基于机器学习的人脸发型推荐算法研究与应用实现
1.摘要
本文主要研究内容是开发一种发型推荐系统,旨在识别用户的面部形状,并根据此形状推荐最适合的发型。首先,收集具有各种面部形状的用户照片,并标记它们的脸型,如长形、圆形、椭圆形、心形或方形。接着构建一个面部分类器,以确定用户的脸型,如长形、圆形、椭圆形、心形或方形。然后,使用机器学习或深度学习技术构建一个面部分类器模型。该模型接受用户照片作为输入,并输出对应的面部形状分类结果。基于分类结果,根据面部分类器的输出结果,为每种面部形状设计一组适合的发型。最终实现的系统将推荐适合用户面部形状的发型。该系统将利用用户对不同发型的偏好和不喜欢程度进行持续更新,以提供个性化的推荐。
2. 算法研究
2.1 数据分析及数据集收集过程:
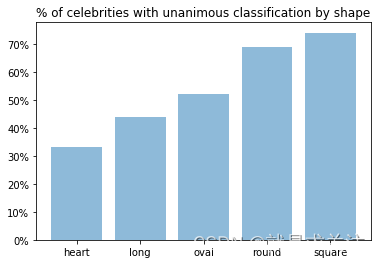
通过查阅22个网站和234位名人的信息来收集具有正确面部形状标签的图像。其中,有33位名人的面部形状在3个或更多网站中得到了一致的分类(65位在2个或更多网站中一致)。还有49位名人虽然在某些网站上的分类存在冲突,但有强烈的共识可以用于分类。最终,利用74位名人的数据进行了分析。
面部形状特征描述:
- 心形脸形(heart-shaped face):具有宽阔的颧骨,逐渐变窄至下巴。
- 长形脸形(long face):长而非常狭窄。
- 椭圆形脸形(oval face):类似于长形脸,但比长形脸更丰满。
- 圆形脸形(round face):短而宽的形状,与其他脸形明显不同。
- 方形脸形(square-shaped face):具有强烈的下颌线。
最终,数据集包含了约 74 名名人的约 1500 张图像,存储到DATA 文件夹中。
基于上述收集的data数据,创建了一个包含各种特征的数据框,这些特征包括面部关键点的坐标、计算出的长度和比率,以及图像名称和分类形状。该数据框的列包括了大量的特征,如面部关键点坐标、长度、比率以及图像名称和分类形状等。接着,通过调用主要函数和第二个用于推荐目的的函数,对上述目录中的所有照片运行主要函数,从而生成了一个整洁的数据集。
data = pd.DataFrame()
data.reset_index
shape_df = pd.DataFrame(columns = ['filenum','filename','classified_shape'])
shape_array = []
def store_features_and_classification():filenum = -1sub_dir = [q for q in pathlib.Path(image_dir).iterdir() if q.is_dir()]start_j = 0end_j = len(sub_dir)for j in range(start_j, end_j):images_dir = [p for p in pathlib.Path(sub_dir[j]).iterdir() if p.is_file()]for p in pathlib.Path(sub_dir[j]).iterdir():print(p)shape_array= []if 1 == 1:face_file_name = os.path.basename(p)classified_face_shape = os.path.basename(os.path.dirname(p)) filenum += 1make_face_df(p,filenum)shape_array.append(filenum)shape_array.append(face_file_name) shape_array.append(classified_face_shape)shape_df.loc[filenum] = np.array(shape_array)store_features_and_classification()
data = pd.concat([df, shape_df], axis=1)
# Add all the faces features with shape to a DATA CSV file for model purpose.
data.to_csv('all_features.csv')这段代码的主要目的是创建一个数据集,其中包含了面部特征和分类形状的信息,并将其保存到一个CSV文件中以供模型使用。
2.2 模型训练过程
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, normalize
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt# 导入数据
data = pd.read_csv('all_features.csv', index_col=None).drop('Unnamed: 0', axis=1).dropna()# 准备数据
X = normalize(data.drop(['filenum', 'filename', 'classified_shape'], axis=1))
Y = data['classified_shape']# 标准化特征
scaler = StandardScaler()
X = scaler.fit_transform(X)# PCA降维
pca = PCA(n_components=18, svd_solver='randomized', whiten=True).fit(X)
X = pca.transform(X)# 划分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, random_state=1200)# MLP模型
mlp_best = MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', hidden_layer_sizes=(60, 100, 30, 100),learning_rate='constant', learning_rate_init=0.01, max_iter=100, random_state=525)
mlp_best.fit(X_train, Y_train)# KNN模型
neigh = KNeighborsClassifier(n_neighbors=5)
neigh.fit(X_train, Y_train)# 随机森林模型
clf = RandomForestClassifier(n_estimators=100, max_depth=None, random_state=5)
clf.fit(X_train, Y_train)# 梯度提升模型
gb_best = GradientBoostingClassifier(n_estimators=300, max_depth=5, learning_rate=0.1)
gb_best.fit(X_train, Y_train)# LDA模型
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, Y_train)# 可视化模型比较结果
def model_graph():models = [mlp_best, neigh, clf, gb_best, lda]model_names = ['MLP', 'KNN', 'Random Forest', 'Gradient Boosting', 'LDA']accuracies = [model.score(X_test, Y_test) for model in models]plt.figure(figsize=(10, 6))plt.bar(model_names, accuracies, color=['blue', 'green', 'pink', 'orange', 'purple'])plt.xlabel('Model')plt.ylabel('Accuracy')plt.title('Comparison of Models')plt.show()model_graph()
该代码的主要目的为比较不同机器学习模型在识别面部形状方面的性能,以帮助选择最佳的模型用于面部形状分类任务。功能如下:
-
数据预处理:首先,导入必要的库,并加载以前处理过的数据。然后,将数据进行清理,去除任何包含NaN值的行,并准备好用于模型训练的特征矩阵 X 和目标向量 Y。
-
标准化:使用
StandardScaler对特征矩阵 X 进行标准化,即移除平均值并缩放到单位方差,以确保每个特征对模型的贡献大致相等。 -
PCA降维:对标准化后的特征矩阵 X 进行主成分分析(PCA)降维,以减少特征的数量。作者选择了包含 18 个主成分的 PCA 模型,通过
fit方法拟合 PCA 模型,并使用transform方法将数据转换为新的主成分空间。 -
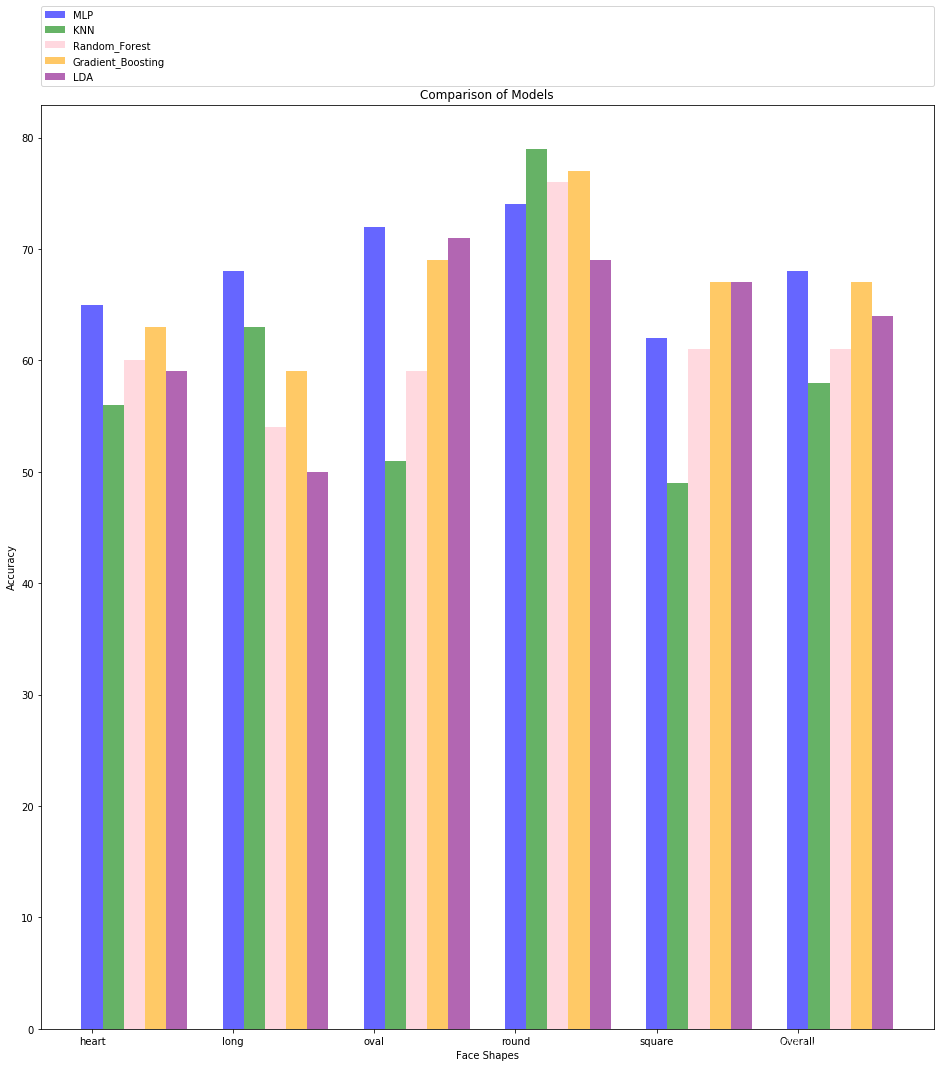
模型选择与训练:作者尝试了多种监督学习模型,包括多层感知机(MLP)、K最近邻分类器(KNN)、随机森林分类器(Random Forest)、梯度提升分类器(Gradient Boosting)和线性判别分析(LDA)。对于每个模型,作者通过调整超参数和使用交叉验证选择最佳模型,并使用最佳模型在测试集上进行评估。
-
模型评估:评估了每个模型在测试集上的性能,并将结果可视化为条形图,展示了不同模型在识别不同面部形状上的准确率。最后,生成一个结果表格,汇总了每个模型对不同面部形状的识别准确率。实验结果如下:
3. 应用实现
基于flask技术实现一个用于面部特征识别和发型推荐的应用程序。
该系统包含:
-
上传照片功能:用户可以在页面中上传自己的照片。上传后,会显示用户的照片,并提供预测和推荐功能。
-
预测功能:用户可以点击“预测”按钮,对上传的照片进行预测,以推荐适合用户脸型和其他特征的发型。
点击开始预测

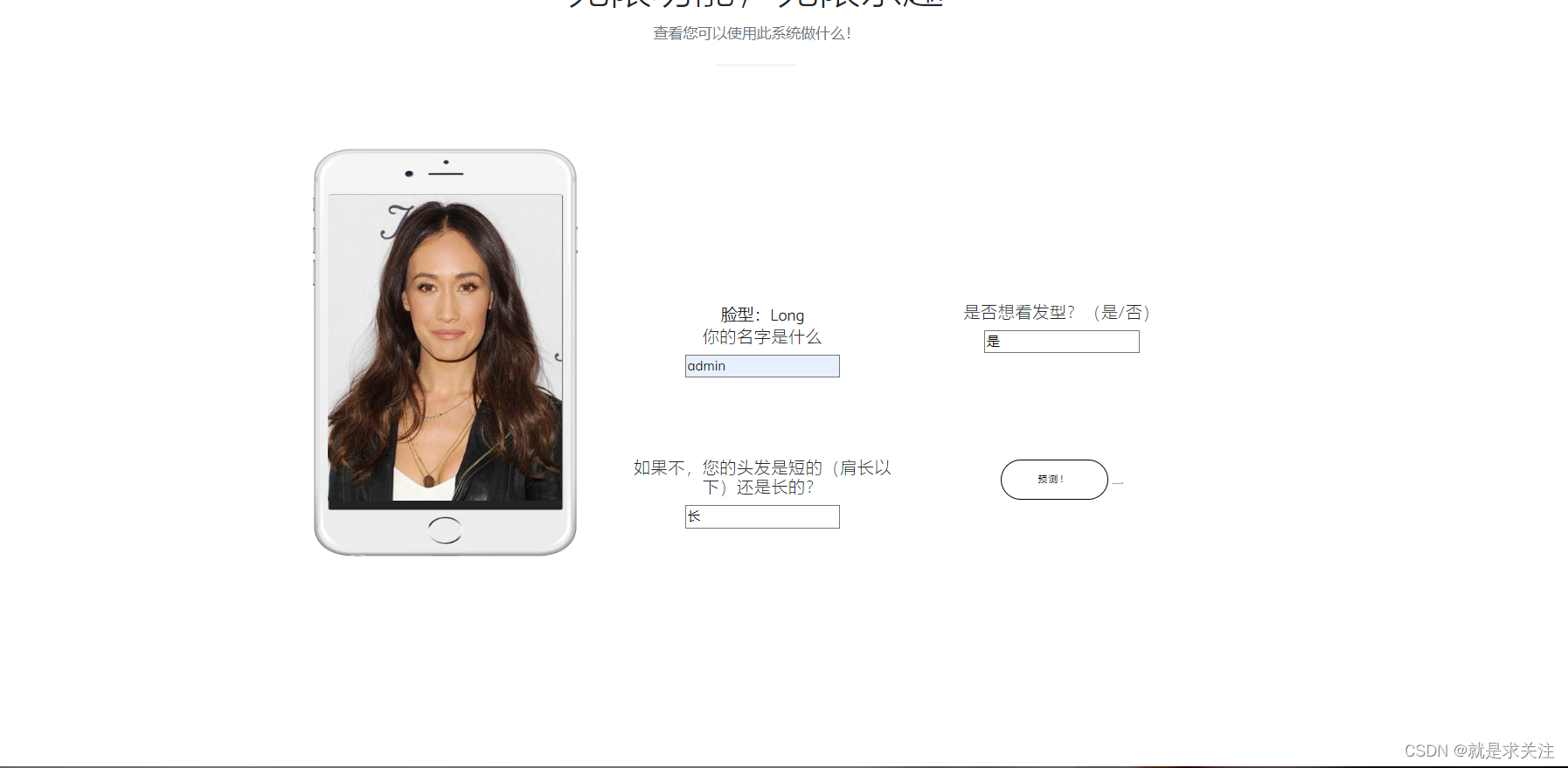
输出结果为:

4. 结语
该研究主要关注开发一种发型推荐系统,其目标是根据用户的面部形状识别最适合的发型。主要研究内容包括:
1.数据收集和分析:收集具有各种面部形状的用户照片,并标记其脸型,如长形、圆形、椭圆形、心形或方形。构建面部分类器以确定用户的脸型,使用机器学习技术构建模型。数据集包含约74位名人的约1500张图像,并存储到CSV文件中以供模型使用。
2.模型训练过程:导入数据,准备数据,并对特征进行标准化和降维。使用多种机器学习模型进行训练,包括MLP、KNN、随机森林、梯度提升和LDA模型。比较不同模型在面部形状分类任务上的性能,并选择最佳模型。
3.应用实现:基于Flask技术实现一个用于面部特征识别和发型推荐的应用程序。应用程序包括一个点击开始预测的功能,输出用户的面部形状分类结果和推荐的发型。
总的来说,该研究旨在帮助用户了解适合其脸型的最佳发型,并提供个性化的发型推荐服务。
上述代码的运行环境为基于python3.7.0配置pandas==1.1.5 Flask==1.0.2 sklearn==0.0 scikit-learn==0.23.1 Werkzeug==0.16.0 opencv-python==4.1.0.25 numpy==1.19.5 matplotlib==3.3.4 Pillow==8.4.0 requests==2.18.4 bs4==0.0.1 beautifulsoup4==4.7.1 seaborn==0.11.0 scipy==1.5.4。
完整代码:
https://download.csdn.net/download/weixin_40651515/89136480
相关文章:
基于机器学习的人脸发型推荐算法研究与应用实现
1.摘要 本文主要研究内容是开发一种发型推荐系统,旨在识别用户的面部形状,并根据此形状推荐最适合的发型。首先,收集具有各种面部形状的用户照片,并标记它们的脸型,如长形、圆形、椭圆形、心形或方形。接着构建一个面部…...

【服务器部署篇】Linux下Nginx的安装和配置
作者介绍:本人笔名姑苏老陈,从事JAVA开发工作十多年了,带过刚毕业的实习生,也带过技术团队。最近有个朋友的表弟,马上要大学毕业了,想从事JAVA开发工作,但不知道从何处入手。于是,产…...

React搭建一个文章后台管理系统
1、项目准备 本篇文章讲解的是一个简单的文章后台管理系统,系统的功能很简单,如下:登录、退出;首页;内容(文章)管理:文章列表、发布文章、修改文章。 1)React官方脚手架:create-rea…...

Elasticsearch 支持的插件 —— 筑梦之路
Analysis 插件: 1、IK Analyzer:适用于中文分词的插件,提供了针对中文文本的分析器。 2、Smart Chinese Analysis:另一个中文分词插件,支持中文智能分词。 集群管理插件: 1、Kibana:Elasticsear…...

HTML:链接
目录 一、超链接 二、 外联元素 一、<a>超链接 <a> 标签用于定义超链接,超链接可以让用户从一个网页跳转到另一个网页。 常用属性: href指定链接的目标地址。download表示链接是一个下载链接,指定下载的文件名。target 指定在…...

vscode远程连接centos
文章目录 vacode连接linux1. 安装插件2. 查看配置3. 打开ssh4. 远程连接 vacode连接linux 1. 安装插件 在扩展栏搜索remote ,找到Remote Development插件,进行安装: 2. 查看配置 打开自己的linux终端,输入ifconfig,…...
)
scala---面向对象(类,对象,继承,抽象类,特质)
一、类(class)和 对象(object) 1、类 类就是对客观的一类事物的抽象。用一个class关键字来描述和Java一样,在这个类中可以拥有这一类事物的属性,行为等等。 2、为什么要有对象 在java中的一个class既可…...

【机器学习300问】68、随机初始化神经网络权重的好处?
一、固定的初始化神经网络权重可能带来的问题 在训练神经网络的时候,初始化权重如果全部设置为0或某个过大值/过小值。会导致一些问题: 对称权重问题:全为0的初始化权重会导致神经网络在前向传播时接收到的信号输入相同。每个神经网络节点中…...
数据结构与算法——20.B-树
这篇文章我们来讲解一下数据结构中非常重要的B-树。 目录 1.B树的相关介绍 1.1、B树的介绍 1.2、B树的特点 2.B树的节点类 3.小结 1.B树的相关介绍 1.1、B树的介绍 在介绍B树之前,我们回顾一下我们学的树。 首先是二叉树,这个不用多说ÿ…...
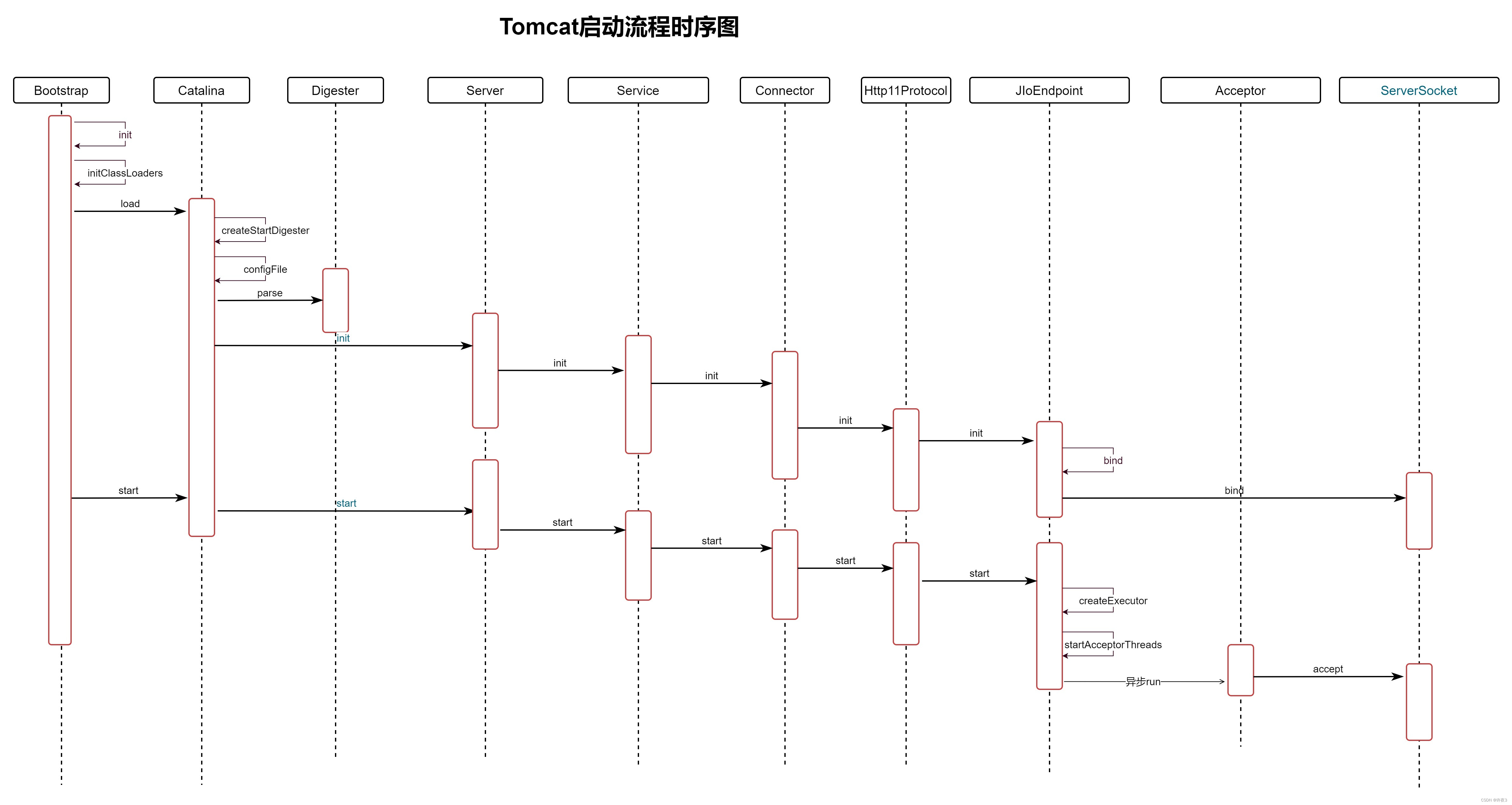
Tomcat源码解析——Tomcat的启动流程
一、启动脚本 当我们在服务启动Tomcat时,都是通过执行startup.sh脚本启动。 在Tomcat的启动脚本startup.sh中,最终会去执行catalina.sh脚本,传递的参数是start。 在catalina.sh脚本中,前面是环境判断和初始化参数,最终…...
蓝桥杯真题演练:2023B组c/c++
日期统计 小蓝现在有一个长度为 100 的数组,数组中的每个元素的值都在 0 到 9 的范围之内。 数组中的元素从左至右如下所示: 5 6 8 6 9 1 6 1 2 4 9 1 9 8 2 3 6 4 7 7 5 9 5 0 3 8 7 5 8 1 5 8 6 1 8 3 0 3 7 9 2 7 0 5 8 8 5 7 0 9 9 1 9 4 4 6 8 6 3 …...
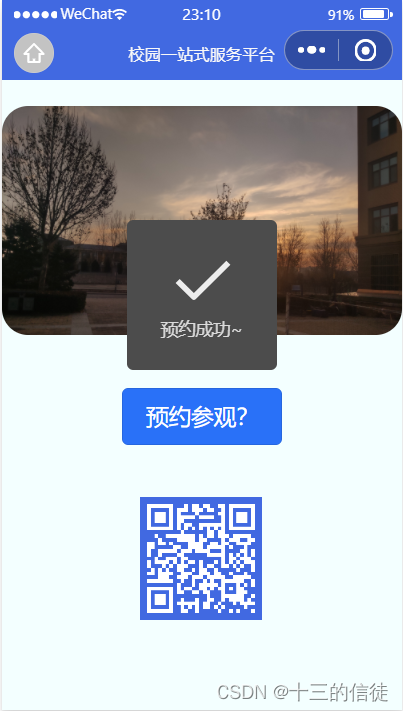
微信小程序实现预约生成二维码
业务需求:点击预约按钮即可生成二维码凭码入校参观~ 一.创建页面 如下是博主自己写的wxml: <swiper indicator-dots indicator-color"white" indicator-active-color"blue" autoplay interval"2000" circular > &…...

专业140+总分410+北京理工大学826信号处理导论考研经验北理工电子信息通信工程,真题,参考书,大纲。
今年考研专业课826信号处理导论(信号系统和数字信号处理)140,总分410,顺利上岸!回看去年将近一年的复习,还是记忆犹新,有不少经历想和大家分享,有得有失,希望可以对大家复…...

做一个后台项目的架构
后台架构的11个维度 架构1:团队协助基础工具链的选型和培训架构2:搭建微服务开发基础设施架构3:选择合适的RPC框架架构4:选择和搭建高可用的注册中心架构5:选择和搭建高可用的配置中心架构6:选择和搭建高性…...
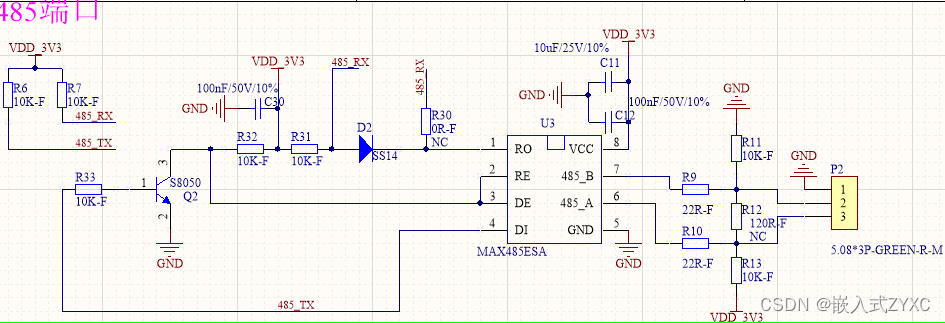
嵌入式单片机 TTL电平、232电平、485电平的区别和联系
一、简介 TTL、232和485是常见的串口通信标准,它们在电平和通信方式上有所不同, ①一般情况下TTL电平应用于单片机外设,属于MCU/CPU等片外外设; ②232/485电平应用于产品整体对外的接口,一般是片外TTL串口转232/485…...
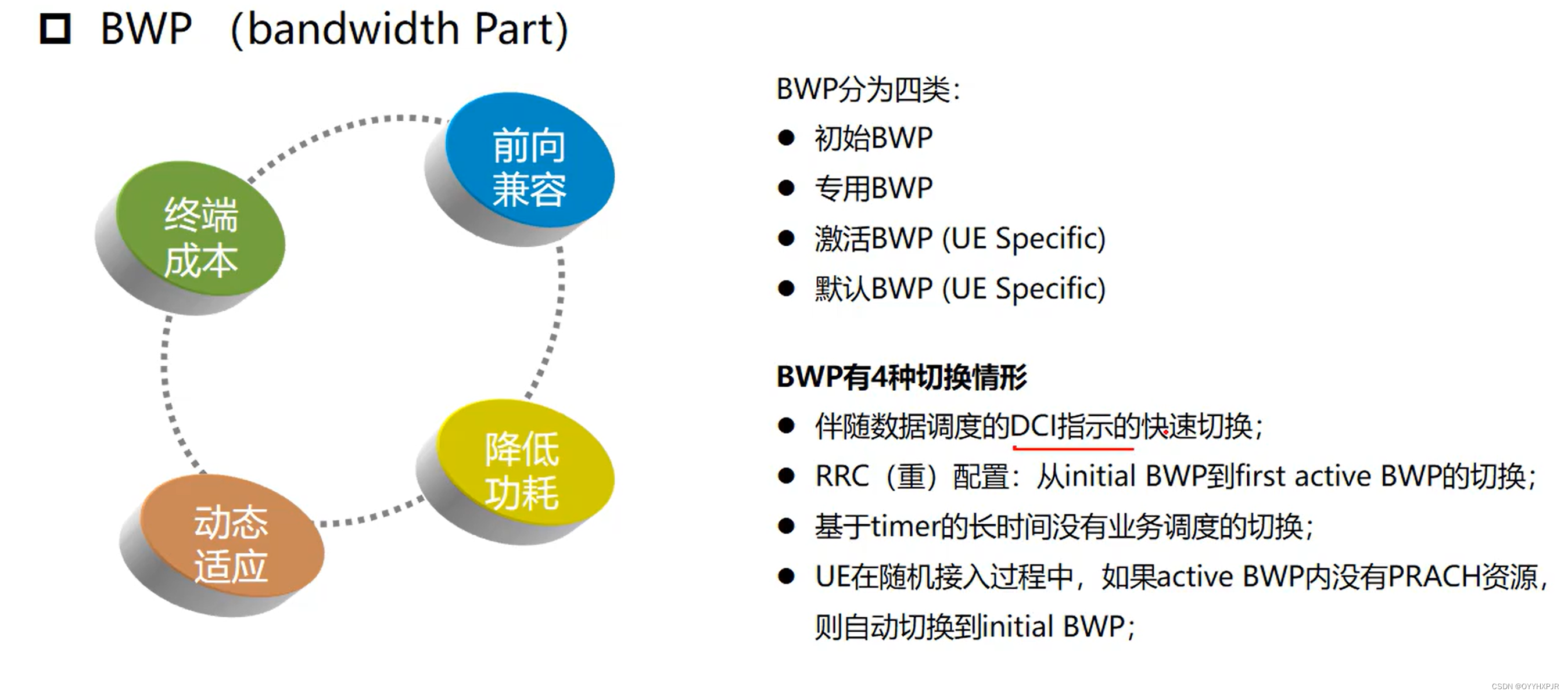
2024年大唐杯备考
努力更新中…… 第一章 网络架构和组网部署 1.1 5G的网络整体架构 5G网络中的中传、回传、前传(这里属于承载网的概念) CU和DU之间是中传 BBU和5GC之间是回传 BBU和AAU之间是前传(这个好记) 这里竟然还藏了MEC(…...
:Spring Boot与MySQL搭配,打造极简高效的数据管理系统)
Spring Boot(06):Spring Boot与MySQL搭配,打造极简高效的数据管理系统
1. 前言 Spring Boot 是一个基于Spring框架的快速开发框架,可以使开发者快速搭建一个可靠的Java Web应用程序。而MySQL是最广泛使用的关系型数据库系统之一,也是Spring Boot整合数据库的首选。本文将介绍Spring Boot如何整合MySQL数据库。 2. 摘要 本文…...

Vue3 + Vite 构建组件库发布到 npm
你有构建完组件库后,因为不知道如何发布到 npm 的烦恼吗?本教程手把手教你用 Vite 构建组件库发布到 npm 搭建项目 这里我们使用 Vite 初始化项目,执行命令: pnpm create vite my-vue-app --template vue这里以我的项目 vue3-xm…...

Vite多环境配置与打包:灵活高效的Vue开发工作流
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
从零实现诗词GPT大模型:数据集介绍和预处理
专栏规划: https://qibin.blog.csdn.net/article/details/137728228 本章将介绍该系列文章中使用的数据集,并且编写预处理代码,处理成咱们需要的格式。 一、数据集介绍 咱们使用的数据集名称是chinese-poetry,是一个在github上开源的中文诗…...

Lua RTOS在ESP32上的应用:从架构解析到物联网项目实战
1. 项目概述:当Lua遇上RTOS,为ESP32注入灵魂 如果你玩过ESP32,大概率用过Arduino框架或者乐鑫官方的ESP-IDF。前者简单易上手,但深度定制和实时性有限;后者功能强大专业,但C语言开发门槛不低,调…...

模拟仿真技术在现代集成电路设计中的挑战与解决方案
1. 模拟仿真技术面临的现代挑战在当今集成电路设计领域,模拟仿真技术正面临前所未有的挑战。随着工艺节点从130nm一路演进到15nm甚至更小尺寸,设计复杂度呈指数级增长。我曾参与过多个采用28nm工艺的混合信号芯片项目,深刻体会到传统SPICE仿真…...

《深入浅出通信原理》连载101-105
连载101:正弦信号的傅立叶变换连载102:直流信号的傅立叶变换连载103:复指数信号傅立叶变换的另外一种求法连载104:非周期信号的傅立叶变换连载105:傅立叶变换的对称性(一)...

【职业发展】程序员成长路径:从初级到架构师的进阶指南
【职业发展】程序员成长路径:从初级到架构师的进阶指南 引言 程序员的职业发展是一个持续学习和成长的过程。从初级程序员成长为技术架构师,需要经历多个阶段的积累和蜕变。本文将详细分析程序员成长的各个阶段,帮助你规划职业发展路径。 …...

从HackRF到USRP B210:我的SDR设备升级之路与真实体验对比
从HackRF到USRP B210:我的SDR设备升级之路与真实体验对比 作为一个长期沉迷于软件定义无线电(SDR)技术的爱好者,设备的选择往往决定了探索的边界。从最初的HackRF One到如今的USRP B210,这段升级旅程不仅是对硬件性能的…...

3大核心模块+5步实战指南:Betaflight飞控固件深度解析与配置方案
3大核心模块5步实战指南:Betaflight飞控固件深度解析与配置方案 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight Betaflight作为开源飞控固件的标杆,为多旋翼和固定…...

Perplexity Stack Overflow查询响应延迟超8秒?紧急修复指南:从token压缩到领域微调的4层加速方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity Stack Overflow查询响应延迟超8秒?紧急修复指南:从token压缩到领域微调的4层加速方案 当Perplexity在Stack Overflow数据源上出现平均响应延迟 > 8s 的告警时&am…...

光纤偏振测量:从琼斯矢量到庞加莱球,六种工具深度解析与工程实践
1. 从一道周五小测题说起:光纤测量中的偏振态表征上周五,我在整理旧资料时,翻到了EE Times在2015年发布的一篇“周五小测”文章,主题是光纤光学测量。其中第一道题就很有意思,它问的是:“以下哪种工具不能用…...

别再傻傻分不清了!MIPI DPHY和CPHY到底怎么选?从带宽、成本和PCB布线给你讲透
MIPI DPHY与CPHY工程选型实战指南:从理论到PCB布局的完整决策框架 在移动设备硬件设计中,MIPI接口的选择往往成为影响项目成败的关键决策点。当面对新一代图像传感器规格书上的DPHY/CPHY双模支持标识时,资深工程师的眉头总会不自觉地皱起——…...

别再为Modbus RTU超时头疼了!STM32CubeMX+FreeModbus从站移植,搞定串口与定时器配置的黄金法则
STM32CubeMXFreeModbus从站移植实战:破解RTU超时难题的工程化思维 当你在深夜调试Modbus RTU从站设备,串口调试助手反复弹出"Timeout"错误提示时,那种挫败感每个嵌入式工程师都深有体会。超时问题就像幽灵般难以捉摸——代码编译通…...