更高效、更简洁的 SQL 语句编写丨DolphinDB 基于宏变量的元编程模式详解
元编程(Metaprogramming)指在程序运行时操作或者创建程序的一种编程技术,简而言之就是使用代码编写代码。通过元编程将原本静态的代码通过动态的脚本生成,使程序员可以创建更加灵活的代码以提升编程效率。
在 DolphinDB 中,元编程常用于 SQL 语句的编写。通过 SQL 元编程,可以解决下述2个场景的问题:
- 场景一:SQL 的字段名或过滤条件等是动态的,需要通过函数参数或变量进行传递。例如,用户报表系统,由前端用户选择查询字段,后端生成 SQL 查出数据。
- 场景二:查询列数非常多的宽表中的多个字段列,或者对普通表中多个字段执行相似的操作(例如同时对多个字段求和),如果完全通过脚本书写 SQL 语句,脚本冗长且耗时。
本教程将围绕 SQL 元编程展开,通过与传统的函数式元编程对比,介绍 DolphinDB V3.00.0 / 2.00.12 版本支持的更高效简洁的元编程方法——基于宏变量的元编程。
1. 基于函数的元编程
基于函数的元编程实现,是指通过内置元编程函数的组合调用生成元代码。以 select 查询语句为例,一个 select 语句通常可以拆分为以下几个部分:select 查询主体,表对象,分组字段,排序字段,过滤条件,返回记录数约束等(参考下图标红部分)。

为了适用于各种 SQL 语句的生成,DolphinDB 设计了用于 SQL 语句的组装的函数 sql(select 语句), sqlUpdate(update 语句), sqlDelete(delete 语句),或者也可以通过 parseExpr + SQL 字符串生成 SQL 元代码。
以 sql 函数为例,其语法为:
sql(select, from, [where], [groupBy], [groupFlag], [csort], [ascSort], [having], [orderBy], [ascOrder], [limit], [hint], [exec=false])sql 函数的每个参数都对应 SQL 的一个子句,通过变量传入即可动态生成对应的 SQL 元代码。

sql 函数各参数对应的 SQL 子句
例如,上图的语句可以通过下述元编程脚本生成:
sel=sqlColAlias(makeUnifiedCall(cumsum, sqlCol("price")), "cum_price")
fm="t"
wre=parseExpr("time between 09:00:00 and 15:00:00")
ctxBy=sqlCol("securityID")
cs=sqlCol("time")
lim=-1sql(select=sel, from=fm, where=wre, groupby=ctxBy, groupFlag=0, csort=cs, limit=lim)
// output:
< select cumsum(price) as cum_price from objByName("t") where time between pair(09:00:00, 15:00:00) context by securityID csort time asc limit -1 >参考以上例子,可以总结出 sql 函数生成元代码的规则:
- 查询字段须以 sqlCol 或者 sqlColAlias 声明。
- 对表字段计算的元代码:
- 单字段参与计算:sqlCol 函数指定 func 参数。
- 多字段参与计算:sqlColAlias 函数 搭配 makeCall 或者 makeUnifiedCall 函数。
- 表对象可以是一个表变量名字符串、表变量如 t 或 loadTable 返回的句柄。
具体的参数说明请参考:sql
sql 函数生成的元代码是基于一些小的元代码片段组装的,为了进一步理解这个规则,下面介绍一下组装涉及到的相关函数及其作用:
- sqlCol:支持生成单字段或多字段应用同一函数的表达式,支持指定别名;生成的表达式形如:
(1) sqlCol("col") --> <col>(2) sqlCol(["col0","col1","col2"]) --> [<col0>, <col1>, …, <colN>](3) sqlCol("col", func=sum, alias="newCol") --> <sum(col) as newCol>(4) sqlCol(["col0","col1","col2"], func=sum, alias=["newCol0","newCol1","newCol2"])
--> [<sum(col0) as newCol0>, <sum(col1) as newCol1>, <sum(col2) as newCol2>]- sqlColAlias:为复杂的列字段计算元代码指定别名;生成的表达式形如:
(1) sqlColAlias(sqlCol("col"), "newCol") --> <col as newCol>(2) sqlColAlias(makeCall(sum, sqlCol("col")), "newCol")
--> <func(col) as newCol>(3) sqlColAlias(makeCall(corr, sqlCol("col0"), sqlCol("col1")), "newCol")
--> <func(col1, col2, …, colN) as newCol>通常搭配下述函数使用:
- makeCall, makeUnifiedCall: 用于生成 <func(cols.., args…)> 的元代码表达式。
- expr, unifiedExpr, binaryExpr:生成多元算术表达式,例如 <a+b+c>, <a1*b1+a2*b2+… +an*bn>
- parseExpr:从字符串生成元代码,将拼接、 API 上传或脚本读取的字符串,生成可执行的脚本。例如 parseExpr(“select * from t”) 即可生成 <select * from t> 的元代码;parseExpr(“where vol>1000“) 生成 sql 函数
where参数部分的元代码等。
以一个更复杂的场景为例:基于函数生成 select 部分的元代码 < nullFill(price, quantile(price, 0.5)) as price >,其中 price 是动态传入的一个字段名:
colName=`price
sqlColAlias(makeCall(nullFill, sqlCol(colName), makeUnifiedCall(quantile, (sqlCol(colName), 0.5))), colName)可以发现,这种基于函数的写法,需要嵌套多层函数才能实现,既复杂又不直观,对于初学者而言学习成本较高。为此, DolphinDB 于 2.00.12/3.00.0 版本推出了基于宏变量实现方法,以更直观的形式编写元代码。
2. 基于宏变量(Macro Variables)的元编程
与函数需要组装嵌套各个部分的元代码不同,基于宏变量的实现,以一种更直观的 <select statement> 方式生成元代码,其中 select statement 就是符合用户书写习惯的 select 语句,用户以宏变量的形式声明其中需要动态传入的字段。但需要明确的时,宏变量的内部实现也是基于函数的元编程方法。
注意:
1. 目前仅支持生成 SQL 查询语句,暂不支持 update 和 delete 语句。
2. 只能应用于列字段、字段别名、函数参数、表达式等,不能搭配 case when 子句、over 子句、from 嵌套查询等使用,例如 <select sum(_$$names2) from select _$$names1 from t>。
3. 搭配 csort 和 order by 子句时,只能使用单列宏变量,不能使用多列宏变量。
例如第一节介绍的 SQL 语句,可以通过宏变量的方式书写为:
col = "price"
cxtByCol = "SecurityID"
csCol = "time"
a = 09:00:00
b = 15:00:00
<select cumsum(_$col) from t where _$csCol between a and b context by _$cxtByCol csort _$csCol limit -1>根据传入的动态字段是标量还是向量,字段的宏变量可以分为单列宏变量(single-column macro variable)和多列宏变量(multi-column macro variable)。
单列宏变量通过 “_$” 声明,例如 ”_$name”;多列宏变量通过 ”_$$“ 声明,例如 ”_$$names“。其中 name(标量) 和 names(向量) 是一个外部定义的存储列名的变量名,必须是 STRING 类型,其指定的列名需要符合命名规范,即不能以数字或符号开头。
注意:为了能够在解析时与 cast 函数的符号 $ 进行区分,设计时特意在声明符中加入了特殊字符下划线。这和读取特殊列名时使用 _”colName” 的用法相似。
单列宏变量在查询语句中只能作为单字段或者一元函数的参数,例如:
t = table(`a`a`b as sym, 1 2 3 as val)
name="sym"
<select _$name from t>.eval()name="val"
grp="sym"
alias="sum_val"
<select sum(_$name) as _$alias from t group by _$grp>.eval()多列宏变量在查询语句中有以下几个使用场景:
- 作为多个查询字段。此场景下,直接输出多个列。
t = table(`a`a`b as sym, 1 2 3 as val1, 2 3 4 as val2)
names=["val1", "val2"]
<select _$$names from t>.eval()- 多字段参与计算,即作为多元函数的参数。此场景下,多列宏变量相当于一个元组,元组的每个元素相当于一列。
alias = "rs_val"
<select rowSum(_$$names) as _$alias from t>.eval()- 多字段一起调用同一个函数分别计算。此场景下,宏变量分别用于函数参数和多列输出的别名。作为函数参数时,多列宏变量相当于一个元组。作为别名时,宏变量指向的列名作为别名。
alias=["v1", "v2"]
<select sum:V(_$$names) as _$$alias from t>.eval()
<select cumsum(_$$names) as _$$alias from t>.eval()注意:
1. 聚合函数 sum 后面用函数模式 byColumn 修饰,是因为希望对元组的每一个元素分别做聚合计算。
2. 向量函数 cumsum 后面没有使用函数模式 byColumn 修饰,是因为内置的向量化函数,应用于一个等长的 Vector 组成的元组时,自动会将向量化应用于元组的每一个元素,并返回一个元组。
3. 字段序列(Column Series)在元编程中的应用
先来设想一个场景,假设有一个 1002 列的宽表,列字段为 sym, date, col000~col999。如果直接写 SQL 脚本取出 col000~col999 列,听起来是一个非常冗长的脚本,这种场景就非常适合用元编程去实现:
cols="col" + lpad(string(0..999), 3, "0")
<select _$$cols from t>为了进一步简化这个场景,DolphinDB 支持了字段序列(Column Series)的功能,符号为(…),上述脚本可以改写为:
<select col000...col999 from t>字段序列可以用于表示查询字段或者别名,使用时需要满足:字段名必须是”前缀+数字“的组合,语法为 colJ…colK。
其中:
1. col 是列名前缀示意,列名需满足 [a-zA-Z\_]{1,}[0-9]+。
2. 数字 J~K 必须是连续的整数序列,abs(J-K) <= 32768。例如字段为 col1, col2, col3, col5,写为 col1…col5 就不符合要求。数字 J~K 可以是连续的整数,如 1,2,..,10,11,…,100,101,…;也可以是格式化后固定位数的整数,如 0001,0002,…,0010,0011,…,0100,0101,…。
字段序列支持直接用在 SQL 语句中作为查询的字段或者别名:
select col1 ... coln from t
select col1...col3 as nm1 ... nm3 from t在元编程中使用时,若列名满足条件,可以替代 “_$$names” 的写法:
names = [col1, col2, ..., coln]
<select _$$names from t>
<select col1 ... coln from t> 字段序列非常适合应用在多个相似列计算的场景,例如:通过 fixedLengthArrayVector 函数多列字段组合成数组向量:
select fixedLengthArrayVector(ask1...ask10) as askArray from t4. 场景案例
本节将结合具体的元编程场景案例,对比基于函数和基于宏变量的元编程编程实现,带大家深入了解元编程的编程思路。
4.1 计算最小二乘回归的残差,列字段动态传入。
以一个自定义的简单的表,先写出该逻辑的 SQL 实现,假设 y, x1, x2, x3 都是动态传入的字段:
// 模拟数据脚本
x1=1 3 5 7 11 16 23
x2=2 8 11 34 56 54 100
x3=8 12 81 223 501 699 521
y=0.1 4.2 5.6 8.8 22.1 35.6 77.2;
t = table(y, x1, x2, x3)// 批计算 SQL 脚本示意
select ols(y, (x1, x2, x3), 1, 2).Residual as residual from t基于函数的元编程
基于函数方法的思路是先把嵌套函数做一个转换和拆分:
ols(y, (x1, x2, x3), 1, 2).Residual
-> 转换
at(ols(y, (x1, x2, x3), 1, 2), "Residual")
-> 拆分
(1) re = makeUnfiedCall(at, obj0)
(2) obj0 = (obj1, "Residual")
(3) obj1 = makeUnfiedCall(ols, obj2)
(4) obj2 = (y, (x1,x2,x3), 1, 2)
需要注意,(x1, x2, x3) 在批处理中可以作为字段元组参与计算,但是在元编程中如果用元组封装字段元代码,会变成 (<x1>, <x2>, <x3>),这会导致元代码无法解析。需要将 (x1, x2, x3) 改写为可以替代的矩阵的形式 matrix(x1, x2, x3),因此上述对象可以进一步拆解:
(4) obj2 = (y, obj3, 1, 2)
(5) obj3 = makeUnifiedCall(matrix, [x1,x2,x3])
将上述所有的表字段使用 sqlCol 嵌套,可以得到下述 select 片段的元代码:
y = "y"
x = `x1`x2`x3
residual = makeCall(member, makeCall(ols, sqlCol(y), makeUnifiedCall(matrix, sqlCol(x)), 1, 2), "Residual")
// output:< member(ols(y, matrix(x1, x2, x3), 1, 2), "Residual") >代入 sql 函数可以得到:
sql(select=sqlColAlias(residual, "residual"), from=t).eval()基于宏变量的元编程
基于宏变量的实现只需要改写批处理的 SQL 语句即可,即把所有表字段都用宏变量替代:
colName = "y"
x = `x1`x2`x3
<select ols(_$colName, _$$x, 1, 2).Residual as residual from t>.eval()
// 或者
<select ols(_$colName, x1...x3, 1, 2).Residual as residual from t>.eval()4.2 多个结构相同的列计算
假设有一个 102 列的表,字段为 sym, date, price1..price50, qty1..qty50, 假设 amount=qty*price,现需要分别计算出这 50 个 price 和 qty 列对应的 amount 字段。
// 模拟数据脚本
sym = ["a" + string(1..10)]
date = [take(2022.01.02, 10)]
price = table(rand(10.0, 500) $ 10:50).values()
qty = table(rand(1000, 500) $ 10:50).values()
data = (sym).appendTuple!(date).appendTuple!(price).appendTuple!(qty)
t=table(1:0, [`sym, `date] join priceCols join amountCols, [SYMBOL, DATE] join take(DOUBLE, 50) join take(INT, 50))
t.tableInsert(data)// 批计算 SQL 脚本示意(中间省略部分)
select price1*qty1 as amount1, price2*qty2 as amount2 ... , price50*qty50 as amount50 from t基于函数的元编程
50 个列字段的形式都是 priceK * qtyK as amountK,此类二元计算很容易想到使用 expr 类的函数实现,其中二元表达式可以借助 binaryExpr 生成,而 as 别名部分则借助 sqlColias 生成,得到的 select 片段的脚本如下:
priceCols = "price" + string(1..50)
qtyCols = "qty" + string(1..50)
amountCols="amount"+string(1..50)
slt=sqlColAlias(binaryExpr(sqlCol(priceCols), sqlCol(qtyCols), *), amountCols)最终生成 SQL 脚本的代码如下:
sql(select=slt, from=t).eval()基于宏变量的元编程
同样基于宏变量的实现只需要改写批处理的 SQL 语句即可:
priceCols = "price" + string(1..50)
qtyCols = "qty" + string(1..50)
amountCols="amount"+string(1..50)
<select _$$priceCols * _$$qtyCols as _$$amountCols from t>.eval()也可以用字段序列声明别名:
<select _$$priceCols * _$$qtyCols as askAmount1...askAmount50 from t>.eval()如果字段是固定不变的,利用向量乘法是两两相乘的规律,也可以通过字段序列直接编写 SQL 脚本:
select (price1...price50) * (qty1...qty50) as amount1...amount50 from t4.3 多列计算返回一个结果列
假设有一个 10 列的表,要计算所有列的加权平均和,如果用批计算的 SQL,脚本如下所示:
// 模拟数据脚本
t = table(rand(10.0, 100) $ 10:10).rename!("val" + string(1..10))// 批计算 SQL 脚本示意(中间省略部分)
select *, val1*0.1 + val2*0.2 + val3*0.3 +...+val10*1.0 from t基于函数的元编程
第一步还是先基于批计算的表达式进行拆解:
val1*0.1 + val2*0.2 + val3*0.3 +...+val10*1.0
→ 拆分为两部分
objk = valk * Wk
re=obj1 + obj2 + … +obj10
参照例 2,其中 objk 是二元表达式,可以使用 binaryExpr 生成,re 相加部分则可以借助函数 unifiedExpr 实现。同样,元代码中列字段用 sqlCol 声明,则最后编写的脚本如下:
t = table(rand(10.0, 100) $ 10:10).rename!("val" + string(1..10))
cols = "val"+string(1..10)
w = (1..10) \ 10 $ ANYslt = sqlColAlias(unifiedExpr(binaryExpr(sqlCol(cols), w, *), take(+,cols.size()-1)),"weightedVal")
sql(select=[sqlCol("*"), slt], from=t).eval()需要注意,此处的权重 w 需声明为元组,否则会作为向量和每一列相乘。
基于宏变量的元编程
该场景下直接通过改写 SQL 脚本并不能降低脚本的复杂度,我们转换 SQL 逻辑进行改写:先一起计算出 val * w 的部分,再求和,即:
select *, rowSum(val1...val10 * w) as weightedVal from t使用元编程可以写为:
cols = "val"+string(1..10)
w = (1..10) \ 10 $ ANY
<select *, rowSum(_$$cols * w) as weightedVal from t>.eval()4.4 where 多条件
筛选出某表中属于新能源或光伏类别的 val 字段:
// 模拟数据脚本
t = table(["新能源01", "新能源02", "电力01"] as flagName, 1 2 3 as val)// 批计算 SQL 脚本
select val from t where flagName like "%新能源%" or flagName like "%光伏%"基于函数的元编程
单个过滤条件 flagName like pattern 可以借助 makeCall/makeUnifiedCall 调用 like 函数实现。
由于过滤条件是动态的且可能不止一个,此时就可以借助 each 系列的高阶函数(each/eachRight/eachLeft)遍历生成多个条件子句,多个子句则可以使用 rowOr 函数进行连接。最终自定义一个用于生成 where 条件的匿名函数(其中 :R 是 eachRight 的模式表示):
def(col, pattern){return rowOr(like:R(col,pattern))}完整的元编程脚本如下:
pattern = ["%新能源%", "%光伏%"]
col= "flagName"
whereCond=makeCall(def(col, pattern){return rowOr(like:R(col,pattern))}, sqlCol(col), pattern)
sql(select=sqlCol("val"), from=t, where=whereCond).eval()基于宏变量的元编程
宏变量方法也需要基于自定义函数去实现:
val="val"
flag="flagName"
def filter(col, pattern){return rowOr(like:R(col,pattern))}
<select _$val from t where filter(_$flag,["%新能源%", "%光伏%"])>.eval()某些特别复杂的场景下,无法使用宏变量去编写 SQL 元代码,此时只能使用基于函数的方法生成。
4.5 每行记录按存储的计算代码(string)进行计算
假设某表有 3 列,前两列为数值列,第三列为字符串列存储计算指标,要求前两列作为参数,带入第三列计算指标列进行计算。
t = table(1 1.1 1.3 1.4 1.5 1.7 as a,0.2 0.2 0.2 0.2 0.2 0.2 as b,["iif(a>1,min(a-1,b),0)","iif(a>1,min(a-2,b),0)","iif(a>1,min(a-3,b),0)","iif(a>1,min(a-4,b),0)","iif(a>1,min(a-5,b),0)","iif(a>1,min(a-6,b),0)"] as v)
通过字符串生成计算代码,可以联想到元编程函数 parseExpr,且 parseExpr 支持指定 varDict 参数,支持计算的指标的参数值以字典形式传入赋值。以第一行计算为例,可以写为:
parseExpr("iif(a>1,min(a-1,b),0)", {a:1.0, b:0.2}).eval()由于每行具有不同的指标,使用 each 函数遍历每行记录,最后将计算结果拼接即可。实现的代码如下:
each(def(mutable d)->parseExpr(d.v, d.erase!(`v)).eval(), t)注:由于表的每一行都是一个字典,d.erase!(`v) 表示删除 v 字段后,就能得到 a, b 的赋值字典。
5. 总结
再回到开头提出的两个元编程场景:
- 场景一:SQL 的字段名或过滤条件等是动态的,需要通过函数参数或变量进行传递。
- 场景二:查询大宽表中的多个字段列,或者对普通表中多个字段执行相似的操作。
结合上述的案例的学习,对于上述场景的解决方案,可以做出如下总结:
- 对于场景一,字段动态传入,必须使用元编程实现,此时首选基于宏变量的元编程,因为这种方式更加简单,脚本可读性也更高。
- 对于场景二,若字段固定,则直接用字段序列书写 SQL 脚本即可,无需再通过元编程去实现。
相关文章:
更高效、更简洁的 SQL 语句编写丨DolphinDB 基于宏变量的元编程模式详解
元编程(Metaprogramming)指在程序运行时操作或者创建程序的一种编程技术,简而言之就是使用代码编写代码。通过元编程将原本静态的代码通过动态的脚本生成,使程序员可以创建更加灵活的代码以提升编程效率。 在 DolphinDB 中&#…...
与sorted()用法)
Python中的sort()与sorted()用法
Python中的sort()函数主要用于对列表(list)中的元素进行排序。它有两种形式:一种是列表的方法(即直接对列表对象调用),另一种则是内置的sorted()函数,它返回一个新的已排序列表,而不…...

15.队列集
1.简介 在使用队列进行任务之间的“沟通交流”时,一个队列只允许任务间传递的消息为同一种数据类型,如果需要在任务间传递不同数据类型的消息时,那么就可以使用队列集。FreeRTOS提供的队列集功能可以对多个队列进行“监听”,只要…...

Dubbo 集群容错
Dubbo 集群容错 假设我们运营一个大型的电子商务网站,它有大量的用户在任何时间都在进行购物、浏览商品、添加到购物车、结账等操作。为了处理这种高流量和高并发性的情况,我们可能已经设置了一个由多个服务器组成的计算机集群。 在这种情况下…...

杨辉三角形(蓝桥杯,acwing)
题目描述: 下面的图形是著名的杨辉三角形: 如果我们按从上到下、从左到右的顺序把所有数排成一列,可以得到如下数列: 1, 1, 1, 1, 2, 1, 1, 3, 3, 1, 1, 4, 6, 4, 1, ... 给定一个正整数 N,请你输出数列中第一次出现…...

计算系数(acwing,数论)
题目描述: 给定一个多项式 (axby)^k,请求出多项式展开后 x^n*y^m 项的系数。 输入格式: 共一行,包含 5 个整数,分别为 a,b,k,n,m,每两个整数之间用一个空格…...
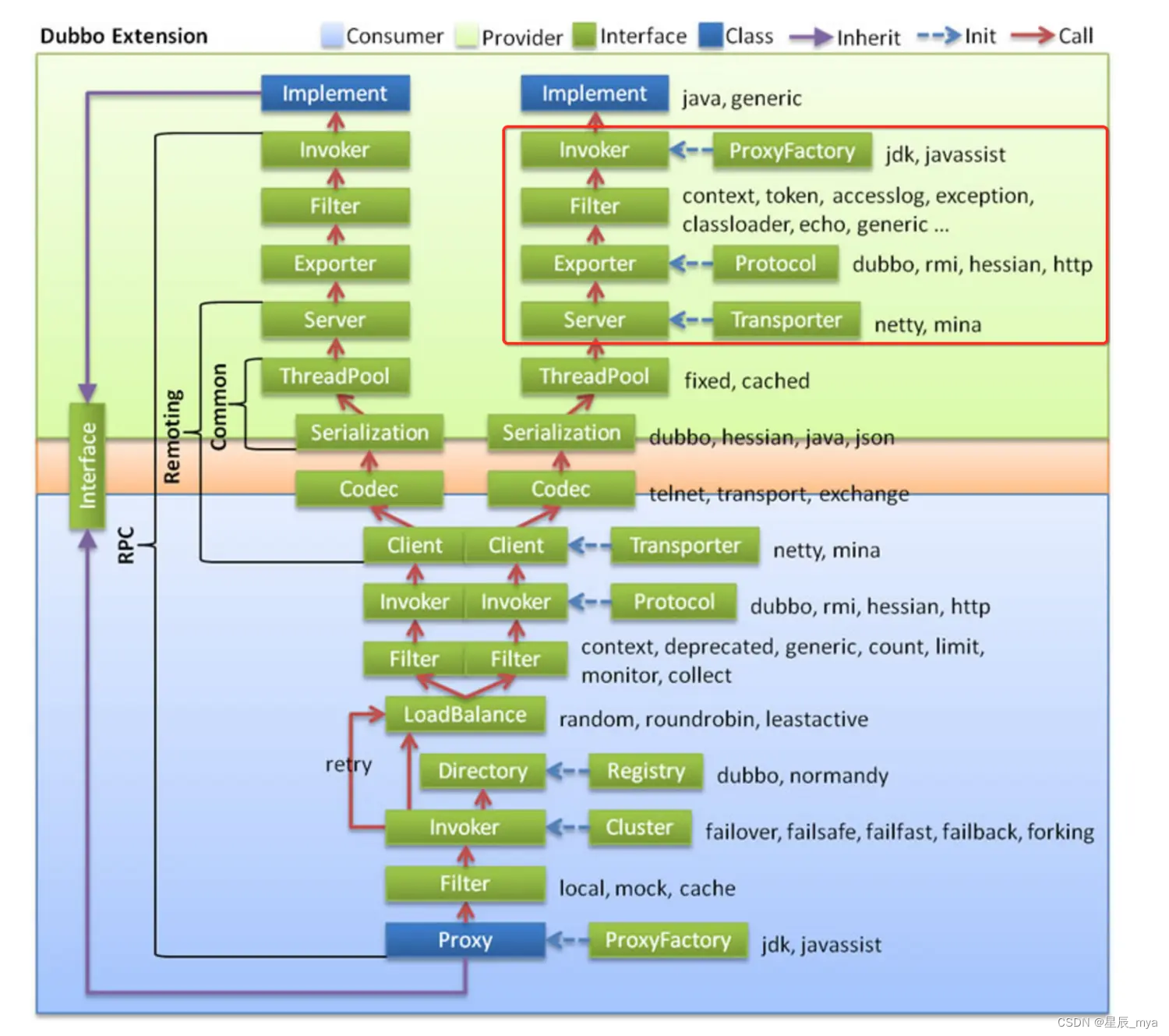
阿里面试题二
实在是太长了 重新开一篇吧 dubbo 服务暴露 Dubbo——服务调用、服务暴露、服务引用过程 - 简书 这两篇文章写的是极好 我现在查得资源强的可怕朋友们 服务降级 MockClusterInvoker 负载均衡策略 容错机制在哪里实现的源码 通信 NIO、BIO区别,NIO解决了什么…...
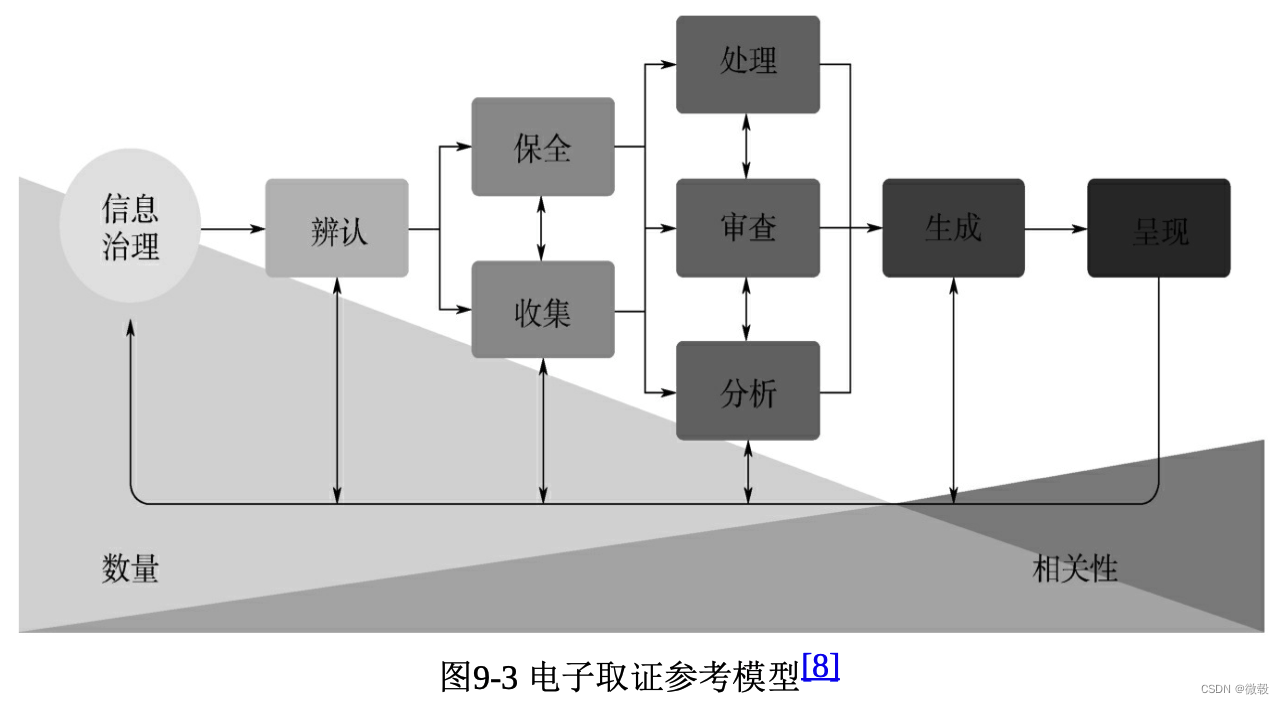
第9章 文件和内容管理
思维导图 9.1 引言 文件和内容管理是指针对存储在关系型数据库之外的数据和信息的采集、存储、访问和使用过程的管理。它的重点在于保持文件和其他非结构化或半结构化信息的完整性,并使这些信息能够被访问。文件和非结构化内容也应是安全且高质量的。 确保文件和内容…...
【Erlang】【RabbitMQ】Linux(CentOS7)安装Erlang和RabbitMQ
一、系统环境 查版本对应,CentOS-7,选择Erlang 23.3.4,RabbitMQ 3.9.16 二、操作步骤 安装 Erlang repository curl -s https://packagecloud.io/install/repositories/rabbitmq/erlang/script.rpm.sh | sudo bash安装 Erlang package s…...
-导出表)
pe格式从入门到图形化显示(七)-导出表
文章目录 前言一、什么是Windows PE格式中的导出表?二、解析导出表并显示1.导出表的结构2.解析导出表3.显示导出表 前言 通过分析和解析Windows PE格式,并使用qt进行图形化显示 一、什么是Windows PE格式中的导出表? PE文件格式的导出表是P…...
)
图片地址生成二维码(通过前端实现)
文章目录 概要安装插件代码实例 概要 要将图片地址生成二维码,你可以使用 QrCode 库(假设你已经在项目中引入了该库)。以下是一个简单的示例代码,演示了如何使用 QrCode 库将图片地址转换为二维码并显示在页面上 安装插件 先下载…...

window安装maven和hadoop3.1.4
前面的文章已讲解如何安装idea和进行基本设置,本文主要带着大家安装配置好maven和hadoop. 大家不用去官网下载,直接使用我发给大家的压缩文件,注意解压后的文件夹不要放在中文目录下,课堂上我们讲解过原因。 这是我电脑上的路径&a…...
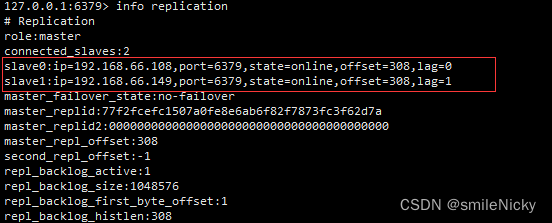
Redis系列之主从复制集群搭建
在上一篇博客,我们已经知道怎么搭建一个redis单机版,这篇博客基于之前的基础,来搭建一个redis主从同步,本博客框架是一主二从,一个主节点,其它两个从节点 实验环境 CentOS7Xshell6XFtp6Redis6.2.2 主从关…...

spring框架介绍
spring 1.优点 1)针对接口编程,解耦合 2)aop:变向切面编程,动态增加功能 3)方便集成框架,mybatis,hibernate,strust等 4)降低j2ee接口的使用难度 2.spring是干什么的 管理bean及bean…...

如果在 Ubuntu 系统中两个设备出现两个相同的端口号解决方案
问题描述: 自己的移动机器人在为激光雷达和IMU配置动态指定的端口时,发现激光雷达和深度相机配置的 idVendor 和 idProduct 相同,但是两个设备都具有不同的ttyUSB号,如下图所示 idVendor:代表着设备的生产商ID,由USB设…...

随手分享的APP链接,可能会让你“大型社死”
早晨上班路上,你在地铁百无聊赖地刷着短视频,看到一则好笑的,随手分享给了你的公司“饭搭子”,并配上了一串“哈哈哈哈哈哈”。 晚上下班路上你再次打开视频APP,发现首页弹窗给你推荐了一组“可能认识的人”ÿ…...

国内AI大模型已近80个,哪个最有前途?
根据中国新一代人工智能发展战略研究院发布的报告显示,目前全国已有3k+家人工智能企业,国内的AI大模型应该也近在200了!!! (原图图片过长了,这里就先放了20个) 面对如…...
美团一面:说说synchronized的实现原理?问麻了。。。。
引言 在现代软件开发领域,多线程并发编程已经成为提高系统性能、提升用户体验的重要手段。然而,多线程环境下的数据同步与资源共享问题也随之而来,处理不当可能导致数据不一致、死锁等各种并发问题。为此,Java语言提供了一种内置…...
P1123 取数游戏(dfs算法)
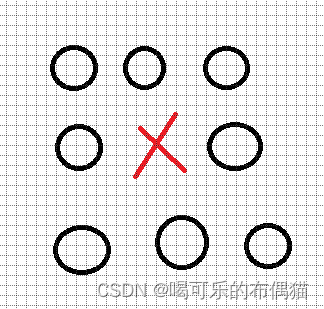
题目描述 一个 NM 的由非负整数构成的数字矩阵,你需要在其中取出若干个数字,使得取出的任意两个数字不相邻(若一个数字在另外一个数字相邻 8个格子中的一个即认为这两个数字相邻),求取出数字和最大是多少。 输入格式 第…...

交叉验证(Cross-Validation)
交叉验证的基本概念 交叉验证通常用于评估机器学习模型在未知数据上的性能。它将数据集分成k个不同的子集,然后进行k次训练和验证。在每次迭代中,选择一个子集作为测试集,其余的子集作为训练集。这样,每个子集都用作过测试集&…...

西门子PLC通信必备:手把手教你用SCL编写Modbus RTU CRC校验功能块
西门子PLC通信实战:SCL实现Modbus RTU CRC校验的工程化解决方案 在工业自动化领域,可靠的数据通信如同设备的神经系统。当两台PLC需要通过RS485接口交换温度传感器读数时,Modbus RTU协议因其简洁高效成为首选。但许多工程师在调试阶段都会遇到…...

用ZYNQ和LWIP搞定8路ADS8681数据采集:从Vivado Block Design到上位机TCP通信的完整流程
ZYNQ与LWIP构建的8通道高速数据采集系统实战指南 在工业自动化、测试测量和科研领域,多通道高精度数据采集系统正变得越来越重要。本文将详细介绍如何利用Xilinx ZYNQ SoC和LWIP协议栈,构建一个支持8路ADS8681同步采集的实时数据传输系统。不同于简单的代…...

别再死记硬背了!用Python模拟超前进位加法器,直观理解其速度优势
用Python模拟超前进位加法器:从硬件原理到算法思维的跨越 在计算机科学和电子工程交叉领域,加法器是最基础却又最精妙的设计之一。传统教学中,我们往往通过抽象的电路图来理解超前进位加法器(CLA)的速度优势࿰…...

Windows平台QT BLE开发避坑指南:从环境搭建到稳定通信
1. Windows平台QT BLE开发环境搭建 在Windows平台上使用QT进行BLE开发,首先需要确保开发环境正确配置。我遇到过不少开发者因为环境问题卡在第一步,白白浪费好几天时间。这里分享几个关键点: 编译器选择是第一个坑。实测发现必须使用MSVC编译…...
)
别再死记硬背公式了!用Python+NumPy手把手带你仿真RLC串联谐振(附代码)
用PythonNumPy动态仿真RLC串联谐振:告别枯燥公式,直观理解电路本质 当你第一次翻开电路分析教材,看到那些密密麻麻的公式推导和抽象的频率响应曲线时,是否感到一阵眩晕?RLC串联谐振作为电路分析的核心概念,…...

Mantic.sh:Bash脚本实现的终端命令自动化与效率提升工具
1. 项目概述:一个为开发者打造的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你肯定对效率工具有着近乎偏执的追求。从cd到ls,从grep到awk,我们依赖这些…...

Rekall:基于时空查询的视频内容智能检索开源框架
1. 项目概述:Rekall,一个面向视频时空查询的开源利器 如果你曾经尝试过从一段长视频里,精准地找出“那个穿红色衣服的人从画面左侧走到右侧的片段”,或者想快速定位“所有出现这只特定宠物狗的镜头”,你就会知道这有多…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...

从零打造专业GitHub个人资料页:Markdown与动态集成实战指南
1. 项目概述与核心价值 在技术圈子里混了十几年,我越来越觉得,一个开发者的“数字门面”和代码能力同等重要。这个门面,很多时候就是你的GitHub主页。早些年,大家的GitHub个人页面就是个简单的仓库列表,加上一些贡献图…...

Claude模型思维链评估框架claweval:原理、实战与高级定制指南
1. 项目概述:一个专为Claude模型设计的“思维链”评估框架最近在AI应用开发圈里,一个名为claweval的项目开始被频繁提及。如果你正在使用Anthropic的Claude系列模型(无论是Claude 3 Opus、Sonnet还是Haiku)来构建需要复杂推理能力…...