ChatGLM2-6B_ An Open Bilingual Chat LLM _ 开源双语对话语言模型
ChatGLM2-6B_ An Open Bilingual Chat LLM _ 开源双语对话语言模型
文章目录
- ChatGLM2-6B_ An Open Bilingual Chat LLM _ 开源双语对话语言模型
- 一、介绍
- 二、使用方式
- 1、环境安装
- 2、代码调用
- 3、从本地加载模型
- 4、API 部署
- 三、低成本部署
- 1、模型量化
- 2、CPU 部署
- 3、Mac 部署
- 4、多卡部署
- 四、协议
- 五、源程序下载
一、介绍
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 [GLM]的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 [FlashAttention]技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。对于更长的上下文,我们发布了 [ChatGLM2-6B-32K] 模型。[LongBench]的测评结果表明,在等量级的开源模型中,ChatGLM2-6B-32K 有着较为明显的竞争优势。
- 更高效的推理:基于 [Multi-Query Attention] 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写[问卷]进行登记后亦允许免费商业使用。
ChatGLM2-6B 开源模型旨在与开源社区一起推动大模型技术发展,恳请开发者和大家遵守开源协议,勿将开源模型和代码及基于开源项目产生的衍生物用于任何可能给国家和社会带来危害的用途以及用于任何未经过安全评估和备案的服务。目前,本项目团队未基于 ChatGLM2-6B 开发任何应用,包括网页端、安卓、苹果 iOS 及 Windows App 等应用。
尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 ChatGLM2-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确性,且模型易被误导。本项目不承担开源模型和代码导致的数据安全、舆情风险或发生任何模型被误导、滥用、传播、不当利用而产生的风险和责任。
二、使用方式
1、环境安装
首先需要下载本仓库:
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
然后使用 pip 安装依赖:
pip install -r requirements.txt
其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
2、代码调用
可以通过如下代码调用 ChatGLM2-6B 模型来生成对话:
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
3、从本地加载模型
以上代码会由 transformers 自动下载模型实现和参数。完整的模型实现在 [Hugging Face Hub]。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
从 Hugging Face Hub 下载模型需要先[安装Git LFS],然后运行
git clone https://huggingface.co/THUDM/chatglm2-6b
如果你从 Hugging Face Hub 上下载 checkpoint 的速度较慢,可以只下载模型实现
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b
然后从[这里]手动下载模型参数文件,并将下载的文件替换到本地的 chatglm2-6b 目录下。
将模型下载到本地之后,将以上代码中的 THUDM/chatglm2-6b 替换为你本地的 chatglm2-6b 文件夹的路径,即可从本地加载模型。
模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在 from_pretrained 的调用中增加 revision="v1.0" 参数。v1.0 是当前最新的版本号,完整的版本列表参见 [Change Log]。
4、API 部署
首先需要安装额外的依赖 pip install fastapi uvicorn,然后运行仓库中的 api.py:
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" \-H 'Content-Type: application/json' \-d '{"prompt": "你好", "history": []}'
得到的返回值为
{"response":"你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-03-23 21:38:40"
}
感谢 @hiyouga 实现了 OpenAI 格式的流式 API 部署,可以作为任意基于 ChatGPT 的应用的后端,比如 ChatGPT-Next-Web。可以通过运行仓库中的openai_api.py 进行部署:
python openai_api.py
进行 API 调用的示例代码为
import openai
if __name__ == "__main__":openai.api_base = "http://localhost:8000/v1"openai.api_key = "none"for chunk in openai.ChatCompletion.create(model="chatglm2-6b",messages=[{"role": "user", "content": "你好"}],stream=True):if hasattr(chunk.choices[0].delta, "content"):print(chunk.choices[0].delta.content, end="", flush=True)
三、低成本部署
1、模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).cuda()
模型量化会带来一定的性能损失,经过测试,ChatGLM2-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。 量化模型的参数文件也可以从[这里]手动下载。
2、CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
如果你的内存不足的话,也可以使用量化后的模型
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).float()
在 cpu 上运行量化后的模型需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 [TDM-GCC] 时勾选 openmp。 Windows 测试环境 gcc 版本为 TDM-GCC 10.3.0, Linux 为 gcc 11.3.0。在 MacOS 上请参考 Q1。
3、Mac 部署
对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM2-6B。需要参考 Apple 的 官方说明 安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,而不是 2.x.x)。
目前在 MacOS 上只支持从本地加载模型。将代码中的模型加载改为从本地加载,并使用 mps 后端:
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
加载半精度的 ChatGLM2-6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 MacBook Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。
此时可以使用量化后的模型 chatglm2-6b-int4。因为 GPU 上量化的 kernel 是使用 CUDA 编写的,因此无法在 MacOS 上使用,只能使用 CPU 进行推理。
为了充分使用 CPU 并行,还需要单独安装 OpenMP。
在 Mac 上进行推理也可以使用 ChatGLM.cpp
4、多卡部署
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate: pip install accelerate,然后通过如下方法加载模型:
from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
即可将模型部署到两张 GPU 上进行推理。你可以将 num_gpus 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 device_map 参数来自己指定。
四、协议
本仓库的代码依照 Apache-2.0 协议开源,ChatGLM2-6B 模型的权重的使用则需要遵循 Model License。ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
五、源程序下载
源程序下载地址:ChatGLM2-6B_ An Open Bilingual Chat LLM _ 开源双语对话语言模型
相关文章:

ChatGLM2-6B_ An Open Bilingual Chat LLM _ 开源双语对话语言模型
ChatGLM2-6B_ An Open Bilingual Chat LLM _ 开源双语对话语言模型 文章目录 ChatGLM2-6B_ An Open Bilingual Chat LLM _ 开源双语对话语言模型一、介绍二、使用方式1、环境安装2、代码调用3、从本地加载模型 4、API 部署 三、低成本部署1、模型量化2、CPU 部署3、Mac 部署4、…...

JAVA的学习日记DAY6
文章目录 数组例子数组的使用数组的注意事项和细节练习数组赋值机制数组拷贝数组反转数组添加 排序冒泡排序 查找多维数组 - 二维数组二维数组的使用二维数组的遍历杨辉三角二维数组的使用细节和注意事项练习 开始每日一更!得加快速度了! 数组 数组可以…...
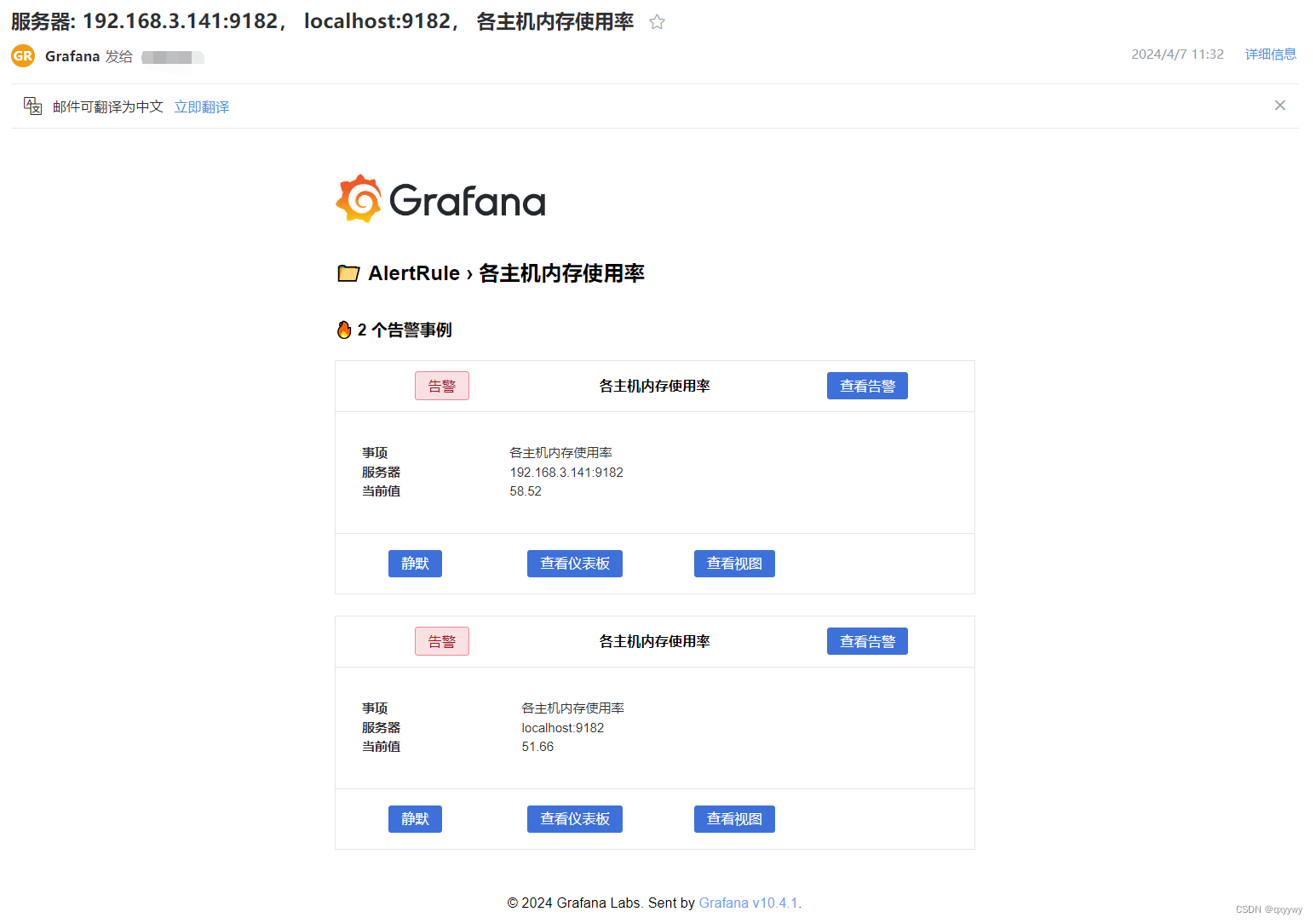
Grafana告警(邮件)自定义模板配置
一年前给客户部署配置过grafana,告警配置也是用的原始的,客户在使用过程中只需要一些核心点信息,想要实现这个就需要用Grafana的自定义告警模板以及编辑邮件模板。 通知模板 模板信息的配置中查阅了相关资料,自己组装了一套&…...
)
大话设计模式——六大基本设计原则(SOLID原则)
设计模式 定义:软件开发中,在特定上下文中解决一类常见问题的被证明为有效的最佳实践。可供其他开发者重复使用解决相似问题。 好处: 提高代码的可重用性,减少重复代码。提高代码的可维护性,使代码更易于理解和修改。…...

Qt | Q_PROPERTY属性和QVariant 类
一、属性基础 1、属性与数据成员相似,但是属性可使用 Qt 元对象系统的功能。他们的主要差别在于存取方式不相同,比如属性值通常使用读取函数(即函数名通常以 get 开始的函数)和设置函数(即函数名通常以 set 开始的函数)来存取其值,除此种方法外,Qt 还有其他方式存取属性值…...
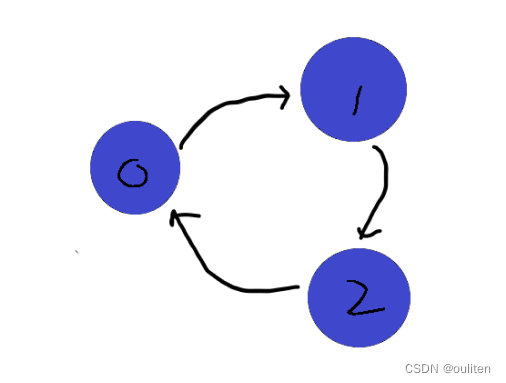
力扣207.课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。 在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。 例如…...

十五届web模拟题整理
模拟赛一期 1.动态的Tab栏 请在 style.css 文件中补全代码。 当用户向下滚动的高度没有超过标题栏(即 .heading 元素)的高度时,保持 Tab 栏在其原有的位置。当滚动高度超过标题栏的高度时,固定显示 Tab 栏在网页顶部。 /* TODO…...

ubuntu20.04 安裝PX4 1.13
step1_install_depenences.sh #!/bin/bash #install gazebo 11 #install protobuf 3.19.6python3 -m pip install --upgrade pip python3 -m pip install --upgrade Pillow# 將 empy 的版本調整爲3.3.4 pip3 uninstall empy pip3 install empy3.3.4sudo apt-get update sudo ap…...
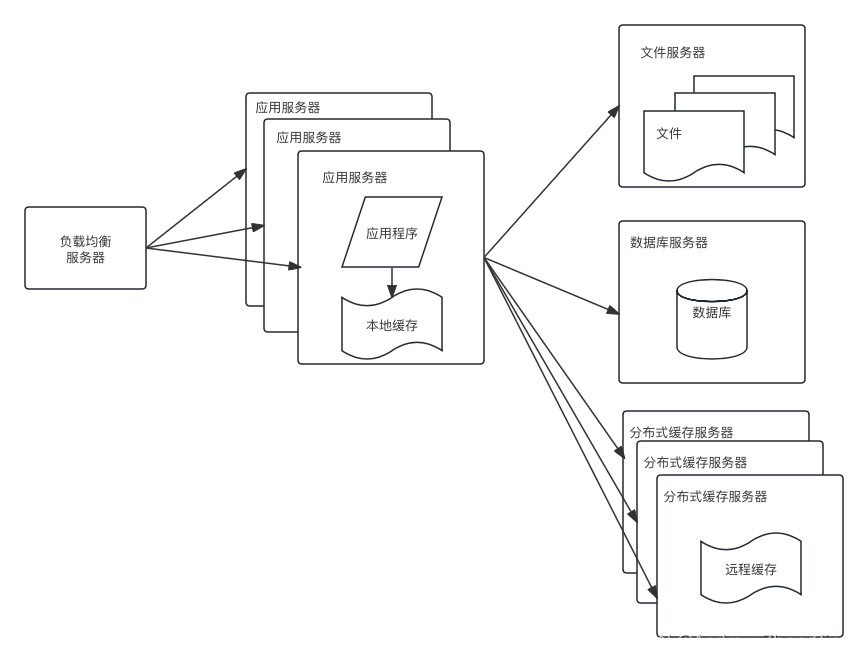
大型网站系统架构演化
大型网站质量属性优先级:高性能 高可用 可维护 应变 安全 一、单体架构 应用程序,数据库,文件等所有资源都在一台服务器上。 二、垂直架构 应用和数据分离,使用三台服务器:应用服务器、文件服务器、数据服务器 应用服…...
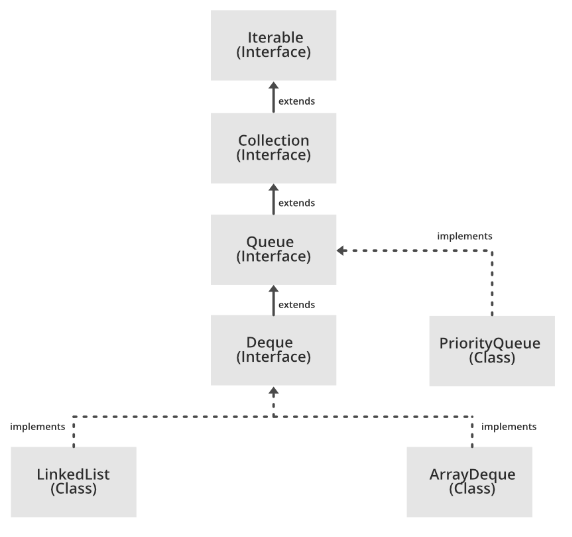
探索Java中的栈:Stack与Deque(ArrayDeque和LinkedList)
文章目录 1. 栈(Stack)1.1 定义方式1.2 特点1.3 栈的层次结构 2. 双端队列(Deque)2.1 定义方式及继承关系2.2 特点:2.3 ArrayDeque2.4 LinkedList2.5 Deque 的各种方法2.6 如何选择ArrayDeque和LinkedList 3. 如何选择…...

实践笔记-03 docker buildx 使用
docker buildx 使用 1.启用docker buildx2.启用 binfmt_misc3.从默认的构建器切换到多平台构建器3.1创建buildkitd.toml文件(私有仓库是http没有证书的情况下,需要配置)3.2创建构建器并使用新创建的构建器 4.构建多架构镜像并推送至harbor仓库…...

【数据结构与算法】之8道顺序表与链表典型编程题心决!
个人主页:秋风起,再归来~ 数据结构与算法 个人格言:悟已往之不谏,知来者犹可追 克心守己,律己则安! 目录 1、顺序表 1.1 合并两个有序数组 1.2 原地移除数组中所有的元素va…...

Go 源码之旅-开篇
欢迎来到《Go 源码之旅》专栏!在这个专栏中,我们将深入探索 Go 编程语言的内部数据结构的工作原理,一起踏上一段令人兴奋的源码之旅。 我们将一步步解析关键的数据结构底层工作原理以及一些常用框架的设计原理及其源码。 无论你是初学者还是…...

spring的事件推送
本质上是设计模式中的观察者模式。 一、什么是观察者模式 观察者模式是一种行为型设计模式,它定义了一种一对多的依赖关系,当一个对象的状态发生改变时,其所有依赖者都会收到通知并自动更新。 二、什么是spring的事件推送 在 Spring 的事…...

计算机网络—HTTPS协议详解:工作原理、安全性及应用实践
🎬慕斯主页:修仙—别有洞天 ♈️今日夜电波:ヒューマノイド—ずっと真夜中でいいのに。 1:03━━━━━━️💟──────── 5:06 🔄 ◀️ ⏸…...

卫星遥感影像在农业方面的应用及评价
一、引言 随着科技的进步,卫星遥感技术在农业领域的应用越来越广泛。卫星遥感技术以其宏观、快速、准确的特点,为农业生产和管理提供了有力的技术支撑。本文将对卫星遥感在农业方面的应用进行详细介绍,并通过具体案例进行说明。 二、…...
docker pull镜像的时候指定arm平台
指定arm平台 x86平台下载arm平台的镜像包 以mysql镜像为例 docker pull --platform linux/arm64 mysqldocker images查看镜像信息 要查看Docker镜像的信息,可以使用docker inspect命令。这个命令会返回镜像的详细信息,包括其元数据和配置。 docker i…...

如何通过OceanBase V4.2 动态采样优化查询性能
OceanBase v4.2 推出了优化器动态采样的功能,在SQL运行过程中,该功能会收集需要的统计信息,协助优化器制定出更好的执行计划,进一步提升了查询性能。 影响查询性能的因素是什么?为何你的优化器效果不佳? …...
Vue3---基础1(认识,创建)
变化 相对于Vue2,Vue3的变化: 性能的提升 打包大小减少 41% 初次渲染快 55%,更新渲染快133% 内存减少54% 源码的升级 使用 proxy 代替 defineProperty 实现响应式 重写虚拟 DOM 的实现和 Tree-shaking TypeScript Vue3就可以更好的支持TypeSc…...

JAVA集合ArrayList
目录 ArrayList概述 add(element) 用法 add(index, element)用法 remove(element)用法 remove(index)用法 get(index)用法 set(index,element) 练习 test1 定义一个集合,添加字符串,并进行遍历&…...

Kali 2023最新版安装Fluxion避坑指南:从git clone到镜像源全流程
Kali 2023最新版安装Fluxion避坑指南:从git clone到镜像源全流程 如果你正在学习网络安全渗透测试,Fluxion绝对是一个值得掌握的Wi-Fi安全审计工具。作为Kali Linux生态中最受欢迎的无线网络测试套件之一,它通过智能化的交互界面让复杂的攻击…...

实战级SQL注入测试技巧揭秘
目录 一、高阶注入判断技巧(不爆数据,只测漏洞) 1. 布尔盲注(Boolean-based) 2. 时间盲注(Time-based) 3. 报错注入(Error-based) 二、高阶利用手法(实战…...

别再死记硬背了!一张图+一个故事,帮你彻底搞懂分治、动态规划和贪心法的区别
算法三剑客:用旅行规划故事理解分治、动态规划与贪心法 想象你正在计划一次横跨欧亚大陆的三个月背包旅行。面对错综复杂的路线选择、预算分配和景点取舍,不同的决策策略会带来截然不同的旅行体验——这恰恰是分治法、动态规划和贪心算法在现实中的生动映…...
)
Unity游戏开发:如何用UniTask实现可撤销的异步流程(附完整代码)
Unity游戏开发:UniTask实现可撤销异步流程的工程实践 在游戏开发中,异步操作的管理一直是让开发者头疼的问题。想象这样一个场景:玩家在教学关卡中反复尝试某个操作,需要随时回退到上一步;或者在剧情分支选择时&#…...

5大核心功能提升英雄联盟体验:League-Toolkit全场景应用指南
5大核心功能提升英雄联盟体验:League-Toolkit全场景应用指南 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-T…...

Frida启动报错invalid address?手把手教你修复Android逆向工程环境
Frida启动报错invalid address?手把手教你修复Android逆向工程环境 当你满怀期待地启动Frida准备进行Android应用动态分析时,控制台突然抛出"invalid address"错误,那种感觉就像赛车手在起跑线上发现引擎故障。这个看似简单的错误信…...

GT IP跑Aurora 64B66B协议:从变速箱到加扰的实战避坑指南
GT IP实现Aurora 64B66B协议:从变速箱到加扰的工程实践全解析 在高速串行通信领域,Xilinx的GT系列IP核配合Aurora 64B66B协议已成为许多硬件工程师的首选方案。这种组合能够提供高达数十Gbps的数据传输速率,广泛应用于数据中心互连、高性能计…...

避坑指南:CentOS7部署LibreNMS常见错误及解决方案
CentOS7部署LibreNMS避坑实战:从SELinux到数据库权限的深度排错指南 对于网络监控系统的部署,LibreNMS以其开源特性和强大功能成为众多技术团队的首选。但在CentOS7环境下,从系统配置到服务调优的每个环节都可能成为阻碍顺利部署的暗礁。本文…...

Elasticsearch-05-四种搜索方案
Elasticsearch-05-四种搜索方案详解 概述 Elasticsearch提供了多种搜索方案以满足不同的业务需求。本文档将详细介绍四种核心搜索方案:纯BM25、纯KNN、混合搜索和优化KNN参数,包括各自的适用场景、配置方法和实际应用。 方案1:纯BM25搜索 场景…...

Ultimaker Cura:开源3D打印切片工具从入门到精通指南
Ultimaker Cura:开源3D打印切片工具从入门到精通指南 【免费下载链接】Cura 3D printer / slicing GUI built on top of the Uranium framework 项目地址: https://gitcode.com/gh_mirrors/cu/Cura Ultimaker Cura作为一款免费开源的3D打印切片软件ÿ…...