[机器学习Day 1~3
[机器学习]Day 1~3
- 数据预处理
- 第1步:导入库
- 第2步:导入数据集
- 第3步:处理丢失数据
- 第4步:解析分类数据
- 创建虚拟变量
- 第5步:拆分数据集为训练集合和测试集合
- 第6步:特征量化
- 简单线性回归模型
- 第一步:数据预处理
- 第二步:训练集使用简单线性回归模型来训练
- 第三步:预测结果
- 第四步:可视化
- 训练集结果可视化
- 测试集结果可视化
- 多元线性回归
- 第1步: 数据预处理
- 导入库
- 导入数据集
- 将类别数据数字化
- 躲避虚拟变量陷阱
- 拆分数据集为训练集和测试集
- 第2步: 在训练集上训练多元线性回归模型
- Step 3: 在测试集上预测结果
数据预处理

第1步:导入库
import numpy as np
import pandas as pd
第2步:导入数据集
//随后一列是label
dataset = pd.read_csv('Data.csv')//读取csv文件
X = dataset.iloc[ : , :-1].values//.iloc[行,列]
Y = dataset.iloc[ : , 3].values // : 全部行 or 列;[a]第a行 or 列// [a,b,c]第 a,b,c 行 or 列
第3步:处理丢失数据
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
imputer = imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
第4步:解析分类数据
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
创建虚拟变量
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
第5步:拆分数据集为训练集合和测试集合
#from sklearn.model_selection import train_test_split
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
第6步:特征量化
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
简单线性回归模型

第一步:数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdataset = pd.read_csv('studentscores.csv')
X = dataset.iloc[ : , : 1 ].values
Y = dataset.iloc[ : , 1 ].valuesfrom sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/4, random_state = 0)
第二步:训练集使用简单线性回归模型来训练
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor = regressor.fit(X_train, Y_train)
第三步:预测结果
Y_pred = regressor.predict(X_test)
第四步:可视化
训练集结果可视化
plt.scatter(X_train , Y_train, color = 'red')
plt.plot(X_train , regressor.predict(X_train), color ='blue')
plt.show()
测试集结果可视化
plt.scatter(X_test , Y_test, color = 'red')
plt.plot(X_test , regressor.predict(X_test), color ='blue')
plt.show()
多元线性回归

第1步: 数据预处理
导入库
import pandas as pd
import numpy as np
导入数据集
dataset = pd.read_csv('50_Startups.csv')
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 4 ].values
将类别数据数字化
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder()
X[: , 3] = labelencoder.fit_transform(X[ : , 3])
onehotencoder = OneHotEncoder(categorical_features = [3])
X = onehotencoder.fit_transform(X).toarray()
躲避虚拟变量陷阱
X = X[: , 1:]
拆分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
第2步: 在训练集上训练多元线性回归模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, Y_train)
Step 3: 在测试集上预测结果
y_pred = regressor.predict(X_test)
相关文章:
[机器学习Day 1~3
[机器学习]Day 1~3 数据预处理第1步:导入库第2步:导入数据集第3步:处理丢失数据第4步:解析分类数据创建虚拟变量 第5步:拆分数据集为训练集合和测试集合第6步:特征量化 简单线性回归模型第一步:…...
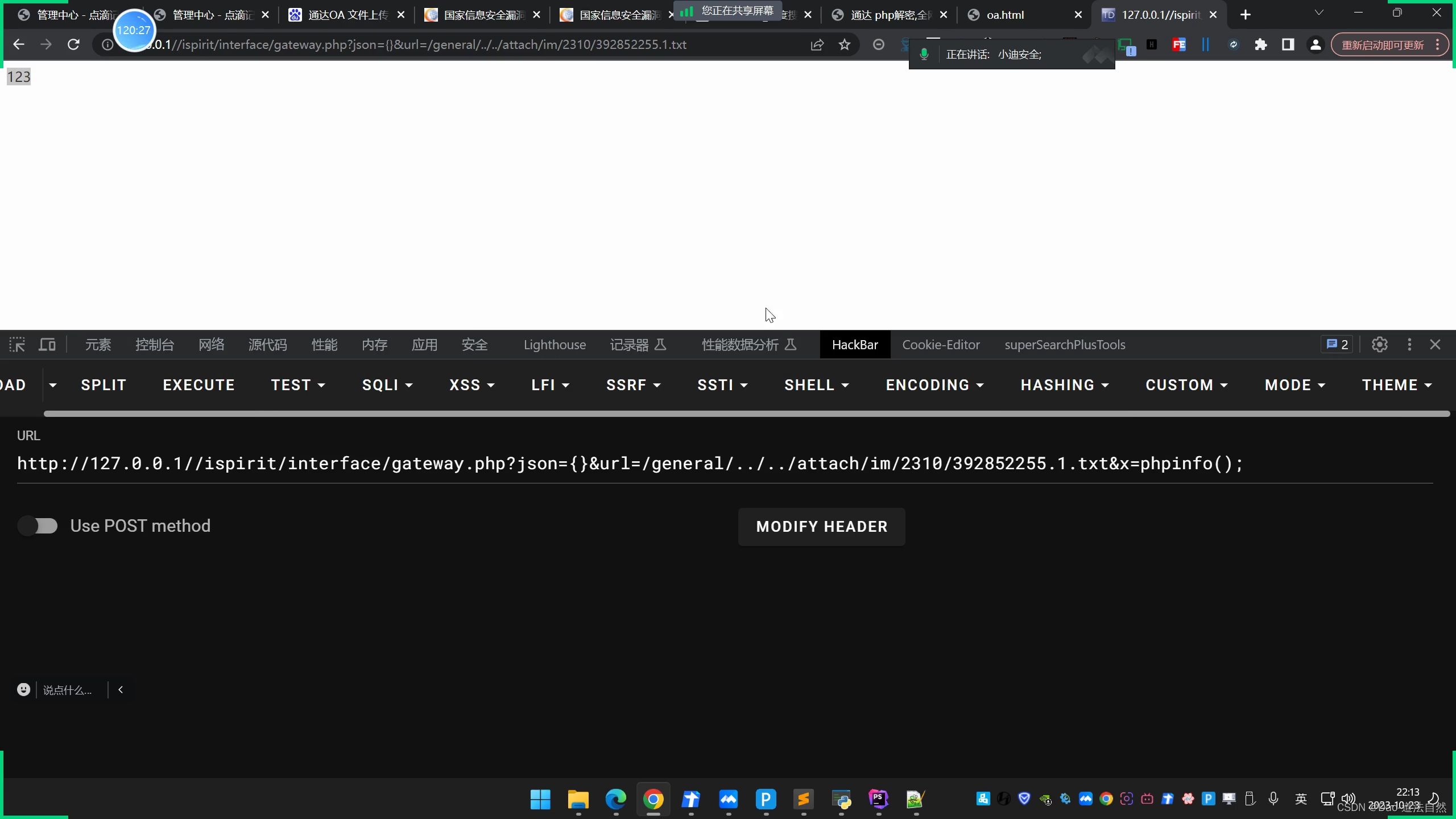
Day106:代码审计-PHP原生开发篇文件安全上传监控功能定位关键搜索1day挖掘
目录 emlog-文件上传&文件删除 emlog-模板文件上传 emlog-插件文件上传 emlog-任意文件删除 通达OA-文件上传&文件包含 知识点: PHP审计-原生开发-文件上传&文件删除-Emlog PHP审计-原生开发-文件上传&文件包含-通达OA emlog-文件上传&文件…...

数码视讯Q7盒子刷armbian遇到的坑之二
继续,nand的q7 搜遍全网,这个盒子能用的安卓映像有两个,一个本站付费下载的那个,另一个是20191218-Q7-nand-4.4.2-root-twrp-Milton这个映像(具体地址自己搜索吧)。第一个需要license,需要自己…...
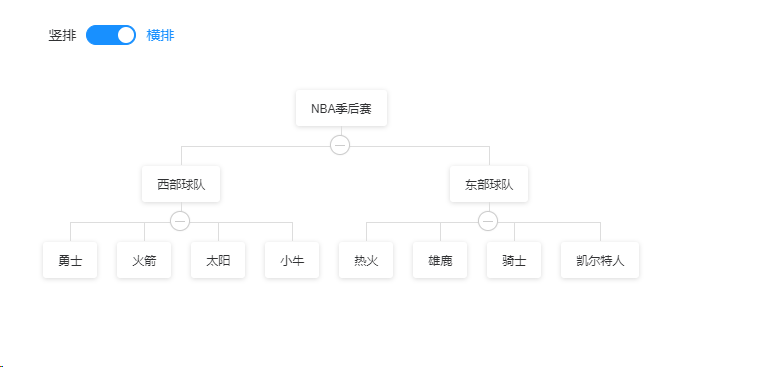
vue2 使用vue-org-tree demo
1.安装 npm i vue2-org-tree npm install -D less-loader less安装 less-loader出错解决办法,直接在package.json》devDependencies下面加入less和less-loader版本,然后执行npm i ,我用的nodejs版本是 16.18.0,“webpack”: “^4…...
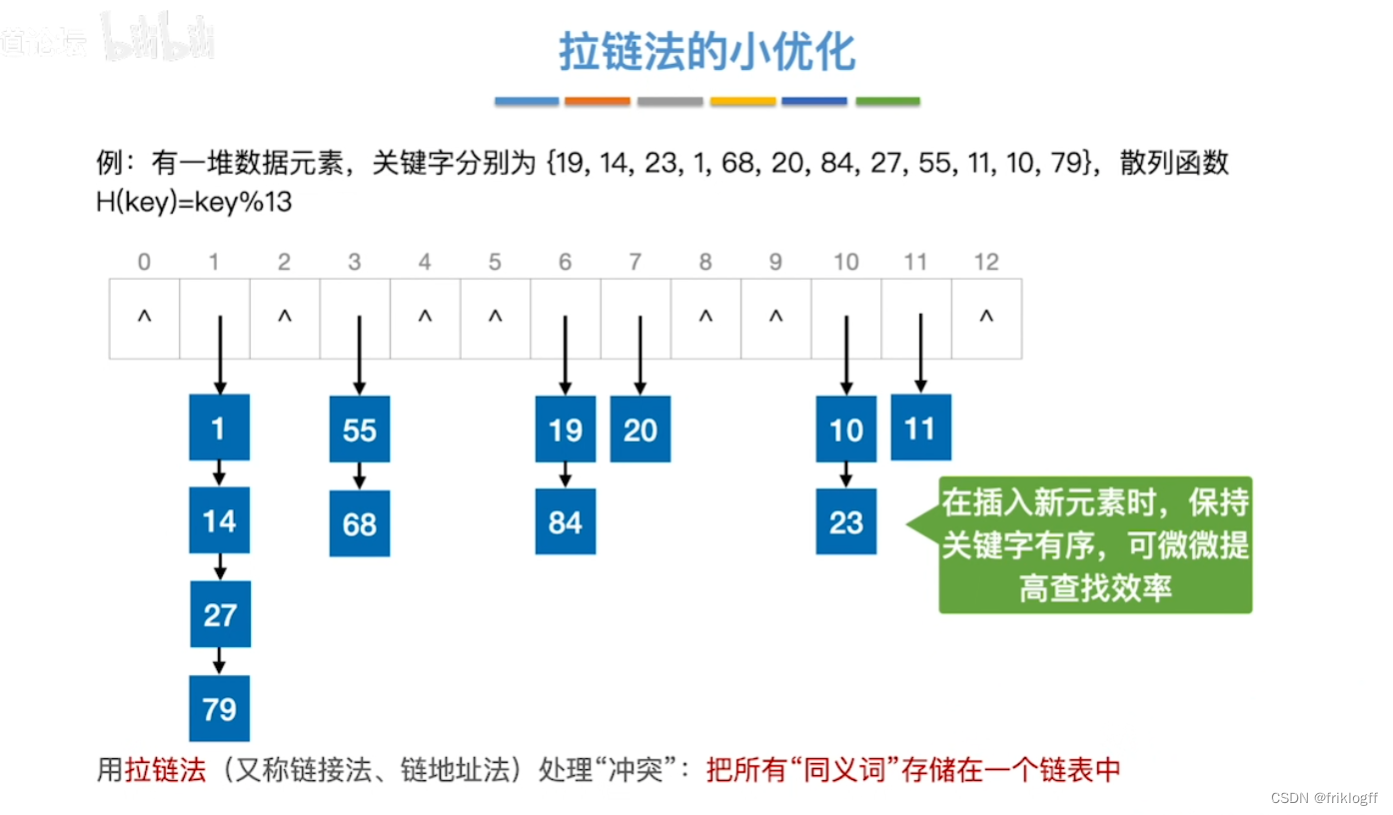
【数据结构】考研真题攻克与重点知识点剖析 - 第 7 篇:查找
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...

【数仓】DataX 通过SpringBoot项目自动生成 job.json 文件
相关文章 【数仓】基本概念、知识普及、核心技术【数仓】数据分层概念以及相关逻辑【数仓】Hadoop软件安装及使用(集群配置)【数仓】Hadoop集群配置常用参数说明【数仓】zookeeper软件安装及集群配置【数仓】kafka软件安装及集群配置【数仓】flume软件安…...

注解式 WebSocket - 构建 群聊、单聊 系统
目录 前言 注解式 WebSocket 构建聊天系统 群聊系统(基本框架) 群聊系统(添加昵称) 单聊系统 WebSocket 作用域下无法注入 Spring Bean 对象? 考虑离线消息 前言 很久之前,咱们聊过 WebSocket 编程式…...
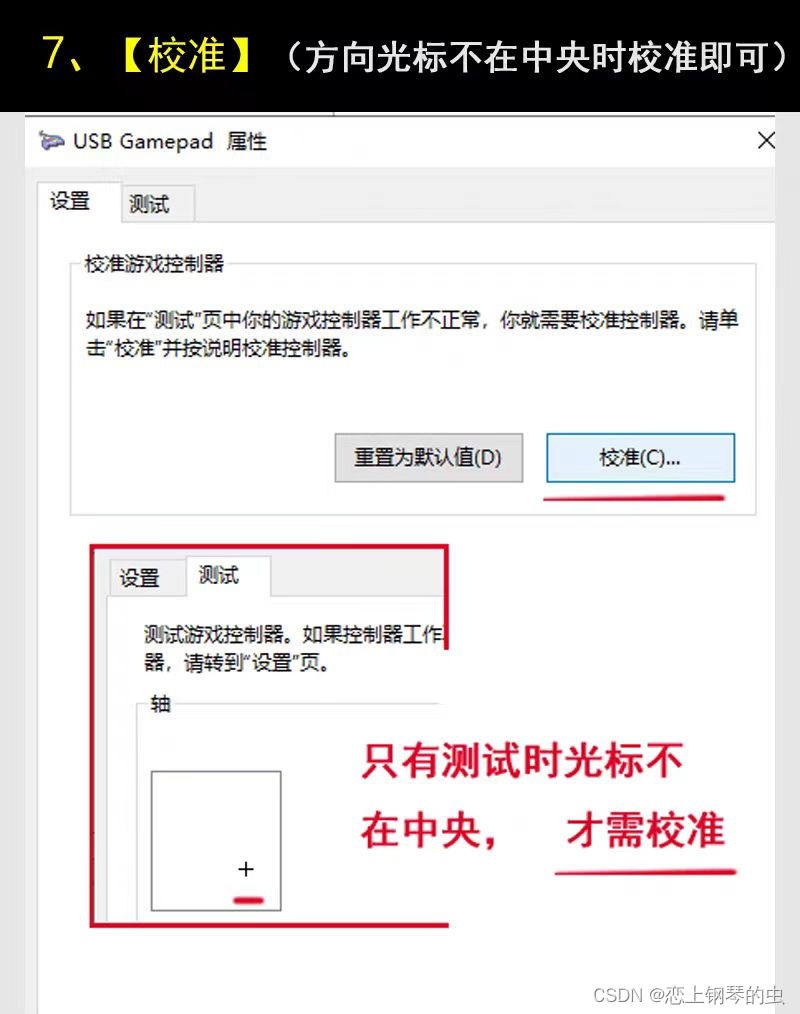
无线游戏手柄的测试(Windows11系统手柄调试方法)
实物 1、把游戏手柄的无线接收器插入到电脑usb接口中 2、【控制面板】----【查看设备和打印机】 3、【蓝牙和其它设备】--【更多设备和打印机设置】 4、鼠标右键【游戏控制器设置】 5、【属性】 6、【测试】(每个按键是否正常) 7、【校准】(…...

计算机的各种转换
一、存量容量的转换 特别注意:1 B 8 bit 转换为:1024 2(10) 括号中的数字为2的指数(即多少次方) 1KB2(10)B1024B; 括号中的数字为2的指数(即多少次方) 1MB2(10)KB1024KB2(20)B; 1GB2(10)MB1024MB2(3…...
Git分布式版本控制系统——Git常用命令(一)
一、获取Git仓库--在本地初始化仓库 执行步骤如下: 1.在任意目录下创建一个空目录(例如GitRepos)作为我们的本地仓库 2.进入这个目录中,点击右键打开Git bash窗口 3.执行命令git init 如果在当前目录中看到.git文件夹&#x…...
【Node.js】短链接
原文链接:Nodejs 第六十二章(短链接) - 掘金 (juejin.cn) 短链接是一种缩短长网址的方法,将原始的长网址转换为更短的形式。短链接的主要用途之一是在社交媒体平台进行链接分享。由于这些平台对字符数量有限制,长网址可…...

详解 Redis 在 Centos 系统上的安装
文章目录 详解 Redis 在 Centos 系统上的安装1. 使用 yum 安装 Redis 52. 创建符号链接3. 修改配置文件4. 启动和停止 Redis 详解 Redis 在 Centos 系统上的安装 1. 使用 yum 安装 Redis 5 如果是Centos8,yum 仓库中默认的 redis 版本就是5,直接 yum i…...

C语言 | Leetcode C语言题解之第17题电话号码的字母组合
题目: 题解: char phoneMap[11][5] {"\0", "\0", "abc\0", "def\0", "ghi\0", "jkl\0", "mno\0", "pqrs\0", "tuv\0", "wxyz\0"};char* digits…...

wordpress全站开发指南-面向开发者及深度用户(全中文实操)--wordpress中的著名循环
wordpress中的著名循环 首先,在深入研究任何代码之前,我们首先要确保我们有不止一篇博客文章可以工作。因此,我们要去自己的wordpress站点,从侧边栏单机Posts(文章),进行创建 在执行代码的时候会优先执行single.php如…...
libVLC 提取视频帧使用QGraphicsView渲染
在前面章节中,我们讲解了如何使用QWidget渲染每一帧视频数据,这种方法对 CPU 负荷较高。 libVLC 提取视频帧使用QWidget渲染-CSDN博客 后面又讲解了使用OpenGL渲染每一帧视频数据,使用 OpenGL去绘制,利用 GPU 减轻 CPU 计算负荷…...

大厂Java笔试题之判断字母大小写
/*** 题目:如果一个由字母组成的字符串,首字母是大写,那么就统计该字符串中大写字母的数量,并输出该字符串中所有的大写字母。否则,就输出* 该字符串不是首字母大写*/ public class Demo2 {public static void main(St…...
场景文本检测识别学习 day02(AlexNet论文阅读、ResNet论文精读)
怎么读论文 在第一遍阅读的时候,只需要看题目,摘要和结论,先看题目是不是跟我的方向有关,看摘要是不是用到了我感兴趣的方法,看结论他是怎么解决摘要中提出的问题,或者怎么实现摘要中的方法,然…...

4.9日总结
1.MySQL概述 1.数据库基本概念:存储数据的仓库,数据是有组织的进行存储 2.数据库管理系统:操纵和管理数据库的大型软件 3.SQL:操作关系型数据库的编程语言,定义了一套操作型数据库统一标准 2.MySQL数据库 关系型数…...

python第四次作业
1、找出10000以内能被5或6整除,但不能被两者同时整除的数(函数) def func():for i in range(10001):if (i % 5 0 or i % 6 0) and i % 30 ! 0:print(i,end " ")func() 2、写一个方法,计算列表所有偶数下标元素的…...

工业通信原理——Modbus-TCP通信规约定义
工业通信原理——Modbus-TCP通信规约定义 前言 Modbus TCP是一种基于TCP/IP协议的通信规约,用于在客户机和服务器之间进行数据通信。 Modbus-TCP通信规约定义 Modbus TCP通信规约的定义,包括客户机请求和服务器响应的基本流程: 连接建立…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

CI/CD安全最佳实践:保护软件交付流程
CI/CD安全最佳实践:保护软件交付流程 一、CI/CD安全最佳实践概述 1.1 CI/CD安全最佳实践的定义 CI/CD安全最佳实践是指在持续集成和持续部署流程中实施的安全策略和措施。它涵盖代码提交、构建、测试、部署等各个阶段的安全防护。 1.2 CI/CD安全最佳实践的价值 安全…...

无代码物联网实战:基于ESP32与WipperSnapper的泳池水温监测方案
1. 项目概述:告别繁琐编程,用无代码方案守护泳池水温又到了打理泳池的季节,除了常规的清洁和化学平衡,水温其实是个挺关键的指标。水温不仅影响游泳的舒适度,也关系到泳池加热设备的能耗和泳池化学品的反应速率。以前想…...

可逆计算与量子电路合成:改进QM算法与全局优化
1. 可逆计算与量子电路合成基础在量子计算领域,可逆计算是一项关键技术,它不仅是实现低功耗设计的核心方法,更是量子电路合成的基础。传统计算机中的逻辑门大多是不可逆的,这意味着计算过程中会丢失信息并产生热量。而量子计算由于…...

开源无人机任务控制系统:微服务架构与自主飞行开发实战
1. 项目概述:一个开源的无人机任务控制系统如果你和我一样,玩过一段时间无人机,从最初的“一键起飞”到后来想实现一些自动化的航线飞行,你可能会发现,市面上成熟的任务规划软件(比如DJI的Pilot 2或一些地面…...

CircuitPython实战:I2S音频播放与asyncio异步编程构建智能温度监测系统
1. 项目概述与核心价值如果你正在寻找一种能让你的嵌入式项目“开口说话”或者“耳听八方”的方案,I2S音频绝对是你绕不开的技术。不同于我们熟悉的模拟音频,I2S是一种纯粹的数字音频传输协议,它通过三根线——时钟、声道选择和数据——就能传…...

OpenClaw 快速接入 MiniMax 图文指南
OpenClaw连接MiniMax图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 电脑可以正常联网并访问 MiniMax 开放平台。 建议提前准备好 MiniMax 开放平台账号。 如果账户余额为 0.00,需要先充值后再调用接口。 …...

2025最权威的五大降重复率方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于学术探索的终点之处,一篇出色的毕业论文乃是知识跟汗水所凝结而成的&#x…...
)
【负荷预测】基于LSTM-KAN的负荷预测研究(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

ElevenLabs泰米尔语音部署踩坑实录:DNS解析超时、UTF-8 BOM导致静音、方言ID混淆——97%开发者忽略的3个关键参数
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs泰米尔语音部署踩坑实录:DNS解析超时、UTF-8 BOM导致静音、方言ID混淆——97%开发者忽略的3个关键参数 DNS解析超时:被忽略的区域路由策略 ElevenLabs 的 API 在印度…...