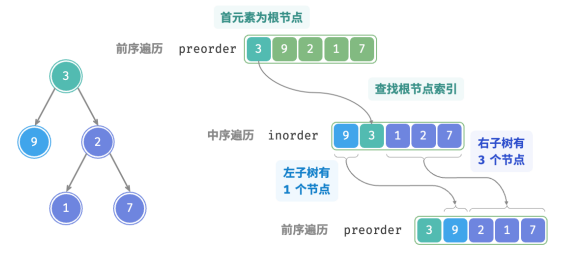
以上图数据为例,可以通过下图所示的步骤得到划分结果:
1.前序遍历的首元素 3 是根节点的值。
2.查找根节点 3 在 inorder 中的索引,利用该索引可将 inorder 划分为 [ 9 | 3 | 1 2 7 ] 。
3.根据 inorder 的划分结果,易得左子树和右子树的节点数量分别为 1 和 3 ,从而可将 preorder 划分为[ 3 | 9 | 2 1 7 ] 。
3.基于变量描述子树区间
根据以上划分方法,已经得到根节点、左子树、右子树在 preorder 和 inorder 中的索引区间。而为了描述这些索引区间,需要借助几个指针变量。
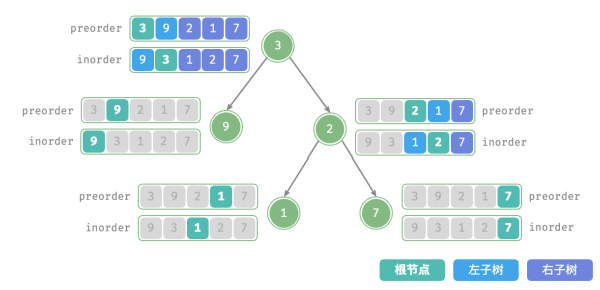
将当前树的根节点在 preorder 中的索引记为 𝑖 ;
将当前树的根节点在 inorder 中的索引记为 𝑚 ;
将当前树在 inorder 中的索引区间记为 [𝑙, 𝑟] 。

通过以上变量即可表示根节点在 preorder 中的索引,以及子树在 inorder 中的索引区间。
右子树根节点索引中的 (𝑚 − 𝑙) 的含义是“左子树的节点数量”:
代码实现
为了提升查询 𝑚 的效率,借助一个哈希表 hmap 来存储数组 inorder 中元素到索引的映射:
/*** File: build_tree.cpp* Created Time: 2023-07-17* Author: Krahets (krahets@163.com)*/#include "../utils/common.hpp"/* 构建二叉树:分治 */
TreeNode *dfs(vector<int> &preorder, unordered_map<int, int> &inorderMap, int i, int l, int r) {// 子树区间为空时终止if (r - l < 0)return NULL;// 初始化根节点TreeNode *root = new TreeNode(preorder[i]);// 查询 m ,从而划分左右子树int m = inorderMap[preorder[i]];// 子问题:构建左子树root->left = dfs(preorder, inorderMap, i + 1, l, m - 1);// 子问题:构建右子树root->right = dfs(preorder, inorderMap, i + 1 + m - l, m + 1, r);// 返回根节点return root;}/* 构建二叉树 */
TreeNode *buildTree(vector<int> &preorder, vector<int> &inorder) {// 初始化哈希表,存储 inorder 元素到索引的映射 unordered_map<int, int> inorderMap;for (int i = 0; i < inorder.size(); i++) {inorderMap[inorder[i]] = i;}TreeNode *root = dfs(preorder, inorderMap, 0, 0, inorder.size() - 1);return root;
}/* Driver Code */
int main() {vector<int> preorder = {3, 9, 2, 1, 7};vector<int> inorder = {9, 3, 1, 2, 7};cout << "前序遍历 = ";printVector(preorder);cout << "中序遍历 = ";printVector(inorder);TreeNode *root = buildTree(preorder, inorder);cout << "构建的二叉树为:\n";printTree(root);return 0;
}
下图展示了构建二叉树的递归过程,各个节点是在向下“递”的过程中建立的,而各条边(引用)是在向上“归”的过程中建立的:
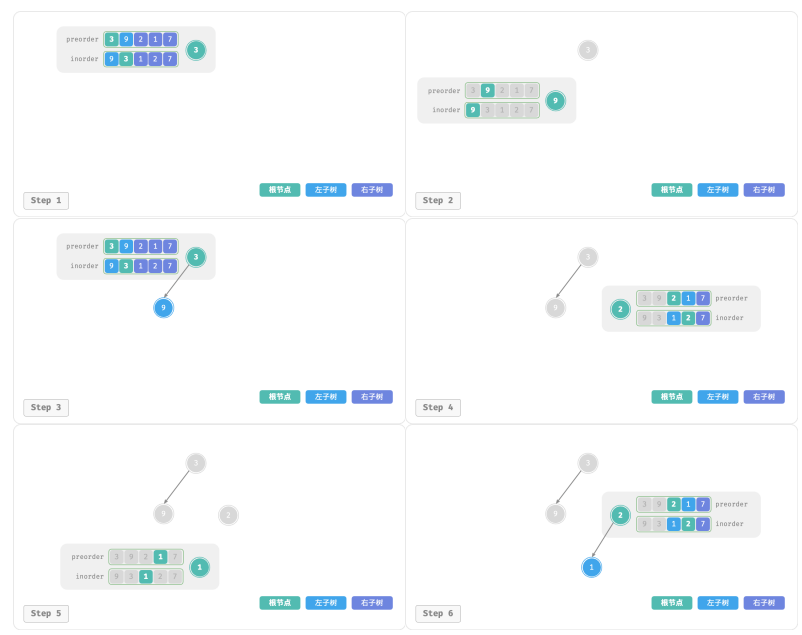
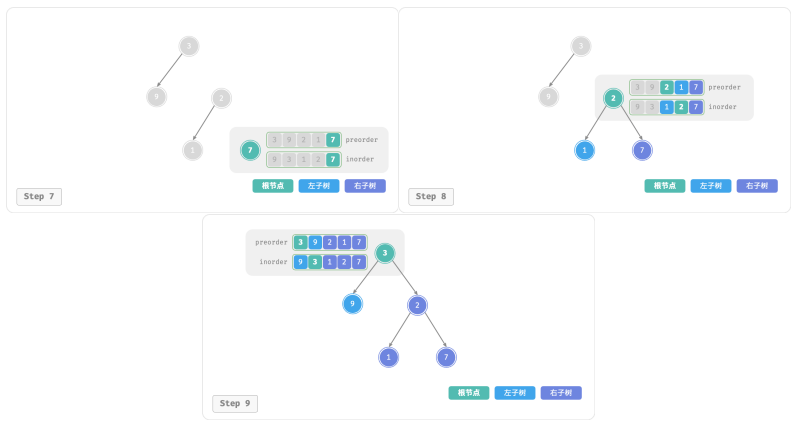
每个递归函数内的前序遍历 preorder 和中序遍历 inorder 的划分结果如图所示:
设树的节点数量为 𝑛 ,初始化每一个节点(执行一个递归函数 dfs() )使用 𝑂(1) 时间。因此总体时间复杂度为 𝑂(𝑛) 。
哈希表存储 inorder 元素到索引的映射,空间复杂度为 𝑂(𝑛) 。在最差情况下,即二叉树退化为链表时,递归深度达到 𝑛 ,使用 𝑂(𝑛) 的栈帧空间。因此总体空间复杂度为 𝑂(𝑛) 。
汉诺塔问题
给定三根柱子,记为 A、B 和 C 。起始状态下,柱子 A 上套着 𝑛 个圆盘,它们从上到下按照从小到大的顺序排列。

任务是要把这 𝑛 个圆盘移到柱子 C 上,并保持它们的原有顺序不变(如图所示)。在移动圆盘的过程中,需要遵守以下规则:
1.圆盘只能从一根柱子顶部拿出,从另一根柱子顶部放入。
2.每次只能移动一个圆盘。
3.小圆盘必须时刻位于大圆盘之上。
将规模为 𝑖 的汉诺塔问题记作 𝑓(𝑖) 。例如 𝑓(3) 代表将 3 个圆盘从 A 移动至 C 的汉诺塔问题。
1.考虑基本情况
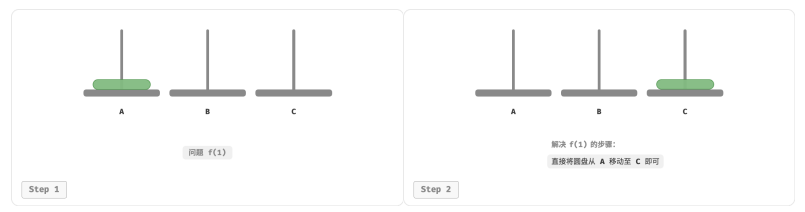
对于问题 𝑓(1) ,即当只有一个圆盘时,将它直接从 A 移动至 C 即可。
对于问题 𝑓(2) ,即当有两个圆盘时,由于要时刻满足小圆盘在大圆盘之上,因此需要借助 B 来完成移动:
1.先将上面的小圆盘从 A 移至 B ;
2.再将大圆盘从 A 移至 C ;
3.最后将小圆盘从 B 移至 C 。

解决问题 𝑓(2) 的过程可总结为:将两个圆盘借助 B 从 A 移至 C 。其中,C 称为目标柱、B 称为缓冲柱。
2.子问题分解
对于问题 𝑓(3) ,即当有三个圆盘时,情况变得稍微复杂了一些。
因为已知 𝑓(1) 和 𝑓(2) 的解,所以我们可从分治角度思考,将 A 顶部的两个圆盘看作一个整体。
执行下图所示的步骤。这样三个圆盘就被顺利地从 A 移至 C 了。
1.令 B 为目标柱、C 为缓冲柱,将两个圆盘从 A 移至 B ;
2.将 A 中剩余的一个圆盘从 A 直接移动至 C ;
3.令 C 为目标柱、A 为缓冲柱,将两个圆盘从 B 移至 C 。
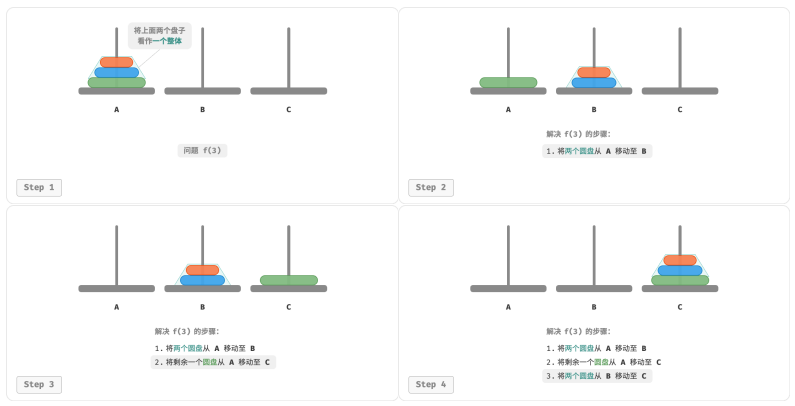
从本质上看,将问题 𝑓(3) 划分为两个子问题 𝑓(2) 和一个子问题 𝑓(1) 。按顺序解决这三个子问题之后,原问题随之得到解决。这说明子问题是独立的,而且解可以合并。
至此,可总结出解决汉诺塔问题的分治策略:将原问题 𝑓(𝑛) 划分为两个子问题 𝑓(𝑛−1) 和一个子问题 𝑓(1) ,并按照以下顺序解决这三个子问题:
1.将 𝑛 − 1 个圆盘借助 C 从 A 移至 B 。
2.将剩余 1 个圆盘从 A 直接移至 C 。
3.将 𝑛 − 1 个圆盘借助 A 从 B 移至 C 。
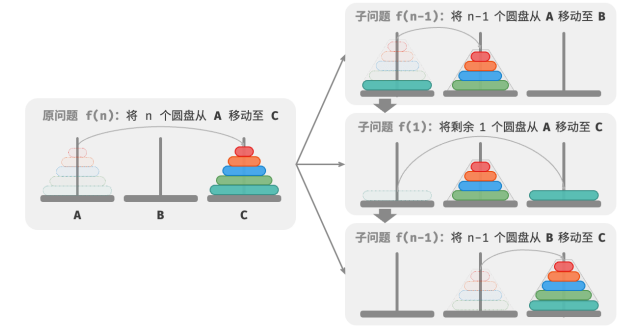
对于这两个子问题 𝑓(𝑛 − 1) ,可以通过相同的方式进行递归划分,直至达到最小子问题 𝑓(1) 。而 𝑓(1) 的解是已知的,只需一次移动操作即可。
3.代码实现
在代码中,声明一个递归函数 dfs(i, src, buf, tar) ,它的作用是将柱 src 顶部的 𝑖 个圆盘借助缓冲柱 buf 移动至目标柱 tar :
// === File: hanota.cpp ===
/* 移动一个圆盘 */
void move(vector<int> &src, vector<int> &tar) {// 从 src 顶部拿出一个圆盘int pan = src.back();src.pop_back();// 将圆盘放入 tar 顶部tar.push_back(pan);
}/* 求解汉诺塔问题 f(i) */
void dfs(int i, vector<int> &src, vector<int> &buf, vector<int> &tar) {// 若 src 只剩下一个圆盘,则直接将其移到 tarif (i == 1) {move(src, tar);return;}// 子问题 f(i-1) :将 src 顶部 i-1 个圆盘借助 tar 移到 bufdfs(i - 1, src, tar, buf);// 子问题 f(1) :将 src 剩余一个圆盘移到 tarmove(src, tar);// 子问题 f(i-1) :将 buf 顶部 i-1 个圆盘借助 src 移到 tardfs(i - 1, buf, src, tar);
}
/* 求解汉诺塔问题 */
void solveHanota(vector<int> &A, vector<int> &B, vector<int> &C) {int n = A.size();// 将 A 顶部 n 个圆盘借助 B 移到 Cdfs(n, A, B, C);
}
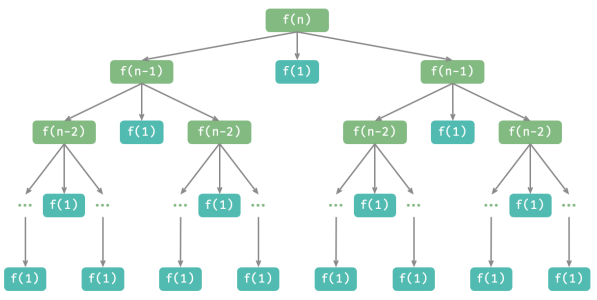
汉诺塔问题形成一棵高度为 𝑛 的递归树,每个节点代表一个子问题,对应一个开启的 dfs()函数,因此时间复杂度为 𝑂(2^𝑛) ,空间复杂度为 𝑂(𝑛) 。
学习地址
学习地址:https://github.com/krahets/hello-algo
重新复习数据结构,所有的内容都来自这里。
相关文章:
数据结构和算法:分治
分治算法 分治(divide and conquer),全称分而治之,是一种非常重要且常见的算法策略。分治通常基于递归实现,包括“分”和“治”两个步骤。 1.分(划分阶段):递归地将原问题分解为两个…...

增强Java技能:使用OkHttp下载www.dianping.com信息
在这篇技术文章中,我们将探讨如何使用Java和OkHttp库来下载并解析www.dianping.com上的商家信息。我们的目标是获取商家名称、价格、评分和评论,并将这些数据存储到CSV文件中。此外,我们将使用爬虫代理来绕过任何潜在的IP限制,并实…...

用友 NC saveXmlToFIleServlet 任意文件上传漏洞复现
0x01 产品简介 用友NC是一款企业级ERP软件。作为一种信息化管理工具,用友NC提供了一系列业务管理模块,包括财务会计、采购管理、销售管理、物料管理、生产计划和人力资源管理等,帮助企业实现数字化转型和高效管理。 0x02 漏洞概述 用友 NC saveXmlToFIleServlet接口处存在…...

JS第九天
今天是第九天,学习了JS中的设置日期和倒计时,计时器以及验证码倒计时,那么话不多说我们开始今天的学习吧 一、日期设置 1.1日期创建 调用 new Date() 来创建一个新的 Date 对象。在调用时可以带有一些参数,创建一个 Date 对象&…...

CSS设置字体样式
目录 前言: 1.font-family: 2.font-style: 3.font-weight: 4.font-size: 5.font-variant: 6.font: 前言: 在网页中字体是重要的组成部分,使用好字体可以让网页更…...
[Java线程池]ExecutorService|CompletionService的区别与选择
这段时间对业务系统做了个性能测试,其中使用了较多线程池的技术,故此做一个技术总结。 这次总结的内容比较多,主要是四个: ExecutorServiceCompletionServiceRunnableCallable 前两个是线程池相关接口,后两个是多线…...
MySQL-SQL编写练习:基本的SELECT语句
基本的SELECT语句 1. SQL的分类 DDL:数据定义语言。CREATE \ ALTER \ DROP \ RENAME \ TRUNCATEDML:数据操作语言。INSERT \ DELETE \ UPDATE \ SELECT (重中之重)DCL:数据控制语言。COMMIT \ ROLLBACK \ SAVEPOINT \ GRANT \ REVOKE 学习技巧…...
)
C++经典面试题目(十九)
1、什么是析构函数?它有什么作用? 析构函数是类的特殊成员函数,用于在对象被销毁时执行清理工作。它的名称与类名相同,前面加上波浪号(~)。析构函数的作用在于确保在对象被销毁时释放占用的资源࿰…...

acwing算法提高之图论--SPFA找负环
目录 1 介绍2 训练 1 介绍 本专题用来记录使用spfa算法来求负环的题目。 2 训练 题目1:904虫洞 C代码如下, #include <cstring> #include <iostream> #include <algorithm> #include <queue>using namespace std;typedef p…...
I2C驱动实验:测试I2C驱动是否与设备匹配
一. 简介 前面一篇文章在设备树中创建 ap3216c设备节点信息。 第二篇文章编写了简单的 I2C设备驱动框架,包括 构造 i2c_driver结构体,i2c_driver的注册与注销等。文章如下: I2C驱动实验:向设备树添加 I2C设备的设备节点信息-C…...

5560.树的直径
蛮不错的一道题目,你要利用树的性质分析出,你只需要维护上一次的树的直径的两个端点就好了 #include<iostream>using namespace std; using ll long long; using pii pair<int,int>; const int N 6e510; const int inf 0x3f3f3f3f; cons…...
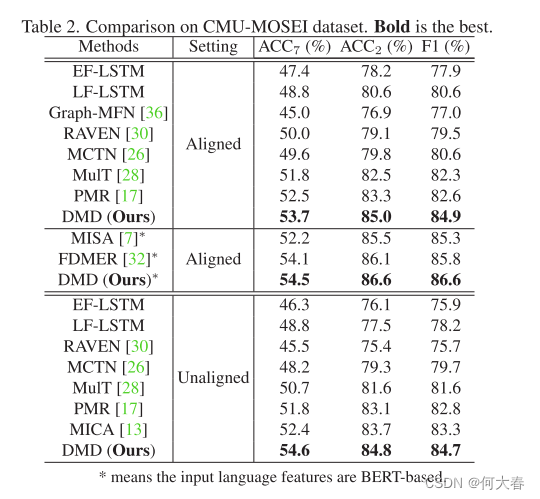
Decoupled Multimodal Distilling for Emotion Recognition 论文阅读
Decoupled Multimodal Distilling for Emotion Recognition 论文阅读 Abstract1. Introduction2. Related Works2.1. Multimodal emotion recognition2.2. Knowledge distillation3. The Proposed Method3.1. Multimodal feature decoupling3.2. GD with Decoupled Multimodal …...

【css】使用display:inline-block后,元素间存在4px的间隔
问题:在本地项目中使用【display: inline-block】,元素间存在4px间隔。打包后发布到外网又不存在这个问题了。 归根结底这是一个西文排版的问题,英文有空格作为词分界,而中文则没有。 此时的元素具有文本属性,只要标签…...

代码执行漏洞
原理:没有对接口输入的内容进行严格的判断 造成攻击者精心构造的代码非法执行 当应用在调用一些能将字符转化为代码的函数(如PHP中的eval)时,没有考虑用户是否能控 制这个字符串,这就会造成代码执行漏洞。 相 关 函 数 : PHP&…...

SQLServer2022安装
首先从官网上下载2022版本SQL Server 下载 | Microsoft 选择此把呢不能运行,适合我们在学习阶段使用。 同时网页往下滑动,下载SSMS 下载后的文件 注意:在运行时最好获取管理员权限运行,第一次在安装时未获取管理员权限最终…...

vue2 配置@指向src
使用的是vue cli创建的项目。 1.安装 path 如果在 Node.js 环境中运行代码,path 模块默认是可用的,则不需要单独安装,否则输入下面命令安装path npm i path -S 2.找到vue.config.js文件: const { defineConfig } require(vue/…...
用友U9 存在PatchFile.asmx接口任意文件上传漏洞
声明: 本文仅用于技术交流,请勿用于非法用途 由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任。 简介 用友U9是由中国用友软件股份有限公司开发的一款企业…...
如何卸载干净 IDEA(图文讲解)
更新时间 2022-12-20 11:一则或许对你有用的小广告 星球 内第一个项目:全栈前后端分离博客项目,演示地址:Weblog 前后端分离博客, 1.0 版本已经更新完毕,正在更新 2.0 版本。采用技术栈 Spring Boot Mybatis Plus Vue 3.x Vit…...
Ansible 之进程管理模块)
自动化运维(十)Ansible 之进程管理模块
Ansible的进程管理模块提供了一种强大而灵活的方式来管理和操作各种进程管理器和服务。无论你使用的是Supervisor、Systemd、传统的init脚本还是Runit,这些模块都可以帮助你轻松地管理服务的生命周期。通过合理地使用这些模块,你可以实现服务的自动化管理,提高系统的可靠性和稳…...

【leetcode279】完全平方数,动态规划解法
原问题:给定一个非负整数n,如果把它视作一些完全平方数的和,那么最少需要多少个完全平方数? 这次学习到一个热心网友的解法:把问题转化兑换零钱问题,然后使用动态规划求解。 比如,给定 n12, 那…...

解决Claude Code频繁封号与Token不足的替代接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的替代接入方案 1. 场景与核心思路 对于依赖Claude Code进行编程辅助的开发者而言࿰…...

工业DC-DC电源模块性能选型解析|钡特电源 VB15-48S24MD 与 URB4824YMD-15WR3 封装互通
在工业控制、通信设备、仪器仪表等领域,工业 DC-DC 模块电源作为核心供电单元,其稳定性、兼容性与性价比直接影响系统整体可靠性。随着国产化进程加速,国产工业电源模块在技术、品质上已达到国际先进水平,成为硬件工程师选型的重要…...
)
从继电器到边缘计算:拆解PAC控制器里的‘智能手机’架构(以Codesys/倍福为例)
从继电器到边缘计算:拆解PAC控制器里的‘智能手机’架构 在工业自动化领域,PAC(可编程自动化控制器)正逐渐取代传统PLC,成为智能制造的核心大脑。这种转变类似于功能手机向智能手机的进化——从单一功能到开放平台&…...

怎样高效使用Mac微信插件:5大实用功能完全指南
怎样高效使用Mac微信插件:5大实用功能完全指南 【免费下载链接】WeChatExtension-ForMac A plugin for Mac WeChat 项目地址: https://gitcode.com/gh_mirrors/we/WeChatExtension-ForMac 想让你的Mac微信变得更加强大吗?WeChatExtension-ForMac正…...

从仿真结果到科研图表:手把手教你用Tonyplot处理Silvaco TCAD数据
从仿真结果到科研图表:手把手教你用Tonyplot处理Silvaco TCAD数据 在半导体器件研究中,TCAD仿真数据的可视化呈现往往决定着研究成果的传达效果。许多研究者花费大量时间完成Silvaco仿真后,却苦于无法将原始数据转化为符合学术出版要求的专业…...

OpencvSharp 算子学习教案之 - Cv2.Sobel
OpencvSharp 算子学习教案之 - Cv2.Sobel 大家好,Opencv在很多工程项目中都会用到,而OpencvSharp则是以C#开发与实现的Opencv操作库,对.NET开发人员友好,但很多API的中文资料、应用场景及常见坑点等缺乏系统性归纳,因此…...
)
别再为Matlab App打包发愁了!手把手教你从Web部署到桌面应用(含Runtime安装避坑)
从零到一:Matlab App Designer全流程打包实战指南 第一次尝试将Matlab App Designer开发的应用程序打包成可执行文件时,那种既期待又忐忑的心情相信很多开发者都深有体会。作为一款强大的交互式开发环境,Matlab App Designer让图形用户界面(G…...

OpenFOAM实战:在interFoam中植入多孔介质源项模拟复杂固壁
1. 多孔介质模拟的工程需求与原理 在流体力学仿真中,我们经常遇到需要处理复杂几何边界的情况。传统方法是通过精细的网格划分来精确描述固体边界,但这会带来两个主要问题:一是计算成本急剧上升,二是对于动态变化的边界࿰…...
深入Linux网络栈:当虚拟机网络中断时,如何像侦探一样解读‘transmit queue timed out‘内核警告
深入Linux网络栈:当虚拟机网络中断时,如何像侦探一样解读transmit queue timed out内核警告 在虚拟化环境中,网络中断往往是最令人头疼的问题之一。当虚拟机突然失去网络连接,而宿主机的物理网卡却显示一切正常时,问题…...

从Concur到特斯拉:为什么伟大产品始于“丑陋”的1.0版本
1. 从一笔74亿美元的收购案说起:为什么别急着给1.0产品判死刑 前几天翻看一些旧资料,看到一篇2014年的行业评论,讲的是德国软件巨头SAP以74亿美元的天价,收购了一家名叫Concur的西雅图公司。当时很多人觉得不可思议,Co…...