如何在 Ubuntu 14.04 上使用 Rsyslog、Logstash 和 Elasticsearch 实现日志集中管理
Elastic 的一篇文章
介绍
理解组织生成的数百万条日志行可能是一个艰巨的挑战。一方面,这些日志行提供了对应用程序性能、服务器性能指标和安全性的视图。另一方面,日志管理和分析可能非常耗时,这可能会阻碍对这些日益必要的服务的采用。
开源软件,如 rsyslog、Elasticsearch 和 Logstash 提供了传输、转换和存储日志数据的工具。
在本教程中,您将学习如何创建一个集中的 rsyslog 服务器,以存储来自多个系统的日志文件,然后使用 Logstash 将它们发送到 Elasticsearch 服务器。然后,您可以决定如何最好地分析数据。
目标
本教程教会您如何集中存储由 syslog 生成或接收的日志,特别是被称为 rsyslog 的变体。Syslog 和基于 syslog 的工具如 rsyslog 从内核和许多运行以保持类 UNIX 服务器运行的程序中收集重要信息。由于 syslog 是一个标准,而不仅仅是一个程序,许多软件项目都支持向 syslog 发送数据。通过集中存储这些数据,您可以更轻松地审计安全性,监视应用程序行为,并跟踪其他重要的服务器信息。
从一个集中或聚合的 rsyslog 服务器,您可以将数据转发到 Logstash,它可以在将数据发送到 Elasticsearch 之前进一步解析和丰富您的日志数据。
本教程的最终目标是:
- 设置一个单一的客户端(或转发)rsyslog 服务器
- 设置一个单一的服务器(或收集)rsyslog 服务器,以接收来自 rsyslog 客户端的日志
- 设置一个 Logstash 实例,以接收来自 rsyslog 收集服务器的消息
- 设置一个 Elasticsearch 服务器,以接收来自 Logstash 的数据
先决条件
在相同的 DigitalOcean 数据中心中,创建以下启用了私有网络的 Droplets:
- 名为 rsyslog-client 的 Ubuntu 14.04 Droplet
- 名为 rsyslog-server 的 Ubuntu 14.04 Droplet(1 GB 或更大),用于存储集中日志和安装 Logstash
- 安装了 Elasticsearch 的 Ubuntu 14.04 Droplet,安装方法请参考《在 Ubuntu 14.04 上安装和配置 Elasticsearch》
您还需要为每个服务器创建一个具有 sudo 权限的非 root 用户。《使用 Ubuntu 14.04 进行初始服务器设置》解释了如何设置这一点。
参考《如何设置和使用 DigitalOcean 私有网络》以获取有关在创建 Droplets 时启用私有网络的帮助。
如果您在没有启用私有网络的情况下创建了 Droplets,请参考《如何在现有 Droplets 上启用 DigitalOcean 私有网络》。
步骤 1 —— 确定私有 IP 地址
在本节中,您将确定每个 Droplet 分配了哪些私有 IP 地址。这些信息将在整个教程中需要。
在每个 Droplet 上,使用 ifconfig 命令找到其 IP 地址:
sudo ifconfig -a
使用 -a 选项显示所有接口。主要以太网接口通常称为 eth0。但在这种情况下,我们需要来自 eth1 的 IP,即 私有 IP 地址。这些私有 IP 地址在互联网上不可路由,并且用于在私有 LAN 中进行通信 — 在这种情况下,是在同一数据中心中启用了次要接口的服务器之间。
输出将类似于:
eth0 Link encap:Ethernet HWaddr 04:01:06:a7:6f:01 inet addr:123.456.78.90 Bcast:123.456.78.255 Mask:255.255.255.0inet6 addr: fe80::601:6ff:fea7:6f01/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1RX packets:168 errors:0 dropped:0 overruns:0 frame:0TX packets:137 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:1000 RX bytes:18903 (18.9 KB) TX bytes:15024 (15.0 KB)eth1 Link encap:Ethernet HWaddr 04:01:06:a7:6f:02 inet addr:10.128.2.25 Bcast:10.128.255.255 Mask:255.255.0.0inet6 addr: fe80::601:6ff:fea7:6f02/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1RX packets:6 errors:0 dropped:0 overruns:0 frame:0TX packets:5 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:1000 RX bytes:468 (468.0 B) TX bytes:398 (398.0 B)lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0inet6 addr: ::1/128 Scope:HostUP LOOPBACK RUNNING MTU:16436 Metric:1RX packets:0 errors:0 dropped:0 overruns:0 frame:0TX packets:0 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:0 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
这里需要注意的部分是 eth1 和其中的 inet addr。在这种情况下,私有网络地址是 10.128.2.25。这个地址只能从启用了私有网络的同一区域内的其他服务器访问。
请确保对所有 3 个 Droplets 都重复此步骤。将这些私有 IP 地址保存在安全的地方。它们将在整个教程中使用。
步骤 2 —— 设置 Elasticsearch 的绑定地址
作为先决条件,您在单独的 Droplet 上设置了 Elasticsearch。《在 Ubuntu 14.04 上安装和配置 Elasticsearch》教程向您展示了如何将绑定地址设置为 localhost,以便其他服务器无法访问该服务。然而,我们需要更改这一设置,以便 Logstash 可以通过其专用网络地址向其发送数据。
我们将 Elasticsearch 绑定到其专用 IP 地址。Elasticsearch 只会监听对该 IP 地址的请求。
在 Elasticsearch 服务器上,编辑配置文件:
sudo nano /etc/elasticsearch/elasticsearch.yml
找到包含 network.bind_host 的行。如果它被注释掉了,通过删除行首的 # 字符来取消注释。将值更改为 Elasticsearch 服务器的专用 IP 地址,使其看起来像这样:
network.bind_host: private_ip_address
最后,重新启动 Elasticsearch 以启用更改。
sudo service elasticsearch restart
步骤 3 —— 配置中心服务器以接收数据
在本节中,我们将配置 rsyslog-server Droplet 为能够从其他 syslog 服务器在 514 端口接收数据的 中心 服务器。
要配置 rsyslog-server 以从其他 syslog 服务器接收数据,请编辑 rsyslog-server Droplet 上的 /etc/rsyslog.conf:
sudo nano /etc/rsyslog.conf
找到您的 rsyslog.conf 中已经注释掉的这些行:
# provides UDP syslog reception
#$ModLoad imudp
#$UDPServerRun 514# provides TCP syslog reception
#$ModLoad imtcp
#$InputTCPServerRun 514
每个部分的第一行($ModLoad imudp 和 $ModLoad imtcp)分别加载 imudp 和 imtcp 模块。imudp 代表 input module udp,imtcp 代表 input module tcp。这些模块监听来自其他 syslog 服务器的传入数据。
每个部分的第二行($UDPSerververRun 514 和 $TCPServerRun 514)指示 rsyslog 应启动分别监听端口 514(这是 syslog 的默认端口)的 UDP 和 TCP 服务器。
要启用这些模块和服务器,请取消注释这些行,使文件现在包含:
# provides UDP syslog reception
$ModLoad imudp
$UDPServerRun 514# provides TCP syslog reception
$ModLoad imtcp
$InputTCPServerRun 514
保存并关闭 rsyslog 配置文件。
通过运行以下命令重新启动 rsyslog:
sudo service rsyslog restart
您的中心 rsyslog 服务器现在已配置为监听来自远程 syslog(包括 rsyslog)实例的消息。
步骤 4 —— 配置 rsyslog 以远程发送数据
在本节中,我们将配置 rsyslog-client 以将日志数据发送到我们在上一步中配置的 ryslog-server Droplet。
在 Ubuntu 上的默认 rsyslog 设置中,您会在 /etc/rsyslog.d 中找到两个文件:
20-ufw.conf50-default.conf
在 rsyslog-client 上,编辑默认配置文件:
sudo nano /etc/rsyslog.d/50-default.conf
在 log by facility 部分之前的文件顶部添加以下行,将 private_ip_of_ryslog_server 替换为您 中心 服务器的私有 IP:
*.* @private_ip_of_ryslog_server:514
保存并退出文件。
行的第一部分(.)表示我们要发送所有消息。虽然这超出了本教程的范围,但您可以配置 rsyslog 仅发送某些消息。行的其余部分解释了如何发送数据以及发送数据的位置。在我们的情况下,@ 符号表示 rsyslog 使用 UDP 发送消息。将其更改为 @@ 以使用 TCP。然后是安装有 rsyslog 和 Logstash 的 rsyslog-server 的私有 IP 地址。冒号后面的数字是要使用的端口号。
重新启动 rsyslog 以启用更改:
sudo service rsyslog restart
恭喜!您现在正在将您的 syslog 消息发送到一个中心服务器!
步骤 5 —— 将日志数据格式化为 JSON
Elasticsearch 要求其接收的所有文档都以 JSON 格式提供,而 rsyslog 提供了一种通过模板实现这一点的方法。
在本步骤中,我们将配置我们的中心 rsyslog 服务器以使用 JSON 模板在将数据发送到 Logstash 之前格式化日志数据,然后由 Logstash 将其发送到另一台服务器上的 Elasticsearch。
回到 rsyslog-server 服务器,在发送到 Logstash 之前创建一个新的配置文件以将消息格式化为 JSON 格式:
sudo nano /etc/rsyslog.d/01-json-template.conf
将以下内容精确复制到文件中:
template(name="json-template"type="list") {constant(value="{")constant(value="\"@timestamp\":\"") property(name="timereported" dateFormat="rfc3339")constant(value="\",\"@version\":\"1")constant(value="\",\"message\":\"") property(name="msg" format="json")constant(value="\",\"sysloghost\":\"") property(name="hostname")constant(value="\",\"severity\":\"") property(name="syslogseverity-text")constant(value="\",\"facility\":\"") property(name="syslogfacility-text")constant(value="\",\"programname\":\"") property(name="programname")constant(value="\",\"procid\":\"") property(name="procid")constant(value="\"}\n")
}
除了第一行和最后一行外,注意到此模板生成的行在开头有一个逗号。这是为了保持 JSON 结构 和 帮助保持文件的可读性。此模板将按照 Elasticsearch 和 Logstash 期望接收的方式格式化您的消息。它们将如下所示:
{"@timestamp" : "2015-11-18T18:45:00Z","@version" : "1","message" : "Your syslog message here","sysloghost" : "hostname.example.com","severity" : "info","facility" : "daemon","programname" : "my_program","procid" : "1234"
}
发送的数据尚未使用此格式。下一步显示了如何配置服务器以使用此模板文件。
第六步 —— 配置集中式服务器发送到 Logstash
现在我们已经有了定义正确 JSON 格式的模板文件,让我们配置集中式 rsyslog 服务器将数据发送到 Logstash,在本教程中 Logstash 与其在同一台 Droplet 上。
在启动时,rsyslog 将查看 /etc/rsyslog.d 中的文件并从中创建其配置。让我们添加自己的配置文件来扩展配置。
在 rsyslog-server 上,创建 /etc/rsyslog.d/60-output.conf:
sudo nano /etc/rsyslog.d/60-output.conf
将以下行复制到此文件中:
# 此行将所有行发送到指定 IP 地址的 10514 端口,
# 使用 "json-template" 格式模板*.* @private_ip_logstash:10514;json-template
开头的 *.* 表示处理所有日志消息的其余部分。@ 符号表示使用 UDP(使用 @@ 来使用 TCP)。@ 后面的 IP 地址或主机名是要转发消息的地方。在我们的情况下,由于 rsyslog 集中式服务器和 Logstash 服务器都安装在同一台 Droplet 上,我们使用 rsyslog-server 的私有 IP 地址。这必须与您在下一步中配置 Logstash 监听的私有 IP 地址相匹配。
接下来是端口号。本教程使用端口 10514。请注意,Logstash 服务器必须使用相同的协议在相同的端口上监听。最后一部分是我们的模板文件,显示了如何在传递数据之前格式化数据。
不要立即重新启动 rsyslog。首先,我们必须配置 Logstash 来接收消息。
第七步 —— 配置 Logstash 接收 JSON 消息
在此步骤中,您将安装 Logstash,配置它以从 rsyslog 接收 JSON 消息,并配置它将 JSON 消息发送到 Elasticsearch。
Logstash 需要 Java 7 或更高版本。使用 Elasticsearch 教程的 第一步 中的说明在 rsyslog-server Droplet 上安装 Java 7 或 8。
接下来,安装 Logstash 存储库的安全密钥:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
将存储库定义添加到您的 /etc/apt/sources.list 文件中:
echo "deb http://packages.elastic.co/logstash/2.3/debian stable main" | sudo tee -a /etc/apt/sources.list
更新软件包列表以包括 Logstash 存储库:
sudo apt-get update
最后,安装 Logstash:
sudo apt-get install logstash
现在 Logstash 已安装,让我们配置它以监听来自 rsyslog 的消息。
Logstash 的默认安装在 /etc/logstash/conf.d 中查找配置文件。编辑主配置文件:
sudo nano /etc/logstash/conf.d/logstash.conf
然后,在 /etc/logstash/conf.d/logstash.conf 中添加以下行:
# 此输入块将在端口 10514 上监听日志。
# 主机应该是 Logstash 服务器上的一个 IP。
# codec => "json" 表示我们期望接收的行是 JSON 格式的
# type => "rsyslog" 是一个可选标识符,用于帮助识别管道中的消息流。input {udp {host => "logstash_private_ip"port => 10514codec => "json"type => "rsyslog"}
}# 这是一个空的过滤器块。您可以稍后在这里添加其他过滤器以进一步处理
# 您的日志行filter { }# 此输出块将发送所有类型为 "rsyslog" 的事件到配置的 Elasticsearch
# 主机和端口,进入每日索引的模式,"rsyslog-YYYY.MM.DD"output {if [type] == "rsyslog" {elasticsearch {hosts => [ "elasticsearch_private_ip:9200" ]}}
}
syslog 协议从定义上是 UDP,因此此配置反映了该标准。
在输入块中,通过将 logstash_private_ip 替换为 rsyslog-server 的私有 IP 地址来设置 Logstash 主机地址,该服务器也安装有 Logstash。
输入块配置 Logstash 监听端口 10514,因此它不会与同一台机器上的 syslog 实例竞争。小于 1024 的端口需要以 root 用户身份运行 Logstash,这不是一个良好的安全实践。
确保将 elasticsearch_private_ip 替换为您的 Elasticsearch Droplet 的私有 IP 地址。输出块显示了一个简单的条件配置。它的目的是只允许匹配的事件通过。在这种情况下,只有具有 “type” 为 “rsyslog” 的事件。
测试您的 Logstash 配置更改:
sudo service logstash configtest
如果没有语法错误,它应该显示 Configuration OK。否则,请尝试阅读错误输出,查看您的 Logstash 配置有什么问题。
完成所有这些步骤后,您可以通过运行以下命令启动 Logstash 实例:
sudo service logstash start
还要重新启动同一台服务器上的 rsyslog,因为它现在有一个要转发的 Logstash 实例:
sudo service rsyslog restart
要验证 Logstash 是否在端口 10514 上监听:
netstat -na | grep 10514
您应该会看到类似以下内容:
udp6 0 0 10.128.33.68:10514 :::*
您将看到 rsyslog-server 的私有 IP 地址和我们用于监听 rsyslog 数据的 10514 端口号。
第八步 — 验证 Elasticsearch 输入
在之前的步骤中,我们配置了 Elasticsearch 监听其私有 IP 地址。现在它应该正在接收来自 Logstash 的消息。在这一步中,我们将验证 Elasticsearch 是否正在接收日志数据。
rsyslog-client 和 rsyslog-server Droplets 应该将它们所有的日志数据发送到 Logstash,然后传递到 Elasticsearch。让我们生成一个安全消息来验证 Elasticsearch 是否确实收到了这些消息。
在 rsyslog-client 上,执行以下命令:
sudo tail /var/log/auth.log
您将在输出的末尾看到本地系统上的安全日志。它看起来类似于:
May 2 16:43:15 rsyslog-client sudo: sammy : TTY=pts/0 ; PWD=/etc/rsyslog.d ; USER=root ; COMMAND=/usr/bin/tail /var/log/auth.log
May 2 16:43:15 rsyslog-client sudo: pam_unix(sudo:session): session opened for user root by sammy(uid=0)
通过简单的查询,您可以检查 Elasticsearch:
在 Elasticsearch 服务器上或任何被允许访问它的系统上运行以下命令。将 elasticsearch_ip 替换为 Elasticsearch 服务器的私有 IP 地址。这个 IP 地址也必须是您在本教程中早些时候配置 Elasticsearch 监听的 IP 地址。
curl -XGET 'http://elasticsearch_ip:9200/_all/_search?q=*&pretty'
在输出中,您将看到类似以下内容:
{"_index" : "logstash-2016.05.04","_type" : "rsyslog","_id" : "AVR8fpR-e6FP4Elp89Ww","_score" : 1.0,"_source":{"@timestamp":"2016-05-04T15:59:10.000Z","@version":"1","message":" sammy : TTY=pts/0 ; PWD=/home/sammy ; USER=root ; COMMAND=/usr/bin/tail /var/log/auth.log","sysloghost":"rsyslog-client","severity":"notice","facility":"authpriv","programname":"sudo","procid":"-","type":"rsyslog","host":"10.128.33.68"}},
请注意,生成 rsyslog 消息的 Droplet 的名称在日志中(rsyslog-client)。
通过这个简单的验证步骤,您的集中式 rsyslog 设置已经完成并且完全可操作!
结论
您的日志现在存储在 Elasticsearch 中。接下来呢?考虑阅读一下 Kibana 能做什么,以可视化您在 Elasticsearch 中的数据,包括线条图、柱状图、饼图、地图等。《如何在 Ubuntu 14.04 上使用 Logstash 和 Kibana 实现日志集中化》解释了如何使用 Kibana web 界面来搜索和可视化日志。
也许您的数据通过进一步解析和标记化会更有价值。如果是这样,那么学习更多关于 Logstash 的知识将有助于您实现这一结果。
相关文章:

如何在 Ubuntu 14.04 上使用 Rsyslog、Logstash 和 Elasticsearch 实现日志集中管理
Elastic 的一篇文章 介绍 理解组织生成的数百万条日志行可能是一个艰巨的挑战。一方面,这些日志行提供了对应用程序性能、服务器性能指标和安全性的视图。另一方面,日志管理和分析可能非常耗时,这可能会阻碍对这些日益必要的服务的采用。 …...

mapbox 工作问题暂时记录
mapbox 工作问题暂时记录 mapbox样式修改1.2.3.4. mapbox样式修改 1. mapbox直接用class名无法修改样式, 可以添加 :deep 来修改样式 2. map.value.getStyle().layers这行代码可以获取页面中所有图层,可以判断图层id来做相应操作 3. map.value.setLayoutProperty(layer.id…...
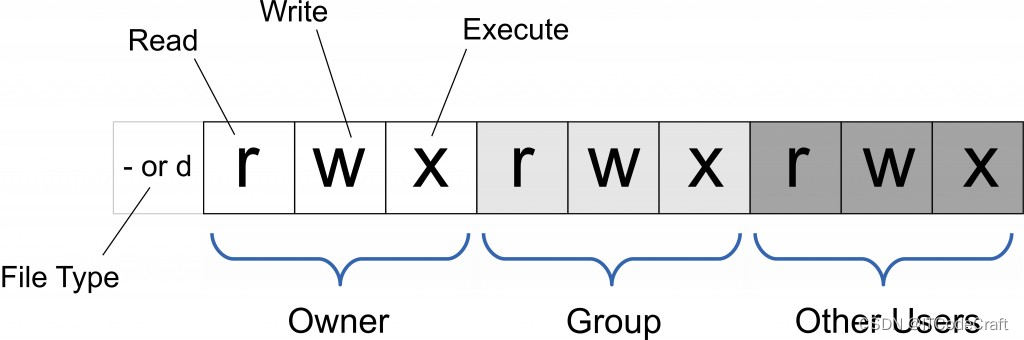
Linux、Docker、Brew、Nginx常用命令
Linux、Docker、Brew、Nginx常用命令 Linuxvi编辑器文件操作文件夹操作磁盘操作 DockerBrewNginx参考 Linux vi编辑器 Vi有三种模式。命令模式、输入模式、尾行模式,简单的关系如下: i -- 切换到输入模式,在光标当前位置开始输入文本。&a…...
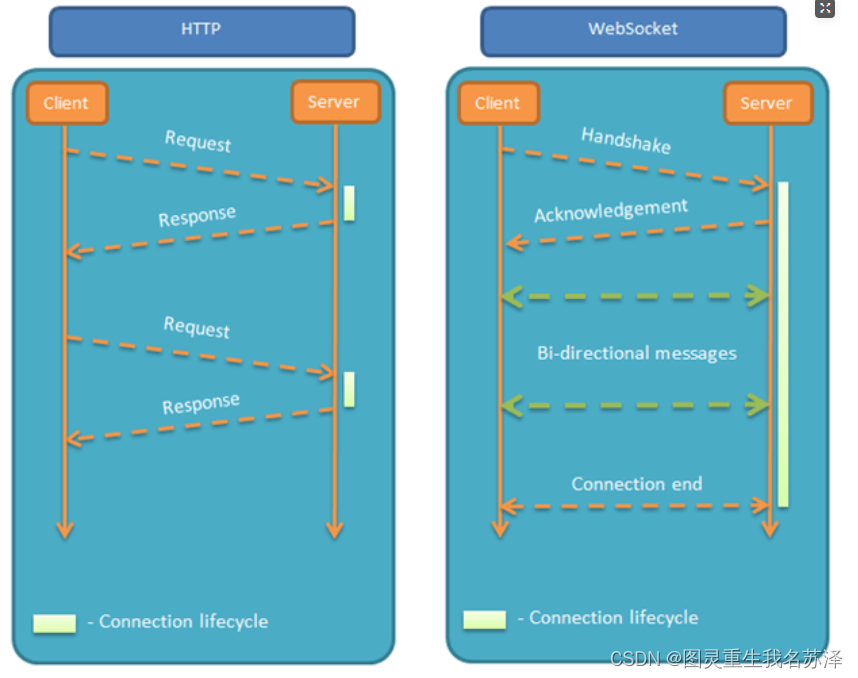
【Spring实战项目】SpringBoot3整合WebSocket+拦截器实现登录验证!从原理到实战
🎉🎉欢迎光临,终于等到你啦🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟持续更新的专栏《Spring 狂野之旅:从入门到入魔》 &a…...

第二证券|政策利好不断,工业母机概念爆发,华东数控等涨停
工业母机概念10日盘中大幅走高,截至发稿,恒进感应、宏德股份、华东重机、华东数控等涨停,凯腾精工涨超20%,创世纪涨逾11%,华辰配备、盘古智能涨超9%,博亚精工涨逾8%。 音讯面上,工业和信息化部…...
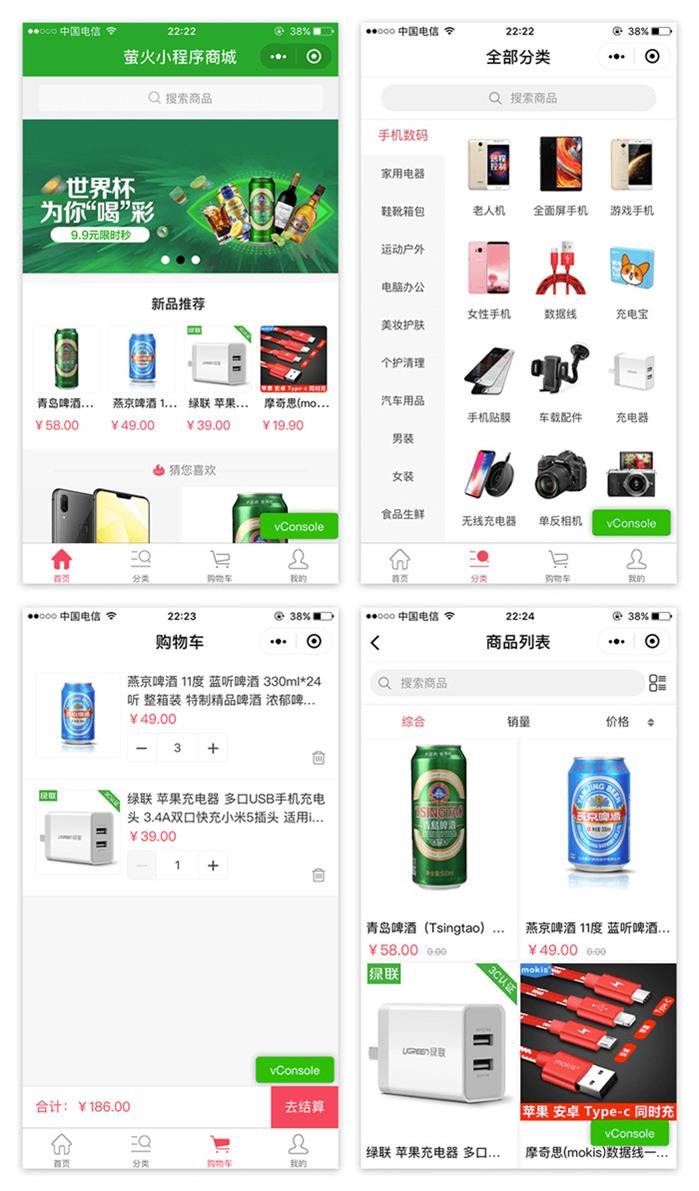
Thinkphp5萤火商城B2C小程序源码
源码介绍 Thinkphp5萤火商城B2C小程序源码,是一款开源的电商系统,为中小企业提供最佳的新零售解决方案。采用稳定的MVC框架开发,执行效率、扩展性、稳定性值得信赖。 环境要求 Nginx/Apache/IIS PHP5.4 MySQL5.1 建议使用环境ÿ…...

PostgreSQL介绍
PostgreSQL是一个高度先进的对象关系型数据库管理系(ORDBMS),其起源可以追溯到1986年,最初是加州大学伯克利分校计算机系的一个项目,名为POSTGRES。它是从Ingres项目演变而来的,目的是克服当时关系数据库系…...

简析数据安全保护策略中的十个核心要素
数据显示,全球企业组织每年在数据安全防护上投入的资金已经超过千亿美元,但数据安全威胁态势依然严峻,其原因在于企业将更多资源投入到数据安全能力建设时,却忽视了这些工作本身的科学性与合理性。因此,企业在实施数据…...

Python+Django+Html河道垃圾识别网页系统
程序示例精选 PythonDjangoHtml河道垃圾识别网页系统 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对《PythonDjangoHtml河道垃圾识别网页系统》编写代码,代码整洁,规…...

BUUCTF:BUU UPLOAD COURSE 1[WriteUP]
构造一句话PHP木马 <?php eval(system($_POST[shell])); ?> 利用eval函数解析$shell的值使得服务器执行system命令 eval函数是无法直接执行命令的,只能把字符串当作php代码解析 这里我们构造的木马是POST的方式上传,那就用MaxHacKBar来执行 …...

从零开始学习:如何使用Selenium和Python进行自动化测试?
安装selenium 打开命令控制符输入:pip install -U selenium 火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能 Selenium IDE 是嵌入到Firefox 浏览器中的一个插件,实现简单的浏览器操 作的录制与回…...
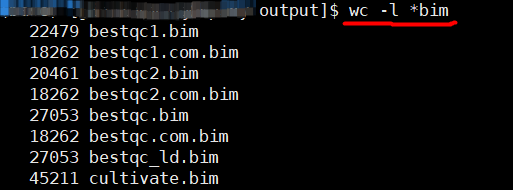
【linux基础】bash脚本的学习:定义变量及引用变量、统计目标目录下所有文件行数、列数
假设目的:统计并输出指定文件夹下所有文件行数 单个文件可以用 wc -l ;多个文件,可以用通配符 / 借助bash脚本 1.定义变量名,使用引号 a"bestqc.com.map" b"Anno.variant_function" c"enrichment/GOe…...

算法四十天-删除排序链表中的重复元素
删除排序链表中的重复元素 题目要求 解题思路 一次遍历 由于给定的链表是排好序的,因此重复的元素在链表中的出现的位置是连续的,因此我们只需要对链表进行一次遍历,就可以删除重复的元素。 具体地,我们从指针cur指向链表的头节…...

Linux-等待子进程
参考资料:《Linux环境编程:从应用到内核》 僵尸进程 进程退出时会进行内核清理,基本就是释放进程所有的资源,这些资源包括内存资源、文件资源、信号量资源、共享内存资源,或者引用计数减一,或者彻底释放。…...

【LeetCode热题100】【二叉树】二叉树的最大深度
题目链接:104. 二叉树的最大深度 - 力扣(LeetCode) 最大深度等于左子树的最大深度和右子树的最大深度中的较大者加一 class Solution { public:int maxDepth(TreeNode *root) {if (!root)return 0;return max(maxDepth(root->left), max…...

想做产品经理,应该选择什么专业?
产品经理作为互联网公司的核心职位,一直以来备受关注。随着互联网的不断发展,产品经理的需求也越来越高,很多人都想要了解哪些专业适合做产品经理。本文将为大家介绍几个适合做产品经理的专业。 1、心理学相关专业 C端产品工作的本源&#x…...

[机器学习Day 1~3
[机器学习]Day 1~3 数据预处理第1步:导入库第2步:导入数据集第3步:处理丢失数据第4步:解析分类数据创建虚拟变量 第5步:拆分数据集为训练集合和测试集合第6步:特征量化 简单线性回归模型第一步:…...
Day106:代码审计-PHP原生开发篇文件安全上传监控功能定位关键搜索1day挖掘
目录 emlog-文件上传&文件删除 emlog-模板文件上传 emlog-插件文件上传 emlog-任意文件删除 通达OA-文件上传&文件包含 知识点: PHP审计-原生开发-文件上传&文件删除-Emlog PHP审计-原生开发-文件上传&文件包含-通达OA emlog-文件上传&文件…...

数码视讯Q7盒子刷armbian遇到的坑之二
继续,nand的q7 搜遍全网,这个盒子能用的安卓映像有两个,一个本站付费下载的那个,另一个是20191218-Q7-nand-4.4.2-root-twrp-Milton这个映像(具体地址自己搜索吧)。第一个需要license,需要自己…...
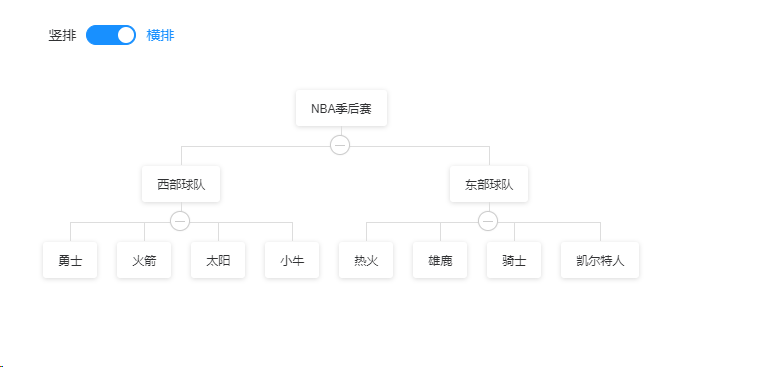
vue2 使用vue-org-tree demo
1.安装 npm i vue2-org-tree npm install -D less-loader less安装 less-loader出错解决办法,直接在package.json》devDependencies下面加入less和less-loader版本,然后执行npm i ,我用的nodejs版本是 16.18.0,“webpack”: “^4…...

开源项目容器镜像全流程实践:从命名规范到生产部署
1. 项目概述:从镜像名到开源协作生态的深度解构看到mco-org/mco这个镜像名,很多人的第一反应可能是去 Docker Hub 或 GitHub 上搜索,看看它具体是什么。但今天,我想从一个更本质、更实战的角度来聊聊这个话题。mco-org/mco不是一个…...

揭秘GPT超级提示工程:从原理到实战,打造高效AI协作指南
1. 项目概述:当“Awesome”遇见“Super Prompting”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫“CyberAlbSecOP/Awesome_GPT_Super_Prompting”。光看这名字,就透着一股“硬核”和“集大成”的味道。作为一个长期和各类大语…...

Apache Burr框架:构建可观测有状态数据应用的核心原理与实践
1. 项目概述:一个用于构建和评估数据产品的Python框架如果你正在处理数据密集型应用,比如推荐系统、个性化广告或者任何需要根据用户行为实时调整策略的场景,你肯定遇到过这样的困境:模型训练和离线评估做得再好,一旦上…...

5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南
5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南 【免费下载链接】SerialAssistant A serial port assistant that can be used directly in the browser. 项目地址: https://gitcode.com/gh_mirrors/se/SerialAssistant 你是否还在为串口调试工具…...

独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力 对于独立开发者或小型工作室而言,在产品开发的早期阶段…...

VS Code Live Server完全指南:告别手动刷新,拥抱实时开发新时代
VS Code Live Server完全指南:告别手动刷新,拥抱实时开发新时代 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vs…...

React Native聊天UI组件库集成指南:从Sendbird UIKit入门到高级定制
1. 项目概述:一个开箱即用的React Native聊天UI组件库如果你正在用React Native开发一个需要集成聊天功能的App,并且希望这个聊天界面看起来专业、交互流畅,同时你又不想从零开始造轮子,那么你很可能已经听说过或者正在寻找一个合…...

CursorTouch/Web-Use:用JavaScript在桌面端模拟移动端触摸交互
1. 项目概述:当光标变成你的手指你有没有想过,在电脑上浏览网页时,如果能像在手机上那样,直接用手指滑动、点击、缩放,体验会不会更流畅?尤其是在处理一些需要精细操作或快速浏览长文档的场景时,…...

红外对射传感器实战指南:从原理到Arduino/CircuitPython应用
1. 项目概述红外对射传感器,也叫红外遮断传感器,是我在自动化项目和互动装置里用得最多的基础传感器之一。它原理简单直接,但用好了能解决很多实际问题,比如统计人流、检测传送带上的物品、制作一个简单的防盗报警器,或…...
)
ElevenLabs菲律宾语语音突然变卡顿?紧急排查清单:DNS劫持、Token过期、区域节点错配(含curl诊断脚本)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs菲律宾语语音突然变卡顿?紧急排查清单:DNS劫持、Token过期、区域节点错配(含curl诊断脚本) 当ElevenLabs API在调用菲律宾语(fil-P…...