深度学习的层、算子和函数空间
目录
一、层、算子和函数空间概念
二、层(Layers)
三、算子(Operators)
3.1常见算子
3.2常见算子的性质
四、函数空间(Function Space)
一、层、算子和函数空间概念
层(Layers):层是神经网络的基本构建块,用于实现从输入到输出的数据转换。每一层都包含一组参数,这些参数在训练过程中被学习以最小化损失函数。不同类型的层执行不同的功能,比如全连接层、卷积层、池化层、循环层等。层之间的连接形成了神经网络的拓扑结构,通过堆叠不同类型的层可以构建出各种复杂的神经网络结构。
算子(Operators):在深度学习中,算子通常指的是对数据进行特定操作的函数或操作符。这些操作可以是数学运算、变换、激活函数等,用于在神经网络中实现各种功能。例如,卷积运算、池化运算、激活函数(如ReLU)、归一化操作等都可以看作是算子。在深度学习框架中,通常会提供各种内置的算子来方便用户构建神经网络模型。
函数空间(Function Space):函数空间是指包含所有可能函数的集合。在深度学习中,神经网络模型可以看作是在函数空间中搜索最优函数的过程。每个神经网络模型都定义了一个函数族,通过调整模型的参数(即权重和偏置),可以使得模型逼近目标函数。因此,神经网络的训练过程实质上就是在函数空间中寻找最优函数的过程。不同类型的神经网络结构对应于不同的函数空间,而训练过程则是在这些函数空间中搜索最优解的过程。
二、层(Layers)
层是构建神经网络模型的基本组件,负责数据的转换和特征提取。不同类型的层执行不同的功能,并且可以根据任务的需求灵活组合和堆叠。
以下是常见的神经网络层类型及其功能:
全连接层(Fully Connected Layer):也称为密集连接层或线性层。全连接层中的每个神经元与上一层的所有神经元相连,每个连接都有一个权重参数。这种层常用于在输入数据上执行线性变换,并且通常会接一个非线性激活函数,如ReLU、Sigmoid或Tanh。
卷积层(Convolutional Layer):卷积层主要用于处理图像数据,通过应用卷积操作来提取特征。卷积操作可以捕捉输入数据中的局部相关性,并且通过共享权重的方式减少参数数量。卷积层通常包含多个卷积核(或滤波器),每个卷积核对输入数据执行卷积操作以生成输出特征图。
池化层(Pooling Layer):池化层用于减少特征图的空间维度,从而减少计算量并增强模型的鲁棒性。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling),它们分别选择输入特征图中局部区域的最大值或平均值作为输出。
循环层(Recurrent Layer):循环层用于处理序列数据,如文本、时间序列等。循环层中的神经元会保存一个状态,并且可以接收来自上一时间步的输入和上一状态的输出。这使得循环层能够考虑序列数据的时间依赖关系。
嵌入层(Embedding Layer):嵌入层通常用于将高维的离散数据(如单词或类别)映射到低维的连续向量空间中。这种技术在处理自然语言处理任务中特别常见,如词嵌入(Word Embeddings)。
归一化层(Normalization Layer):归一化层用于加速模型收敛并提高泛化性能。常见的归一化技术包括批归一化(Batch Normalization)和层归一化(Layer Normalization),它们通过规范化每层的输入或激活值来减少训练过程中的内部协变量偏移。
注意力层(Attention Layer):注意力机制用于加强模型对输入中不同部分的关注程度。在处理序列数据时,注意力层可以帮助模型动态地学习到输入序列中的重要部分,并在输出时进行加权融合。
这些是常见的神经网络层类型,每种类型都有其特定的功能和应用场景。在构建神经网络模型时,通常会根据任务的需求选择合适的层类型并进行堆叠组合,以实现对输入数据的高效处理和表征学习。
三、算子(Operators)
3.1常见算子
算子通常指的是对数据进行特定操作的函数或操作符。这些操作可以是数学运算、变换、激活函数等,用于在神经网络中实现各种功能。下面是一些常见的算子及其功能:
卷积算子(Convolution Operator):用于图像处理和特征提取。卷积操作将一个滤波器(卷积核)与输入数据进行卷积运算,产生输出特征图。卷积操作可以捕获输入数据的局部空间结构,并且通过共享权重的方式减少参数数量。
池化算子(Pooling Operator):用于减少特征图的空间维度,降低计算复杂度。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling),它们分别选择输入特征图中局部区域的最大值或平均值作为输出。
激活函数(Activation Function):用于在神经网络中引入非线性变换,增加模型的表达能力。常见的激活函数包括ReLU(Rectified Linear Unit)、Sigmoid、Tanh等,它们将输入信号映射到不同的输出范围内。
批归一化算子(Batch Normalization Operator):用于加速模型训练过程并提高模型的泛化性能。批归一化算子在每个批次的数据上进行归一化操作,有助于减少内部协变量偏移并加速梯度下降过程。
Dropout算子:用于减少神经网络的过拟合现象。Dropout算子会随机地丢弃网络中的一些神经元及其连接,以防止神经网络过度依赖某些特征。
全连接算子(Fully Connected Operator):也称为线性变换或仿射变换。全连接算子将输入数据与权重矩阵相乘,并加上偏置向量,实现从输入到输出的线性变换。
Softmax算子:用于将神经网络的输出转化为概率分布。Softmax算子将神经网络的原始输出进行归一化,并将其转化为表示概率的形式,常用于多分类任务的输出层。
损失函数(Loss Function):用于衡量模型预测结果与真实标签之间的差异。损失函数通常定义了模型在训练过程中需要最小化的目标,常见的损失函数包括交叉熵损失、均方误差损失等。
这些算子是构建神经网络模型时经常用到的基本组件,它们通过组合和堆叠实现了对输入数据的复杂处理和特征提取,从而实现了各种不同类型任务的解决。
3.2常见算子的性质
卷积算子:
- 局部性:卷积操作在输入数据的局部区域上进行滑动,捕获了数据的局部空间结构。
- 参数共享:卷积核的参数在整个输入数据上共享,这样可以减少模型的参数数量。
- 平移不变性:卷积操作具有平移不变性,即对输入数据进行平移操作后,输出结果不变。
- 稀疏交互性:卷积操作的参数只与输入数据的局部区域相关,因此在处理高维数据时,具有稀疏交互性,减少了计算复杂度。
池化算子:
- 降维:池化操作通过选择局部区域的最大值或平均值来减少特征图的空间维度,降低了计算复杂度。
- 平移不变性:池化操作通常具有平移不变性,即对输入数据进行平移操作后,输出结果不变。
- 特征不变性:最大池化操作具有特征不变性,即对输入数据的小变化不敏感,有助于提取更加鲁棒的特征。
激活函数:
- 非线性变换:激活函数引入了非线性变换,增加了神经网络的表达能力,可以学习到更加复杂的函数关系。
- 可微性:激活函数通常要求是可微的,以便在反向传播过程中计算梯度。
- 饱和性:一些激活函数在输入值较大或较小时可能会饱和,导致梯度消失问题。
批归一化算子:
- 加速训练:批归一化操作有助于加速模型的收敛过程,并且增加了模型对学习率的鲁棒性。
- 规范化:批归一化操作可以使得每个批次的数据具有相似的分布,有助于减少内部协变量偏移。
Dropout算子:
- 防止过拟合:Dropout操作通过随机丢弃一部分神经元及其连接,可以降低模型对某些特征的依赖,从而减少过拟合现象。
- 集成学习:Dropout可以看作是对模型进行集成学习的一种形式,增加了模型的鲁棒性和泛化能力。
全连接算子:
- 参数化:全连接操作将输入数据与权重矩阵相乘,并加上偏置向量,实现从输入到输出的线性变换。
- 表达能力:全连接层具有较高的表达能力,但也容易导致过拟合问题,特别是在参数数量较大时。
Softmax算子:
- 输出概率分布:Softmax操作将神经网络的原始输出进行归一化,将其转化为表示概率的形式,常用于多分类任务的输出层。
- 单调性:Softmax操作保持了输入的单调性,即输出概率随着输入值的增加而增加。
损失函数:
- 衡量差异:损失函数用于衡量模型预测结果与真实标签之间的差异,是优化算法的目标函数。
- 可微性:损失函数通常要求是可微的,以便在反向传播过程中计算梯度并更新模型参数。
四、函数空间(Function Space)
函数空间是指包含所有可能函数的集合。在深度学习中,函数空间是一个非常重要的概念,因为神经网络模型本质上就是在函数空间中搜索最优函数的过程。
具体来说,神经网络模型可以看作是参数化的函数族,即通过调整模型的参数(如权重和偏置),可以生成不同的函数。这些函数可以实现从输入到输出的复杂映射关系,例如图像分类、语言翻译等任务。
函数空间的大小取决于神经网络模型的复杂性和参数数量。通常情况下,神经网络模型的参数越多,函数空间的维度就越高,可以表示的函数也就越复杂。而训练过程则是在函数空间中搜索最优函数的过程,即寻找能够最好地拟合训练数据并且具有良好泛化能力的函数。
在深度学习中,通过使用各种优化算法(如梯度下降)来调整模型的参数,从而在函数空间中搜索最优函数。训练过程中的目标是最小化损失函数,即模型预测与真实标签之间的差异,以使模型学到的函数尽可能地接近目标函数。
函数空间是深度学习中一个抽象而关键的概念,它描述了神经网络模型的表达能力和训练过程的基本原理。理解函数空间的概念有助于深入理解神经网络的工作原理以及训练过程中的优化方法。
相关文章:

深度学习的层、算子和函数空间
目录 一、层、算子和函数空间概念 二、层(Layers) 三、算子(Operators) 3.1常见算子 3.2常见算子的性质 四、函数空间(Function Space) 一、层、算子和函数空间概念 层(Layers)…...

Pillow教程11:九宫格切图的实现方法(安排!!!)
---------------Pillow教程集合--------------- Python项目18:使用Pillow模块,随机生成4位数的图片验证码 Python教程93:初识Pillow模块(创建Image对象查看属性图片的保存与缩放) Pillow教程02:图片的裁…...

Macos 部署自己的privateGpt(2024-0404)
Private Chatgpt 安装指引 https://docs.privategpt.dev/installation/getting-started/installation#base-requirements-to-run-privategpt 下载源码 git clone https://github.com/imartinez/privateGPT cd privateGPT安装软件 安装: Homebrew /bin/bash -c…...

先安装CUDA后安装Visual Studio的额外配置
VS新建项目中增加CUDA选项 以vs2019 cuda 11.3为例 关闭vs2019解压cuda的windows安装包cuda_11.3.0_465.89_win10.exe进入路径cuda_11.3.0_465.89_win10\visual_studio_integration\CUDAVisualStudioIntegration\extras\visual_studio_integration\CudaProjectVsWizards\拷贝…...

2024 蓝桥打卡Day35
20240407蓝桥杯备赛 1、学习蓝桥云课省赛冲刺课 【3-搜索算法】【4-枚举与尺度法】2、学习蓝桥云课Java省赛无忧班 【1-语言基础】3、代码练习数字反转数字反转优化算法sort排序相关String字符串相关StringBuilder字符串相关HashSet相关 1、学习蓝桥云课省赛冲刺课 【3-搜索算法…...
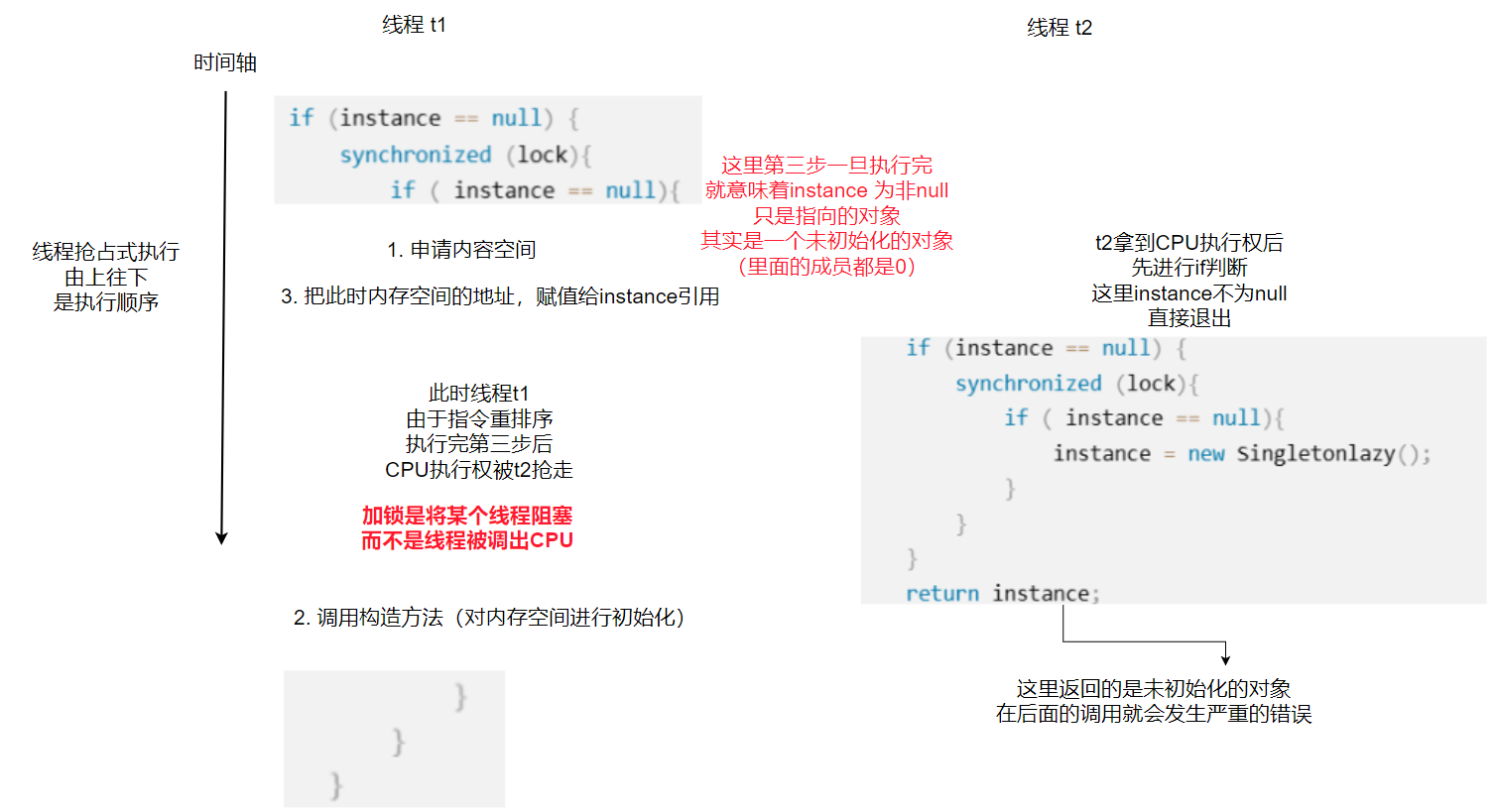
【Java】单例模式
单例模式是面试中常考的设计模式之一 在面试中,面试官常常会要求写出两种类型的单例模式并解释原理 本文中,将从0到1的介绍单例模式究竟是什么 文章目录 ✍一、什么是设计模式?✍二、单例模式是什么?✍三、单例模式的类型**1.饿汉…...

Linux|从 STDIN 读取 Awk 输入
简介 在之前关于 Awk 工具的系列文章中,主要探讨了如何从文件中读取数据。但如果你希望从标准输入(STDIN)中读取数据,又该如何操作呢? 在本文中,将介绍几个示例,展示如何使用 Awk 来过滤其他命令…...

关于K8S集群中maste节点r和worker节点的20道面试题
1. 什么是Kubernetes(K8S)? Kubernetes(通常简称为K8S)是一种开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。以下是Kubernetes的一些核心特性和优势: 自动化部署和扩展&…...

基于 OpenHarmony HistogramComponent 柱状图开发指南
1. HistogramComponent 组件功能介绍 1.1. 功能介绍 应用开发过程,用鸿蒙提供的 Component 自定义柱状图效果。 HistogramComponent 组件可以更快速实现一个简单的柱状图功能。 HistogramComponent 对外提供数据源,修改柱状图颜色,间距的…...

C语言指针相关
C语言指针int(*p)[4]如何理解? 快速搞懂 C/C 指针声明...

设计模式:责任链模式
责任链模式是一种行为设计模式,允许你将请求沿着一条链传递,直到一个对象处理它为止。这种模式包含了一些处理对象,每个对象都包含逻辑来处理特定类型的命令或请求。如果一个对象不能处理该请求,它就会将请求传递给链中的下一个对象,如此类推。 定义 责任链模式通过定义…...

【Linux】 OpenSSH_9.3p1 升级到 OpenSSH_9.6p1(亲测无问题,建议收藏)
👨🎓博主简介 🏅CSDN博客专家 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入!…...

宁波中墙建材对于蒸压加气混凝土砌块2024年前景预测
宁波中墙建材对于蒸压加气混凝土砌块2024年前景预测 蒸压加气混凝土砌块(AAC)是一种轻质、多孔、保温隔热性能良好的建筑材料,广泛应用于建筑领域。2024年前景预测如下: 市场需求持续增长:随着全球对节能减排和绿色建筑…...
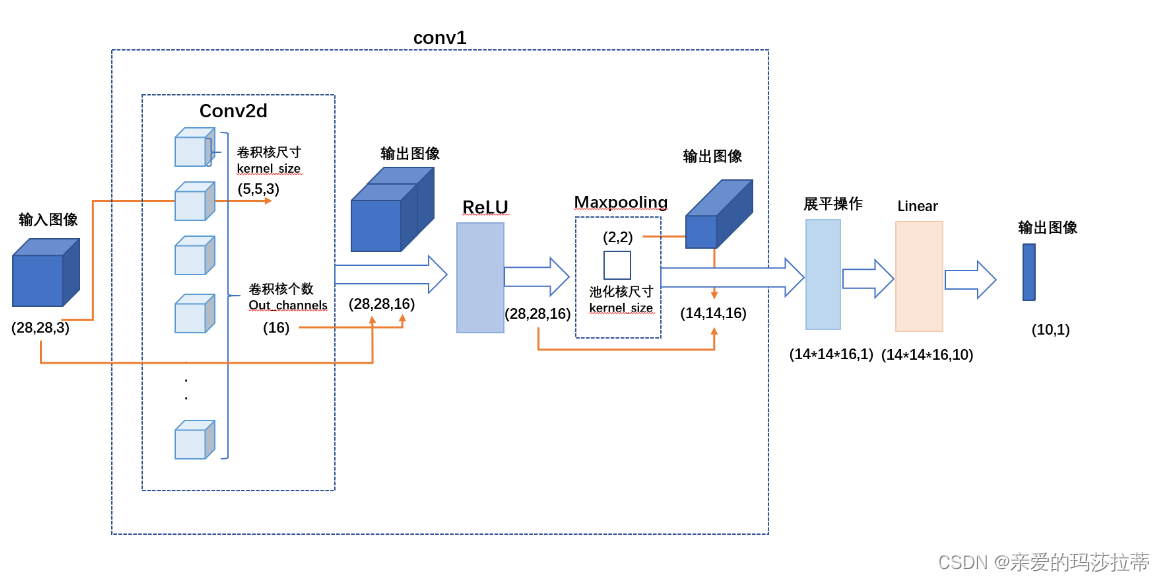
【神经网络】卷积神经网络CNN
卷积神经网络 欢迎访问Blog全部目录! 文章目录 卷积神经网络1. 神经网络概览2.CNN(Convolutional Neunal Network)2.1.学习链接2.2.CNN结构2.2.1.基本结构2.2.1.1输入层2.2.1.2.卷积层|Convolution Layers2.2.1.3.池化层|Pooling layers2.3…...
微信小程序-接入sse数据流并实现打字机效果( ChatGPT )
从流中获取的数据格式如下 小程序调用SSE接口 const requestTask wx.request({url: xxx, // 需要请求的接口地址enableChunked: true, // enableChunked必须为truemethod: "GET",timeout: 120000,success(res) {console.log(res.data)},fail: function (error) {//…...
深入了解iOS内存(WWDC 2018)笔记-内存诊断
主要记录下用于分析iOS/macOS 内存问题的笔记。 主要分析命令: vmmap, leaks, malloc_history 一:前言 有 3 种思考方式 你想看到对象的创建吗?你想要查看内存中引用对象或地址的内容吗?或者你只是想看看 一个实例有多大&#…...

《C语言深度解剖》(4):深入理解一维数组和二维数组
🤡博客主页:醉竺 🥰本文专栏:《C语言深度解剖》 😻欢迎关注:感谢大家的点赞评论关注,祝您学有所成! ✨✨💜💛想要学习更多数据结构与算法点击专栏链接查看&am…...

信号处理基础
傅里叶分析之掐死教程(完整版)更新于2014.06.06 先放一篇关于傅里叶变换以及欧拉公式的讲解在这里。后续会搬运到CSDN上。...

原地移除数组中所有的元素val,要求时间复杂度为O(N),空间复杂度为O(1)
一、题目描述 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超…...
如何提升产品用户体验?4个工具+6张案例,让你快速吃透!
在数字时代的浪潮中,产品用户体验早已不再是简单的“好用”或“不好用”的评判标准,它不仅仅是功能的堆砌,更是情感的连接、智慧的体现。在这个竞争激烈的市场中,只有那些能够深入理解用户需求、精准把握用户心理的产品࿰…...

第二章 小程序目录结构与核心文件详解
第二章 小程序目录结构与核心文件详解 📚 系列教程:微信小程序投票系统完整开发 🔗 上一章:第一章 - 微信小程序概述与开发准备 🔗 下一章:第三章 - WXML 所有表单组件与使用 2.1 完整目录结构 wx/page/ …...

Win11Debloat免费工具:3步彻底清理Windows 11垃圾,性能提升51%
Win11Debloat免费工具:3步彻底清理Windows 11垃圾,性能提升51% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes …...

OBS实时字幕插件完整指南:3分钟快速部署专业直播字幕
OBS实时字幕插件完整指南:3分钟快速部署专业直播字幕 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin OBS实时字幕插件是一款基于Go…...

毫秒算网的光通信技术——从“东数西算“到“毫秒用算“
引言:从"算力在哪"到"算力怎么到" 2021年启动的"东数西算"工程回答了一个根本问题:算力应该布局在哪里。通过在西部建设8大枢纽、10大集群,国家将算力基础设施与绿色能源禀赋深度耦合,开启了算力地…...

react项目优化方案
下面给你一套实战级、可直接落地的 React 项目优化策略,覆盖 渲染性能、打包体积、代码层面、体验层面、工程层面。 适合 中大型 React / React TS 项目。一、渲染性能优化(最核心 ⭐) 1️⃣ 减少不必要的重渲染 ✅ React.memo const Child …...

信步NSE SVX-C2304嵌入式主板拆解:Elkhart Lake平台在工业边缘计算的应用
1. 项目概述:一块嵌入式主板的深度拆解最近在整理一个工业边缘计算项目的硬件选型方案,手头拿到了一块信步科技(Seavo)的NSE SVX-C2304嵌入式主板。这名字听起来可能有点“板正”,不像消费级产品那样花哨,但…...

GIT 切换分支合并分支前一定要先 fetch,一定要选择远程分支进行操作
测试 GIT 切换分支 合并分支 1、切换和合并分支时,要选择远程的分支,确保本地的代码是最新的 2、切换分支前不 fetch3、切换分支前先点 fetch4、合并分支前不 fetch5、合并分支前先 fetch...

机器学习40讲-总结课:机器学习的模型体系
用17讲的篇幅,我和你分享了目前机器学习中的大多数主流模型。可是除开了解了各自的原理,这些模型背后的共性规律在哪里,这些规律又将如何指导对于新模型的理解呢?这就是今天这篇总结的主题。 要想在纷繁复杂的模型万花筒中梳理出一条清晰的脉络,还是要回到最原始的出发点…...

LAMMPS效率翻倍秘籍:从单机到并行,你的MPICH配置真的对了吗?
LAMMPS效率翻倍秘籍:从单机到并行,你的MPICH配置真的对了吗? 在分子动力学模拟领域,LAMMPS因其开源特性和强大的计算能力成为研究者的首选工具。然而,许多用户在使用过程中常遇到一个令人沮丧的现象——明明配置了多核…...

避开这些坑!用AD5934测量从3Ω到100kΩ阻抗的实战经验与校准技巧
避开这些坑!用AD5934测量从3Ω到100kΩ阻抗的实战经验与校准技巧 在精密阻抗测量领域,AD5934作为一款高集成度的阻抗转换芯片,凭借其宽频带扫描能力和数字解调技术,成为从生物传感器到材料分析等多个领域的核心器件。但实际应用中…...