深度剖析C语言预处理
致前行的人:
人生像攀登一座山,而找寻出路,却是一种学习的过程,我们应当在这过程中,学习稳定冷静,学习如何从慌乱中找到生机。

目录
1.程序翻译过程:
2.字符串宏常量
3.用宏定义充当注释符号
4.用define宏定义表达式
5.宏定义中的空格
6.宏定义的位置
7.#undef
8.条件编译
8.1条件编译如何使用?
8.2为何要有条件编译?
8.3条件编译都在哪些地方用?
9.文件包含
10.#error 预处理
12.#line 预处理
13.#pragma 预处理
14.#运算符
15.##预算符
1.程序翻译过程:
程序从文本文件到可执行二进制程序需要经历以下四个阶段:
预处理-E :头文件展开,去注释,宏替换,条件编译
编译-S : 将干净的C语言,编译成为汇编语言
汇编-c :将汇编翻译成为目标二进制文件
链接 :将目标二进制文件与相关库链接,形成可执行程序
本篇重点讲解第一个预处理阶段的所有细节!
2.字符串宏常量
1.字符串没有带双引号,直接报错:
#include<stdio.h>
//#define PATH /user/bin err
#define PATH "/user/bin"
int main()
{printf("%s\n", PATH);return 0;
}结论:宏定义代表字符串的时候,一定要带上双引号
2.可以用\续行
#include<stdio.h>
#define PATH "/user/bin/\
test.c"
int main()
{printf("%s\n", PATH);return 0;
}3.用宏定义充当注释符号
//当前,我们用BSC充当C++风格的注释
#define BSC //
int main()
{BSC printf("hello world\n");return 0;
}在vs上编译运行,发现是直接报错的:

切换平台在Linux上做测试:
直接编译运行:发现也是错误的
 下面不让程序直接编译运行,而是让程序在预处理完之后就停下来
下面不让程序直接编译运行,而是让程序在预处理完之后就停下来
测试发现并没有报错:

打开预处理完之后生成的文件test.i:

倘若,先执行宏替换,那么先得到的代码应该是
int main()
{ //将BSC替换成为‘//’// printf("hello world\n"); return 0;
}
再执行去注释,那么代码最终的样子,应该是
int main()
{ return 0; //printf被注释掉
}并且,最终运行的时候,应该没有输出
但实际上,并非如此
实际上,是先执行去注释,在进行宏替换
先去掉宏后面的//,因为是注释
#define BSC // //最终宏变成了#define BSC
int main()
{BSC printf("hello world\n"); //因为BSC是空,所以在进行替换之后,就是printf("hello world\n");return 0;
}结论:预处理期间:先执行去注释,在进行宏替换
4.用define宏定义表达式
1.用#define定义单条语句:
#define SUM(x) (x)+(x)
int main()
{printf("%d\n", SUM(10));return 0;
}
运行截图:

#define定义的表达式是在预处理阶段完成替换的

2.用#define定义多条语句:
//该宏最大的特征是,替换的不是单个变量/符号/表达式,而是多行代码
#define INIT_VALUE(a,b)\a = 0;\b = 0;
int main()
{int flag = 0;scanf("%d", &flag);int a = 100;int b = 200;printf("before: %d, %d\n", a, b);if (flag)INIT_VALUE(a, b);elseprintf("error!\n");printf("after: %d, %d\n", a, b);return 0;
}编译运行:直接报错

因为#define是在预处理阶段完成替换的,下面在Linux平台下观察一下预处理完成之后生成的test.i文件:
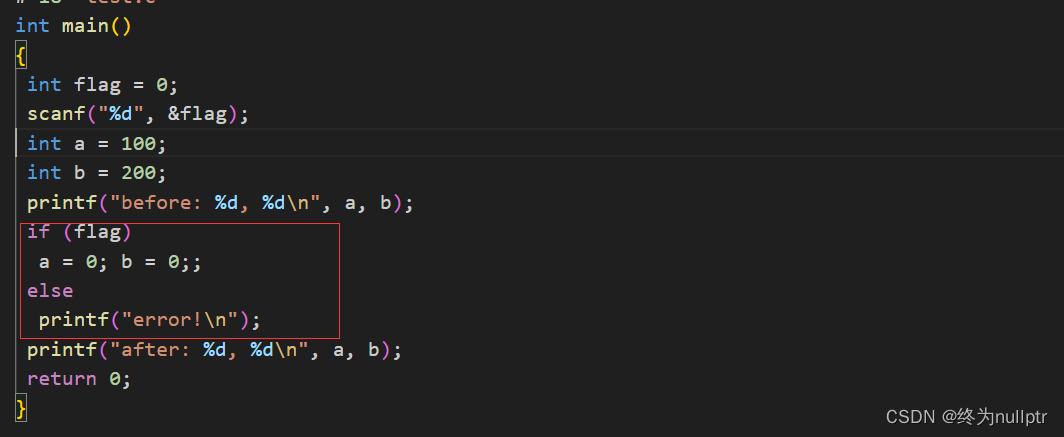
通过观察上图可以发现,完成宏替换之后if后面跟了多条语句,因为if是没有带{}的,所以只能跟一条语句,当有多条语句时,else就匹配失败,出现报错
解决方法1
在编写的时候带上{}:
#define INIT_VALUE(a,b)\a = 0;\b = 0;
int main()
{int flag = 0;scanf("%d", &flag);int a = 100;int b = 200;printf("before: %d, %d\n", a, b);if (flag){INIT_VALUE(a, b);}elseprintf("error!\n");printf("after: %d, %d\n", a, b);return 0;
}运行成功:

解决方法2
在编写宏的时候,用do-while-0的结构定义多条语句:
#define INIT_VALUE(a,b)\
do\
{\a = 0; \b = 0;\
}while(0)
int main()
{int flag = 0;scanf("%d", &flag);int a = 100;int b = 200;printf("before: %d, %d\n", a, b);if (flag)INIT_VALUE(a, b);elseprintf("error!\n");printf("after: %d, %d\n", a, b);return 0;
}运行截图:

5.宏定义中的空格
#define INC(a) a++ //定义时能带空格
int main()
{int i = 0;INC (i); //使用可以带空格,但是严重不推荐(不要处处显得自己不一样哦)printf("%d\n", i);
}运行截图:

6.宏定义的位置
1.宏只能在main上面定义吗?
答案是否定的,如图所示:可以在不同文件中定义,在使用的时候只需要包含头文件即可

2. 在一个源文件内,宏的有效范围是什么?
答案是:在一个源文件内,宏可以在任意的位置定义,包括函数体内部,全局和局部中,但是从定义出往下有效,往上是无效的
如图所示:test.c
#define M 10
int main()
{printf("%d, %d\n", M, N);
#define N 100printf("%d, %d\n", M, N);return 0;
}test.i:
int main()
{printf("%d, %d\n", 10, N);printf("%d, %d\n", 10, 100);return 0;
}
7.#undef
#undef的作用:
test.c:
#define M 10
int main()
{
#define N 100printf("%d, %d\n", M, N);printf("%d, %d\n", M, N);printf("%d, %d\n", M, N);#undef M //取消M
#undef N //取消Nprintf("%d, %d\n", M, N);printf("%d, %d\n", M, N);printf("%d, %d\n", M, N);return 0;
}test.i:
int main()
{printf("%d, %d\n", 10, 100);printf("%d, %d\n", 10, 100);printf("%d, %d\n", 10, 100);printf("%d, %d\n", M, N);printf("%d, %d\n", M, N);printf("%d, %d\n", M, N);return 0;
}
结论:undef是取消宏的意思,可以用来限定宏的有效范围。
8.条件编译
8.1条件编译如何使用?
#ifdef - #else - #endif
int main()
{
#ifdef PRINTprintf("hello world!\n");printf("hello byte!\n");
#elseprintf("Non Message!\n");
#endifreturn 0;
}当前,PRINT并没有被定义,所以输出#else部分的内容
运行截图:

#ifndef - #else - #endif
int main()
{
#ifndef DEBUGprintf("hello debug\n");
#elseprintf("hello release\n");
#endifreturn 0;
}当前,DEBUG并没有被定义,所以输出#ifndef部分的内容
运行截图:

同样上述代码,使用#if可以有很多中写法,下面是写法大全
1.单个条件的情况:
#define DEBUG 1
int main()
{
#if DEBUGprintf("hello bit\n");
#endifreturn 0;
}2.带else的情况:
//报错
//#define DEBUG
//定义了,为假
#define DEBUG 0
//定义了,为真
//#define DEBUG 1
int main()
{
#if DEBUGprintf("hello world\n");
#elseprintf("hello C\n");
#endifreturn 0;
}3.多条件的情况:
//#define DEBUG 0
//#define DEBUG 1
//#define DEBUG 2
#define DEBUG 3
int main()
{
#if DEBUG==0printf("hello C 0\n");
#elif DEBUG==1printf("hello C 1\n");
#elif DEBUG==2printf("hello C 2\n");
#elseprintf("hello else\n");
#endifreturn 0;
}4.#if模拟#ifdef:
#define DEBUG
int main()
{
#if defined(DEBUG)printf("hello debug\n");
#elseprintf("hello release\n");
#endifreturn 0;
}5.#if模拟#ifndef:
int main()
{
#if !defined(DEBUG)printf("hello debug\n");
#elseprintf("hello release\n");
#endifreturn 0;
}6.其它使用方法:
#define C
#define CPP
int main()
{
#if defined(C) && defined(CPP)printf("hello c && cpp\n");
#elseprintf("hello other\n");
#endifreturn 0;
}#define C
//#define CPP
int main()
{
#if defined(C) || defined(CPP)printf("hello c&&cpp\n");
#elseprintf("hello other\n");
#endifreturn 0;
}#define C
#define CPP
int main()
{
#if !(defined(C) || defined(CPP))printf("hello c&&cpp\n");
#elseprintf("hello other\n");
#endifreturn 0;
}#define C
#define CPP
int main()
{
#if defined(C)
#if defined (CPP)printf("hello CPP\n");
#endifprintf("hello C\n");
#elseprintf("hello other\n");
#endifreturn 0;
}8.2为何要有条件编译?
本质认识:条件编译,其实就是编译器根据实际情况,对代码进行裁剪。而这里“实际情况”,取决于运行平台,代码本身的业务逻辑等。
可以认为有两个好处:
1. 可以只保留当前最需要的代码逻辑,其他去掉。可以减少生成的代码大小
2. 可以写出跨平台的代码,让一个具体的业务,在不同平台编译的时候,可以有同样的表现
8.3条件编译都在哪些地方用?
举一个例子吧
我们经常听说过,某某版代码是完全版/精简版,某某版代码是商用版/校园版,某某软件是基础版/扩展版等。其实这些软件在公司内部都是项目,而项目本质是有多个源文件构成的。所以,所谓的不同版本,本质其实就是功能的有无,在技术层面上,公司为了好维护,可以维护多种版本,当然,也可以使用条件编译,你想用哪个版本,就使用哪种条件
进行裁剪就行。
著名的Linux内核,功能上,其实也是使用条件编译进行功能裁剪的,来满足不同平台的软件。
9.文件包含
1. 为何所有头文件,都推荐写入下面代码?本质是为什么?
#ifndef XXX
#define XXX//TODO#endif2. #include究竟干了什么?
形成的.i文件,发现文件大小比我们实际的代码要大得多
结论:#include本质是把头文件中相关内容,直接拷贝至源文件中!
那么,在多文件包含中,有没有可能存在头文件被重复包含,乃至被重复拷贝的问题呢?
#ifndef _TEST_H_
#define _TEST_H_ //注意,这里没有包含<stdio.h>防止信息太多干扰我们
void show(); //任意一个函数声明
#endif故意包含两次:
#include"test.h"
#include"test.h"
int main()
{return 0;
}
去掉条件编译:

void show(); //内容被拷贝第一次
# 2 "test.c" 2
# 1 "test.h" 1
void show(); //内容被拷贝第二次
# 3 "test.c" 2
int main()
{return 0;
}结论:所有头文件都必须带上条件编译,防止被重复包含!
那么,重复包含一定报错吗??不会!
重复包含,会引起多次拷贝,主要会影响编译效率!
10.#error 预处理
//#define __cplusplus
int main()
{
#ifndef __cplusplus
#error 不是C++
#endifreturn 0;
}
结论:核心作用是可以进行自定义编译报错。
12.#line 预处理
本质其实是可以定制化你的文件名称和代码行号,很少使用
#include <stdio.h>
int main()
{printf("%s, %d\n", __FILE__, __LINE__); //C预定义符号,代表当前文件名和代码行号
#line 60 "hehe.h" //定制化完成printf("%s, %d\n", __FILE__, __LINE__);return 0;
}运行截图:

13.#pragma 预处理
#pragma message()作用:可以用来进行对代码中特定的符号(比如其他宏定义)进行是否存在进行编译时消息提醒
#include <stdio.h>
#define M 10
int main()
{
#ifdef M
#pragma message("M宏已经被定义了")
#endifreturn 0;
}运行截图:

14.#运算符
首先补充,临近字符串自动连接特性:
int main()
{printf("hello"" world""\n");const char* msg = "hello""bit""\n";printf(msg);return 0;
}运行截图:

#:可以将数字转换成字符串:
#include<string.h>
#define STR(s) #s
int main()
{char buf[64] = { 0 };strcpy(buf, STR(1234));printf("%s\n", buf);return 0;
}运行截图:
![]()
15.##预算符
##的作用:将##相连的两个符号,连接成为一个符号
#define CONT(x,n) (x##e##n)
int main()
{printf("%lf\n", CONT(2, 5));计算浮点数科学计数法,相当于2 * (10^5)return 0;
}运行截图:

相关文章:
深度剖析C语言预处理
致前行的人: 人生像攀登一座山,而找寻出路,却是一种学习的过程,我们应当在这过程中,学习稳定冷静,学习如何从慌乱中找到生机。 目录 1.程序翻译过程: 2.字符串宏常量 3.用宏定义充当注释符号 4…...
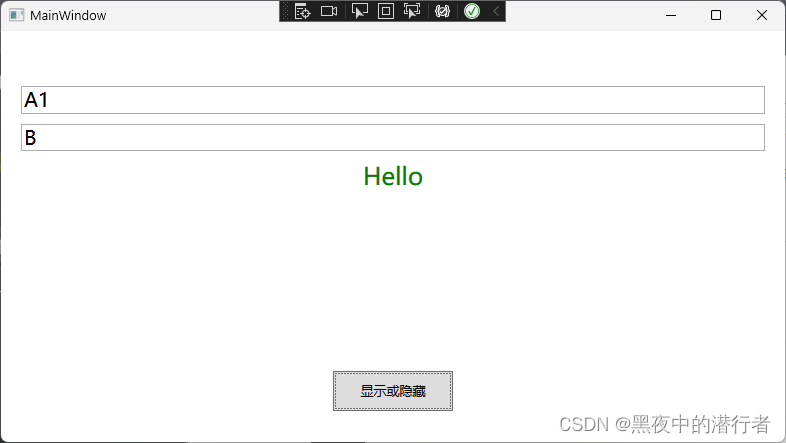
【WPF 值转换器】ValueConverter 进阶用法
【WPF 值转换器】ValueConverter 进阶用法介绍基类实现子类实现效果介绍 值转换器在WPF开发中是非常常见的,当然不仅仅是在WPF开发中。值转换器可以帮助我们很轻松地实现,界面数据展示的问题,如:模块隐藏显示、编码数据展示为可读…...
Vue2的基本使用
一、vue的基本使用 第一步 引入vue.js文件 <script src"https://cdn.staticfile.org/vue/2.7.0/vue.min.js"></script> 或者<script src"./js/vue.js"></script> 第二步 在body中设置一个挂载点 {{msg}} <div id"app…...

【云原生kubernetes】k8s数据存储之Volume使用详解
目录 一、什么是Volume 二、k8s中的Volume 三、k8s中常见的Volume类型 四、Volume 之 EmptyDir 4.1 EmptyDir 特点 4.2 EmptyDir 实现文件共享 4.2.1 关于busybox 4.3 操作步骤 4.3.1 创建配置模板文件yaml 4.3.2 创建Pod 4.3.3 访问nginx使其产生访问日志 4.3.4 …...
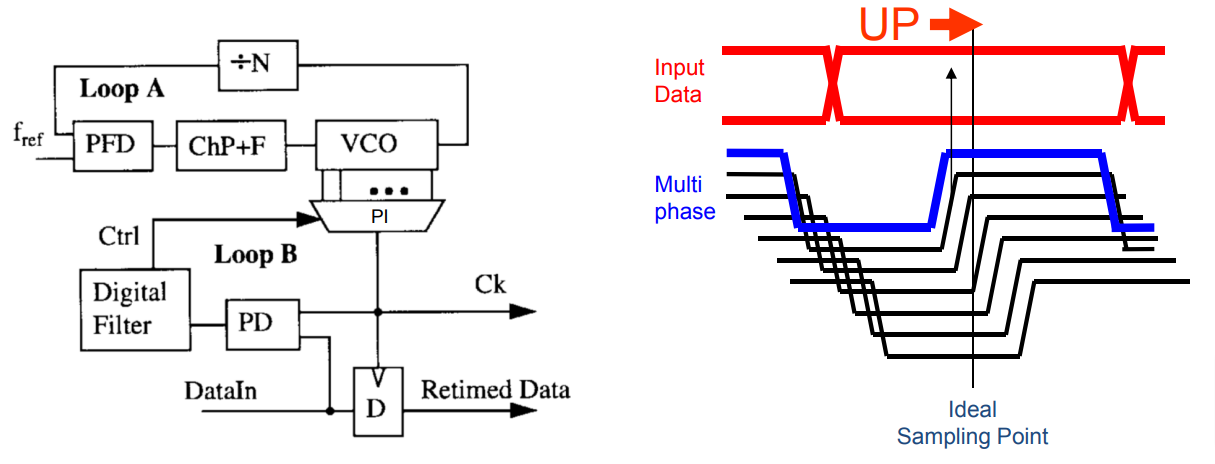
SerDes---CDR技术
1、为什么需要CDR 时钟数据恢复主要完成两个工作,一个是时钟恢复,一个是数据重定时,也就是数据的恢复。时钟恢复主要是从接收到的 NRZ(非归零码)码中将嵌入在数据中的时钟信息提取出来。 2、CDR种类 PLL-Based CDROve…...

如何实现在on ethernetPacket中自动回复NDP response消息
对于IPv4协议来说,如果主机想通过目标ipv4地址发送以太网数据帧给目的主机,需要在数据链路层填充目的mac地址。根据目标ipv4地址查找目标mac地址,这是ARP协议的工作原理 对于IPv6协议来说,根据目标ipv6地址查找目标mac地址,它使用的不是ARP协议,而是邻居发现NDP(Neighb…...
CSS清楚浮动
先看看关于浮动的一些性质 浮动使元素脱离文档流 浮动元素可以设置宽高,在CSS中,任何元素都可以浮动,浮动元素会生成一个块级框,而不论其本身是何种元素。 如果没有给浮动元素指定高度,,那么它会以内容的…...
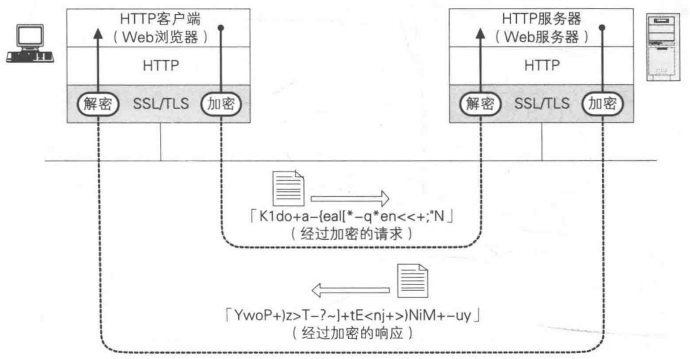
HTTPS详解(原理、中间人攻击、CA流程)
摘要我们访问浏览器也经常可以看到https开头的网址,那么什么是https,什么是ca证书,认证流程怎样?这里一一介绍。原理https就是httpssl,即用http协议传输数据,数据用ssl/tls协议加密解密。具体流程如下图&am…...
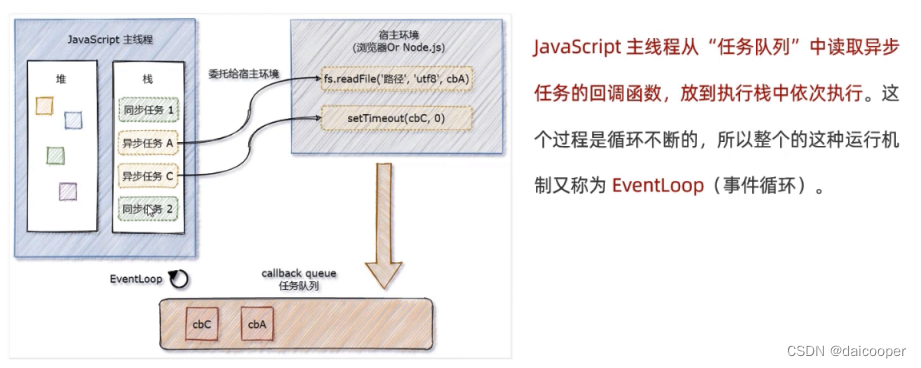
EventLoop机制
JavaScript 是单线程的语言 JavaScript 是一门单线程执行的编程语言。也就是说,同一时间只能做一件事情。 单线程执行任务队列的问题: 如果前一个任务非常耗时,则后续的任务就不得不一直等待,从而导致程序假死的问题。 同步任…...
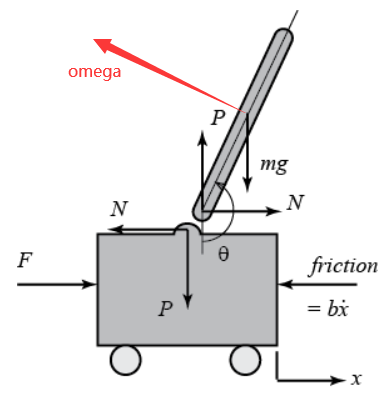
倒立摆建模
前言 系统由一辆具有动力的小车和安装在小车上的倒立摆组成,系统是不稳定,我们需要通过控制移动小车使得倒立摆保持平衡。 具体地,考虑二维情形如下图,控制力为水平力FFF,输出为角度θ\thetaθ以及小车的位置xxx。 力…...

SpringSecurity支持WebAuthn认证
WebAuthn是无密码身份验证技术,解决了密码泄露的风险,主流的浏览器都支持。有很多开源的类库实现了WebAuthn规范,Java下流行的类库有:webauthn4jjava-webauthn-serververtx-authSpring Security官方暂时未支持WebAuthn,…...
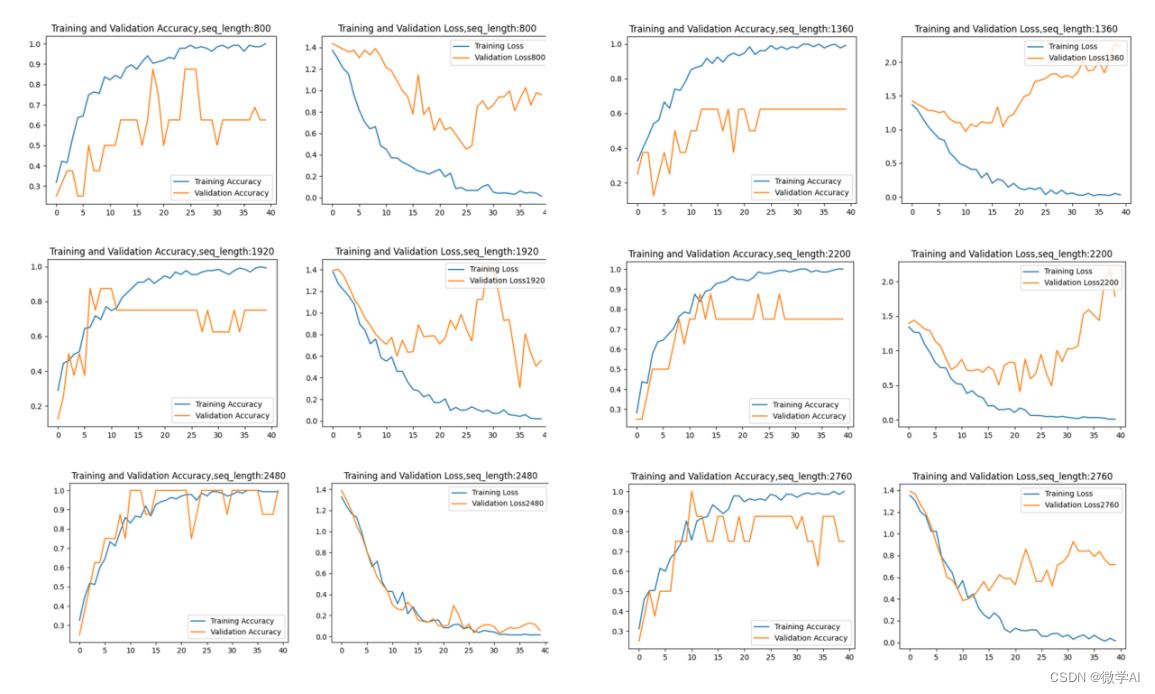
深度学习技巧应用3-神经网络中的超参数搜索
大家好,我是微学AI,今天给大家带来深度学习技巧应用3-神经网络中的超参数搜索。 在深度学习任务中,一个算法模型的性能往往受到很多超参数的影响。超参数是指在模型训练之前需要我们手动设定的参数,例如:学习率、正则…...
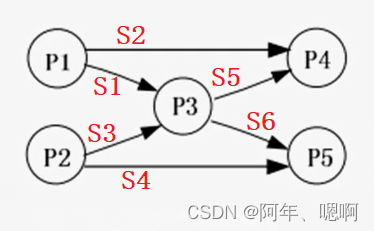
【信号量机制及应用】
水善利万物而不争,处众人之所恶,故几于道💦 目录 一、信号量机制 二、信号量的应用 >利用信号量实现进程互斥 >利用信号量实现前驱关系 >利用记录型信号量实现同步 三、例题 四、参考 一、信号量机制 信号量是操作系统提…...

围棋高手郭广昌的“假眼”棋局
(图片来源于网络,侵删)文丨熔财经作者|易不二2022年,在复星深陷债务压顶和变卖资产漩涡的而立之年,“消失”已久的郭广昌,在质疑与非议声中回国稳定军心,强调复星将在未来的五到十年迎来一个全新…...

学成教育-统一异常处理实现
一、统一异常处理实现 统一在base基础工程实现统一异常处理,各模块依赖了base基础工程都 可以使用。 首先在base基础工程添加需要依赖的包: <dependency><groupId>org.springframework</groupId><artifactId>spring-web</…...
JNI内通过参数形式从C/C++中传递string类型数据至Java层
目录 0 前言 1 string类型参数形式传值 2 测试和结果 0 前言 类似之前我写过的两篇文章:一篇介绍了在JNI中基础类型int的传值方式;一篇详细梳理了在JNI层中多维数组的多种传值方式。 JNI内两种方式从C/C中传递一维、二维、三维数组数据至Java层详细…...
自动化测试——执行javaScript脚本
文章目录一、点击元素(对应的click())二、input标签对应的值(对应的send_keys())修改时间控件的属性值:三、元素的文本属性四、js脚本滚动操作一、点击元素(对应的click()) 使用场景:当使用显性等待不能解决问题时 代码中实现点击…...

常用十种算法滤波
十种算法滤波1. 限幅滤波法(又称程序判断滤波法)2. 中位值滤波法3. 算术平均滤波法4. 递推平均滤波法(又称滑动平均滤波法)5. 中位值平均滤波法(又称防脉冲干扰平均滤波法)6. 限幅平均滤波法7. 一阶滞后滤波…...

IO多路复用
一、概述 IO多路复用:进程同时检查多个文件描述符,以找出他们中的任何一个是否可执行IO操作。 核心:同时检查多个文件描述符,看他们是否准备好了执行IO操作。文件描述符就绪状态的转化是通过一些IO事件来触发。 二、水平触发和…...

Python中的错误是什么,Python中有哪些错误
7.1 错误(errors) 由于Python代码通常是人类编写的,那么无论代码是在解释之前还是运行之后,或多或少总会出现一些问题。 在Python代码解释时遇到的问题称为错误,通常是语法和缩进问题导致的,这些错误会导致代码无法通过解释器的解…...

MAX31856在工业温控项目中的实战应用:从选型、电路设计到故障诊断避坑指南
MAX31856工业温控系统设计全流程:从芯片选型到抗干扰实战 工业温度监测系统的可靠性直接关系到生产安全与产品质量。在钢铁冶炼、化工反应等场景中,一个温度传感器的失效可能导致数百万损失。MAX31856作为工业级热电偶数字转换器,其45V过压保…...

VisualCppRedist AIO:一站式解决Windows应用程序运行库缺失难题
VisualCppRedist AIO:一站式解决Windows应用程序运行库缺失难题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 在Windows系统中,你是否经…...

网站国产化改造怎么做?深度解读国产化替代路径与CMS推荐
在近年来科技领域的舆论场中,“国产化”无疑是出现频率最高的关键词之一。从芯片到操作系统,从数据库到办公软件,再到企业对外展示的门户——网站,国产化替代已从“可选项”变成了很多行业的“必答题”。但国产化仅仅是“换个牌子…...

詹姆斯·韦伯望远镜:344个单点故障背后的航天工程极限挑战
1. 韦伯望远镜的“生死十日”:一场价值百亿美元的太空芭蕾作为一名在航天与深空探测领域摸爬滚打了十几年的工程师,我经历过无数次地面测试的紧张,也见证过发射倒计时的屏息瞬间。但像詹姆斯韦伯空间望远镜(JWST)这样&…...

AI智能体通过MCP协议连接Figma:实现设计稿自动化操作与代码生成
1. 项目概述:当AI智能体学会“看”设计稿最近在折腾一个挺有意思的东西:让AI智能体(比如Cursor、Claude Code)能直接和Figma对话。听起来有点科幻?其实原理不复杂,就是通过一个叫Model Context Protocol&am…...

红米AX3000路由器SSH完整解锁终极指南:3步获取root权限
红米AX3000路由器SSH完整解锁终极指南:3步获取root权限 【免费下载链接】unlock-redmi-ax3000 Scripts for getting Redmi AX3000 (aka. AX6) SSH access. 项目地址: https://gitcode.com/gh_mirrors/un/unlock-redmi-ax3000 想要完全掌控你的红米AX3000路由…...

.NET 10 + CQRS + MediatR 一个跨平台文档管理系统
前言基于 .NET 10 打造的跨平台文档管理系统,才真正感受到了什么叫"专业级"的开源力量。它不仅仅是一个简单的文件存储工具,更是一个集成了 CQRS 架构、实时通信、版本控制等高级特性的现代化应用示例。项目介绍一款标准的前后端分离项目&…...

Android系统开发避坑:为什么你改了config.xml,导航栏还是不显示?
Android系统导航栏显示失效的深度排查指南 当你熬夜修改了config.xml文件,满怀期待地刷入系统,却发现导航栏依然不见踪影——这种挫败感我太熟悉了。导航栏显示问题看似简单,实则涉及Android资源覆盖机制的复杂层级。本文将带你深入AOSP的底层…...

Mega:基于上下文工程的Brainbase平台AI开发效率革命
1. 项目概述:Mega,你的Brainbase平台AI工程专家如果你正在使用Claude Code、Cursor或者任何能读取文件的AI编程工具来构建基于Brainbase平台的对话式AI应用,那么你很可能遇到过这样的困境:你需要花费大量时间向AI解释Brainbase的架…...

如何轻松解锁QQ音乐加密文件:qmcdump实战指南
如何轻松解锁QQ音乐加密文件:qmcdump实战指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾经下载…...