如何从零开始训练一个语言模型
如何从零开始训练一个语言模型
本文主要三个方面介绍语言模型的训练过程,主要包括:数据集介绍(包含预训练数据和微调数据),数据的预处理,模型训练和微调,但不涉及对齐阶段(RLHF),对齐需要对齐的数据,也需要不同的预处理方式,对齐的目的是构建一个可以与人类价值观保持一致的LLM,减少虚假有害信息的输出。
数据集
Pretrain Data:
预训练数据主要来自从互联网上收集的文本数据,token的规模大概在trillion级别,整体质量偏低。
SFT Data:
SFT(Supervised Fine-Tuning)数据一般由指令,输入,响应组成,指令和输入一起组成prompt,作为模型的输入,响应作为标签。这类数据对质量要求较高,一般由人工构造,也可由GPT4生成。
预处理
分词Tokenizer:把文本序列转为为token序列。
Pretrain Process:
预训练是通过自监督(SSL)的方式训练,也就是预测下个词(token),数据处理方式如下:
def __getitem__(self, index: int):sample = self.data[index]X=np.array(sample[:-1]).astype(np.int64)Y=np.array(sample[1:]).astype(np.int64)return torch.from_numpy(X),torch.from_numpy(Y)
例如:文本分词后:sample = [1, 2, 3, 4, 5, 6]
- x : 1, 2, 3, 4, 5
- y : 2, 3, 4, 5, 6
SFT Process:
SFT(Supervised Fine-Tuning)阶段喂给模型的示例遵循(prompt、response)的格式,prompt包含:指令+输入,也称为指令数据,数据处理方式如下:
- 拼接指令和输入
# 拼接指令和输入字符
q_lst, a_lst = [],[]
for per in data:q=per['instruction']i=per['input']a=per['output']q=q+iq_lst.append(q)a_lst.append(a)
df=pd.DataFrame(columns=['prompt','answer'])
df['prompt']=q_lst
df['answer']=a_lst
- 拼接提示和响应,并添加分割符,同时生成掩码,掩码的作用是在计算loss时屏蔽prompt部分。
def __getitem__(self, index: int):sample = self.df.iloc[index]# 分词tokenizerprompt = self.tokenizer.encode(sample['prompt'],add_special_tokens=False)answer = self.tokenizer.encode(sample['answer'],add_special_tokens=False)# 截断最大长度if len(prompt) > self.prompt_max_len:prompt = prompt[:self.prompt_max_len-2]if len(answer) > self.answer_max_len:answer = answer[:self.answer_max_len-2]# 拼接提示和响应,同时添加特殊token,标识提示和响应结束inputs = prompt+[self.bos]+answer+[self.eos]# 掩码长度=提示长度prompt_length = inputs.index(self.bos)mask_position = prompt_length - 1# 填充至最大长度pad_len = self.max_length - len(inputs)inputs = inputs + [self.pad] * pad_lenif pad_len==0:# 屏蔽提示和填充位置loss_mask = [0]*prompt_length+[1]*(len(inputs[mask_position+1:]))else:loss_mask = [0]*prompt_length+[1]*(len(inputs[mask_position+1:-pad_len])) + [0]*pad_leninputs = np.array(inputs)X=np.array(inputs[:-1]).astype(np.int64)Y=np.array(inputs[1:]).astype(np.int64)loss_mask=np.array(loss_mask[:-1])return torch.from_numpy(X),torch.from_numpy(Y),torch.from_numpy(loss_mask)
例如:bos : 8, eos : 16, pad : 0,max_length = 16
inputs = prompt + [bos] + answer + [eos] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
-
pad_len = 0:
-
prompt = [1, 2, 3, 4, 5, 6, 7]
-
answer = [9, 10, 11, 12, 13, 14, 15]
-
inputs = prompt + [bos] + answer + [eos] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
- x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
- y = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
- mask = [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
-
pad_len > 0:
-
prompt = [1, 2, 3, 4, 5, 6, 7]
-
answer = [9, 10, 11, 12, 13]
-
inputs = prompt + [bos] + answer + [eos] + [pad]*2 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 16, 0, 0]
- x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 16, 0, 0]
- y = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 16, 0, 0]
- mask = [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0]
预训练阶段
预训练阶段采用标准的语言模型建模来最大化目标函数:
L p r e t r a i n ( X ) = ∑ i l o g P ( x i ∣ x i − k , . . . , x i − 1 ; Θ ) L_{pretrain}(\mathcal{X}) = \sum_i logP(x_i|x_{i-k},...,x_{i-1};\mathcal{\Theta}) Lpretrain(X)=i∑logP(xi∣xi−k,...,xi−1;Θ)
-
x = x 1 , . . . , x n \mathcal{x} = {x_1, ..., x_n} x=x1,...,xn :语料
-
k k k : 上下文长度
-
P P P : 条件概率由参数为 Θ \Theta Θ的神经网络模型建模
神经网络模型(包含多个transformer模块),模型输入经过分词后(tokenzier)后的token序列,首先经过嵌入层,然后经过transformer_block,最后经过输出层输出token概率分布。
h 0 = X W e + W p h_0 = XW_e + W_p h0=XWe+Wp
h l = t r a n s f o r m e r b l o c k ( h l − 1 ) , ∀ i ∈ [ 1 , n ] h_l = transformer_{block}(h_{l-1}), \forall i \in [1,n] hl=transformerblock(hl−1),∀i∈[1,n]
P ( u ) = s o f t m a x ( h n W e T ) P(u) = softmax(h_nW_e^T) P(u)=softmax(hnWeT)
- W e W_e We : 嵌入矩阵
- W p W_p Wp : 位置嵌入矩阵
微调阶段
微调阶段的数据前面已经提过,由3部分组成: X = { X i n s t r u c t i o n , X i n p u t , X a n s w e r } \mathcal{X} = \{X_{instruction} , X_{input},X_{answer}\} X={Xinstruction,Xinput,Xanswer}
经过预处理后: X = X i n s t r u c t i o n + X i n p u t + b o s + X a n s w e r + e o s \mathcal{X} = X_{instruction}+X_{input}+bos+X_{answer}+eos X=Xinstruction+Xinput+bos+Xanswer+eos
在微调阶段,模型结构不变,目标改变为:
L s f t ( X a n s w e r ) = ∑ i = l o c a l ( b o s ) l o c a l ( e o s ) l o g P ( x i ∣ x i − k , . . . , x i − 1 ; Θ ) L_{sft}(\mathcal{X_{answer}}) = \sum_{i=local(bos)}^{local(eos)} logP(x_i|x_{i-k},...,x_{i-1};\mathcal{\Theta}) Lsft(Xanswer)=i=local(bos)∑local(eos)logP(xi∣xi−k,...,xi−1;Θ)
在微调阶段只关注answer部分token序列的联合概率分布最大化。
经过SFT(Supervised Fine-Tuning)阶段,通过给模型展示如何正确地响应不同的提示(指令)(例如问答,摘要,翻译等)的示例,模型会学会模仿示例数据中的响应行为,学会问答、翻译、摘要等能力。指令微调优势在于,对于任何特定任务的专用模型,只需要在通用大模型的基础上通过特定任务的指令数据进行微调,就可以解锁LLM在特定任务上的能力,不在需要从头去构建专用的小模型。
相关文章:

如何从零开始训练一个语言模型
如何从零开始训练一个语言模型 #mermaid-svg-gtUlIrFtNPw1oV5a {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-gtUlIrFtNPw1oV5a .error-icon{fill:#552222;}#mermaid-svg-gtUlIrFtNPw1oV5a .error-text{fill:#5522…...

Python 设计一个监督自己的软件1
基本要求:每做一件事,软件就会按照事情权重加相应的分数,总分数也会增加,要可视化页面 使用Python编写的一个简单的日常任务记录和评分系统,包括可视化页面。 首先,我们定义一个任务字典,其中包含各种日常任务及其对应的权重分数…...
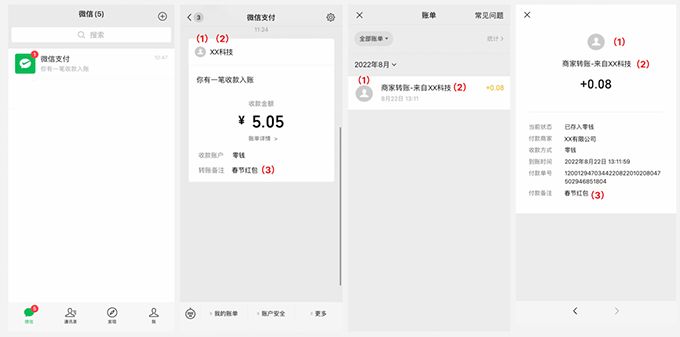
商家转账到零钱权限开通操作攻略
商家转账到零钱是什么? 商家转账到零钱是微信商户号里的一个功能,很早以前叫企业付款到零钱。 从2022年5月18日,原“企业付款到零钱”升级为“商家转账到零钱”,已开通商户的功能使用暂不受影响,新开通商户可前往「产…...
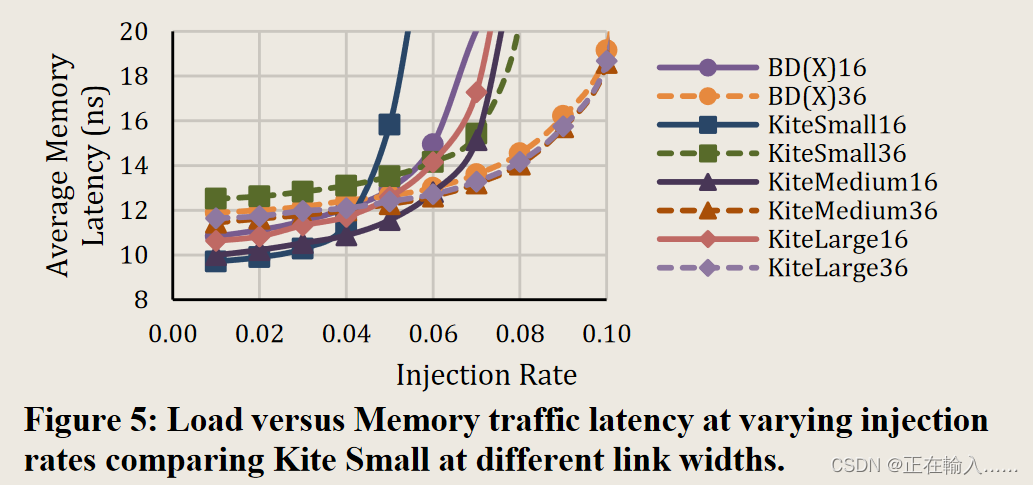
【DAC‘ 2022】Kite: A Family of Heterogeneous Interposer Topologies
Kite: A Family of Heterogeneous Interposer Topologies Enabled via Accurate Interconnect Modeling 背景和动机 背景动机 工作内容 KITE 拓扑 实验方法和评估结果 Kite: A Family of Heterogeneous Interposer Topologies Enabled via Accurate Interconnect Modeling 通…...

数据结构—堆
什么是堆 堆是一种特殊的树形结构,其中每个节点都有一个值。堆可以分为两种类型:最大堆和最小堆。在最大堆中,每个节点的值都大于等于其子节点的值;而在最小堆中,每个节点的值都小于等于其子节点的值。这种特性使得堆…...

Kubernetes学习笔记8
Kubernetes集群客户端工具kubectl 我们已经能够部署Kubernetes了,那么我们如何使用Kubernetes集群运行企业的应用程序呢?那么,我们就需要使用命令行工具kubectl。 kubectl就是控制Kubernetes的驾驶舱,它允许你执行所有可能的Kube…...
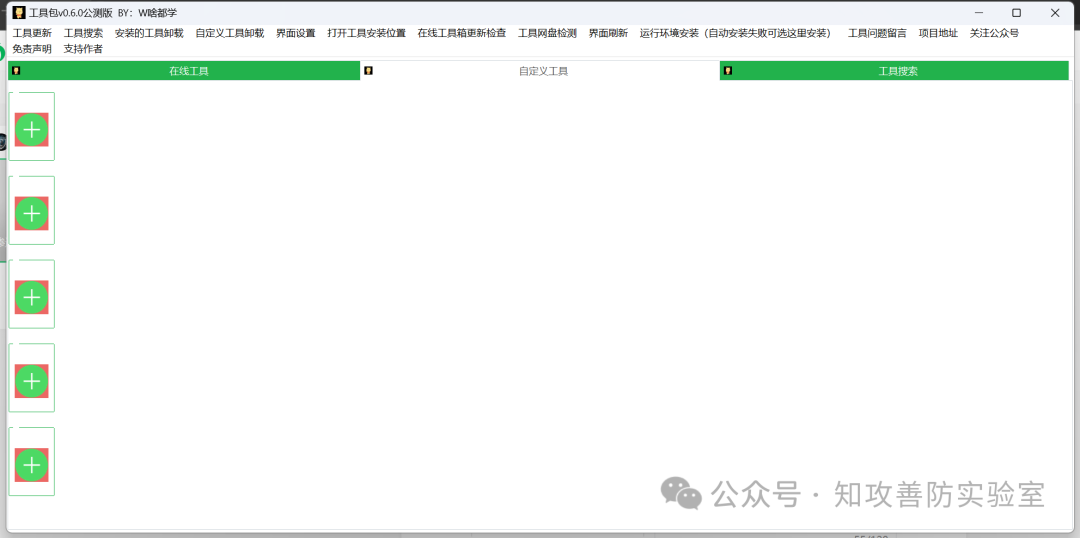
[渗透利器]在线渗透测试工具箱?测评
前言 hxd更新完了在线工具箱,受邀写一下使用体验以及测评 使用体验 这个工具箱设计的比较轻便,以往用过的工具箱大多都是以离线打包的方式发布,该工具箱,作者自己掏钱自己买服务器,自己买带宽,先生大义。…...
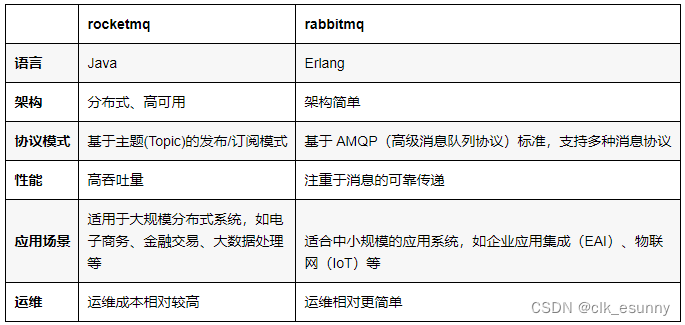
rocketmq和rabbitmq总是分不清?
1. 官方解答 摘自百度搜索: 2. 通俗易懂的回答...

利用Python ARM网关仓储物流AGV小车控制器
在现代智慧物流体系中,高效的信息管理系统是物流中心实现精准跟踪货物、科学管理库存及优化配送路线的关键环节。通过采用ARM架构的工控机或网关,并结合Python的二次开发能力,可以有效集成并强化物流管理系统的数据处理与通信功能,…...
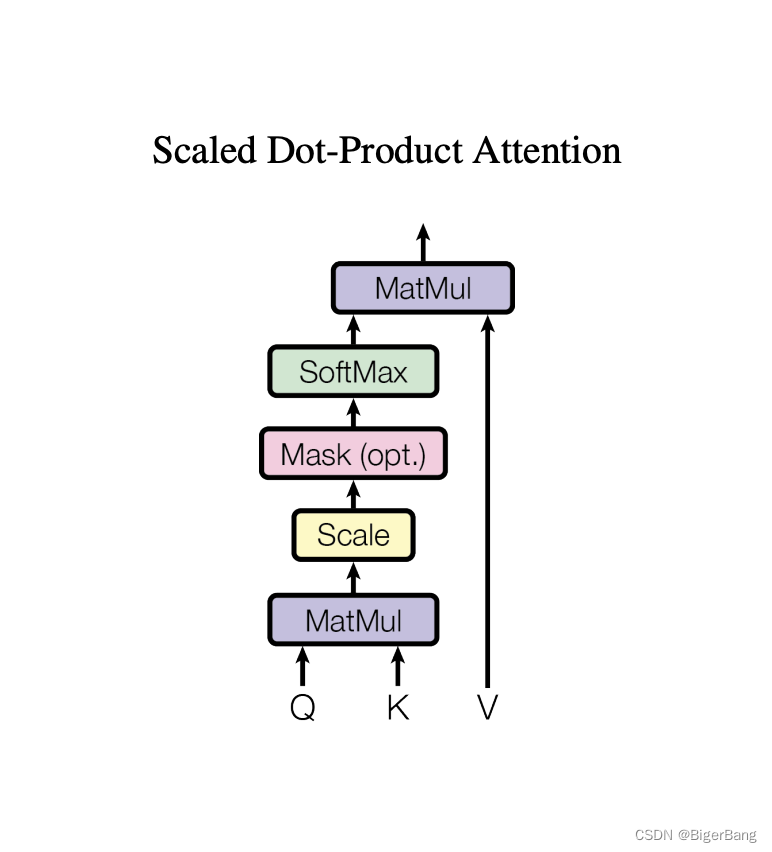
Transformer详解和知识点总结
目录 1. 注意力机制1.1 注意力评分函数1.2 多头注意力(Multi-head self-attention) 2. Layer norm3. 模型结构4. Attention在Transformer中三种形式的应用 论文:https://arxiv.org/abs/1706.03762 李沐B站视频:https://www.bilibi…...

【Ubuntu】update-alternatives 命令详解
1、查看所有候选项 sudo update-alternatives --list java 2、更换候选项 sudo update-alternatives --config java 3、自动选择优先级最高的作为默认项 sudo update-alternatives --auto java 4、删除候选项 sudo update-alternatives --rem…...

数据结构之堆练习题及PriorityQueue深入讲解!
题外话 上午学了一些JavaEE初阶知识,下午继续复习数据结构内容 正题 本篇内容把堆的练习题做一下 第一题 1.下列关键字序列为堆的是:( A ) A: 100,60,70,50,32,65 B: 60,70,65,50,32,100 C: 65,100,70,32,50,60 D: 70,65,100,32,50,60 E: 32,50,100,70,65,60 …...

MySQL——Linux安装包
一、下载安装包 MySQL下载路径: MySQL :: MySQL Downloads //默认下载的企业版MySQL 下载社区版MySQL MySQL :: MySQL Community Downloads 1、源码下载 2、仓库配置 3、二进制安装包 基于官方仓库安装 清华centos 软件仓库: Index of /cen…...

MySQL学习笔记(数据类型, DDL, DML, DQL, DCL)
Learning note 1、前言2、数据类型2.1、数值类型2.2、字符串类型2.3、日期类型 3、DDL总览数据库/表切换数据库查看表内容创建数据库/表删除数据库/表添加字段删除字段表的重命名修改字段名(以及对应的数据类型) 4、DML往字段里写入具体内容修改字段内容…...
)
Asible管理变量与事实——管理变量(1)
Ansible简介 Ansible支持利用变量来储存值,并在Ansible项目的所有文件中重复使用这些值。这可以简化项目的创建和维护,并减少错误的数量。 通过变量,您可以轻松地在Ansible项目中管理给定环境的动态值。例如,变量可能包含下面这些…...

【微服务】------微服务架构技术栈
目前微服务早已火遍大江南北,对于开发来说,我们时刻关注着技术的迭代更新,而项目采用什么技术栈选型落地是开发、产品都需要关注的事情,该篇博客主要分享一些目前普遍公司都在用的技术栈,快来分享一下你当前所在用的技…...
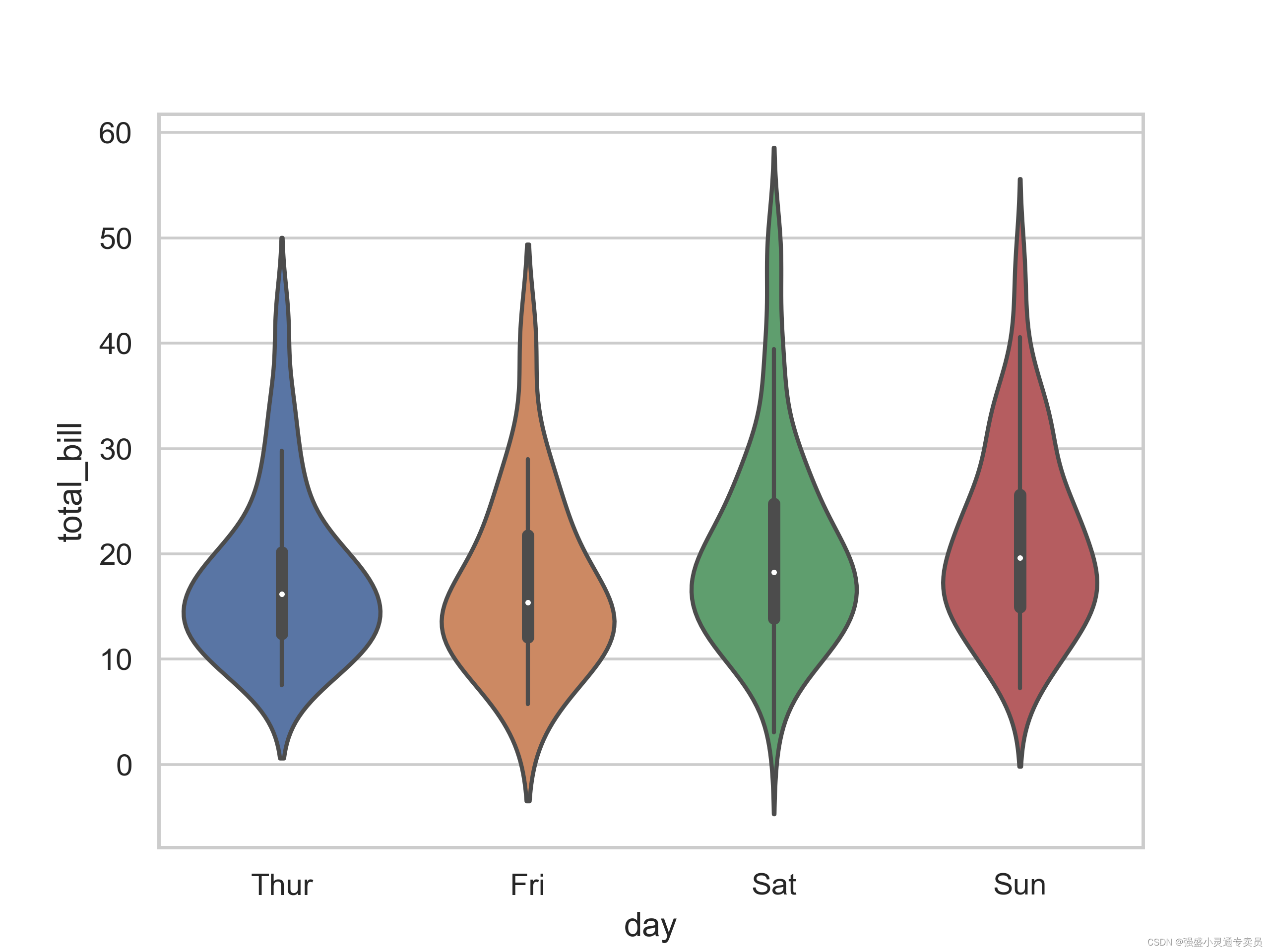
【SCI绘图】【小提琴系列1 python】绘制按分类变量分组的垂直小提琴图
SCI,CCF,EI及核心期刊绘图宝典,爆款持续更新,助力科研! 本期分享: 【SCI绘图】【小提琴系列1 python】绘制按分类变量分组的垂直小提琴图,文末附完整代码 小提琴图是一种常用的数据可视化工具…...
docker------docker入门
🎈个人主页:靓仔很忙i 💻B 站主页:👉B站👈 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:Linux 🤝希望本文对您有所裨益,如有不足之处&#…...

终极数据传输隐秘通道
SOCKS5代理作为网络请求中介的高级形态,提供了一种方法,通过它,数据包在传达其最终目的地前,首先经过一个第三方服务器。这种代理的先进之处在于其对各种协议的支持,包括HTTP、FTP和SMTP,以及它的认证机制&…...

Qt中的事件与事件处理
Qt框架中的事件处理机制是其GUI编程的核心部分,它确保了用户与应用程序之间的交互能够得到正确的响应。以下是对Qt事件处理机制的详细讲解以及提供一些基本示例。 1. 事件与事件处理简介 事件:在Qt中,所有的事件都是从QEvent基类派生出来的&…...

别再傻傻分不清了!一张图看懂CRT、PEM、PFX、P7B证书格式的区别与应用场景
数字证书格式全解析:CRT、PEM、PFX、P7B的核心差异与实战选择 当你第一次在服务器上配置SSL证书时,面对CRT、PEM、PFX、P7B这些后缀名,是不是感觉像在解密码?上周我帮一个创业团队迁移服务器,他们的CTO拿着五个不同格式…...

MobaXterm远程桌面实战:在Ubuntu上配置与连接RDP服务
1. 为什么选择MobaXterm连接Ubuntu远程桌面 作为一名常年和Linux服务器打交道的开发者,我深知纯命令行操作有时会遇到效率瓶颈。特别是当需要处理图形界面应用或者进行复杂配置时,SSH终端就显得力不从心了。这时候,RDP远程桌面协议就成了救命…...

Cytoscape美化进阶:用cytoNCA等5款核心插件深度分析你的生物网络
Cytoscape美化进阶:用cytoNCA等5款核心插件深度分析你的生物网络 生物网络分析早已超越了简单的可视化阶段。当你在Cytoscape中绘制出第一个蛋白质相互作用网络时,那种成就感很快会被一个更迫切的问题取代:这些连接背后隐藏着怎样的生物学故事…...
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题 计算机视觉领域正经历一场由Transformer架构引领的革命。从最初的图像分类任务到如今的复杂场景理解,Transformer以其强大的全局建模能力不断刷新着各项基准。而在天气…...
)
Spring AI完整学习路线:从Java开发到AI Agent的进阶之路(附15篇实战教程)
🔥 Java开发者必看!Spring AI完整学习路线:从CRUD到AI Agent的蜕变之路(2026终极指南) 作者:12年OTA公司资深程序员 技术栈:Spring Boot 3.5.9 Spring AI 1.1.4 Reactor 多模型集成 阅读时间…...

百度网盘Mac版终极加速方案:免费解锁SVIP级下载体验
百度网盘Mac版终极加速方案:免费解锁SVIP级下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的蜗牛下载速度而烦…...

反向海淘代购集运系统三种搭建路径对比:自研、开源二开、SaaS
「技术、数据、接口、系统问题欢迎留言私信沟通」引言:标准业务架构# 系统演示、API测试控制台:http://console.open.onebound.cn/console/?iRookie用户层(Web / App / 小程序)↓ 网关层(Nginx / Gateway)…...

OpenHarmony Rust开发实战:GN构建配置与FFI互操作指南
1. 项目概述:为什么要在OpenHarmony里搞Rust?最近在折腾OpenHarmony开发板,想把一些对性能和安全性要求比较高的模块用Rust重写,结果发现官方文档里关于Rust构建的部分讲得比较零散。踩了一圈坑之后,我决定把OpenHarmo…...

拯救你的C盘空间:用FreeMove实现无痛文件迁移的完整指南
拯救你的C盘空间:用FreeMove实现无痛文件迁移的完整指南 【免费下载链接】FreeMove Move directories without breaking shortcuts or installations 项目地址: https://gitcode.com/gh_mirrors/fr/FreeMove 你是否经常看到C盘变红的警告,却不敢随…...

问卷星 vs 腾讯问卷 vs 金数据:2026主流问卷工具AI开放能力最新横评
作为问卷调研行业的深度观察者,老N近期注意到调研工具链正在发生一场静悄悄的革命。最近,问卷星正式上线了AI工具包(wjx-ai-kit),其CLI(命令行工具)支持多达67个子命令,并适配了Clau…...