K-means聚类算法的原理、应用与实例
文章目录
- K-means 聚类算法:原理
- K-means 聚类算法的应用
- K-means 聚类算法的优化与改进
- 一个使用 K-means 聚类算法进行客户细分的简单实例
K-means 聚类算法:原理
K-means 算法是一种经典的无监督学习方法,用于对未标记的数据集进行分群,即将数据集中相似的对象划分为不同的簇。以下是其基本原理:
1. 初始化:
- 设定簇的数量(K):由用户预先指定,表示希望得到的簇的数量。
- 选择初始聚类中心(Centroids):通常随机从数据集中选取 K 个对象作为初始的聚类中心。
2. 分配对象到簇:
- 计算距离:对于数据集中每一个对象,计算其与 K 个聚类中心之间的距离(通常使用欧氏距离)。
- 分配归属:将每个对象分配到与其最近的聚类中心对应的簇中。
3. 更新聚类中心:
- 计算簇内平均值:对于每个簇,计算其包含的所有对象的特征均值,得到新的聚类中心。
- 移动中心:将簇的聚类中心更新为这个新的计算出的均值位置。
4. 判断收敛与迭代:
- 检查终止条件:比较当前迭代前后聚类中心的变化情况,如果变化小于某个预定阈值或达到最大迭代次数,则算法结束;否则,返回步骤2,继续进行新一轮的分配和更新。
上述过程反复进行,直到聚类中心的位置不再显著变化或达到预设的迭代次数上限。最终得到的簇即为数据集中的自然结构划分,每个簇内的对象在特征空间中较为接近,而不同簇之间的对象相对较远。
K-means 聚类算法的应用
K-means 聚类因其简单、高效的特点,在众多领域中有着广泛应用,包括但不限于:
1. 数据挖掘与分析:
- 市场细分:对消费者数据进行聚类,识别具有相似消费习惯或偏好特征的客户群体,以便制定针对性的营销策略。
- 文档分类:对文本数据(如新闻文章、网页等)进行聚类,自动划分主题相似的文章类别。
- 社交网络分析:对用户行为数据进行聚类,发现用户社区、兴趣小组或用户角色。
2. 图像处理与计算机视觉:
- 图像分割:对图像像素进行聚类,实现基于颜色、纹理等特征的图像区域划分。
- 对象识别与跟踪:对视频帧中的对象进行聚类,辅助进行运动对象的识别与跟踪。
3. 生物医学研究:
- 基因表达数据分析:对基因表达谱数据进行聚类,识别具有相似表达模式的基因组群,揭示潜在的生物学功能或疾病相关性。
- 医疗影像分析:对医学影像(如MRI、CT等)进行聚类,区分正常组织与异常区域,辅助诊断与治疗规划。
4. 其他领域:
- 地理信息系统(GIS):对地理位置数据进行聚类,发现人口分布、商业热点等空间模式。
- 物联网(IoT):对传感器数据进行聚类,识别设备工作状态模式或异常行为。
K-means 聚类算法的优化与改进
尽管 K-means 算法简单易用,但在实际应用中可能会遇到一些挑战,为此研究人员提出了多种优化与改进策略:
1. 初始聚类中心的选择:
- K-means++:通过概率方法选择初始聚类中心,确保它们尽可能分散且能代表数据的整体分布,从而提高算法的稳定性和收敛速度。
- 其他策略:如基于密度的方法、基于层次的方法或使用智能优化算法(如遗传算法、模拟退火等)来确定初始聚类中心。
2. 距离度量与标准化:
- 非欧氏距离:根据数据特性选择更适合的距离度量,如曼哈顿距离、余弦相似度、马氏距离等。
- 特征缩放与标准化:对数据进行预处理,如归一化、标准化等,以消除特征间尺度差异对聚类结果的影响。
3. 处理不同类型数据与噪声:
- 模糊 C 均值(FCM):允许对象属于多个簇,适用于边界模糊或含有噪声的数据。
- DBSCAN 或 OPTICS:针对具有不同密度区域的数据,发现任意形状的簇,并能较好地处理噪声点和离群值。
4. 动态调整簇数量 K:
- 肘部法则:通过观察轮廓系数、 inertia(簇内平方和)等指标随 K 值变化的趋势,选择“肘部”处的 K 值作为最优簇数。
- 交叉验证或**贝叶斯信息准则(BIC)**等统计方法:用于评估不同 K 值下的聚类质量,选择最优 K。
5. 并行与分布式计算:
- MapReduce 或 Spark 等框架:对大规模数据集进行分布式 K-means 聚类,利用多核处理器或集群的并行计算能力加速算法执行。
6. 异质聚类:
- 混合高斯模型(GMM):将数据视为由多个高斯分布生成,每个高斯分布对应一个簇,适用于数据内部存在异质性的场景。GMM 通过 EM 算法进行参数估计和聚类。
- 概率潜在语义分析(PLSA):适用于处理文本数据,假设每个文档是若干隐含主题的混合,每个主题对应一个簇,通过最大化似然函数进行参数估计和聚类。
7. 高维数据聚类:
- 子空间聚类(如 CLIQUE、SPEC、PROCLUS 等):寻找数据中具有聚类结构的低维子空间,降低维度以改善 K-means 在高维空间中的性能。
- 稀疏编码或深度学习预处理:通过学习数据的潜在表示(如自编码器、深度神经网络等),将原始高维数据映射到低维、更利于聚类的特征空间。
8. 时间序列与流数据聚类:
- 在线 K-means 或 增量 K-means:适应数据流的实时更新,仅对新加入的数据点或发生变化的簇进行重新分配和中心更新,无需每次都遍历整个数据集。
- 动态聚类(如 DenStream、CluStream 等):适用于数据分布随时间变化的场景,能够持续监控数据流,发现并跟踪动态出现和消失的簇。
9. 加权 K-means 聚类:
- 加权 K-means:为数据点赋予权重,反映其在聚类中的相对重要性,适用于处理带有不确定性的数据或含有噪声的数据集。
- 约束 K-means:引入先验知识或用户指定的约束条件(如必须将某些对象分到同一簇、某些对象不能分到同一簇等),引导聚类过程,提高结果的实用价值。
10. 聚类后处理与评估:
- 后处理方法:如对小簇合并、大簇分裂、边界对象重新分配等操作,以改善聚类的直观解释性和用户接受度。
- 聚类评估指标:如轮廓系数、Calinski-Harabasz 指数、Davies-Bouldin 指数等,定量评价聚类结果的质量,为算法选择和参数调优提供依据。
综上所述,通过对 K-means 聚类算法进行适当的优化与改进,我们可以应对更广泛的数据类型、规模、特性和应用场景,提高聚类的准确性和效率,使其在实际问题中发挥更大的作用。同时,结合领域知识和具体需求,灵活运用各种策略和方法,有助于获得更为满意的聚类结果。
一个使用 K-means 聚类算法进行客户细分的简单实例
以下是一个使用 K-means 聚类算法进行客户细分的简单实例。在这个例子中,我们假设有一家电商公司收集了其部分客户的购买历史数据,包括两个主要特征:年度消费金额(Annual_Spending)和购物频次(Purchase_Frequency)。公司希望通过 K-means 聚类算法将客户分为不同的群体,以便制定更具针对性的营销策略。
数据准备:
假设我们有一个包含 n 个客户的样本数据集 dataset,其中每个客户记录由两列组成:
dataset = [[Annual_Spending_1, Purchase_Frequency_1],[Annual_Spending_2, Purchase_Frequency_2],...[Annual_Spending_n, Purchase_Frequency_n]
]
实施 K-means 聚类:
- 初始化聚类中心:选择
k个初始聚类中心,这里假设k=3,可以随机从数据集中抽取k个样本作为初始聚类中心。
import numpy as npk = 3
initial_centers = np.random.choice(dataset, k, replace=False)
-
迭代过程:
- 分配样本到最近的聚类中心:计算每个样本到各个聚类中心的距离(通常使用欧氏距离),将其分配到距离最近的聚类。
def euclidean_distance(sample, center):return np.sqrt(np.sum((sample - center)**2))clusters = [[] for _ in range(k)] for sample in dataset:distances = [euclidean_distance(sample, center) for center in initial_centers]closest_cluster_index = np.argmin(distances)clusters[closest_cluster_index].append(sample)- 更新聚类中心:重新计算每个聚类内所有样本的均值,作为新的聚类中心。
new_centers = [] for cluster in clusters:if cluster:mean = np.mean(cluster, axis=0)new_centers.append(mean)else:# 如果某个聚类为空,可以重新随机选择一个样本作为中心,或者使用前一轮的中心new_centers.append(initial_centers[np.random.randint(k)]) -
收敛判断:比较新旧聚类中心的变化,如果变化小于某个设定阈值或达到最大迭代次数,则停止迭代;否则,用新聚类中心替换旧中心,继续下一轮迭代。
convergence_threshold = 0.01
max_iterations = 100
iteration = 0while iteration < max_iterations:old_centers = initial_centers.copy()initial_centers = new_centers# ... 重复步骤 2 中的分配样本和更新聚类中心操作# ... 计算新旧聚类中心之间的差异,并判断是否满足收敛条件# 如果未达到收敛条件,增加迭代计数器并继续下一轮iteration += 1# 当算法收敛或达到最大迭代次数时,输出最终的聚类结果
结果解释与应用:
经过 K-means 聚类后,我们得到了三个客户群体(假设 k=3)。每个群体代表一类具有相似消费行为的客户,可以根据聚类结果分析:
- 低消费、低频次群体:可能对应价格敏感型客户,可推送优惠券或特价商品以刺激消费。
- 中等消费、中频次群体:可能是忠诚但并不频繁购物的客户,可以通过定期促销活动保持其活跃度。
- 高消费、高频次群体:可能为VIP客户,应提供专属客户服务、优先权益等,以维持其高价值贡献。
以上实例展示了如何使用 K-means 聚类算法对客户数据进行细分。实际应用中,可能还需要对数据进行预处理(如标准化或归一化)、选择合适的 k 值(可以通过肘部法则、轮廓系数等方法确定)、以及对聚类结果进行可视化(如使用散点图展示不同群体在特征空间中的分布)等步骤。
上述实例展示了 K-means 聚类算法的基本应用流程。接下来,我们将对实例进行补充和完善,包括数据预处理、确定 K 值、结果可视化以及对聚类结果的解释与应用。
1. 数据预处理:
在实际应用中,数据往往需要进行预处理以提高聚类效果。在这个例子中,由于年度消费金额和购物频次的量纲和数值范围可能存在较大差异,我们对其进行标准化处理:
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
scaled_dataset = scaler.fit_transform(dataset)
标准化后的数据将具有零均值和单位方差,有助于消除特征间的尺度差异,使得距离计算更加公平。
2. 确定 K 值:
K-means 聚类算法需要预先指定簇的数量 k。在这里,我们使用肘部法则来帮助确定一个合适的 k 值。肘部法则通过观察随着 k 增大,轮廓系数或簇内平方和(inertia)的变化趋势,选择拐点(即“肘部”)处的 k 值。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_scoreinertias = []
silhouette_scores = []for k in range(2, 11): # 测试 2 到 10 个簇kmeans = KMeans(n_clusters=k).fit(scaled_dataset)inertias.append(kmeans.inertia_)silhouette_scores.append(silhouette_score(scaled_dataset, kmeans.labels_))plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 1)
plt.plot(range(2, 11), inertias, marker='o')
plt.title('Elbow Method: Inertia vs. Number of Clusters')
plt.xlabel('Number of Clusters (k)')
plt.ylabel('Inertia')plt.subplot(1, 2, 2)
plt.plot(range(2, 11), silhouette_scores, marker='o')
plt.title('Silhouette Score vs. Number of Clusters')
plt.xlabel('Number of Clusters (k)')
plt.ylabel('Silhouette Score')plt.tight_layout()
plt.show()# 根据图形判断“肘部”位置,选择合适的 k 值
3. 结果可视化:
使用散点图将聚类结果可视化,可以帮助我们直观理解不同客户群体在年度消费金额和购物频次特征空间中的分布。
def plot_clusters(dataset, labels, centers):plt.figure(figsize=(8, 6))plt.scatter(dataset[:, 0], dataset[:, 1], c=labels, cmap='viridis', alpha=0.8)plt.scatter(centers[:, 0], centers[:, 1], marker='X', s=150, color='red', label='Cluster Centers')plt.xlabel('Annual Spending (Standardized)')plt.ylabel('Purchase Frequency (Standardized)')plt.legend()plt.show()k = 3 # 假设通过肘部法则确定 k=3
kmeans = KMeans(n_clusters=k).fit(scaled_dataset)
labels = kmeans.labels_
centers = kmeans.cluster_centers_plot_clusters(scaled_dataset, labels, centers)
4. 聚类结果的解释与应用:
根据散点图和聚类结果,我们可以对三个客户群体进行如下解读和应用策略:
-
群体 0:低年度消费金额、低购物频次的客户,可能对价格敏感。营销策略:推送优惠券、特价商品,鼓励他们增加消费。
-
群体 1:中等年度消费金额、中购物频次的客户,具有一定忠诚度但购物频率不高。营销策略:定期发送新品推荐、促销活动通知,保持其购物活跃度。
-
群体 2:高年度消费金额、高购物频次的客户,为公司的高价值客户。营销策略:提供 VIP 服务、优先权益,维护其满意度和忠诚度,确保长期价值贡献。
至此,我们完成了使用 K-means 聚类算法对客户数据进行细分的完整过程,包括数据预处理、确定 K 值、结果可视化以及对聚类结果的解释与应用。这些步骤有助于电商公司制定有针对性的营销策略,提升客户管理与服务效果。
python推荐学习汇总连接:
50个开发必备的Python经典脚本(1-10)
50个开发必备的Python经典脚本(11-20)
50个开发必备的Python经典脚本(21-30)
50个开发必备的Python经典脚本(31-40)
50个开发必备的Python经典脚本(41-50)
————————————————
最后我们放松一下眼睛

相关文章:
K-means聚类算法的原理、应用与实例
文章目录 K-means 聚类算法:原理K-means 聚类算法的应用K-means 聚类算法的优化与改进 一个使用 K-means 聚类算法进行客户细分的简单实例 K-means 聚类算法:原理 K-means 算法是一种经典的无监督学习方法,用于对未标记的数据集进行分群&…...

使用SquareLine Studio创建LVGL项目到IMX6uLL平台
文章目录 前言一、SquareLine Studio是什么?二、下载安装三、工程配置四、交叉编译 前言 遇到的问题:#error LV_COLOR_DEPTH should be 16bit to match SquareLine Studios settings,解决方法见# 四、交叉编译 一、SquareLine Studio是什么…...
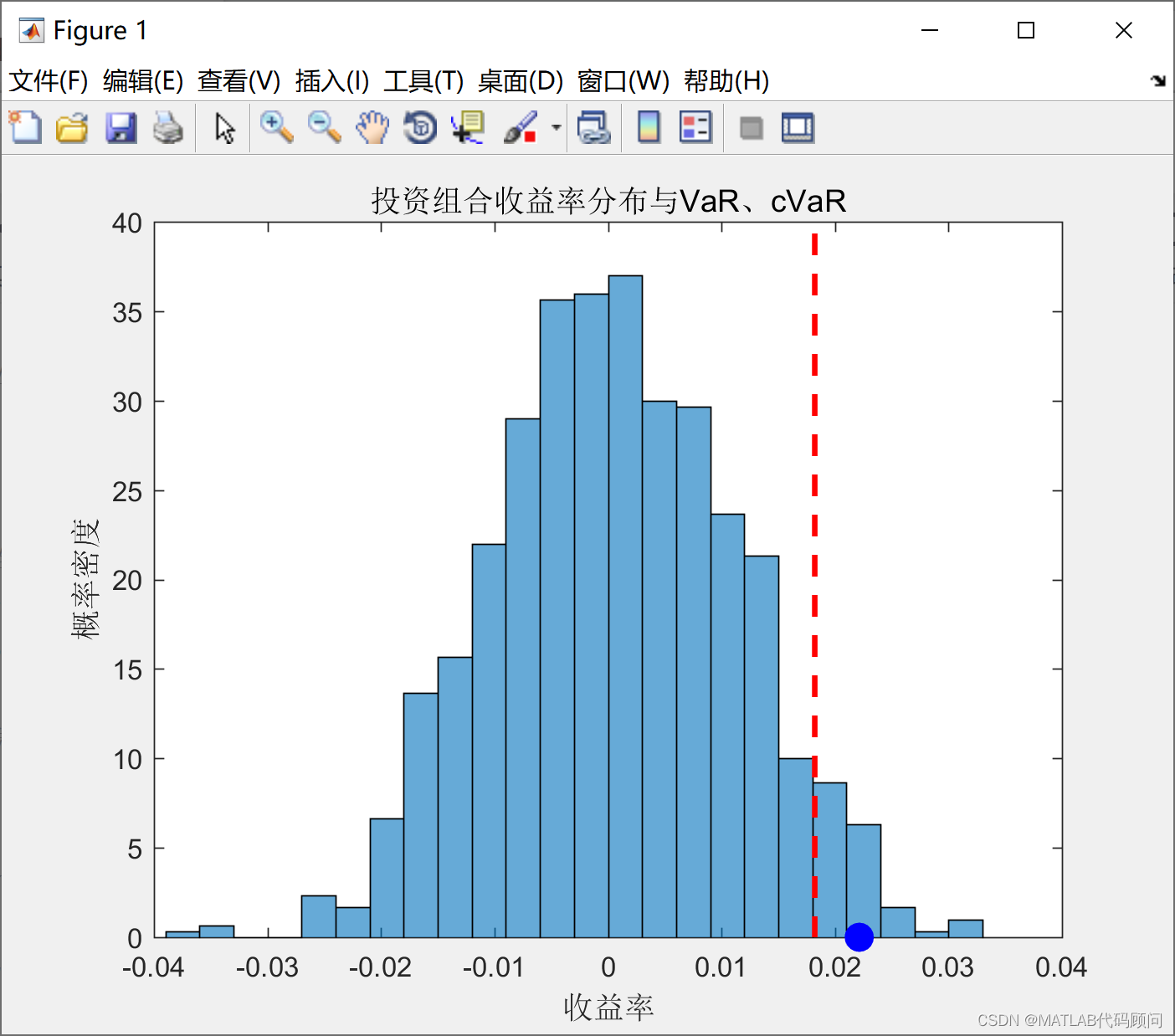
MATLAB计算投资组合的cVaR和VaR
计算条件风险价值 (Conditional Value-at-Risk, cVaR) 是一种衡量投资组合风险的方法,它关注的是损失分布的尾部风险。 MATLAB代码如下: clc;close all;clear all;warning off;%清除变量 rand(seed, 100); randn(seed, 100); format long g;% 随机产生数据&#x…...

YOLOv7全网独家改进: 卷积魔改 | 变形条状卷积,魔改DCNv3二次创新
💡💡💡本文独家改进: 变形条状卷积,DCNv3改进版本,不降低精度的前提下相比较DCNv3大幅度运算速度 💡💡💡强烈推荐:先到先得,paper级创新,直接使用; 💡💡💡创新点:1)去掉DCNv3中的Mask;2)空间域上的双线性插值转改为轴上的线性插值; 💡💡💡…...
使用vue3搭建一个CRM(客户关系管理)系统
目录 1. 需求分析 2. 设计 3. 技术选型 4. 开发环境搭建 5. 前端开发 6. 后端开发 7. 数据库搭建 8. 测试 9. 部署 10. 维护和迭代 总结 搭建一个CRM(客户关系管理)系统是一个复杂的项目,涉及到需求分析、设计、开发、测试和部署等…...

Linux虚拟内存简介
Linux,像多数现代内核一样,采用了虚拟内存管理技术。该技术利用了大多数程序的一个典型特征,即访问局部性(locality of reference),以求高效使用CPU和RAM(物理内存)资源。大多数程序…...
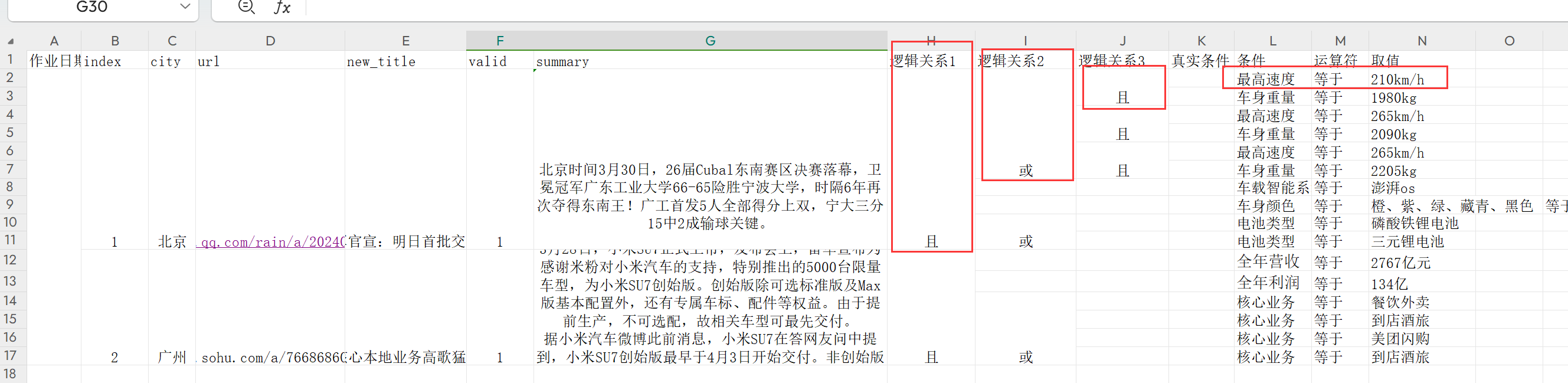
合并单元格的excel文件转换成json数据格式
github地址: https://github.com/CodeWang-Ay/DataProcess 类型1 需求1: 类似于数据格式: https://blog.csdn.net/qq_44072222/article/details/120884158 目标json格式 {"位置": 1, "名称": "nba球员", "国家": "美国"…...

云平台和云原生
目录 1.0 云平台 1.1.0 私有云、公有云、混合云 1.1.1 私有云 1.1.2 公有云 1.1.3 混合云 1.2 常见云管理平台 1.3 云管理的好处 1.3.1 多云的统一管理 1.3.2 跨云资源调度和编排需要 1.3.3 实现多云治理 1.3.4 多云的统一监控和运维 1.3.5 统一成本分析和优化 1.…...

ES6 => 箭头函数
目录 语法基本形式 参数 函数体 特点 箭头函数(Arrow Function)是ES6(ECMAScript 2015)中引入的一种新的函数语法,它提供了一种更简洁的方式来编写函数。箭头函数有几个显著的特点和优势,下面我们来详细…...

vue将html生成pdf并分页
jspdf html2canvas 此方案有很多的css兼容问题,比如虚线边框、svg、页数多了内容显示不全、部分浏览器兼容问题,光是解决这些问题就耗费了我不少岁月和精力 后面了解到新的技术方案: jspdf html-to-image npm install --save html-to-i…...

数字社会下的智慧公厕:构筑智慧城市的重要组成部分
智慧城市已经成为现代城市发展的趋势,而其中的数字化转型更是推动未来社会治理体系和治理能力现代化的必然要求。在智慧城市建设中,智慧公厕作为一种新形态的信息化公共厕所,扮演着重要角色。本文智慧公厕源头实力厂家广州中期科技有限公司&a…...
比较好玩的车子 高尔夫6
https://www.sohu.com/a/484063087_221273 四万多如愿收获手动挡高尔夫6,可靠性、经济性、操控性兼顾_搜狐汽车_搜狐网 2.基本上其他人也不知道到底是什么相关的车子信息...

智过网:非安全专业能否报考注安?哪些专业可以报考?
近年来,随着社会对安全生产管理的日益重视,注册安全工程师(简称注安)这一职业逐渐受到广大从业人员的青睐。然而,对于许多非安全专业的朋友来说,他们可能会困惑:非安全专业是否可以报考注安&…...

基于Whisper语音识别的实时视频字幕生成 (一): 流式显示视频帧和音频帧
Whishow Whistream(微流)是基于Whisper语音识别的的在线字幕生成工具,支持rtsp/rtmp/mp4等视频流在线语音识别 1. whishow介绍 whishow(微秀)是在线音视频流播放python实现,支持rtsp/rtmp/mp4等输入&…...
STM32+ESP8266水墨屏天气时钟:文字取模和图片取模教程
项目背景 本次的水墨屏幕项目需要显示一些图片和文字,所以需要对图片和文字进行取模。 取模步骤 1.打开取模软件 2.选择图形模式 3.设置字模选项 注意:本次项目采用的是水墨屏,并且是局部刷新的代码,所以设置字模选项可能有点…...

华为机试题
目录 第一章、HJ1计算字符串最后一个单词的长度,单词以空格隔开。1.1)描述1.2)解题第二章、算法题HJ2 计算某字符出现次数1.1)题目描述1.2)解题思路与答案第三章、算法题HJ3 明明的随机数1.1)题目描述1.2&a…...

【VUE】Vue3+Element Plus动态间距处理
目录 1. 动态间距调整1.1 效果演示1.2 代码演示 2. 固定间距2.1 效果演示2.2 代码演示 其他情况 1. 动态间距调整 1.1 效果演示 并行效果 并列效果 1.2 代码演示 <template><div style"margin-bottom: 15px">direction:<el-radio v-model"d…...
华为 2024 届校园招聘-硬件通⽤/单板开发——第一套(部分题目分享,完整版带答案,共十套)
华为 2024 届校园招聘-硬件通⽤/单板开发——第一套 部分题目分享,完整版带答案(有答案和解析,答案非官方,未仔细校正,仅供参考)(共十套)获取(WX:didadidadidida313,加我…...

自己整理的ICT云计算题库四
14. 【多选题】 CIFS 支持的认证方式是以下哪些选项? A: A 全局认证 B: B LADP 域 C: C 本地认证 D: D AD 域 答案 正确答案:ACD 解释 全局认证为先本地,后AD,再LADP 15. 【单选题】 华为 oceanstor v3 smarterase 在使用时…...

5.消息队列
消息队列 消息队列是一种常用的线程间通讯方式,用来传输数据。使用消息队列传输数据时有两种方法:拷贝:把数据、把变量的值复制进消息队列里;引用:把数据、把变量的地址复制进消息队列里。rtt使用拷贝值的方法。 …...
)
用Keras和MNIST数据集,5分钟搞定一个图像去噪的CNN自编码器(附完整代码)
5分钟实战:用Keras构建图像去噪自编码器的极简指南 当一张布满噪点的老照片在AI处理后重现清晰画面时,这种"数字魔法"背后往往是自编码器在发挥作用。作为深度学习领域的瑞士军刀,自编码器不仅能用于图像去噪,还在数据压…...

3倍效率提升:Gofile批量下载工具实战指南
3倍效率提升:Gofile批量下载工具实战指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 您是否曾为Gofile平台的文件下载效率低下而烦恼?当面对大文…...

Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案
Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 你是否曾在Sketchfab上发现完美的3D…...

技术视角:Sketchfab数据提取工具深度解析3D模型下载机制
技术视角:Sketchfab数据提取工具深度解析3D模型下载机制 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在WebGL技术日益成熟的今天,Sketch…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

Python与ChatGPT构建智能办公自动化:从任务分解到智能体系统
1. 项目概述:用Python与ChatGPT联手,让办公自动化“开口说话”如果你每天还在重复着打开Excel、复制粘贴数据、手动写邮件、整理报告这些枯燥的活儿,那这个项目可能就是你的“数字员工”入职通知书。Sven-Bo/automate-office-tasks-using-cha…...

如何轻松管理Switch游戏:NS-USBLoader完整指南,三步搞定游戏安装与系统引导
如何轻松管理Switch游戏:NS-USBLoader完整指南,三步搞定游戏安装与系统引导 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制
OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏中的卡顿和帧率限制?Open…...