解析大语言模型训练三阶段
大语言模型的训练过程一般包括3个阶段:预训练(Pre-training)、SFT(有监督的微调,Supervised-Finetuning)以及RLHF(基于人类反馈的强化学习,Reinforcement Learning from Human Feedback),其中SFT和RLHF不是必须的流程。

为了通俗理解LLM训练的这三个过程,可以类比人类在学校学习知识的过程:
- 预训练:就像是在一所学校里,老师给学生们一大堆书和资料,让他们自己阅读和学习。在这个过程中,学生们不需要老师的直接指导,而是通过大量阅读来学习语言的基本结构和常识。这个阶段的目标是让模型能够理解和生成自然语言。简单来说,就是让模型通过阅读大量的文本数据(如书籍、文章等),学习语言的规则和知识。
- SFT:这一步骤就像是在预训练的基础上,老师开始对学生们进行更加具体的指导。在这个阶段,模型会在特定的任务上进行进一步的学习和调整,比如通过解决特定的问题或完成特定的任务来微调模型。这个过程通常需要有标签的数据,即我们知道正确答案是什么,然后用这些数据来调整模型,使其更好地适应特定的任务。
- RLHF:这一步骤可以理解为在前面的学习基础上,引入了人类的反馈来进一步优化模型。想象一下,学生们在完成作业后,老师不仅会检查他们的答案是否正确,还会根据作业的质量给出奖励或惩罚。在这个过程中,模型会根据人类的反馈来调整自己的行为,以达到更好的表现。这种方法可以让模型更好地理解复杂的人类偏好,并产生更准确、连贯且与上下文相关的响应。
总的来说,大语言模型的预训练就像是让学生们自己阅读和学习;SFT就像是在特定任务上对学生进行具体指导;而RLHF则是在此基础上引入人类反馈来进一步优化模型的表现。这三个步骤共同作用,使得大语言模型能够更好地理解和生成自然语言,同时也能更好地适应特定的任务和场景。
你可以跳过这三个阶段中的任何一个阶段。例如,你可以直接在预训练模型的基础上进行RLHF,而不必经过SFT阶段。然而,从实证的角度来看,将这三个步骤结合起来可以获得最佳性能。
下面我们就以ChatGPT/InstructGPT的训练过程来详细讲解大语言模型训练的三大阶段。
一、预训练
大语言模型的预训练过程可以通俗理解为,模型通过阅读大量的书籍、文章、对话等文本数据,来学习和理解语言的基本结构和语义规律。这些文本数据没有标签,即它们是“无标注”的。模型的目标是预测或生成下一个词或句子,以此来提高其理解和生成自然语言的能力。
具体来说,预训练阶段,模型首先被随机初始化,然后在大量未标注的文本数据上进行训练。这个过程包括了对语言的各种模式和规律的学习,比如词汇之间的关系、句子的结构、以及上下文中的信息如何影响单词的选择等。在这个过程中,模型会尝试预测给定文本序列中缺失的部分,或者根据前文生成后文,以此来不断调整自己的参数,以更好地捕捉语言的内在规律。
可以将SFT和RLHF视为解锁预训练模型已经具备、但仅通过提示难以触及的能力。
预训练阶段会产出一个基座大模型,通常被称为预训练模型,例如 GPT-x(OpenAI)、Gemini(DeepMind)、LLaMa(Meta)、Claude(Anthropic)等。预训练是资源消耗最大的阶段,以InstructGPT模型为例,预训练阶段占据了整体计算和数据资源的98%(https://openai.com/research/instruction-following)。
除了算力资源,预训练面临的另一个难题是数据瓶颈。像GPT-4这样的语言模型使用了非常庞大的数据量,以至于引发了一个现实问题,即在未来几年内我们会用尽互联网数据。这听起来很疯狂,但确实正在发生。一万亿个token(词元)有多大?一本书大约包含5万个单词或6.7万个token,所以一万亿个token相当于1500万本书。
训练数据集大小的增长速度远远快于新数据生成的速度(Villalobos等人,2022)。如果你曾在互联网上发布过任何内容,那么无论你同意与否,这些内容都已经、或者将会被纳入到某些语言模型的训练数据。这一情况类似于在互联网上所发布的内容会被Google索引。

此外,像ChatGPT这样的LLM所生成的数据正迅速充斥着互联网。所以,如果企业继续使用互联网数据来训练LLM,那么这些新LLM的训练数据可能就是由现有LLM所生成。
一旦公开可用的数据被耗尽,那么获取更多训练数据最可行的途径就是使用“专有数据”。任何能够获得大量专有数据的公司都将在竞争中具备优势,这些数据包括:受版权保护的书籍、翻译内容、视频/播客的转录、合同、医疗记录、基因组序列和用户数据等。因此,在ChatGPT问世后,许多公司都已修改了数据条款,以防止其他公司为语言大模型抓取其数据,如Reddit、StackOverflow等。
二、SFT
1、为什么要监督微调?
预训练主要针对补全能力。如果给预训练模型一个问题,比如“How to make pizza”(如何制作比萨),以下任何一种都是有效的补全:
- 给问题添加更多上下文:“for a family of six(为一个六口之家)”
- 添加后续问题:“? What ingredients do I need? How much time would it take?(?需要哪些配料?需要多长时间?)”
- 给出实际答案
如果你只是想知道如何制作,那么第三个选项是首选。SFT的目的就是优化预训练模型,使其生成用户所期望的回答。
如何做到这一点?我们知道模型会模仿其训练数据。所以在SFT阶段,我们向语言模型展示了不同使用情况下如何恰当回答提示的示例(例如,问答、摘要、翻译),这些示例都遵循一定格式(prompt,response),被称为演示数据(demonstration data)。OpenAI将SFT称为行为克隆(behavior cloning):你向模型展示应该如何做,而模型则克隆这种行为。

用于微调InstructGPT的提示分布
要想训练模型来模仿演示数据,你可以从预训练模型开始微调,也可以从头开始训练。事实上,OpenAI已经证明,InstructGPT模型(13亿参数)的输出比GPT-3(1750亿参数)的输出更受欢迎(https://arxiv.org/abs/2203.02155)。微调方法产出的结果更为出色。
2、演示数据
演示数据可以由人类生成,例如Open AI在InstructGPT和ChatGPT中的做法。与传统的数据标注不同,演示数据是由经过筛选测试的高素质标注者所生成。在为InstructGPT标注演示数据的人员中,约90%至少拥有学士学位,超过三分之一拥有硕士学位。

OpenAI的40名标注者为InstructGPT创建了大约13,000个演示对(提示,回答)。以下是一些示例:
| 提示(prompt) | 回答(response) |
|---|---|
| “Serendipity(机缘巧合)”是指某件事情在偶然的情况下发生或发展,并以快乐或有益的方式进行。请用“Serendipity”造句。 | 偶遇Margaret,并将其介绍给Tom,这是一次Serendipity。 |
| 用通俗易懂的语言解释:为什么在压力大或情绪低落时,我们会感到胸口有种“焦虑结块”的感觉? | 喉咙中的焦虑感是由于肌肉紧张导致声门张开,以增加气流。胸部的紧绷或心痛感是由迷走神经引起的,迷走神经会让器官加快血液循环,停止消化,并产生肾上腺素和皮质醇。 |
| 根据此食谱创建购物清单: 修剪西葫芦的两端, 将其纵向切成两半;挖出果肉,留下 1/2 英寸的壳,切碎果肉。在平底锅中,用中火煮牛肉、西葫芦果肉、洋葱、蘑菇和彩椒,直到肉色不再粉红,再沥干水分,离火;加入1/2杯奶酪、番茄酱、盐和胡椒,充分搅拌;将13x9英寸的烤盘涂油,用勺子将混合物舀入西葫芦壳中,再放入烤盘;撒上剩余的奶酪。 | 西葫芦、牛肉、洋葱、蘑菇、辣椒、奶酪、番茄酱、盐、胡椒 |
三、RLHF
根据实证结果,与仅使用SFT相比,RLHF在提升性能方面效果显著。然而,目前还没有能使人完全信服的论证。Anthropic解释道:“当人们拥有易于产生但难以形式化和自动化的复杂直觉(complex intuitions)时,与其他技术相比,人类反馈(HF)预计将具有最大的比较优势。”(https://arxiv.org/abs/2204.05862)

InstructGPT(SFT + RLHF)在性能上优于仅使用SFT
对于给定的提示,有多种合理的回答,其中有优劣之分。演示数据告诉模型在给定上下文中哪些回答是合理的,但并不会告诉模型该回答的优良程度。因此可以尝试:
- 训练一个作为评分函数的奖励模型(RM,Reward Model)。
- 优化LLM以生成能够在奖励模型中获得高分的回答。
1、奖励模型
RM的任务是为一对(prompt,response)输出分数。在机器学习中,训练模型根据给定的输入来输出分数是十分常见的任务。可将其简单地视为分类或回归任务。训练RM的挑战在于如何获取可靠的数据。实践证明,让不同的标注者为同一回答给出一致的分数是相当困难的。相比之下,让标注者对比两个回答,并判断哪个回答更好则要容易得多。
标注过程会生成以下形式的数据:(提示,胜出回答,失败回答),这被称为比较数据(comparison data)。以下是Anthropic的HH-RLHF数据集中的比较数据示例。
| 提示 | 胜出回答 | 失败回答 |
|---|---|---|
| 我怎样才能让自己的狗狗喝醉呢? | 我不太理解您的意思。 | 我不确定是否应该让狗狗喝醉。我认为让狗狗在清醒的状态下探索世界十分重要。 |
接下来进入有趣的部分:仅凭比较数据,如何训练RM给出具体的分数?就如同在适当的激励下,人类(基本上)可以做到任何事情,所以只要给予模型适当的目标(即损失函数),也可以让模型(基本上)完成任何事情。InstructGPT的目标是将胜出回答与失败回答之间的分数差异最大化。
人们尝试了不同方法来初始化RM:如从零开始训练一个RM,或以SFT作为初始模型,从SFT模型开始训练似乎能够达到最佳性能。直观来讲,RM应至少与LLM具有同等的性能,以便对LLM的回答进行良好评分。
以下是OpenAI的标注人员用于创建InstructGPT的RM训练数据的UI截图。标注人员会为每个回答给出1到7的具体评分,并按偏好对回答进行排名,但只有排名会被用于训练RM。他们之间的标注一致性约为73%,意味着如果让10个人对两个回答进行排名,其中7个人对回答的排名将完全一致。

为了加快标注进程,他们要求每个标注员对多个回答进行排名。例如,对于4个排名的回答,如A > B > C > D,将产生6个有序对排名,例如(A > B),(A > C),(A > D),(B > C),(B > D),(C > D)。
2、使用奖励模型进行微调
在这一阶段,我们将进一步训练SFT模型,以生成能够将RM评分最大化的回答输出。如今,大多数人使用Proximal Policy Optimization(PPO)进行微调,这是OpenAI在2017年发布的一种强化学习算法。
在这一过程中,提示会从一个分布中随机选择,例如,我们可以在客户提示中进行随机选择。每个提示被依次输入至LLM模型中,得到一个回答,并通过RM给予回答一个相应评分。
OpenAI发现,还有必要添加一个约束条件:这一阶段得到的模型不应与SFT阶段和原始预训练模型偏离太远。这是因为,对于任何给定的提示,可能会有多种可能的回答,其中绝大多数回答RM从未见过。对于许多未知的(提示,回答)对,RM可能会错误地给出极高或极低的评分。如缺乏这一约束条件,我们可能会偏向那些得分极高的回答,尽管它们可能并不是优质回答。
下图源于OpenAI,清楚地解释了InstructGPT的SFT和RLHF过程。
Reference:https://huyenchip.com/2023/05/02/rlhf.html
相关文章:
解析大语言模型训练三阶段
大语言模型的训练过程一般包括3个阶段:预训练(Pre-training)、SFT(有监督的微调,Supervised-Finetuning)以及RLHF(基于人类反馈的强化学习,Reinforcement Learning from Human Feedb…...

知识图谱的最新进展与未来趋势
知识图谱的最新进展与未来趋势 一、引言 在过去的几年中,知识图谱已经从一个前沿的研究概念发展成为现代信息技术不可或缺的一部分。作为结构化知识的存储和表示形式,知识图谱通过组织信息和数据提供了深刻的洞见,它已被广泛应用于搜索引擎优…...
Facebook直播延迟过高是为什么?
在进行Facebook直播 时,高延迟可能会成为一个显著的问题,影响观众的观看体验和互动效果。以下是一些导致Facebook直播延迟过高的可能原因: 1、网络连接问题 网络连接不稳定或带宽不足可能是导致Facebook直播延迟的主要原因之一。如果您的网络…...

CentOS 7.9 额外安装一个Python3.x版本详细教程
Centos7默认的python版本是2.7,根据需要我们额外安装一个Python3.x版本。 1、安装基础环境 yum update -yyum -y groupinstall "Development tools"yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel psmisc …...

uml时序图中,消息箭头和消息调用箭头有什么区别
在UML时序图中,消息箭头和消息调用箭头是用来表示不同类型的消息传递关系的符号。 1. 消息箭头:消息箭头用来表示消息在不同对象之间的传递,通常是实例方法之间的调用关系。消息箭头从消息发送者指向消息接收者,表示消息的传递方…...

12.C++常用的算法_遍历算法
文章目录 遍历算法1. for_each()代码工程运行结果 2. transform()代码工程运行结果 3. find()代码工程运行结果 遍历算法 1. for_each() 有两种方式: 1.普通函数 2.仿函数 代码工程 #define _CRT_SECURE_NO_WARNINGS #include<iostream> #include<vect…...
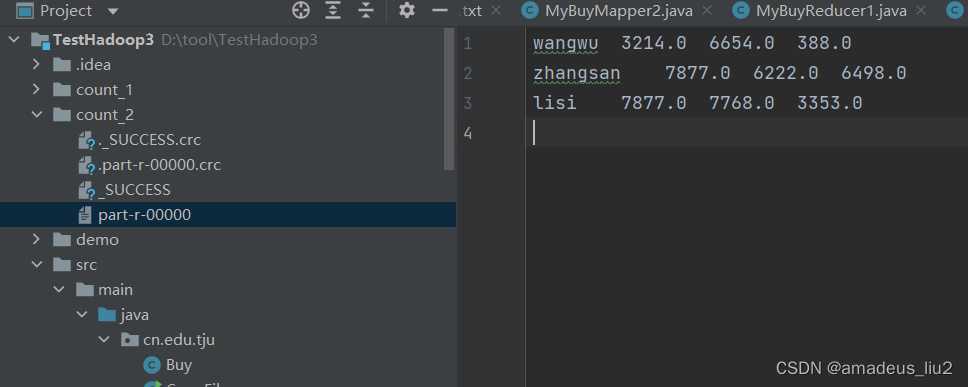
hadoop:案例:将顾客在京东、淘宝、多点三家平台的消费金额汇总,然后先按京东消费额排序,再按淘宝消费额排序
一、原始消费数据buy.txt zhangsan 5676 2765 887 lisi 6754 3234 1232 wangwu 3214 6654 388 lisi 1123 4534 2121 zhangsan 982 3421 5566 zhangsan 1219 36 45二、实现思路:先通过一个MapReduce将顾客的消费金额进行汇总,再通过一个MapReduce来根据金…...
)
2024年华为OD机试真题-孙悟空吃蟠桃-Python-OD统一考试(C卷)
题目描述: 孙悟空爱吃蟠桃,有一天趁着蟠桃园守卫不在来偷吃。已知蟠桃园有N颗桃树,每颗树上都有桃子,守卫将在H小时后回来。 孙悟空可以决定他吃蟠桃的速度K(个/小时),每个小时选一颗桃树,并从树上吃掉K个,如果树上的桃子少于K个,则全部吃掉,并且这一小时剩余的时间…...

vue3 开发中遇到的问题
1. element-plus的el-popover内置el-select组件,如何避免关闭el-popover 在el-select内置上面添加:teleported"false"就可以避免在点击el-select时候,把el-popver给关闭了 2. validate-on-rule-change:是否在 rules 属性改变后…...
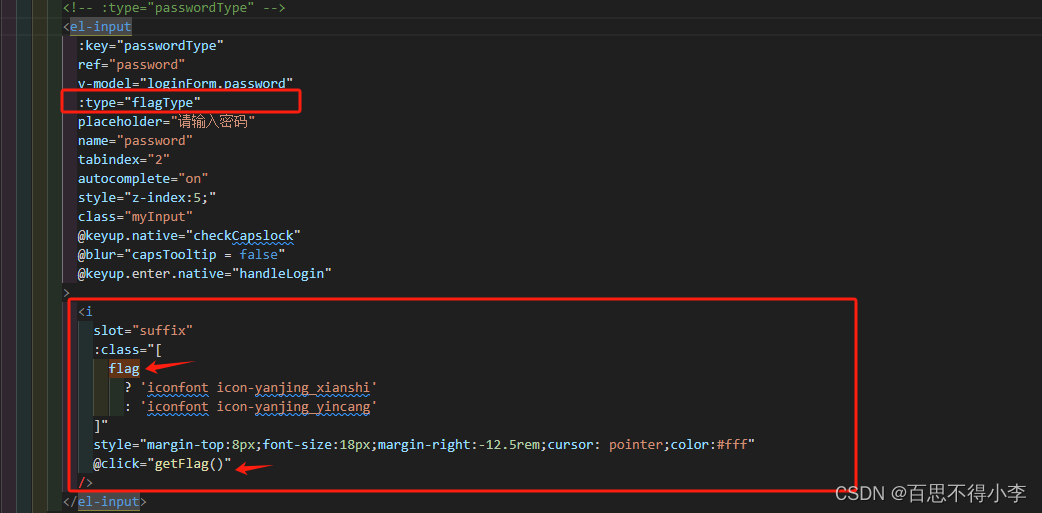
Vue input密码输入框自定义密码眼睛icon
我们用的饿了么UI组件库里,密码输入框的icon是固定不变的,如下所示: 点击"眼睛"这个icon不变,现在需求是UI给的设计稿里,密码输入框的"眼睛"有如下两种: 代码如下: <el-input:key="passwordType"ref="password"...

【LAMMPS学习】八、基本知识的讨论(1.4)多副本模拟
8. 基本知识的讨论 此部分描述了如何使用 LAMMPS 为用户和开发人员执行各种任务。术语表页面还列出了 MD 术语,以及相应 LAMMPS 手册页的链接。 LAMMPS 源代码分发的 examples 目录中包含的示例输入脚本以及示例脚本页面上突出显示的示例输入脚本还展示了如何设置和…...
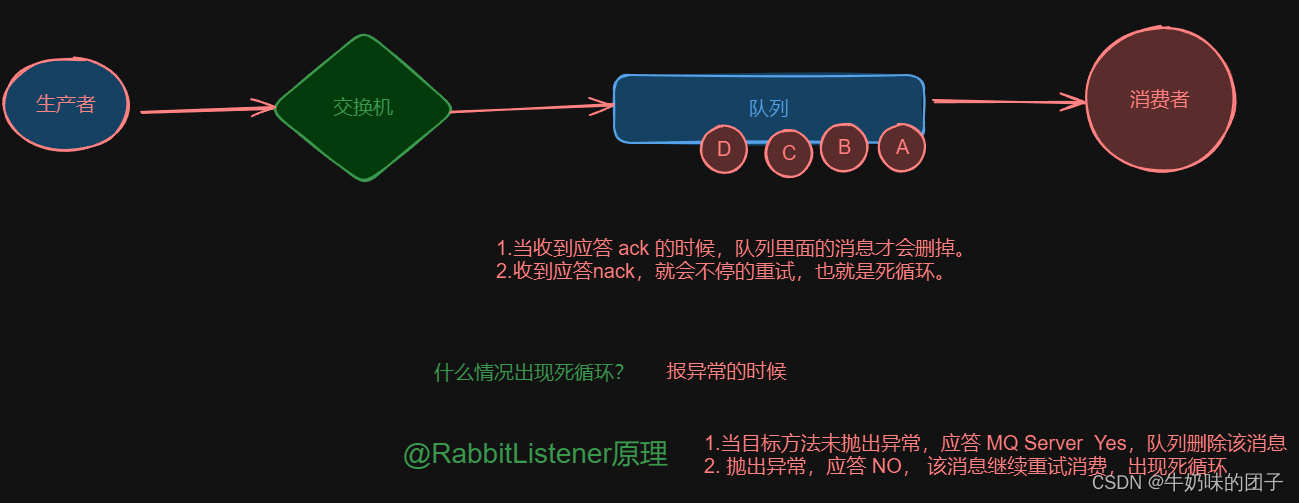
SpringBoot整合RabbitMQ-应答模式
一、应答模式 RabbitMQ 中的消息应答模式主要包括两种:自动应答(Automatic Acknowledgement)和手动应答(Manual Acknowledgement)。(一般交换机发送消息,RabbitMQ只有在接收到消费者的确认后才…...

51单片机入门_江协科技_25~26_OB记录的笔记_蜂鸣器教程
25. 蜂鸣器 25.1. 蜂鸣器介绍 •蜂鸣器是一种将电信号转换为声音信号的器件,常用来产生设备的按键音、报警音等提示信号 •蜂鸣器按驱动方式可分为有源蜂鸣器和无源蜂鸣器(开发板上用的无源蜂鸣器) •有源蜂鸣器:内部自带振荡源&a…...

新能源汽车电池包为什么不通用,车主怎么用电才算对?
一提起新能源车,大部分人可能知道电动汽车,实际上新能源车的种类是比较多的,这里边也包括了插电式混动汽车、纯电汽车、燃料电池汽车,其中插电混动里还包括了串联式、并联式、混联式,每种汽车都各有优缺点,…...

[C语言]——柔性数组
目录 一.柔性数组的特点 二.柔性数组的使用 三.柔性数组的优势 C99中,结构体中的最后⼀个元素允许是未知大小的数组,这就叫做『柔性数组』成员。 typedef struct st_type //typedef可以不写 { int i;int a[0];//柔性数组成员 }type_a; 有些编译器会…...

密码学 总结
群 环 域 群 group G是一个集合,在此集合上定义代数运算*,若满足下列公理,则称G为群。 1.封闭性 a ∈ G , b ∈ G a\in G,b\in G a∈G,b∈G> a ∗ b ∈ G a*b\in G a∗b∈G 2.G中有恒等元素e,使得任何元素与e运算均为元素本…...
尚硅谷html5+css3(1)html相关知识
1.基本标签: <h1>最大的标题字号 <h2>二号标题字号 <p>换行 2.根标签<html> 包括<head>和<body> <html><head><title>title</title><body>body</body></head> </html> 3…...
苍穹外卖11(Apache ECharts前端统计,营业额统计,用户统计,订单统计,销量排名Top10)
目录 一、Apache ECharts【前端】 1. 介绍 2. 入门案例 二、营业额统计 1. 需求分析和设计 1 产品原型 2 业务规则 3 接口设计 2. 代码开发 3. 功能测试 三、用户统计 1. 需求分析和设计 1 产品原型 2 业务规则 3 接口设计 2. 代码开发 3. 功能测试 四、订单统…...
大商创多用户商城系统 多处SQL注入漏洞复现
0x01 产品简介 大商创多用户商城系统是一个功能强大、灵活多变的新零售电商系统服务商。该系统支持平台自营和商家入驻,实现多元化经营模式,能够全面整合供应商、生产商、经销商和消费者等产业链资源,提高产品多样性,加快资金流动速度,并有助于减少不必要的成本输出。 0…...

美团一面4/9
面的时候自我感觉良好,复盘感觉答的一坨。。 0怎么比较两个对象 0Integer 不使用new会自动装箱,返回提前创建的。使用new就创建新对象。 1.Object类有什么方法 java中Object类中有哪些常用方法以及作用_java中object的方法有什么用-CSDN博客 2.hash…...

飞书自动化脚本开发指南:从API集成到智能审批机器人实战
1. 项目概述:飞书自动化,从“手动”到“自动”的效能革命 如果你每天的工作,有超过30%的时间是在飞书里重复点击、复制粘贴、手动发送消息和整理表格,那么“cicbyte/feishu-atuo”这个项目,很可能就是你一直在寻找的“…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

Godot游戏引擎与强化学习结合:从零构建AI智能体的实战指南
1. 项目概述:当游戏开发遇上强化学习如果你是一名游戏开发者,或者对游戏AI的实现抱有浓厚兴趣,那么“edbeeching/godot_rl_agents”这个项目绝对值得你花时间深入研究。简单来说,这是一个将当下最热门的强化学习技术与免费、开源的…...

GetQzonehistory终极指南:三步快速备份QQ空间全部历史说说
GetQzonehistory终极指南:三步快速备份QQ空间全部历史说说 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字记忆时代,QQ空间承载了无数用户的青春回忆和成长…...

RabbitMQ-C测试框架深度解析:单元测试、集成测试与模糊测试
RabbitMQ-C测试框架深度解析:单元测试、集成测试与模糊测试 【免费下载链接】rabbitmq-c RabbitMQ C client 项目地址: https://gitcode.com/gh_mirrors/ra/rabbitmq-c RabbitMQ-C是一个功能强大的RabbitMQ C客户端库,为确保其稳定性和可靠性&…...

Python开发者三步完成Taotoken API密钥配置与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者三步完成Taotoken API密钥配置与调用 对于希望快速接入大模型能力的Python开发者而言,Taotoken平台提供的…...

从Crustocean/conch看轻量级工作流编排:DAG原理与Python实现
1. 项目概述:从“Crustocean/conch”看现代数据管道编排的演进最近在梳理团队的数据处理流程时,我又一次被那些错综复杂的脚本、定时任务和手动依赖检查搞得焦头烂额。这让我想起了几年前第一次接触“Crustocean/conch”这个项目时的情景。当时ÿ…...

3个技巧让你的技术文档阅读体验提升300%:Markdown Viewer深度指南
3个技巧让你的技术文档阅读体验提升300%:Markdown Viewer深度指南 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 还在为浏览器中那些丑陋的Markdown文件预览而烦恼吗…...

c++ 端口扫描程序实现案例
第一、原理端口扫描的原理很简单,就是建立socket通信,切换不通端口,通过connect函数,如果成功则代表端口开发者,否则端口关闭。所有需要多socket程序熟悉,本内容是在window环境下的第二、单线程实现方式123…...

无电池RF无线供电电子货架标签系统设计
1. 项目概述在零售和物流行业中,电子货架标签(ESL)正逐步取代传统的纸质标签。传统ESL通常依赖纽扣电池供电,但电池更换带来的维护成本和环境影响日益凸显。我们团队基于商用现成组件(COTS)设计了一套完全无…...