【Hadoop技术框架-MapReduce和Yarn的详细描述和部署】
前言:
💞💞大家好,我是书生♡,今天的内容主要是Hadoop的后两个组件:MapReduce和yarn的相关内容。同时还有Hadoop的完整流程。希望对大家有所帮助。感谢大家关注点赞。
💞💞前路漫漫,希望大家坚持下去,不忘初心,成为一名优秀的程序员
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
- 1. MapReduce的概述
- 1.1 MapReduce的定义
- 1.2 MapReduce的两个阶段
- 1.3 MapReduce原理-案例
- 2. YARN概述
- 2. 1 Yarn的概念
- 3. YARN架构
- 3.1 Yarn架构
- 3.2 YARN容器
- 4. MapReduce & YARN 的部署
- 4.1 Yarn集群规划
- 4. 2 Yarn部署
- 4.3 查看YARN的WEB UI页面
- 5. MapReduce & YARN 初体验
- 5. 1 Yarn集群的启停
- 5.2 执行mapreduce任务
- 6. 历史服务器
1. MapReduce的概述
1.1 MapReduce的定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。

1.2 MapReduce的两个阶段
MapReduce是hadoop三大组件之一,是分布式计算组件,分为两个阶段:
- Map阶段 : 将数据拆分到不同的服务器后执行Maptask任务,得到一个中间结果。
- Reduce阶段 : 将Maptask执行的结果进行汇总,按照Reducetask的计算 规则获得一个唯一的结果
MapReduce的核心思想是: 先分(Map)再和(Reduce)
分散->汇总模式:
- 将数据分片,多台服务器各自负责一部分数据处理
- 然后将各自的结果,进行汇总处理
- 最终得到想要的计算结果
1.3 MapReduce原理-案例
我们以一个案例来演示一下他的流程:
假设有如下文件,内部记录了许多的单词。且已经开发好了一个MapReduce程序,功能是统计每个单词出现的次数。
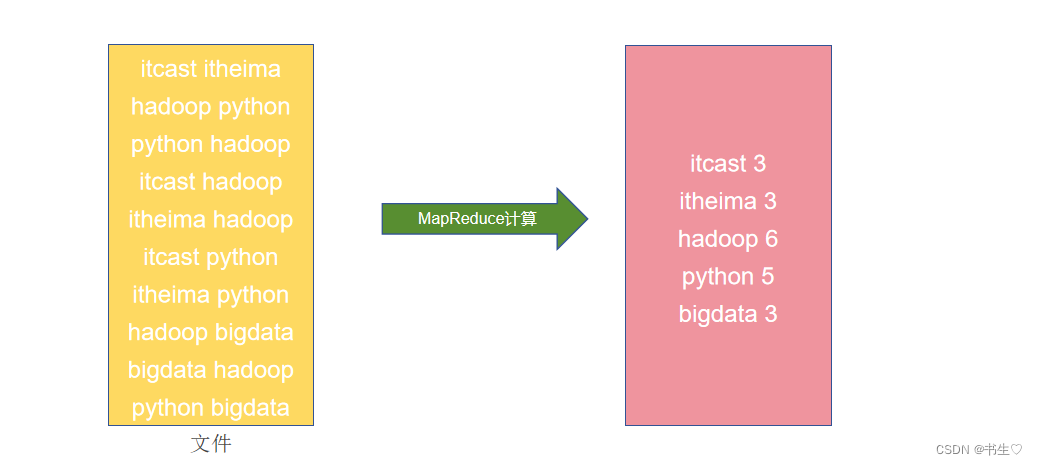
假定有4台服务器用以执行MapReduce任务,可以3台服务器执行Map,1台服务器执行Reduce
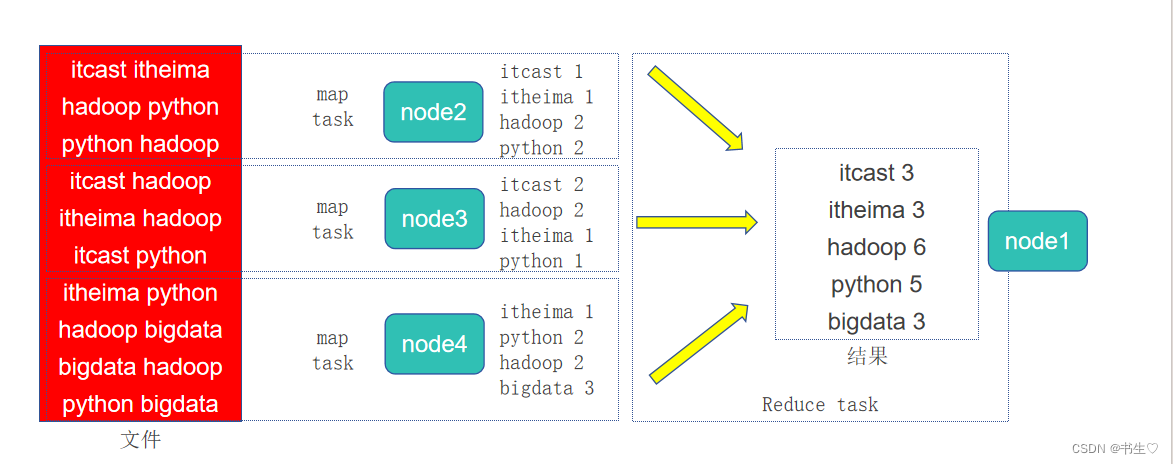
注意:
MapReduce可供Java、Python等语言开发计算程序
2. YARN概述
MapReduce是基于YARN运行的,即没有YARN”无法”运行MapReduce程序
2. 1 Yarn的概念
Yarn是Hadoop的分布式资源调度平台,负责为集群的运算提供运算资源。如果把分布式计算机和单个计算机相对应的话,HDFS就相当于计算机的文件系统,Yarn就是计算机的操作系统,MapReduce就是计算机上的应用程序。

yarn是一个分布式资源调度平台,主要是给MapReduce调度资源。
- 调度的有:cpu资源和内存资源
yarn中资源调度的目的是什么?
提高集群资源的利用率,防止部分程序恶意占用资源, 采用申请制,申请多少资源就使用多少资源
向YARN申请使用资源,YARN分配好资源后运行,空闲资源可供其它程序使用
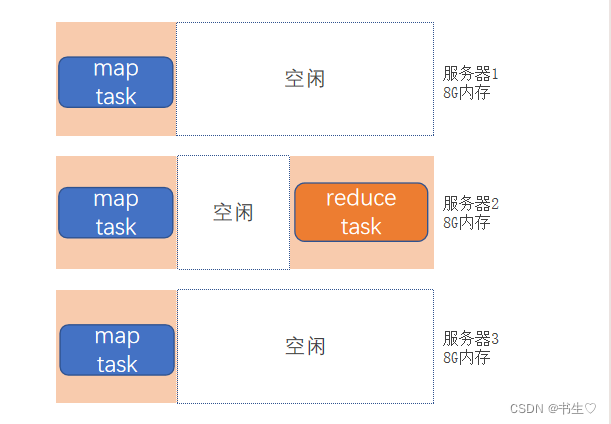
程序向YARN申请所需资源
YARN为程序分配所需资源供程序使用
3. YARN架构
3.1 Yarn架构
Yarn既然是分布式那一定是一个标准的主从架构
- 主角色ResourceManager: 统一管理和分配集群资源,监控每一个NodeManager的健康状况.
- 从角色NodeManager: 统计汇报集群资源给RM,当前服务器集群资源的使用和容器拆分.监督资源回收
YARN,主从架构,有2个角色
- 主(Master)角色:ResourceManager
- 从(Slave) 角色:NodeManager
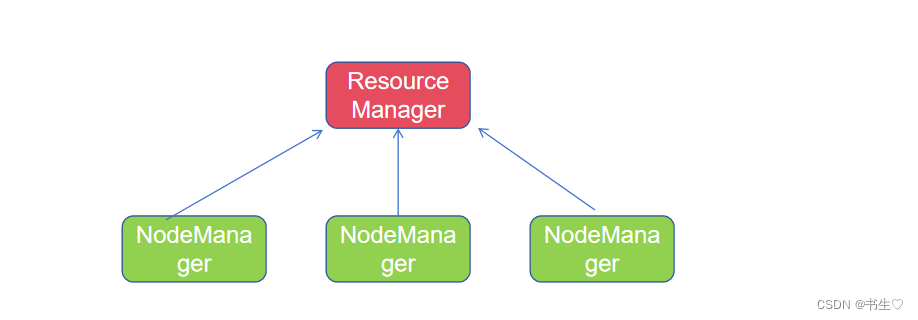
ResourceManager:整个集群的资源调度者, 负责协调调度各个程序所需的资源。
NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。
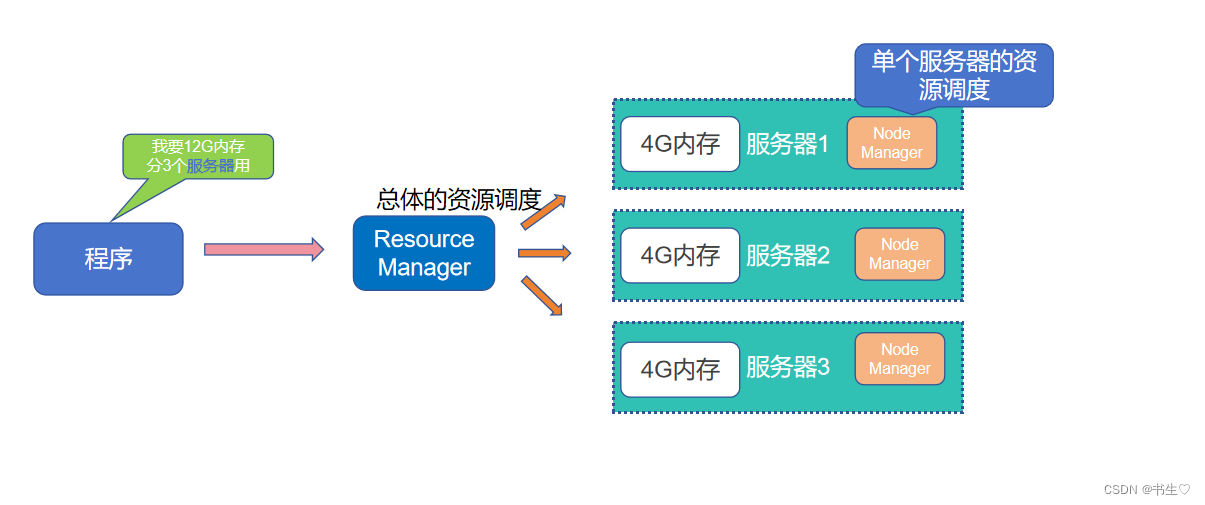
3.2 YARN容器
我们要在服务器上分配资源,怎么才能准确的分配资源呢?
这个时候我们就要引入容器这个概念。
容器机制:容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段
NodeManager,在程序没有执行时就预先抢占一部分资源划分为容器,等待服务进行使用
程序运行时先申请资源,RM分配资源后,由NodeManager划分出相应的资源支持程序运行
程序运行期间无法突破资源限制最多只能使用容器范围内的资源
容器资源分为: 内存资源和cpu资源
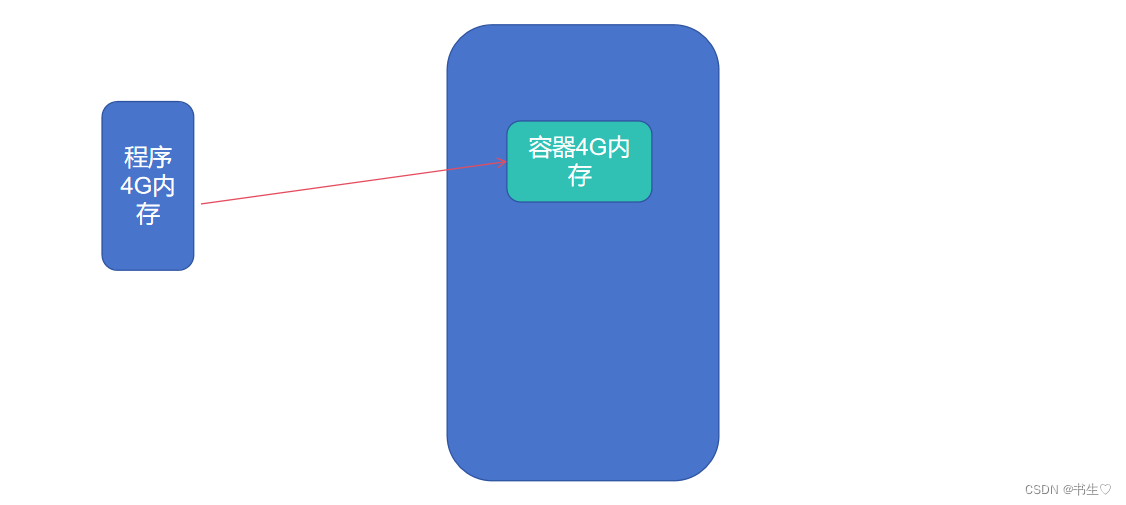
注意:
分配集群资源时,容器可以合并,但是不能拆分.
4. MapReduce & YARN 的部署
4.1 Yarn集群规划
YARN的集群规划
思考1: 哪一个角色占用资源最多??? ResourceManager
所以我们将RM放置在node1中,因为node1的服务器性能最好
思考2: hadoop中yarn集群可以和hdfs集群在同一台服务器中么?
可以,一般Hadoop服务部署时,hdfs和yarn逻辑上分离,物理上在一起.
yarn分配的是内存和cpu资源, 从而运行MapReduce计算任务,而该计算任务需要获取计算数据,计算数据存放在hdfs上,所以他们物理上在一起后数据传输速度快.
4. 2 Yarn部署
前提:Yarn的部署实在hdfs已经部署成功下完成的。
所以大家需要先去部署hdfs大家可以参考我的上一篇博客。
Hdfs的基础概念与部署🤞🤞🤞
- 先关闭HDFS集群
stop-dfs.sh
- 修改配置文件
先进入目录下进行修改
cd /export/server/hadoop/etc/hadoop
3.修改mapred-site.xml文件
大家主需要把我下面的代码直接复制过去就可以。
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property><!-- MR程序历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>node1:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value>
</property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 配置 yarn-site.xml文件
额外配置项的功能后续会慢慢接触到
目前先复制粘贴配置上使用即可
同理:直接复制
<!-- 设置YARN集群主角色运行机器位置 -->
<property><name>yarn.resourcemanager.hostname</name><value>node1</value>
</property><!-- 为MapReduce开启shuffle服务 -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property><!-- NodeManager本地数据存储路径 -->
<property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value>
</property><!-- NodeManager日志数据存储路径 -->
<property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value>
</property><!-- 设置yarn历史服务器地址 -->
<property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value>
</property><!-- 开启日志聚集 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
- 修改完node1上的配置文件后,需要远程发送到node2和node3中
scp -r /export/server/hadoop root@node2:/export/server
scp -r /export/server/hadoop root@node3:/export/server
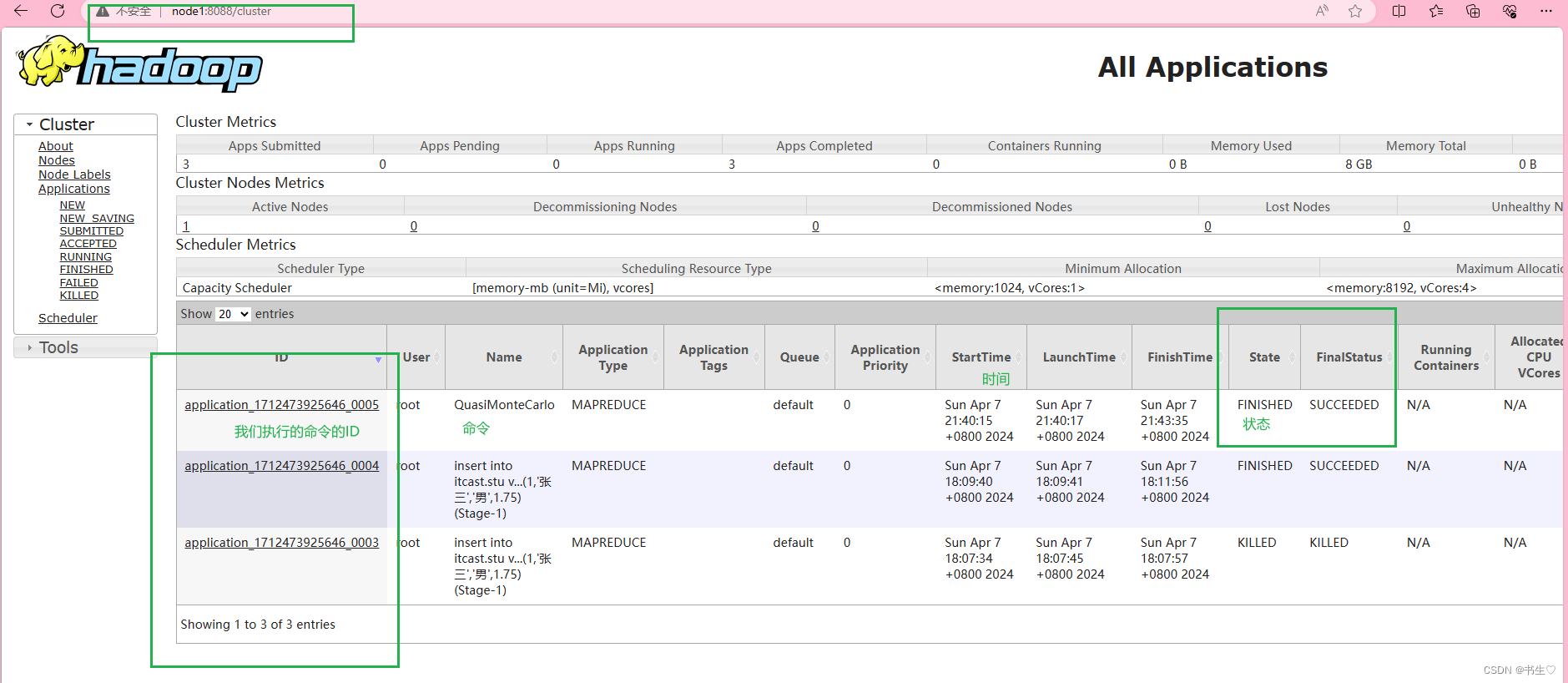
4.3 查看YARN的WEB UI页面
我们在配置完Yarn文件之后,通用端口号访问Yarn的页面
能进入到这个页面,说明我们的Yarn配置成功
node1:8088
5. MapReduce & YARN 初体验
我们这里就只是简单的了解一下怎么使用,具体的使用我们在后面会详细的说明。
5. 1 Yarn集群的启停
我们在之前学过hdfs的启停
- yarn和hdfs是一样的:通过start和stop
# 启动yarn集群
start-yarn.sh
# 停止yarn集群
stop-yarn.sh
- 当然我们也可以通过单启单停
yarn --daemon start|stop|status resourcemanager或者nodemanager
- 我们还可以直接全部启动所有的服务:一键自动hdfs和yarn集群
# 启动
start-all.sh
# 终止
stop-all.sh
5.2 执行mapreduce任务
保证服务启动且可以正常使用(yarn 和hdfs)
- 求Π
先进入到这个目录下
cd /export/server/hadoop/share/hadoop/mapreduce
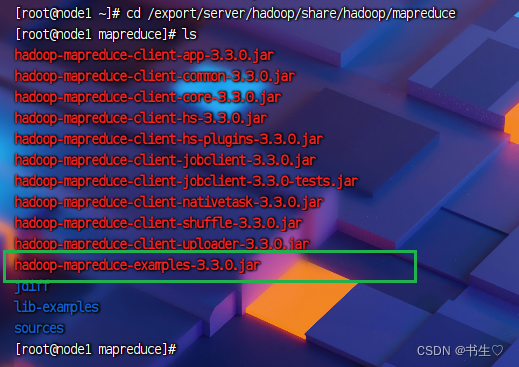
使用已经有的命令
注意:这个命令是我们已经封装好的
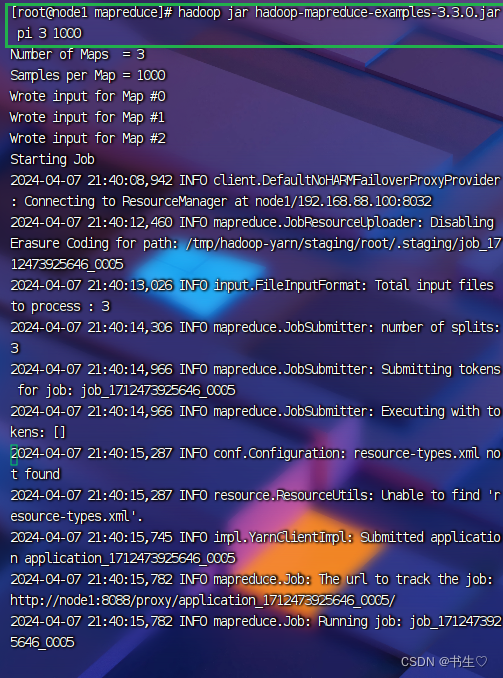
hadoop jar hadoop-mapreduce-examples-3.3.4.jar pi 3 1000
2. 词频统计
# 1. 创建一个文件words.txt内部书写如下单词组合
itheima itcast itheima itcast
hadoop hdfs hadoop hdfs
hadoop mapreduce hadoop yarn
itheima hadoop itcast hadoop
itheima itcast hadoop yarn mapreduce# 2. 创建输入和输出目录,并且将words文件上传到输入目录中
hadoop fs -mkdir -p /input/wordcount
hadoop fs -mkdir /output
hadoop fs -put words.txt /input/wordcount/# 3. 执行示例
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount
hdfs://node1:8020/input/wordcount
hdfs://node1:8020/output/wc# 注意: 输入目录必须存在,输出目录必须不存在,否则报错
6. 历史服务器
历史服务器:主要是为了将各个NodeManager中零散的log日志聚集起来,存放到hdfs中,启动一个历史服务器,用来统一查看历史服务信息(计算任务的执行信息)
我们需要配置一下历史服务器:
cd /export/server/hadoop/etc/hadoop
yarn-site.xml文件
<!-- 设置yarn历史服务器地址 -->
<property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value>
</property><!-- 开启日志聚集 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
注意:修改完配置以后,一定要重启hadoop服务,否则无法生效
历史服务器启动
mapred --daemon start historyserver

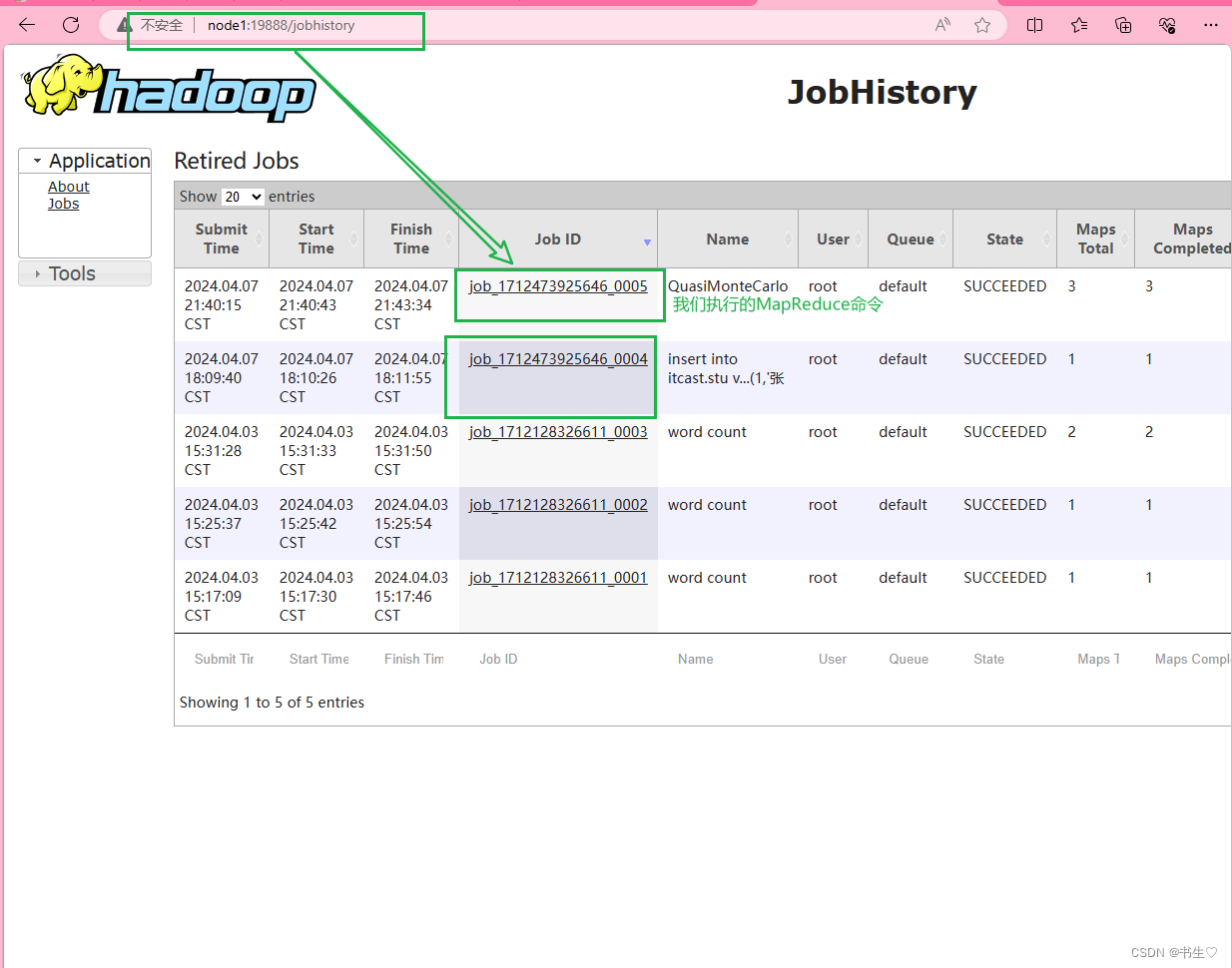
我们直接通过端口号19888,通过浏览器访问
node1:19888
相关文章:
【Hadoop技术框架-MapReduce和Yarn的详细描述和部署】
前言: 💞💞大家好,我是书生♡,今天的内容主要是Hadoop的后两个组件:MapReduce和yarn的相关内容。同时还有Hadoop的完整流程。希望对大家有所帮助。感谢大家关注点赞。 💞💞前路漫漫&…...
)
蓝桥杯刷题 前缀和与差分-[3507]异或和之和(C++)
题目描述 给定一个数组 Ai,分别求其每个子段的异或和,并求出它们的和。 或者说,对于每组满足 1≤L≤R≤n 的 L,R求出数组中第 L 至第 R 个元素的异或和。 然后输出每组 L,R 得到的结果加起来的值。 输入格式 输入…...

background背景图参数边渐变CSS中创建背景图像的渐变效果
效果:可以看到灰色边边很难受,希望和背景融为一体 原理: 可以使用线性渐变(linear-gradient)或径向渐变(radial-gradient)。以下是一个使用线性渐变作为背景图像 代码: background: linear-gradient(to top, rgba(255,255,255,0)…...

『大模型笔记』吴恩达:AI 智能体工作流引领人工智能新趋势
吴恩达:AI 智能体工作流引领人工智能新趋势 文章目录 一. 概述二. AI 智能体的设计模式2.1. 反思(Reflection)2.2. 使用工具(Tool use)2.3. 规划(Planning)2.4. 多智能体协作(Multi-agent collaboration)三. 最后总结四. 参考文献一. 概述 我期待与大家分享我在 AI 智能体方面…...
)
腾讯光子工作室群 一面 (30min)
问题: 你毕业是打算考研还是直接工作 深挖项目(介绍、剖析遇到问题如何解决): 你在进行攻击的时候会不会有穿模的情况,怎么解决 为什么会造成卡顿(多嘴说的) 说说行为树和状态机之间的差别 …...
)
Linux的信号栈的实现(1)
作者 pengdonglin137@163.com 环境 Linux 6.5 + ARM64 概述 在前一篇文章中介绍了Linux系统中的几种栈以及它们之间的切换,进程在用户态和内核态会使用不同的栈,在用户态的主线程和其他线程都有各自的栈,此外进程在执行信号处理程序时也需要栈,那么这个栈来自哪呢? …...
Python学习笔记——heapq
堆排序 思路 堆排序思路是: 将数组以二叉树的形式分析,令根节点索引值为0,索引值为index的节点,子节点索引值分别为index*21、index*22;对二叉树进行维护,使得每个非叶子节点的值,都大于或者…...
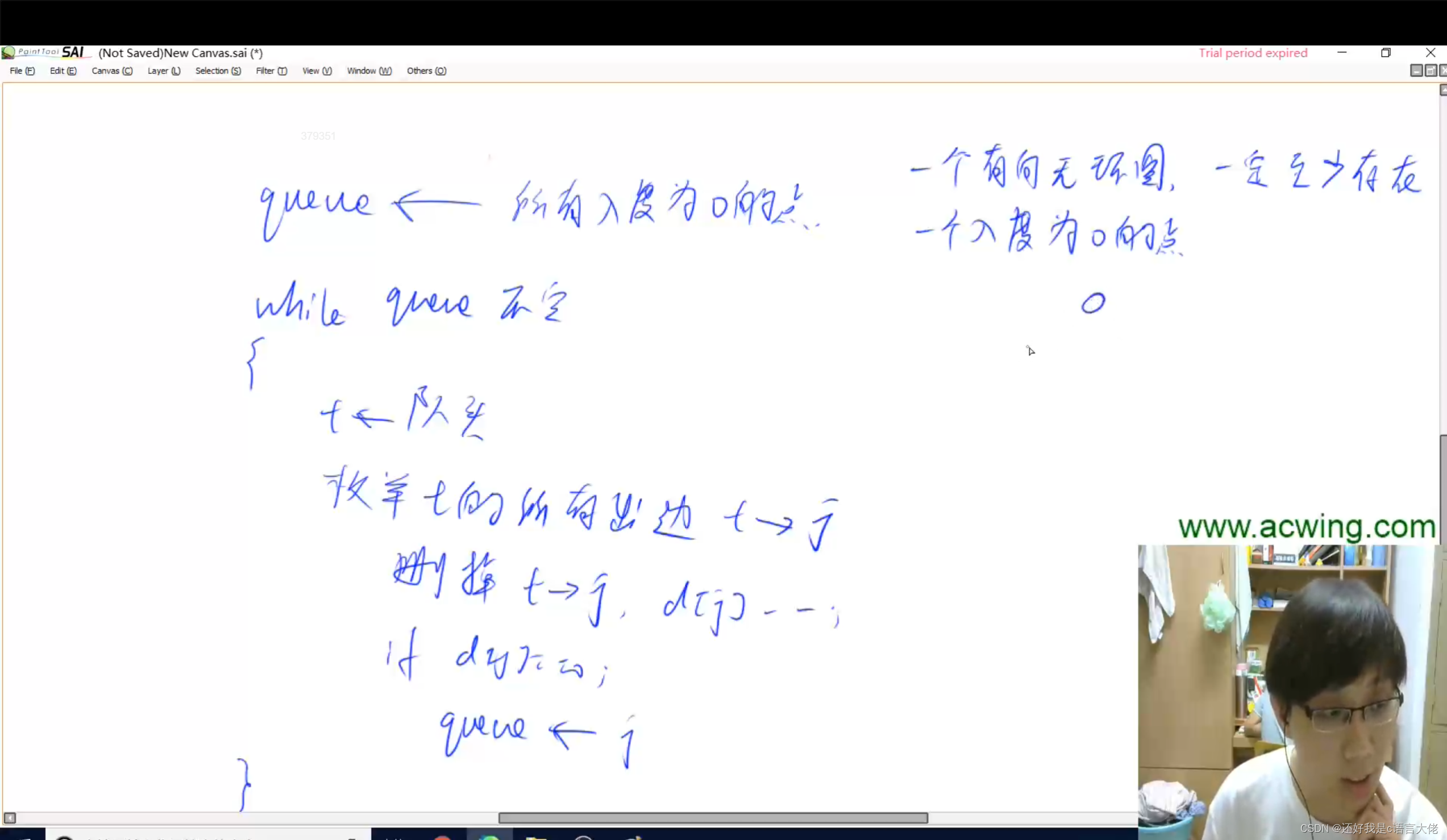
搜索与图论——拓扑排序
有向图的拓扑排序就是图的宽度优先遍历的一个应用 有向无环图一定存在拓扑序列(有向无环图又被称为拓扑图),有向有环图一定不存在拓扑序列。无向图没有拓扑序列。 拓扑序列:将一个图排成拓扑序后,所有的边都是从前指…...

linux CentOS7配置docker的yum源并安装
[TOC](这里写目录标题 配置yum源Docker的自动化安装一些其他启动相关的命令: 配置yum源 使用以下命令下载CentOS官方的yum源文件 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo 清除yum缓存 yum clean all 更新yum缓存…...
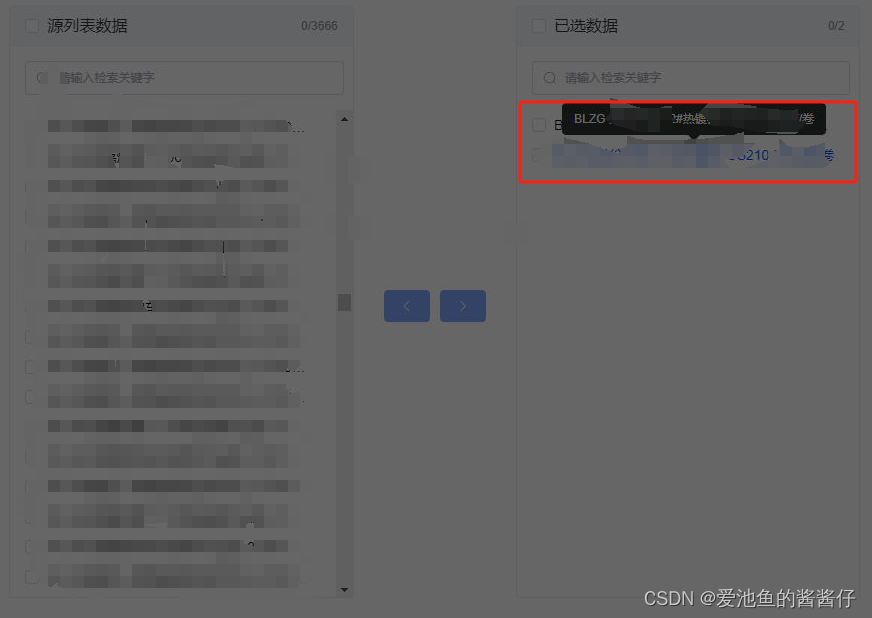
vue结合Elempent-Plus/UI穿梭框更改宽度以及悬浮文本显示
由于分辨率不同会导致文本内容显示不全,如下所示: 因此需要 1、悬浮到对应行上出现悬浮信息 实现代码如下所示: 这里只演示Vue3版本代码,Vue2版本不再演示 区别就在插槽使用上Vue3使用:#default“”;Vu…...

汇川PLC学习Day4:电机参数和气缸控制参数
汇川PLC学习Day4:伺服电机参数和气缸控制参数 一、伺服电机参数二、气缸参数1. 输入IO映射(1)输入IO映射(2) 输入IO触摸屏标签显示映射 2. 输出IO映射(1)输出IO映射(2) …...
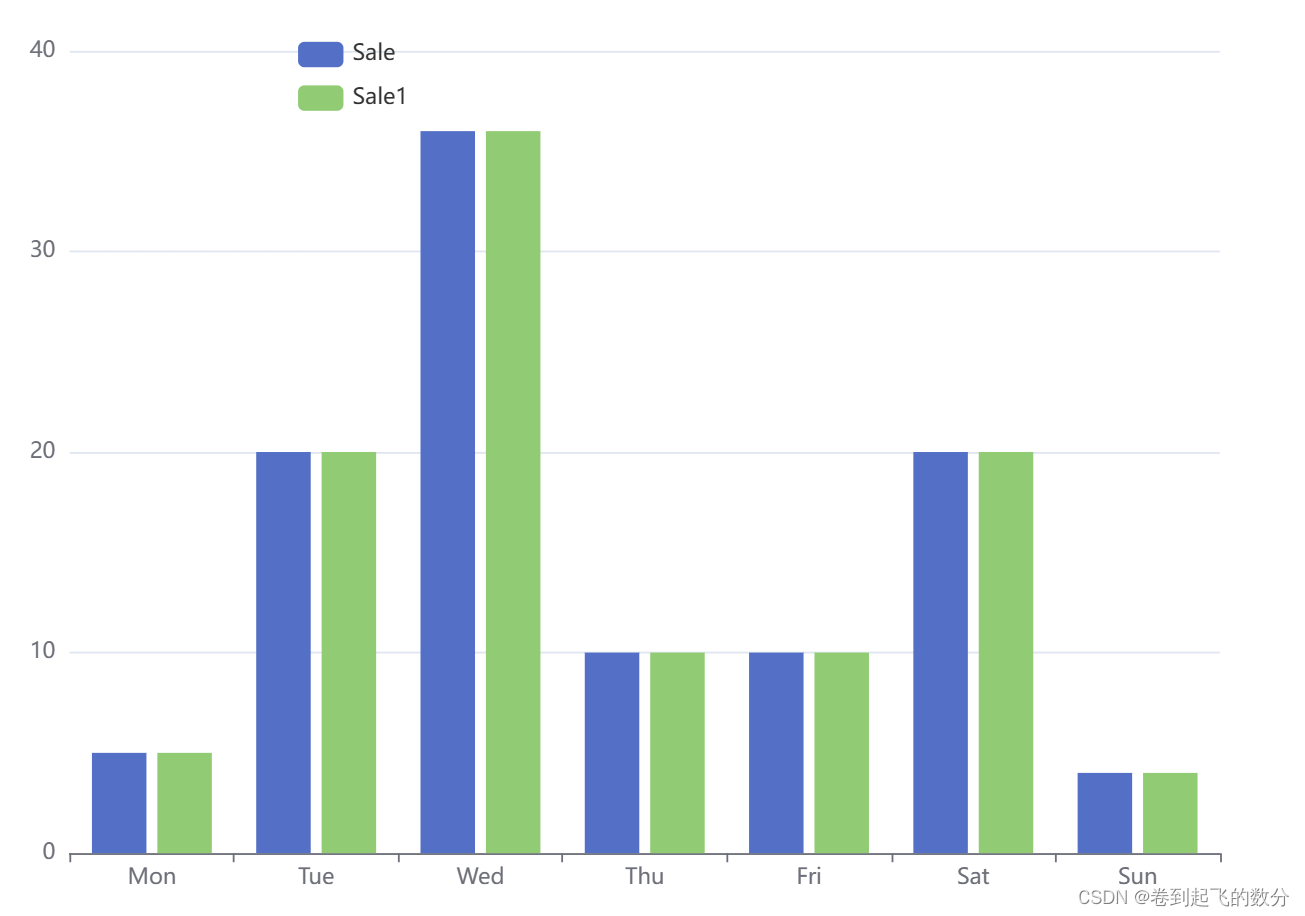
数据可视化高级技术Echarts(快速上手柱状图进阶操作)
目录 1.Echarts的配置 2.程序的编码 3.柱状图的实现(入门实现) 相关属性介绍(进阶): 1.标记最大值/最小值 2.标记平均值 3.柱的宽度 4. 横向柱状图 5.colorBy series系列(需要构造多组数据才能实现…...

【数据结构与算法】力扣 206. 反转链表
题目描述 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 示例 1: 输入: head [1,2,3,4,5] 输出: [5,4,3,2,1]示例 2: 输入: head [1,2] 输出: [2,1]示例 3&#…...

【随笔】Git 高级篇 -- 本地栈式提交 rebase | cherry-pick(十七)
💌 所属专栏:【Git】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! 💖 欢迎大…...

数据结构-- 基于顺序表的通讯录代码讲解
我们了解顺序表之后来一个比较简单的小项目来巩固一下. 每一个函数我都进行了详细的补充, 各位可以仔细阅读。我将整个项目分为了Contact.h 、Contact.c和test.c三个文件中,其中Contact.h用于函数声明和结构体创建,Contact.c用于函数的实现,t…...
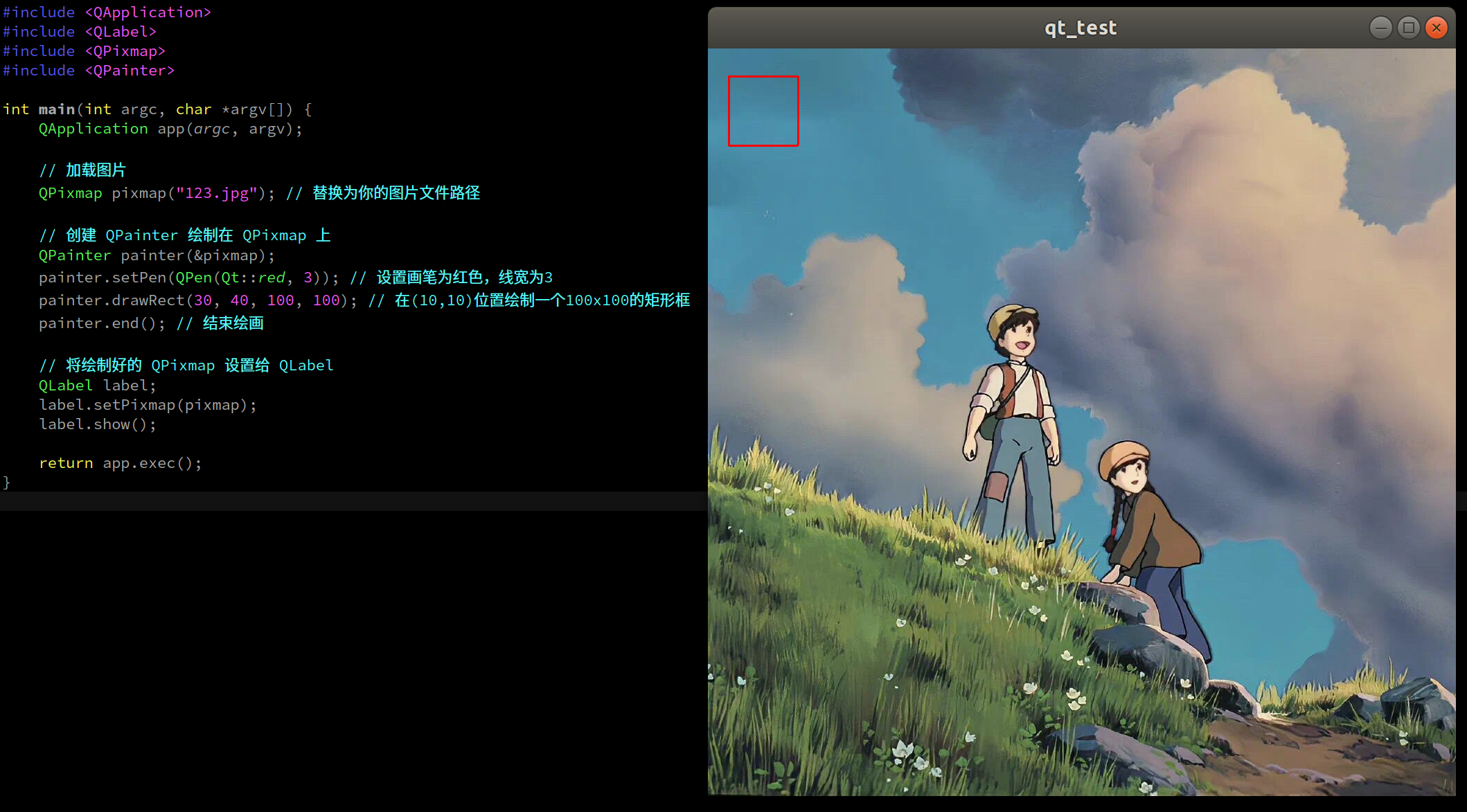
qt-C++笔记之QLabel加载图片
qt-C笔记之QLabel加载图片 —— 2024-04-06 夜 code review! 文章目录 qt-C笔记之QLabel加载图片0.文件结构1.方法一:把图片放在项目路径下,在 .pro 文件中使用 DISTFILES添加图片文件1.1.运行1.2.qt_test.pro1.3.main.cpp 2.方法二:不在 .pr…...
Unity中UI系统1——GUI
介绍 工作原理和主要作用 基本控件 a.文本和按钮控件 练习: b.多选框和单选框 练习: 用的是第三种方法 c.输入框和拖动框 练习: 练习二: e.图片绘制和框 练习: 复合控件 a.工具栏和选择网格 练习: b.滚动视…...

GIt 删除某个特定commit
目的 多次commit,想删掉中间的一个/一些commit 操作方法 一句话说明:利用rebase命令的d表示移除commit的功能,来移除特定的commit # 压缩这3次commit,head~3表示从最近1次commit开始,前3个commit git rebase -i head~3rebase…...

Django --静态文件
静态文件 除了由服务器生成的HTML文件外,WEB应用一般需要提供一些其它的必要文件,比如图片文件、JavaScript脚本和CSS样式表等等,用来为用户呈现出一个完整的网页。在Django中,我们将这些文件统称为“静态文件”,因为…...
蓝桥杯第十三届省赛C++B组(未完)
目录 刷题统计 修剪灌木 X进制减法 【前缀和双指针】统计子矩阵 【DP】积木画 【图DFS】扫雷 李白打酒加强版 DFS (通过64%,ACwing 3/11); DFS(AC) DP(AC) 砍竹子(X) 刷题统计 题目描述 小明决定从下周一开始努力刷题准…...

AI 入门 30 天挑战 - Day 28 - 前沿技术概览
🌟 完整项目和代码 本教程是 AI 入门 30 天挑战 系列的一部分! 💻 GitHub 仓库: https://github.com/Lee985-cmd/AI-30-Day-Challenge📖 CSDN 专栏: https://blog.csdn.net/m0_67081842?typeblog⭐ 欢迎 Star 支持!…...

3个步骤掌握微信聊天记录导出:让珍贵对话永不丢失的实用方法 [特殊字符]
3个步骤掌握微信聊天记录导出:让珍贵对话永不丢失的实用方法 📱 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitH…...

Fuzzz靶场学习笔记
前言正文1、端口扫描2、安卓端口反向代理3、目录遍历获取RSA密钥4、用户提权前言 本文介绍了Kali Linux的基本使用技巧和nmap常见命令,重点演示了端口扫描、安卓设备反向代理和权限提升过程。通过nmap扫描发现安卓设备5555端口开放,使用adb工具连接后&a…...

通过环境变量统一管理Taotoken密钥提升项目安全与便捷性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过环境变量统一管理Taotoken密钥提升项目安全与便捷性 在开发基于大模型的应用时,API密钥的管理是一个基础但至关重要…...

XYBot V2:基于Python的插件化微信机器人框架开发与部署指南
1. 项目概述:一个功能丰富的微信机器人框架最近在折腾一个挺有意思的开源项目,叫XYBot V2。简单来说,它是一个基于Python的微信机器人框架,能让你在微信里实现各种自动化交互和趣味功能。项目作者HenryXiaoYang已经声明因个人原因…...

openclaw官网入口中文版_一键1分钟免费使用小龙虾AI!
好的,这是为您撰写的文章: OpenClaw官网入口中文版_一键1分钟免费使用小龙虾AI! 在当今人工智能技术蓬勃发展的时代,便捷、高效的AI工具正逐渐成为我们工作和学习的得力助手。今天,就让我们一起了解一个新兴的AI平台—…...

CoPaw智能体工厂:基于三层策略与安全协议的自动化创建工具
1. 项目概述:一个为CoPaw智能体平台量身定制的“智能体工厂”如果你正在使用CoPaw(或者更广为人知的AgentScope)来构建和管理你的AI智能体,那么你肯定遇到过这样的场景:每次想创建一个新的智能体工作区(wor…...

JAVA学习之JAVASE基础
集合列表ListArrayList利用空参创建的集合,在底层创建一个默认长度为0的数组添加第一个元素时,底层会创建一个新的长度为10的数组存满时,会扩容1.5倍一次存多个元素,1.5倍还不够,则新创建的数组长度以实际为准LinkedLi…...

调试STM32双CAN通信的5个常见坑:从TJA1050供电到过滤器配置的避坑指南
STM32双CAN通信实战:从硬件陷阱到软件优化的深度排错指南 当你在实验室里搭建好STM32F407VE与两片TJA1050组成的双CAN系统,满心期待看到数据流畅传输时,示波器上却只有死寂的直线——这种挫败感我太熟悉了。双CAN系统调试就像在雷区跳舞&…...

iSCSI共享存储实战:从单服务器配置到多主机集群数据访问测试
1. iSCSI共享存储基础概念与场景解析 第一次接触iSCSI时,我被它神奇的网络磁盘共享能力震撼到了——就像给服务器插上了"无线硬盘"。iSCSI(Internet Small Computer System Interface)本质上是通过IP网络传输SCSI协议,把…...