深度学习基础之一:机器学习
文章目录
- 深度学习基本概念(Basic concepts of deep learning)
- 机器学习
- 典型任务
- 机器学习分类
- 模型训练的基本概念
- 基本名词
- 机器学习任务流程
- 模型训练详细流程
- 正、反向传播
- 学习率
- Batch size
- 激活函数
- 激活函数 sigmoid
- 损失函数
- MSE & M
- 交叉熵损失
- 优化器
- 优化器 — 梯度下降
- 优化器 — Momentum
- 优化器 — AdaGrad
- 优化器 — RMSprop
- 优化器 — Adam
- 模型评估指标
- 回归模型
深度学习基本概念(Basic concepts of deep learning)
机器学习
-
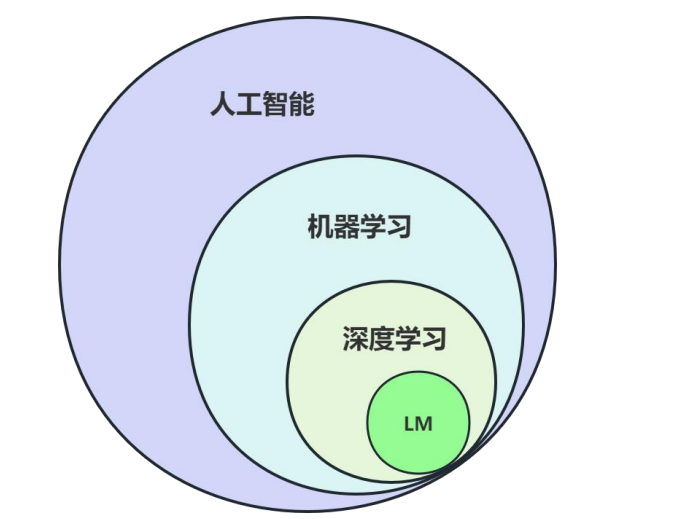
深度学习基于机器学习,是人工智能的一部分,而LM又是深度学习的一部分。
-
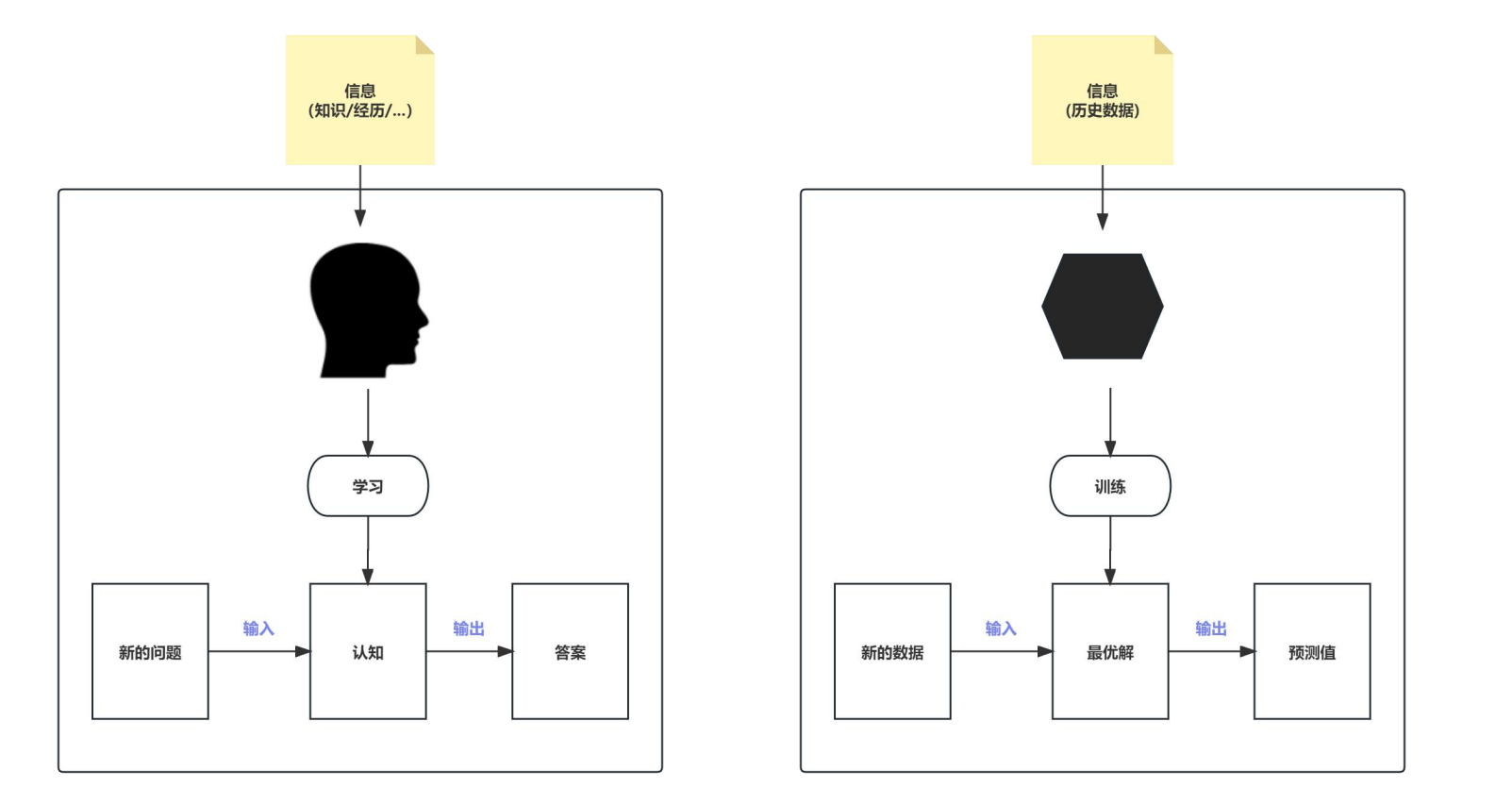
机器学习模拟人的学习过程,通过历史数据进行训练,然后利用积累的经验解决新的问题。
-
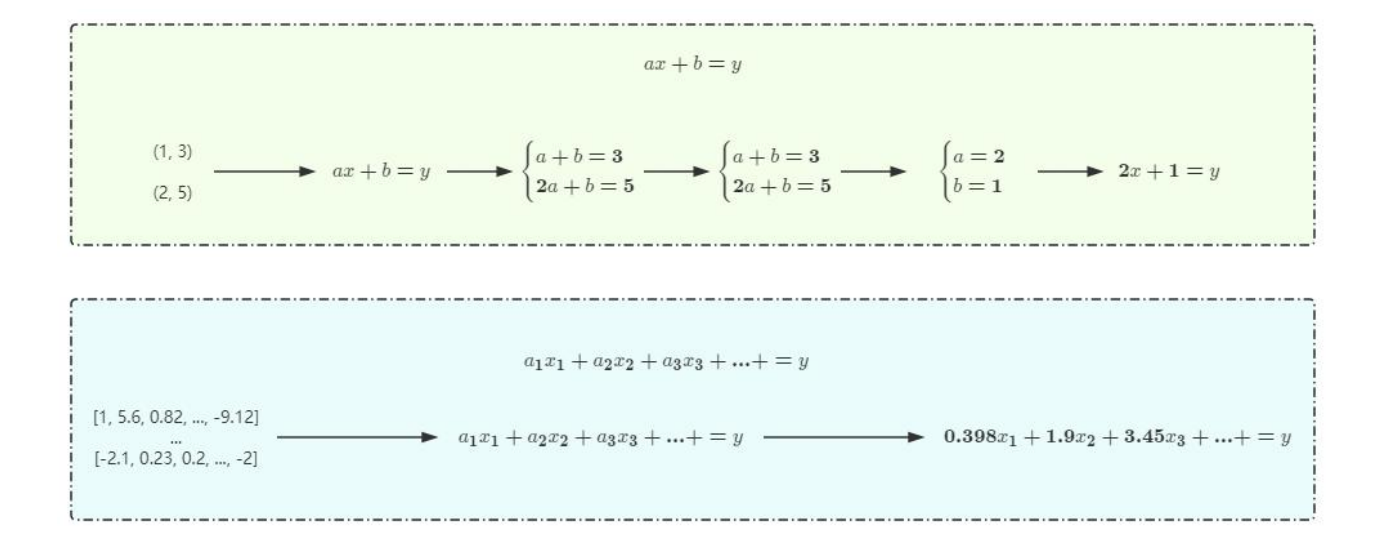
模型:一个包含大量未知参数的函数,所谓训练,就是通过大量的数据去迭代逼近这些未知参数的最优解
-
机器学习:是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。简单说,就是“从样本中学习的智能程序”。
-
深度学习:深度学习的概念源于人工神经网络的研究,是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
-
不论是机器学习还是深度学习,都是通过对大量数据的学习,掌握数据背后的分布规律,进而对符合该分布的其他数据进行准确预测
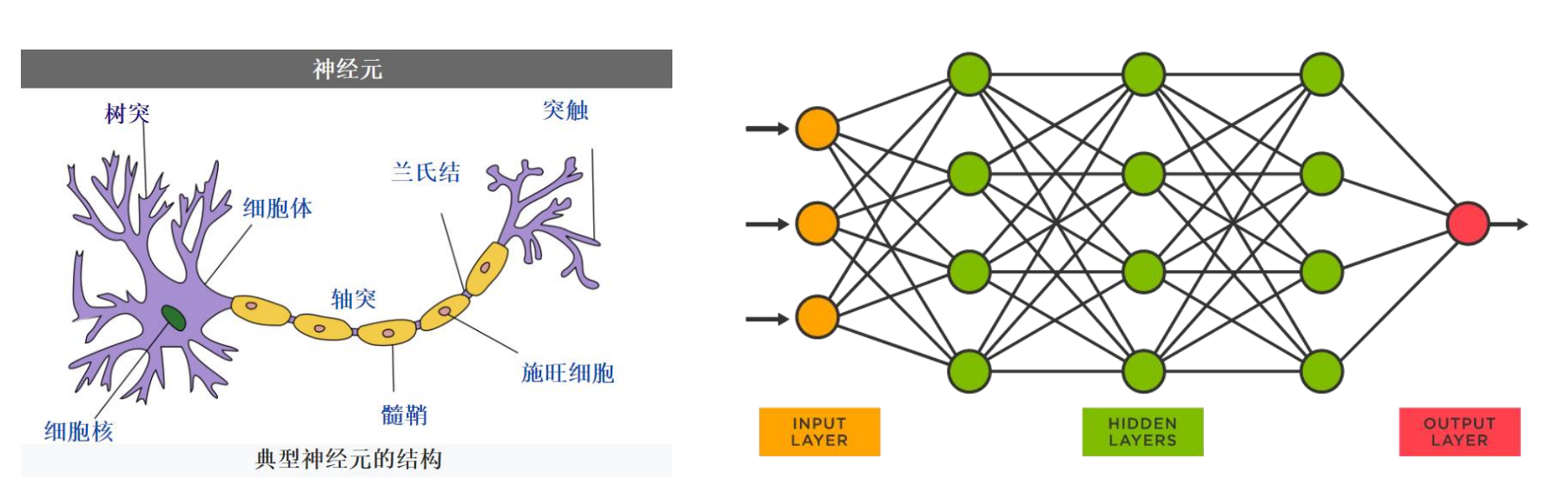
- 人体神经元结构和机器学习结构对比,
典型任务
-
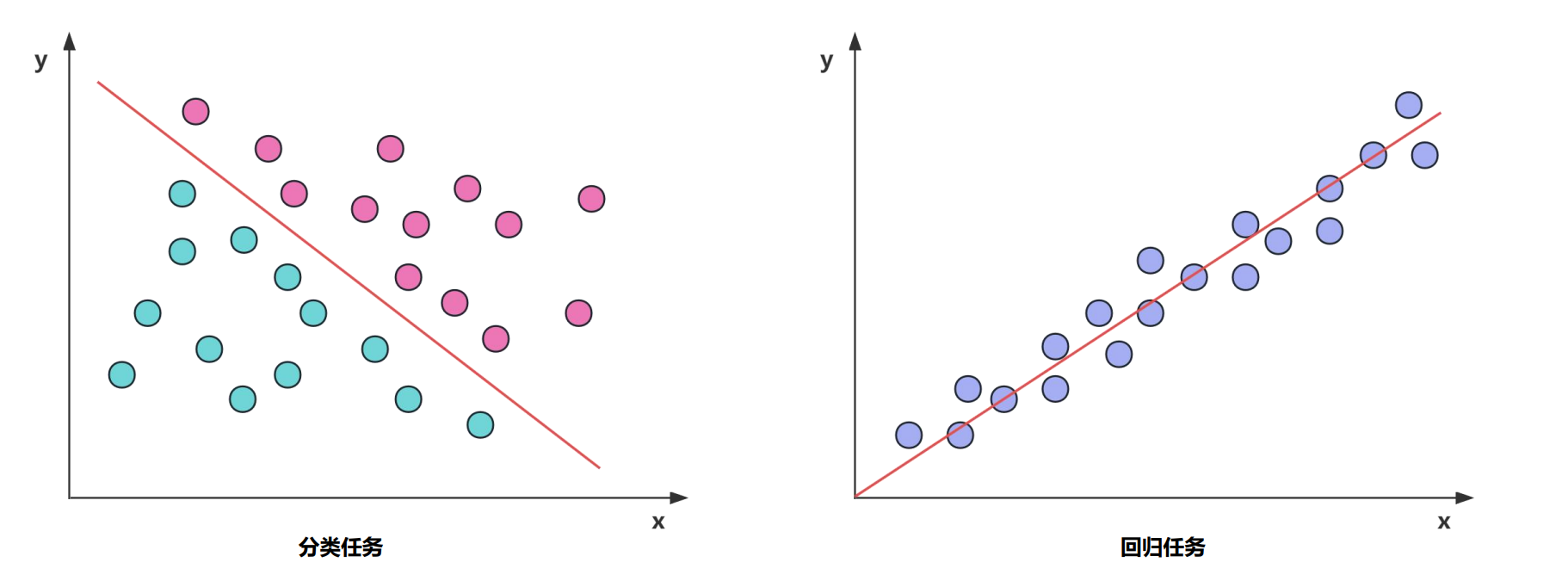
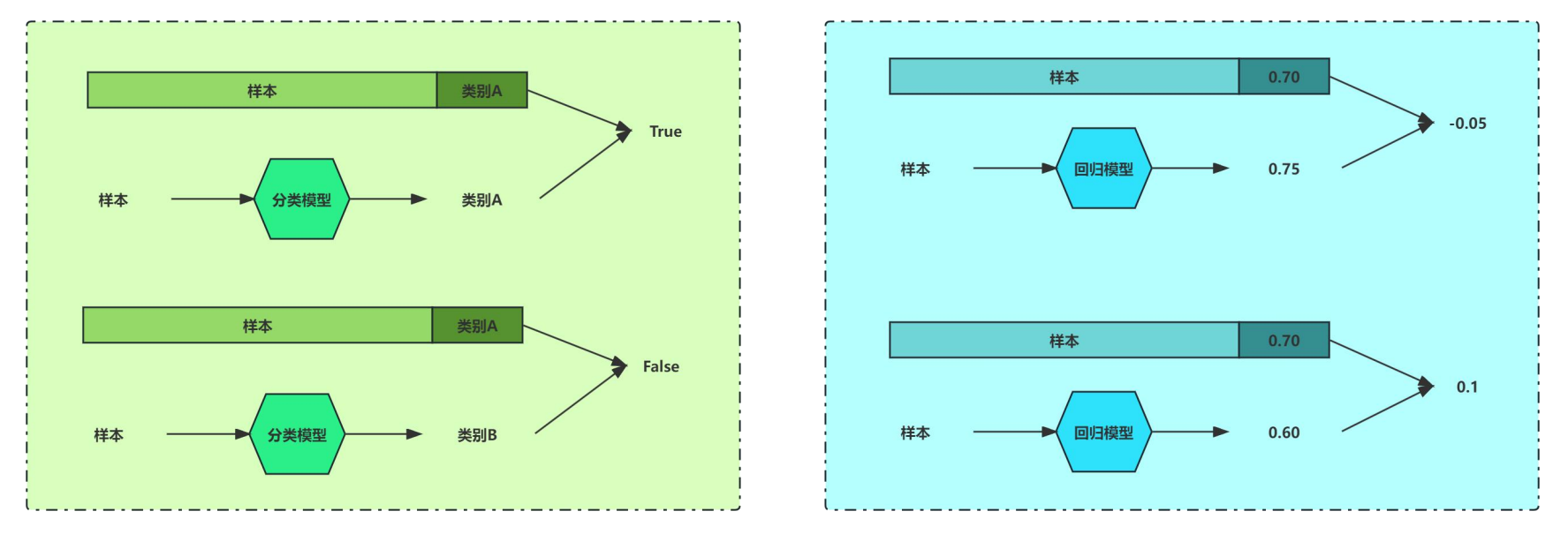
机器学习中的典型任务类型可以分为分类任务(Classification)和回归任务(Regression)
-
分类任务是对离散值进行预测,根据每个样本的值/特征预测该样本属于类型A、类型B 还是类型C,相当于学习一个分类边界(决策边界),用分类边界把不同类别的数据区分开来。
-
回归任务是对连续值进行预测,根据每个样本的值/特征预测该样本的具体数值,例如房价预测,股票预测等,相当于学习这组数据背后的分布,能够根据数据的输入预测该数据的取值。
-
分类与回归的根本区别在于输出空间是否为一个度量空间。
f ( x ) → y , x ∈ A , y ∈ B f(x) \rightarrow y,x \in A,y \in B f(x)→y,x∈A,y∈B -
对于分类问题,目的是寻找决策边界,其输出空间B不是度量空间,即“定性”。也就是说,在分类问题中,只有分类“正确”与“错误”之分,至于分类到类别A还是类别B,没有分别,都是错误数量+1。
-
**对于回归问题,目的是寻找最优拟合,其输出空间B是一个度量空间,即“定量”,通过度量空间衡量预测值与真实值之间的“误差大小”。**当真实值为10,预测值为5时,误差为5,预测值为8时,误差为2
机器学习分类
- 有监督学习:监督学习利用大量的标注数据来训练模型,对模型的预测值和数据的真实标签计算损失,然后将误差进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。
- 每条数据都有正确答案,通过模型预测结果与正确答案的误差不断优化模型参数
- 无监督学习:无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。
- 只有数据没有答案,常见的是聚类算法,通过衡量样本之间的距离来划分类别
-
有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。
-
半监督学习:利用有标签数据和无标签数据来训练模型。一般假设无标签数据远多于有标签数据。例如使用有标签数据训练模型,然后对无标签数据进行分类,再使用正确分类的无标签数据训练模型
- 利用大量的无标注数据和少量有标注数据进行模型训练
- 自监督学习:机器学习的标注数据源于数据本身,而不是由人工标注。目前主流大模型的预训练过程都是采用自监督学习,将数据构建成完型填空形式,让模型预测对应内容,实现自监督学习。
- 通过对数据进行处理,让数据的一部分成为标签,由此构成大规模数据进行模型训练
- 远程监督学习:主要用于关系抽取任务,采用bootstrap的思想通过已知三元组在文本中寻找共现句,自动构成有标签数据,进行有监督学习。
- 基于现有的三元组收集训练数据,进行有监督学习
- 强化学习:强化学习是智能体根据已有的经验,采取系统或随机的方式,去尝试各种可能答案的方式进行学习,并且智能体会通过环境反馈的奖赏来决定下一步的行为,并为了获得更好的奖赏来进一步强化学习。
- 以获取更高的环境奖励为目标优化模型
模型训练的基本概念
基本名词
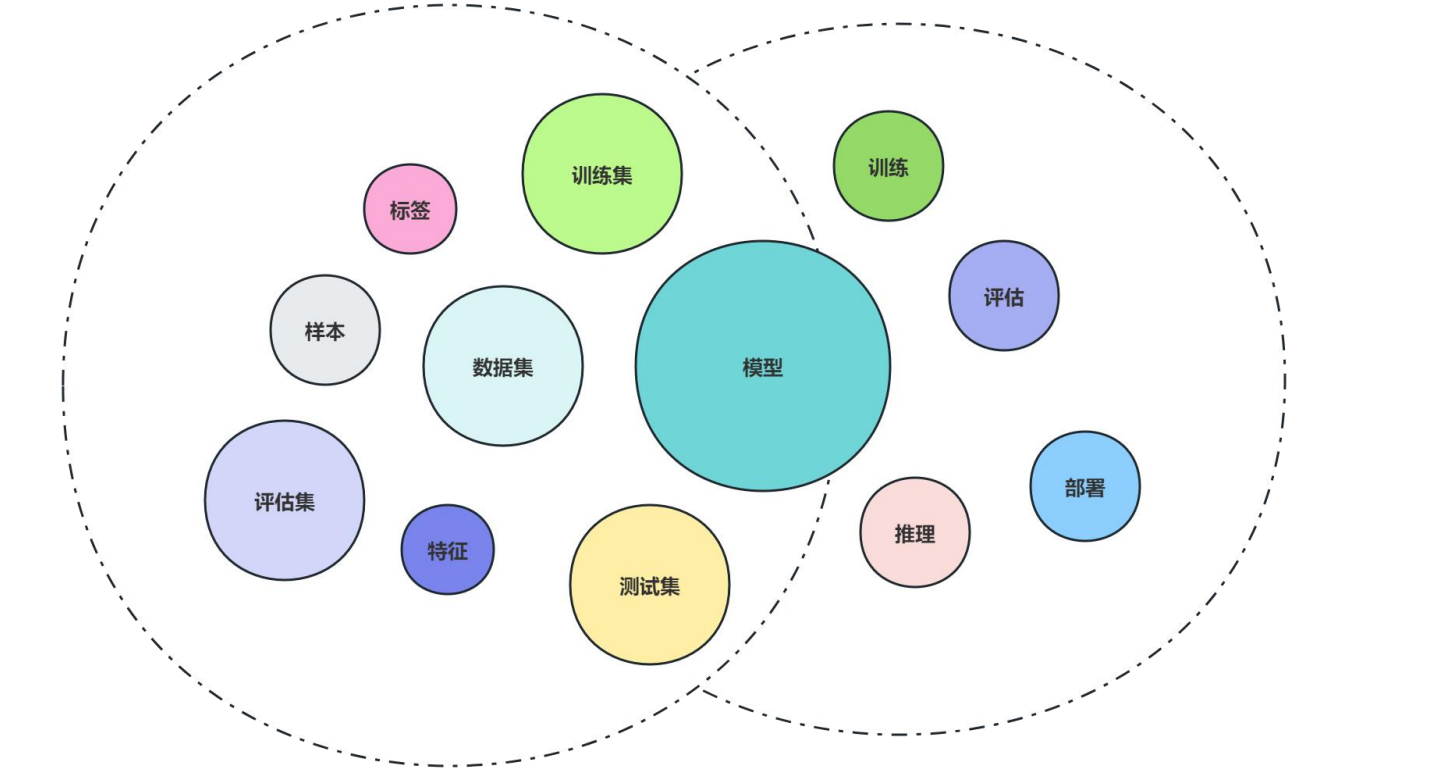
- 样本:一条数据
- 特征:被观测对象的可测量特性,例如西瓜的颜色、纹路、敲击声等
- 特征向量:用一个 d 维向量表征一个样本的所有或部分特征
- 标签(label)/真实值:样本特征对应的真实类型或者真实取值,即正确答案
- 数据集(dataset):多条样本组成的集合
- 训练集(train):用于训练模型的数据集合
- 评估集(eval):用于在训练过程中周期性评估模型效果的数据集合
- 测试集(test):用于在训练完成后评估最终模型效果的数据集合
- 模型:可以从数据中学习到的,可以实现特定功能/映射的函数
- 误差/损失:样本真实值与预测值之间的误差
- 预测值:样本输入模型后输出的结果
- 模型训练:使用训练数据集对模型参数进行迭代更新的过程
- 模型收敛:任意输入样本对应的预测结果与真实标签之间的误差稳定
- 模型评估:使用测试数据和评估指标对训练完成的模型的效果进行评估的过程
- 模型推理/预测:使用训练好的模型对数据进行预测的过程
- 模型部署:使用服务加载训练好的模型,对外提供推理服务
机器学习任务流程
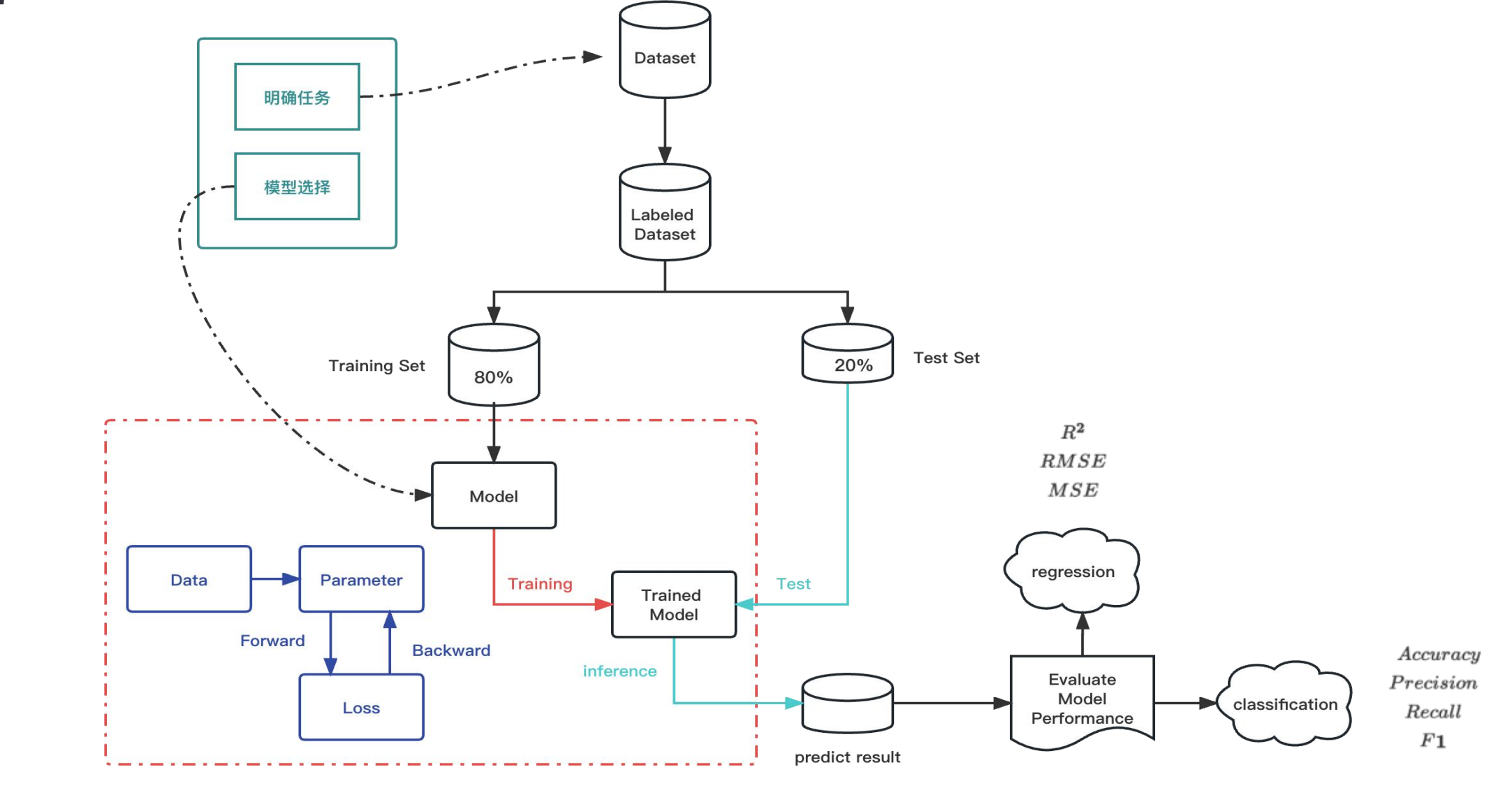
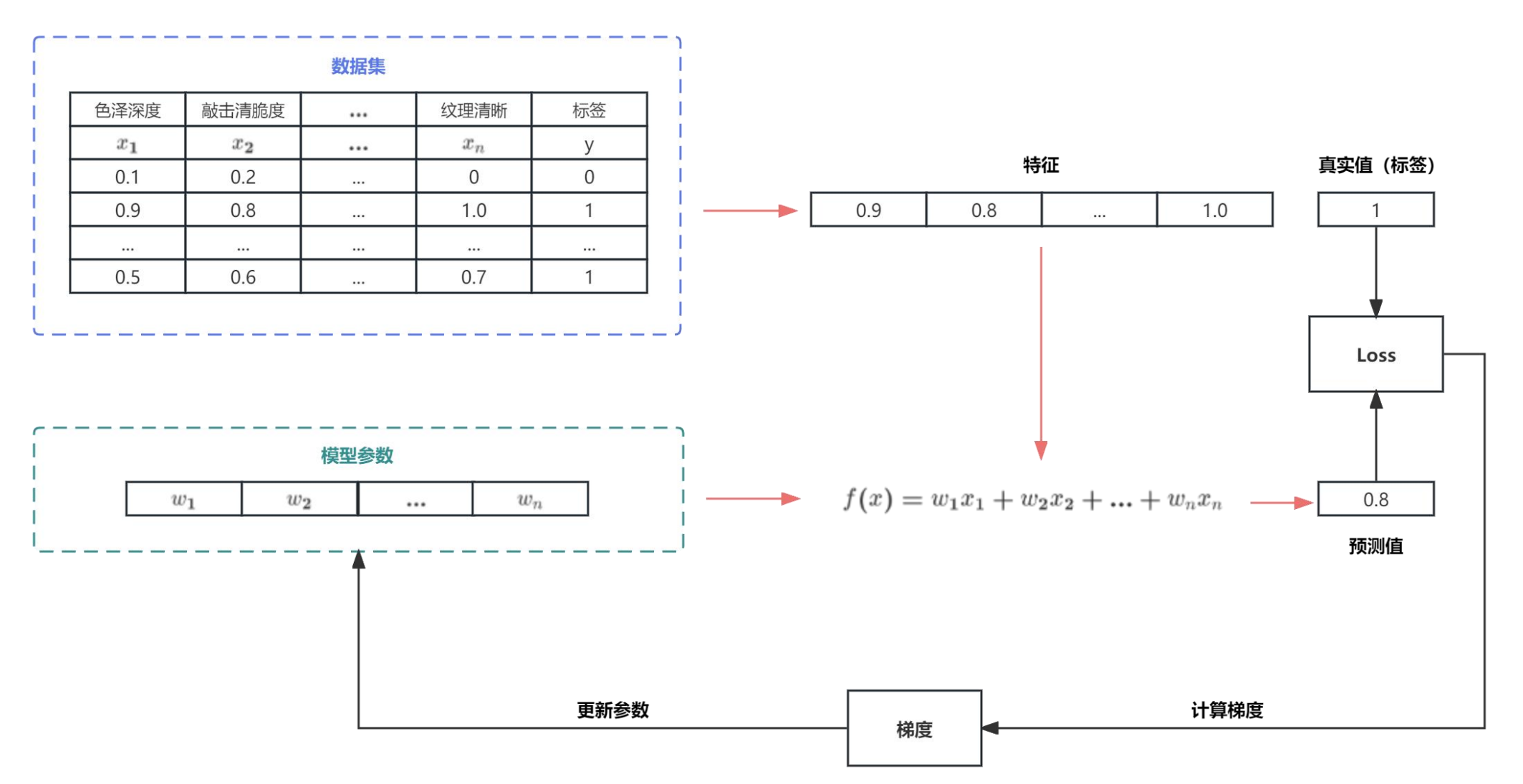
模型训练详细流程
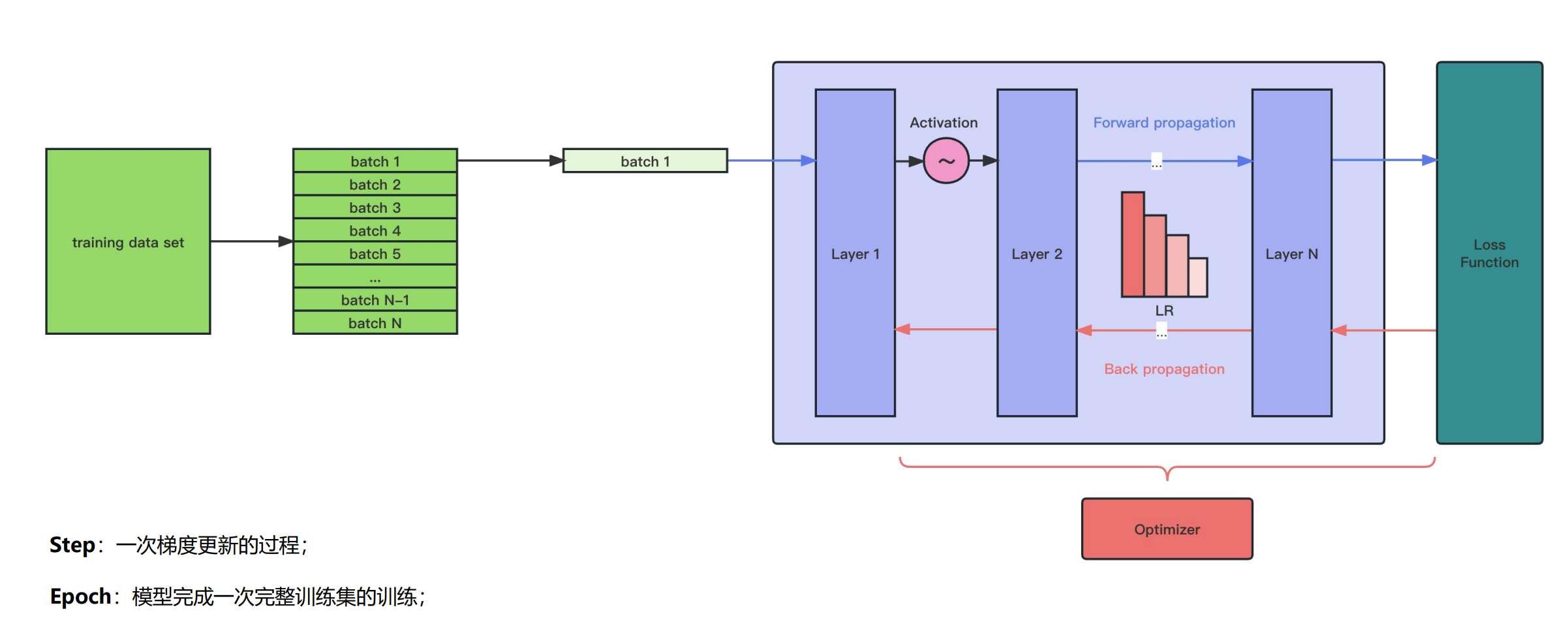
正、反向传播
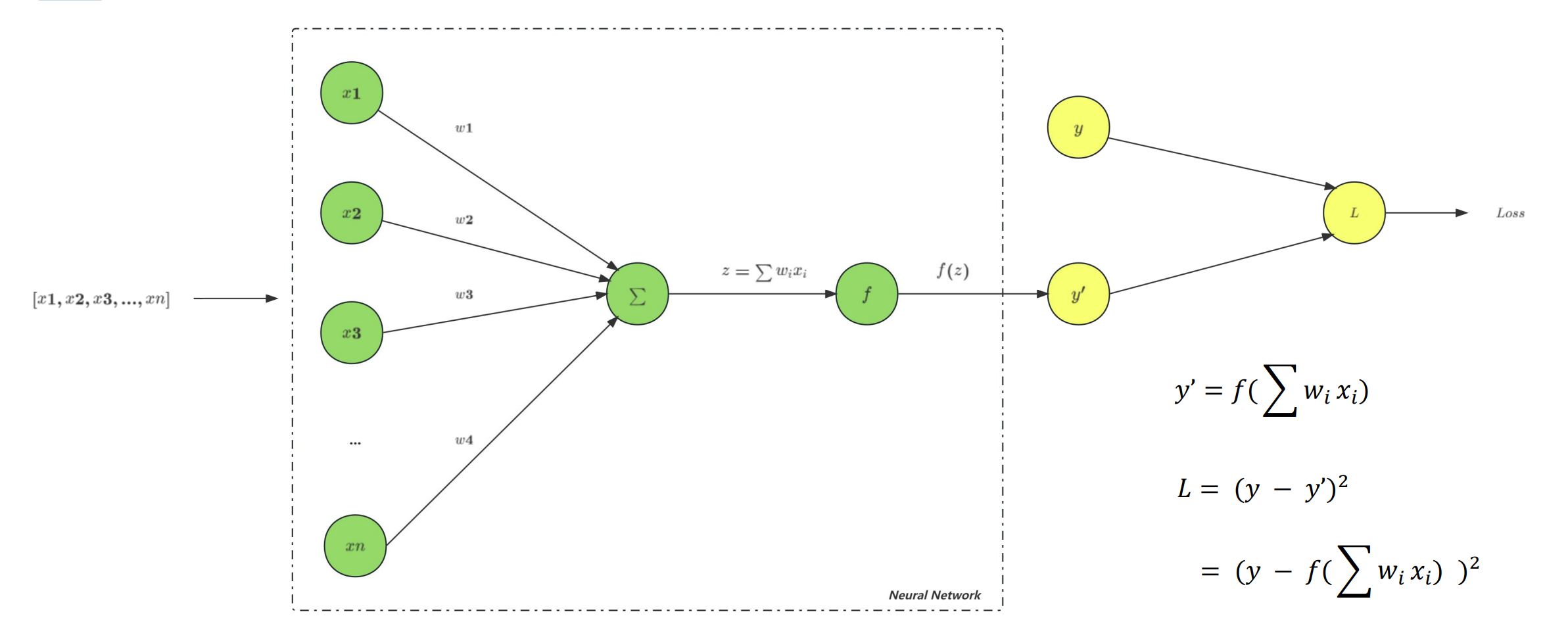
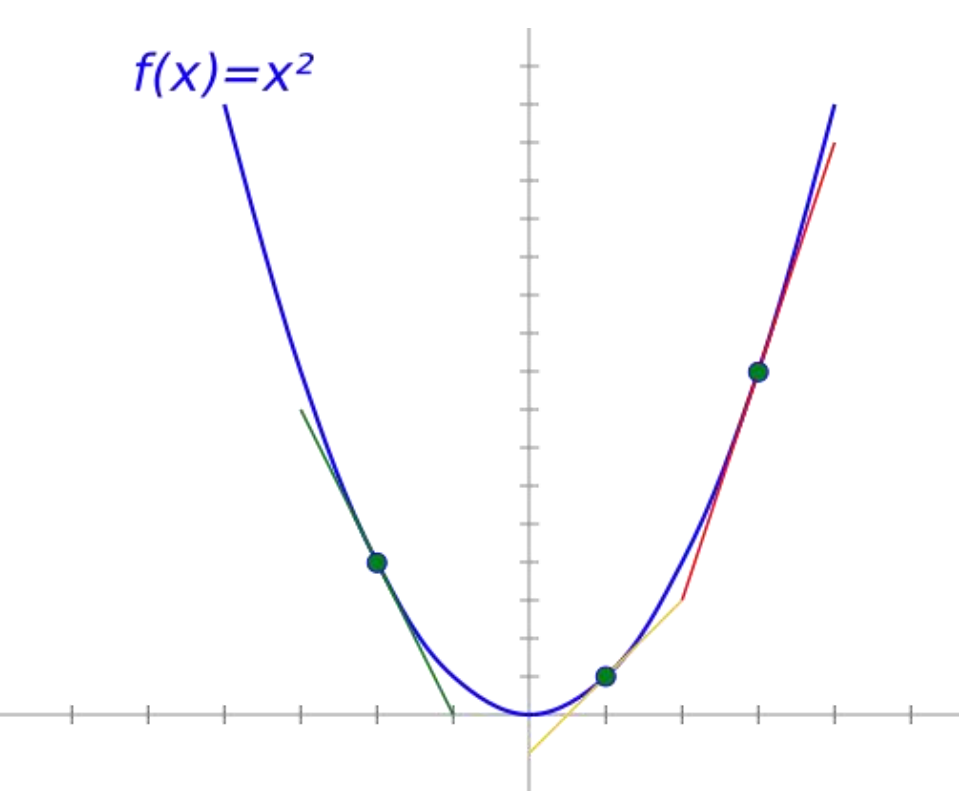
- 梯度:梯度是一个向量(矢量),函数在一点处沿着该点的梯度方向变化最快,变化率最大。换而言之,自变量沿着梯度方向变化,能够使因变量(函数值)变化最大。
学习率
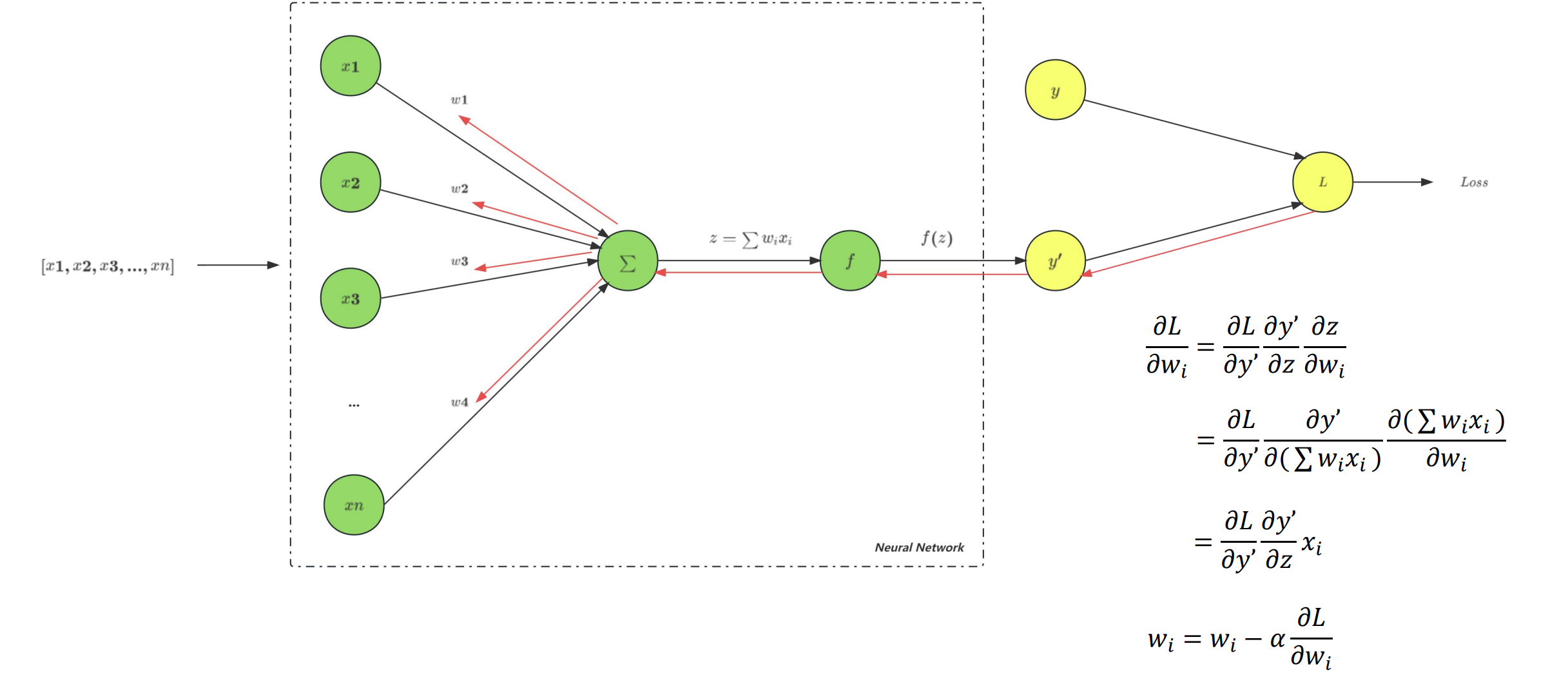
- 学习率(Learning Rate,LR)决定模型参数的更新幅度,学习率越高,模型参数更新越激进,即相同 Loss 对模型参数产生的调整幅度越大,反之越越小。
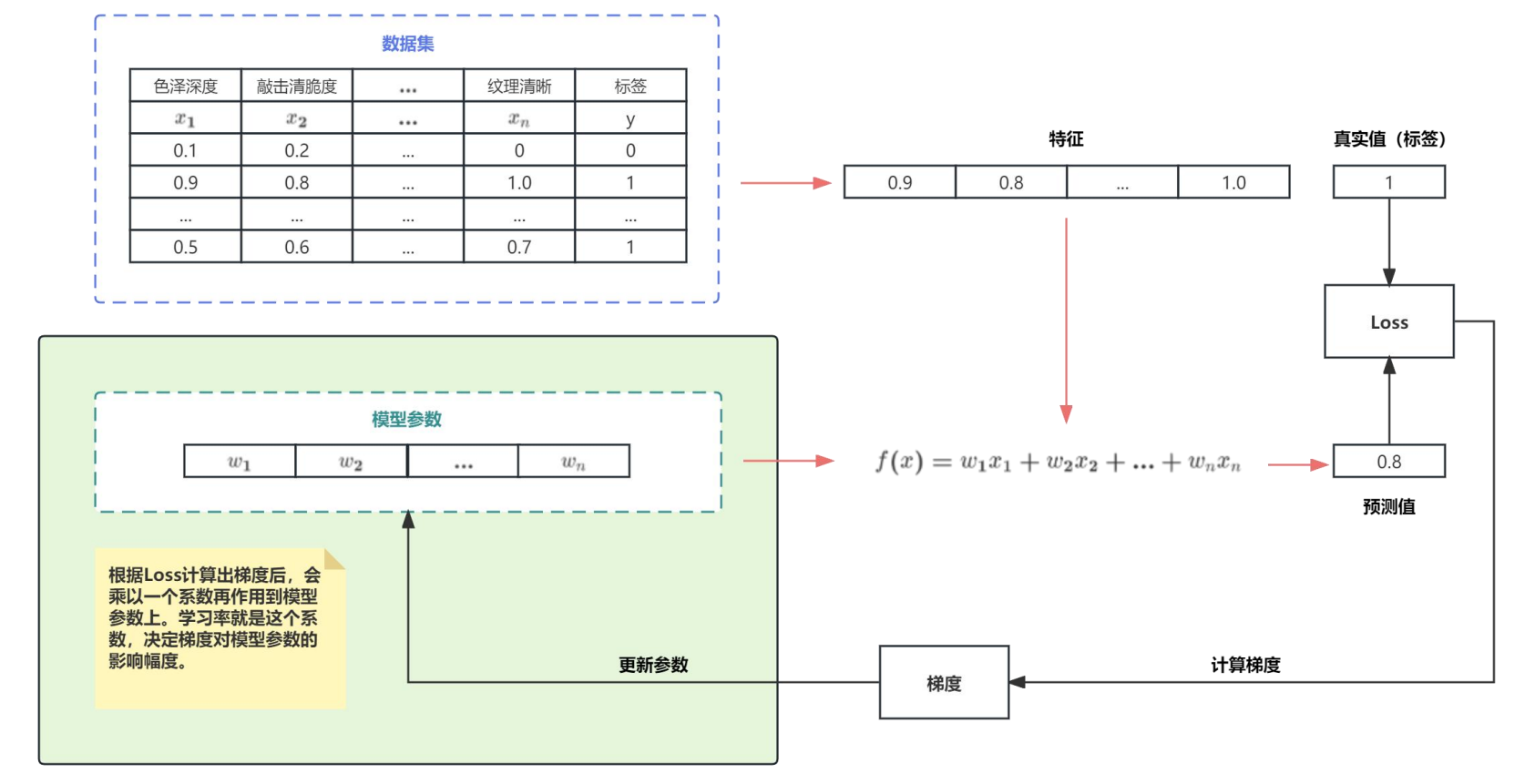
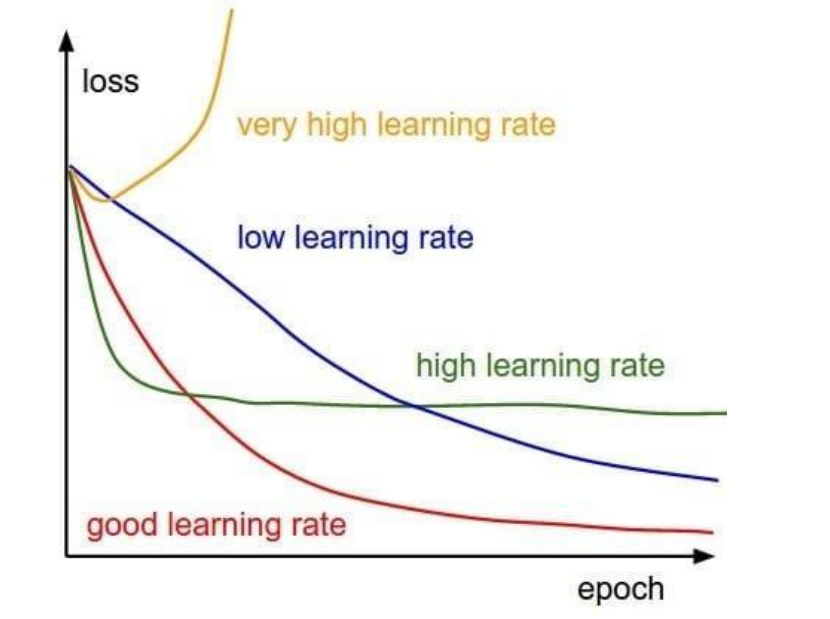
- 如果学习率太小,会导致网络 loss 下降非常慢;如果学习率太大,那么参数更新的幅度就非常大,产生振荡,导致网络收敛到局部最优点,或者 loss 不降反增。
Batch size
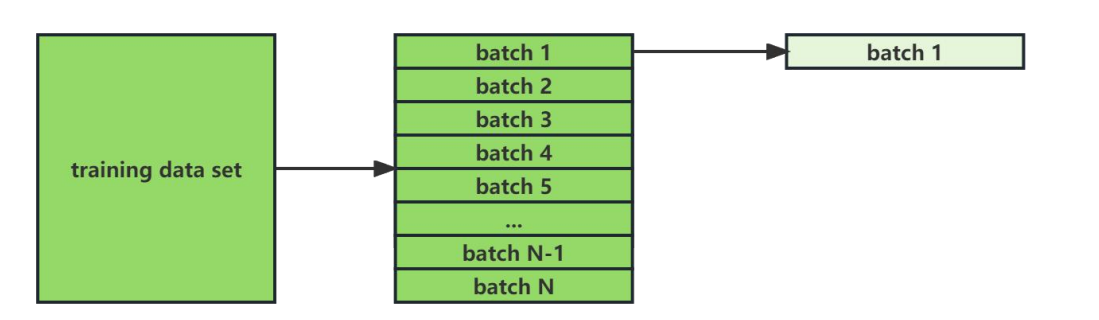
- Batch size 是一次向模型输入的数据数量,Batch size 越大,模型一次处理的数据量越大,能够更快的运行完一个 Epoch,反之运行完一个 Epoch 越慢
- 由于模型一次是根据一个 Batch size 的数据计算 Loss,然后更新模型参数,如果 Batchsize 过小,单个 Batch 可能与整个数据的分布有较大差异,会带来较大的噪声,导致模型难以收敛。
- Batch size 越大,模型单个 Step 加载的数据量越大,对于 GPU 显存的占用也越大,当 GPU 显存不够充足的情况下,较大的 Batch size 会导致 OOM,因此,需要针对实际的硬件情况,设置合理的 Batch size 取值。
在合理范围内,更大的 Batch size 能够:
- 提高内存利用率,提高并行化效率
- 一个 Epoch 所需的迭代次数变少,减少训练时间
- 梯度计算更加稳定,训练曲线更平滑,下降方向更准,能够取得更好的效果
对于传统模型,在较多场景中,较小的 Batch size 能够取得更好的模型性能;对于大模型,往往更大的 Batch size 能够取得更好的性能。
激活函数
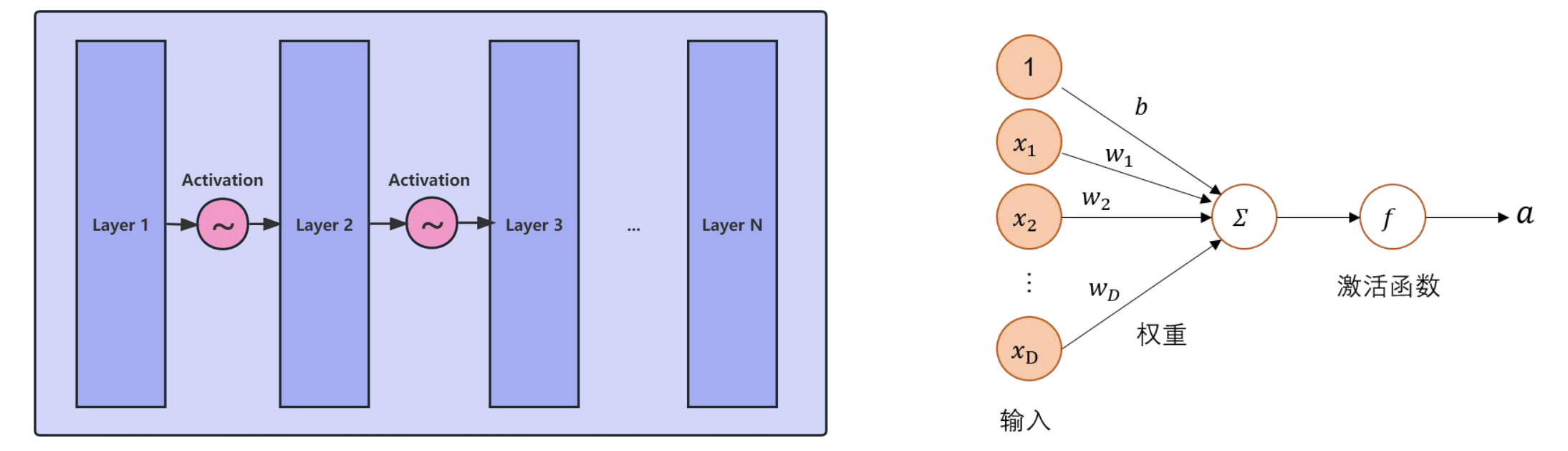
- 线性函数是一次函数的别称,非线性函数即函数图像不是一条直线的函数。非线性函数包括指数函数、幂函数、对数函数、多项式函数等等基本初等函数以及他们组成的复合函数。
- 激活函数是多层神经网络的基础,保证多层网络不退化成线性网络
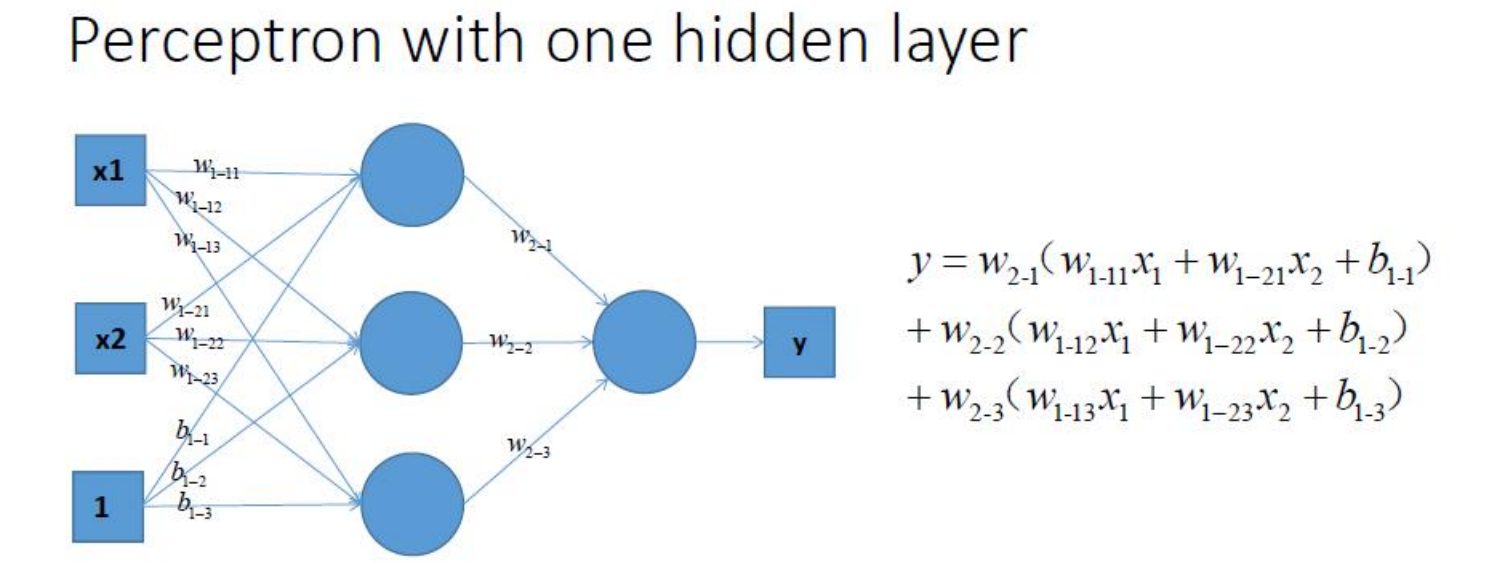
- 为什么需要使用激活函数?
- 线性模型的表达能力不够,激活函数使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中
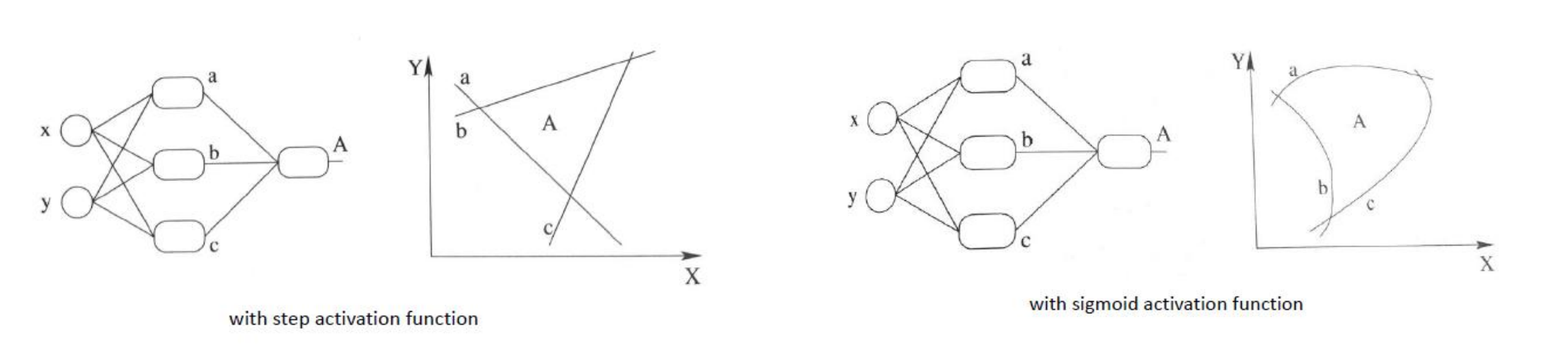
- 线性模型的表达能力不够,激活函数使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中
激活函数 sigmoid
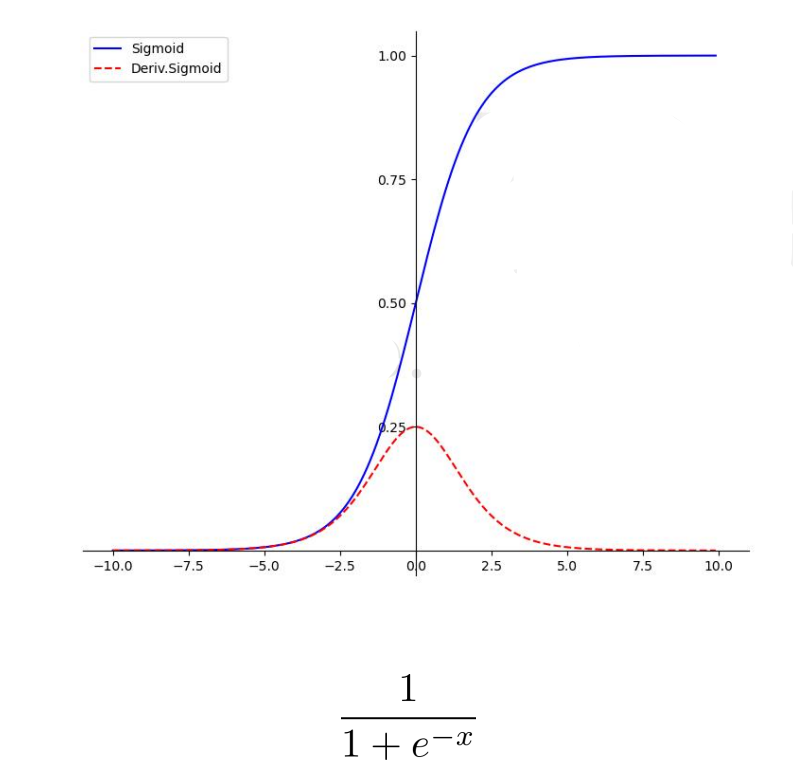
- sigmoid函数具有软饱和特性,在正负饱和区的梯度都接近于0,只在0附近有比较好的激活特性
- sigmoid导数值最大0.25,也就是反向传播过程中,每层至少有75%的损失,这使得当sigmoid被用在隐藏层的时候,会导致梯度消失(一般5层之内就会产生)
- 函数输出不以0为中心,也就是输出均值不为0,会导致参数更新效率降低;
- sigmoid函数涉及指数运算,导致计算速度较慢。
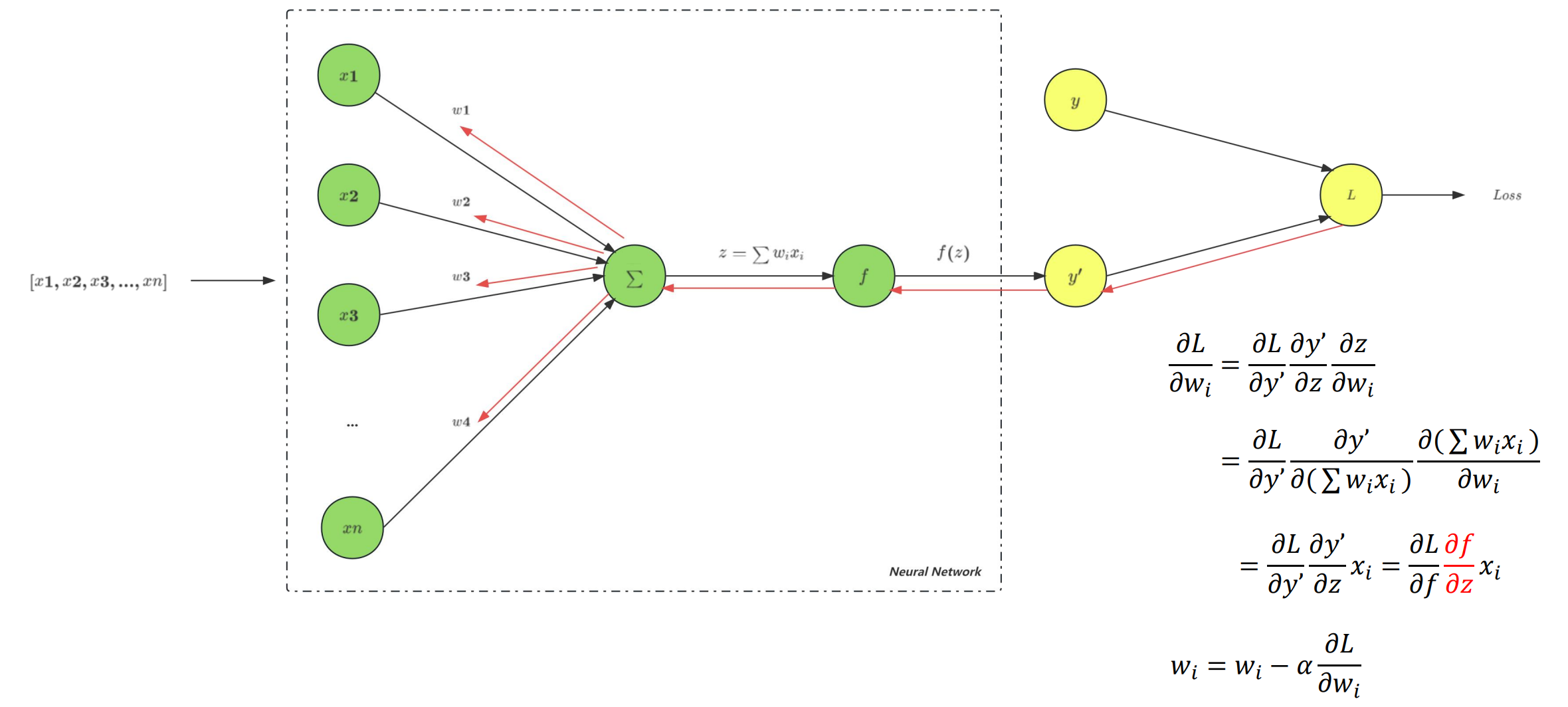
- 为什么希望激活函数输出均值为0?
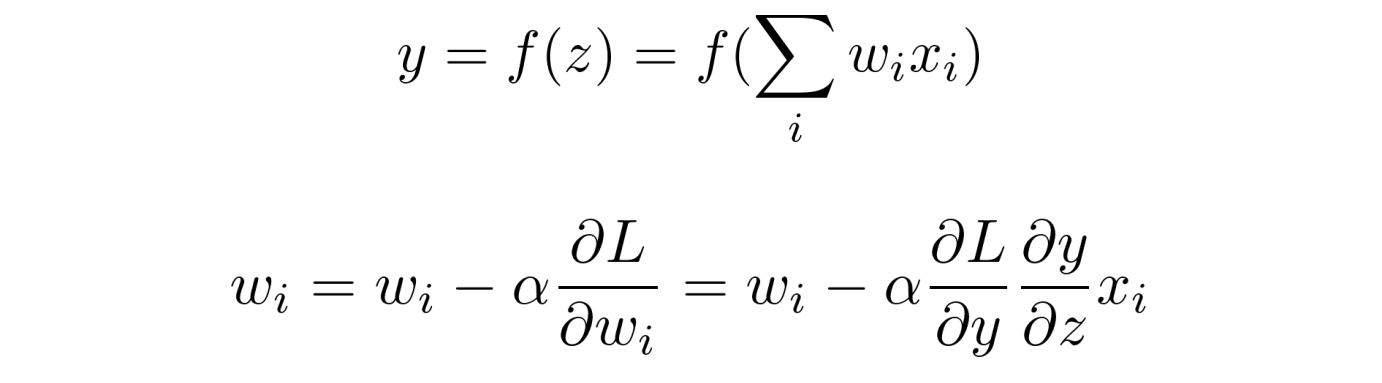
- 在上面的参数 w i w_i wi 更新公式中,对于所有 w i w_i wi 都是一样的, x i x_i xi 是 i − 1 i - 1 i−1 层的激活函数的输出,如果像 sigmoid 一样,输出值只有正值,那么对于第 i i i 层的所有 w i w_i wi ,其更新方向完全一致,模型为了收敛,会走 Z 字形来逼近最优解
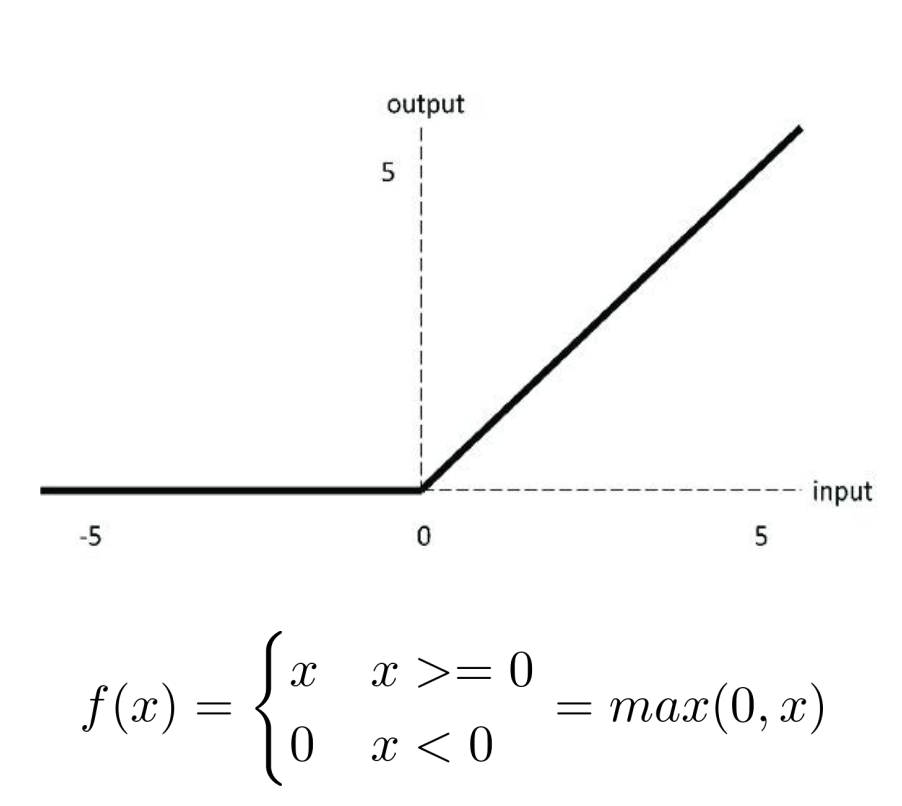
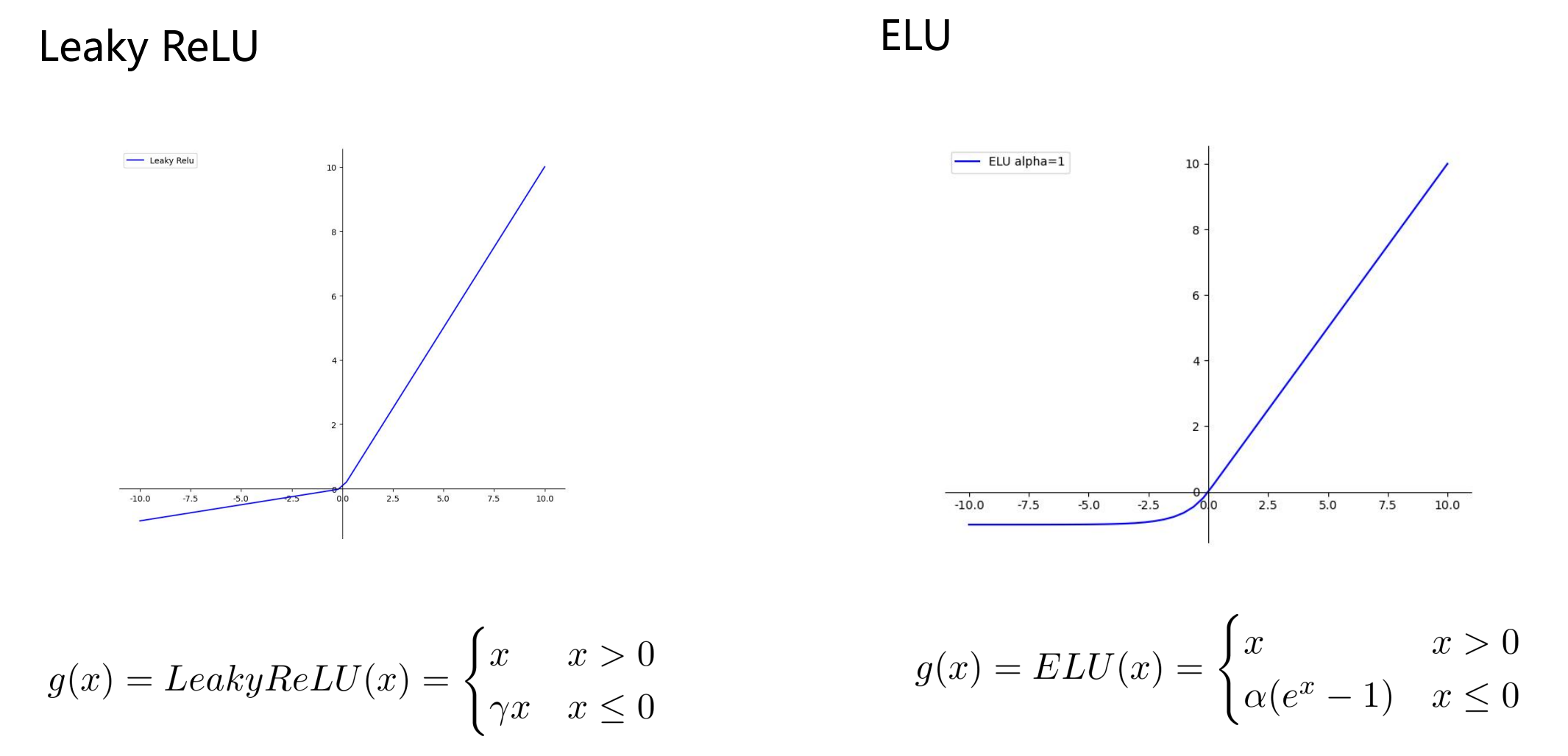
- eLU 是一个分段线性函数,因此是非线性函数;
- ReLU 的发明是深度学习领域最重要的突破之一;
- ReLU 不存在梯度消失问题;
- ReLU 计算成本低,收敛速度比 sigmoid 快6倍;
- 函数输出不以0为中心,也就是输出均值不为0,会导致参数更新效率降低;
- 存在 dead ReLU 问题(输入 ReLU 有负值时,ReLU输出为0,梯度在反向传播期间无法流动,导致权重不会更新)
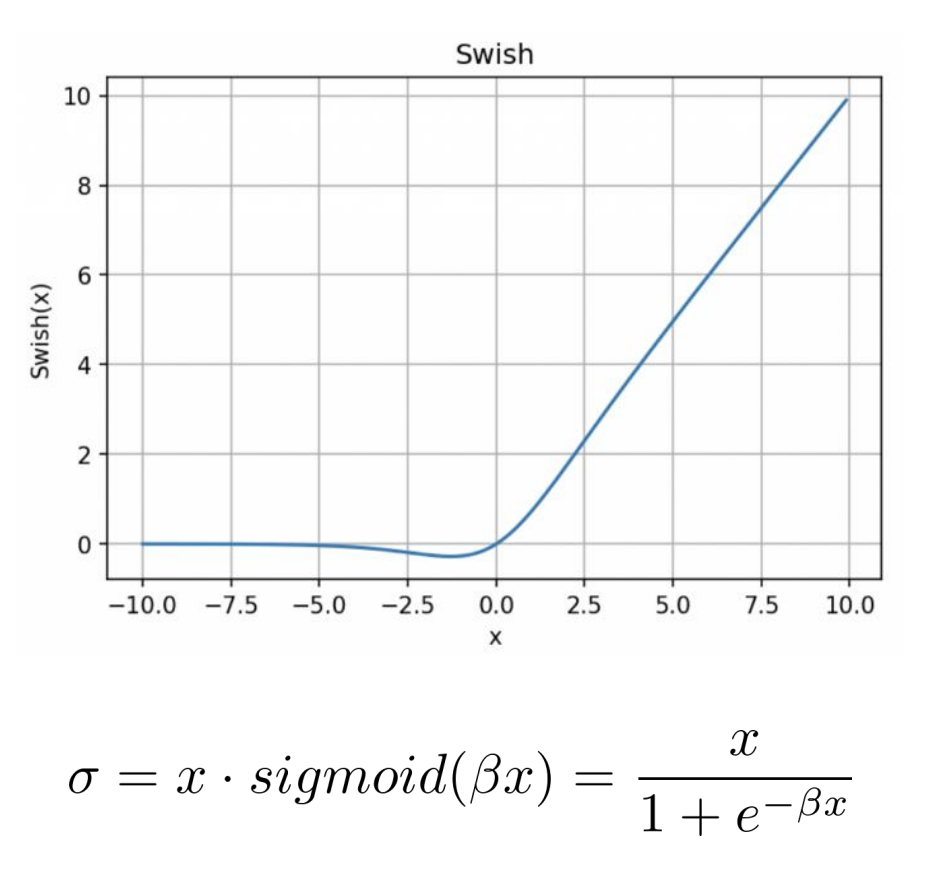
- 参数不变情况下,将模型中ReLU替换为Swish,模型性能提升;
- Swish 无上界,不会出现梯度饱和;
- Swish 有下界,不会出现 dead ReLU 问题;
- Swish 处处连续可导
损失函数
- 损失函数(loss function):用来度量模型的预测值f(x)与真实值Y的差异程度(损失值)的运算函数,它是一个非负实值函数。
- 损失函数仅用于模型训练阶段,得到损失值后,通过反向传播来更新参数,从而降低预测值与真实值之间的损失值,从而提升模型性能。
- 整个模型训练的过程,就是在通过不断更新参数,使得损失函数不断逼近全局最优点(全局最小值)
- 不同类型的任务会定义不同的损失函数,例如回归任务重的MAE、MSE,分类任务中的交叉熵损失等
MSE & M
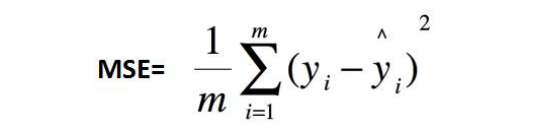
- 均方误差(mean squared error,MSE),也叫平方损失或 L2 损失,常用在最小二乘法中,它的思想是使得各个训练点到最优拟合线的距离最小(平方和最小)
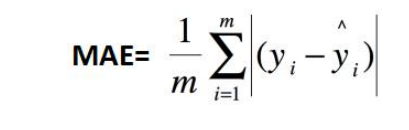
- 平均绝对误差(Mean Absolute Error,MAE)是所有单个观测值与算术平均值的绝对值的平均,也被称为 L1 loss,常用于回归问题中
交叉熵损失
-
【二分类】
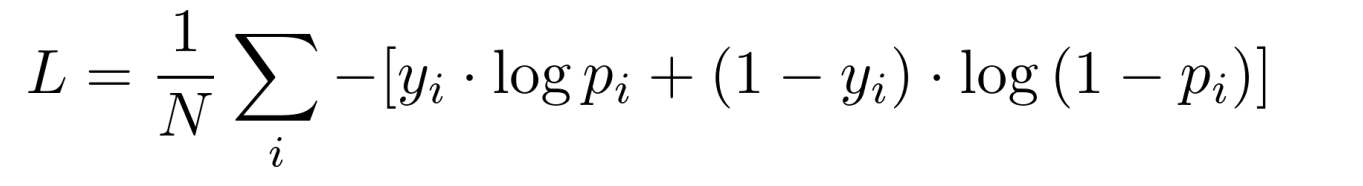
- y i y_i yi 为样本 i i i 的真实标签,正类为 1,负类为 0; p i p_i pi 表示样本 i i i 预测为正类的概率
-
【多分类】
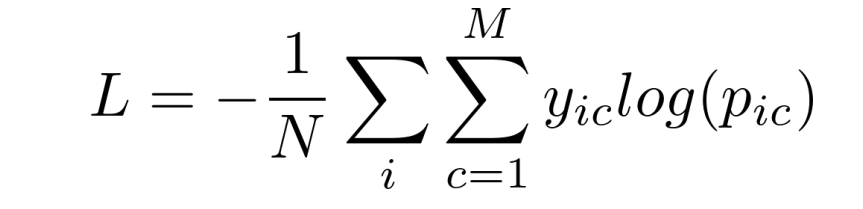
- M 为类别数量; y i c y_{ic} yic 符号函数,样本 i i i 真实类别等于 c 则为 1,否则为 0;预测样本 i i i属于类别 c 的预测概率
-
假设有一个二分类任务,正类为1,负类为0,存在一个正样本A,当模型输出其为正类的概率为0.8时,交叉熵损失为:
l o s s = − ( 1 × l o g ( 0.8 ) + 0 × l o g ( 0.2 ) ) = − l o g ( 0.8 ) = 0.0969 loss=-(1\times log(0.8)+0 \times log(0.2))=-log(0.8)=0.0969 loss=−(1×log(0.8)+0×log(0.2))=−log(0.8)=0.0969
当模型输出其为正类的概率为0.5时,交叉熵损失为:
l o s s = − ( 1 × l o g ( 0.5 ) + 0 × l o g ( 0.5 ) ) = − l o g ( 0.5 ) = 0.3010 loss=-(1\times log(0.5)+0 \times log(0.5))=-log(0.5)=0.3010 loss=−(1×log(0.5)+0×log(0.5))=−log(0.5)=0.3010 -
由此可见,当模型预测的误差越大时,交叉熵损失函数计算得到的损失越大
-
假设分类任务有3种类别A,B,C,有三个样本,其中 sample 1类型为C,smaple 2类型为B,sample 3类型为A,对于 sample 1,当模型预测概率不同时:
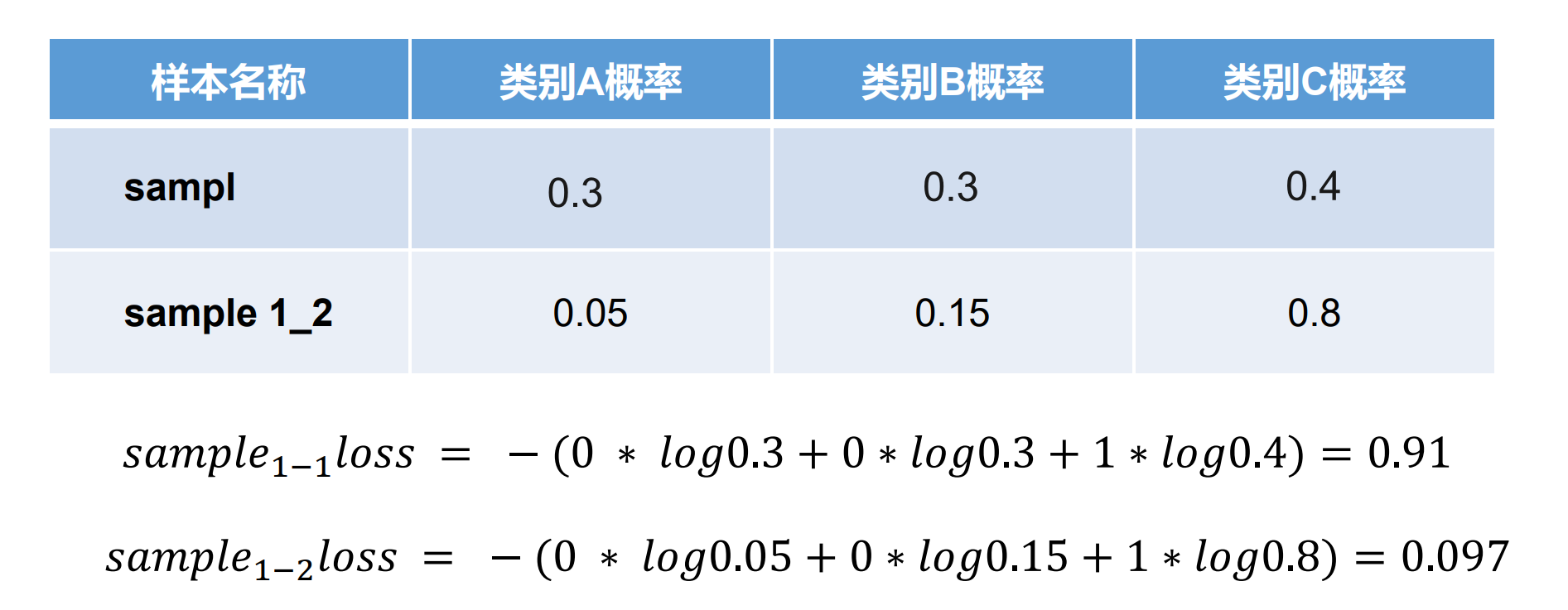
-
假设模型对这三个样本的预测概率为:
| 样本名称 | 类别A概率 | 类别B概率 | 类别C概率 |
|---|---|---|---|
| sample 1 | 0.3 | 0.3 | 0.4 |
| sample 2 | 0.3 | 0.4 | 0.3 |
| sample 3 | 0.1 | 0.2 | 0.7 |
- 交叉熵损失计算
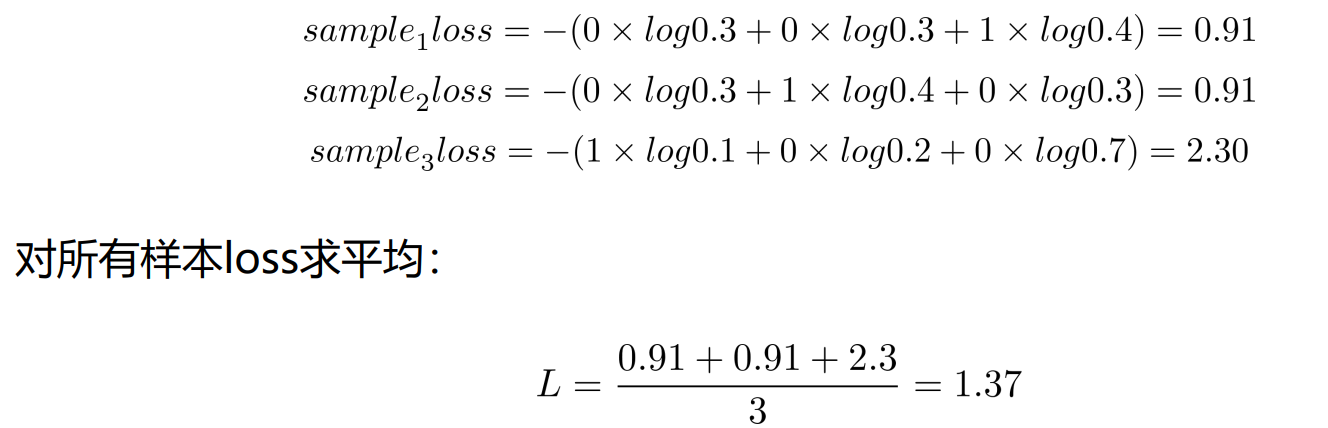
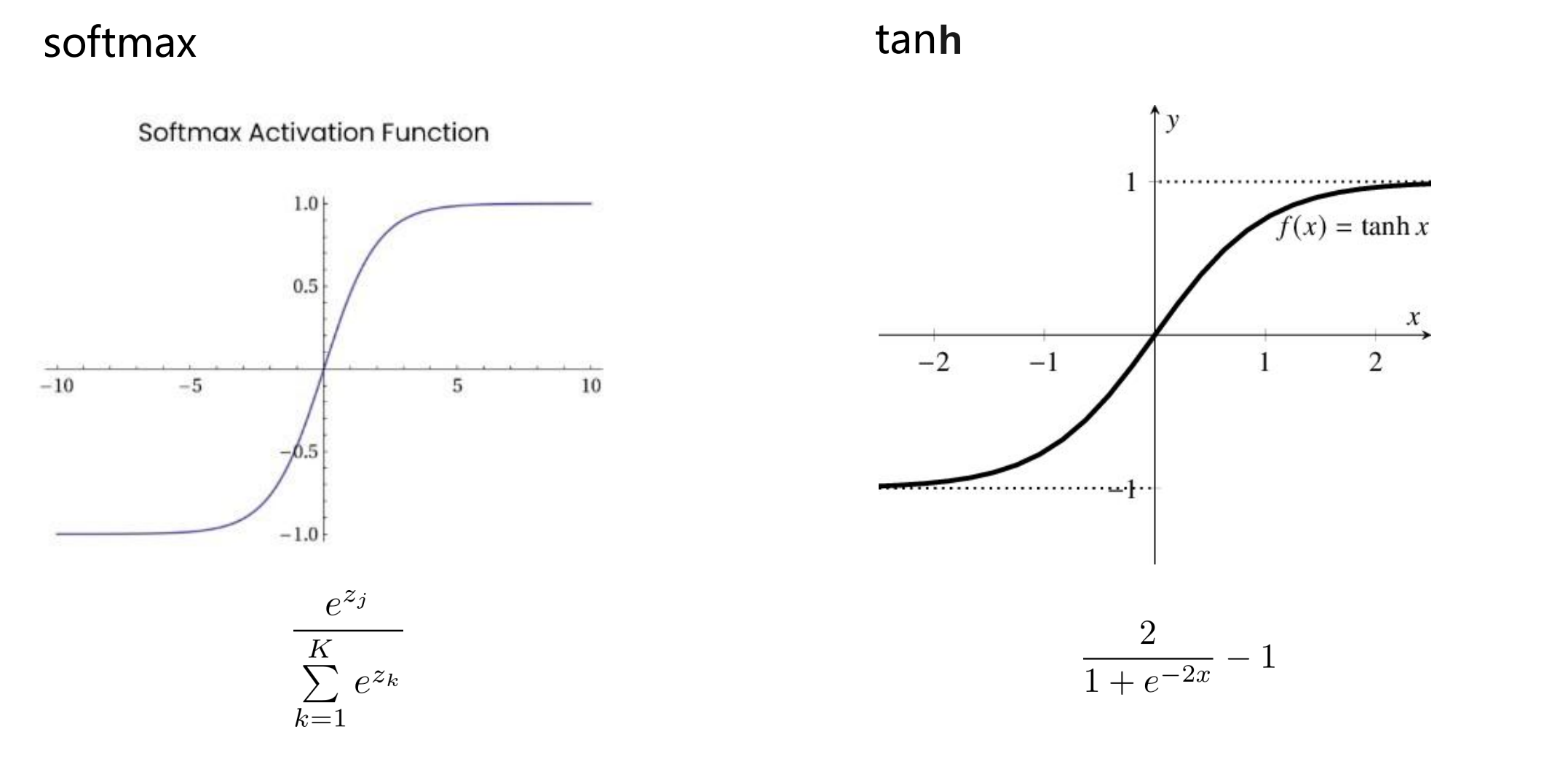
对于不同的分类任务,交叉熵损失函数使用不同的激活函数(sigmoid/softmax)获得概率输出:
- 二分类:使用sigmoid和softmax均可,注意在二分类中,Sigmoid函数,可以当作成它是对一个类别的“建模”,另一个相对的类别就直接通过1减去得到。而softmax函数,是对两个类别建模,同样的,得到两个类别的概率之和是1
- 单标签多分类:交叉熵损失函数使用softmax获取概率输出(互斥输出)
- 多标签多分类:交叉熵损失函数使用sigmoid获取概率输出
优化器
- 优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数损失函数(目标函数)值不断逼近全局最小。
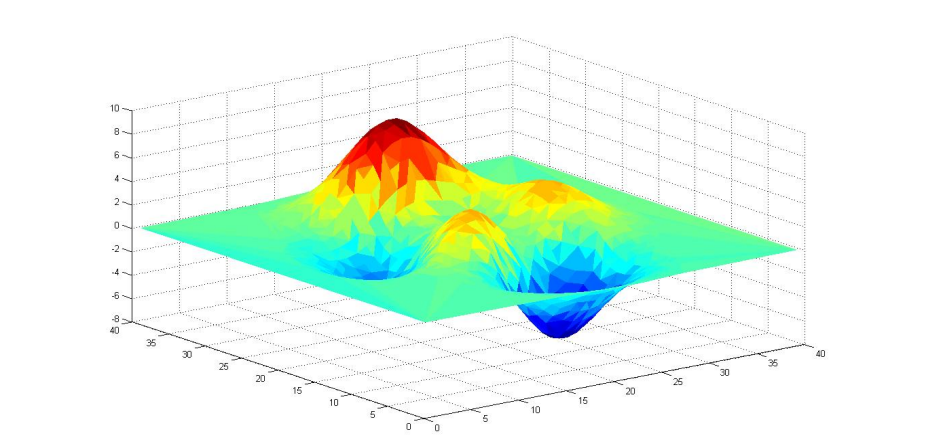
- 如果损失函数是一座山峰,优化器会通过梯度下降,帮助我们以最快的方式,从高山下降到谷底

- 梯度是一个向量,它的每一个分量都是对一个特定变量的偏导数,每个元素都指示了函数里每个变量的最陡上升方向(梯度指向函数增长最多的方向。)
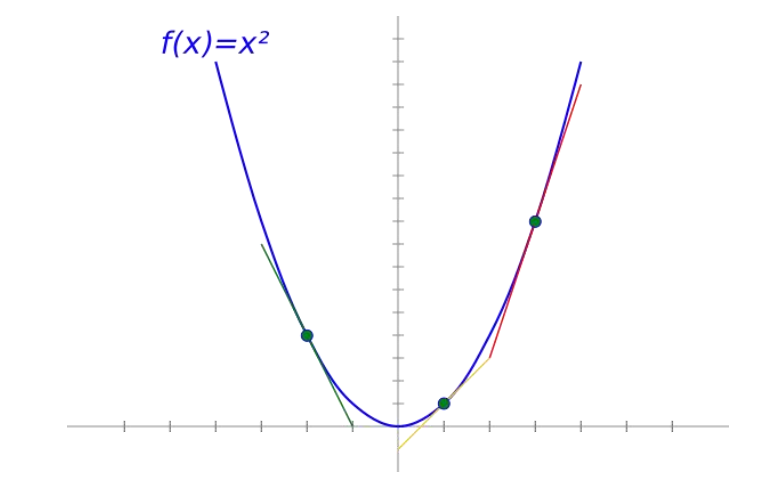
优化器 — 梯度下降
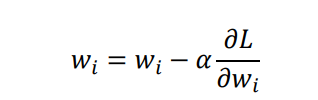
-
BGD:批量梯度下降法在全部训练集上计算精确的梯度。
-
SGD:随机梯度下降法则采样单个样本来估计的当前梯度。
-
mini-batch GD:mini-batch梯度下降法使用batch的一个子集来计算梯度。
-
为获取准确的梯度,批量梯度下降法的每一步都把整个训练集载入进来进行计算,时间花费和内存开销都非常大,无法应用于大数据集、大模型的场景。
-
随机梯度下降法则放弃了对梯度准确性的追求,每步仅仅随机采样一个样本来估计当前梯度,计算速度快,内存开销小。但由于每步接受的信息量有限,随机梯度下降法对梯度的估计常常出现偏差,造成目标函数曲线收敛得很不稳定,伴有剧烈波动,有时甚至出现不收敛的情况。
- 鉴于 BGD 和 SGD 各自的局限性,目前的训练采用 Mini-Batch GD,每次对batch_size的数据进行梯度计算,更新参数
优化器 — Momentum
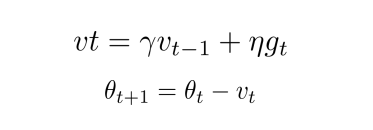
v t vt vt 由两部分组成:一是学习速率 η η η 乘以当前估计的梯度 g t g_t gt ;二是带衰减的前一次步伐 v t − 1 v_{t−1} vt−1 和 g t g_t gt, 而不仅仅是 g t g_t gt。另外,衰减系数 γ γ γ 扮演了阻力的作用
优化器 — AdaGrad
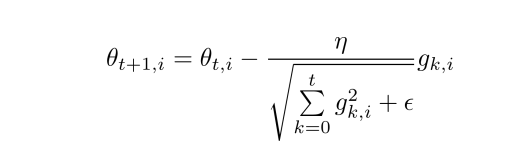
- 引入自适应思想,训练过程中,学习速率逐渐衰减,经常更新的参数其学习速率衰减更快
- AdaGrad方法采用所有历史梯度平方和的平方根做分母,分母随时间单调递增,产生的自适应学习速率随时间衰减的速度过于激进
优化器 — RMSprop
- RMSprop 是 Hinton 在课程中提到的一种方法,是对 Adagrad 算法的改进,主要是解决学习速率过快衰减的问题
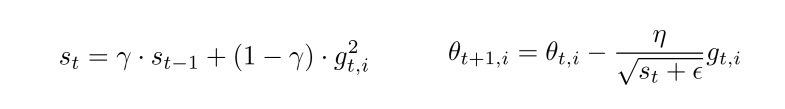
- 采用梯度平方的指数加权移动平均值,其中一般取值0.9,有助于避免学习速率很快下降的问题,学习率建议取值为0.001
优化器 — Adam
- Adam方法将惯性保持(动量)和自适应这两个优点集于一身
- Adam记录梯度的一阶矩(first moment),即过往梯度与当前梯度的平均,这体现了惯性保持:
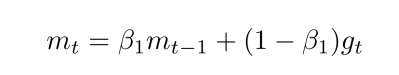
- Adam还记录梯度的二阶矩(second moment),即过往梯度平方与当前梯度平方的平均,这类似AdaGrad方法,体现了自适应能力,为不同参数产生自适应的学习速率:
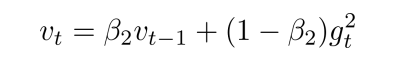
- 一阶矩和二阶矩采用类似于滑动窗口内求平均的思想进行融合,即当前梯度和近一段时间内梯度的平均值,时间久远的梯度对当前平均值的贡献呈指数衰减。
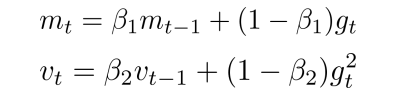
- 其中,β1,β2 为衰减系数,β1通常取值0.9,β2通常取值0.999, m t m_t mt 是一阶矩, v t v_t vt 是二阶矩阵。其中, m t ^ \hat{m_t} mt^
和 v t ^ \hat{v_t} vt^ 是 m t m_t mt、 v t v_t vt 偏差矫正之后的结果
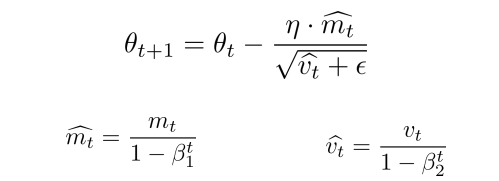
模型评估指标
回归模型
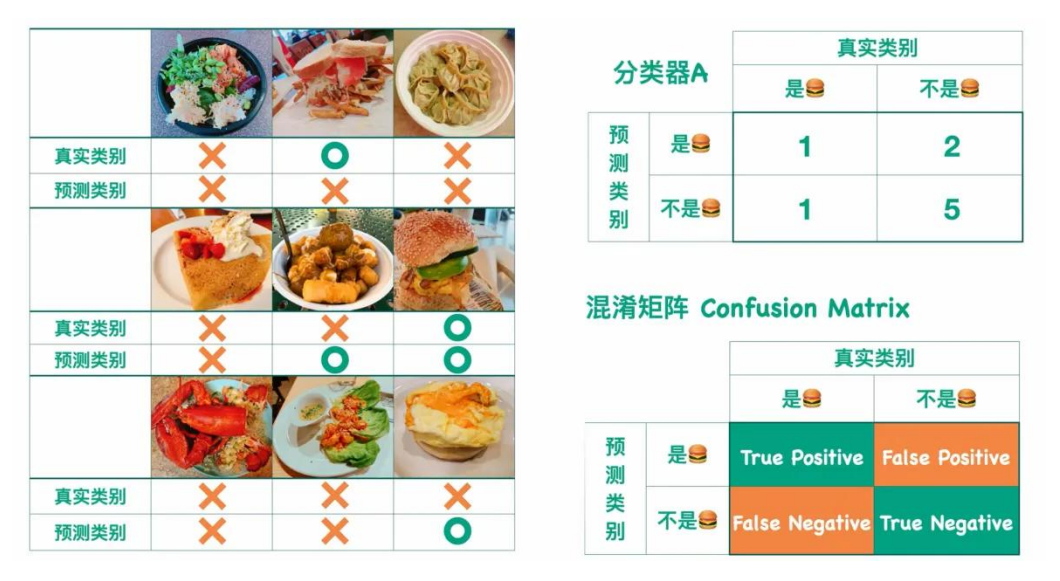
- 混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总
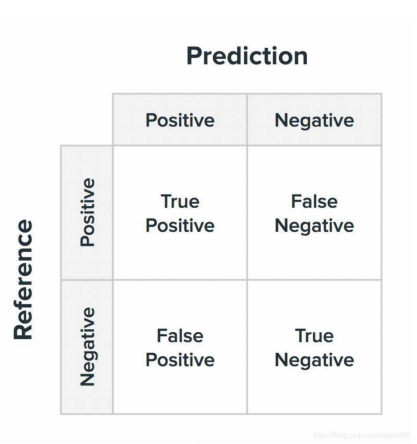
- True Positive(TP):真正类。正类被预测为正类。
- False Negative(FN):假负类。正类被预测为负类。
- False Positive(FP):假正类。负类被预测为正类。
- True Negative(TN):真负类。负类被预测为负类。
- Precision:精准率,表示预测结果中,预测为正样本的样本中,正确预测的概率
T P T P + F P \dfrac{TP}{TP+FP} TP+FPTP - Recall:召回率,表示在原始样本的正样本中,被正确预测为正样本的概率
T P T P + F N \dfrac{TP}{TP+FN} TP+FNTP - Precision值和Recall值是既矛盾又统一的两个指标,为提高Precision值,分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,导致Recall值降低
- F1:F1-score是Precision和Recall两者的综合,是一个综合性的评估指标
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1=\dfrac{2 \times Precision \times Recall}{Precision + Recall} F1=Precision+Recall2×Precision×Recall - Micro-F1:不区分类别,直接使用总体样本的准召计算f1 score。
- Macro-F1:先计算出每一个类别的准召及其f1 score,然后通过求均值得到在整个样本上的f1 score。
- 数据均衡,两者均可;样本不均衡,相差很大,使用Macro-F1;样本不均衡,相差不大,优先选择Micro-F1。
-
MSE:均方误差, y i − y i ^ y_i - \hat{y_i} yi−yi^ 为真实值-预测值。MSE中有平方计算,会导致量纲与数据不一致
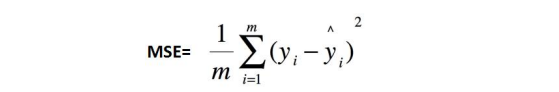
-
RMSE:均方根误差, y i − y i ^ y_i - \hat{y_i} yi−yi^ 为真实值-预测值。解决量纲不一致的问题。
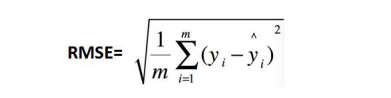
-
MAE:平均绝对误差, y i − y i ^ y_i - \hat{y_i} yi−yi^ 为真实值-预测值。
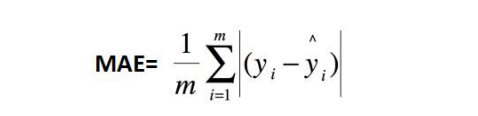
-
RMSE 与 MAE 的量纲相同,但求出结果后我们会发现RMSE比MAE的要大一些。
这是因为RMSE是先对误差进行平方的累加后再开方,它其实是放大较大误差之间的差距。而MAE反应的是真实误差。因此在衡量中使RMSE的值越小其意义越大,因为它的值能反映其最大误差也是比较小的。 -
R 2 R^2 R2
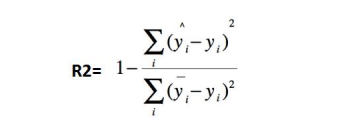
-
决定系数,分子部分表示真实值与预测值的平方差之和,类似于均方差 MSE;分母部分表示真实值与均值的平方差之和,类似于方差 Var。
-
根据 R 2 R^2 R2 的取值,来判断模型的好坏,其取值范围为 [ 0 , 1 ] [0,1] [0,1]:
-
R 2 R^2 R2 越大,表示模型拟合效果越好。 R 2 R^2 R2 反映的是大概的准确性,因为随着样本数量的增加, R 2 R^2 R2 必然增加,无法真正定量说明准确程度,只能大概定量。
-
GSB:通常用于两个模型之间的对比, 而非单个模型的评测,可以用GSB指标评估两个模型在某类数据中的性能差异
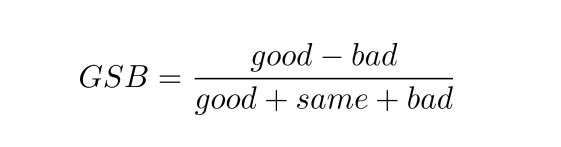
相关文章:
深度学习基础之一:机器学习
文章目录 深度学习基本概念(Basic concepts of deep learning)机器学习典型任务机器学习分类 模型训练的基本概念基本名词机器学习任务流程模型训练详细流程正、反向传播学习率Batch size激活函数激活函数 sigmoid 损失函数MSE & M交叉熵损失 优化器优化器 — 梯度下降优化…...

Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之五 简单指定视频某片段重复播放效果
Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之五 简单指定视频某片段重复播放效果 目录 Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之五 简单指定视频某片段重复播放效果 一、简单介绍 二、简单指定视频某片段重复播放…...
)
ARXML处理 - C#的解析代码(二)
参数类 参数容器(ECUCPARAMCONFCONTAINERDEF)的PARAMETERS集合类由以下参数类实例构成。 枚举参数(ECUCENUMERATIONPARAMDEF ) 配置一个下拉选项,如PORT中一个pin可以配置SPI, CAN, PWM /// <remarks/>[Syste…...

关于华为即将举行的鸿蒙春季沟通会的新闻报道
华为计划在4月11日举办此次活动,届时将推出与车和PC类相关的新产品。尽管备受期待的华为P70系列设备的发布尚未得到官方确认,但已有多家媒体对此进行了报道。 文章中还提到了智界S7的新款可能在4月11日上市,并进行多项新功能升级。智界S7是去…...

MySQL视图及如何导入导出
1.视图 MySQL 视图(View)是一种虚拟存在的表,同真实表一样,视图也由列和行构成,但视图并不实际存在于数据库中。行和列的数据来自于定义视图的查询中所使用的表,并且还是在使用视图时动态生成的࿰…...

文心一言上线声音定制功能;通义千问开源模型;openAI又侵权?
文心一言上线定制专属声音功能 百度旗下 AI 聊天机器人文心一言上线新功能,用户录音一句话,即可定制声音。 使用这项功能需要使用文心一言 App。在创建智能体中,点击创建自己的声音,朗读系统提示的一句话,等候几秒钟时…...

课时89:流程控制_函数进阶_函数变量
2.1.4 综合案例 这一节,我们从 信息采集、环境部署、小结 三个方面来学习。 信息采集 脚本实践-采集系统负载信息 查看脚本内容 [rootlocalhost ~]# cat function_systemctl_load.sh #!/bin/bash # 功能:采集系统负载信息 # 版本:v0.3 # …...
)
Linux命令-dpkg-preconfigure命令(Debian Linux中软件包安装之前询问问题)
说明 dpkg-preconfigure命令 用于在Debian Linux中软件包安装之前询问问题。 语法 dpkg-preconfigure(选项)(参数)选项 -f:选择使用的前端; -p:感兴趣的最低的优先级问题; --apt:在apt模式下运行。参数 软件包&am…...

SEO优化艺术:精细化技巧揭示与搜索引擎推广全面战略解读
SEO(搜索引擎优化,Search Engine Optimization)是一种网络营销策略,旨在通过改进网站内外的各项元素,提升网站在搜索引擎自然搜索结果中的排名,从而吸引更多目标用户访问网站,增加流量ÿ…...
《springcloud alibaba》 四 seata安装以及使用
目录 准备调整db配置准备创建数据库 seata配置nacos配置confi.txt下载向nacos推送配置的脚本 启动seata新建项目order-seata项目 订单项目数据库脚本pom.xmlapplication.yml启动类实体类dao类service类controller类feign类mapper类 stock-seata 库存项目数据库脚本pom.xmlappli…...

-bash: cd: /etc/hadoop: 没有那个文件或目录
解决办法:source /etc/profile 运行 source /etc/profile 命令会重新加载 /etc/profile 文件中的配置,这样做的目的是使任何更改立即生效,而不需要注销并重新登录用户。通常,/etc/profile 文件包含系统范围的全局 Shell 配置&…...
JVM字节码与类加载——字节码指令集与解析
文章目录 1、概述1.1、字节码与数据类型1.2、指令分类 2、加载与存储指令2.1、局部变量入栈指令2.2、常量入栈指令2.3、出栈装入局部变量表指令 3、算术指令3.1、彻底理解i与i3.2、比较指令 4、类型转换指令4.1、宽化类型转换4.2、窄化类型转换 5、对象、数组的创建与访问指令5…...
景芯2.5GHz A72训练营dummy添加(一)
景芯A72做完布局布线之后导出GDS,然后进行GDS merge,然后用Calibre对Layout添加Dummy。在28nm以及之前的工艺中,Dummy metal对Timing的影响不是很大,当然Star RC也提供了相应的解决方案,可以考虑Dummy metal来抽取RC。…...

React - 请你说一说setState是同步的还是异步的
难度级别:中高级及以上 提问概率:70% 在React项目中,使用setState可以更新状态数据,而不能直接使用为this.state赋值的方式。而为了避免重复更新state数据,React首先将state添加到状态队列中,此时我们可以通过shouldComponentUpdate这个钩…...
设计模式之命令模式(下)
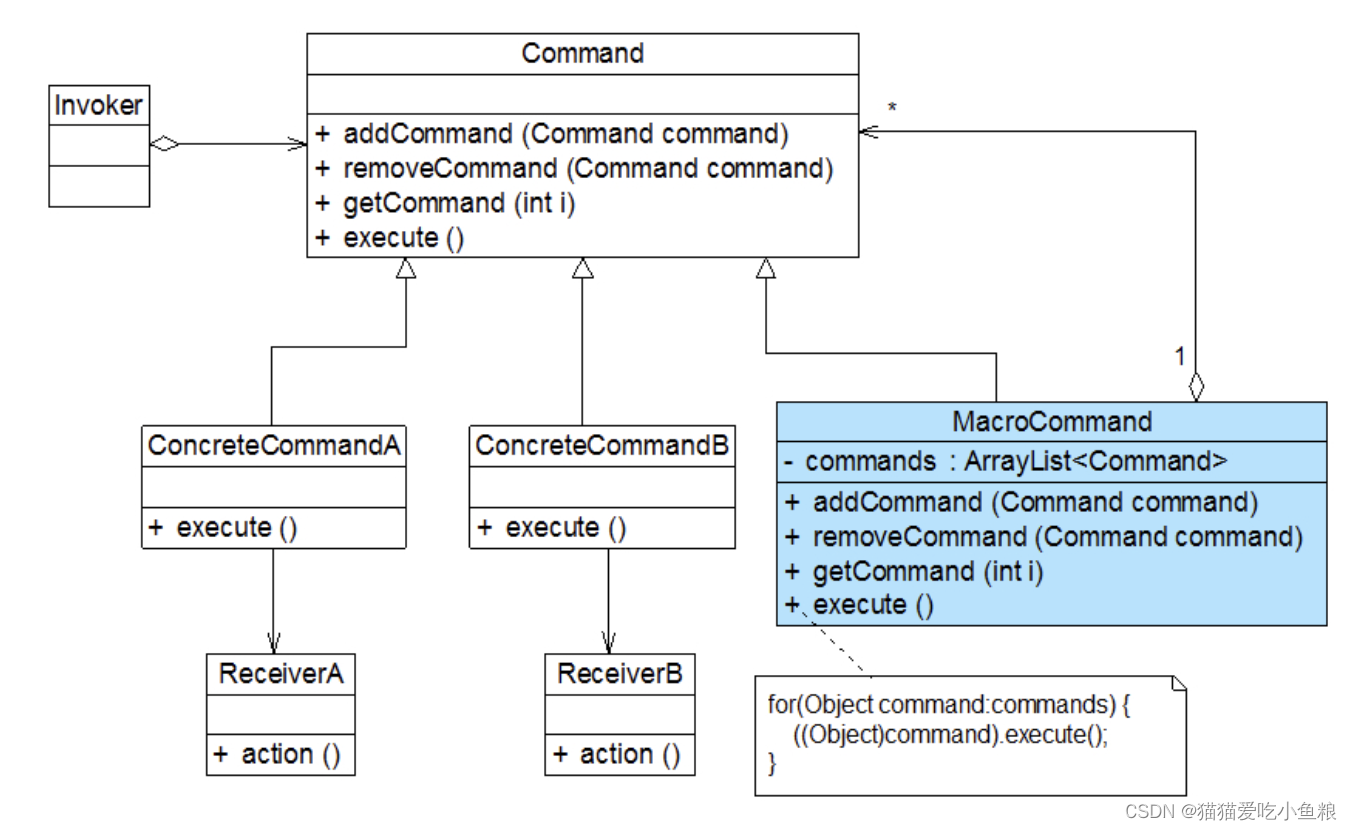
2)完整解决方案 1.结构图 FBSettingWindow是“功能键设置”界面类,FunctionButton充当请求调用者,Command充当抽象命令类,MinimizeCommand和HelpCommand充当具体命令类,WindowHanlder和HelpHandler充当请求接收者。 …...

【opencv】示例-demhist.cpp 调整图像的亮度和对比度,并在GUI窗口中实时显示调整后的图像以及其直方图。...
#include "opencv2/core/utility.hpp" // 包含OpenCV核心工具库的头文件 #include "opencv2/imgproc.hpp" // 包含OpenCV图像处理的头文件 #include "opencv2/imgcodecs.hpp" // 包含OpenCV图像编码解码的头文件 #include "opencv2/highgui…...

计算机网络---第三天
OSI参考模型与TCP/IP模型 参考模型产生背景: 背景:①兼容性较差,接口不统一 ②不利于排错与维护 ③设备成本高 参考模型概念: 概念:OSI参考模型定义了网络中设备所遵守的层次结构 参考模型优点: 优点…...

怎么防止文件被拷贝,复制别人拷贝电脑文件
怎么防止文件被拷贝,复制别人拷贝电,脑文件 防止文件被拷贝通常是为了保护敏感数据、知识产权或商业秘密不被未经授权的人员获取或传播。以下列出了一系列技术手段和策略,可以帮助您有效地防止文件被拷贝。 1. 终端管理软件: 如安企神、域智…...

流式密集视频字幕
流式密集视频字幕 摘要1 IntroductionRelated Work3 Streaming Dense Video Captioning Streaming Dense Video Captioning 摘要 对于一个密集视频字幕生成模型,预测在视频中时间上定位的字幕,理想情况下应该能够处理长的输入视频,预测丰富、…...
【教程】iOS Swift应用加固
🔒 保护您的iOS应用免受恶意攻击!在本篇博客中,我们将介绍如何使用HTTPCORE DES加密来加固您的应用程序,并优化其安全性。通过以下步骤,您可以确保您的应用在运行过程中不会遭受数据泄露和未授权访问的风险。 摘要 …...

观察使用TaotokenTokenPlan后项目月度AI成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Taotoken TokenPlan后项目月度AI成本的变化趋势 对于许多采用按量计费模式的中小型项目而言,大模型API的月度支…...

【亲测免费】 PLC1200四路抢答器程序:打造高效公平的抢答体验
PLC1200四路抢答器程序:打造高效公平的抢答体验 【下载地址】PLC1200四路抢答器程序 本仓库提供了一个完整的S7-1200四路抢答器程序,可以直接下载并使用。该程序适用于需要进行四路抢答的场景,如竞赛、培训等。程序经过精心设计和测试&#x…...

Arm SMIN指令解析:多向量最小值计算与优化实践
1. Arm SMIN指令深度解析:多向量最小值计算实战指南在Armv9架构的SVE2指令集中,SMIN(Signed Minimum)指令作为向量处理的重要成员,专门用于计算多组向量元素间的有符号最小值。我第一次在嵌入式AI项目中用到这个指令时…...

自动驾驶安全基石:从ODD到ODC的设计原则与工程实践
1. 自动驾驶安全的底层逻辑:为什么需要ODD与ODC? 十年前我第一次接触自动驾驶系统时,工程师们最常讨论的是传感器精度和算法性能。直到参与某L3级高速领航项目后,我才真正理解:定义"在什么条件下能安全运行"…...
)
What Are You Talking About(HDU- P1075)
伊格纳修斯真是走了狗屎运,昨天居然遇到了火星人!可惜他完全听不懂火星人的语言。临走时,火星人给了他一本火星历史书和一本词典。现在伊格纳修斯想把这本历史书翻译成英语,你能帮帮他吗?输入本题只有一组测试数据&…...

构建Web化配置中心:从环境变量管理到实时热更新的工程实践
1. 项目概述与核心价值最近在折腾一个挺有意思的小项目,叫Laliet/cc-switch-web。乍一看这个标题,可能有点摸不着头脑,但如果你是一个经常需要处理不同环境配置、或者在不同服务之间切换的前端或全栈开发者,这个项目很可能就是你一…...
)
限时开放|Perplexity学术搜索私藏工作区(含18个学科定制模板+实时更新的期刊影响因子映射表)
更多请点击: https://kaifayun.com 第一章:Perplexity学术搜索的核心价值与适用场景 Perplexity.ai 并非传统搜索引擎,而是一个融合大语言模型推理能力与实时学术信息检索的智能研究协作者。其核心价值在于将“提问—验证—溯源”闭环内化为…...

什么是“中国词元”?——解析中国AI自主生态的核心公式与关键平台
在当前的AI发展阶段,构建自主可控的产业生态已成为关键议题。本文将解析“中国词元”(Chinese Tokens)这一核心概念,并介绍其关键支撑平台——模力方舟Moark。文章面向AI开发者、企业技术决策者及生态关注者,旨在阐明如…...

UE5新手必看:给你的自定义Pawn加上碰撞,别再让它“穿墙”了!
UE5碰撞系统实战:从零构建防穿墙Pawn的完整指南 当你在UE5中第一次创建自定义Pawn时,最令人沮丧的莫过于看着自己精心设计的角色像幽灵一样穿过墙壁和障碍物。这种"穿模"现象不仅破坏游戏体验,更会导致后续游戏逻辑的全面崩溃。本文…...

Linux常用命令之文件操作命令零基础教程
前言 本文整理了目录创建、文件创建/写入/查看/删除、重命名剪切复制、压缩解压、权限修改全套常用命令,完全零基础友好,逐条讲解、附带语法和实操用法。 一、目录创建命令 mkdir 1. 基础语法 mkdir 目录名称作用:创建单个空目录 2. 查看帮助…...