【数据结构】考研真题攻克与重点知识点剖析 - 第 7 篇:查找
前言
- 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。
- 此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术有限,最终数据清洗结果不够理想,相关CSDN文章便没有发出。
(考研真题待更新)
欢迎订阅专栏:408直通车
请注意,本文中的部分内容来自网络搜集和个人实践,如有任何错误,请随时向我们提出批评和指正。本文仅供学习和交流使用,不涉及任何商业目的。如果因本文内容引发版权或侵权问题,请通过私信告知我们,我们将立即予以删除。
文章目录
- 前言
- 第七章 查找
- 查找的基本概念
- 在哪里找?
- 什么是查找?
- 查找表咋么分类?
- 如何评价查找算法?
- 查找过程中研究什么?
- 线性表的查找
- 顺序查找(线性查找)
- 折半查找(二分/对分查找)
- 小结
- 分块查找
- 小结
- 比较
- 树表的查找
- 当表插入、删除操作频繁时,为维护表的有序性,需要移动很多记录,改用动态查找表(几种特殊的树)
- 二叉排序树 BST
- 小结
- 平衡二叉树 AVL
- 练习
- 小结
- 删除
- AVL树删除操作―—例1
- AVL树删除操作―—例2
- AVL树删除操作―—例3
- AVL树删除操作―—例4
- AVL树删除操作―—例5
- AVL树删除操作―—例6
- 小结
- 红黑树
- B树
- 小结
- 小结
- B+树
- B树与B+树的异同
- 散列表的查找
- 散列表概述
- 散列函数的构造方法
- 冲突解决的方法
- 散列的查找及性能分析
第七章 查找
查找的基本概念
在哪里找?
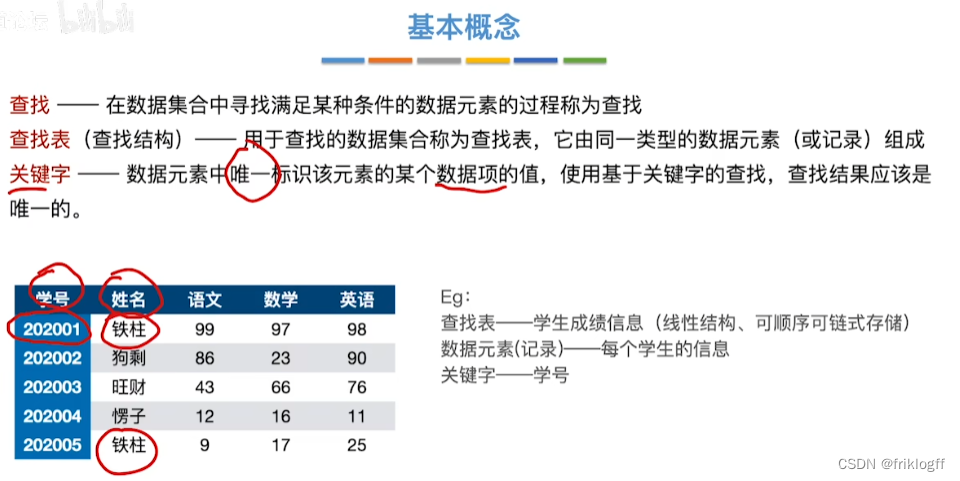
- 查找表:是由同一类型的数据元素(或记录)构成的集合(数据元素之间关系松散,应用灵活方便)
什么是查找?
-
查找:根据给定值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)(查找成功/查找不成功)

-
关键字
-
用来标识一个数据元素(或记录)的某个数据项的值
-
主关键字:可唯一标识一个记录的关键字
-
次关键字:用以识别若干记录的关键字
-
查找表咋么分类?

-
静态查找表:仅作查询(检索)操作的查找表
-
查询:某个“特定”数据元素是否在查找表中
-
检索:某个“特定”数据元素的各种属性
-
-
动态查找表:作插入和删除操作的查找表
-
在查找表中查找,若查询结果不在查找表中,则插入一个数据元素
-
从查找表中删除其查询结果在表中的某个数据元素
-
如何评价查找算法?
-
平均查找长度ASL

-

- n:记录个数;pi:查找第i个记录的概率(通常为1/n);ci:找到第i个记录所需的比较次数


- n:记录个数;pi:查找第i个记录的概率(通常为1/n);ci:找到第i个记录所需的比较次数
-
查找过程中研究什么?
- 研究查找表的各种组织方法及其查找过程的实施(构造查找表时,人为添加约束关系,并设计与之匹配的查找方法,从而提高查找表的查询效率)

线性表的查找
顺序查找(线性查找)
-
概念
-
顺序查找顺序表或线性链表表示的静态查找表
- 表内元素无序

- 表内元素无序
-
-
过程
-
从线性表的一端开始,逐个检查关键字是否满足条件
-
若满足则查找成功,返回元素位置
- 若已经查到表的另一端,且还没有找到符合条件的元素,则返回查找失败的信息

- 若已经查到表的另一端,且还没有找到符合条件的元素,则返回查找失败的信息
-
-
优化
-
哨兵
- 将待查关键字存入表头,从后向前比较,可免去查找过程中每步都要检查是否查找完毕,效率可提高一倍

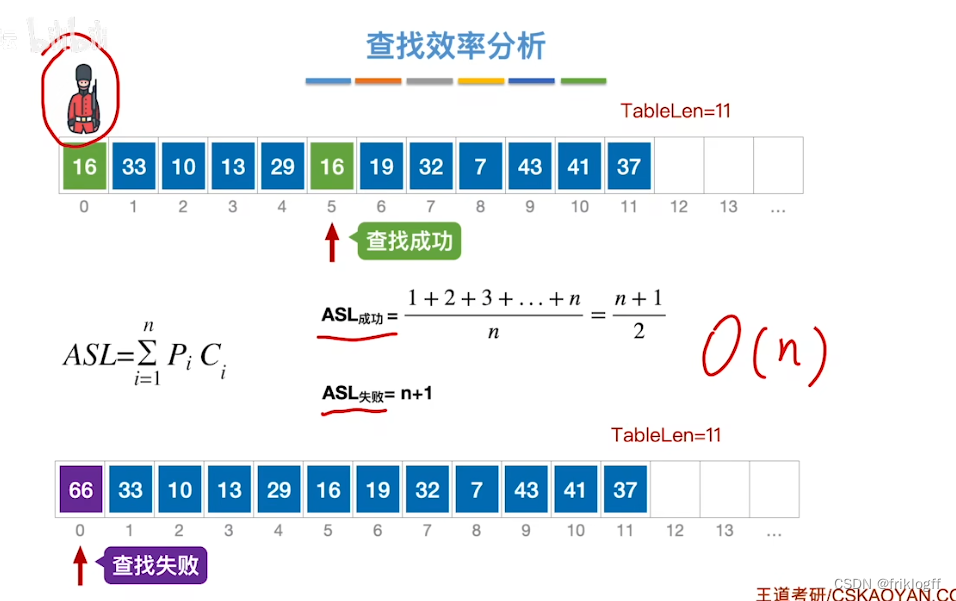
- 将待查关键字存入表头,从后向前比较,可免去查找过程中每步都要检查是否查找完毕,效率可提高一倍
-
按查找频率高低存储
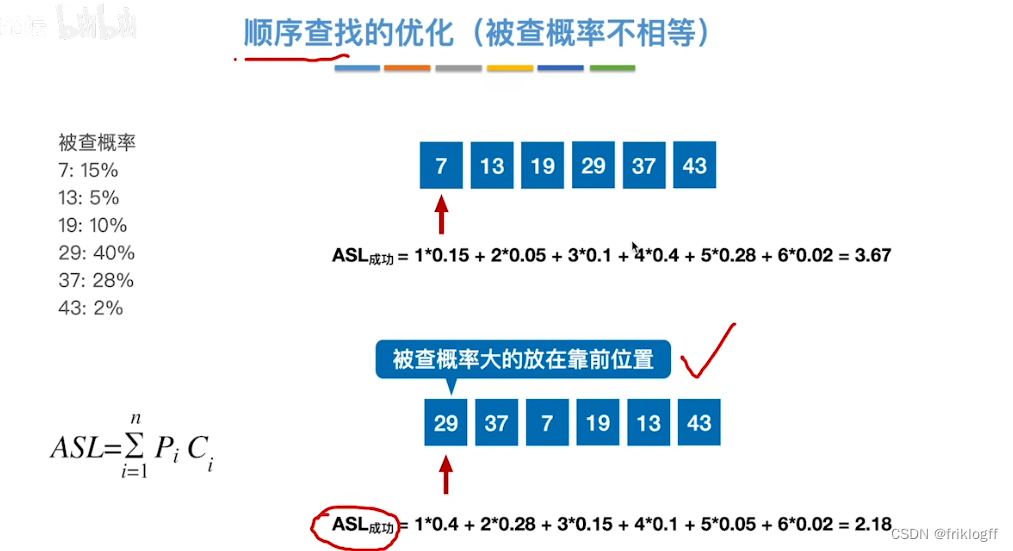
- 若无法测定,按概率动态调整记录顺序(访问频度域)
-
顺序查找的优化(对有序表)


-
-
平均查找长度
-
成功(Pi=1/n)

-
失败(Pi=1/n)

-

折半查找(二分/对分查找)

-
概念
-
每次将待查记录所在区间缩小一半
- 有序的顺序表
-
-


-
在[low, high]之间找目标关键字,将给定key值与表中中间位置mid比较,若相等则查找成功
-
不等,则根据mid所指元素与key值大小比较,调整low或high,缩小边界范围,不断重复
-
若low>high,则查找失败
-
-
判定树
-

-
圆形结点为记录,值为关键字;叶结点表示查找不成功的情况

-
特性
-
判定树是平衡的二叉排序树(只有最下面一层不满)
-
若查找表有n个关键字,则失败结点有n+1个
-
树高h = ⌈log2(n+1)⌉(不包含失败结点)

-
-
查找成功平均长度
- ASL <= h

-
时间复杂度:O(log2n)
-
-
-
仅适合于顺序存储结构,不适合于链式存储结构,且关键字有序




小结





分块查找
-
概念
- 又称索引顺序查找,吸取了顺序查找和折半查找的优点,既有动态结构(若为动态查找表,优先使用链式存储),又适用于快速查找
-
过程
-

-
将查找表分为若干子块,块内的元素可以无序,但块间有序,一个块的最大关键字小于下一个块中所有记录的关键字
-
再建立一个索引表,索引表中的每个元素含有各块的最大关键字和各块中第一个元素的地址,索引表按关键字排序
-
查找过程:在索引表中确定记录所在块,在块内顺序查找

-
-



-
查找成功长度
-
将长度为n的查找表均匀地分为b块,每块有s个记录
- ASL = Lb(对索引表查找的ASL) + Ls(对块内查找的ASL)
-
若块内和索引表都用顺序查找,则按顺序查找公式
-
ASL = Lb + Ls = (b+1)/2 + (s+1)/2
- 可根据b和s的关系化简,若用折半查找,则用折半的公式替换h = ⌈log2(n+1)⌉



- 可根据b和s的关系化简,若用折半查找,则用折半的公式替换h = ⌈log2(n+1)⌉
-
-
小结


比较
以下是按照您的要求创建的四行四列的Markdown表格:
| 查找 | 顺序查找 | 折半查找 | 分块查找 |
|---|---|---|---|
| ASL | 最大 | 最小 | 中间 |
| 表结构 | 有序/无序表 | 有序表 | 分块有序 |
| 存储结构 | 顺序/线性链表 | 顺序表 | 顺序/线性链表 |
树表的查找
当表插入、删除操作频繁时,为维护表的有序性,需要移动很多记录,改用动态查找表(几种特殊的树)
二叉排序树 BST
-
二叉排序树的定义

-
特性
-
左子树结点值(若左子树非空) < 根结点值 < 右子树结点值(若右子树非空)
-
其左右子树本树又各是一棵二叉排序树
-
-
性质
- 中序遍历非空的二叉排序树所得到的数据元素序列是一个按关键字排序的递增有序序列
-
-
二叉排序树的查找


-
从根结点开始,沿某分支逐层向下比较的过程,若二叉排序树非空,先将给定值与根结点关键字比较
-
若相等则成功
-
若小于根结点关键字,则在左子树上查找;若大于根结点关键字,则在右子树上查找(可递归实现)
-
-
-
二叉排序树的插入

-
过程
-
若关键字小于根结点值,插入左子树
-
若关键字大于根结点值,插入右子树
-
-
生成


-
按关键字序列依次插入
-
不同插入次序的序列生成不同形态的二叉排序树
-
-
-
二叉排序树的删除
-
若被删除的结点是叶结点,直接删

-
若结点只有一棵左子树或右子树,让子树成为该结点的父结点的子树,代替该结点

-
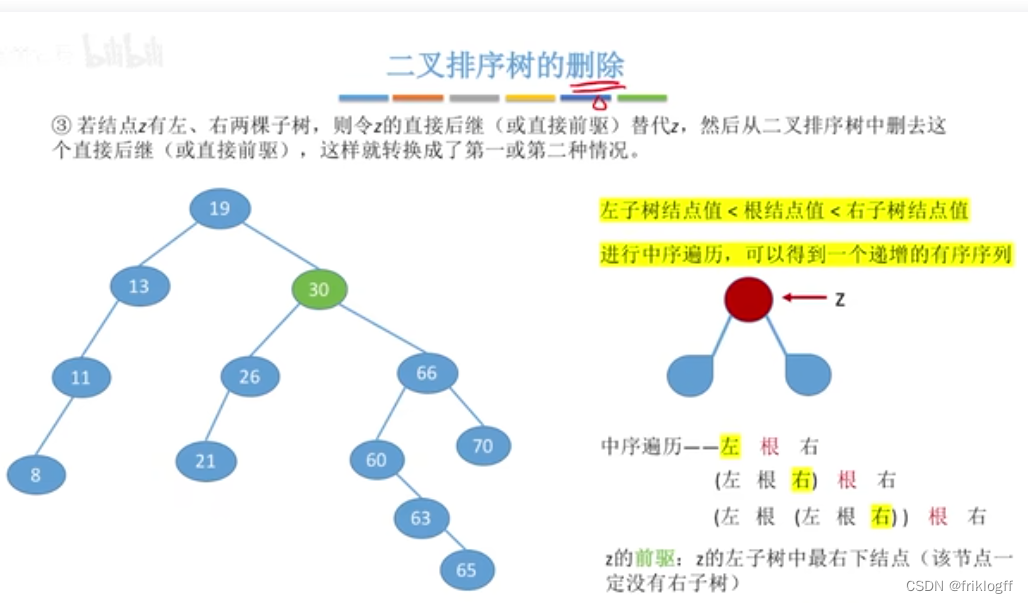
若结点有左、右两棵子树
-
以其中序前驱值替换之(值替换),然后再删除该前驱结点(前驱是左子树中最大的结点)
-
也可以用其后继替换之,然后再删除后继结点(后继是右子树中最小的结点)
-
-
-
二叉排序树的查找效率分析
-


-
查找成功的平均查找长度ASL = (11 + 22 + 3*4 + 4 * 1) / 8 = 2.625
-
查找失败的平均查找长度ASL = (37 + 42) / 9 =3.22
-
查找效率主要取决于树的高度
-
若二叉排序树为平衡二叉树,平均执行时间为O(log2n)
-
若二叉排序树只有左/右孩子单支树,平均查找时间为O(n)
-
-
-
小结


平衡二叉树 AVL



-
概念
-
特性
-
是二叉排序树,具有二叉排序树性质
-
左子树与右子树的高度之差的绝对值小于等于1
-
左子树和右子树也是平衡二叉排序树
-
-
平衡因子=结点左子树的高度-结点右子树的高度
- 故平衡二叉树中,平衡因子只能是 -1、0,1
-
-
平衡调整

-
当平衡二叉树插入(删除)一个结点时
-
首先检查其插入路径上的结点是否因此次操作导致不平衡
-
若不止一个失衡结点时,从最小失衡子树的根结点开始平衡,直到所有结点都满足平衡二叉树特性
-
-
LL 右单旋

-
RR 左单旋

-
LR 先左后右双旋转


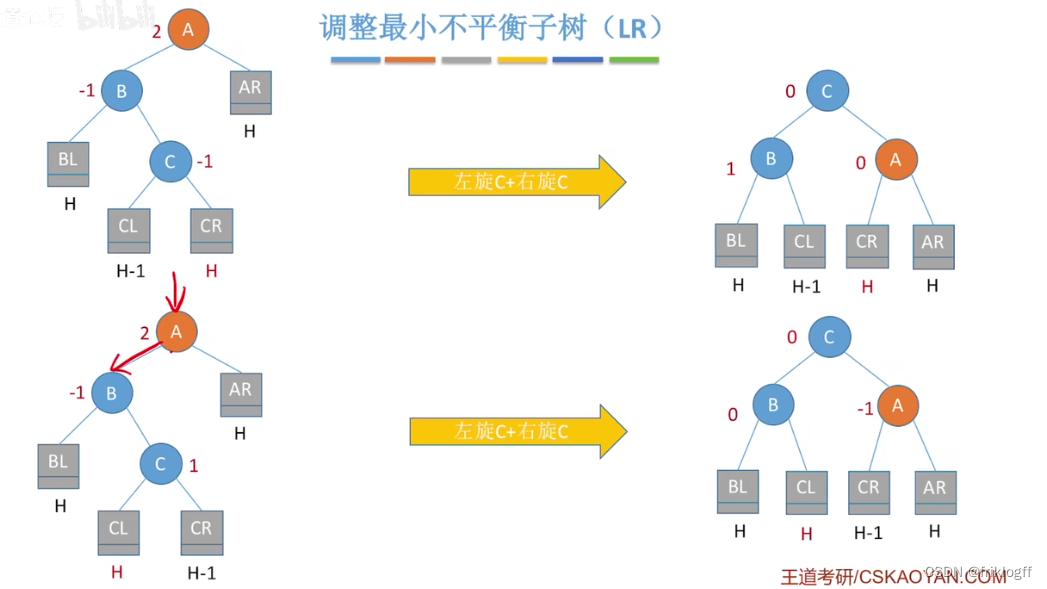
-
RL 先右后左双旋转
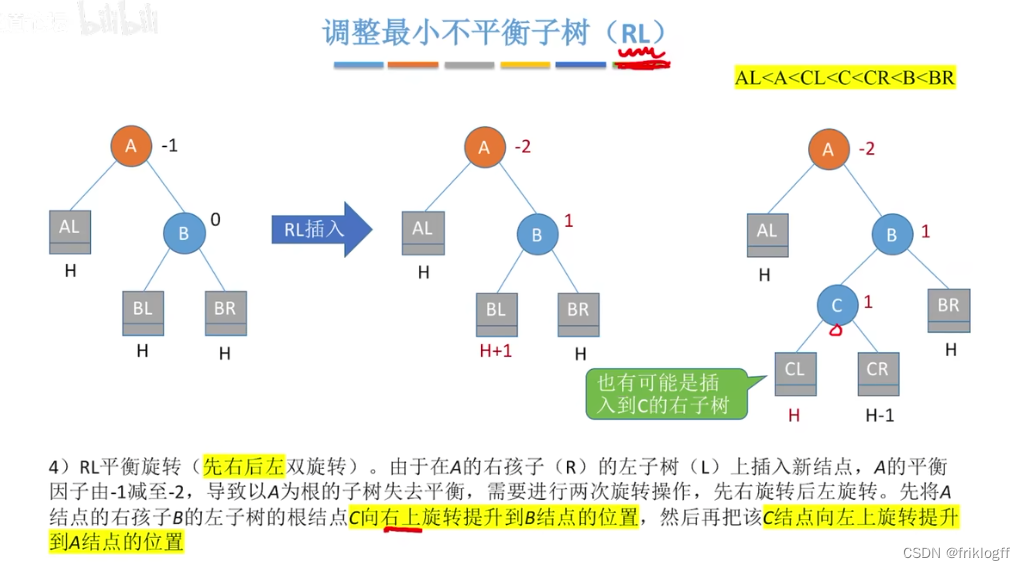


-

-
如果记不住王道四种情况,遵循以下两个原则,代入到前四个情况理解一下,可能就懂了
-
原则一:降低高度
- 原则二:保持二叉排序树性质
-
-
-
调整最小不平衡子树






- 平均查找长度,O(log2n)

练习




小结

删除



AVL树删除操作―—例1


AVL树删除操作―—例2



AVL树删除操作―—例3



AVL树删除操作―—例4







AVL树删除操作―—例5






AVL树删除操作―—例6



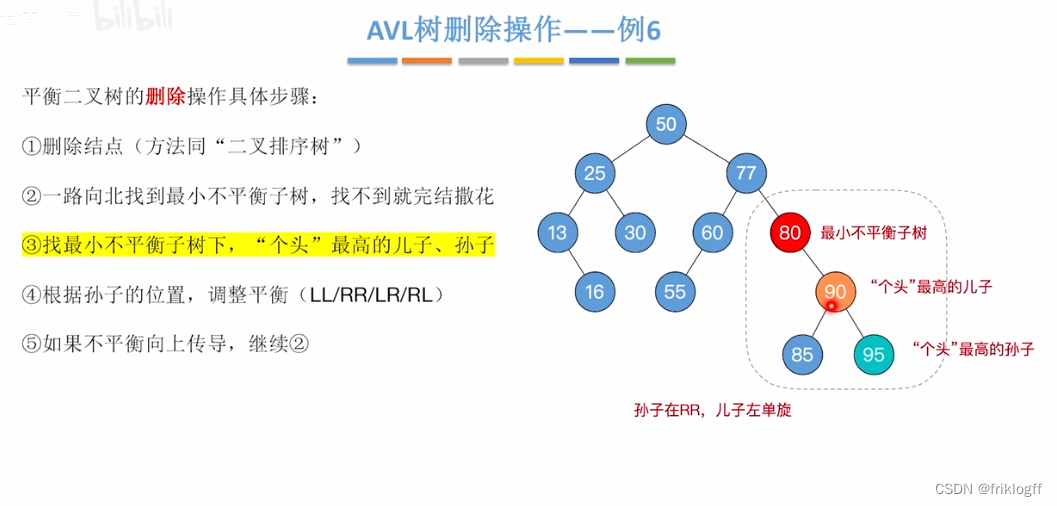







小结

红黑树


-
红黑树的概念
-


-
定义
-
红黑树是二叉排序树(左子树结点值 < 根结点值 < 右子树结点值)
-
根结点是黑色的(每个结点不是黑,就是红)
-
叶结点(外部结点/NULL结点/失败结点)均是黑色
-
不存在两个相邻的红结点(即红结点的父结点和孩子结点均是黑色)
-
对每个结点,从该结点到任一叶结点的简单路径上,所含黑结点的数目相同
-
-
口诀
- 左根右,根叶黑;不红红,黑路同
-
性质
-
根到叶结点最长路径不大于最短路径(全黑)2倍
-
n个结点高度h<=2log2(n+1)
-
-
黑高bh


-
从某结点出发(不包含该结点)到达任一空叶结点路径上黑色结点数
-
结论:若根结点黑高为h,内部结点数(关键字)最少有2^h-1个
-
-
-
-
红黑树的插入(删除)























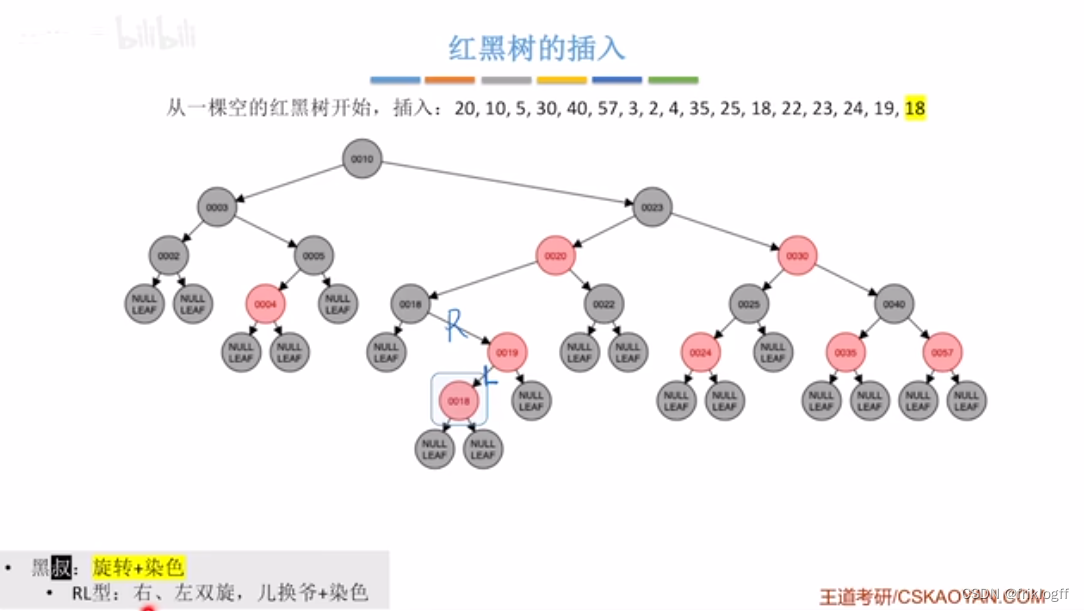






https://www.cs.usfca.edu/~galles/visualization/RedBlack.html



- 红黑树的性能分析
B树






-
概述
-
概念
- 又称多路平衡查找树,B树中所有结点的孩子个数的最大值称为B树的阶,用m表示
-



-
特点
-
树中每个结点至多有m棵子树,至多有m-1个关键字
-
关键字个数:⌈m/2⌉-1<=n<=m-1(根结点:1<=n<=m-1)
-
子树个数:⌈m/2⌉ <= n <= m(根结点:2 <= n <= m)
-
所有的叶结点都出现在同一层次上,且不带信息
-
B树是所有结点的平衡因子均为0的多路平衡查找树
-
-
性质
-
结点的孩子个数 = 该结点关键字个数 + 1
-
对任一结点,其所有子树高度都相同
-
关键字的值:子树0<关键字1<子树1<关键字2<子树2<…(类比二叉排序树 左<中<右)
-
-
-
B树的高度(磁盘存取次数)
-



- 对任意一颗包含n个关键字、高度为h、阶数为m的B树- h > logm (n+1)
小结

-
B树的操作
-
查找
-
在B树上查找到某个结点后,先在有序表中进行查找
-
若找到则查找成功,否则按照对应的指针信息到所指的子树中去查找
-
查找到叶结点时(对应指针为空指针),则说明树中没有对应的关键字,查找失败
-
-
插入
-




-










-
定位:利用查找算法,找出插入该关键字的最底层中的某个非叶结点
-
在插入后,若结点关键字个数大于等于m,则从中间位置(⌈m/2⌉)将关键字分为两部分
左部分留在原结点、右部分放到新的结点、中间位置(⌈m/2⌉)的结点插入原结点的父结点
-
-
-
-
删除
-
非终端结点关键字



- 用其直接前驱(左子树“最右下”元素)或直接后继(右子树“最左下”元素)替代其位置,化为对“终端结点”的删除
-
终端结点关键字

-
删除后结点关键字个数未低于下限,无需处理
-
低于下限
-
右兄弟够借,则用当前结点的后继、后继的后继依次顶替空缺


-
左兄弟够借,则用当前结点的前驱、前驱的前驱依次顶替空缺


-
左右兄弟都不够借,需要将父结点内关键字、左右兄弟进行合并,合并后导致父结点关键字数量-1,可能需要继续合并




-
-
-
-
小结

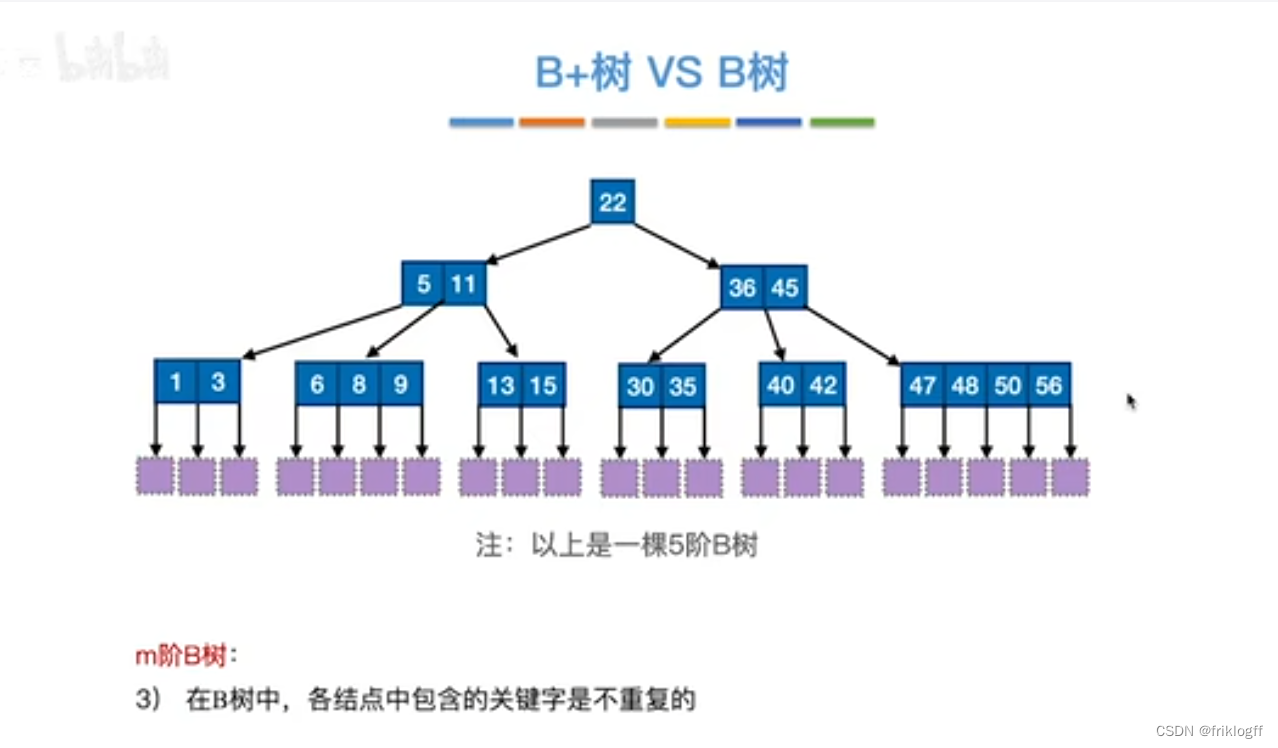
B+树
-







-
m阶B+树
-
每个分支结点最多m棵子树


-
非叶根结点最少有2棵子树,其他每个结点分支:⌈m/2⌉ <= n <= m


-
结点的子树与关键字个数相等

-
所有叶结点包含全部关键字及指向相应记录的指针,叶结点中将关键字按大小顺序排序,并且相邻叶结点按大小顺序相互链接起来
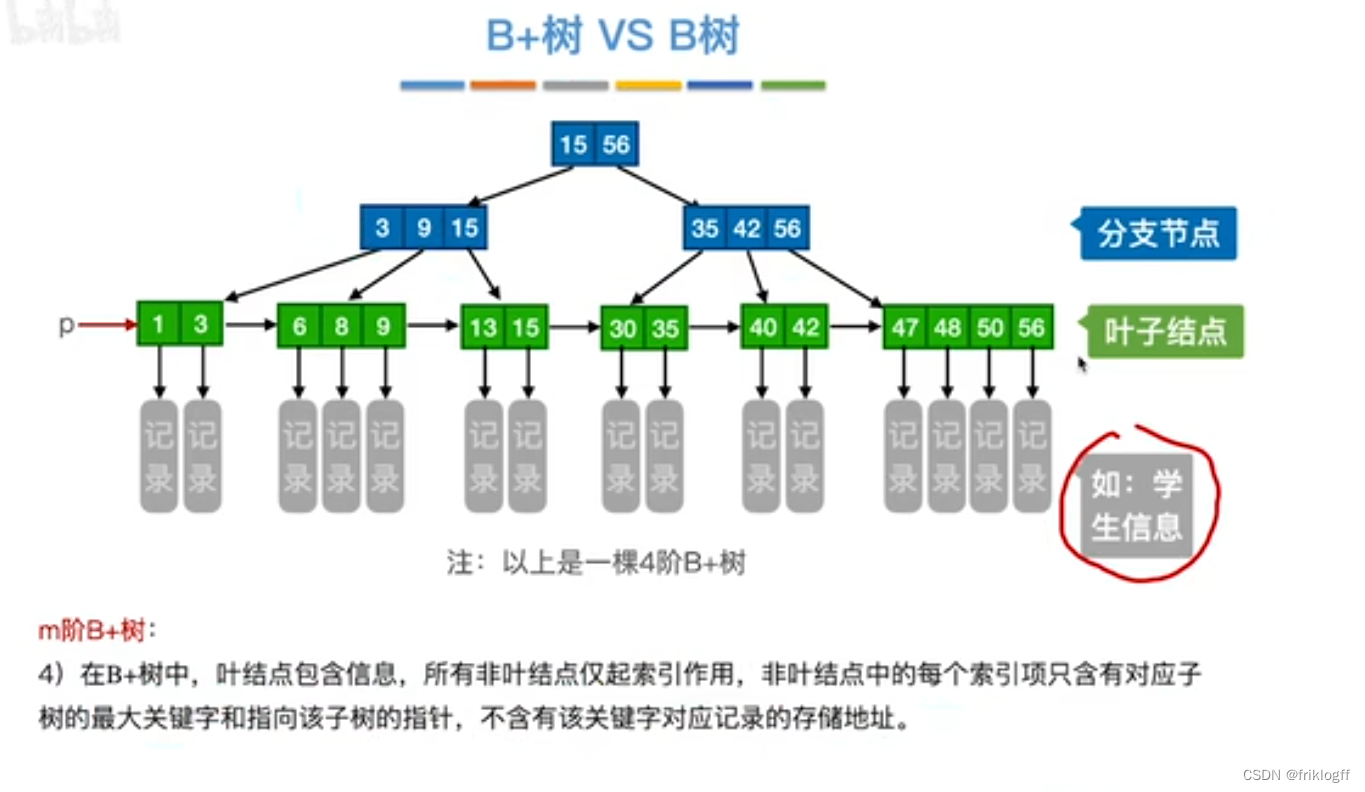

-
所有分支结点(可视为索引的索引)中仅包含它的各个结点(即下一级的索引块)中关键字的最大值及指向其子结点的指针


-
-
B树与B+树的异同
-
差异
-
m阶B树
- 关键字个数:⌈m/2⌉-1<=n<=m-1(根结点:1<=n<=m-1)
- n个关键字,n+1棵子树
- 结点包含记录信息
- 不支持顺序查找
查找成功可能在任何一层,速度不稳定
-
m阶B+树
-
关键字个数:⌈m/2⌉ <= n <= m(根结点:1 <= n <= m)
-
n个关键字,n棵子树
-
仅最下层叶子结点包含记录信息(访问磁盘次数少)
-
支持顺序查找
成功失败都在最后一层,速度稳定
-
-
-
相同
- 任何结点子树一样高(绝对平衡)

散列表的查找











散列表概述
-
基本思想
-
记录的存储位置与关键字之间存在对应关系
- 对应关系------hash函数(散列函数)
-
-
概念
-
散列方法
-
选取某个函数,依该函数按关键字计算元素的存储位置,并按此存放
-
查找时,由同一个函数对给定值k计算地址,将k与地址单元中元素关键码进行比较,确定查找是否成功
-
-
散列函数
- 把查找表中的关键字映射成该关键字对应的地址的函数,记为Hash(key) = Addr(这里的地址可以是数组下标,索引或内存地址等)
-
散列表
- 根据关键字而直接进行访问的数据结构,散列表建立了关键字和存储地址之间的一种直接映射关系
-
冲突
- 不同的关键码映射到同一个散列地址 key1 != key2,但H(key1) = H(key2)
-
同义词
- 具有相同函数值的多个关键字
-
-
性能
- 查找效率高,可达到 O(1) 、空间效率低
-
使用散列表要解决好两个问题
-
构造好散列函数
-
所选函数尽可能简单,提高转换速度
-
所选函数对关键码计算出的地址,应在散列地址集中致均匀分布,以减少空间浪费
-
-
制定一个好的解决冲突的方案
-
散列函数的构造方法
-
考虑的因素
- 执行速度(即计算散列函数所需时间)、关键字的长度、散列表的大小、关键字的分布情况、查找频率
-
要求
-
n个数据仅占用n个地址,虽然散列查找是以空间换时间,但希望散列的地址空间尽量少
-
无论用什么方法存储,目的都是尽量均匀地存放元素,以避免冲突
-
-
散列函数
-
除留余数法



-
概述
- 假定散列表表长为m,取一个不大于m但最接近或等于m的质数p,利用以下公式把关键字转换为散列地址
-
散列函数
- H(key) = key % p
-
特点
- 关键在p的选取,使得每个关键字通过该函数转换后等概率映射到散列空间的任一地址,减少冲突
-
-
直接定址法

-
概述
- 直接取关键字的某个线性函数值为散列函数
-
散列函数
- H(key) = key 或 H(key) = a*key + b,a和b为常数
-
特点
-
计算最简单,不会产生冲突
- 适合关键字分布连续的情况(若不连续,则存储空间浪费很多)
-
-
-
数字分析法

-
概述
- 设关键字是r进制数,而r个数码在各位上出现的频率不一定相同,可能在某些位上分布均匀,某种数码出现机会均等。选取数码分布较为均匀的若干位作为散列地址
-
特点
- 适合于已知的关键字集合,若更换了关键字,则需要重新构造新的散列函数
-
-
平方取中法

-
概述
- 取关键字的平方值的中间几位作为散列地址
-
特点
- 适合于关键字的每位取值都不够均匀或均小于散列地址所需位数
-
-

冲突解决的方法
-
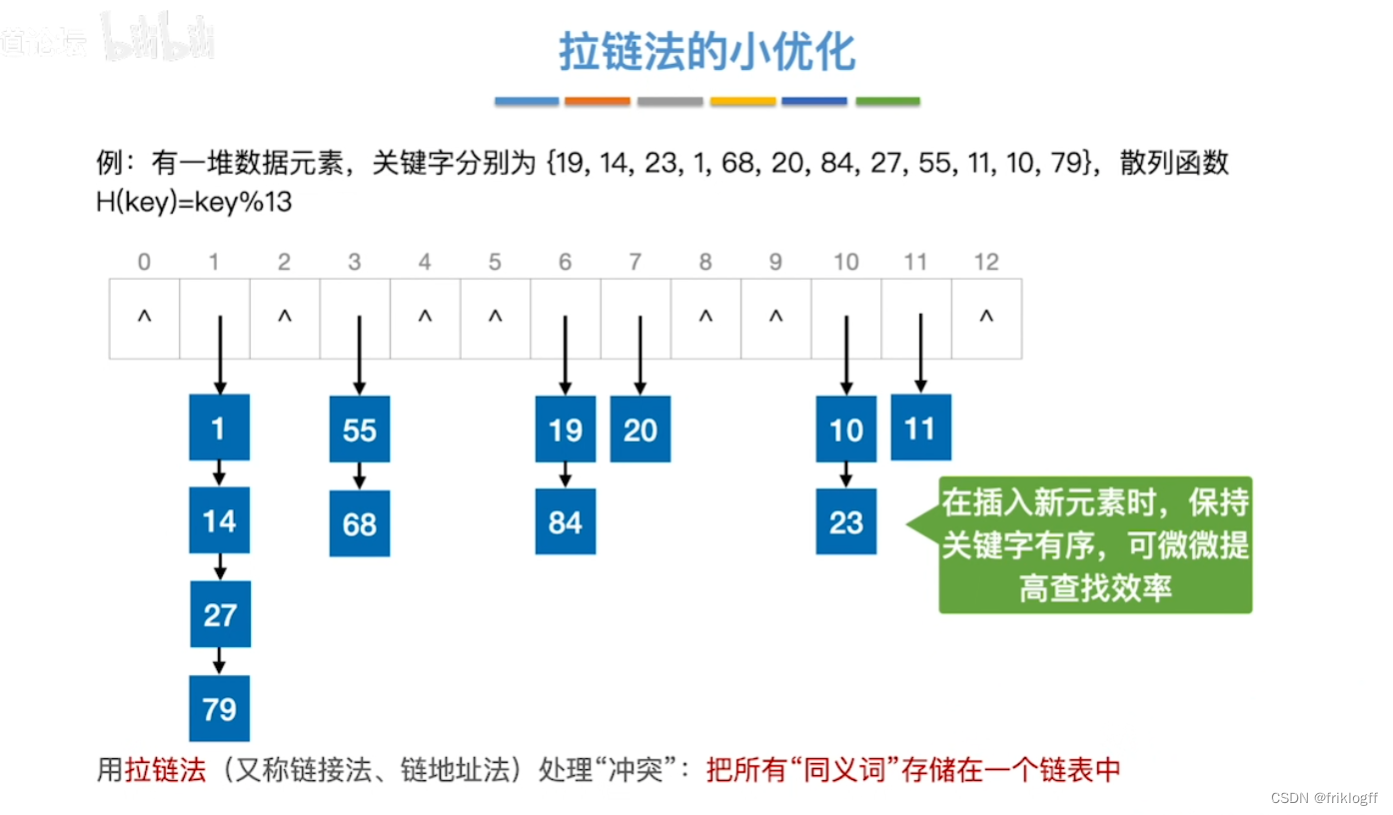
拉链法
-
概述
-


- 为了避免冲突,把所有的同义词存储在一个线性链表(由散列地址唯一标识)中
-
-
优点
-
非同义词不会冲突,无“聚集”现象
-
链表上结点空间动态申请,更适合于表长不确定的情况(经常插入删除)
-
-
-
开放定址法

-
概念
- 指可存放新表项的空闲地址,即向它的同义词开发,又向其非同义词开发(删除元素时,用标记表示)
-
数学递推公式
-
Hi = (H(key) + di) % m
- di即为增量序列
-
增量d的取值
-
线性探测法









-
di = 0, 1, 2, … , m-1
- 发生冲突时,顺序表查看表中下一个元素,直到有空闲单元
-
会出现聚集现象,降低查询效率










-
-
平方探测法

-
di = 0² , +1² , -1² , +2² , -2² , … , +k² , -k²
-
不会出现聚集现象,不能探测所有单元,但至少能探测一半

-
-
伪随机序列法

- di = 伪随机数序列
-
-
-

-
再散列法

-
公式变为:Hi = (H(key) + i×Hash2(key)) % m
- di=Hash2(key),i为冲突次数,作为公式中再散列系数,别漏了
-
散列的查找及性能分析
-
查找过程
-
检测由散列函数形成的地址上是否有记录,若无记录则失败;
若有记录比较关键字值,若相等则查找成功,否则散列函数更新增量值,重复执行 -
补充:求查找失败的ASL时
- 失败位置也计数;若H(key) = k%7,则失败要算0,1,2,3,4,5,6
-
-
散列表查找效率取决于三个因素
-
散列函数
-
处理冲突的方法
-
装填因子
-
装填因子为描述一个表装满程度,越大越容易冲突
-
装填因子α = 表中记录数n/散列表长度m
-

- 平均查找长度依赖于散列表的装填因子
-
-
-
补充
-
散列表技术具有很好的平均性能,优于一些传统的技术
-
链地址法优于开放定址法
-
除留余数法作散列函数优于其它类型函数
-

相关文章:
【数据结构】考研真题攻克与重点知识点剖析 - 第 7 篇:查找
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...

【数仓】DataX 通过SpringBoot项目自动生成 job.json 文件
相关文章 【数仓】基本概念、知识普及、核心技术【数仓】数据分层概念以及相关逻辑【数仓】Hadoop软件安装及使用(集群配置)【数仓】Hadoop集群配置常用参数说明【数仓】zookeeper软件安装及集群配置【数仓】kafka软件安装及集群配置【数仓】flume软件安…...

注解式 WebSocket - 构建 群聊、单聊 系统
目录 前言 注解式 WebSocket 构建聊天系统 群聊系统(基本框架) 群聊系统(添加昵称) 单聊系统 WebSocket 作用域下无法注入 Spring Bean 对象? 考虑离线消息 前言 很久之前,咱们聊过 WebSocket 编程式…...
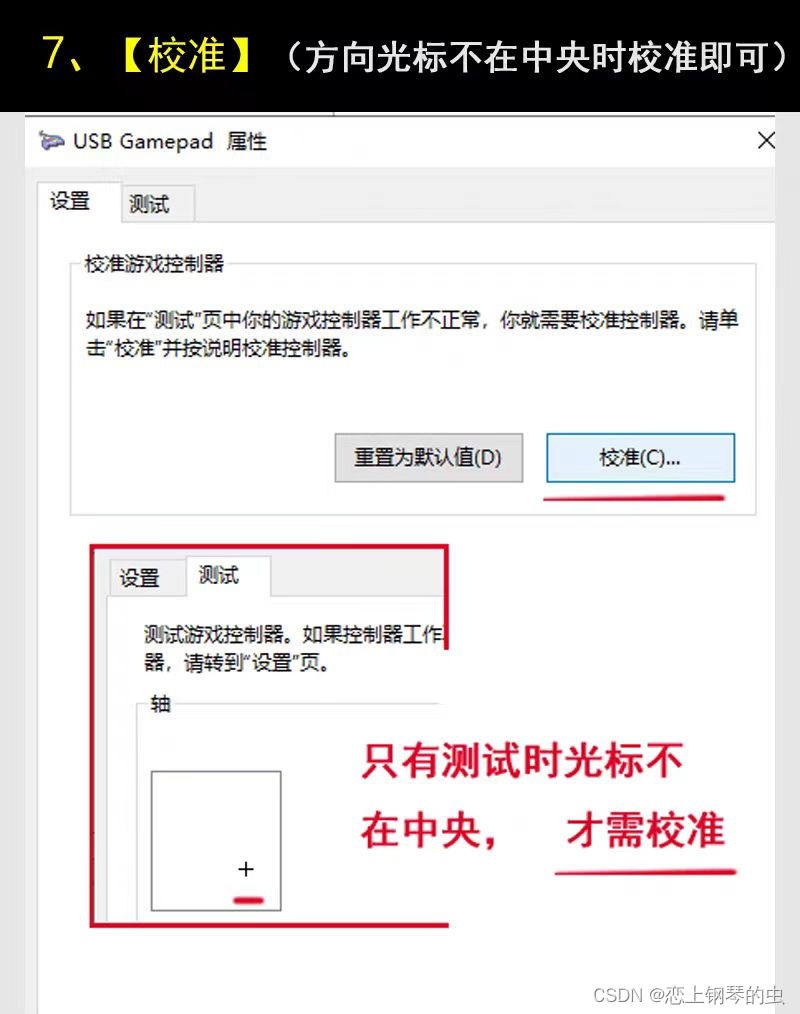
无线游戏手柄的测试(Windows11系统手柄调试方法)
实物 1、把游戏手柄的无线接收器插入到电脑usb接口中 2、【控制面板】----【查看设备和打印机】 3、【蓝牙和其它设备】--【更多设备和打印机设置】 4、鼠标右键【游戏控制器设置】 5、【属性】 6、【测试】(每个按键是否正常) 7、【校准】(…...

计算机的各种转换
一、存量容量的转换 特别注意:1 B 8 bit 转换为:1024 2(10) 括号中的数字为2的指数(即多少次方) 1KB2(10)B1024B; 括号中的数字为2的指数(即多少次方) 1MB2(10)KB1024KB2(20)B; 1GB2(10)MB1024MB2(3…...
Git分布式版本控制系统——Git常用命令(一)
一、获取Git仓库--在本地初始化仓库 执行步骤如下: 1.在任意目录下创建一个空目录(例如GitRepos)作为我们的本地仓库 2.进入这个目录中,点击右键打开Git bash窗口 3.执行命令git init 如果在当前目录中看到.git文件夹&#x…...
【Node.js】短链接
原文链接:Nodejs 第六十二章(短链接) - 掘金 (juejin.cn) 短链接是一种缩短长网址的方法,将原始的长网址转换为更短的形式。短链接的主要用途之一是在社交媒体平台进行链接分享。由于这些平台对字符数量有限制,长网址可…...

详解 Redis 在 Centos 系统上的安装
文章目录 详解 Redis 在 Centos 系统上的安装1. 使用 yum 安装 Redis 52. 创建符号链接3. 修改配置文件4. 启动和停止 Redis 详解 Redis 在 Centos 系统上的安装 1. 使用 yum 安装 Redis 5 如果是Centos8,yum 仓库中默认的 redis 版本就是5,直接 yum i…...

C语言 | Leetcode C语言题解之第17题电话号码的字母组合
题目: 题解: char phoneMap[11][5] {"\0", "\0", "abc\0", "def\0", "ghi\0", "jkl\0", "mno\0", "pqrs\0", "tuv\0", "wxyz\0"};char* digits…...

wordpress全站开发指南-面向开发者及深度用户(全中文实操)--wordpress中的著名循环
wordpress中的著名循环 首先,在深入研究任何代码之前,我们首先要确保我们有不止一篇博客文章可以工作。因此,我们要去自己的wordpress站点,从侧边栏单机Posts(文章),进行创建 在执行代码的时候会优先执行single.php如…...
libVLC 提取视频帧使用QGraphicsView渲染
在前面章节中,我们讲解了如何使用QWidget渲染每一帧视频数据,这种方法对 CPU 负荷较高。 libVLC 提取视频帧使用QWidget渲染-CSDN博客 后面又讲解了使用OpenGL渲染每一帧视频数据,使用 OpenGL去绘制,利用 GPU 减轻 CPU 计算负荷…...

大厂Java笔试题之判断字母大小写
/*** 题目:如果一个由字母组成的字符串,首字母是大写,那么就统计该字符串中大写字母的数量,并输出该字符串中所有的大写字母。否则,就输出* 该字符串不是首字母大写*/ public class Demo2 {public static void main(St…...
场景文本检测识别学习 day02(AlexNet论文阅读、ResNet论文精读)
怎么读论文 在第一遍阅读的时候,只需要看题目,摘要和结论,先看题目是不是跟我的方向有关,看摘要是不是用到了我感兴趣的方法,看结论他是怎么解决摘要中提出的问题,或者怎么实现摘要中的方法,然…...

4.9日总结
1.MySQL概述 1.数据库基本概念:存储数据的仓库,数据是有组织的进行存储 2.数据库管理系统:操纵和管理数据库的大型软件 3.SQL:操作关系型数据库的编程语言,定义了一套操作型数据库统一标准 2.MySQL数据库 关系型数…...

python第四次作业
1、找出10000以内能被5或6整除,但不能被两者同时整除的数(函数) def func():for i in range(10001):if (i % 5 0 or i % 6 0) and i % 30 ! 0:print(i,end " ")func() 2、写一个方法,计算列表所有偶数下标元素的…...

工业通信原理——Modbus-TCP通信规约定义
工业通信原理——Modbus-TCP通信规约定义 前言 Modbus TCP是一种基于TCP/IP协议的通信规约,用于在客户机和服务器之间进行数据通信。 Modbus-TCP通信规约定义 Modbus TCP通信规约的定义,包括客户机请求和服务器响应的基本流程: 连接建立…...
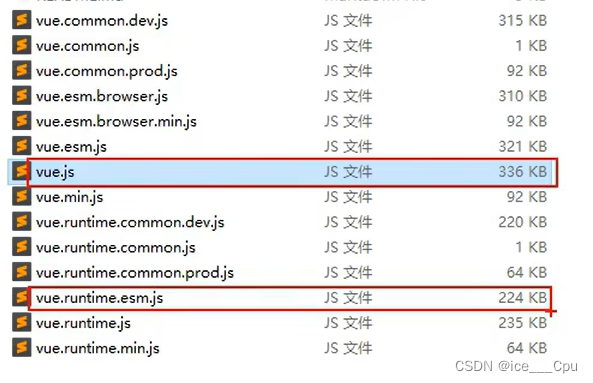
Vue - 4( 8000 字 Vue 入门级教程)
一: Vue 初阶 1.1 关于不同版本的 Vue Vue.js 有不同版本,如 vue.js 与 vue.runtime.xxx.js,这些版本主要针对不同的使用场景和需求进行了优化,区别主要体现在以下几个方面: 完整版 vs 运行时版: vue.js&…...

5.118 BCC工具之xfsslower.py解读
一,工具简介 xfsslower显示了XFS的读取、写入、打开和fsync操作,这些操作慢于一个阈值。 二,代码示例 #!/usr/bin/env pythonfrom __future__ import print_function from bcc import BPF import argparse from time import strftime# arguments examples = ""…...

Spark编程基础
一、RDD入门 1.RDD是什么? RDD是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合,即弹性分布式数据集。 2.RDD的三种创建方式 第一种是将程序中已存在的集合(如集合、列表、数组&a…...

React 状态管理:高效处理数组数据的5种方法
1.原因 为什么在 React 中,状态(state)如果是数组类型,需要单独处理?主要有以下几个原因: 不可变性(Immutability): React 中的状态是不可变的,意味着我们不能直接修改状态,而是要创建一个新的状态对象。对于数组来说,直接修改数组元素是不符合 React 的设计原则的…...

Emacs AI编程助手:ai-code-interface.el深度集成指南
1. 项目概述:一个为Emacs注入AI灵魂的代码接口如果你是一位Emacs的深度用户,同时又对AI辅助编程抱有极大的热情,那么你很可能已经厌倦了在浏览器、终端和编辑器之间反复横跳的割裂体验。tninja/ai-code-interface.el这个项目,正是…...

从开源AI导师项目GURU-Ai拆解:如何构建具备教学能力的智能体
1. 项目概述:一个“AI导师”的诞生与定位最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个平平无奇的AI工具仓库。但点进去细看,你会发现它的野心不小——它想做的不是又一个聊天机…...

ElevenLabs葡萄牙语语音优化黄金7步法:含音频波形对比图、MOS评分提升路径与合规性审查checklist
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs葡萄牙语语音优化的底层逻辑与技术边界 ElevenLabs 对葡萄牙语(尤其是巴西葡萄牙语,pt-BR)的语音合成并非简单地复用英语模型微调,而是基于多阶…...

Pandrator:基于Python的自动化内容生成与数据转换工具实践
1. 项目概述与核心价值最近在折腾一些自动化数据处理和内容生成的工作流,发现了一个挺有意思的开源项目,叫Pandrator。乍一看这个名字,可能会联想到“潘多拉”和“生成器”的结合,实际上它也确实是一个功能强大的内容转换与生成工…...

树莓派+Kali Linux+PiTFT打造便携式安全测试平台全攻略
1. 项目概述如果你和我一样,对网络安全和嵌入式硬件都抱有浓厚的兴趣,那么将Kali Linux与树莓派结合,再配上一块小巧的触摸屏,绝对是一个能让你兴奋起来的项目。这不仅仅是把两个热门技术拼在一起,更是打造一个真正便携…...

Cursor编辑器状态快照插件开发:一键保存与恢复工作区
1. 项目概述:一个专为开发者设计的“后悔药”如果你是一名重度使用 Cursor 编辑器的开发者,那么你一定经历过这样的场景:在沉浸式编码时,为了快速定位或修改,你可能会频繁地使用CtrlClick跳转到函数定义,或…...

VS Code Live Server完全指南:告别手动刷新,拥抱实时开发新时代
VS Code Live Server完全指南:告别手动刷新,拥抱实时开发新时代 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vs…...

Maestro:基于YAML的声明式任务编排引擎,实现DevOps自动化工作流
1. 项目概述:从“指挥家”到“自动化交响乐”在软件开发和运维的世界里,我们常常扮演着“救火队员”的角色。一个微服务挂了,需要手动登录服务器查看日志;一个API接口响应慢了,得去翻监控图表找原因;新功能…...

Altium Designer20 从零到一:新手必备的安装与核心功能上手指南
1. Altium Designer20安装全攻略 第一次接触Altium Designer20(简称AD20)时,我和大多数电子设计新手一样,面对这个专业软件既兴奋又忐忑。记得当时为了完成课程设计,我在宿舍折腾了整整一个下午才搞定安装。现在回想起…...

UE5 3D Widget 渲染优化:告别动态模糊与重影困扰
1. 3D Widget动态模糊问题的根源剖析 第一次在UE5项目中使用3D Widget展示动态角色动画时,我被那些飘忽不定的睫毛重影彻底搞懵了。明明在静态预览时一切正常,但只要角色开始眨眼或做表情,睫毛和发丝边缘就会出现诡异的拖影效果,就…...