【数仓】DataX 通过SpringBoot项目自动生成 job.json 文件
相关文章
- 【数仓】基本概念、知识普及、核心技术
- 【数仓】数据分层概念以及相关逻辑
- 【数仓】Hadoop软件安装及使用(集群配置)
- 【数仓】Hadoop集群配置常用参数说明
- 【数仓】zookeeper软件安装及集群配置
- 【数仓】kafka软件安装及集群配置
- 【数仓】flume软件安装及配置
- 【数仓】flume常见配置总结,以及示例
- 【数仓】Maxwell软件安装及配置,采集mysql数据
- 【数仓】通过Flume+kafka采集日志数据存储到Hadoop
- 【数仓】DataX软件安装及配置,从mysql同步到hdfs
DataX的任务脚本job.json格式基本类似,而且我们在实际同步过程中通常都是一个表对应一个job,那么如果需要同步的表非常多的话,需要编写的job.json文件也非常多。既然是类似文件结构,那么我们就有办法通过程序自动生成相关的job.json文件。
居于以上考虑,有了下面的SpringBoot项目自动生成job.json的程序!
一、job 配置说明
DataX的job配置中的reader、writer和setting是构成数据同步任务的关键组件。
1、reader
reader是数据同步任务中的数据源读取配置部分,用于指定从哪个数据源读取数据以及如何读取数据。它通常包含以下关键信息:
name: 读取插件的名称,如mysqlreader、hdfsreader等,用于指定从哪种类型的数据源读取数据。parameter: 具体的读取参数配置,包括数据源连接信息、读取的表或文件路径、字段信息等。
示例:
假设要从MySQL数据库读取数据,reader的配置可能如下:
"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "password","column": ["id", "name", "age"],"connection": [{"jdbcUrl": "jdbc:mysql://localhost:3306/test_db","table": ["test_table"]}]}
}
2、writer
writer是数据同步任务中的目标数据源写入配置部分,用于指定将数据写入哪个目标数据源以及如何写入数据。它通常包含以下关键信息:
name: 写入插件的名称,如mysqlwriter、hdfswriter等,用于指定将数据写入哪种类型的数据源。parameter: 具体的写入参数配置,包括目标数据源连接信息、写入的表或文件路径、字段映射等。
示例:
假设要将数据写入HDFS,writer的配置可能如下:
"writer": {"name": "hdfswriter","parameter": {"writeMode": "append","fieldDelimiter": ",","compress": "gzip","column": [{"name": "id", "type": "int"}, {"name": "name", "type": "string"}, {"name": "age", "type": "int"}],"connection": [{"hdfsUrl": "hdfs://localhost:9000","file": ["/user/hive/warehouse/test_table"]}]}
}
3、setting
setting是数据同步任务的全局设置部分,用于配置影响整个任务行为的参数。它通常包含以下关键信息:
speed: 控制数据同步的速度和并发度,包括通道数(channel)和每个通道的数据传输速度(如byte)。errorLimit: 设置数据同步过程中的错误容忍度,包括允许出错的记录数(record)和错误率(percentage)。
示例:
一个典型的setting配置可能如下:
"setting": {"speed": {"channel": 3, // 并发通道数"byte": 1048576 // 每个通道的数据传输速度,单位是字节(1MB)},"errorLimit": {"record": 0, // 允许出错的记录数"percentage": 0.02 // 允许出错的记录数占总记录数的百分比}
}
综上所述,reader、writer和setting三个部分共同构成了DataX数据同步任务的配置文件。通过合理配置这些部分,用户可以灵活地定义数据源、目标数据源以及数据同步的行为和性能。在实际应用中,用户应根据具体的数据源类型、目标数据源类型和数据同步需求来填写和调整这些配置。
二、示例,从mysql同步到hdfs
该配置文件定义了从一个 MySQL 数据库读取数据,并将这些数据写入到 HDFS 的过程。
{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"column": ["id","name","msg","create_time","status","last_login_time"], "connection": [{"jdbcUrl": ["jdbc:mysql://192.168.56.1:3306/user?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai"], "table": ["t_user"]}], "password": "password", "username": "test", "where": "id>3"}}, "writer": {"name": "hdfswriter", "parameter": {"column": [{"name":"id","type":"bigint"},{"name":"name","type":"string"},{"name":"msg","type":"string"},{"name":"create_time","type":"date"},{"name":"status","type":"string"},{"name":"last_login_time","type":"date"}], "compress": "gzip", "defaultFS": "hdfs://hadoop131:9000", "fieldDelimiter": "\t", "fileName": "mysql2hdfs01", "fileType": "text", "path": "/mysql2hdfs", "writeMode": "append"}}}], "setting": {"speed": {"channel": "1"}}}
}
- 参考 mysqlreader
- 参考 hdfswriter
三、通过SpringBoot项目自动生成job文件
本例使用SpringBoot 3.0 结合 JDBC 读取mysql数据库表结构信息,生成job.json文件
1、创建SpringBoot项目,添加pom依赖以及配置
1)增加pom.xml依赖jar包
<!-- Spring Boot JDBC Starter -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- MySQL JDBC Driver -->
<dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.25</version>
</dependency>
2)增加application.properties配置项
server.port=8080
# mysql 数据库链接
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/user?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
spring.datasource.username=test
spring.datasource.password=password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver# datax 相关配置,在生成文件时使用
datax.hdfs.defaultFS=hdfs://hadoop131:9000
datax.hdfs.path=/origin_data
# 需要生成job文件的表,多个用逗号隔开
datax.mysql.tables=t_user,t_user_test,t_sys_dict
# job文件存储位置
datax.savepath=d:/temp/
2、按照job.json格式创建好各个 vo
1)基础结构vo
@Data
public class DataxJobRoot {private Job job;
}
@Data
public class Job {private List<Content> content;private Setting setting = new Setting();
}
@Data
public class Content {private Reader reader;private Writer writer;
}
@Data
public class Setting {private Speed speed = new Speed();@Datapublic static class Speed {private String channel = "1";}
}
@Data
public class Reader {private String name;private Parameter parameter;
}
@Data
public class Writer {private String name;private Parameter parameter;@Datapublic static class MysqlParameter {private List<String> column;private List<Connection> connection;private String password;private String username;private String writeMode = "replace";}@Datapublic static class Connection {private String jdbcUrl;private List<String> table;}
}public class Parameter {
}
2)mysql2hdfs的vo实现类
@EqualsAndHashCode(callSuper = true)
@Data
public class MysqlReader extends Reader {public String getName() {return "mysqlreader";}@EqualsAndHashCode(callSuper = true)@Datapublic static class MysqlParameter extends Parameter {private List<String> column;private List<Connection> connection;private String password;private String username;private String where;}@Datapublic static class Connection {private List<String> jdbcUrl;private List<String> table;}
}@EqualsAndHashCode(callSuper = true)
@Data
public class HdfsWriter extends Writer {public String getName() {return "hdfswriter";}@EqualsAndHashCode(callSuper = true)@Datapublic static class HdfsParameter extends Parameter {private List<Column> column;private String compress = "gzip";private String encoding = "UTF-8";private String defaultFS;private String fieldDelimiter = "\t";private String fileName;private String fileType = "text";private String path;private String writeMode = "append";}@Datapublic static class Column {String name;String type;}
}
3)hdfs2mysql的vo实现类
@EqualsAndHashCode(callSuper = true)
@Data
public class HdfsReader extends Reader {@Overridepublic String getName() {return "hdfsreader";}public HdfsParameter getParameter() {return new HdfsParameter();}@EqualsAndHashCode(callSuper = true)@Datapublic static class HdfsParameter extends Parameter {private List<String> column = Collections.singletonList("*");private String compress = "gzip";private String encoding = "UTF-8";private String defaultFS;private String fieldDelimiter = "\t";private String fileName;private String fileType = "text";private String path;private String nullFormat = "\\N";}
}
@EqualsAndHashCode(callSuper = true)
@Data
public class MysqlWriter extends Writer {public String getName() {return "mysqlwriter";}public MysqlParameter getParameter() {return new MysqlParameter();}@EqualsAndHashCode(callSuper = true)@Datapublic static class MysqlParameter extends Parameter {private List<String> column;private List<Connection> connection;private String password;private String username;private String writeMode = "replace";}@Datapublic static class Connection {private String jdbcUrl;private List<String> table;}
}
3、创建Repository、Service类读取数据库表结构
@Repository
public class DatabaseInfoRepository {private final JdbcTemplate jdbcTemplate;@Autowiredpublic DatabaseInfoRepository(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}// 获取所有表名public List<String> getAllTableNames() {String sql = "SHOW TABLES";return jdbcTemplate.queryForList(sql, String.class);}// 根据表名获取字段信息public List<Map<String, Object>> getTableColumns(String tableName) {String sql = "SHOW FULL COLUMNS FROM " + tableName;return jdbcTemplate.queryForList(sql);}
}
@Service
public class DatabaseInfoService {private final DatabaseInfoRepository databaseInfoRepository;@Autowiredpublic DatabaseInfoService(DatabaseInfoRepository databaseInfoRepository) {this.databaseInfoRepository = databaseInfoRepository;}public void printAllTablesAndColumns() {// 获取所有表名List<String> tableNames = databaseInfoRepository.getAllTableNames();// 遍历表名,获取并打印每个表的字段信息for (String tableName : tableNames) {System.out.println("Table: " + tableName);// 获取当前表的字段信息List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);// 遍历字段信息并打印for (Map<String, Object> column : columns) {System.out.println(" Column: " + column.get("Field") + " (Type: " + column.get("Type") + ")" + " (Comment: " + column.get("Comment") + ")");}System.out.println(); // 打印空行作为分隔}}/** 查询指定表的所有字段列表 */public List<String> getColumns(String tableName) {List<String> list = new ArrayList<>();// 获取当前表的字段信息List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);// 遍历字段信息并打印for (Map<String, Object> column : columns) {list.add(column.get("Field").toString());}return list;}/** 查询指定表的所有字段列表,封装成HdfsWriter格式 */public List<HdfsWriter.Column> getHdfsColumns(String tableName) {List<HdfsWriter.Column> list = new ArrayList<>();// 获取当前表的字段信息List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);// 遍历字段信息并打印for (Map<String, Object> column : columns) {String name = column.get("Field").toString();String typeDb = column.get("Type").toString();String type = "string";if (typeDb.equals("bigint")) {type = "bigint";} else if (typeDb.startsWith("varchar")) {type = "string";} else if (typeDb.startsWith("date") || typeDb.endsWith("timestamp")) {type = "date";}HdfsWriter.Column columnHdfs = new HdfsWriter.Column();columnHdfs.setName(name);columnHdfs.setType(type);list.add(columnHdfs);}return list;}
}
4、创建Service生成job.json文件
@Service
public class GenHdfs2mysqlJsonService {@Value("${spring.datasource.url}")private String url;@Value("${spring.datasource.password}")private String password;@Value("${spring.datasource.username}")private String username;@Value("${datax.mysql.tables}")private String tables;@Value("${datax.hdfs.defaultFS}")private String defaultFS;@Value("${datax.hdfs.path}")private String path;@Value("${datax.savepath}")private String savepath;@Autowiredprivate DatabaseInfoService databaseInfoService;/*** 生成 hdfs2mysql的job.json* @param table*/public void genHdfs2mysqlJson(String table) {DataxJobRoot root = new DataxJobRoot();Job job = new Job();root.setJob(job);Content content = new Content();HdfsReader reader = new HdfsReader();MysqlWriter writer = new MysqlWriter();content.setReader(reader);content.setWriter(writer);job.setContent(Collections.singletonList(content));HdfsReader.HdfsParameter hdfsParameter = reader.getParameter();hdfsParameter.setPath(path);hdfsParameter.setFileName(table + "_hdfs");hdfsParameter.setDefaultFS(defaultFS);MysqlWriter.MysqlParameter mysqlParameter = writer.getParameter();mysqlParameter.setPassword(password);mysqlParameter.setUsername(username);List<String> columns = databaseInfoService.getColumns(table);mysqlParameter.setColumn(columns);MysqlWriter.Connection connection = new MysqlWriter.Connection();connection.setJdbcUrl(url);connection.setTable(Collections.singletonList(table));mysqlParameter.setConnection(Collections.singletonList(connection));String jsonStr = JSONUtil.parse(root).toJSONString(2);System.out.println(jsonStr);File file = FileUtil.file(savepath, table + "_h2m.json");FileUtil.appendString(jsonStr, file, "utf-8");}/*** 生成 mysql2hdfs 的job.json* @param table*/public void genMysql2HdfsJson(String table) {DataxJobRoot root = new DataxJobRoot();Job job = new Job();root.setJob(job);Content content = new Content();HdfsWriter writer = new HdfsWriter();MysqlReader reader = new MysqlReader();content.setReader(reader);content.setWriter(writer);job.setContent(Collections.singletonList(content));HdfsWriter.HdfsParameter hdfsParameter = new HdfsWriter.HdfsParameter();writer.setParameter(hdfsParameter);hdfsParameter.setPath(path);hdfsParameter.setFileName(table + "_hdfs");hdfsParameter.setDefaultFS(defaultFS);List<HdfsWriter.Column> lstColumns = databaseInfoService.getHdfsColumns(table);hdfsParameter.setColumn(lstColumns);MysqlReader.MysqlParameter mysqlParameter = new MysqlReader.MysqlParameter();reader.setParameter(mysqlParameter);mysqlParameter.setPassword(password);mysqlParameter.setUsername(username);List<String> columns = databaseInfoService.getColumns(table);mysqlParameter.setColumn(columns);MysqlReader.Connection connection = new MysqlReader.Connection();connection.setJdbcUrl(Collections.singletonList(url));connection.setTable(Collections.singletonList(table));mysqlParameter.setConnection(Collections.singletonList(connection));String jsonStr = JSONUtil.parse(root).toJSONString(2);System.out.println(jsonStr);File file = FileUtil.file(savepath, table + "_m2h.json");FileUtil.appendString(jsonStr, file, "utf-8");}public void genAllTable() {Splitter.on(",").split(tables).forEach(this::genMysql2HdfsJson);}}
5、执行测试
调用genAllTable()方法,在配置的存储目录中自动生成每个表的job.json文件,结构示例如下:
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","name","msg","create_time","last_login_time","status"],"connection": [{"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/user?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai"],"table": ["t_user"]}],"password": "password","username": "test"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "msg","type": "string"},{"name": "create_time","type": "date"},{"name": "last_login_time","type": "date"},{"name": "status","type": "bigint"}],"compress": "gzip","encoding": "UTF-8","defaultFS": "hdfs://hadoop131:9000","fieldDelimiter": "\t","fileName": "t_user_hdfs","fileType": "text","path": "/origin_data","writeMode": "append"}}}],"setting": {"speed": {"channel": "1"}}}
}
至此,通过SpringBoot项目自动生成DataX的job.json文件,功能完成!
其中细节以及其他的reader\writer转换可以按照例子实现。
参考
- 【数仓】DataX软件安装及配置,从mysql同步到hdfs
- https://github.com/alibaba/DataX/blob/master/userGuid.md
相关文章:

【数仓】DataX 通过SpringBoot项目自动生成 job.json 文件
相关文章 【数仓】基本概念、知识普及、核心技术【数仓】数据分层概念以及相关逻辑【数仓】Hadoop软件安装及使用(集群配置)【数仓】Hadoop集群配置常用参数说明【数仓】zookeeper软件安装及集群配置【数仓】kafka软件安装及集群配置【数仓】flume软件安…...

注解式 WebSocket - 构建 群聊、单聊 系统
目录 前言 注解式 WebSocket 构建聊天系统 群聊系统(基本框架) 群聊系统(添加昵称) 单聊系统 WebSocket 作用域下无法注入 Spring Bean 对象? 考虑离线消息 前言 很久之前,咱们聊过 WebSocket 编程式…...
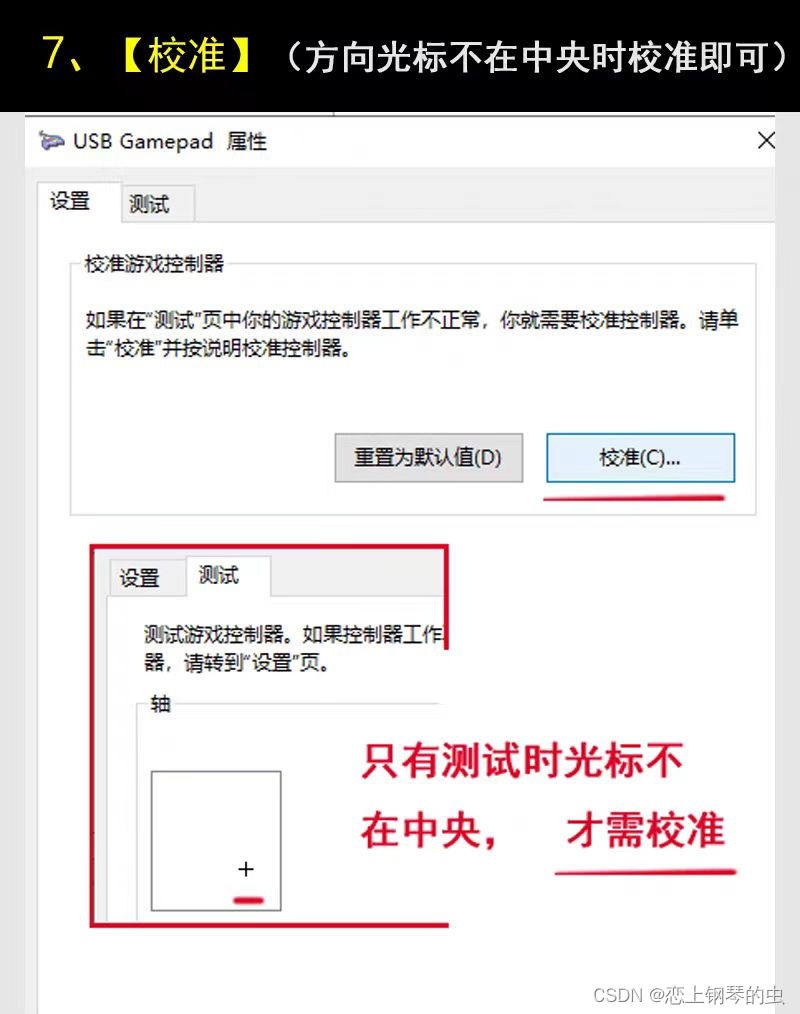
无线游戏手柄的测试(Windows11系统手柄调试方法)
实物 1、把游戏手柄的无线接收器插入到电脑usb接口中 2、【控制面板】----【查看设备和打印机】 3、【蓝牙和其它设备】--【更多设备和打印机设置】 4、鼠标右键【游戏控制器设置】 5、【属性】 6、【测试】(每个按键是否正常) 7、【校准】(…...

计算机的各种转换
一、存量容量的转换 特别注意:1 B 8 bit 转换为:1024 2(10) 括号中的数字为2的指数(即多少次方) 1KB2(10)B1024B; 括号中的数字为2的指数(即多少次方) 1MB2(10)KB1024KB2(20)B; 1GB2(10)MB1024MB2(3…...
Git分布式版本控制系统——Git常用命令(一)
一、获取Git仓库--在本地初始化仓库 执行步骤如下: 1.在任意目录下创建一个空目录(例如GitRepos)作为我们的本地仓库 2.进入这个目录中,点击右键打开Git bash窗口 3.执行命令git init 如果在当前目录中看到.git文件夹&#x…...
【Node.js】短链接
原文链接:Nodejs 第六十二章(短链接) - 掘金 (juejin.cn) 短链接是一种缩短长网址的方法,将原始的长网址转换为更短的形式。短链接的主要用途之一是在社交媒体平台进行链接分享。由于这些平台对字符数量有限制,长网址可…...

详解 Redis 在 Centos 系统上的安装
文章目录 详解 Redis 在 Centos 系统上的安装1. 使用 yum 安装 Redis 52. 创建符号链接3. 修改配置文件4. 启动和停止 Redis 详解 Redis 在 Centos 系统上的安装 1. 使用 yum 安装 Redis 5 如果是Centos8,yum 仓库中默认的 redis 版本就是5,直接 yum i…...

C语言 | Leetcode C语言题解之第17题电话号码的字母组合
题目: 题解: char phoneMap[11][5] {"\0", "\0", "abc\0", "def\0", "ghi\0", "jkl\0", "mno\0", "pqrs\0", "tuv\0", "wxyz\0"};char* digits…...

wordpress全站开发指南-面向开发者及深度用户(全中文实操)--wordpress中的著名循环
wordpress中的著名循环 首先,在深入研究任何代码之前,我们首先要确保我们有不止一篇博客文章可以工作。因此,我们要去自己的wordpress站点,从侧边栏单机Posts(文章),进行创建 在执行代码的时候会优先执行single.php如…...
libVLC 提取视频帧使用QGraphicsView渲染
在前面章节中,我们讲解了如何使用QWidget渲染每一帧视频数据,这种方法对 CPU 负荷较高。 libVLC 提取视频帧使用QWidget渲染-CSDN博客 后面又讲解了使用OpenGL渲染每一帧视频数据,使用 OpenGL去绘制,利用 GPU 减轻 CPU 计算负荷…...

大厂Java笔试题之判断字母大小写
/*** 题目:如果一个由字母组成的字符串,首字母是大写,那么就统计该字符串中大写字母的数量,并输出该字符串中所有的大写字母。否则,就输出* 该字符串不是首字母大写*/ public class Demo2 {public static void main(St…...
场景文本检测识别学习 day02(AlexNet论文阅读、ResNet论文精读)
怎么读论文 在第一遍阅读的时候,只需要看题目,摘要和结论,先看题目是不是跟我的方向有关,看摘要是不是用到了我感兴趣的方法,看结论他是怎么解决摘要中提出的问题,或者怎么实现摘要中的方法,然…...

4.9日总结
1.MySQL概述 1.数据库基本概念:存储数据的仓库,数据是有组织的进行存储 2.数据库管理系统:操纵和管理数据库的大型软件 3.SQL:操作关系型数据库的编程语言,定义了一套操作型数据库统一标准 2.MySQL数据库 关系型数…...

python第四次作业
1、找出10000以内能被5或6整除,但不能被两者同时整除的数(函数) def func():for i in range(10001):if (i % 5 0 or i % 6 0) and i % 30 ! 0:print(i,end " ")func() 2、写一个方法,计算列表所有偶数下标元素的…...

工业通信原理——Modbus-TCP通信规约定义
工业通信原理——Modbus-TCP通信规约定义 前言 Modbus TCP是一种基于TCP/IP协议的通信规约,用于在客户机和服务器之间进行数据通信。 Modbus-TCP通信规约定义 Modbus TCP通信规约的定义,包括客户机请求和服务器响应的基本流程: 连接建立…...
Vue - 4( 8000 字 Vue 入门级教程)
一: Vue 初阶 1.1 关于不同版本的 Vue Vue.js 有不同版本,如 vue.js 与 vue.runtime.xxx.js,这些版本主要针对不同的使用场景和需求进行了优化,区别主要体现在以下几个方面: 完整版 vs 运行时版: vue.js&…...

5.118 BCC工具之xfsslower.py解读
一,工具简介 xfsslower显示了XFS的读取、写入、打开和fsync操作,这些操作慢于一个阈值。 二,代码示例 #!/usr/bin/env pythonfrom __future__ import print_function from bcc import BPF import argparse from time import strftime# arguments examples = ""…...

Spark编程基础
一、RDD入门 1.RDD是什么? RDD是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合,即弹性分布式数据集。 2.RDD的三种创建方式 第一种是将程序中已存在的集合(如集合、列表、数组&a…...

React 状态管理:高效处理数组数据的5种方法
1.原因 为什么在 React 中,状态(state)如果是数组类型,需要单独处理?主要有以下几个原因: 不可变性(Immutability): React 中的状态是不可变的,意味着我们不能直接修改状态,而是要创建一个新的状态对象。对于数组来说,直接修改数组元素是不符合 React 的设计原则的…...

SSH和交换机端口安全概述
交换机的安全是一个很重要的问题,因为它可能会遭受到一些恶意的攻击,例如MAC泛洪攻击、DHCP欺骗和耗竭攻击、中间人攻击、CDP 攻击和Telnet DoS 攻击等,为了防止交换机被攻击者探测或者控制,必须采取相应的措施来确保交换机的安全…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

从SD卡初始化到读写文件:一个完整嵌入式项目中的SDIO驱动避坑实践
从SD卡初始化到读写文件:嵌入式SDIO驱动实战全解析 在嵌入式系统开发中,SD卡因其高容量、低成本和便携性成为数据存储的首选方案。然而,看似简单的SD卡接口背后隐藏着复杂的初始化协议和时序要求。许多工程师在项目初期都会遇到SD卡无法识别、…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案
Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 你是否曾在Sketchfab上发现完美的3D…...

Aurora框架解析:一体化高性能云原生开发平台的设计与实践
1. 项目概述与核心价值如果你在开源社区里混迹过一段时间,尤其是对现代化、高性能的Web开发框架感兴趣,那么“Aurora”这个名字你大概率不会陌生。它不是一个简单的库或者工具,而是一个由社区驱动的、旨在构建下一代企业级应用开发平台的雄心…...

Mantic.sh:Bash脚本实现的终端命令自动化与效率提升工具
1. 项目概述:一个为开发者打造的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你肯定对效率工具有着近乎偏执的追求。从cd到ls,从grep到awk,我们依赖这些…...

符号链接批量管理工具 linko:声明式配置与自动化实践
1. 项目概述与核心价值最近在折腾一些自动化脚本和工具链,发现一个挺有意思的仓库:monsterxx03/linko。乍一看这个名字,你可能会有点懵,这到底是干嘛的?是链接管理工具,还是某种网络代理的客户端࿱…...
)
设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测)
更多请点击: https://intelliparadigm.com 第一章:设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测) Midjourney v6.1…...

从单一AI到智能体集群:构建模块化AI协作系统的核心原理与实践
1. 项目概述:当AI学会“开会”,一个开源智能体集群的诞生最近在GitHub上看到一个挺有意思的项目,叫daveshap/OpenAI_Agent_Swarm。光看名字,你可能会觉得这又是一个调用OpenAI API的简单封装库。但如果你点进去,花上十…...

从零打造专业GitHub个人资料页:Markdown与动态集成实战指南
1. 项目概述与核心价值 在技术圈子里混了十几年,我越来越觉得,一个开发者的“数字门面”和代码能力同等重要。这个门面,很多时候就是你的GitHub主页。早些年,大家的GitHub个人页面就是个简单的仓库列表,加上一些贡献图…...