大数据基本名词
目录[-]
- 1.1. 1. Hadoop
- 1.2. 2. Hive
- 1.3. 3. Impala
- 1.4. 4. Hbase
- 1.5. 5.hadoop hive impala hbase关系
- 1.6. 6. Spark
- 1.7. 7. Flink
- 1.8. 8. Spark 和 Flink 的应用场景
1. Hadoop

开源官网:https://hadoop.apache.org/
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
2. Hive

开源官网:https://hive.apache.org/
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析
3. Impala

开源官网:https://impala.apache.org/
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
4. Hbase

开源官网:https://hbase.apache.org/
HBase – Hadoop Database是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
5.hadoop hive impala hbase关系
Hadoop生态系统中的三个重要组件Hive、Impala和HBase各自都有其特定的用途和设计优势,它们之间的主要区别如下:
-
Hive:Hive是一个构建在Hadoop上的数据仓库平台,它提供了类似SQL的查询语言(HQL)来分析存储在Hadoop上的数据。Hive用于静态数据分析,主要是用于批处理。
-
Impala:Impala是一个用于处理存储在Hadoop数据的实时、交互式查询引擎。它比Hive快得多,通过使用Impala,用户可以直接与数据进行交互,而不需要通过MapReduce任务。
-
HBase:HBase是一个分布式、可伸缩的、面向列的开源数据库,它以Google的Bigtable为原型。HBase用于实时、随机访问大规模数据集。它是一个非常适合实时应用程序的数据存储,因为它可以快速地提供随机访问内容。
总结区别:
- Hive主要用于数据仓库任务,支持批处理查询。
- Impala主要用于交互式SQL查询,支持实时分析。
- HBase主要用于实时随机访问大数据,适合存储结构化数据。
每个系统都有其自身的用途,可以根据应用场景选择合适的工具。
Hive的使用虽然和关系型数据库类似,但是其本质上是建立在Hadoop体系架构上的一层SQL抽象,自身不存储和处理数据,实际数据保存在HDFS文件中,真正的计算和执行则由MapReduce完成;Impala是Hive的补充,可以读取和写入 Hive 表,依赖Hive的元数据,自身不存储数据。Impala提供的有一个分布式查询引擎;HBase是列存储的NoSQL数据库,主要提供接口的形式与外界交互,数据保存在HDFS上,也支持使用Hive直接访问HBase;HDFS是Hadoop生态最底层的存储,Hive、Impala、HBase都建立在HDFS之上
6. Spark

开源网址:https://spark.apache.org/
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
7. Flink

https://flink.apache.org/
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行
8. Spark 和 Flink 的应用场景
Spark 适合于吞吐量比较大的场景,数据量非常大而且逻辑复杂的批数据处理,并且对计算效率有较高要求(比如用大数据分析来构建推荐系统进行个性化推荐、广告定点投放等)。其次,Spark是批处理架构,适合基于历史数据的批处理。最好是具有大量迭代计算场景的批处理。Spark可以支持近实时的流处理,延迟性要求在在数百毫秒到数秒之间。Spark的生态更健全,SQL操作也更加健全,已经存在Spark生态的可以直接使用。Flink 主要用来处理要求低延时的任务,实时监控、实时报表、流数据分析和实时仓库。Flink可以用于事件驱动型应用,数据管道,数据流分析等。总的来说,spark离线计算,Flink实时计算。
相关文章:
大数据基本名词
目录[-] 1.1. 1. Hadoop1.2. 2. Hive1.3. 3. Impala1.4. 4. Hbase1.5. 5.hadoop hive impala hbase关系1.6. 6. Spark1.7. 7. Flink1.8. 8. Spark 和 Flink 的应用场景 1. Hadoop 开源官网:https://hadoop.apache.org/ Hadoop是一个由Apache基金会所开发的分…...

网站网页客服、微信公众号客服、H5客服、开源源码与高效部署的完美结合
随着互联网技术的飞速发展,企业与客户之间的沟通方式也在持续变革。在线客服系统作为一种新兴的沟通工具,已经成为提升企业服务质量、增强客户满意度的重要手段。本文将详细介绍在线客服系统的优势、功能以及如何高效部署,特别是推荐一款名为…...

1、Qt UI控件 -- qucsdk
前言:Qt编写的自定义控件插件的sdk集合,包括了各个操作系统的动态库文件以及控件的头文件和sdk使用demo。类似于Wpf中的LivChart2控件库,都是一些编译好的控件,可以直接集成到项目中。该控件是飞扬青云大神多年前开发的࿰…...

Sora是什么?Sora怎么使用?Sora最新案例视频以及常见问题答疑
Sora 是什么? 2024年2月16日,OpenAI 在其官网上面正式宣布推出文本生成视频的大模型Sora 这样说吧给你一段话, 让你写一篇800字的论文,你的理解很可能都有偏差,那么作为OpenAi要做文生视频到底有多难,下面…...
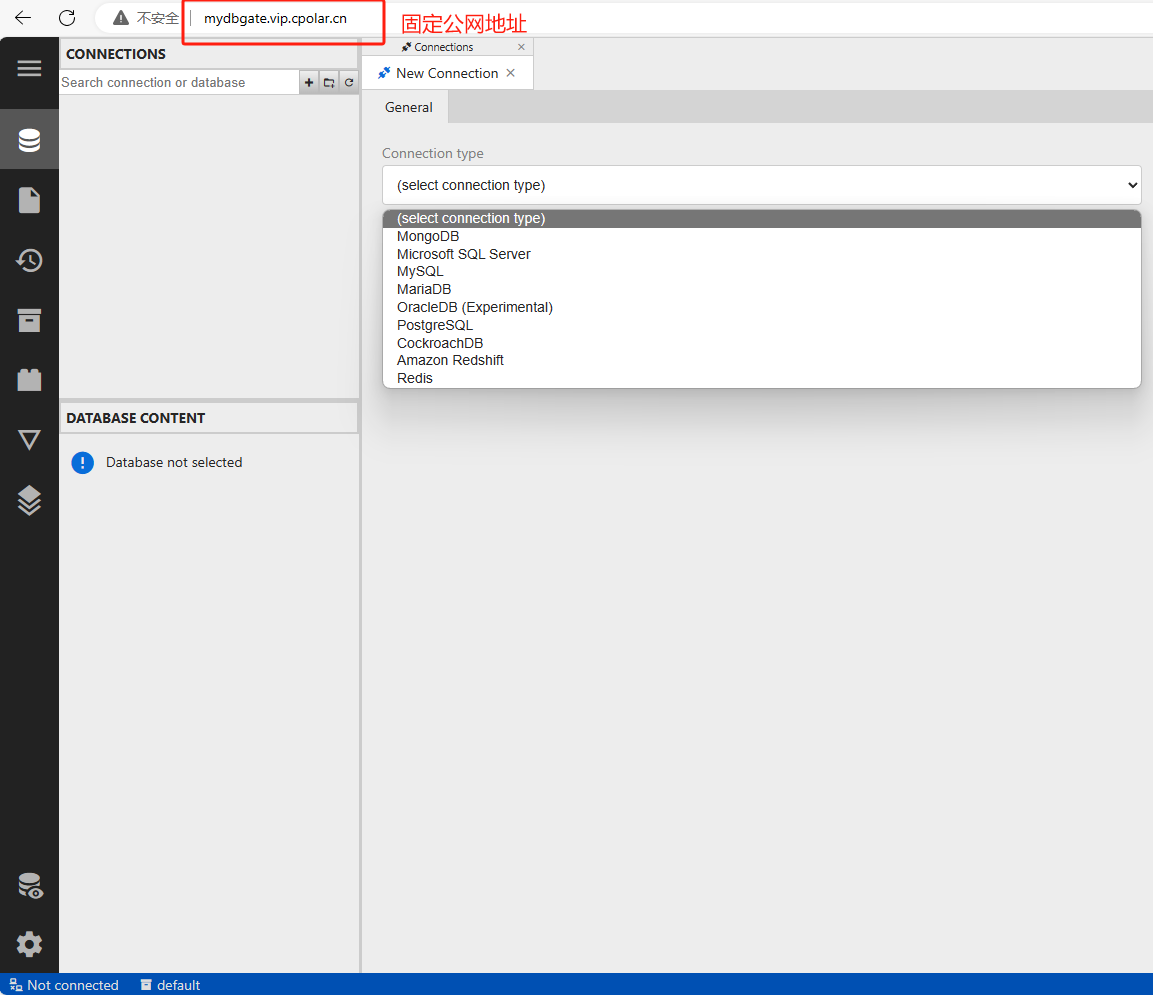
如何在Ubuntu系统使用docker部署DbGate容器并发布至公网可访问
文章目录 1. 安装Docker2. 使用Docker拉取DbGate镜像3. 创建并启动DbGate容器4. 本地连接测试5. 公网远程访问本地DbGate容器5.1 内网穿透工具安装5.2 创建远程连接公网地址5.3 使用固定公网地址远程访问 本文主要介绍如何在Linux Ubuntu系统中使用Docker部署DbGate数据库管理工…...
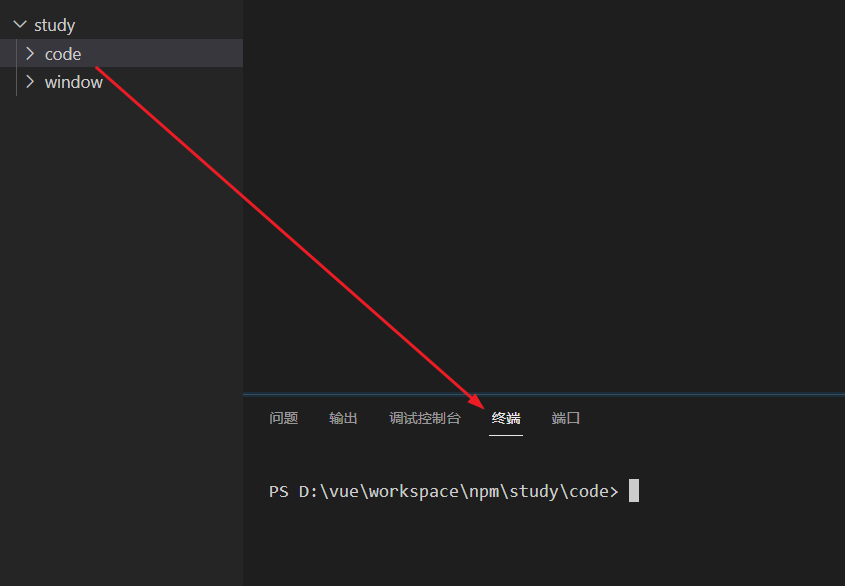
解决 VSCode 编辑器点击【在集成终端中打开】出现新的弹框
1、问题描述 在 VSCode 的项目下,鼠标右键,点击【在集成终端中打开】,出现新的一个弹框。新版的 VSCode 会有这个问题,一般来说我们都希望终端是在 VSCode 的控制台中打开的,那么如何关闭这个弹框呢? 2、解…...

从零开始:构建、打包并上传个人前端组件库至私有npm仓库的完整指南
文章目录 一、写组件1、注册全局组件方法2、组件13、组件2 二、测试三、发布1、配置package.json2、生成库包3、配置发布信息4、发布 四、使用1、安装2、使用 五、维护1、维护和更新2、注意事项 一、写组件 确定组件库的需求和功能:在开始构建组件库之前,…...

Ant Design Vue 表单验证手机号的正则
代码: pattern: /^1[3456789]\d{9}$/ 1. <a-form-item label"原手机号" v-bind"validateInfos.contactTel"><a-inputstyle"width: 600px"allow-clear:maxlength"20"placeholder"请输入原手机号"v-mo…...
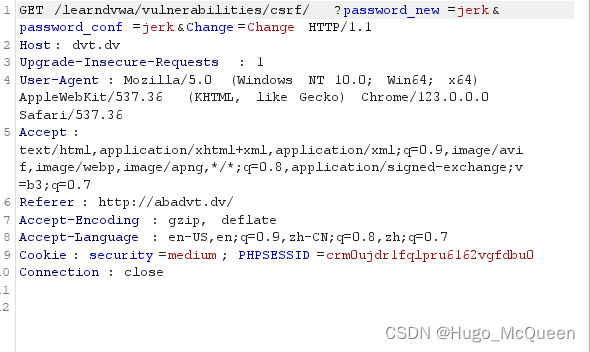
[dvwa] CSRF
CSRF 0x01 low 跨站,输入密码和确认密码直接写在url中,将连接分享给目标,点击后修改密码 社工方式让目标点击短链接 伪造404页,在图片中写路径为payload,目标载入网页自动请求构造链接,目标被攻击 http…...

只为兴趣,2024年你该学什么编程?
讲动人的故事,写懂人的代码 当你想学编程但不是特别关心找工作的时候,选哪种语言学完全取决于你自己的目标、兴趣和能找到的学习资料。一个很重要的点,别只学一种语言啊!毕竟,"门门都懂,样样皆通",每种编程语言都有自己的优点和适合的用途,多学几种可以让你的…...
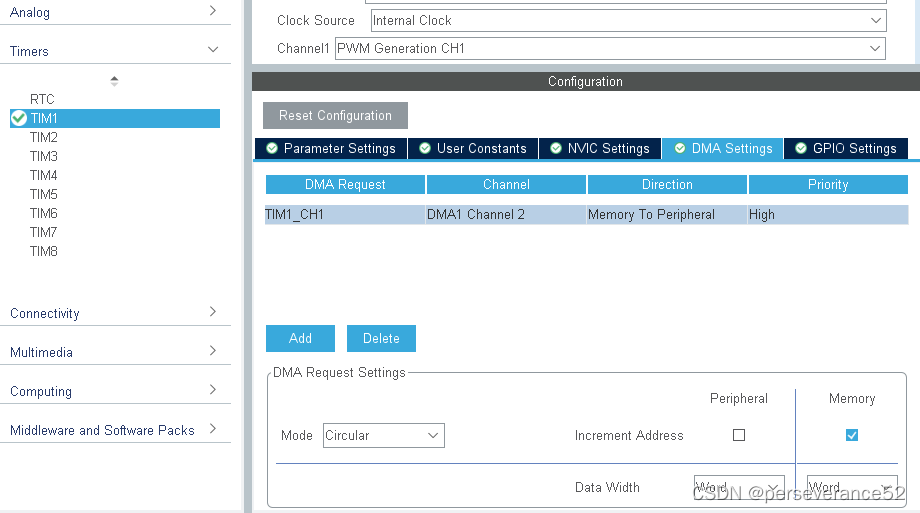
HAL STM32 定时器PWM DMA输出方式
HAL STM32 定时器PWM DMA输出方式 🧨遗留问题:当配置RCR重复计数器,配置为2时,在定义了3组PWM参数情况下,只能输出第二组参数的PWM波形。(HAL_TIM_PWM_Start_DMA(&htim1, TIM_CHANNEL_1, aCCValue_Buff…...

博客部署004-centos安装mysql及redis
1、如何查看当前centos版本? cat /etc/os-release 2、安装mysql 我的是centos8版本,使用dnf命令 2.1 CentOS 7/8: sudo yum install -y mysql-community-server 或者在CentOS 8上,使用DNF:🌟 sudo dnf install -y mysql-ser…...

Hive 之 UDF 运用(包会的)
文章目录 UDF 是什么?reflect静态方法调用实例方法调用 自定义 UDF(GenericUDF)1.创建项目2.创建类继承 UDF3.数据类型判断4.编写业务逻辑5.定义函数描述信息6.打包与上传7.注册 UDF 函数并测试返回复杂的数据类型 UDF 是什么? H…...

数据驱动目标:如何通过OKR实现企业数字化转型
在数字化转型的浪潮中,企业管理者面临着前所未有的挑战和机遇。如何确保企业在变革中不仅能够生存,还能蓬勃发展?答案可能就在于有效的目标管理——特别是采用OKR(Objectives and Key Results,目标与关键成果ÿ…...

软考120-上午题-【软件工程】-软件开发模型02
一、演化模型 软件类似于其他复杂的系统,会随着时间的推移而演化。在开发过程中,常常会面临以下情形:商业和产品需求经常发生变化,直接导致最终产品难以实现;严格的交付时间使得开发团队不可能圆满地完成软件产品&…...
C语言面试题之返回倒数第 k 个节点
返回倒数第 k 个节点 实例要求 1、实现一种算法,找出单向链表中倒数第 k 个节点;2、返回该节点的值; 示例:输入: 1->2->3->4->5 和 k 2 输出: 4 说明:给定的 k 保证是有效的。实…...

力扣爆刷第116天之CodeTop100五连刷66-70
力扣爆刷第116天之CodeTop100五连刷66-70 文章目录 力扣爆刷第116天之CodeTop100五连刷66-70一、144. 二叉树的前序遍历二、543. 二叉树的直径三、98. 验证二叉搜索树四、470. 用 Rand7() 实现 Rand10()五、64. 最小路径和 一、144. 二叉树的前序遍历 题目链接:htt…...

B站广告推广操作教程及费用?
哔哩哔哩(B站)作为国内极具影响力的年轻人文化社区,已成为众多品牌与企业触达目标受众、提升品牌影响力的重要阵地。然而,面对B站复杂的广告系统与精细化运营需求,许多广告主可能对如何高效开展B站广告推广感到困惑。云…...

Linux操作系统之docker基础
目录 一、docker 1.1 简介 1.2 安装配置docker 二、dockerfile 1.1、简介 1.2、dockerfile 关键字 一、docker 1.1 简介 容器技术 容器其实就是虚拟机,每个容器可以运行不同的系统【系统是以linux为主的】 为什么要使用docker? docker容器之间相互隔…...

35-3 使用dnslog探测fastjson漏洞
一、DNSLog 原理 DNSLog是一种记录在DNS上的域名相关信息的机制,类似于日志文件,记录了对域名或IP的访问信息。了解多级域名的概念对理解DNSLog至关重要。因特网采用树状结构的命名方法,按照组织结构划分域,每个域都是名字空间中被管理的一个划分,可以进一步划分为子域。域…...
)
保姆级教程:在STM32F103上从零移植FreeModbus V1.6(RTU模式)
保姆级教程:在STM32F103上从零移植FreeModbus V1.6(RTU模式) Modbus协议作为工业自动化领域的"普通话",其开源实现FreeModbus凭借轻量级和可移植性成为嵌入式开发者的首选。本文将手把手带你在STM32F103C8T6开发板上完成…...

Goofys安全最佳实践:保护你的S3文件系统访问的终极指南
Goofys安全最佳实践:保护你的S3文件系统访问的终极指南 【免费下载链接】goofys a high-performance, POSIX-ish Amazon S3 file system written in Go 项目地址: https://gitcode.com/gh_mirrors/go/goofys 在当今云原生时代,安全访问云存储变得…...

从IntelliJ到VSCode:开发体验无缝迁移完全指南
从IntelliJ到VSCode:开发体验无缝迁移完全指南 【免费下载链接】vscode-intellij-idea-keybindings Port of IntelliJ IDEA key bindings for VS Code. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-intellij-idea-keybindings 一、发现迁移痛点&…...

Wangle客户端开发实战:从零开始构建高效网络应用
Wangle客户端开发实战:从零开始构建高效网络应用 【免费下载链接】wangle Wangle is a framework providing a set of common client/server abstractions for building services in a consistent, modular, and composable way. 项目地址: https://gitcode.com/g…...

TheAmazingAudioEngine实战案例:构建完整的音乐制作应用
TheAmazingAudioEngine实战案例:构建完整的音乐制作应用 【免费下载链接】TheAmazingAudioEngine 项目地址: https://gitcode.com/gh_mirrors/th/TheAmazingAudioEngine TheAmazingAudioEngine是一款功能强大的音频处理框架,专为移动应用开发打造…...

从FasterRCNN到自定义检测器:SimpleDet扩展开发完全手册
从FasterRCNN到自定义检测器:SimpleDet扩展开发完全手册 【免费下载链接】simpledet A Simple and Versatile Framework for Object Detection and Instance Recognition 项目地址: https://gitcode.com/gh_mirrors/si/simpledet SimpleDet是一个简单且多功能…...

别再单独部署Mosquitto了!用Docker一步搞定带MQTT插件的RabbitMQ 3.13
告别繁琐部署:用Docker Compose快速搭建支持MQTT的RabbitMQ集群 在物联网和微服务混合架构中,消息中间件选型常常让开发者陷入两难——选择轻量级的Mosquitto MQTT broker虽然能满足设备通信需求,却无法处理服务间的AMQP消息;部署…...

5大核心能力解析:YimMenu如何重塑GTA5游戏体验与安全防护
5大核心能力解析:YimMenu如何重塑GTA5游戏体验与安全防护 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/Y…...

关键词搜索和SEO优化有什么关系_常见的关键词搜索误区有哪些
<h2>关键词搜索和SEO优化有什么关系</h2> <p>在当前数字化时代,网站流量的获取和保持已成为每一个企业和个人的重要目标。在这其中,关键词搜索和SEO优化是两个密不可分的环节。它们之间的关系不仅丰富了我们的网站内容,还帮…...

利用Dify平台快速搭建InternLM2-Chat-1.8B智能应用
利用Dify平台快速搭建InternLM2-Chat-1.8B智能应用 你是不是也遇到过这种情况:好不容易在服务器上部署了一个像InternLM2-Chat-1.8B这样的开源大模型,感觉它能力挺强,但除了在命令行里一问一答,就不知道怎么把它变成一个真正能用…...