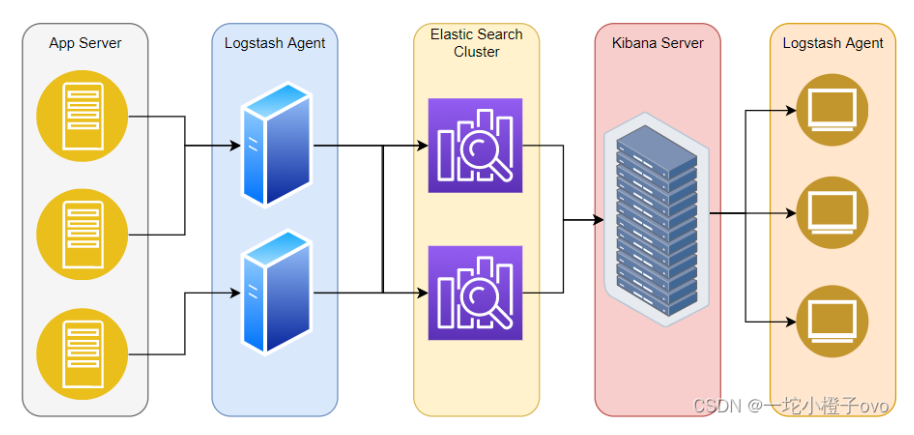
【ELK】ELK企业级日志分析系统
搜集日志;日志处理器;索引平台;提供视图化界面;客户端登录
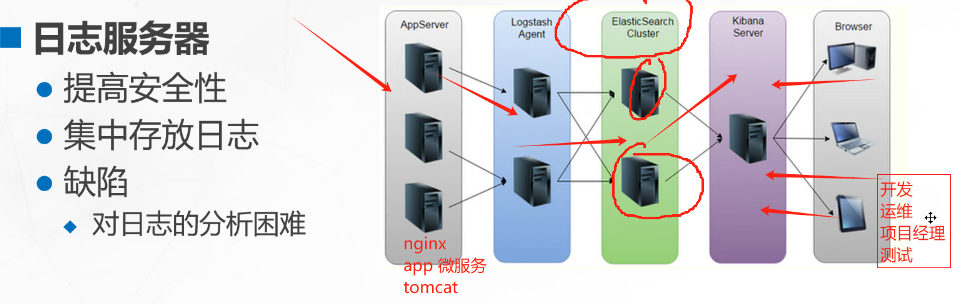
日志收集者:负责监控微服务的日志,并记录
日志存储者:接收日志,写入
日志harbor:负责去连接多个日志收集者,将日志传输给存储者
1.ELK概述
ELK简介
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求;
ElasticSearch
●ElasticSearch:是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
Elasticsearch 是用 Java 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与Elasticsearch 通信
restful api
get 获取,下载,搜索(文档、日志)
post 创建
put 更新
delete 删除
es是一个实时的、分布式的可扩展的搜索引擎
Elasticsearch是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大容量的日志数据,也可用于搜索许多不同类型的文档。
es 提供了一个分布式的存储搜索引擎,用来存储各类日志;
kiabana
kiabana通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
Kibana 提供图形化的 web 界面;汇总、分析和搜索重要数据
Logstash
作为数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 Elasticsearch。
Logstash 由 Ruby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具, 可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
数据收集引擎;对数据进行(传输、格式处理、格式化,数据输入和加工)过滤、统一格式,然后发送给es;
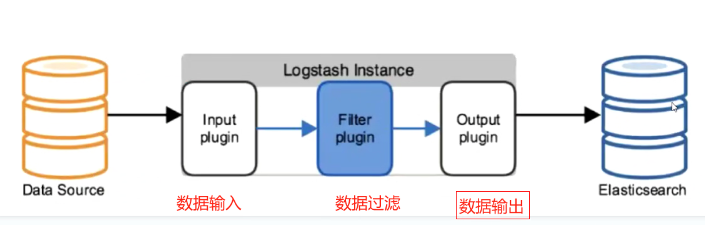
input(数据采集) filter(数据过滤) output(数据输出)
#可以添加的其它组件:
Filebeat
轻量级的开源日志文件数据搜集器;通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。
轻量级的开源日志文件数据收集器;能快速收集数据发送给logstash或es;应用于ELFK中
filebeat 结合 logstash 带来好处
1)通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻 Elasticsearch 持续写入数据的压力
2)从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
3)将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
4)使用条件数据流逻辑组成更复杂的处理管道
缓存/消息队列(redis、kafka、RabbitMQ等)
可以对高并发日志数据进行流量削峰和缓冲,这样的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦
Fluentd
是一个流行的开源数据收集器。由于 logstash 太重量级的缺点,Logstash 性能低、资源消耗比较多等问题,随后就有 Fluentd 的出现。相比较 logstash,Fluentd 更易用、资源消耗更少、性能更高,在数据处理上更高效可靠,受到企业欢迎,成为 logstash 的一种替代方案,常应用于 EFK 架构当中。在 Kubernetes 集群中也常使用 EFK 作为日志数据收集的方案。
在 Kubernetes 集群中一般是通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。 它通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
fluentd,开源的数据收集器;比logstash易用,资源消耗少,性能高,数据处理高效可靠;应用于EFK架构,k8s也常用EFK来收集日志;
2.为什么要用ELK
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
往往单台机器的日志我们使用grep、awk等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用 grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
单台机器使用grep、awk等工具就能实现简单的分析
百台机器就需要使用elk来集中式检索,提高定位问题的效率
思路:查看日志时,执行一次错误的地方,再看日志,方便定位;
企业:了解业务架构,数据流向
3.完整日志系统基本特征
收集:能够采集多种来源的日志数据
传输:能够稳定的把日志数据解析过滤并传输到存储系统
存储:存储日志数据
分析:支持 UI 分析
警告:能够提供错误报告,监控机制
总结:logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理
input 数据采集
output 数据输出
filter 数据过滤
ELK工作原理

ELK 集群部署
es吃资源,至少要2核4G
npm工具用来打包前端的包
后端打包用:
java -jar 启动微服务名称.jar/war
环境准备
Node1节点(2C/4G):node1/192.168.67.11 Elasticsearch Kibana
Node2节点(2C/4G):node2/192.168.67.12 Elasticsearch
Apache节点:apache/192.168.67.10 Logstash Apachesystemctl stop firewalld
setenforce 0
Elasticsearch部署(在Node1、Node2节点上操作)
做主机映射(node1、2都做)
echo "192.168.67.11 node1" >> /etc/hosts
echo "192.168.67.12 node2" >> /etc/hosts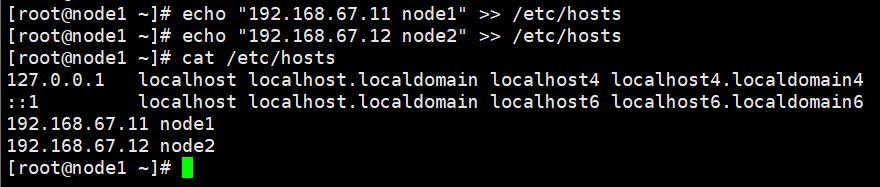
查看java版本
建议使用jdk
java -version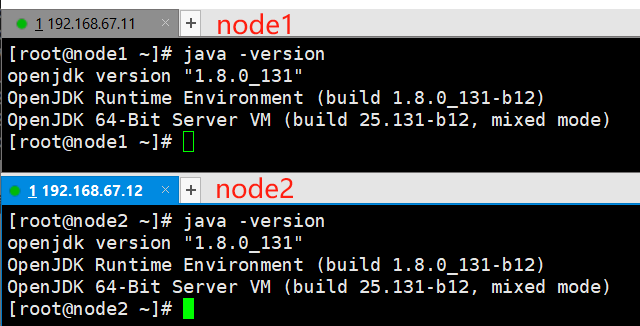
部署Elasticsearch软件
1)安装elasticsearch.rpm包
#上传安装包到/opt#解压
rpm -ivh elasticsearch-5.5.0.rpm 
2)加载服务
systemctl daemon-reload
systemctl enable elasticsearch.service
3)修改elasticsearch主配置文件
#先备份再改,留后路
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
集群名:![]()
节点名: ![]()
![]()
数据存放路径:![]()
日志存放路径:![]()
不锁定内存:![]()
监听地址:![]()
端口:![]()
指定发现节点:![]()
查看一下修改的内容
grep -v "^#" /etc/elasticsearch/elasticsearch.yml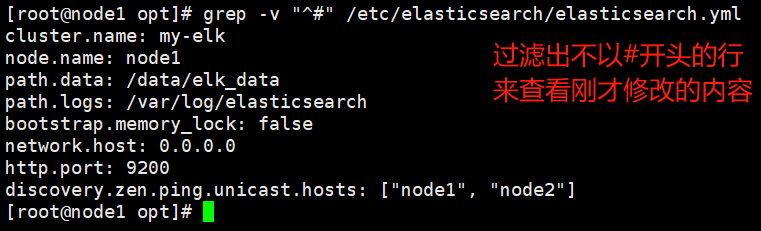
4)创建数据存放路径并授权
#创建目录
mkdir -p /data/elk_data
#修改属主和属组进行授权
chown elasticsearch:elasticsearch /data/elk_data/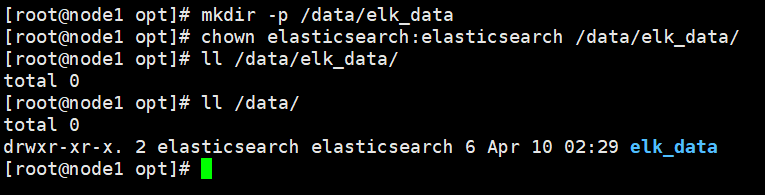
5)启动elasticsearch是否成功开启
systemctl start elasticsearch.service
netstat -antp | grep 9200
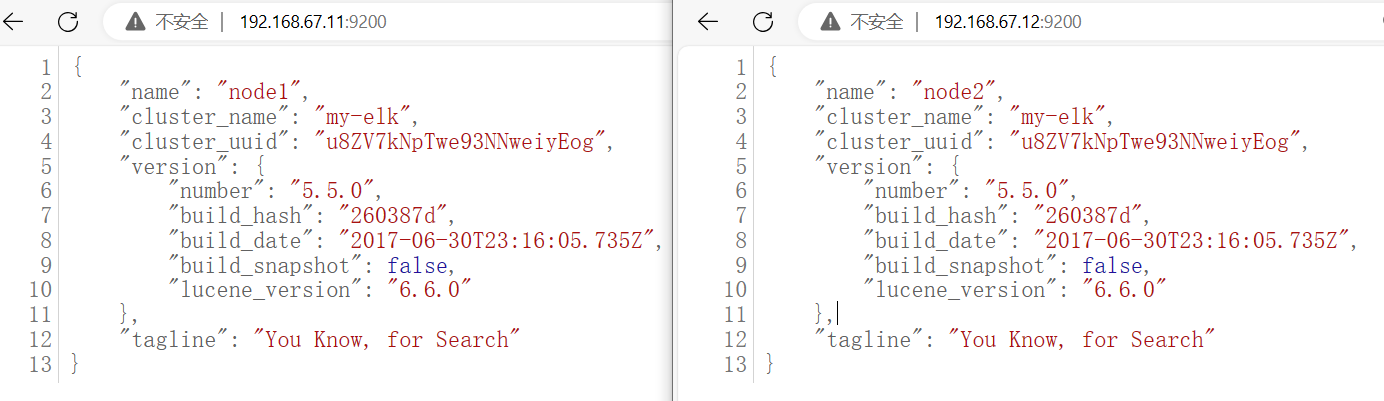
6)查看节点信息
浏览器访问:
http://192.168.67.11:9200
http://192.168.67.12:9200
查看节点 Node1、Node2 的信息
浏览器访问
http://192.168.67.11:9200/_cluster/health?pretty
http://192.168.67.12:9200/_cluster/health?pretty
查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行
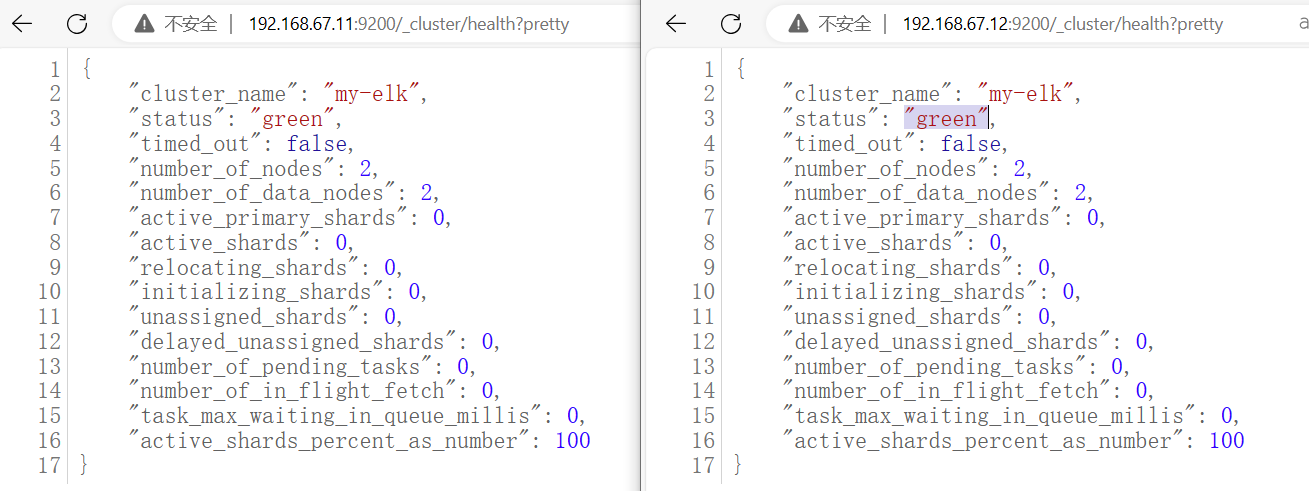
绿色:健康 数据和副本 全都没有问题
红色:数据都不完整
黄色:数据完整,但副本有问题
#使用上述方式查看群集的状态对用户并不友好,可以通过安装 Elasticsearch-head 插件,可以更方便地管理群集。
安装 Elasticsearch-head 插件(node1上做就行)
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到
#解压jar包,本次实验用不到
java -jar weifuwu.jar/war
1)编译安装 node
安装编译环境
yum install gcc gcc-c++ make -y#上传软件包 node-v8.2.1.tar.gz 到/opt
[root@node1 opt]# rz -E
rz waiting to receive.
[root@node1 opt]# ls
elasticsearch-5.5.0.rpm node-v8.2.1.tar.gz rh

解压node
cd /opt
tar zxvf node-v8.2.1.tar.gz
编译安装
cd node-v8.2.1/
./configure
#多用几个核,加快编译速度;看自己电脑来
make -j 4 && make install2)安装 phantomjs(前端的框架)
上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到/opt
[root@node1 ~]# cd /opt/
[root@node1 opt]# rz -E
rz waiting to receive.
[root@node1 opt]# ls
elasticsearch-5.5.0.rpm node-v8.2.1.tar.gz rh
node-v8.2.1 phantomjs-2.1.1-linux-x86_64.tar.bz2解压
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/-z:有gzip属性的
-j:有bz2属性的
-v:显示所有过程复制phantomjs文件到 /usr/local/bin下
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin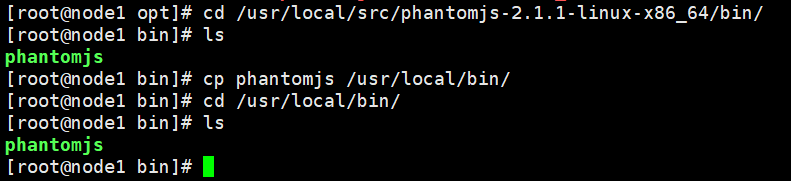
3)安装 Elasticsearch-head 数据可视化工具
#上传软件包 elasticsearch-head.tar.gz 到/opt
[root@node1 opt]# rz -E
rz waiting to receive.
[root@node1 opt]# ls
elasticsearch-5.5.0.rpm node-v8.2.1 phantomjs-2.1.1-linux-x86_64.tar.bz2
elasticsearch-head.tar.gz node-v8.2.1.tar.gz rh
解包
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install

4)修改 Elasticsearch 主配置文件
---G o 末尾添加以下内容---
#开启跨域访问支持,默认为 false
http.cors.enabled: true
#指定跨域访问允许的域名地址为所有
http.cors.allow-origin: "*"
重启es服务
systemctl restart elasticsearch5)启动 elasticsearch-head 服务
#必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
#到 elasticsearch-head 目录下启动服务
cd /usr/local/src/elasticsearch-head/
npm run start &
回车即可退出
查看elasticsearch-head 监听的端口
netstat -natp |grep 9100
6)通过 Elasticsearch-head 查看 Elasticsearch 信息
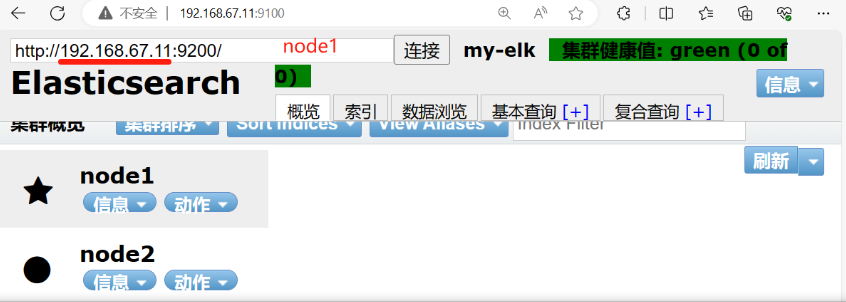
浏览器访问
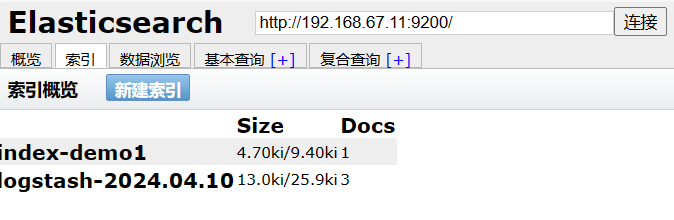
http://192.168.67.11:9100/
访问地址并连接群集。如果看到群集健康值为 green 绿色,代表群集很健康。
#localhost该为本机地址
7)插入索引
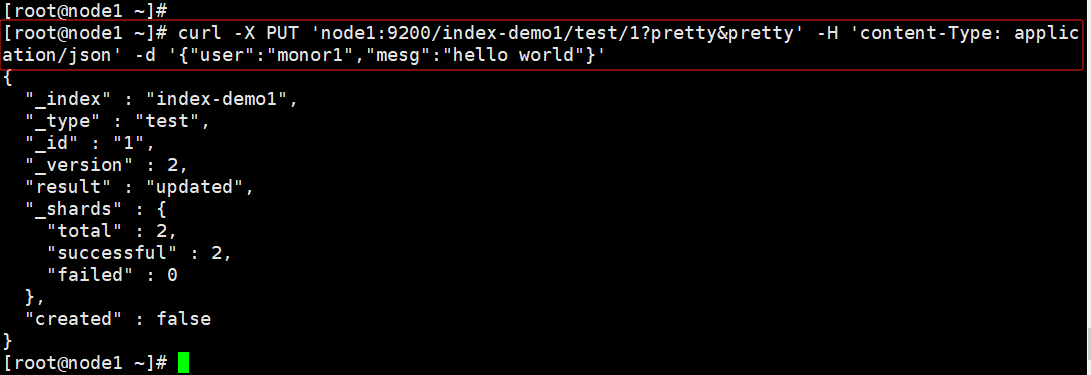
#通过命令插入一个测试索引,索引为 index-demo,类型为 test。
输出结果如下:
curl -X PUT 'node1:9200/index-demo1/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"monor1","mesg":"hello world"}'
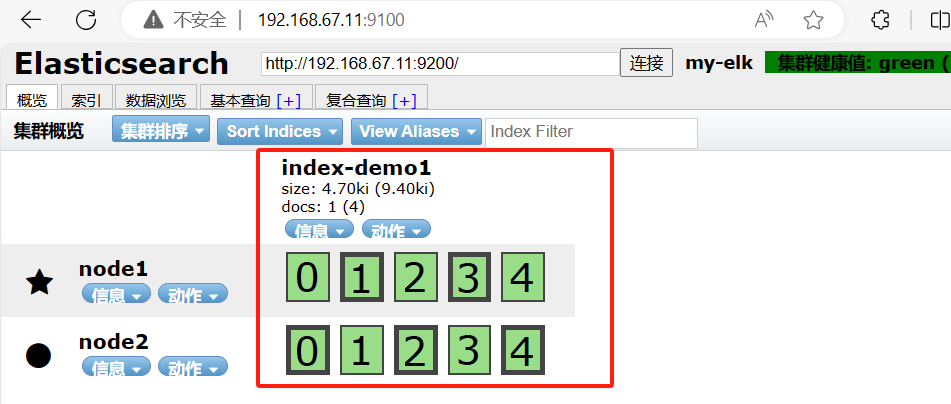
浏览器访问
http://192.168.67.11:9100/
查看索引信息,可以看见索引默认被分片5个,并且有一个副本。
点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息

ELK Logstash 部署(在 Apache 节点上操作)
环境准备
#更改主机名
hostnamectl set-hostname apache
bashsystemctl stop firewalld
setenforce 0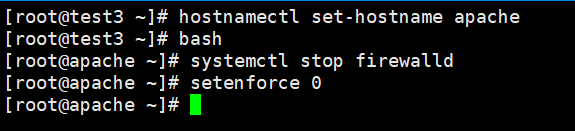
安装Apahce服务(httpd)
#安装epel源
yum -y install epel
#安装httpd
yum -y install httpd
#查看状态
systemctl status httpd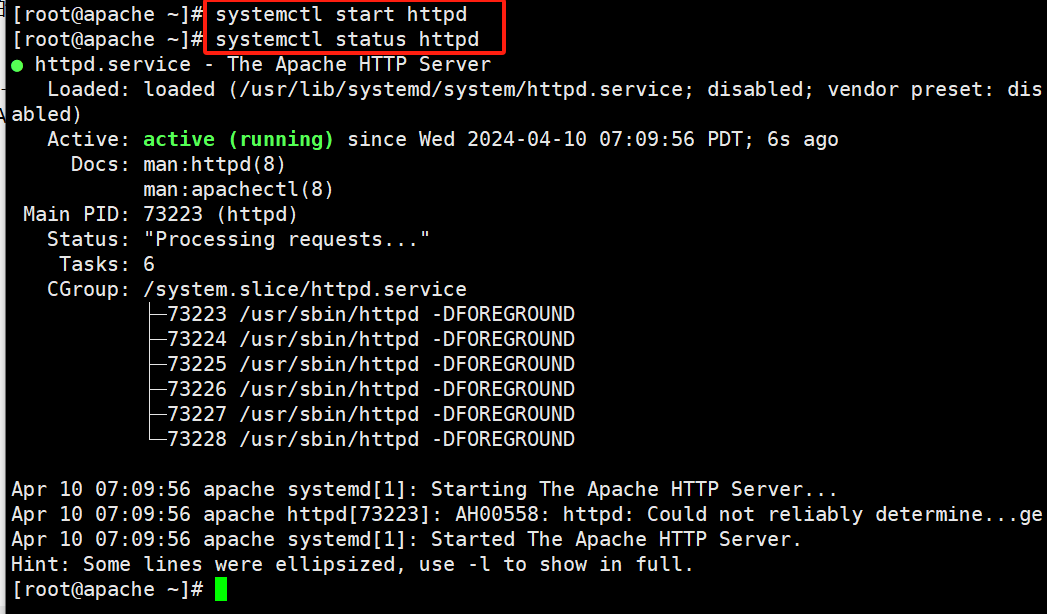
安装Java环境
yum -y install java
java -version
安装logstash
#上传软件包 logstash-5.5.1.rpm 到/opt目录下
[root@apache ~]# cd /opt/
[root@apache opt]# ls
rh
[root@apache opt]# rz -E
rz waiting to receive.
[root@apache opt]# ls
logstash-5.5.1.rpm rh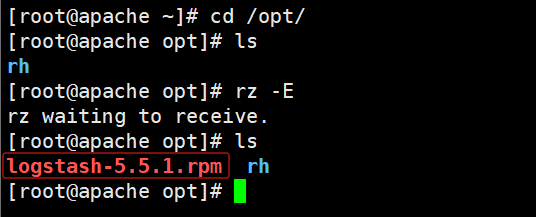
解压
cd /opt/
rpm -ivh logstash-5.5.1.rpm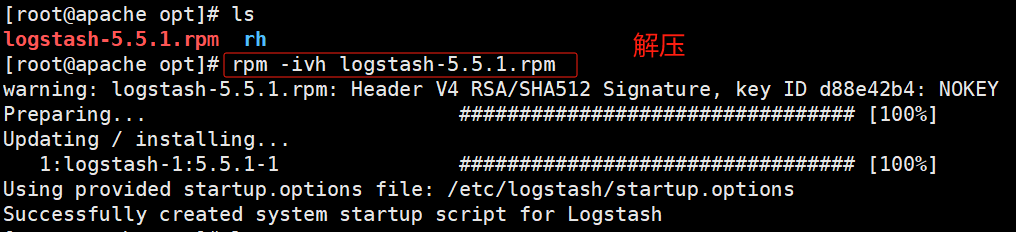
开启服务,并设置开机自启动
systemctl start logstash.service
systemctl enable logstash.service
设置软连接
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
测试 Logstash
Logstash 命令常用选项
-f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。
-e:从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)
-t:测试配置文件是否正确,然后退出
定义输入和输出流:
#输入采用标准输入,输出采用标准输出(类似管道)
logstash -e 'input { stdin{} } output { stdout{} }'
#键入内容(标准输入)
www.baidu.com
#输出结果(标准输出)
2024-04-10T15:34:34.188Z apache www.baidu.com#键入内容(标准输入)
www.sina.com.cn#输出结果(标准输出)
2024-04-10T15:34:47.996Z apache www.sina.com.cn

//执行 ctrl+c 退出

#使用 rubydebug 输出详细格式显示,codec 为一种编解码器
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'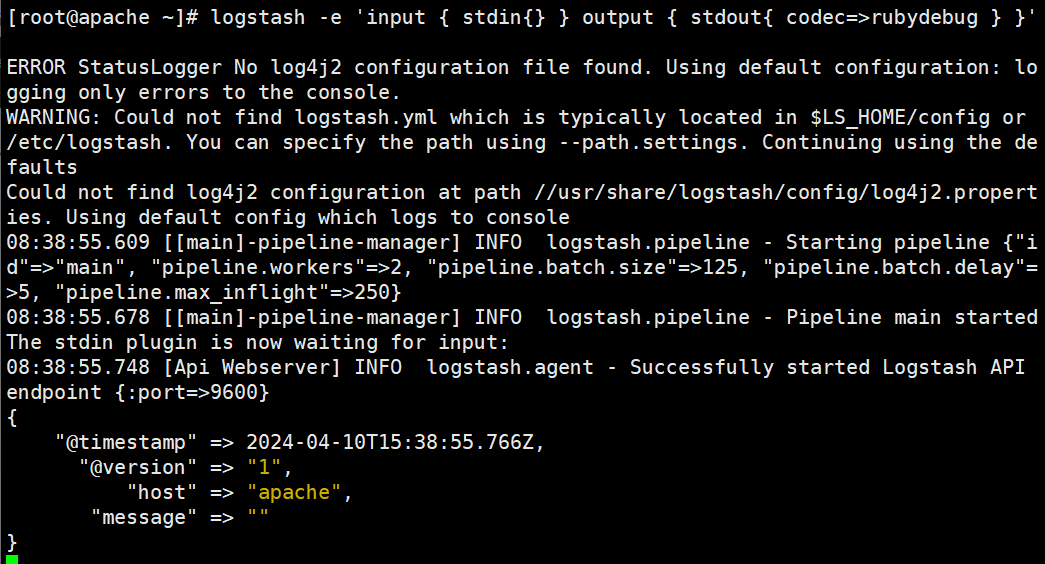
www.baidu.com
#使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.67.11:9200"] } }'输入 输出 www.baidu.com
www.sina.com.cn
www.google.com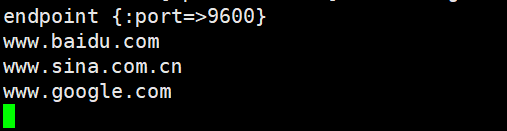
//结果不在标准输出显示,而是发送至 Elasticsearch 中,
可浏览器访问 http://192.168.67.11:9100/ 查看索引信息和数据浏览。
http://192.168.67.11:9100/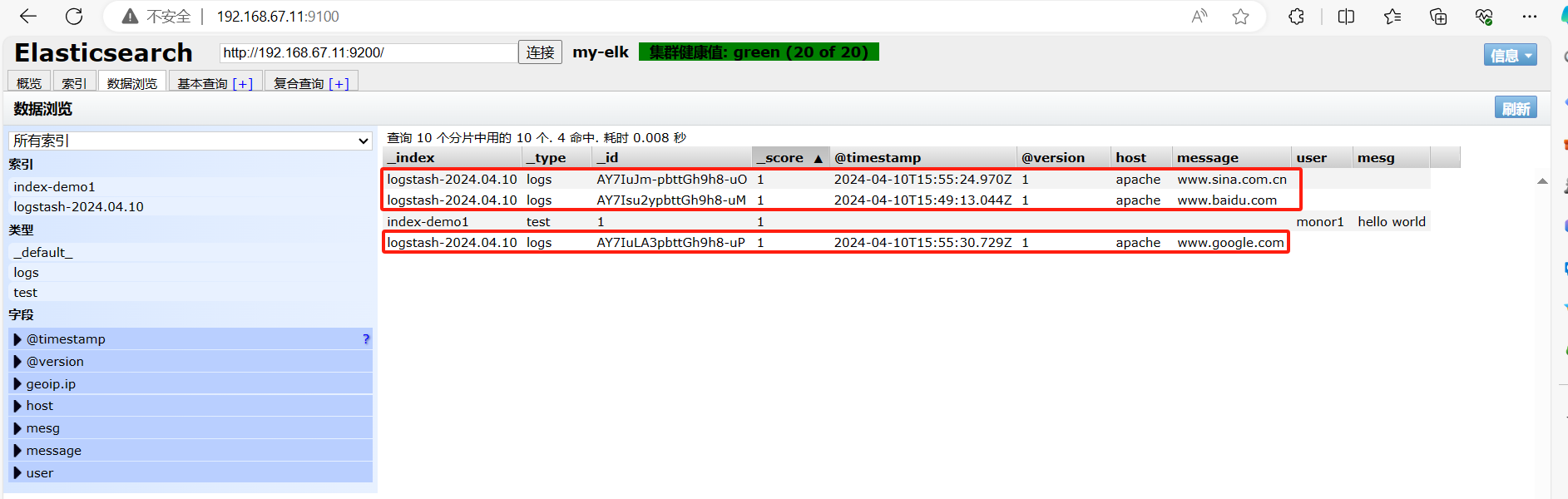
定义 logstash配置文件
Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)。
input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等
filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
output:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch
#格式如下:
input {...}
filter {...}
output {...}
#在每个部分中,也可以指定多个访问方式
例如,若要指定两个日志来源文件,则格式如下:
input {file { path =>"/var/log/messages" type =>"syslog"}file { path =>"/var/log/httpd/access.log" type =>"apache"}
}#修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中
日志文件
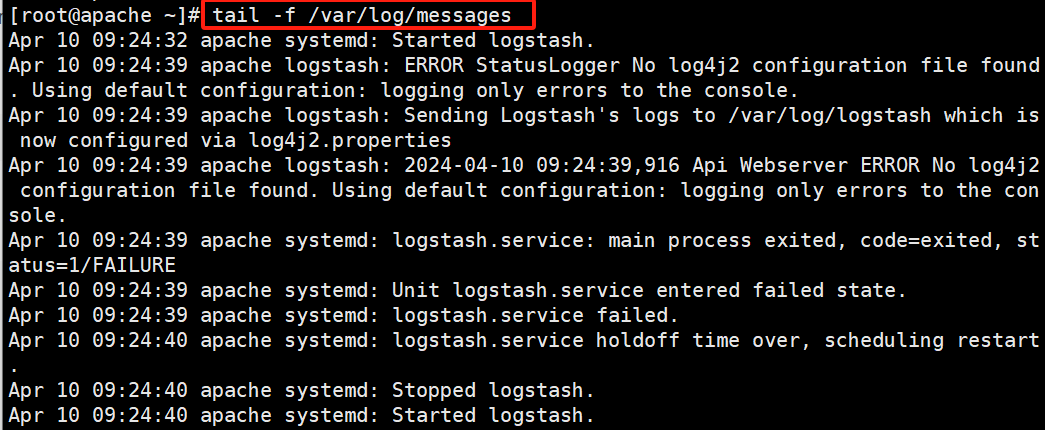
#让 Logstash 可以读取日志
chmod +r /var/log/messages

修改 Logstash 配置文件
vim /etc/logstash/conf.d/system.conf
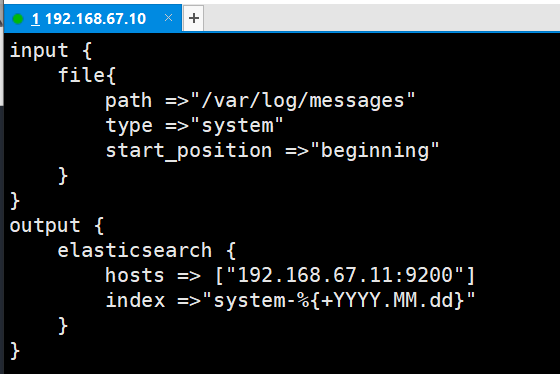
input {file{#指定要收集的日志的位置path =>"/var/log/messages"#自定义日志类型标识type =>"system"#表示从 开始处 收集start_position =>"beginning" }
}
output {#输出到 elasticsearchelasticsearch {#指定 elasticsearch 服务器的地址和端口hosts => ["192.168.67.11:9200"]#指定输出到 elasticsearch 的索引格式index =>"system-%{+YYYY.MM.dd}"}
}
重启logstash
systemctl restart logstash 浏览器访问
浏览器访问 http://192.168.67.11:9100/ 查看索引信息
http://192.168.67.11:9100/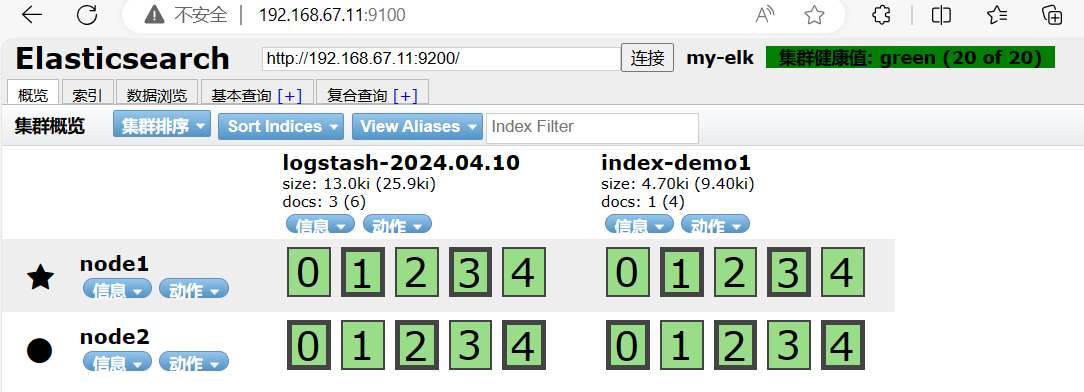
相关文章:
【ELK】ELK企业级日志分析系统
搜集日志;日志处理器;索引平台;提供视图化界面;客户端登录 日志收集者:负责监控微服务的日志,并记录 日志存储者:接收日志,写入 日志harbor:负责去连接多个日志收集者&am…...

详细的讲一下java的接口回调
Java的接口回调是一种允许程序在特定事件发生时通知其他对象的机制。这是观察者设计模式的一种实现方式,常用于实现事件监听和异步处理。接口回调允许对象之间进行松耦合的交互:一个对象只知道它可以调用另一个对象的方法,但它不需要知道这个…...
如何将powerpoint(PPT)幻灯片嵌入网页中在线预览、编辑并保存到服务器?
猿大师办公助手不仅可以把微软Office、金山WPS和永中Office的Word文档、Excel表格内嵌到浏览器网页中实现在线预览、编辑保存等操作,还可以把微软Office、金山WPS和永中Office的PPT幻灯片实现网页中在线预览、编辑并保存到服务器。 猿大师办公助手把本机原生Office…...

[Java基础揉碎]日期类
目录 日期类 第一代日期类 第二代日期类 第三代日期类 >前面两代日期类的不足分析 针对以上问题Java在jdk8加入了以下方法 jdk8的时间格式化 时间戳 第三代日期类更多方法 日期类 [知道怎么查,怎么用即可,不用每个方法都背] 第一代日期类 1) Date: …...

4.10作业
//.h文件#ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTimerEvent> //定时器事件类 #include <QTime> //时间类 #include <QString> #include <QPushButton> //按钮类 #include <QLabel> //标签类 #include <QT…...

Hive概述与基本操作
一、Hive基本概念 1.什么是hive? (1)hive是数据仓库建模的工具之一 (2)可以向hive传入一条交互式的sql,在海量数据中查询分析得到结果的平台 2.Hive简介 Hive本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS…...

安装 FFmpeg
安装 FFmpeg 1. Install FFmpeg On Ubuntu2. Install FFmpeg On Ubuntu 16.042.1. First add the repository2.2. Update the newly added repository2.3. Now install the ffmpeg2.4. For opening the ffmpeg for that type ffpmeg on the terminal 3. Uninstall ffmpegRefere…...

18、差分
差分 题目描述 输入一个长度为n的整数序列。 接下来输入m个操作,每个操作包含三个整数l, r, c,表示将序列中[l, r]之间的每个数加上c。 请你输出进行完所有操作后的序列。 输入格式 第一行包含两个整数n和m。 第二行包含n个整数,表示整…...

13 指针(上)
指针是 C 语言最重要的概念之一,也是最难理解的概念之一。 指针是C语言的精髓,要想掌握C语言就需要深入地了解指针。 指针类型在考研中用得最多的地方,就是和结构体结合起来构造结点(如链表的结点、二叉树的结点等)。 本章专题脉络 1、指针…...
AI 对话完善【人工智能】
AI 对话【人工智能】 前言版权开源推荐AI 对话v0版本:基础v1版本:对话数据表tag.jsTagController v2版本:回复中textarea.jsChatController v3版本:流式输出chatLast.jsChatController v4版本:多轮对话QianfanUtilChat…...

利用数组储存表格数据
原理以及普通数组储存表格信息 在介绍数组的时候说过,数组能够用来储存任何同类型的数据,这里的意思就表明只要是同一个类型的数组据就可以储存到一个数组中。那么在表格中同一行的数据是否可以储存到同一个数组中呢?答案自然是可以ÿ…...

[数据概念|数据技术]智能合约如何助力数据资产变现
“ 区块链上数据具有高可信度,智能合约将区块链变得更加智能化,以支持企业场景。” 之前鼹鼠哥已经发表了一篇文章,简单介绍了区块链,那么,智能合约又是什么呢?它又是如何助力数据资产变现的呢?…...

JS中的常见二进制数据格式
格式描述用途示例ArrayBuffer固定长度的二进制数据缓冲区,不直接操作具体的数据,而是通过类型数组或DataView对象来读写用于存储和处理大量的二进制数据,如文件、图像等let buffer new ArrayBuffer(16);TypedArray基于ArrayBuffer对象的视图…...
uniapp开发h5端使用video播放mp4格式视频黑屏,但有音频播放解决方案
mp4格式视频有一些谷歌播放视频黑屏,搜狗浏览器可以正常播放 可能和视频的编码格式有关,谷歌只支持h.264编码格式的视频播放 将mp4编码格式修改为h.264即可 转换方法: 如果是自己手动上传文件可以手动转换 如果是后端接口调取的地址就需…...
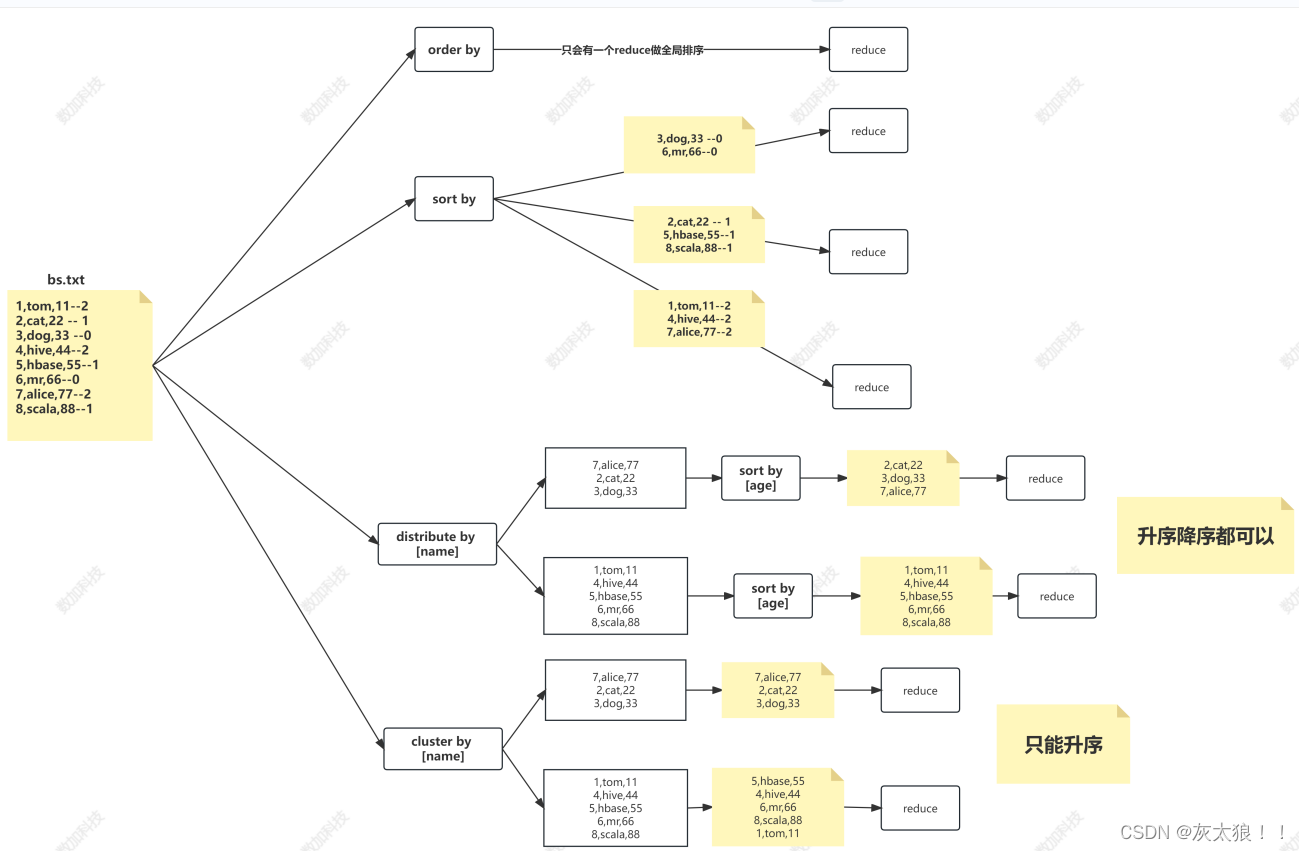
Hive的分区与排序
一、Hive分区 1.引入: 在大数据中,最常见的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的ÿ…...
4.9)
Objective-C学习笔记(内存管理、property参数)4.9
1.引用计数器retainCount:每个对象都有这个属性,默认值为1,记录当前对象有多少人用。 为对象发送一条retain/release消息,对象的引用计数器加/减1,为对象发一条retainCount,得到对象的引用计数器值,当计数器…...

C语言进阶课程学习记录-第29课 - 指针和数组分析(下)
C语言进阶课程学习记录-第29课 - 指针和数组分析(下) 数组名与指针实验-数组形式转换实验-数组名与指针的差异实验-转化后数组名加一的比较实验-数组名作为函数形参小结 本文学习自狄泰软件学院 唐佐林老师的 C语言进阶课程,图片全部来源于课…...
一起学习python——基础篇(13)
前言,python编程语言对于我个人来说学习的目的是为了测试。我主要做的是移动端的开发工作,常见的测试主要分为两块,一块为移动端独立的页面功能,另外一块就是和其他人对接工作。 对接内容主要有硬件通信协议、软件接口文档。而涉…...
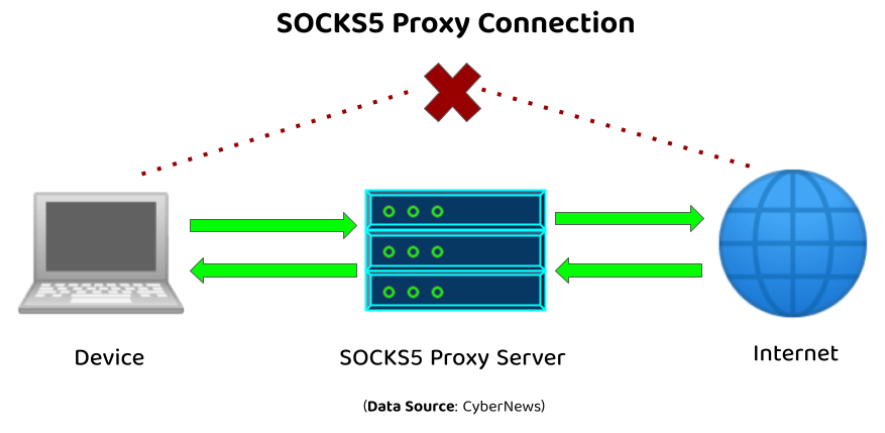
SOCKS代理概述
在网络技术的广阔领域中🌐,SOCKS代理是一个核心组件,它在提升在线隐私保护🛡️、实现匿名通信🎭以及突破网络访问限制🚫方面发挥着至关重要的作用。本文旨在深入探讨SOCKS代理的基础,包括其定义…...

AI助力M-OFDFT实现兼具精度与效率的电子结构方法
编者按:为了使电子结构方法突破当前广泛应用的密度泛函理论(KSDFT)所能求解的分子体系规模,微软研究院科学智能中心的研究员们基于人工智能技术和无轨道密度泛函理论(OFDFT)开发了一种新的电子结构计算框架…...

探秘书匠策AI:毕业论文写作的“智慧引擎”
在学术探索的征途中,毕业论文如同一座巍峨的山峰,让无数学生既敬畏又向往。它不仅是对所学知识的综合检验,更是学术生涯的重要里程碑。然而,面对这座大山,许多人常常感到力不从心,选题迷茫、文献难觅、结构…...

如何通过霞鹜文楷解决中文开源字体在技术项目中的核心挑战
如何通过霞鹜文楷解决中文开源字体在技术项目中的核心挑战 【免费下载链接】LxgwWenKai An unprofessional open-source Chinese font derived from Fontworks Klee One. 一款非专业的开源中文字体,基于 FONTWORKS 出品字体 Klee One 衍生。 项目地址: https://g…...

3.多表关联在电商数据分析中的核心价值
多表关联在电商数据分析中的核心价值 第1章 多表关联、子查询与行列转换在电商数据分析中的核心价值 1.1 为什么单表查询不够用 我刚开始做数据分析的时候,以为SQL就是在一张表上做筛选和汇总。直到有一天,运营问我:“这批高价值用户…...

告别电量焦虑:用STM32+IP2366打造你的140W双向快充移动电源方案
告别电量焦虑:用STM32IP2366打造140W双向快充移动电源方案 1. 为什么需要高性能移动电源方案 当代智能设备对电力的需求呈现爆发式增长。从智能手机到笔记本电脑,从无人机到便携式医疗设备,快速充电和大容量储能已成为刚需。传统移动电源方…...

从“一次性消耗”到“长效资产”:头部品牌如何用易元AI搭建视频中台
2026年,电商内容竞争已从“数量比拼”升级为“资产价值比拼”。传统视频生产是“一次性消耗”——拍完即弃、素材零散、复用率低,内容投入仅为短期成本;而头部品牌已通过视频资产化与AI内容中台,将内容从“成本项”转为“资产项”…...

PasteMD免配置环境:Docker镜像封装,3条命令完成私有化AI格式化服务部署
PasteMD免配置环境:Docker镜像封装,3条命令完成私有化AI格式化服务部署 1. 项目简介:剪贴板智能美化工具 PasteMD是一个完全私有化的AI文本格式化工具,它基于Ollama本地大模型运行框架和强大的llama3:8b模型构建。这个工具的核心…...

AugmentCode无限续杯插件:突破登录限制的自动化解决方案
AugmentCode无限续杯插件:突破登录限制的自动化解决方案 【免费下载链接】free-augment-code AugmentCode 无限续杯浏览器插件 项目地址: https://gitcode.com/gh_mirrors/fr/free-augment-code 痛点解析:开发者的账户管理困境 在软件开发与测试…...

W25Q16 Flash存储器:从基础概念到SPI通信实战
1. 认识W25Q16 Flash存储器 第一次接触W25Q16是在做一个智能家居项目时,需要保存用户的WiFi配置和房间温湿度记录。当时试过用单片机内部的EEPROM,但容量太小不够用,后来发现了这款性价比超高的外部Flash芯片。简单来说,W25Q16就像…...

ESP32开发环境:VS Code与ESP-IDF插件高效配置指南
1. 为什么选择VS Code开发ESP32? 第一次接触ESP32开发时,我尝试过各种开发工具:Arduino IDE、PlatformIO、Eclipse...最后发现VS Code配合ESP-IDF插件才是最佳组合。这个方案不仅免费开源,更重要的是能充分发挥ESP32的全部性能特…...

Qwen3-14B应用案例:智能客服与内容生成,企业落地实操
Qwen3-14B应用案例:智能客服与内容生成,企业落地实操 1. 为什么选择Qwen3-14B作为企业AI解决方案 在当今企业数字化转型浪潮中,AI技术正从实验室走向实际业务场景。Qwen3-14B作为140亿参数的大型语言模型,在能力与资源消耗之间取…...