Clickhouse数据去重
1. Hive去重
先以两个简单的sql启发我们的话题
select count(distinct id)from order_combine;select count(id)
from (select id from order_combine group by id
) t;
从执行日志当中我们可以看到二者的差异(只摘取关键部分)
# distinct
+ Stage-Stage-1:Map: 396 Reduce: 1 ...Time taken: 200.192 seconds#group byStage-Stage-1: Map: 396 Reduce: 457 ...Time taken: 87.191 seconds
二者关键的区别就在于使用distinct会将id都shuffle到一个reducer里面,当数据量大了之后,不可避免的就会出现数据倾斜。
group by在reducer阶段会将数据分布到多台机器上执行,在处理大数据时在执行性能上自然相比于distinct提高很多。
其实一般面试中,这种程度的回答会考量到MapReduce阶段数据的分区分组以及流向是否真正理解。
但是我们今天的主题主要是去重,写到这里就此打住很显然是不行的。
让我们换个角度思考一下
针对一个常用的order表去重就需要消耗87s的时间,如果我们在日常工作中经常需要针对order表进行数据分析,可想而知,这样的速度是难以忍受的。
老兵也常常就遇到这样的问题,两年前公司就开始慢慢的用Spark引擎替换Hive,在速度上加快了很多,但是随着业务的发展,Spark的实时查询能力还是显得有些力不从心,在去重方面的性能自然不必多说。
能不能找到一个方案让去重更快?
说到这里,ClickHouse就呼之欲出了。接下来会详细介绍ClickHouse的主要原理以及他是如何去重的。
2. Clickhouse
ClickHouse 是 Yandex(俄罗斯最大的搜索引擎)开源的一个用于实时数据分析的基于列存储的数据库。
ClickHouse的性能超过了目前市场上可比的面向列的 DBMS,每秒钟每台服务器每秒处理数亿至十亿多行和数十千兆字节的数据。
2.1 MergeTree存储结构
说得这么神乎其神,很多人可能会有疑问,ClickHouse真的有这么强大吗?
要了解Clickhouse的强大,首先要提的绝对是合并树MergeTree引擎,因为Clickhouse的核心原理就是依赖于它,而所有的其他引擎都是基于它来实现的。
我将以MergeTree为切入点揭开ClickHouse神秘面纱。
从图中可以看出,一张数据表的完整物理结构分为3个层级,依次是数据表目录、分区目录及各分区下具体的数据文件。接下来逐一介绍它们的作用。

partition:分区目录,属于相同分区的数据最终会被合并到同一个分区目录,而不同分区的数据,永远不会被合并到一起。checksums.txt:校验文件,使用二进制格式存储。它保存了各类文件(primary.idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。columns.txt:列信息文件,使用明文格式存储。用于存储此数据文件下的列字段信息。count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数。所以,利用Clickhouse我们经常算的分区总行数又何必反复扫描计数。primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引。借助稀疏索引有效减少数据扫描范围,加快查询速度。[Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式。由于MergeTree采用列式存储,所以每一个列都拥有独立的.bin数据文件,并以列字段名称命名(例如impdate.bin,age.bin等)。[Column].mrk:列字段标记文件,使用二进制格式存储。用以保存.bin数据的偏移量。因此,MergeTree就是通过标记文件建立了primary.idx稀疏索引与.bin数据文件之间的映射关系。[Column].mrk2:如果使用了自使用大小的索引间隔,则标记文件会以.mrk2命名。partition.dat与minmax_[Column].id:如果使用了分区键,例如Parition By ImpTime,则会额外生产partition.dat与minmax索引文件,它们均用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值;而minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值。在这些分区索引的作用下,进行数据查询能够快速跳过不必要的数据分区目录,从而减少最终需要扫描的数据范围。skp_idx_[Column].idx与skp_idx_[Column].mrk:如果在建表时声明了二级索引就会额外生成相应的二级索引与标记文件,它们同样也使用二进制存储。显然,最终目的与一级索引相同,都是为了进一步减少所需扫描的数据范围。
反问一个问题,为什么Clickhouse的引擎叫MergeTree呢?
搞懂了它的数据分区相信你们得到答案。我将详细介绍一下Clickhouse是如何进行数据分区的。
2.2 MergeTree数据分区
如果进入数据表所在的磁盘目录后,会发现MergeTree分区目录的完整物理名称并不是只有id而已,在id之后还跟着一串奇怪的数字,例如202112_1_1_0。这些数字代码什么呢?
对于MergeTree而言,最核心的特点就是分区目录的合并过程,想要搞清楚过程,其实从分区目录的命名中就能解读出它的合并逻辑。如下一个完整分区目录的命名公式:
PartitionID_MinBlockNum_MaxBlockNum_Level
我这里画了一张图来便于大家理解,并在下面附加对它的解释。
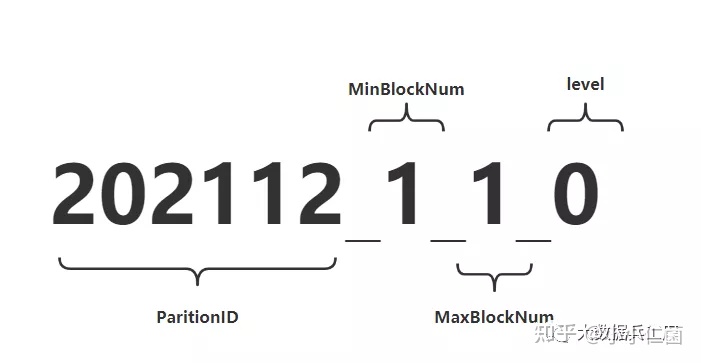
2.2.1 命名规则
PartitionID: 分区ID**MinBlockNum和MaxBlockNum:顾名思义,最小数据块编号和最大数据块编号。这里的BlockNum是一个整型的自增长编号,从1开始,每新创建一个分区目录时,计数n就会累加1。对于一个新的分区目录而言,MinBlockNum与MaxBlockNum取值一样,等同于n,例如202112_1_1_0、202112_2_2_0以此类推。Level:合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄,数值越高,年龄越大。
2.2.2 分区目录的合并过程
MergeTree的分区目录当然和传统意义上的其他数据库有所不同。其中最大的差别是在其他数据库的设计中,追加数据后目录自身不会变化,只是在相同分区目录中追加新的数据文件,比如hive存储目录就是如此。
而MergeTree不同,随着每一批数据的写入,MergeTree都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。
在之后某个时刻,Clickhouse会通过后台任务再将数据相同分区的多个目录合并成一个新的目录。已经存在的旧分区不会立即删除,而是在之后的某个时刻被后台任务删除(默认8分钟)。新目录的合并方式遵循以下规则:
MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值。MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值。Level:取同一分区内最大的Level值并加一。
2.2.3 合并目录名称的变化过程
照例我这里先上一张图让大家直观的看一下合并目录名称的变化过程

按照上图所示,测试表按日期字段格式分区,即PARTITION BY toYTYYYMM(EvenT-Time)。假设在T0时刻,首先分3批插入如上3条数据,按照目录规则,上述代码会创建3个分区目录。分区目录的名称由PartitionID、MinBlockNum、MaxBlockNum和Level组成,3个分区目录ID依次是202111,202111和202112。
而对于每个新建的分区目录而言,它们的MinBlock- Num和MaxBlockNum取值相同,均来源于表内全局自增长的BlockNum。
- BlockNum初始为1,每次新建目录后累计加1。所以,3个分区目录的MinBlockNum和MaxBlockNum依次为
0_0,1_1,2_2。最后就是Level层级,每个新建的分区目录初始Level都是0。 - 假设在T1时刻,MergeTree的合并动作开始了,属于同一分区的目录就会发生合并,这个时候
202111_1_1_0和2021_2_2_0如上图所示完成合并动作之后形成一个新的分区202111_1_2_1。 - 其中MinBlockNum取同一分区内所有目录中
最小的MinBlockNum值所以是1。MaxBlockNum取同一分区内所有目录最大的MaxBlockNum值,也就是2。此时Level取同一分区内最大的Level值加1,即1。而后的合并就是重复上述的过程而已。
至此,大家已经知道了分区ID、目录命名和目录合并的相关规则。相信开始对Clickhouse有一些感觉了。
2.3 稀疏索引
如果仅仅只是分区的优化,详细大家还是会对Clickhouse持怀疑态度。其实相比于传统基于HDFS的OLAP引擎,clickhouse不仅有基于分区的过滤,还有基于列级别的稀疏索引,这样在进行条件查询的时候可以过滤到很多不需要扫描的块,这样对提升查询速度是很有帮助的。

2.3.1 稀疏索引与稠密索引
简单来说,在稠密索引中的每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中,每一行索引标记对应的是一段数据,而不是一行。
如果把MergeTree比作一本书,那么稀疏索引就好比这本书的一级章节目录。
稀疏索引的优势是显而易见的,他仅需要少量的索引标记就可以记录大量的区间位置信息,且数据量越大优势约为明显。以默认的索引粒度(8192)为例,只需要12208行索引就可以为1亿行的数据记录提供索引。由于稀疏索引占用空间小,索引primary.idx内的索引数据常驻内存,取用速度自然极快。
我们以一张图看下索引数据写入primary.idx又是如何进行的

上图不难理解,我们把AccountId作为我们的主键字段,Clickhouse每间隔8192行数据会取一次AccountId作为索引值,索引数据最终被写入primary.idx文件进行保存。
如上的编号0、编号1、编号2是按照字段顺序紧密排序在一起的,比如1112345689,因此我们可以看出MergeTree对于稀疏索引的存储还是非常紧凑的。
不仅此处,clickhouse中很多数据结构都被设计的非常紧凑。比如其使用位读取代替专门的标志位或状态码,不浪费哪怕一个字段的空间。以小见大,这也是为什么Clickhouse为何性能如此出众的深层原因之一。
说到这里,索引的查询过程就是我们不可回避的问题了。
了解索引的查询过程,首先需要了解什么是MarkRange
MarkRange在Clickhouse是用于定义标记区间的对象。通过先前的介绍可知,MergeTree按照自定义的间隔粒度,将一段完整的数据划分成了多个小的间隔数据段,一个具体的数据段即是一个MarkRange。MarkRange与索引编号对应,使用start和end两个属性表示其区间范围。

整个索引的查询过程可以大致分为3个步骤:
- 生成查询条件区间:首先,将查询条件转换成条件区间。如:wehre AccountId = 'U003'会转换成['U003','U003']。
- 递归交集判断:以递归的方式,依次对MarkRange的数值区间与条件区间做交集判断。
- 如果不存在交集,直接
剪枝。 - 如果存在交集,判断MarkRange步长是否大于8(end - start) ,如果大于则进一步拆分成8个子区间(
merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续递归交集判断。 - 如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
- 合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并他们的范围。
- 如果不存在交集,直接
Clickhouse同样支持二级索引,目的也是与一级索引一样,帮助查询时减少数据扫描的范围。
当然,Clickhouse在设计上还做了很多优化来提高我们的数据处理能力以及数据存储能力。篇幅有限,后面再对它们进行详细展开,现在可以大致了解一下。
2.4 其他特性
1)CPP
clickhouse是CPP编写的,代码中大量使用了CPP最新的特性来对查询进行加速。优秀的代码,对性能的极致追求。
2)列存储
最小化数据扫描范围。更好的进行数据压缩。
3)压缩数据块
有效减少数据大小,降低存储空间并加速数据传输效率。在具体读取某一列数据时,首先需要将压缩数据加载到内存并解压,这样才能进行后续的数据处理。通过压缩数据块,可以在不读取整个数据文件的情况下将读取的粒度降低到压缩数据级别,从而进一步缩小了数据读取的范围。
4)SIMD
Clickhouse利用CPU的SIMD指令来实现向量化执行。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式 ( 其他的还有指令级并行和线程级并行 )。
原理: 在CPU寄存器层面实现数据的并行操作。
简单来说就是一个指令能够同时处理多个数据。所以利用CPU向量化执行的特性,对于程序的性能提升意义非凡。
数据分片与分布式查询Clickhouse作为一款在线分析处理查询的大数据引擎,自然少不了集群部署、数据分片的能力。从而利用分布式查询横向扩展提高数据查询速度。
光说不练假把式,我们最后就来看看基于Clickhouse做去重究竟有多快~
3. ClickHouse去重优化
下面是我针对12亿数据做的测试,帮大家直观的感受下Clickhouse的速度。(涉及保密信息会被msk-手动狗头)
3.1 数据查询(非去重)
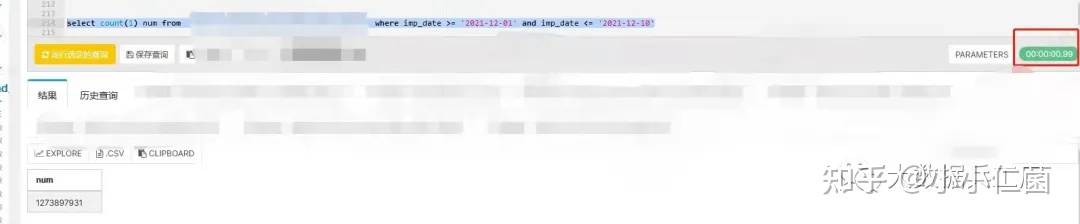
select count(1) num
from a
whereimp_date >= '2021-12-01' and imp_date <= '2021-12-10'
3.2 数据查询(去重)
下面看看Clickhouse普通去重的写法:
select count(distinct dt_accountid ) user_num
from awhere imp_date >= '2021-12-01' and imp_date <= '2021-12-10'
从两张图中的红框部分我们能得到两个信息:
- 基于
12亿数据做count聚合查询总数可以秒级别内得到响应,这与我前面提高的数据分区目录存储和索引密不可分。 - 基于12亿数据数据去重,响应时间在
7s左右
看到这样的测试结果,相信很多之前没有接触过Clickhouse的人会大吃一惊。因为它相比于spark、hive简直是太快了。其实它在去重上的能力还远不止于此。
3.3 数据查询(Bitmap去重)
下面我们使用Clihouse的Bitmap机制进行去重:

select groupBitmap(toUInt64OrZero (dt_accountid)) user_num
from a
where imp_date >= '2021-12-01' and imp_date <= '2021-12-10'
从图中我们会惊奇的发现,换了一个写法,Clickhouse基于Bitmap去重竟然将去重速度又提高了一个量级。
这就是我们经常在处理大数据去重为了加快速度和节省内存时做的终极优化: 利用Bitmap。
为什么用count(distinct)跟groupBitmap两个函数差异如此之大呢我们有必要看下源码:
// count(distinct)
// HashSetTable
void merge(const Self & rhs){if (!this->hasZero() && rhs.hasZero()){this->setHasZero();++this->m_size;}for (size_t i = 0; i < rhs.grower.bufSize(); ++i)if (!rhs.buf[i].isZero(*this))this->insert(rhs.buf[i].getValue());}
// groupBitmap
// RoaringBitmapWithSmallSet
void merge(const RoaringBitmapWithSmallSet & r1){if (r1.isLarge()){if (isSmall())toLarge();*rb |= *r1.rb;}else{for (const auto & x : r1.small)add(x.getValue());}}
Bitmap原理
- 从上面的代码块我们可以很清楚地看到:
count(distinct)用到的uniqExact是使用一个hash表来合并聚合数据,利用hash表的唯一特性来精确去重,在10亿级别的for循环中十分耗时(gdb打印了rhs.grower.bufSize()的值为20亿,耗时2分钟左右)。 - 而
RoaringBitmapWithSmallSet的merge在高基维场景下只做了一次或运算,耗时基本可以忽略。大家如果还不了解HashSetTable和RoaringBitmap可以自行补上这些知识,这里暂且不展开来讲。
所以我们发现即便在Clickhouse这种场景下,不深入了解他的基本原理,我们对于同一个业务不同的实现性能也会差别极大。
相关文章:
Clickhouse数据去重
1. Hive去重 先以两个简单的sql启发我们的话题 select count(distinct id)from order_combine;select count(id) from (select id from order_combine group by id ) t;从执行日志当中我们可以看到二者的差异(只摘取关键部分) # distinctStage-Stage…...

精讲typescript从入门到入土
前言 TypeScript是一种由Microsoft开发的编程语言,它是JavaScript的超集,意味着它可以编写与JavaScript完全兼容的代码,并且可以扩展其功能。TypeScript的主要目标是提供类型安全性和更好的可维护性,使得开发大型复杂应用程序更加…...

typora-beta-0.11.18版本又提示过期的解决方案
很实用,所以照搬一下下面的作者的回答,省得以后再找~~~ 知乎的作者来源如下: 作者:吴小皓 链接:typora打开报错:This beta version of Typora is expired, please download and install a newer version …...
-优化:测试对象无法连接或出现异常时,请更新本文作为测试对象)
WebUI自动化测试框架搭建(二十)-优化:测试对象无法连接或出现异常时,请更新本文作为测试对象
(二十)-测试对象无法连接或出现异常时,请更新本文作为测试对象 1 测试对象说明2 源代码下载3 学生管理系统配置安装3.1 解压打开3.2 安装依赖3.3 安装mysql数据库3.4 修改项目数据库配置3.4 安装数据库连接工具Navicat3.5 导入数据库脚本4 运行学生管理系统5 系统查看1 测试…...
【FATE联邦学习】standalone版Fateboard修改配置
背景&做法 很多其他程序(比如vscode的code server)也会使用这个 127 0 0 1:8080 socket进行通信,这样就没办法远程用vscode去开发了,所以需要修改下Fateboard的socket配置。官方文档中也给出了如何修改配置 The default data…...
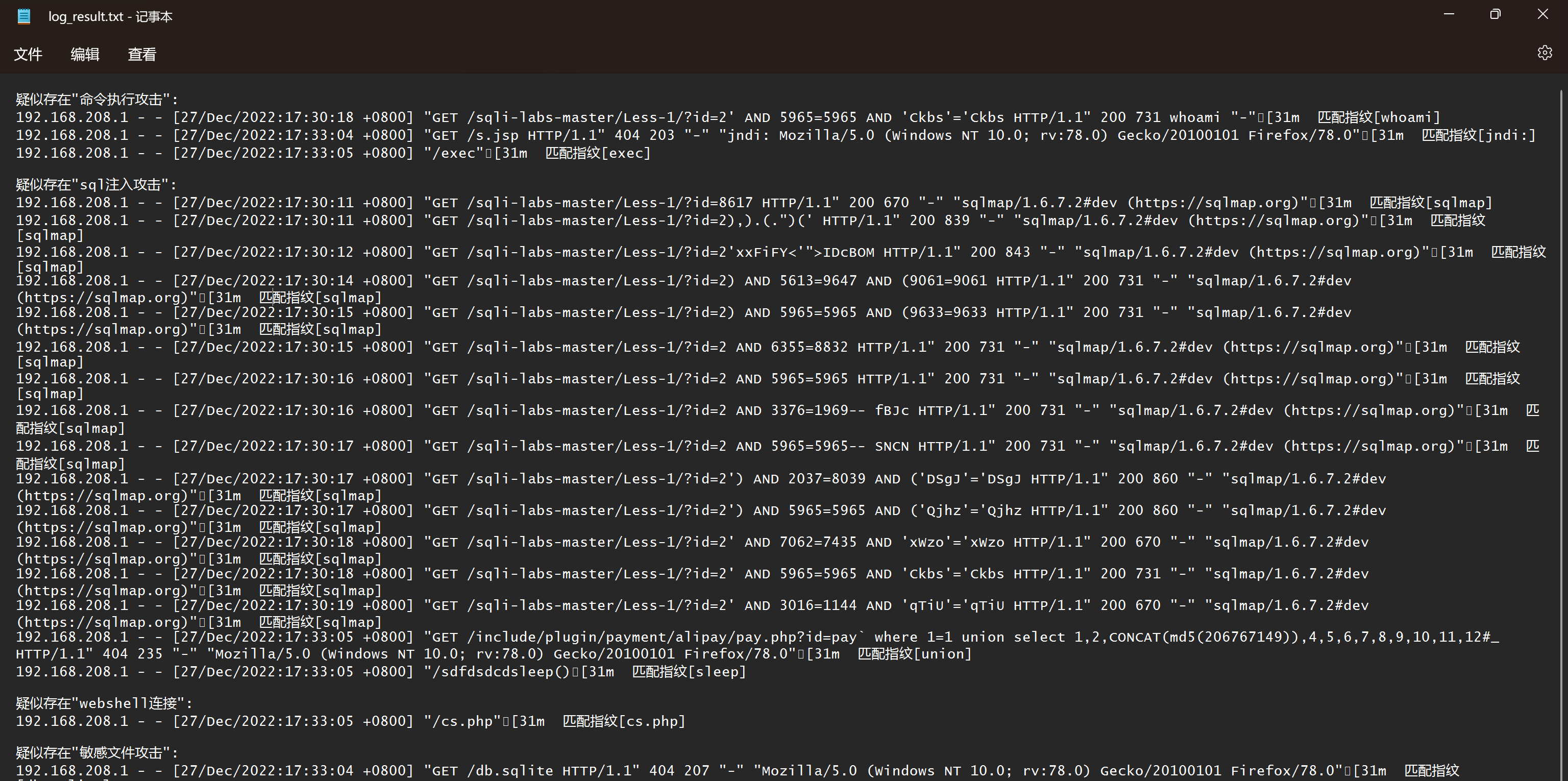
分享一个应急响应web日志:access.log文件分析小工具
有时做应急响应的时候,需要提取web日志如access.log日志文件来分析系统遭受攻击的具体原因,由于开源的工具并不是很好用,所以自己用Python3写了一个简单的日志分析工具。先介绍一下access.log日志access.log日志文件记录了所有目标对Web服务器…...

windows注册服务非常实用
方式一:使用Windows自带的sc命令 1、使用管理员权限打开cmd窗口 2、注册服务命令: sc create 服务名 binpath 程序所在路径 type own start auto displayname 服务显示名称 sc create redis binpath d:\tools\redis-x64-5.0.14\redis-server.exe type …...
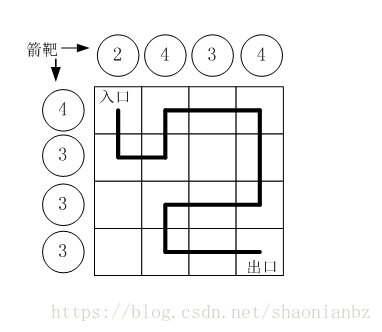
蓝桥dfs专题
1、dfs 路径打印 小明冒充X星球的骑士,进入了一个奇怪的城堡。 城堡里边什么都没有,只有方形石头铺成的地面。 假设城堡地面是 n x n 个方格。【如图1.png】所示。 按习俗,骑士要从西北角走到东南角。 可以横向或纵向移动,但不能…...
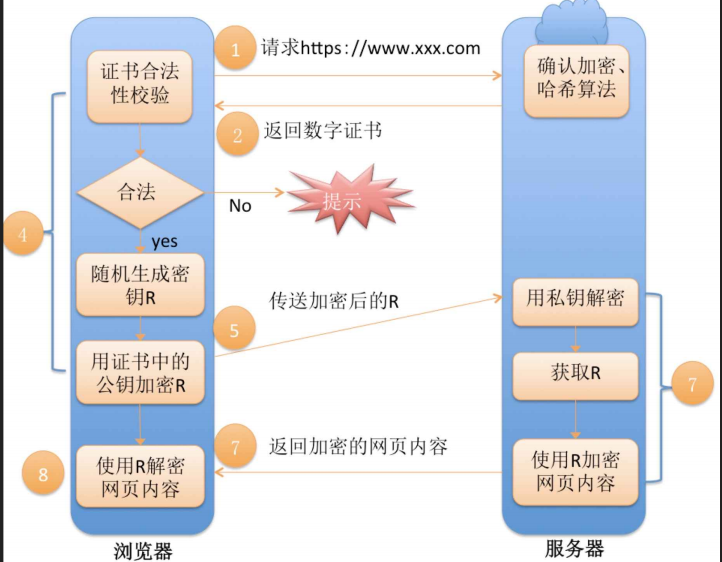
[ 网络 ] 应用层协议——HTTPS协议原理
目录 1.HTTPS是什么 2.加密技术 2.1什么是加密 2.2为什么要加密 2.3加密处理防止被窃听 3.常见的加密方式 对称加密 非对称加密 4.数据摘要&&数据指纹 5.数字签名 6.HTTPS的工作过程探究 方案1——只是用对称加密 方案2——只进行非对称加密 方案3——双方…...

http协议如何操作
、HTTP协议(超文本传输协议) 1.1、http协议是一个基于“请求与响应”模式的、无状态的应用层协议。 http协议采用URL作为定位网络资源的标识。 1.2、URL格式 http://host[:port][path] host:合法的Internet主机域名或IP地址 port:端口号…...

ESP Insights 系列文章
ESP Insights 系列 #1 | 远程查看设备信息,快速解决固件问题 ESP Insights 是一个可远程查看设备固件运行状态和日志的平台,能够帮助开发人员快速定位并解决固件问题。 ESP Insights 系列 #2 | 新增功能 最新版本优化了用户界面、修复了系统稳定性&am…...

如何提高爬虫工作效率
单进程单线程爬取目标网站太过缓慢,这个只是针对新手来说非常友好,只适合爬取小规模项目,如果遇到大型项目就不得不考虑多线程、线程池、进程池以及协程等问题。那么我们该如何提升工作效率降低成本? 学习之前首先要对线程&#…...

React结合Drag API实现拖拽示例详解
Drag API React中的Drag API是用于实现拖放功能的API。该API由React DnD库提供,可用于实现拖放操作,例如将元素从一个位置拖动到另一个位置。 React DnD库提供了两种Drag API:基于HTML5的拖放API和自定义实现的拖放API。 基于HTML5的拖放AP…...
)
【华为OD机试java、python、c++、jsNode】新学校选址(100%通过+复盘思路)
代码请进行一定修改后使用,本代码保证100%通过率。本文章提供java、python、c++、jsNode四种代码。复盘思路在文章的最后 题目描述 为了解新学期学生暴涨的问题,小乐村要建立所新学校, 考虑到学生上学安全问题,需要所有学生家到学校的距离最短。 假设学校和所有学生家都走在…...
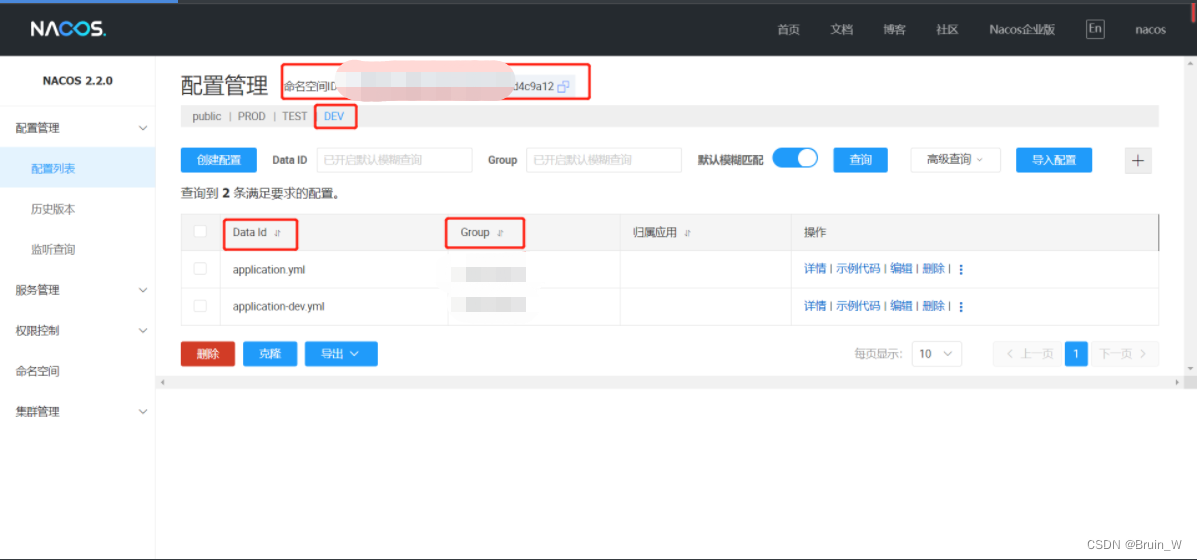
Nacos配置中心,分组配置参考,以及python、go、bash客户端连接获取
Nacos使用说明 nacos官方网站 https://nacos.io/zh-cn/docs/v2/what-is-nacos.html 1、基本配置说明 nacosIP地址:http://xxxxx:8848/nacos/ 服务管理端登录账号:nacos XXX Java最小配置,其他客户端可参考,配置可对应到第三章…...

node-red中有关用户登录,鉴权,权限控制的流程解析
前言 默认地,node-red编辑器可以被任何访问的用户操作,包括修改节点,流数据,重新部署流。 这种默认的部署方式只适用于运行在可靠的网络中。下面我就给大家介绍一下,在公网上部署node-red后,如何对其进行安全加固和权限验证。 主要分为三部分 开启https权限保护编辑器和…...

MQTT协议-使用CONNECT报文连接阿里云
使用网络调试助手发送CONNECT报文连接阿里云 参考:https://blog.csdn.net/daniaoxp/article/details/103039296 在前面文章介绍了如何组装CONNECT报文,以及如何计算剩余长度 CONNECT报文:https://blog.csdn.net/weixin_46251230/article/d…...

每日学术速递3.8
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CV 1.Unleashing Text-to-Image Diffusion Models for Visual Perception 标题:释放用于视觉感知的文本到图像扩散模型 作者:Wenliang Zhao, Yongming Rao, Zuya…...

测牛学堂:软件测试之接口测试理论基础总结
接口概念 接口:系统之间数据交互的通道。 这个系统,可以是外部和内部,也可以是两个内部系统之间的通道。 比如我们前端的登录信息,主要是用户名和密码,它通过接口传递给后端,后端校验以后,把结…...

基于土壤数据与机器学习算法的农作物推荐算法代码实现
1.摘要 近年来,机器学习方法在农业领域的应用取得巨大成功,广泛应用于科 学施肥、产量预测和经济效益预估等领域。根据土壤信息进行数据挖掘,并在此基础上提出区域性作物的种植建议,不仅可以促进农作物生长从而带来经济效益&#…...

开源自托管看板工具:基于Preact+Hono+SQLite的零云依赖方案
1. 项目概述:一个为自托管与AI协作而生的看板应用如果你正在寻找一个可以完全掌控在自己手里、没有订阅费用、又能无缝集成到你自己产品中的看板工具,那么clawnify/open-kanban这个项目值得你花时间深入研究。它不是一个玩具,而是一个生产就绪…...

智能家居安全新突破:视觉AI如何实现从感知到认知的跨越
1. 项目概述:当视觉智能成为家庭安全的“火眼金睛”最近几年,智能家居的概念越来越火,从智能门锁到语音助手,似乎家里的一切都在变得“聪明”。但说实话,很多所谓的“智能”安全方案,比如单纯依靠门窗传感器…...

TEdit终极教程:如何用免费地图编辑器10倍提升泰拉瑞亚创作效率
TEdit终极教程:如何用免费地图编辑器10倍提升泰拉瑞亚创作效率 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also let…...

端到端AI安家助手:基于WhatsApp的多模态智能体系统架构与实践
1. 项目概述:一个为加拿大新移民设计的端到端AI安家助手如果你刚到一个陌生的国家,面对一堆看不懂的表格、复杂的申请流程和紧迫的截止日期,是不是会感到手足无措?这正是许多加拿大新移民面临的真实困境。49th项目就诞生于这种切身…...

如何给非技术背景的老板汇报技术问题?一个框架搞定
一、为什么你的技术汇报,老板总是听不进去?作为软件测试工程师,你可能经历过这样的场景:你花了一整个周末整理出一份详尽的测试报告,里面涵盖了用例执行率、缺陷分布、严重等级、性能拐点等专业数据。但当你信心满满地…...

Firefly开源中文大模型:指令微调、部署与领域适配实战
1. 项目概述:一个专为中文优化的开源大语言模型最近在开源社区里,Firefly(流萤)这个项目引起了我的注意。它不是一个通用框架,而是一个经过精心指令微调的大语言模型系列。简单来说,你可以把它理解为一个“…...

2026论文降AI实战SOP:保留排版格式,8款工具与结构级优化指南
内容ai率检测数值太高,不得不熬夜改了一遍又一遍,润色到想吐,结果检测报告上数字还是不尽人意,截止日期越逼越近,真的是没办法了。 我花了整整三天,把2026全网热门的几十款降AI工具通通测了个遍࿰…...

PetaLinux下为ZynqMP配置GMII2RGMII驱动:从设备树修改到内核编译的完整指南
PetaLinux下为ZynqMP配置GMII2RGMII驱动的实战指南 在嵌入式Linux开发中,以太网驱动的配置往往是系统集成的关键环节。对于使用Xilinx ZynqMP芯片的开发者来说,当硬件设计采用GMII2RGMII IP核实现PL端以太网功能时,如何在PetaLinux环境下正确…...

Windows 10/11 环境下 OpenClaw v2.7.1 安装避坑与常见问题解决方案
🦞 OpenClaw v2.7.1 Windows 一键部署教程|5 分钟搭建本地 AI 智能体 在本地 AI 自动化工具快速普及的当下,OpenClaw(小龙虾)凭借全程可视化、一键部署、本地运行的特点,成为 Windows 平台上易用性突出的 …...

CLion集成LVGL与SDL:打造高效嵌入式GUI模拟开发环境
1. 为什么需要CLionLVGLSDL组合? 如果你正在开发嵌入式设备的图形界面,肯定遇到过这样的困境:每次修改UI都要烧录到硬件上测试,一个简单的颜色调整可能要反复折腾十几分钟。我在开发智能手表项目时就深受其害,直到发现…...