01 Python进阶:正则表达式
re.match函数
使用 Python 中的 re 模块时,可以通过 re.match() 函数来尝试从字符串的开头匹配一个模式。以下是一个简单的详解和举例:
import re# 定义一个正则表达式模式
pattern = r'^[a-z]+' # 匹配开头的小写字母序列# 要匹配的字符串
text = "hello world"# 使用 re.match() 尝试匹配模式
match_obj = re.match(pattern, text)if match_obj:print("匹配成功:", match_obj.group())
else:print("无匹配结果")
在这个示例中,我们使用了 re.match() 函数来尝试从字符串的开头匹配一个小写字母序列。让我们具体解释一下:
-
r'^[a-z]+':这是一个正则表达式模式,包含了以下几个部分:^表示匹配字符串的开头。[a-z]表示匹配任意一个小写字母。+表示匹配前面的模式一次或多次。
-
"hello world":这是我们要进行匹配的字符串。 -
re.match(pattern, text):使用 re.match() 函数尝试从字符串开头匹配指定的模式。 -
match_obj:re.match() 函数返回一个 Match 对象,如果匹配成功则包含匹配的结果,否则为 None。 -
match_obj.group():如果匹配成功,可以通过 match_obj.group() 方法获取匹配的内容。
在这个示例中,由于 “hello” 符合模式 r'^[a-z]+',因此匹配成功,输出 “匹配成功: hello”。
re.search方法
可以通过 re.search() 函数来搜索整个字符串,尝试找到与指定模式匹配的子串。以下是一个详细解释和示例:
import re# 定义一个正则表达式模式
pattern = r'world' # 要匹配的模式是 "world"# 要搜索的字符串
text = "hello world"# 使用 re.search() 方法在整个字符串中搜索模式
search_obj = re.search(pattern, text)if search_obj:print("找到匹配:", search_obj.group())
else:print("未找到匹配")
在这个示例中,我们使用了 re.search() 函数来搜索整个字符串,尝试找到子串 “world”。以下是每个部分的详细解释:
-
r'world':这是一个简单的正则表达式模式,它表示要匹配的字符串是 “world”。 -
"hello world":这是我们要进行搜索的字符串。 -
re.search(pattern, text):使用 re.search() 函数在整个字符串中搜索指定的模式。 -
search_obj:re.search() 函数返回一个 Match 对象,如果找到了匹配的子串,Match 对象就会包含匹配的结果,否则为 None。 -
search_obj.group():如果找到了匹配的子串,可以通过调用 match_obj.group() 方法来获取匹配的内容。
在这个示例中,由于字符串 “world” 存在于 “hello world” 中,因此 re.search() 函数找到了匹配,输出 “找到匹配: world”。
re.search() 是一个非常有用的函数,可以帮助您在字符串中查找特定的模式。希望这个示例能够帮助您理解 re.search() 函数的使用方法。
re.match 与 re.search的区别
re.match() 和 re.search() 是 Python 中 re 模块中用于正则表达式匹配的两个函数,它们之间有以下区别:
-
re.match():
- re.match() 函数尝试从字符串的开头开始匹配模式。
- 如果字符串开头不符合模式,则匹配失败,返回 None。
- 如果字符串开始部分与模式匹配,返回一个 Match 对象,可以通过 group() 方法获取匹配的内容。
-
re.search():
- re.search() 函数在整个字符串中搜索并找到第一个符合模式的子串。
- 不要求字符串从开头开始匹配,只要找到一个符合模式的子串就返回。
- 返回第一个匹配到的结果,也是一个 Match 对象,可以通过 group() 方法获取匹配的内容。
举例来说,假设有字符串 “hello world”,并使用以下两个正则表达式模式进行匹配:
-
模式为
r'world':- re.match() 将会匹配失败,因为 “hello” 不符合该模式,返回 None。
- re.search() 将会匹配成功,在 “world” 中找到了符合的子串,返回 “world”。
-
模式为
r'hello':- re.match() 将会匹配成功,因为 “hello” 符合该模式,返回 “hello”。
- re.search() 将会匹配成功,在 “hello world” 中找到了符合的子串,返回 “hello”。
re.match() 适用于需要从字符串开头处进行匹配的场景,而 re.search() 则适用于需要在整个字符串中查找符合模式的子串的场景。根据具体的需求选择使用不同的函数能够更有效地实现匹配目的。
检索和替换
在Python中,您可以使用re模块来进行文本的检索和替换。下面是一个简单的例子来说明如何使用re模块进行检索和替换:
import re# 要操作的字符串
text = "The cat and the hat sat on the mat."# 定义要搜索的模式
pattern = r'cat'# 使用re.sub()进行替换
new_text = re.sub(pattern, 'dog', text)print(new_text)
在上面的示例中,我们使用了re.sub()函数来将文本中所有匹配模式r’cat’的部分替换为’dog’。执行上述代码后,输出结果为:“The dog and the hat sat on the mat.”。
另外,如果想要查找所有匹配的子串,并对其进行特定处理,也可以使用re.findall()和re.finditer()函数来实现。这两个函数可以用于找到所有匹配的子串,并返回它们的位置或者进行进一步的处理。
repl 参数是一个函数
是的,re 模块中的 re.sub() 函数允许使用一个函数作为 repl 参数,以便对每个匹配的子串进行更复杂的替换操作。下面是一个示例,演示了如何使用函数作为 repl 参数:
import re# 要操作的字符串
text = "The cat and the hat sat on the mat."# 定义替换函数
def repl_function(match_obj):word = match_obj.group()if word == 'cat':return 'dog'elif word == 'hat':return 'rug'else:return '***'# 使用re.sub()并将函数作为repl参数
new_text = re.sub(r'\b(cat|hat)\b', repl_function, text)print(new_text)
在这个示例中,我们定义了一个名为 repl_function 的函数,该函数接收一个 Match 对象作为输入,并根据匹配到的子串来决定如何进行替换。然后,我们使用 re.sub() 函数,将这个函数作为 repl 参数传递给它。执行上述代码后,输出结果为:“The dog and the rug sat on the mat.”。
函数作为 repl 参数的用法,可以让你对每个匹配到的子串进行更加灵活和复杂的处理,从而进行更加精细的替换操作。
compile 函数
在 Python 中,re 模块提供了 compile() 函数,用于将正则表达式编译为一个对象,以便在之后的匹配中复用。这种预编译的方式可以提高匹配效率,特别是在需要多次使用同一模式进行匹配时。下面是一个简单的示例来说明 compile() 函数的使用:
import re# 将正则表达式编译为对象
pattern = re.compile(r'hello')# 要匹配的字符串
text = "hello world"# 使用编译后的对象进行匹配
match_obj = pattern.search(text)if match_obj:print("找到匹配:", match_obj.group())
else:print("未找到匹配")
在上述示例中,我们首先使用 re.compile() 函数将正则表达式模式 r’hello’ 编译为一个模式对象 pattern,然后在之后的代码中可以重复使用这个 pattern 对象进行匹配操作。
使用 compile() 函数的优点包括提高匹配效率和可以提前检查正则表达式的有效性(如果有语法错误,会在编译阶段就抛出异常)。
re.compile() 函数允许您事先编译好正则表达式模式,并得到一个可重复使用的模式对象,为之后的匹配操作提供了便利和性能上的提升。
findall
在 Python 的 re 模块中,re.findall() 函数用于在给定的字符串中查找所有匹配指定模式的子串,并以列表的形式返回这些子串。下面是一个简单的示例来说明 re.findall() 函数的使用:
import re# 要匹配的字符串
text = "The cat and the hat sat on the mat."# 使用 re.findall() 查找所有匹配的子串
matches = re.findall(r'\b\w{3}\b', text)print(matches)
使用了 re.findall() 函数来搜索字符串中所有匹配特定模式的子串。具体来说,我们使用的模式是 \b\w{3}\b,表示匹配长度为 3 的单词。
执行这段代码后,将输出结果作为一个列表:['The', 'cat', 'the', 'hat', 'sat', 'the', 'mat'],其中包含所有匹配到的长度为3的单词。
re.findall() 函数非常适合在不需要对每个匹配结果做更复杂处理的情况下,快速地获取所有匹配到的子串。当需要获取文本中所有符合特定模式的部分时,这个函数非常实用。
re.finditer
re.finditer() 函数与 re.findall() 类似,但它返回一个迭代器(iterator),该迭代器生成匹配的模式在字符串中的每一次出现。下面是一个简单的示例来说明 re.finditer() 函数的使用:
import re# 要匹配的字符串
text = "The cat and the hat sat on the mat."# 使用 re.finditer() 查找所有匹配的子串
matches = re.finditer(r'\b\w{3}\b', text)for match in matches:print(match.group(), match.start(), match.end())
在这个示例中,我们使用了 re.finditer() 函数来搜索字符串中所有匹配特定模式的子串。具体来说,我们使用的模式是 \b\w{3}\b,表示匹配长度为 3 的单词。
使用 re.finditer() 返回的迭代器,我们可以迭代处理每次匹配到的结果,从中获取匹配子串的内容以及其在原始文本中的起始和结束位置。执行上述代码后, 将输出每个匹配子串的内容以及起始和结束索引位置。
因此,re.finditer() 是一个非常有用的函数,特别适用于需要对每个匹配结果做更复杂处理的情况,或者在需要获取匹配子串的位置信息时。
re.split
re.split() 函数用于根据指定的模式对字符串进行分割,并返回分割后的子串组成的列表。下面是一个简单的示例来说明 re.split() 函数的使用方式:
import re# 要分割的字符串
text = "apple, banana, cherry, date"# 使用 re.split() 进行分割
result = re.split(r',\s*', text)print(result)
在这个示例中,我们使用了 re.split() 函数来根据逗号加空格的模式 ,\\s* 对字符串进行分割,其含义是以逗号加零或多个空格为分隔符。执行上述代码后,将输出结果作为一个列表:['apple', 'banana', 'cherry', 'date'],即根据指定的模式成功地将原始字符串分割成了多个子串。
re.split() 是在字符串操作中非常有用的函数,特别适用于需要根据复杂的模式对字符串进行分割的情况,如按照标点符号、空格或其他自定义的分割符号进行分割。
正则表达式对象
正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。
re.MatchObject
group() 返回被 RE 匹配的字符串。
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
在 Python 的 re 模块中,使用re.compile()函数可以将正则表达式模式编译为一个正则表达式对象。正则表达式对象具有与模式相关联的各种方法,可用于在文本中进行搜索、匹配和替换操作。以下是一些常用的正则表达式对象的方法:
search(string[, pos[, endpos]]): 在字符串中搜索模式的第一个匹配项,返回一个匹配对象。match(string[, pos[, endpos]]): 在字符串开头匹配模式,如果匹配成功则返回一个匹配对象。findall(string[, pos[, endpos]]): 找到所有与模式匹配的子串,并以列表的形式返回这些子串。finditer(string[, pos[, endpos]]): 返回一个迭代器,用于生成字符串中与模式匹配的每一个匹配对象。split(string[, maxsplit]): 根据模式对字符串进行分割,返回分割后的子串组成的列表。sub(repl, string, count=0): 使用指定的替换字符串替换匹配到的模式,返回替换后的字符串。
正则表达式对象的创建通过re.compile()函数,其基本语法如下:
import re
pattern = re.compile(r'正则表达式模式')
接下来,您可以使用pattern对象调用上述列出的方法来进行搜索、匹配或替换操作。例如:
# 使用 compile() 函数将正则表达式模式编译为对象
pattern = re.compile(r'\b\w{4}\b')# 使用 findall() 方法找到所有匹配的子串
matches = pattern.findall("The cat and the hat sat on the mat.")
print(matches)
这将会输出:['cat', 'hat', 'sat'],即从字符串中找到了所有长度为 4 的单词。
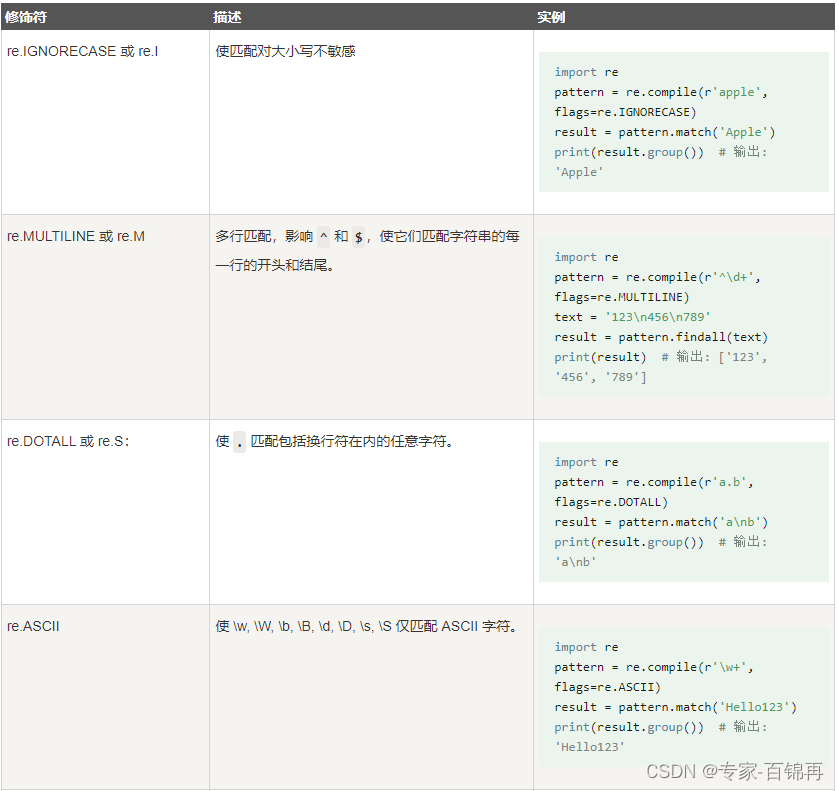
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。
以下标志可以单独使用,也可以通过按位或(|)组合使用。例如,re.IGNORECASE | re.MULTILINE 表示同时启用忽略大小写和多行模式。

正则表达式模式
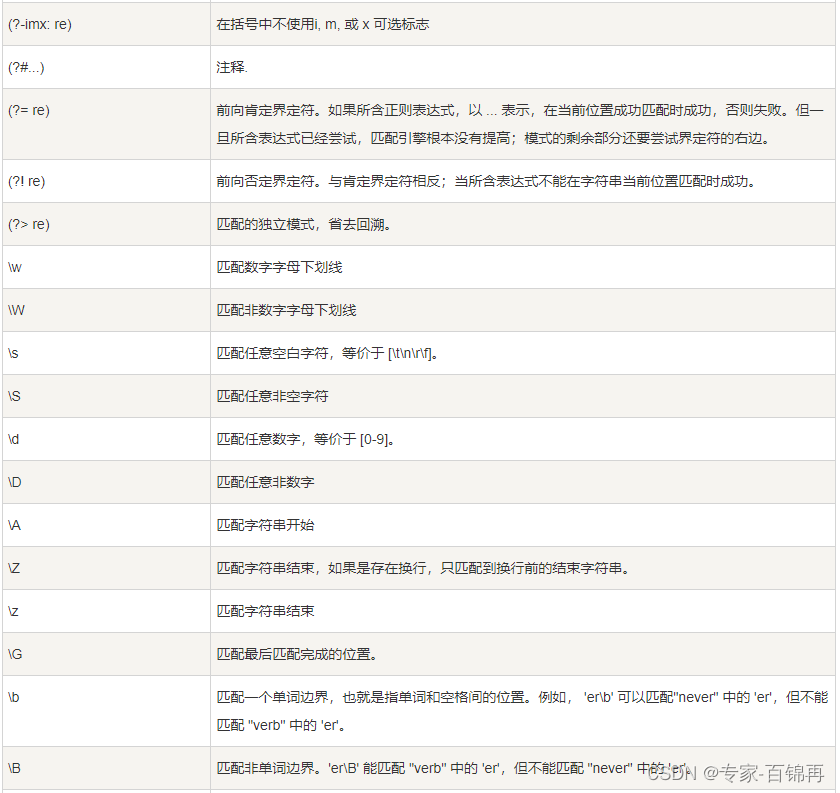
正则表达式模式是由普通字符(例如字符 a 到 z)和特殊字符(称为元字符)组合而成的字符串,用于描述在文本中搜索、匹配或替换特定模式的规则。下面列举了一些常用的正则表达式元字符及其含义:
.:匹配任意单个字符,除了换行符。^:匹配字符串的开头。$:匹配字符串的结尾。*:匹配前面的元素零次或多次。+:匹配前面的元素一次或多次。?:匹配前面的元素零次或一次。\d:匹配任意数字,相当于 [0-9]。\w:匹配字母、数字、下划线,相当于 [a-zA-Z0-9_]。[...]:匹配方括号中的任意一个字符。(x|y):匹配 x 或 y。\s:匹配任意空白字符,包括空格、制表符、换行符等。
除了上述元字符外,正则表达式还支持通过括号来表示分组,使用 {} 来指定重复次数,使用 \ 来转义特殊字符等。
例如,正则表达式模式 \b\w{3}\b 可以用于匹配长度为 3 的单词,其中:
\b表示单词的边界。\w匹配任意字母、数字或下划线。{3}表示重复前面的元素三次。- 因此,整个模式就是匹配长度为 3 的单词。
正则表达式模式在对文本进行搜索、匹配或替换时非常强大,可以满足各种复杂的匹配需求。


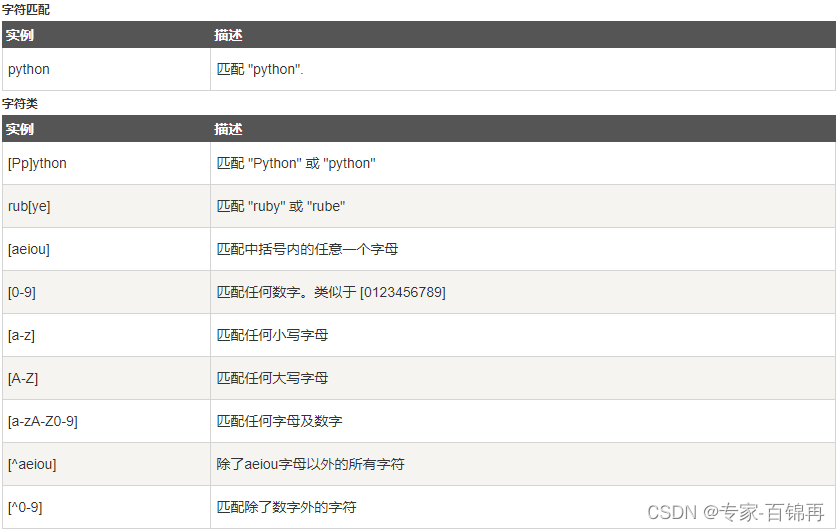
正则表达式实例

关注我,不迷路,共学习,同进步
关注我,不迷路,共学习,同进步

相关文章:
01 Python进阶:正则表达式
re.match函数 使用 Python 中的 re 模块时,可以通过 re.match() 函数来尝试从字符串的开头匹配一个模式。以下是一个简单的详解和举例: import re# 定义一个正则表达式模式 pattern r^[a-z] # 匹配开头的小写字母序列# 要匹配的字符串 text "h…...

pdf图片识别分类
文章目录 解析pdf数据ocr识别分类方法正则匹配词频统计分类模型 分类完提示 解析pdf数据 试了几种方法 fitz-get_image后面方法不适用,用pixmap分辨率低 用pypdf2版本低方法用不了 用pdf2image还要下依赖工具 用spire.pdf的SaveAsImage分辨率低,Extract…...
)
24双非考研哈尔滨工程大学计算机(@程程笔记)
前言 个人情况,本科双非考研软件工程。24考研成绩总分369(政治75,英语58,数学102,专业课134),整体各科成绩比较均衡,没有太突出和瘸腿的,初始排名5/19,复试后排名5/13。 政治 政治…...
IO流(2.其他流)
能够高效读写的缓冲流,能够转换编码的转换流,能够持久化存储对象的序列化流 一、缓冲流 缓冲流,也叫高效流,是对4个基本的FileXxx 流的增强,所以也是4个流,按照数据类型分类: 字节缓冲流:Buffe…...

PyTorch之计算模型推理时间
一、参考资料 如何测试模型的推理速度 Pytorch 测试模型的推理速度 二、计算PyTorch模型推理时间 1. 计算CPU推理时间 import torch import torchvision import time import tqdm from torchsummary import summarydef calcCPUTime():model torchvision.models.resnet18()…...
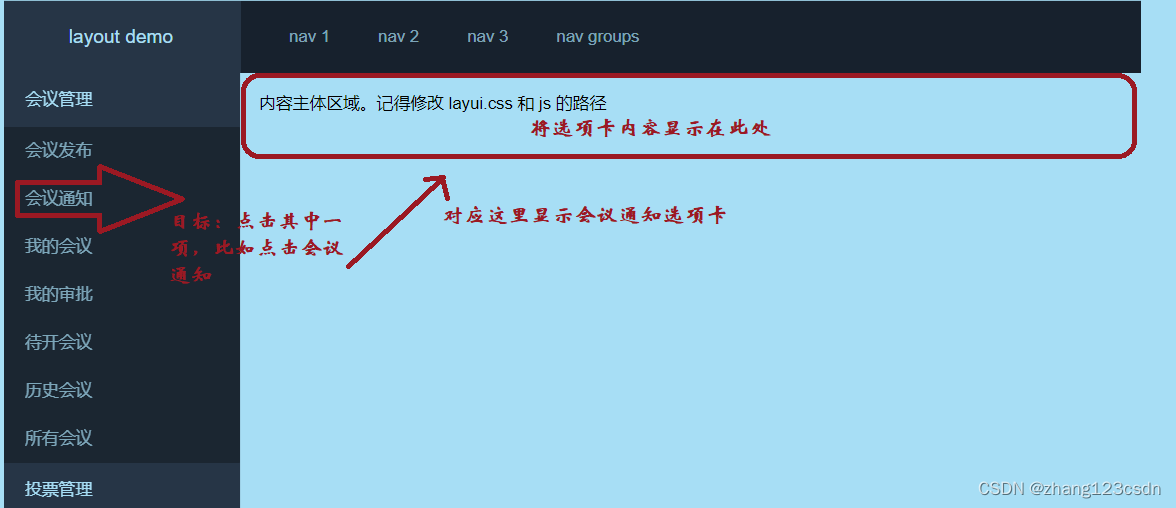
layui后台框架,将左侧功能栏目 集中到一个页面,通过上面的tab切换 在iframe加载对应页面
实现上面的 功能效果。 1 html代码 <form class"layui-form layui-form-pane" action""><div class"layui-tab" lay-filter"demo"><ul class"layui-tab-title"><li id"a0" class"lay…...
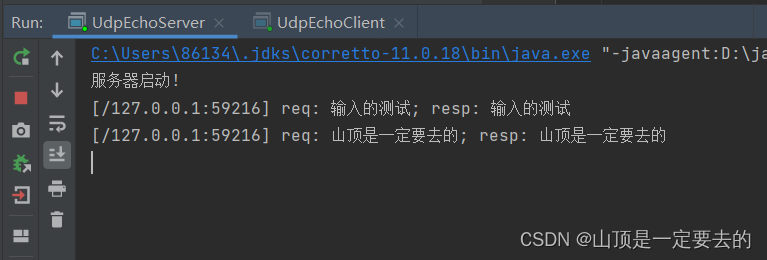
【网络原理】使用Java基于TCP搭建简单客户端与服务器通信
目录 🎄API介绍🌸ServerSocket API🌸Socket API 🍀TCP中的长短连接🌳建立TCP回显客户端与服务器🌸TCP搭建服务器🌸TCP搭建客户端 ⭕总结 TCP服务器与客户端的搭建需要借助以下API 🎄…...

Hadoop生态系统主要是什么?
Hadoop生态系统主要由以下几部分组成: Hadoop HDFS:这是Hadoop的核心组件之一,是一个用于存储大数据的分布式文件系统。它可以在廉价的硬件上提供高度的容错性,通过数据复制和故障切换实现数据的高可用性。 MapReduce:…...

GlusterFS分布式文件系统
前言 存储可分为文件存储和对象存储,常见的文件存储相关技术有:nfs、lvm、raid;常见的对象存储相关技术有:gfs、ceph、fdfs、nas、oss、s3、switch。GlusterFS 归类为文件存储系统,它提供了一种强大的方式来管理和存储…...

spark本地模拟多个task时如何启动多个Excutor
1、首先在9090端口下启动Excutor,作为第一个Excutor 2、然后修改9090端口为:9091,如下图点击Edit Configration 3、然后按下图操作 , 4、修改一下名字 5、点击apply,🆗 6、检查下面圈1是否是刚刚我们新建的MyExcutor(2…...
SpringBoot整合RocketMQ广播消费消息)
RocketMQ笔记(八)SpringBoot整合RocketMQ广播消费消息
目录 一、简介1.1、消费模式 二、消费者2.1、maven依赖2.2、application配置2.3、消费监听 三、生产者3.1、发送消息3.2、运行结果 四、其他 一、简介 在之前的文章中,我们讲过了,同步发送单条消息,异步发送单条消息,发送单向消息…...
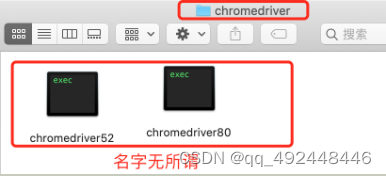
Appium如何自动判断浏览器驱动
问题:有的测试机chrome是这个版本,有的是另一个版本,怎么能让自动判断去跑呢?? 解决办法:使用appium的chromedriverExecutableDir和chromedriverChromeMappingFile 切忌使用chromedriverExecutableDir和c…...

MVCC-多版本并发控制
MVCC(多版本并发控制)简介 在数据库系统中,并发控制是一个非常重要的话题。为了提高系统的并发性能和吞吐量,现代数据库系统通常使用多种技术来实现对数据的安全访问,其中一种重要的技术就是多版本并发控制࿰…...

c++找最高成绩
根据给定的程序,写成相关的成员函数,完成指定功能。 函数接口定义: 定义max函数,实现输出最高成绩对应的学号以及最高成绩值。 裁判测试程序样例: #include <iostream> using namespace std; class Student{…...

前端saas化部署
在项目中难免会遇到一些特殊的需求,例如同一套代码需要同时部署上两个不同的域名A和B。A和B的不同之处仅在于,例如一些背景图片,logo,展示模块的不同,其他业务逻辑是和展示模块是完全一样的。此时我们当然可以考虑单独…...
[Java基础揉碎]Math类
目录 基本介绍 方法一览(均为静态方法) 1) abs 绝对值 2) pow 求幂 3) ceil 向上取整 4) floor 向下取整 5) round 四舍五入 6) sqrt 求开方 7) random求随机数 8) max 求两个数的最大值 9) min 求两个数的最小值 基本介绍 Math类包含用于执行基本数学运算的方法&…...
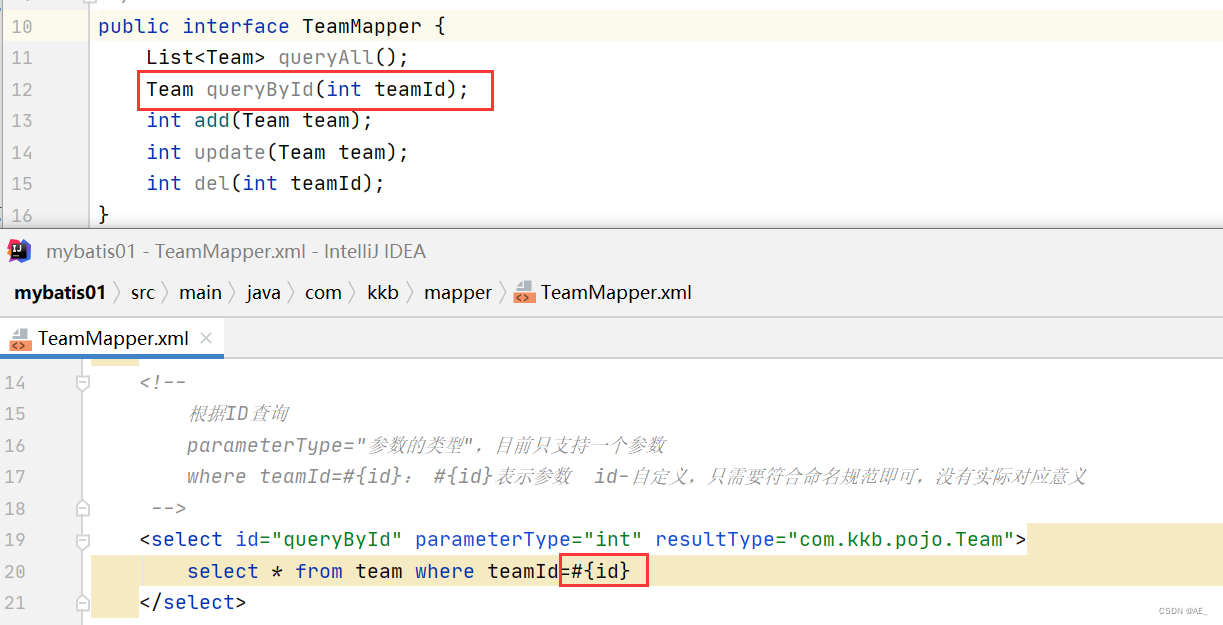
MyBatis输入映射
1 parameterType parameterType:接口中方法参数的类型,类型必须是完全限定名或别名(稍后讲别名)。该属性非必须,因为Mybatis框架能自行判断具体传入语句的参数,默认值为未设置(unset)。<sel…...

金三银四,程序员求职季
随着春天的脚步渐近,对于许多程序员来说,一年中最繁忙、最重要的面试季节也随之而来。金三银四,即三月和四月,被广大程序员视为求职的黄金时期。在这两个月里,各大公司纷纷开放招聘,求职者们则通过一轮又一…...
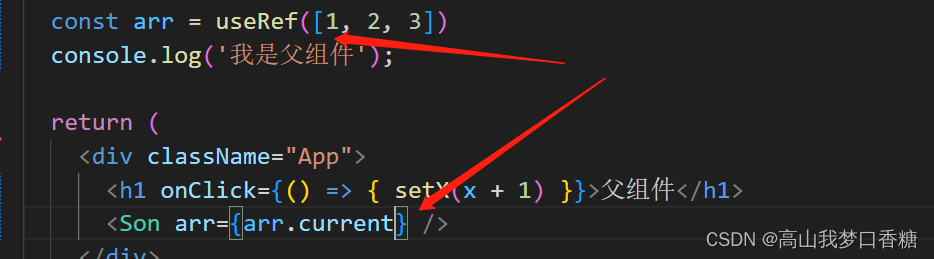
[react优化] 避免组件或数据多次渲染/计算
代码如下 点击视图x➕1,导致视图更新, 视图更细导致a也重新大量计算!!这很浪费时间 function App() {const [x, setX] useState(3)const y x 2console.log(重新渲染, x, y);console.time(timer)let a 0for (let index 0; index < 1000000000; index) {a}console.timeE…...

「意」起出发 丨意大利OXO城市展厅盛大启幕,成都设计圈共襄盛举
4月8日,主题为“「意」起出发「智」见OXO”的意大利OXO城市展厅发布会在成都大悦城OXO成都城市展厅隆重举办。 大会现场,成都装饰协会领导,喜尔康董事长吴锡山,天合智能副董事长罗洁,意大利OXO卫浴市场部总监兰彬&…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

用PyTorch和ECANet18搞定RAF-DB表情分类:从数据集下载到模型部署的保姆级教程
基于ECANet18的RAF-DB表情识别实战:从零构建高精度分类模型 人脸表情识别(FER)作为计算机视觉领域的重要分支,在情感计算、智能交互等领域展现出巨大潜力。本文将带您完整实现一个基于PyTorch和ECANet18的端到端表情识别系统&…...

【CH32V307实战】4P OLED屏I2C驱动移植与快速显示指南
1. CH32V307与4P OLED屏的硬件连接指南 第一次拿到CH32V307开发板和4P OLED屏时,最让我头疼的就是接线问题。这种4线制OLED(通常标注为4P或4PIN)相比传统的7线制简化了不少,但引脚定义各家厂商可能略有差异。经过多次实测…...

终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼
终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中疯狂上跳的枪口而…...

开源机械爪OpenClaw:从设计到力控抓取的完整实现指南
1. 项目概述:从“OpenClaw”看开源机械爪的无限可能最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“MeyerZhou/openclaw”。光看名字,你大概能猜到这是个关于机械爪的开源项目。没错,这是一个旨在提供低成本、模块…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

基于RAG的智能知识库问答系统:从原理到部署实战
1. 项目概述:当AI大模型遇见知识库,一个开源的智能问答解决方案 最近在折腾一个很有意思的开源项目,叫 zhimaAi/chatwiki 。光看名字,你大概能猜到它的核心: chat 代表对话, wiki 代表知识库。没错&a…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...