【域适应】基于域分离网络的MNIST数据10分类典型方法实现
关于
大规模数据收集和注释的成本通常使得将机器学习算法应用于新任务或数据集变得异常昂贵。规避这一成本的一种方法是在合成数据上训练模型,其中自动提供注释。尽管它们很有吸引力,但此类模型通常无法从合成图像推广到真实图像,因此需要域适应算法来操纵这些模型,然后才能成功应用。现有的方法要么侧重于将表示从一个域映射到另一个域,要么侧重于学习提取对于提取它们的域而言不变的特征。然而,通过只关注在两个域之间创建映射或共享表示,他们忽略了每个域的单独特征。域分离网络可以实现对每个域的独特之处进行特征建模,,同时进行模型域不变特征的提取。
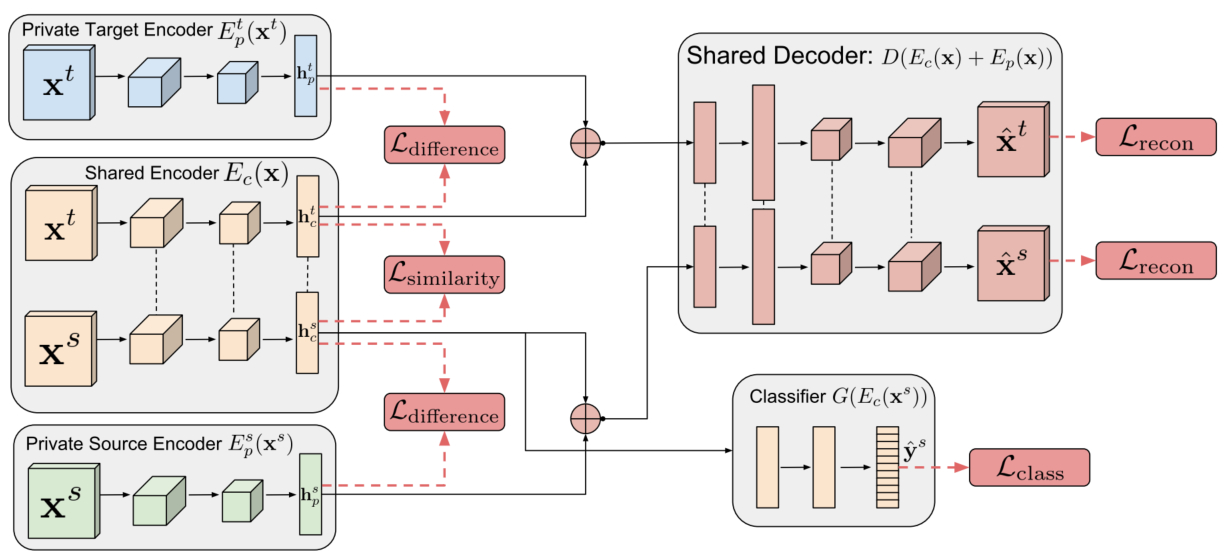
参考文章: https://arxiv.org/abs/1608.06019
工具


方法实现
数据集定义
import torch.utils.data as data
from PIL import Image
import osclass GetLoader(data.Dataset):def __init__(self, data_root, data_list, transform=None):self.root = data_rootself.transform = transformf = open(data_list, 'r')data_list = f.readlines()f.close()self.n_data = len(data_list)self.img_paths = []self.img_labels = []for data in data_list:self.img_paths.append(data[:-3])self.img_labels.append(data[-2])def __getitem__(self, item):img_paths, labels = self.img_paths[item], self.img_labels[item]imgs = Image.open(os.path.join(self.root, img_paths)).convert('RGB')if self.transform is not None:imgs = self.transform(imgs)labels = int(labels)return imgs, labelsdef __len__(self):return self.n_data模型搭建
import torch.nn as nn
from functions import ReverseLayerFclass DSN(nn.Module):def __init__(self, code_size=100, n_class=10):super(DSN, self).__init__()self.code_size = code_size########################################### private source encoder##########################################self.source_encoder_conv = nn.Sequential()self.source_encoder_conv.add_module('conv_pse1', nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5,padding=2))self.source_encoder_conv.add_module('ac_pse1', nn.ReLU(True))self.source_encoder_conv.add_module('pool_pse1', nn.MaxPool2d(kernel_size=2, stride=2))self.source_encoder_conv.add_module('conv_pse2', nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5,padding=2))self.source_encoder_conv.add_module('ac_pse2', nn.ReLU(True))self.source_encoder_conv.add_module('pool_pse2', nn.MaxPool2d(kernel_size=2, stride=2))self.source_encoder_fc = nn.Sequential()self.source_encoder_fc.add_module('fc_pse3', nn.Linear(in_features=7 * 7 * 64, out_features=code_size))self.source_encoder_fc.add_module('ac_pse3', nn.ReLU(True))########################################## private target encoder#########################################self.target_encoder_conv = nn.Sequential()self.target_encoder_conv.add_module('conv_pte1', nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5,padding=2))self.target_encoder_conv.add_module('ac_pte1', nn.ReLU(True))self.target_encoder_conv.add_module('pool_pte1', nn.MaxPool2d(kernel_size=2, stride=2))self.target_encoder_conv.add_module('conv_pte2', nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5,padding=2))self.target_encoder_conv.add_module('ac_pte2', nn.ReLU(True))self.target_encoder_conv.add_module('pool_pte2', nn.MaxPool2d(kernel_size=2, stride=2))self.target_encoder_fc = nn.Sequential()self.target_encoder_fc.add_module('fc_pte3', nn.Linear(in_features=7 * 7 * 64, out_features=code_size))self.target_encoder_fc.add_module('ac_pte3', nn.ReLU(True))################################# shared encoder (dann_mnist)################################self.shared_encoder_conv = nn.Sequential()self.shared_encoder_conv.add_module('conv_se1', nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5,padding=2))self.shared_encoder_conv.add_module('ac_se1', nn.ReLU(True))self.shared_encoder_conv.add_module('pool_se1', nn.MaxPool2d(kernel_size=2, stride=2))self.shared_encoder_conv.add_module('conv_se2', nn.Conv2d(in_channels=32, out_channels=48, kernel_size=5,padding=2))self.shared_encoder_conv.add_module('ac_se2', nn.ReLU(True))self.shared_encoder_conv.add_module('pool_se2', nn.MaxPool2d(kernel_size=2, stride=2))self.shared_encoder_fc = nn.Sequential()self.shared_encoder_fc.add_module('fc_se3', nn.Linear(in_features=7 * 7 * 48, out_features=code_size))self.shared_encoder_fc.add_module('ac_se3', nn.ReLU(True))# classify 10 numbersself.shared_encoder_pred_class = nn.Sequential()self.shared_encoder_pred_class.add_module('fc_se4', nn.Linear(in_features=code_size, out_features=100))self.shared_encoder_pred_class.add_module('relu_se4', nn.ReLU(True))self.shared_encoder_pred_class.add_module('fc_se5', nn.Linear(in_features=100, out_features=n_class))self.shared_encoder_pred_domain = nn.Sequential()self.shared_encoder_pred_domain.add_module('fc_se6', nn.Linear(in_features=100, out_features=100))self.shared_encoder_pred_domain.add_module('relu_se6', nn.ReLU(True))# classify two domainself.shared_encoder_pred_domain.add_module('fc_se7', nn.Linear(in_features=100, out_features=2))####################################### shared decoder (small decoder)######################################self.shared_decoder_fc = nn.Sequential()self.shared_decoder_fc.add_module('fc_sd1', nn.Linear(in_features=code_size, out_features=588))self.shared_decoder_fc.add_module('relu_sd1', nn.ReLU(True))self.shared_decoder_conv = nn.Sequential()self.shared_decoder_conv.add_module('conv_sd2', nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5,padding=2))self.shared_decoder_conv.add_module('relu_sd2', nn.ReLU())self.shared_decoder_conv.add_module('conv_sd3', nn.Conv2d(in_channels=16, out_channels=16, kernel_size=5,padding=2))self.shared_decoder_conv.add_module('relu_sd3', nn.ReLU())self.shared_decoder_conv.add_module('us_sd4', nn.Upsample(scale_factor=2))self.shared_decoder_conv.add_module('conv_sd5', nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3,padding=1))self.shared_decoder_conv.add_module('relu_sd5', nn.ReLU(True))self.shared_decoder_conv.add_module('conv_sd6', nn.Conv2d(in_channels=16, out_channels=3, kernel_size=3,padding=1))def forward(self, input_data, mode, rec_scheme, p=0.0):result = []if mode == 'source':# source private encoderprivate_feat = self.source_encoder_conv(input_data)private_feat = private_feat.view(-1, 64 * 7 * 7)private_code = self.source_encoder_fc(private_feat)elif mode == 'target':# target private encoderprivate_feat = self.target_encoder_conv(input_data)private_feat = private_feat.view(-1, 64 * 7 * 7)private_code = self.target_encoder_fc(private_feat)result.append(private_code)# shared encodershared_feat = self.shared_encoder_conv(input_data)shared_feat = shared_feat.view(-1, 48 * 7 * 7)shared_code = self.shared_encoder_fc(shared_feat)result.append(shared_code)reversed_shared_code = ReverseLayerF.apply(shared_code, p)domain_label = self.shared_encoder_pred_domain(reversed_shared_code)result.append(domain_label)if mode == 'source':class_label = self.shared_encoder_pred_class(shared_code)result.append(class_label)# shared decoderif rec_scheme == 'share':union_code = shared_codeelif rec_scheme == 'all':union_code = private_code + shared_codeelif rec_scheme == 'private':union_code = private_coderec_vec = self.shared_decoder_fc(union_code)rec_vec = rec_vec.view(-1, 3, 14, 14)rec_code = self.shared_decoder_conv(rec_vec)result.append(rec_code)return result模型训练
import random
import os
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import numpy as np
from torch.autograd import Variable
from torchvision import datasets
from torchvision import transforms
from model_compat import DSN
from data_loader import GetLoader
from functions import SIMSE, DiffLoss, MSE
from test import test######################
# params #
######################source_image_root = os.path.join('.', 'dataset', 'mnist')
target_image_root = os.path.join('.', 'dataset', 'mnist_m')
model_root = 'model'
cuda = True
cudnn.benchmark = True
lr = 1e-2
batch_size = 32
image_size = 28
n_epoch = 100
step_decay_weight = 0.95
lr_decay_step = 20000
active_domain_loss_step = 10000
weight_decay = 1e-6
alpha_weight = 0.01
beta_weight = 0.075
gamma_weight = 0.25
momentum = 0.9manual_seed = random.randint(1, 10000)
random.seed(manual_seed)
torch.manual_seed(manual_seed)#######################
# load data #
#######################img_transform = transforms.Compose([transforms.Resize(image_size),transforms.ToTensor(),transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])dataset_source = datasets.MNIST(root=source_image_root,train=True,transform=img_transform
)dataloader_source = torch.utils.data.DataLoader(dataset=dataset_source,batch_size=batch_size,shuffle=True,num_workers=8
)train_list = os.path.join(target_image_root, 'mnist_m_train_labels.txt')dataset_target = GetLoader(data_root=os.path.join(target_image_root, 'mnist_m_train'),data_list=train_list,transform=img_transform
)dataloader_target = torch.utils.data.DataLoader(dataset=dataset_target,batch_size=batch_size,shuffle=True,num_workers=8
)#####################
# load model #
#####################my_net = DSN()#####################
# setup optimizer #
#####################def exp_lr_scheduler(optimizer, step, init_lr=lr, lr_decay_step=lr_decay_step, step_decay_weight=step_decay_weight):# Decay learning rate by a factor of step_decay_weight every lr_decay_stepcurrent_lr = init_lr * (step_decay_weight ** (step / lr_decay_step))if step % lr_decay_step == 0:print 'learning rate is set to %f' % current_lrfor param_group in optimizer.param_groups:param_group['lr'] = current_lrreturn optimizeroptimizer = optim.SGD(my_net.parameters(), lr=lr, momentum=momentum, weight_decay=weight_decay)loss_classification = torch.nn.CrossEntropyLoss()
loss_recon1 = MSE()
loss_recon2 = SIMSE()
loss_diff = DiffLoss()
loss_similarity = torch.nn.CrossEntropyLoss()if cuda:my_net = my_net.cuda()loss_classification = loss_classification.cuda()loss_recon1 = loss_recon1.cuda()loss_recon2 = loss_recon2.cuda()loss_diff = loss_diff.cuda()loss_similarity = loss_similarity.cuda()for p in my_net.parameters():p.requires_grad = True#############################
# training network #
#############################MNIST数据重建/共有部分特征/私有数据特征可视化

MNIST_m数据重建/共有部分特征/私有数据特征可视化
代码获取
相关问题和项目开发,欢迎私信交流和沟通。
相关文章:
【域适应】基于域分离网络的MNIST数据10分类典型方法实现
关于 大规模数据收集和注释的成本通常使得将机器学习算法应用于新任务或数据集变得异常昂贵。规避这一成本的一种方法是在合成数据上训练模型,其中自动提供注释。尽管它们很有吸引力,但此类模型通常无法从合成图像推广到真实图像,因此需要域…...

从零实现诗词GPT大模型:pytorch框架介绍
专栏规划: https://qibin.blog.csdn.net/article/details/137728228 因为咱们本系列文章主要基于深度学习框架pytorch进行,所以在正式开始之前,现对pytorch框架进行一个简单的介绍,主要面对深度学习或者pytorch还不熟悉的朋友。 一、安装pytorch 这一步很简单,主要通过p…...

[目标检测] OCR: 文字检测、文字识别、text spotter
概述 OCR技术存在两个步骤:文字检测和文字识别,而end-to-end完成这两个步骤的方法就是text spotter。 文字检测数据集摘要 daaset语言体量特色MTWI中英文20k源于网络图像,主要由合成图像,产品描述,网络广告(淘宝)MS…...

Windows环境下删除MySQL
文章目录 一、关闭MySQL服务1、winR打开运行,输入services.msc回车2、服务里找到MySQL并停止 二、卸载MySQL软件1、打开控制模板--卸载程序--卸载MySQL相关的所有组件 三、删除MySQL在物理硬盘上的所有文件1、删除MySQL的安装目录(默认在C盘下的Program …...

uniapp:uview-plus的一些记录
customStyle 并不是所有的组件都有customStyle属性来设置自定义属性,有的还是需要通过::v-deep来修改内置样式 form表单 labelStyle 需要的是一个对象 :labelStyle"{color: #333333,fontSize: 32rpx,fontWeight: 500}"dateTimePicker选择器设置默认值…...

OLTP 与 OLAP 系统说明对比和大数据经典架构 Lambda 和 Kappa 说明对比——解读大数据架构(五)
文章目录 前言OLTP 和 OLAPSMP 和 MPPlambda 架构Kappa 架构 前言 本文我们将研究不同类型的大数据架构设计,将讨论 OLTP 和 OLAP 的系统设计,以及有效处理数据的策略包括 SMP 和 MPP 等概念。然后我们将了解经典的 Lambda 架构和 Kappa 架构。 OLTP …...
步骤大全:网站建设3个基本流程详解
一.领取一个免费域名和SSL证书,和CDN 1.打开网站链接:https://www.rainyun.com/z22_ 2.在网站主页上,您会看到一个"登陆/注册"的选项。 3.点击"登陆/注册",然后选择"微信登录"选项。 4.使用您的…...
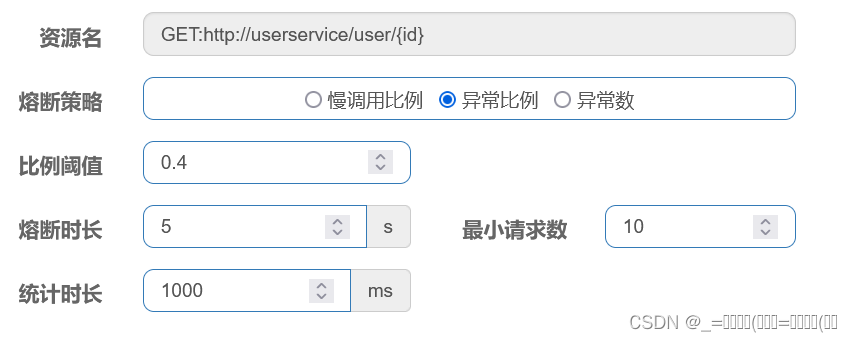
利用Sentinel解决雪崩问题(二)隔离和降级
前言: 虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。而要将这些故障控制在一定范围避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了,不管是线程隔离还是熔断降级,都是对客户端(调…...

基于springboot的房产销售系统源码数据库
基于springboot的房产销售系统源码数据库 摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于房产销售系统当然也不能排除在外,随着网络技术的不断成熟,带动了房产…...

【MATLAB】基于Wi-Fi指纹匹配的室内定位-仿真获取WiFi RSSI数据(附代码)
基于Wi-Fi指纹匹配的室内定位-仿真获取WiFi RSSI数据 WiFi指纹匹配是室内定位最为基础和常见的研究,但是WiFi指纹的采集可以称得上是labor-intensive和time-consuming。现在,给大家分享一下我们课题组之前在做WiFi指纹定位时的基于射线跟踪技术仿真WiFi…...

深圳晶彩智能ESP32-3248S035R使用LovyanGFX实现手写板
深圳晶彩智能ESP32-3248S035R介绍 深圳晶彩智能出品ESP32-3248S035R为3.5寸彩色屏采用分辨率480x320彩色液晶屏,驱动芯片是ST7796。板载乐鑫公司出品ESP-WROOM-32,Flash 4M。型号尾部“R”标识电阻膜的感压式触摸屏,驱动芯片是XPT2046。 Lo…...
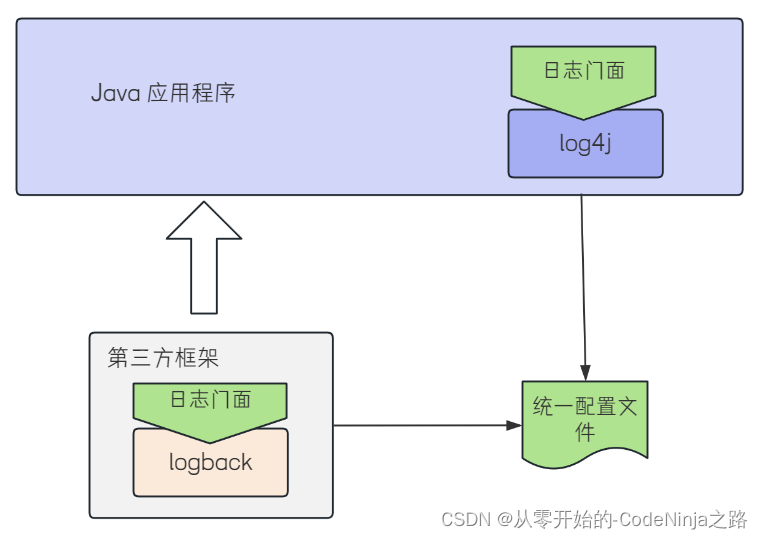
【Spring Boot】深入解密Spring Boot日志:最佳实践与策略解析
💓 博客主页:从零开始的-CodeNinja之路 ⏩ 收录文章:【Spring Boot】深入解密Spring Boot日志:最佳实践与策略解析 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 Spring Boot 日志一. 日志的概念?…...
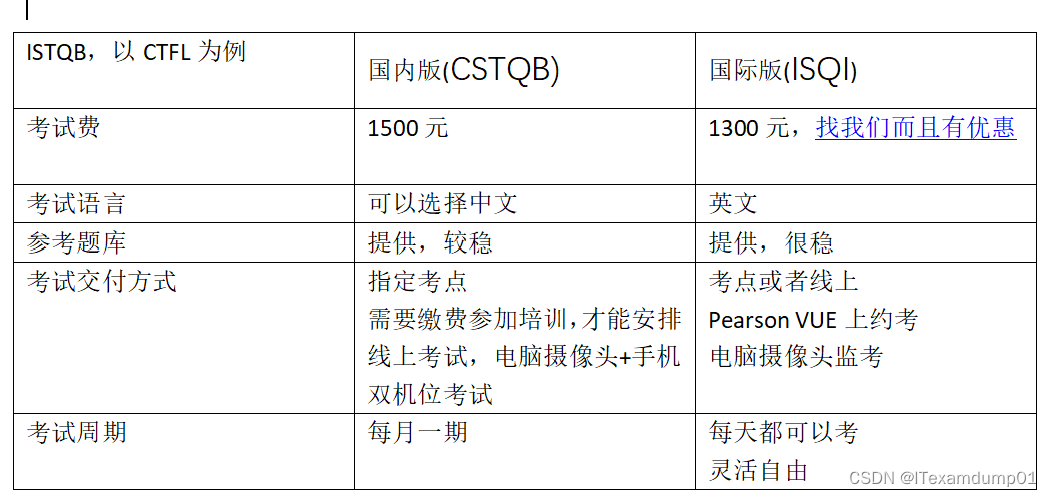
ISTQB选择国内版,还是国际版呢
1, ISTQB简介 ISTQB(International Software Testing Qualifications Board)是一个国际软件测试资格认证机构,旨在提供一个统一的软件测试认证标准。ISTQB成立于2002年,是非盈利性的组织,由世界各地的国家或地区软件测…...

头歌-机器学习 第11次实验 softmax回归
第1关:softmax回归原理 任务描述 本关任务:使用Python实现softmax函数。 相关知识 为了完成本关任务,你需要掌握:1.softmax回归原理,2.softmax函数。 softmax回归原理 与逻辑回归一样,softmax回归同样…...
Qt for MCUs 2.7正式发布
本文翻译自:Qt for MCUs 2.7 released 原文作者:Qt Group高级产品经理Yoann Lopes 翻译:Macsen Wang Qt for MCUs的新版本已发布,为Qt Quick Ultralite引擎带来了新功能,增加了更多MCU平台的支持,并且我们…...

共享IP和独享IP如何选择,两者有何区别?
有跨境用户在选择共享IP和独享IP时会有疑问,不知道该如何进行选择,共享IP和独享IP各有其特点和应用场景,选择哪种方式主要取决于具体需求和预算。以下是对两者的详细比较: 首先两者的主要区别在于使用方式和安全性:共…...

文心一言VSchatGPT4
文心一言和GPT-4各有优势,具体表现在不同的测试场景下。 在某些测试场景中心一言的表现优于GPT-4,例如在故事的完整度和情节吸引力方面,文心一言表现得更加符合指令,情节更吸引人。这可能得益于其模型在训练时对中文语境的深入理…...
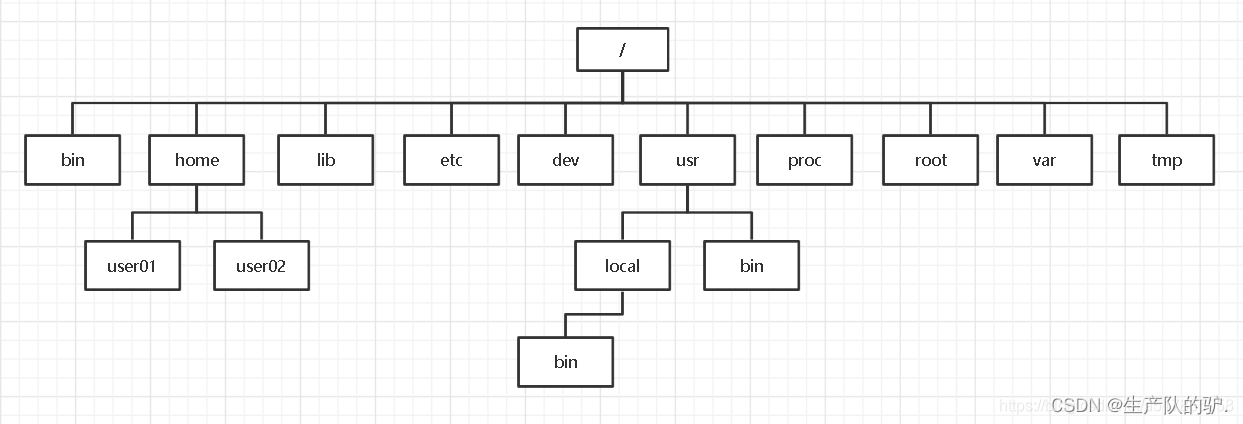
Linux 目录结构与基础查看命令
介绍 目录结构如下 /bin:存放着用户最经常使用的二进制可执行命令,如cp、ls、cat等。这些命令是系统管理员和普通用户进行日常操作所必需的。 /boot:存放启动系统使用的一些核心文件,如引导加载器(bootstrap loader…...
【matlab】如何解决打开缓慢问题(如何让matlab在十几秒内打开)
【matlab】如何解决打开缓慢问题(如何让matlab在十几秒内打开) 找到我们解压缩时Crack中的license_standalone.lic文件,将其拷贝 在安装matlab的路径下新建一个文件,粘贴上面的license_standalone.lic文件 在桌面鼠标移动到matl…...

【stata】求滚动波动情况
0.计算对象 计算 t t t、 t 1 t1 t1、 t 2 t2 t2 这三起滚动波动情况 V o l i , t l n ( ∑ n t n t 2 ( g n − g ˉ ) 2 3 ) Vol_{i,t} ln(\sqrt{\frac{\sum_{nt}^{nt2}(g_{n}-\bar{g})^2}{3}}) Voli,tln(3∑ntnt2(gn−gˉ)2 ) e . g e.g e.g: 假设 200…...

如何一站式解决漫画格式转换难题:CBconvert完整指南
如何一站式解决漫画格式转换难题:CBconvert完整指南 【免费下载链接】cbconvert CBconvert is a Comic Book converter 项目地址: https://gitcode.com/gh_mirrors/cb/cbconvert 还在为不同设备上的漫画格式兼容性问题而烦恼吗?CBconvert作为一款…...

Fish 4.6发布,命令行工具迎来新升级
近日,基于 Rust 语言开发的现代化交互式 Shell Fish 4.6 正式发布。它以智能提示和友好体验著称,此次更新带来细节优化,支持 systemd 环境变量,提升与 Linux 系统集成度。深度集成 systemd2024 年起,systemd 引入三个用…...
)
Docker下Kong+Konga全栈部署避坑指南(附PostgreSQL 9.6配置)
Docker环境下Kong与Konga全栈部署实战指南 引言 在现代微服务架构中,API网关扮演着流量调度与安全管控的关键角色。Kong作为开源API网关的标杆产品,凭借其插件化架构和强大性能,已成为企业级API管理的首选方案。而Konga作为Kong的图形化管理…...

解放你的创造力:用TEdit打造泰拉瑞亚专属世界地图
解放你的创造力:用TEdit打造泰拉瑞亚专属世界地图 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you change…...
和段(Segment)在 SAP 中关系非常紧密,但它们的设计目的和应用场景有本质区别)
利润中心(Profit Center)和段(Segment)在 SAP 中关系非常紧密,但它们的设计目的和应用场景有本质区别
利润中心(Profit Center)和段(Segment)在 SAP 中关系非常紧密,但它们的设计目的和应用场景有本质区别。简单来说,段(Segment)是利润中心的一个上级归类。它们之间通常是“一对多”的…...

FanControl完全指南:5分钟掌握Windows风扇智能控制
FanControl完全指南:5分钟掌握Windows风扇智能控制 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...

2024通信工程师初级备考指南:综合能力与专业实务核心考点解析
1. 2024通信工程师初级考试概况 2024年通信工程师初级资格考试定于9月28日举行,采用机考形式,考试时间为上午8:30至12:30,总时长4小时。这个考试分为两个科目:《通信专业综合能力》和《通信专业实务》,两科连续考试&am…...

释放创意:Mi-Create让智能表盘设计触手可及
释放创意:Mi-Create让智能表盘设计触手可及 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 问题发现:智能表盘设计的三重困境 在智能穿…...

Pyrene-PEG-Sil,芘丁酸酯聚乙二醇三乙氧基硅烷,荧光特性对微环境变化高度敏感
一.名称英文名称:Pyrene-PEG-Silane,Pyrene-PEG-Sil,Py-PEG-Silane,Py-PEG-Sil中文名称:芘丁酸酯聚乙二醇三乙氧基硅烷,芘丁酸酯-PEG-三乙氧基硅烷分子量:1k,2k,3.4k&…...

DanKoe 视频笔记:人生经验课:给18岁自己的信
在本节课中,我们将学习一位28岁人士回顾过去,总结出的核心人生经验。这些经验旨在帮助年轻人,特别是那些感到迷茫、渴望超越平凡生活的人,建立自主性、明确目标并采取有效行动。我们将把这些经验整理成一套清晰的教程,…...