Spark编程基础
一、RDD入门
1.RDD是什么?
RDD是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合,即弹性分布式数据集。
2.RDD的三种创建方式
- 第一种是将程序中已存在的集合(如集合、列表、数组)转换成RDD。
- 第二种是读取外部数据集来创建RDD。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.1准备数据:将程序中已存在的集合(如集合、列表、数组)转换成RDDval rdd1 = sc.parallelize(List(1,2,3,4))val rdd2 = sc.makeRDD(List(1,2,3,4))//2.2准备数据:读取外部数据集来创建RDDval rdd3 = sc.textFile("dataset/words.txt")//3.查看数据rdd1.collect().foreach(println)println("-------------------------")rdd2.collect().foreach(println)println("-------------------------")rdd3.collect().foreach(println)}- 第三种是对已有RDD进行转换得到新的RDD(在RDD的操作方法中讲解)。
二、单个RDD的转换操作
Spark RDD提供了丰富的操作方法(函数)用于操作分布式的数据集合,包括转换操作和行动操作两部分。
- 转换操作:可以将一个RDD转换为一个新的RDD,但是转换操作是懒操作,不会立刻执行计算;
- 行动操作:是用于触发转换操作的操作,这时才会真正开始进行计算。
1)map()方法
作用:把 RDD 中的数据 一对一 的转为另一种形式。
格式:def map[U: ClassTag](f: T ⇒ U): RDD[U]
Map 算子是 原RDD → 新RDD 的过程, 传入函数的参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(1,2,3,4))//3.RDD的转换操作mapvar rdd2 = rdd1.map(x => x * 10)//4.打印数据rdd2.collect().foreach(println)//10 20 30 40}2)flatMap()方法
作用:flatMap 算子和 Map 算子类似, 但是 flatMap 是一对多。
格式:def flatMap[U: ClassTag](f: T ⇒ List[U]): RDD[U]
参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据, 需要注意的是返回值是一个集合, 集合中的数据会被展平后再放入新的 RDD。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List("How are you","I am fine","What about you"))//3.RDD的转换操作flatMapvar rdd2 = rdd1.flatMap(x => x.split(" "))//4.打印数据rdd2.collect().foreach(println) //How are you I am fine What about you}
3)sortBy()方法
作用:用于对标准RDD进行排序,有3个可输入参数。
格式:def sortBy(func, ascending, numPartitions)
参数:func指定按照哪个字段来排序,通过这个函数返回要排序的字段;scending 是否升序,默认是true,即升序排序,如果需要降序排序那么需要将参数的值设置为false。;numPartitions 分区数。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List((1,3),(45,2),(7,6)))//3.RDD的转换操作sortBy,按照元组第二个值进行false降序val rdd2 = rdd1.sortBy(x =>x._2,false,1)//4.打印数据 rdd2.collect().foreach(println) //(7,6) (1,3) (45,2)}4)mapPartitionsWithIndex()方法
作用:对RDD中的每个分区(带有下标)进行操作,通过自己定义的一个函数来处理。
格式:def mapPartitionsWithIndex[U](f: (Int, Iterator[T]) => Iterator[U])
参数:f 是函数参数,接收两个参数:
(1)Int:代表分区号
(2)Iterator[T]:分区中的元素
(3)返回:Iterator[U]:操作完后,返回的结果
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据,并设置为2个分区val rdd1 = sc.parallelize(List(1,2,3,4,5),2)//3.RDD的转换操作mapPartionsWithIndexval rdd2 = rdd1.mapPartitionsWithIndex((index,it)=>{it.toList.map(x=>"["+index+","+x+"]").iterator})//4.打印数据:【分区编号,数据】rdd2.collect().foreach(println) //[0,1] [0,2] [1,3] [1,4] [1,5]}
5)filter()方法
作用:是一种转换操作,用于过滤RDD中的元素。
格式:def filter(f: T => Boolean): RDD[T]
将返回值为true的元素保留,将返回值为false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(1,2,3,4))//3.RDD的转换操作filter,过滤偶数val rdd2 = rdd1.filter(x => x%2==0)//4.打印数据rdd2.collect().foreach(println) //2 4}
6)distinct()方法
作用:是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没有参数。
格式:def distinct(): RDD[T]
将数据集中重复的数据去重,返回一个没有重复元素的新RDD。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(1,1,2,3,3))//3.RDD的转换操作filterval rdd2 = rdd1.distinct()//4.打印数据rdd2.collect().foreach(println) //1 2 3}三、多个RDD的集合操作
1)union()方法
作用:是一种并集转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的数据类型需要保持一致。
格式:def union(other: RDD[T]): RDD[T]
对源 RDD 和参数 RDD 求并集后返回一个新的 RDD。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(1,2,3,4))val rdd2 = sc.parallelize(List(1,3,5,6))//3.RDD的转换操作unionval rdd3 = rdd1.union(rdd2)//4.打印数据rdd3.collect().foreach(println) //1,2,3,4,1,3,5,6}2)intersection()方法
作用:是一种交集转换操作,用于将求出两个RDD的共同元素。
格式:def intersection(other: RDD[T]): RDD[T]
对源 RDD 和参数 RDD 求交集后返回一个新的 RDD,两个RDD的顺序不会影响结果。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(1,2,3,4))val rdd2 = sc.parallelize(List(1,2))//3.RDD的转换操作intersectionval rdd3 = rdd1.intersection(rdd2)//4.打印数据rdd3.collect().foreach(println) //1,2}3)subtract()方法
作用:是一种补集转换操作,用于将前一个RDD中在后一个RDD出现的元素删除,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。
格式:def subtract(other: RDD[T]): RDD[T]
将原RDD里和参数RDD里相同的元素去掉后返回一个新的 RDD,两个RDD的顺序会影响结果。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(1,2,3,4))val rdd2 = sc.parallelize(List(1,2,5))//3.RDD的转换操作subtractval rdd3 = rdd1.subtract(rdd2)val rdd4 = rdd2.subtract(rdd1)//4.打印数据rdd3.collect().foreach(println) //3,4println("----------------------")rdd4.collect().foreach(println) //5}4)cartesian()方法
作用:是一种求笛卡儿积操作,用于将两个集合的元素两两组合成一组。
格式:def cartesian(other: RDD[T]): RDD[T]
将原RDD里的每个元素都和参数RDD里的每个组合成一组,返回一个新的RDD。两个RDD的顺序会影响结果。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(1,3,4))val rdd2 = sc.parallelize(List(1,2))//3.RDD的转换操作cartesianval rdd3 = rdd1.cartesian(rdd2)val rdd4 = rdd2.cartesian(rdd1)//4.打印数据rdd3.collect().foreach(println) //(1,1) (1,2) (3,1) (3,2) (4,1) (4,2)println("----------------------")rdd4.collect().foreach(println) //(1,1) (1,3) (1,4) (2,1) (2,3) (2,4)}四、单个键值对RDD的转换操作
Spark的大部分RDD操作都支持所有种类的单值RDD,但是有少部分特殊的操作只能作用于键值对类型的RDD。键值对RDD由一组组的键值对组成,这些RDD被称为PairRDD。PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口。
1)创建键值对RDD
1.将一个普通RDD通过map转化为Pair RDD。当需要将一个普通的RDD转化为一个PairRDD时可以使用map函数来进行操作,传递的函数需要返回键值对。
2.通过List直接创建Pair RDD。
3.使用zip()方法用于将两个RDD组成Pair RDD。要求两个及元素数量相同,否则会抛出异常。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List("I like spark","He likes spark"))//3.1 通过flatMap和map方法将一个普通的RDD转化为一个键值对RDDval rdd2 = rdd1.flatMap(x => x.split(" "))val rdd3 = rdd2.map(x => (x,1))//3.2 通过List直接创建Pair RDDval rdd4 = sc.parallelize(List(("张三",100),("李四",90),("王五",80)))//3.3 使用zip()方法用于将两个RDD组成Pair RDDval dataRdd1 = sc.parallelize(List(1,2,3),2)val dataRdd2 = sc.parallelize(List("A","B","C"),2)val dataRdd3 = dataRdd1.zip(dataRdd2)//4.打印数据rdd2.collect().foreach(println) //(I,like,spark,He,likes,spark)println("---------------------")rdd3.collect().foreach(println) //(I,1) (like,1) (spark,1) (He,1) (likes,1) (spark,1)println("---------------------")rdd4.collect().foreach(println) //(张三,100) (李四,90) (王五,80)println("---------------------")dataRdd3.collect().foreach(println) //(1,A) (2,B) (3,C)}2)键值对RDD的keys和values方法
键值对RDD,包含键和值两个部分。 Spark提供了两种方法,分别获取键值对RDD的键和值。
- keys方法返回一个仅包含键的RDD。
- values方法返回一个仅包含值的RDD。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(("张三",100),("李四",90),("王五",80)))//3.1 获取keysval rdd2 = rdd1.keys//3.2 获取valuesval rdd3 = rdd1.values//3.打印数据rdd2.collect().foreach(println) //张三 李四 王五println("---------------------")rdd3.collect().foreach(println) //100 90 80}3)键值对RDD的reduceByKey()
作用:将相同键的前两个值传给输入函数,产生一个新的返回值,新产生的返回值与RDD中相同键的下一个值组成两个元素,再传给输入函数,直到最后每个键只有一个对应的值为止。
格式:def reduceByKey(func: (V, V) => V): RDD[(K, V)]
可以将数据按照相同的 Key 对 Value 进行聚合。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List("I like spark","He likes spark"))//3.1 通过flatMap和map方法将一个普通的RDD转化为一个键值对RDDval rdd2 = rdd1.flatMap(x => x.split(" "))val rdd3 = rdd2.map(x => (x,1)) // (I,1) (like,1) (spark,1) (He,1) (likes,1) (spark,1)//3.2 使用reduceByKey将相同键的值进行相加,统计词频val rdd4 = rdd3.reduceByKey((a,b) => a+b)//4.打印数据rdd4.collect().foreach(println) //(I,1) (He,1) (spark,2) (like,1) (likes,1)}3)键值对RDD的groupByKey()
作用:按照 Key 分组, 和 reduceByKey 有点类似, 但是 groupByKey 并不求聚合,只是列举 Key 对应的所有 Value。
格式:def groupByKey(): RDD[(K, Iterable[V])]
对于一个由类型K的键和类型V的值组成的RDD,通过groupByKey()方法得到的RDD类型是[K,Iterable[V]],可以将数据源的数据根据 key 对 value 进行分组。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(("a",1),("a",2),("b",1),("c",1),("c",1)))//3.使用groupByKey进行分组val rdd2 = rdd1.groupByKey()//4.使用map方法查看分组后每个分组中的值的数量val rdd3 = rdd2.map(x => (x._1,x._2.size))//5.打印数据rdd2.collect().foreach(println) //(a,CompactBuffer(1, 2)) (b,CompactBuffer(1)) (c,CompactBuffer(1, 1))rdd3.collect().foreach(println) //(a,2) (b,1) (c,2)}五、多个键值对RDD的转换操作
在Spark中,键值对RDD提供了很多基于多个RDD的键进行操作的方法。
1)join()方法
作用:用于根据键,对两个RDD进行内连接,将两个RDD中键相同的数据的值存放在一个元组中,最后只返回两个RDD中都存在的键的连接结果。
格式:def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(("a",1),("b",2),("c",3)))val rdd2 = sc.parallelize(List(("a",2),("b",4),("e",5)))//3.使用join进行内连接val rdd3 = rdd1.join(rdd2)//4.打印数据rdd3.collect().foreach(println) //(a,(1,2)) (b,(2,4))}2)rightOuterJoin()方法
作用:用于根据键,对两个RDD进行右外连接,连接结果是右边RDD的所有键的连接结果,不管这些键在左边RDD中是否存在。
格式:def rightOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
类似于 SQL 语句的右外连接。如果在左边RDD中有对应的键,那么连接结果中值显示为Some类型值;如果没有,那么显示为None值。
3)leftOuterJoin()方法
作用:用于根据键,对两个RDD进行左外连接,连接结果是左边RDD的所有键的连接结果,不管这些键在右边RDD中是否存在。
格式:def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
类似于 SQL 语句的右外连接。如果在右边RDD中有对应的键,那么连接结果中值显示为Some类型值;如果没有,那么显示为None值。
4)fullOuterJoin()方法
作用:用于对两个RDD进行全外连接,保留两个RDD中所有键的连接结果。
格式:def fullOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
类似于 SQL 语句的全外连接。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(("a",1),("b",2),("c",3)))val rdd2 = sc.parallelize(List(("a",2),("b",4),("e",5)))//3.使用rightOuterJoin进行右外连接val rdd3 = rdd1.rightOuterJoin(rdd2)//4.使用leftOuterJoin进行左外连接val rdd4 = rdd1.leftOuterJoin(rdd2)//5.使用fullOuterJoin进行全外连接val rdd5 = rdd1.fullOuterJoin(rdd2)//6.打印数据rdd3.collect().foreach(println) //(a,(Some(1),2)) (b,(Some(2),4)) (e,(None,5))println("--------------------")rdd4.collect().foreach(println) //(a,(1,Some(2))) (b,(2,Some(4))) (c,(3,None))println("--------------------")rdd5.collect().foreach(println) //(a,(Some(1),Some(2))) (b,(Some(2),Some(4))) (c,(Some(3),None)) (e,(None,Some(5)))}5)sortByKey()方法
作用:作用于Key-Value形式的RDD,并对Key进行排序。
格式:def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
参数:scending 是否升序,默认是true,即升序排序,如果需要降序排序那么需要将参数的值设置为false。numPartitions 为分区数。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List((1,3),(45,2),(7,6)))//3.RDD的转换操作sortByKeyval rdd2 = rdd1.sortByKey(true) //按key进行升序val rdd3 = rdd1.sortByKey(false) //按key进行降序//4.打印数据rdd2.collect().foreach(println)println("---------------------")rdd3.collect().foreach(println)}6)lookup()方法
作用:作用于键值对RDD,返回指定键的所有值。
格式:def lookup(key : K) : scala.Seq[V]
作用于K-V类型的RDD上,返回指定K的所有V值
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//2.准备数据val rdd1 = sc.parallelize(List(("张三",100),("李四",90),("王五",80)))//3.使用lookup()方法查找指定键的值val result = rdd1.lookup("李四")//4.打印数据println(result) //WrappedArray(90)}7)combineByKey()方法
作用:用于将键相同的数据聚合,并且允许返回,类型与输入数据的类型不同的返回值。
格式:def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
combineByKey()方法接收3个重要的参数,具体说明如下:
- createCombiner:V=>C,V是键值对RDD中的值部分,将该值转换为另一种类型的值C,C会作为每一个键的累加器的初始值。
- mergeValue:(C,V)=>C,该函数将元素V聚合到之前的元素C(createCombiner)上(这个操作在每个分区内进行)。
- mergeCombiners:(C,C)=>C,该函数将两个元素C进行合并(这个操作在不同分区间进行)。
小练习:将数据 List(("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0)),求每个 key的平均值。
def main(args: Array[String]): Unit = {//1.入口:创建SparkContextval conf = new SparkConf().setMaster("local[*]").setAppName("spark")val sc = new SparkContext(conf)//需求:将数据 List(("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0)),求每个 key的平均值//2.准备数据val rdd1 = sc.parallelize(List(("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0)))//3.1 通过combineByKey方法将RDD安装key进行聚合,返回值形式:(key,(值总和,key个数))val rdd2 = rdd1.combineByKey(score => (score,1),(scoreCount:(Double,Int),newScore:Double) => (scoreCount._1+newScore,scoreCount._2+1),(scoreCount1:(Double,Int),scoreCount2:(Double,Int)) => (scoreCount1._1+scoreCount2._1,scoreCount1._2+scoreCount2._2))//打印combineByKey聚合之后的数据,形式:(key,(值总和,key个数))rdd2.collect().foreach(println) //(zhangsan,(292.0,3)) (lisi,(195.0,2))//3.2 将按值聚合相加后的结果(zhangsan,(292.0,3)) (lisi,(195.0,2)),求每个人的平均值,返回值形式:(key,平均值)val result = rdd2.map(item =>(item._1,item._2._1/item._2._2))//4 打印数据println("------------------")result.collect().foreach(println)}combineByKey()方法执行过程的图解:

相关文章:
Spark编程基础
一、RDD入门 1.RDD是什么? RDD是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合,即弹性分布式数据集。 2.RDD的三种创建方式 第一种是将程序中已存在的集合(如集合、列表、数组&a…...

React 状态管理:高效处理数组数据的5种方法
1.原因 为什么在 React 中,状态(state)如果是数组类型,需要单独处理?主要有以下几个原因: 不可变性(Immutability): React 中的状态是不可变的,意味着我们不能直接修改状态,而是要创建一个新的状态对象。对于数组来说,直接修改数组元素是不符合 React 的设计原则的…...

SSH和交换机端口安全概述
交换机的安全是一个很重要的问题,因为它可能会遭受到一些恶意的攻击,例如MAC泛洪攻击、DHCP欺骗和耗竭攻击、中间人攻击、CDP 攻击和Telnet DoS 攻击等,为了防止交换机被攻击者探测或者控制,必须采取相应的措施来确保交换机的安全…...

K-means聚类算法的原理、应用与实例
文章目录 K-means 聚类算法:原理K-means 聚类算法的应用K-means 聚类算法的优化与改进 一个使用 K-means 聚类算法进行客户细分的简单实例 K-means 聚类算法:原理 K-means 算法是一种经典的无监督学习方法,用于对未标记的数据集进行分群&…...

使用SquareLine Studio创建LVGL项目到IMX6uLL平台
文章目录 前言一、SquareLine Studio是什么?二、下载安装三、工程配置四、交叉编译 前言 遇到的问题:#error LV_COLOR_DEPTH should be 16bit to match SquareLine Studios settings,解决方法见# 四、交叉编译 一、SquareLine Studio是什么…...
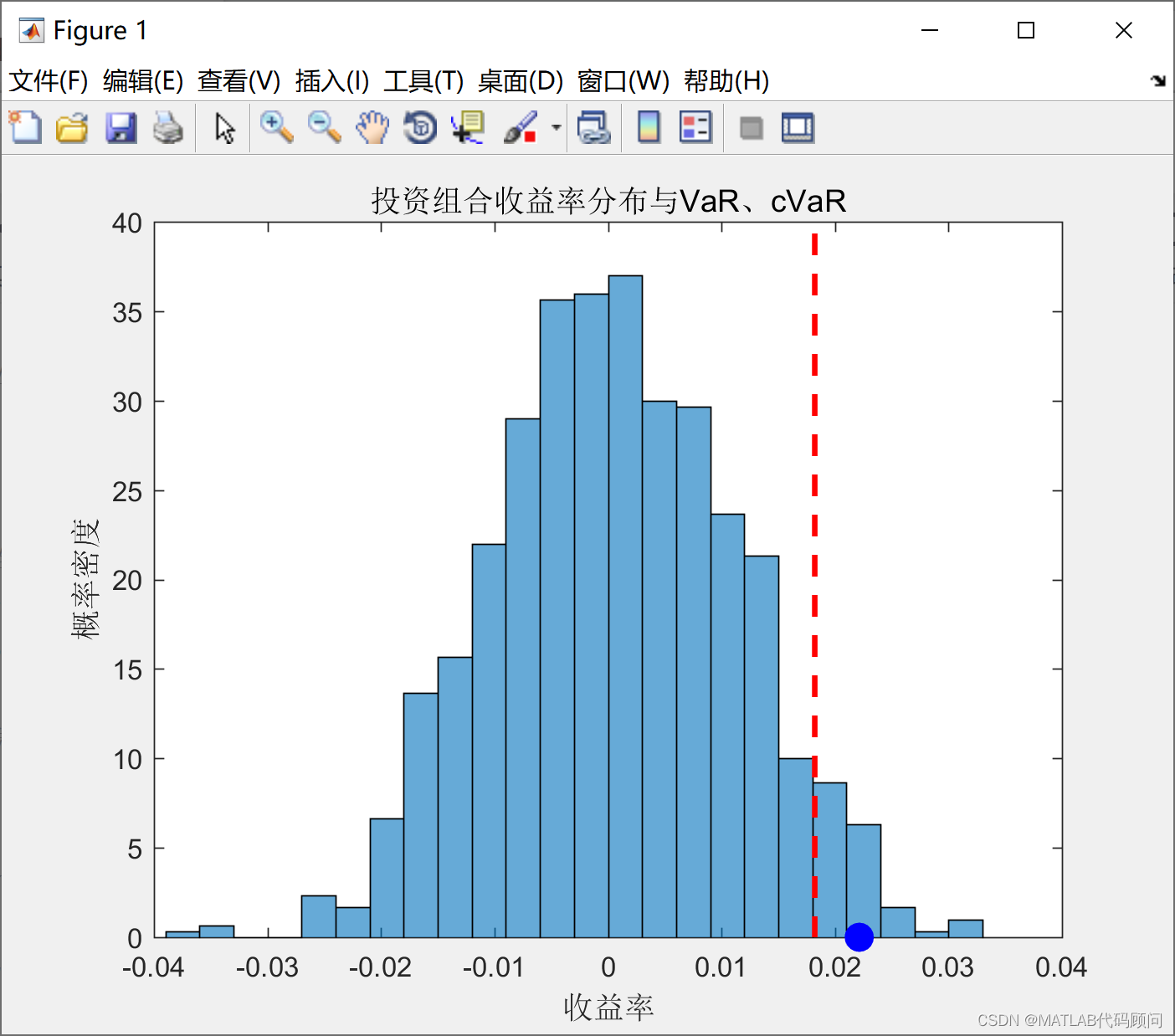
MATLAB计算投资组合的cVaR和VaR
计算条件风险价值 (Conditional Value-at-Risk, cVaR) 是一种衡量投资组合风险的方法,它关注的是损失分布的尾部风险。 MATLAB代码如下: clc;close all;clear all;warning off;%清除变量 rand(seed, 100); randn(seed, 100); format long g;% 随机产生数据&#x…...

YOLOv7全网独家改进: 卷积魔改 | 变形条状卷积,魔改DCNv3二次创新
💡💡💡本文独家改进: 变形条状卷积,DCNv3改进版本,不降低精度的前提下相比较DCNv3大幅度运算速度 💡💡💡强烈推荐:先到先得,paper级创新,直接使用; 💡💡💡创新点:1)去掉DCNv3中的Mask;2)空间域上的双线性插值转改为轴上的线性插值; 💡💡💡…...
使用vue3搭建一个CRM(客户关系管理)系统
目录 1. 需求分析 2. 设计 3. 技术选型 4. 开发环境搭建 5. 前端开发 6. 后端开发 7. 数据库搭建 8. 测试 9. 部署 10. 维护和迭代 总结 搭建一个CRM(客户关系管理)系统是一个复杂的项目,涉及到需求分析、设计、开发、测试和部署等…...

Linux虚拟内存简介
Linux,像多数现代内核一样,采用了虚拟内存管理技术。该技术利用了大多数程序的一个典型特征,即访问局部性(locality of reference),以求高效使用CPU和RAM(物理内存)资源。大多数程序…...
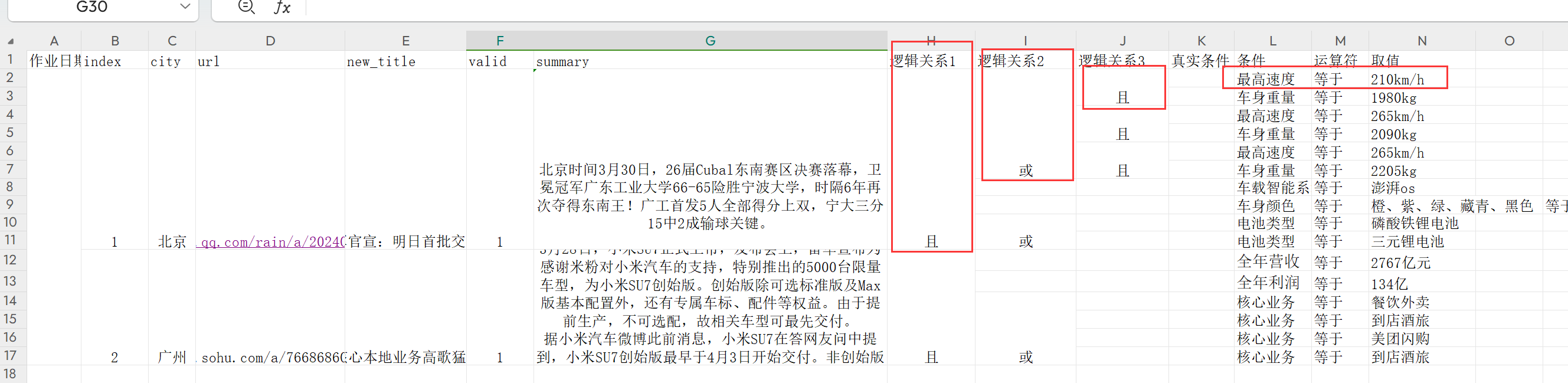
合并单元格的excel文件转换成json数据格式
github地址: https://github.com/CodeWang-Ay/DataProcess 类型1 需求1: 类似于数据格式: https://blog.csdn.net/qq_44072222/article/details/120884158 目标json格式 {"位置": 1, "名称": "nba球员", "国家": "美国"…...

云平台和云原生
目录 1.0 云平台 1.1.0 私有云、公有云、混合云 1.1.1 私有云 1.1.2 公有云 1.1.3 混合云 1.2 常见云管理平台 1.3 云管理的好处 1.3.1 多云的统一管理 1.3.2 跨云资源调度和编排需要 1.3.3 实现多云治理 1.3.4 多云的统一监控和运维 1.3.5 统一成本分析和优化 1.…...

ES6 => 箭头函数
目录 语法基本形式 参数 函数体 特点 箭头函数(Arrow Function)是ES6(ECMAScript 2015)中引入的一种新的函数语法,它提供了一种更简洁的方式来编写函数。箭头函数有几个显著的特点和优势,下面我们来详细…...

vue将html生成pdf并分页
jspdf html2canvas 此方案有很多的css兼容问题,比如虚线边框、svg、页数多了内容显示不全、部分浏览器兼容问题,光是解决这些问题就耗费了我不少岁月和精力 后面了解到新的技术方案: jspdf html-to-image npm install --save html-to-i…...

数字社会下的智慧公厕:构筑智慧城市的重要组成部分
智慧城市已经成为现代城市发展的趋势,而其中的数字化转型更是推动未来社会治理体系和治理能力现代化的必然要求。在智慧城市建设中,智慧公厕作为一种新形态的信息化公共厕所,扮演着重要角色。本文智慧公厕源头实力厂家广州中期科技有限公司&a…...
比较好玩的车子 高尔夫6
https://www.sohu.com/a/484063087_221273 四万多如愿收获手动挡高尔夫6,可靠性、经济性、操控性兼顾_搜狐汽车_搜狐网 2.基本上其他人也不知道到底是什么相关的车子信息...

智过网:非安全专业能否报考注安?哪些专业可以报考?
近年来,随着社会对安全生产管理的日益重视,注册安全工程师(简称注安)这一职业逐渐受到广大从业人员的青睐。然而,对于许多非安全专业的朋友来说,他们可能会困惑:非安全专业是否可以报考注安&…...

基于Whisper语音识别的实时视频字幕生成 (一): 流式显示视频帧和音频帧
Whishow Whistream(微流)是基于Whisper语音识别的的在线字幕生成工具,支持rtsp/rtmp/mp4等视频流在线语音识别 1. whishow介绍 whishow(微秀)是在线音视频流播放python实现,支持rtsp/rtmp/mp4等输入&…...
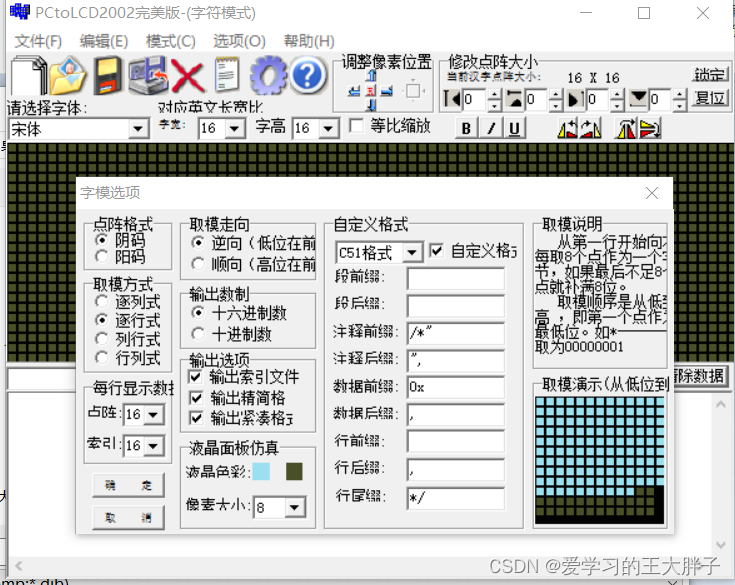
STM32+ESP8266水墨屏天气时钟:文字取模和图片取模教程
项目背景 本次的水墨屏幕项目需要显示一些图片和文字,所以需要对图片和文字进行取模。 取模步骤 1.打开取模软件 2.选择图形模式 3.设置字模选项 注意:本次项目采用的是水墨屏,并且是局部刷新的代码,所以设置字模选项可能有点…...

华为机试题
目录 第一章、HJ1计算字符串最后一个单词的长度,单词以空格隔开。1.1)描述1.2)解题第二章、算法题HJ2 计算某字符出现次数1.1)题目描述1.2)解题思路与答案第三章、算法题HJ3 明明的随机数1.1)题目描述1.2&a…...

【VUE】Vue3+Element Plus动态间距处理
目录 1. 动态间距调整1.1 效果演示1.2 代码演示 2. 固定间距2.1 效果演示2.2 代码演示 其他情况 1. 动态间距调整 1.1 效果演示 并行效果 并列效果 1.2 代码演示 <template><div style"margin-bottom: 15px">direction:<el-radio v-model"d…...

AI Agent执行链路的安全机制:权限控制与沙箱隔离方案
AI Agent执行链路安全深度解析:权限控制与沙箱隔离全栈落地方案 摘要/引言 你有没有遇到过这些场景:刚上线的企业内部运维Agent被恶意Prompt注入后,直接调用了删除生产库的工具;你做的数据分析Agent被诱导执行了恶意Python代码,把公司的用户隐私数据传到了境外黑客服务器…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...

Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案
Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 你是否曾在Sketchfab上发现完美的3D…...

基于轨道模型构建现代化流程编排系统:从概念到实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫s4kuraN4gi/orbit-app。乍一看这个仓库名,可能很多人会有点懵,不知道它具体是做什么的。我花了一些时间深入研究,发现这是一个围绕“轨道”概念构建的现代化应用。这…...
)
STM8硬件IIC驱动BNO055传感器避坑指南(附完整代码)
STM8硬件IIC驱动BNO055传感器实战解析与优化 BNO055作为一款集成了9轴传感器融合算法的智能芯片,能够直接输出姿态角数据,极大简化了嵌入式系统中姿态解算的复杂度。然而在实际应用中,许多开发者发现使用STM32等常见MCU的模拟IIC接口难以稳定…...

Switch便携投影底座DIY:3D打印与硬件改造实战指南
1. 项目概述:当Switch遇上投影,一场桌面上的大屏革命作为一个折腾过不少游戏机外设的玩家,我一直在想,有没有办法让Switch的“便携”属性再进化一步?官方底座接电视固然爽,但总被一根线缆束缚在客厅。直到我…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

终极指南:如何使用League-Toolkit英雄联盟工具箱快速提升游戏效率
终极指南:如何使用League-Toolkit英雄联盟工具箱快速提升游戏效率 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中…...

天学网口碑好不好?2026年最新用户实测反馈给你答案
作为深耕教育数字化落地领域5年的从业者,最近后台收到不少公立校电教组老师、学生家长的提问:主打AI英语教学的天学网口碑到底怎么样?刚好我们团队刚做完2026年第一季度的英语教育数字化工具落地效果调研,结合一手实测数据给大家客…...

基于Nginx-Lua镜像构建高性能可编程网关的实践指南
1. 项目概述:一个为现代Web架构而生的Nginx镜像如果你和我一样,长期在容器化环境中部署和管理Web服务,那么你一定对Nginx的灵活性和Lua脚本的强大能力印象深刻。但将这两者结合,并打包成一个稳定、安全、功能齐全的Docker镜像&…...