ElasticSearch - 分布式文档索引、搜索、更新和删除文档的过程
文章目录
- 1. 分布式文档存储
- 1. 路由一个文档到一个分片中
- 2. 主分片和副本分片如何交互
- 3. 新建、索引和删除文档
- 4. 取回一个文档
- 5. 局部更新文档
- 2. ElasticSearch相关问题
- 1. 路由计算方式?
- 2. 分片控制
- 3. 分布式文档写入(索引)的过程?
- 4. 分布式文档搜索的过程?
- 5. 分布式文档更新和删除的过程?
1. 分布式文档存储
1. 路由一个文档到一个分片中
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing 的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。
2. 主分片和副本分片如何交互
为了说明目的, 我们 假设有一个集群由三个节点组成。 它包含一个叫 blogs 的索引,有两个主分片,每个主分片有两个副本分片。相同分片的副本不会放在同一节点,所以我们的集群看起来像 Figure 8, “有三个节点和一个索引的集群”
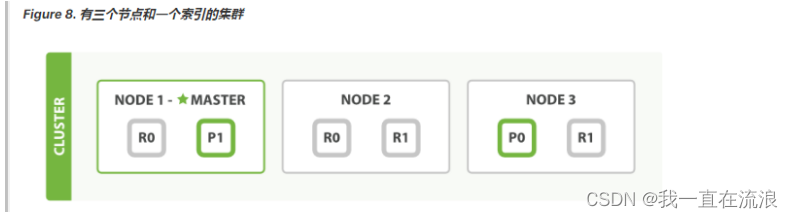
我们可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。 在下面的例子中,将所有的请求发送到 Node 1 ,我们将其称为 协调节点(coordinating node) 。
3. 新建、索引和删除文档
新建、索引和删除 请求都是 写 操作, 必须在主分片上面完成之后才能被复制到相关的副本分片,如下图所示 Figure 9, “新建、索引和删除单个文档” .
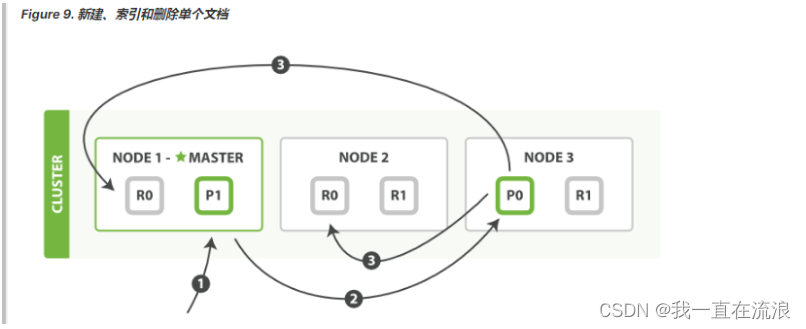
以下是在主副分片和任何副本分片上面 成功新建,索引和删除文档所需要的步骤顺序:
- 客户端向
Node 1发送新建、索引或者删除请求。 - 节点使用文档的
_id确定文档属于分片 0 。请求会被转发到Node 3,因为分片 0 的主分片目前被分配在Node 3上。 Node 3在主分片上面执行请求。如果成功了,它将请求并行转发到Node 1和Node 2的副本分片上。一旦所有的副本分片都报告成功,Node 3将向协调节点报告成功,协调节点向客户端报告成功。
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。
4. 取回一个文档
可以从主分片或者从其它任意副本分片检索文档 ,如下图所示 Figure 10, “取回单个文档” .
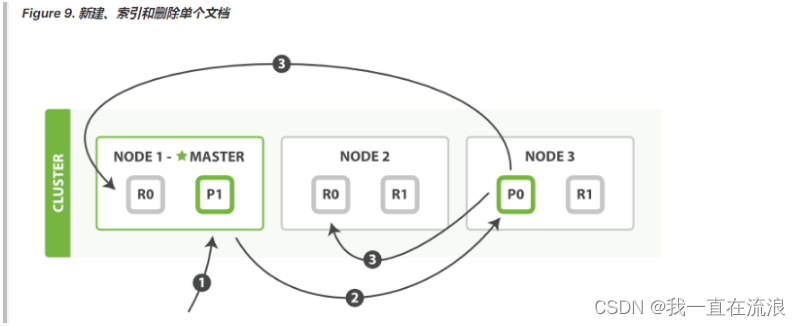
以下是从主分片或者副本分片检索文档的步骤顺序:
1、客户端向 Node 1 发送获取请求。
2、节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到 Node 2 。
3、Node 2 将文档返回给 Node 1 ,然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
5. 局部更新文档
如 Figure 11, “局部更新文档” 所示,update API 结合了先前说明的读取和写入模式。
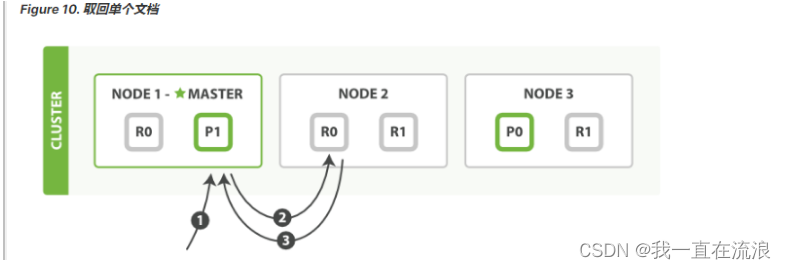
以下是部分更新一个文档的步骤:
- 客户端向
Node 1发送更新请求。 - 它将请求转发到主分片所在的
Node 3。 Node 3从主分片检索文档,修改_source字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。- 如果
Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和Node 2上的副本分片,重新建立索引。 一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果Elasticsearch仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。
2. ElasticSearch相关问题
1. 路由计算方式?
1.1 路由解决的问题
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 P0还是P1和P2中呢?

首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。

这就解释了为什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
你可能觉得由于Elasticsearch主分片数量是固定的会使索引难以进行扩容。实际上当你需要时有很多技巧可以轻松实现扩容。
所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing 的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。相同的路由值总是指向同一个分片。换个说法就是:“之前使用某个路由值将文档存放在特定的分片上,那么搜索时,也去相应的分片查找该文档。”
1.2 路由实战
通过路由控制Elasticsearch,选择将文档发送到哪个主分片。此时需要指定路由参数routing。路由参数值无关紧要,可以选择任何值。重要的是在将不同文档放到同一个分片上时,需要使用相同的值。简单地说,给不同的文档使用相同的路由参数值可以确保这些文档被索引到相同分片中。向Elasticsearch提供路由信息有多种途径。最简单的办法是在索引文档时加一个routing URI参数。例如:

查询时,请求会被发送至所有的分片,所以最关键的事情就是使用一个能均匀分发数据的算法,让每个分片都包含差不多数量的文档。并不希望某个分片持有99%的数据,而另一个分片持有剩下的1%,这样做极其低效。
2. 分片控制
索引一个文档时,这个文档会被存储到主分片中,主分片再将数据拷贝到副本分片中,而主分片和各个副本分片都在不同的节点上,所以每个节点上都有zhangsan这个文档数据,那我们要到哪个节点上获取这个文档数据呢?
实际上,我们可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。 将所有的请求发送到节点 1,我们将其称为协调节点。

但是,当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点。
3. 分布式文档写入(索引)的过程?
新建、索引和删除 请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片,如图所示:新建,索引和删除单个文档

以下是在主副分片和任何副本分片上面成功新建,索引和删除文档所需要的步骤顺序:
① 客户端向 节点 1 发送新建文档请求 (节点 1就是协调节点)。
② 协调节点根据文档的 id 确定文档属于分片 0 (路由计算)。请求会被转发到 节点 2,因为分片0的主分片目前被分配在 节点 2 上。
③ 节点 2 在主分片上面执行请求写入文档。如果成功了,它将请求并行转发到 节点 1 和 节点 3 的副本分片上。一旦所有的副本分片都报告写入成功, 节点 2 将向协调节点报告成功,协调节点向客户端报告成功。
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。
当协调节点接收到来自客户端对某个索引的写入文档请求时,该节点会根据路由算法将该文档映射到某个主分片上,然后将请求转发到该分片所在的节点。完成数据的存储后,该节点会将请求转发给该分片的其他副分片所在的节点,直到所有副分片节点全部完成写入,协调节点向客户端报告写入成功。

如图所示,一个包含3个节点的ES集群,假设索引中只有3个主分片和6个副分片,客户端向节点1发起向索引写入一条文档的请求,在本次请求中,节点1被称为协调节点。节点1判断数据应该映射到哪个分片上。假设将数据映射到分片1上,因为分片1的主分片在节点3上,因此节点1把请求转发到节点3上。节点3接收客户端的数据并进行存储,然后把请求转发到副分片1所在的节点1和节点2上,当所有副分片所在的节点全部完成存储后,协调节点也就是节点1向客户端返回成功标志。
4. 分布式文档搜索的过程?
可以从主分片或者从其它任意副本分片检索文档 ,如下图所示:取回单个文档

以下是从主分片或者副本分片检索文档的步骤顺序:
① 客户端向 节点 1 发送获取请求。
② 节点使用文档的 id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到 节点 3 。
③ 节点 3 将文档返回给 节点 1 ,然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
当协调节点接收到来自客户端的获取某个索引的某文档的请求时,协调节点会找到该文档所在的所有分片,然后根据轮询算法在主/副分片中选择一个分片并将请求转发给该分片所在的节点,该节点会将目标数据发送给协调节点,协调节点再将数据返回给客户端。

一个包含3个节点的ES集群,假设索引中只有3个主分片和6个副分片,客户端向节点1发起向索引获取文档的请求,在本次请求中,节点1被称为协调节点。节点1判断数据应该映射到哪个分片上。假设将数据映射到分片1上,分片1有主/副两种分片,分别在节点2、节点1和节点3上。假设此时协调节点的轮询算法选择的是节点3,那么它会将请求转发到节点3上,然后节点3会把数据传输给协调节点,也就是节点1,最后由节点1向客户端返回文档数据。
在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
5. 分布式文档更新和删除的过程?
update API 结合了读取和写入模式。

以下是部分更新一个文档的步骤:
① 客户端向 节点 1 发送更新请求。
② 节点使用文档的 id 来确定文档属于分片 0 ,它将请求转发到主分片所在的 节点 2 。
③ 节点 2 从主分片检索文档,修改 _source 字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过 retry_on_conflict 次后放弃。
④ 如果 节点 2 成功地更新文档,它将新版本的文档并行转发到 节点 1 和 节点 3 上的副本分片,重新建立索引。 一旦所有副本分片都返回成功, 节点 2 向协调节点也返回成功,协调节点向客户端返回成功。
当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果Elasticsearch仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。
相关文章:
ElasticSearch - 分布式文档索引、搜索、更新和删除文档的过程
文章目录1. 分布式文档存储1. 路由一个文档到一个分片中2. 主分片和副本分片如何交互3. 新建、索引和删除文档4. 取回一个文档5. 局部更新文档2. ElasticSearch相关问题1. 路由计算方式?2. 分片控制3. 分布式文档写入(索引)的过程?4. 分布式文档搜索的过…...
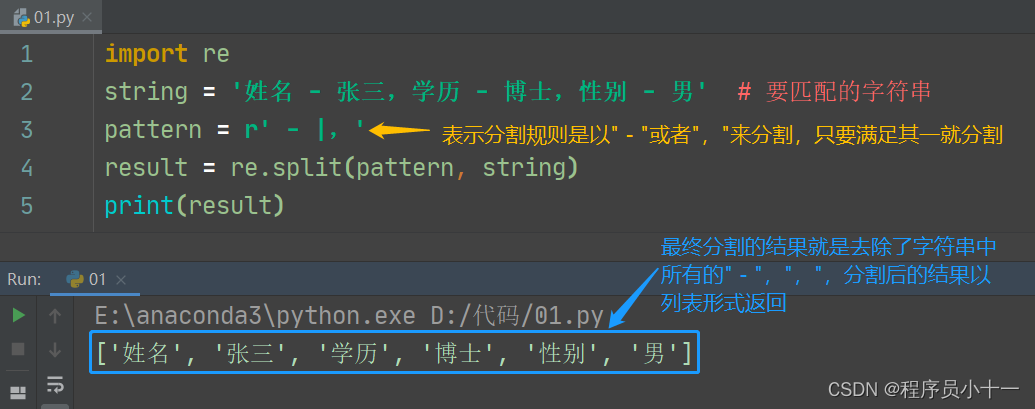
Python之re库用法细讲
文章目录前言一、使用 re 模块的前期准备工作二、使用 re 模块匹配字符串1. 使用 match() 方法进行匹配2. 使用 search() 方法进行匹配3. 使用 findall() 方法进行匹配三、使用 re 模块替换字符串四、使用 re 模块分割字符串总结前言 在之前的博客中我们学习了【正则表达式】的…...
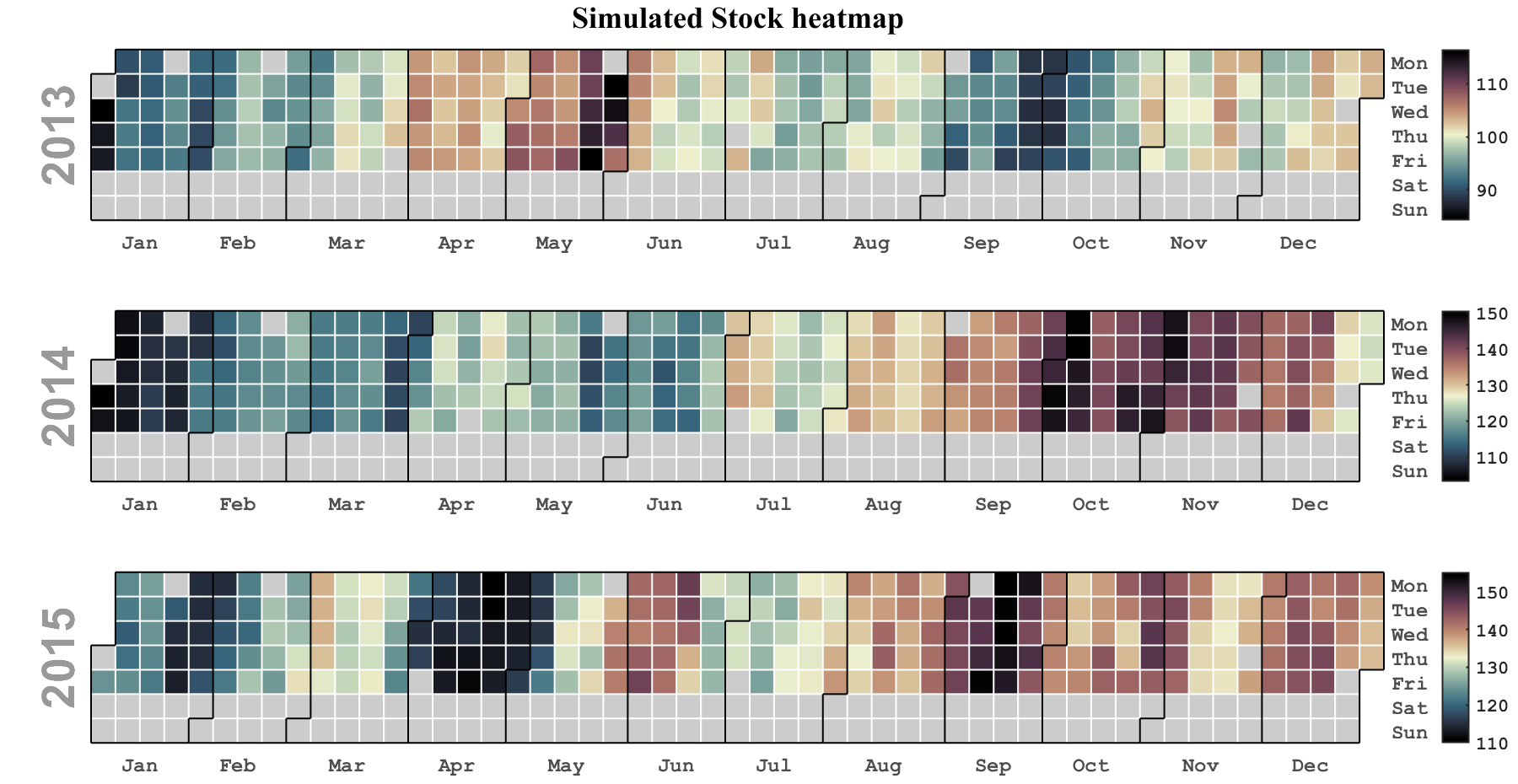
MATLAB | 如何绘制github同款日历热力图
应粉丝要求,出一个类似于github热图的日历热力图,大概长这样: 依旧工具函数放在文末,如有bug请反馈并去gitee下载更新版。 使用教程 使用方式有以下几种会慢慢讲到: heatmapDT(Year,T,V)heatmapDT(Year,T,V,MonLim)h…...

认识适配器模式
适配器模式 一、定义 在不修改原来代码的情况下,适配器模式使接口不兼容的那些类可以一起工作。 二、适配器结构 1、Target(目标抽象类):目标抽象类定义客户所需的接口,可以是一个抽象类或者接口,也可以…...

JavaSe第6次笔记
1.不建议使用c语言的数组的表示方法。 2.二维数组表示方法 3.数组整体初始化时,只能在定义时初始化。 int[] array; array new int[]{1, 2}; 4. boolean类型数组,默认值是false,String类型数组,默认是null,其它是…...

单例设计模式
介绍 单例模式是一种创建型设计模式,其主要特点包括: 只有一个实例:单例模式确保系统中只有一个实例对象存在,所有对该对象的访问都是对同一个对象的引用全局访问:单例模式可以全局访问该实例对象,避免了多个对象之间的冲突和竞争延迟初始化:单例模式通常使用延迟初始化技术,…...
)
第七章 opengl之光照(基础光照)
OpenGL基础光照环境光照漫反射光照镜面光照基础光照 主要需要理解一个模型是冯氏光照模型,主要结构由3个分量组成:环境,漫反射,镜面光照。下面分别描述下这三个光照: 环境光照(Ambient Lighting):即使在黑…...
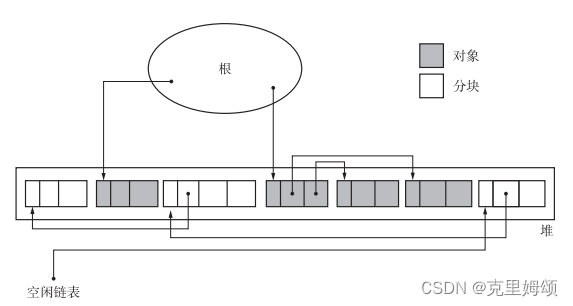
不考虑分配与合并情况下,GO实现GCMarkSweep(标记清除算法)
观前提醒 熟悉涉及到GC的最基本概念到底什么意思(《垃圾回收的算法与实现》)我用go实现(因为其他的都忘了,(╬◣д◢)ムキー!!) 源码地址(你的点赞,是我开源的…...
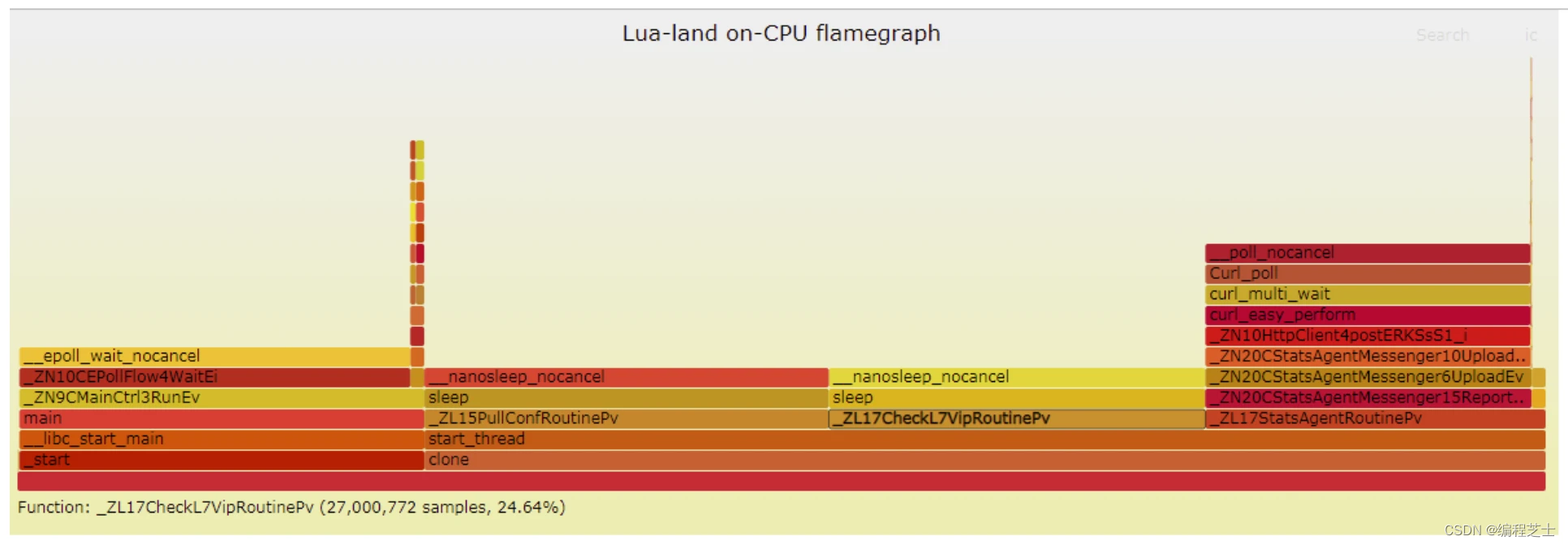
性能分析利器:火焰图
什么是火焰图 火焰图(FlameGraph)是是由 Linux 性能优化大师 Brendan Gregg 发明的。通过 perf 等工具分析得到结果,看起来就像是火焰,这也是它的名字的由来。火焰图以一个全局的视野来看待时间分布,它从底部往顶部&am…...
八股总结(三)操作系统内存管理、进程线程、进程同步与通信、中断与异常、常用命令
layout: post title: 八股总结(三)操作系统内存管理、进程线程、进程同步与通信、中断与异常、常用命令 description: 八股总结(三)操作系统内存管理、进程线程、进程同步与通信、中断与异常、常用命令 tag: 八股总结 文章目录操作…...
)
概率论小课堂:条件概率和贝叶斯公式(机器翻译的工作原理)
文章目录 引言I 条件概率1.1 条件概率的定义1.2 条件概率的计算II 贝叶斯公式2.1贝叶斯公式的本质2.2 机器翻译的原理引言 对于几乎所有的随机事件来讲,条件概率由于条件的存在,它通常不等于本身的概率。 贝叶斯公式的本质:在数学上条件和结果可以互换,通过这种互换,可以…...

流量与日志分析
文章目录1.流量与日志分析1.1系统日志分析1.1.1window系统日志与分析方法1.1.2linux 系统日志与分析方法1.2 web日志分析iis 日志分析方法apache日志分析**access_log****error_log**nginx日志分析tomcat 日志分析主流日志分析工具使用1.流量与日志分析 日志,是作为…...
)
英文论文写作常用例句整理汇总(持续更新)
ContentsGeneral introductionProblem definitionGaps in literatureProblems solutionStudy motivationAims & objectivesSignificance and advantages of your work参考资料General introduction Research on __ has a long tradition For decades, one of the most pop…...
[N0wayBack 练习题] My_enc,Euler,EasyLock,RRRRSA,EasyNumber,pwn
加入一个队,队里的练习题不少,还有WP真好My_enc原题from secret import flag import randomdef Cyber_key(LEN):Key [[] for i in range(row)]for x in range(row):for i in range(LEN):Key[x].append(random.randint(0, 2023))return Keydef Punk_enc(Key, msg):out []for l…...
网分线缆测试和dc-block
今天的好苹果和坏苹果 好苹果:是校准件和网分都是好的,又给了我一次复盘的机会 网分测试线缆: 1.网分直接复位,如果网分复位是校准状态,且解的是精密转接头,BNC的,可以不校准,结果差…...

Java创建线程的方式只有一种:Thread+Runnable
Java创建线程的方式其实只有一种👨🎓一、继承Thread👨🎓二、实现Runnable接口👨🎓三、实现Callable接口👨🎓四、通过线程池创建👨🎓五、总结一般我…...
)
数据加密--课后程序(Python程序开发案例教程-黑马程序员编著-第3章-课后作业)
实例6:数据加密 数据加密是保存数据的一种方法,它通过加密算法和密钥将数据从明文转换为密文。 假设当前开发的程序中需要对用户的密码进行加密处理,已知用户的密码均为6位数字,其加密规则如下: 获取每个数字的ASCI…...
【GO】K8s 管理系统项目33[前端部分–登录和登出]
K8s 管理系统项目[前端部分–登录和登出] 1. 登录登出流程 1.1 登录流程 登入流程总的分为5步: 账号密码验证token生成token验证验证成功进行跳转验证失败返回/login 1.2 登出流程 登出流程就相对简单,分为2步 删除Token跳转/login 2. 登录代码 src/views/login/Login.v…...
Vue 计算属性基础知识 监听属性watch
计算属性的概念 在{{}}模板中放入太多的逻辑会让模板内容过重且难以维护。例如以下代码: <div id"app">{{msg.split().reverse().join()}}</div><script>const vm new Vue({el: "#app",data: {msg:我想把vue学的细一点}})&…...
)
PAT:L1-004 计算摄氏温度、L1-005 考试座位号、L1-006 连续因子(C++)
目录 L1-004 计算摄氏温度 问题描述: 实现代码: L1-005 考试座位号 问题描述: 实现代码: 原理思路: L1-006 连续因子 问题描述: 实现代码: 原理思路: 过于简单的就不再写…...

3步掌握StreamCap:开源直播录制工具的终极使用指南
3步掌握StreamCap:开源直播录制工具的终极使用指南 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/StreamCap …...

ReTerraForged终极指南:5步打造专业级Minecraft地形生成体验
ReTerraForged终极指南:5步打造专业级Minecraft地形生成体验 【免费下载链接】ReTerraForged TerraForged for modern MC versions 项目地址: https://gitcode.com/gh_mirrors/re/ReTerraForged ReTerraForged是一款专为现代Minecraft版本设计的革命性地形生…...

机械工程论文降AI工具免费推荐:2026年机械工程毕业论文降AI知网维普亲测4.8元达标完整指南
机械工程论文降AI工具免费推荐:2026年机械工程毕业论文降AI知网维普亲测4.8元达标完整指南 帮室友处理过机械工程论文降AI,前前后后试了四款工具,最后固定在嘎嘎降AI(www.aigcleaner.com)。 4.8元,达标率…...
:含12类经典数学场景Prompt+错误模式对照表+自动校验脚本)
Perplexity数学知识查询稀缺资源包(限时开放48小时):含12类经典数学场景Prompt+错误模式对照表+自动校验脚本
更多请点击: https://intelliparadigm.com 第一章:Perplexity数学知识查询 Perplexity 是衡量语言模型预测能力的核心指标,其数学定义源于信息论中的交叉熵。它本质上是模型对测试语料困惑程度的指数化表达,值越低表示模型对序列…...

如何用OpenCATS免费开源招聘系统3天搭建企业级人才库
如何用OpenCATS免费开源招聘系统3天搭建企业级人才库 【免费下载链接】OpenCATS Open-source applicant tracking system (ATS) and recruitment CRM for staffing agencies and hiring teams. 项目地址: https://gitcode.com/gh_mirrors/op/OpenCATS 还在为招聘流程混乱…...
)
用树莓派和LED灯带,我亲手搭了个能跑程序的‘图灵机’(附完整代码和接线图)
用树莓派和LED灯带打造实体图灵机:从理论到硬件的沉浸式实践 当计算机科学从抽象的数学公式变成指尖跳动的LED灯光,理论突然有了温度。去年冬天,我在车库工作台前完成了这个项目——用树莓派和LED灯带构建的实体图灵机。当第一个加法程序成功…...
)
手把手教你用STM32CubeMX配置STM32F103的Modbus从站(FreeMODBUS移植指南)
基于STM32CubeMX与FreeMODBUS的工业通信从站开发实战 在工业自动化领域,Modbus协议因其简单可靠的特点,至今仍是设备间通信的黄金标准。对于STM32开发者而言,传统的外设库直接编程方式需要处理大量底层细节,而CubeMX工具链与成熟开…...

别再轮询了!Qt QSerialPort高效读取数据的正确姿势:理解缓冲区与readyRead触发机制
别再轮询了!Qt QSerialPort高效读取数据的正确姿势:理解缓冲区与readyRead触发机制 在嵌入式开发和硬件通信领域,串口通信作为最基础的通信方式之一,其稳定性和效率直接影响整个系统的性能表现。许多开发者在使用Qt的QSerialPort模…...

蘑菇博客MoguBlog:微服务架构的前后端分离博客系统完整指南 [特殊字符]
蘑菇博客MoguBlog:微服务架构的前后端分离博客系统完整指南 🚀 【免费下载链接】mogu_blog_v2 蘑菇博客(MoguBlog),一个基于微服务架构的前后端分离博客系统。Web端使用Vue Element , 移动端使用uniapp和ColorUI。后端使用Spring cloud Spr…...
:实战案例|内存狂涨 / 句柄泄漏怎么查?用 VMMap + Handle + ListDLLs 三步定位)
《Sysinternals实战指南》进程和诊断工具学习笔记(8.15):实战案例|内存狂涨 / 句柄泄漏怎么查?用 VMMap + Handle + ListDLLs 三步定位
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...