部署ELFK+zookeeper+kafka架构
目录
前言
一、环境部署
二、部署ELFK
1、ELFK ElasticSearch 集群部署
1.1 配置本地hosts文件
1.2 安装 elasticsearch-rpm 包并加载系统服务
1.3 修改 elasticsearch 主配置文件
1.4 创建数据存放路径并授权
1.5 启动elasticsearch是否成功开启
1.6 查看节点信息
2、ELFK Logstash 部署
2.1 安装 logstash
2.2 测试 logstash
3、ELFK Kiabana 部署
3.1 安装 Kiabana
3.2 设置 Kibana 的主配置文件并启动服务
4、ELFK filebeat 部署
4.1 安装 filebeat + httpd
4.2 设置 filebeat 的主配置文件
三、部署Zoopkeeper + Kafak 集群
1、部署 Zoopkeeper 集群
1.1 部署 Zoopkeeper 集群
1.2 设置主配置文件
1.3 创建数据目录和日志目录
1.4 创建myid文件
1.5 配置 Zookeeper 启动脚本并设置开机自启
1.6 分别启动 Zookeeper
2、部署 Kafak 集群
2.1 设置主配置文件
2.2 创建数据目录和日志目录
2.3 创建myid文件
2.4 配置 Zookeeper 启动脚本并设置开机自启
2.5 分别启动 Zookeeper
四、测试
1、定义 logstash 的配置文件
2、查看所有的索引
3、登录 Kibana 添加索引
前言
feilbeat + 缓存/消息队列+ Logstash + Elasticsearch + Kibana 模式
这是一种加健壮高效的架构,适合处理海量复杂的日志数据。
在这种模式下,filebeat和iogstach之间加入缓存或消息队列组件,如redis、kafka或RabbitMQ等。
这样可以降低对目志源主机的影响 ,提高目志传输的稳定性和可靠性,以及实现负载均衡和高可用
- Logstash:从Kafka集群中消费日志数据,进行必要的数据解析、过滤、转换等预处理操作,然后将结构化后的数据发送到Elasticsearch
- Elasticsearch:存储经过处理的日志数据,提供全文搜索、聚合分析等功能,便于后期进行日志分析和故障排查
- Kibana:作为前端展示工具,基于Elasticsearch的数据创建可视化图表和仪表盘,为用户提供友好的日志分析界面
- Filebeat/Fluentd:负责从各服务器节点上实时收集日志数据,Filebeat轻量级,适合大规模部署,Fluentd功能强大,支持丰富的插件和灵活的过滤规则
- ZooKeeper:在某些场景下,ZooKeeper可以用于管理Kafka集群的元数据,例如Broker注册、Topic的分区分配等,确保Kafka集群的稳定性和一致性。同时,对于Logstash或Kafka Connect这类组件,也可以通过ZooKeeper获取集群配置信息
- Kafka:作为一个分布式消息队列系统,承担起数据缓冲和中转的角色。日志数据先发送到Kafka集群,一方面可以缓解Logstash或Filebeat的压力,另一方面支持多消费者模型,允许数据被多个下游系统并行消费。此外,Kafka的高吞吐量和持久化特性使得系统在面临大量日志输入时仍能保持稳定
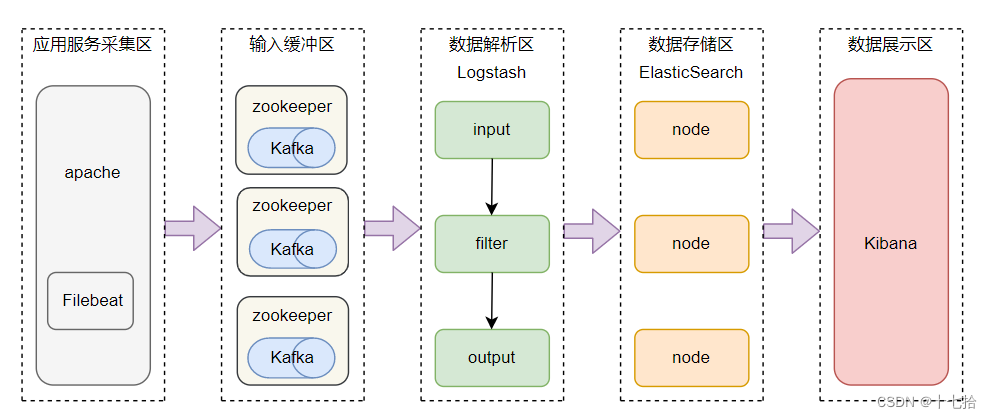
数据流向:应用程序日志 ---> Filebeat ---> Kafka ---> Logstash ---> Elasticsearch ---> Kibana
一、环境部署
(1)关闭所有设备的防火墙和核心防护
[root@localhost ~]#systemctl stop firewalld
[root@localhost ~]#setenforce 0(2)修改所有设备的主机名
[root@localhost ~]#hostnamectl set-hostname logstash
[root@localhost ~]#bash[root@localhost ~]#hostnamectl set-hostname es_node1
[root@localhost ~]#bash[root@localhost ~]#hostnamectl set-hostname es_node2
[root@localhost ~]#bash[root@localhost ~]#hostnamectl set-hostname logstash
[root@localhost ~]#bash[root@localhost ~]#hostnamectl set-hostname filebeat
[root@localhost ~]#bash[root@localhost ~]#hostnamectl set-hostname zk-kfk01
[root@localhost ~]#bash[root@localhost ~]#hostnamectl set-hostname zk-kfk02
[root@localhost ~]#bash[root@localhost ~]#hostnamectl set-hostname zk-kfk03
[root@localhost ~]#bash(3)所有设备都需部署java环境,安装oraclejdk
java -version #不建议使用openjdk,所以三台设备都需安装oraclejdk
# rpm安装oraclejdk#yum install或rpm -ivh安装oraclejdk
cd /opt #将rpm软件包传至/opt目录下
rpm -ivh jdk-8u291-linux-x64.rpm#将openjdk更换至oraclejdk
vim /etc/profile.d/jdk.sh
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64 #输出定义java的工作目录
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar #输出指定java所需的类文件
export PATH=$JAVA_HOME/bin:$PATH #输出重新定义环境变量,$PATH一定要放在$JAVA_HOME的后面,让系统先读取到工作目录中的版本信息source /etc/profile.d/jdk.sh #执行配置文件
java -version
----------------------------------------------------------------------------------------
# 二进制包安装oraclejdkcd /opt #将二进制包传至/opt目录下
tar zxvf jdk-8u291-linux-x64.tar.gz -C /usr/local
ln -s /usr/local/jdk1.8.0_291/ /usr/local/jdkvim /etc/profile.d/jdk.sh
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATHsource /etc/profile.d/jdk.sh
java -version
二、部署ELFK
1、ELFK ElasticSearch 集群部署
1.1 配置本地hosts文件
es_node节点1和es_node节点2都要配置本地的/etc/hosts文件
echo "172.16.12.12 es_node1" >> /etc/hosts
echo "172.16.12.13 es_node2" >> /etc/hosts
1.2 安装 elasticsearch-rpm 包并加载系统服务
#安装elasticsearch-rpm 包
cd /opt #上传elasticsearch-5.5.0.rpm到/opt目录下
rpm -ivh elasticsearch-5.5.0.rpm#加载系统服务
systemctl daemon-reload
systemctl enable elasticsearch.service 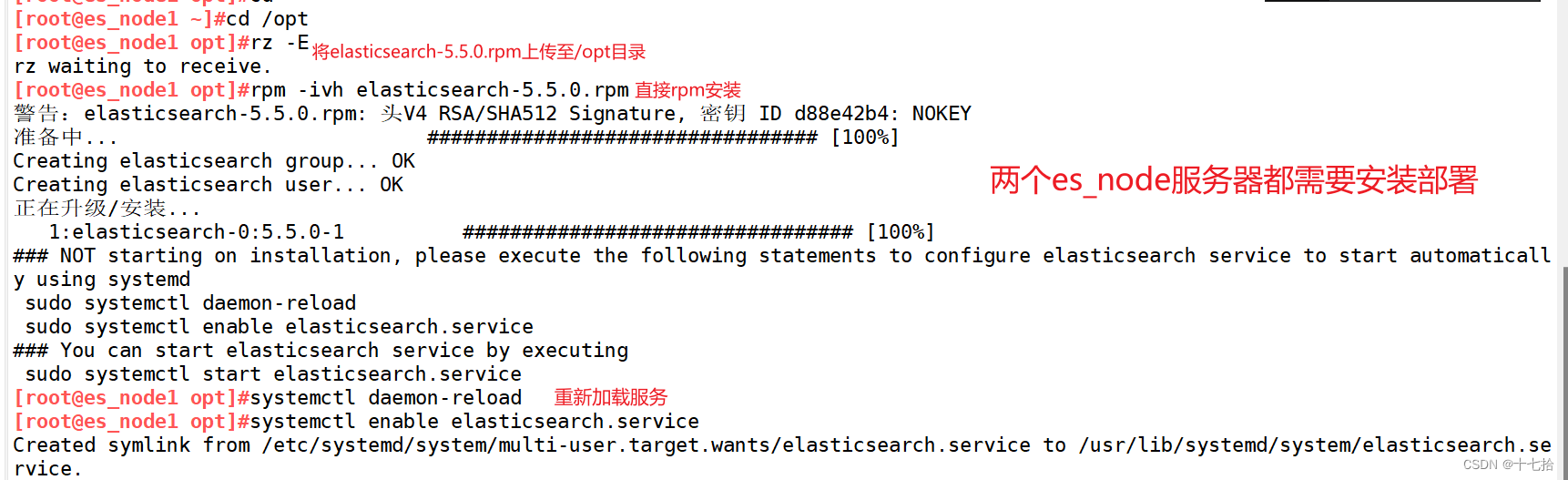
1.3 修改 elasticsearch 主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
discovery.zen.ping.unicast.hosts: ["es_node1", "es_node2"]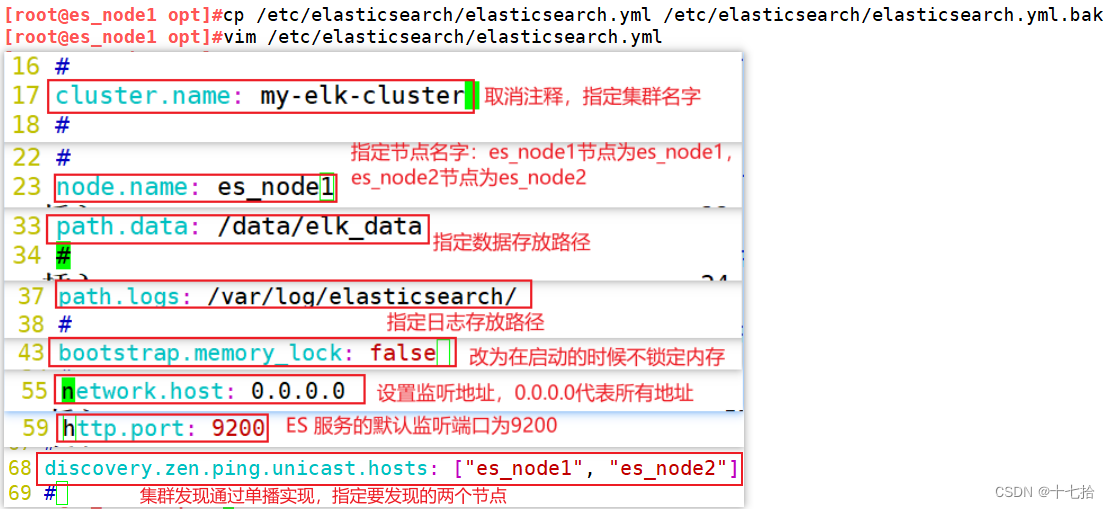
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
#过滤到能生效的语句,检查修改的是否正确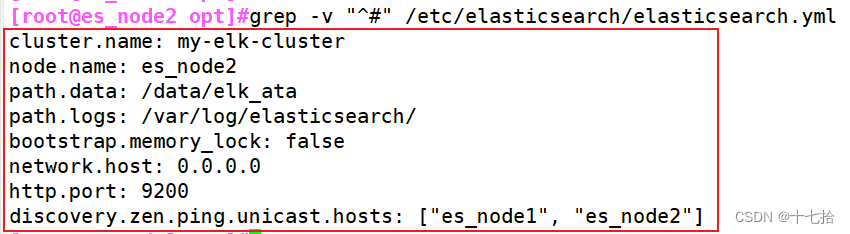
1.4 创建数据存放路径并授权
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
1.5 启动elasticsearch是否成功开启
systemctl start elasticsearch.service
ss -antp | grep 9200![]()

综上,两个es_node节点都部署安装完elasticsearch
1.6 查看节点信息
浏览器访问:http://172.16.12.12:9200 、 http://172.16.12.13:9200 来查看节点 es_node1、es_node2 的信息
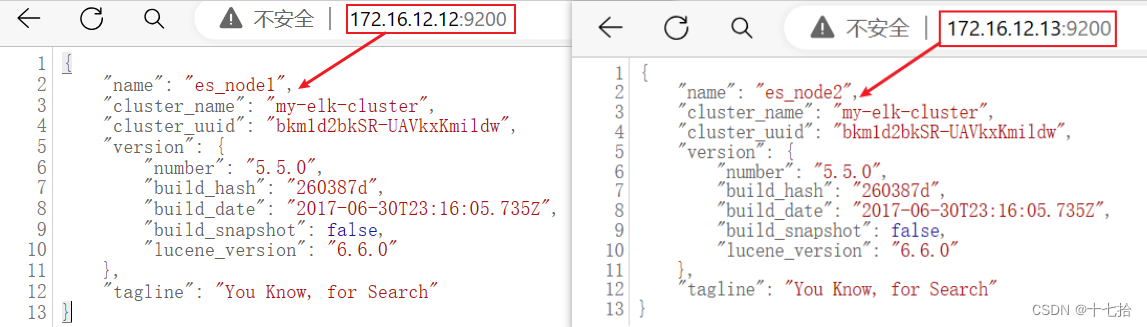
浏览器访问:http://172.16.12.12:9200/_cluster/health?pretty 、 http://172.16.12.12:9200/_cluster/health?pretty 来查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行

绿色:健康,数据和副本,全都没有问题
红色:数据都不完整
黄色:数据完整,但副本有问题
2、ELFK Logstash 部署
需要安装部署在logstash节点服务器上
2.1 安装 logstash
[root@logstash ~]#cd /opt #上传软件包 logstash-5.5.1.rpm 到/opt目录下
[root@logstash opt]#rpm -ivh logstash-5.5.1.rpm
[root@logstash opt]#systemctl enable --now logstash.service
[root@logstash opt]#ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
2.2 测试 logstash
Logstash 命令常用选项:
| 常用选项 | 说明 |
|---|---|
| -f | 通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流 |
| -e | 从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出) |
| -t | 测试配置文件是否正确,然后退出 |
定义输入和输出流:
(1)输入采用标准输入,输出采用标准输出(类似管道)
#输入采用标准输入,输出采用标准输出(类似管道)
[root@logstash opt]#logstash -e 'input { stdin{} } output { stdout{} }'......
www.baidu.com #键入内容(标准输入)
2024-04-11T05:50:42.684Z logstash www.baidu.com #输出结果(标准输出)
www.google.com #键入内容(标准输入)
2024-04-11T05:51:07.295Z logstash www.google.com #输出结果(标准输出)//执行 ctrl+c 退出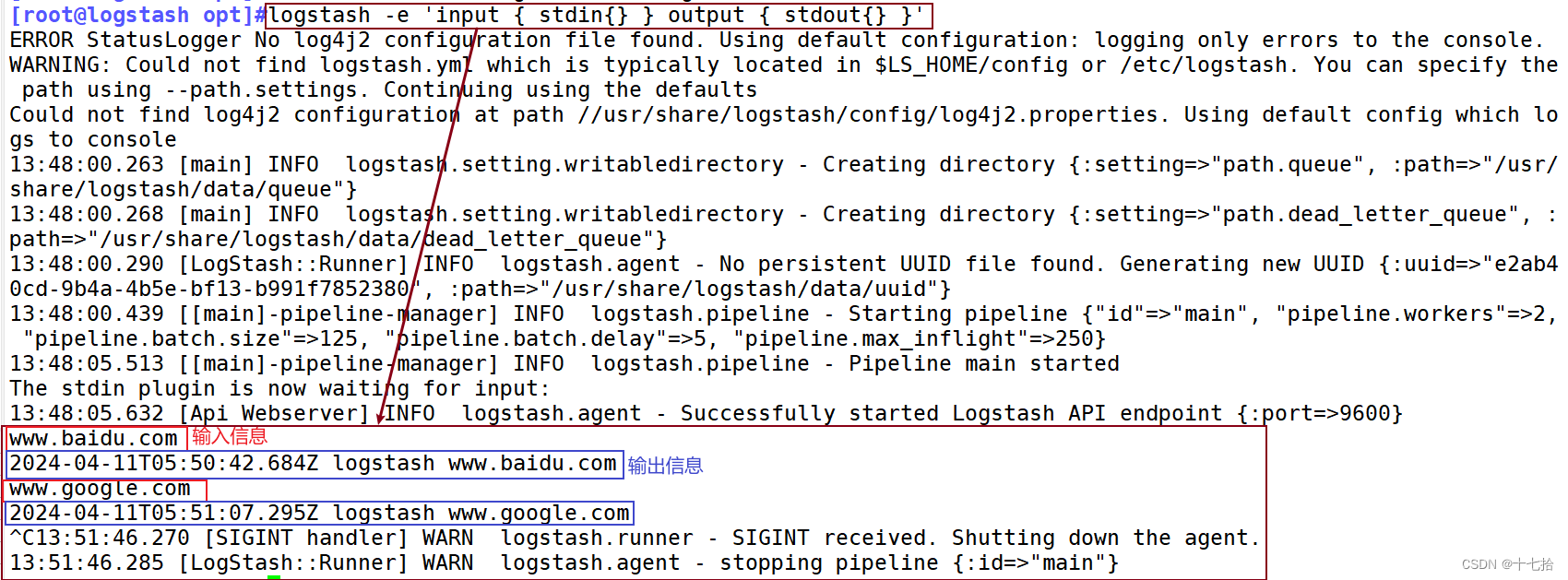
(2) 使用 rubydebug 输出详细格式显示,codec 为一种编解码器
#使用 rubydebug 输出详细格式显示,codec 为一种编解码器
[root@logstash opt]#logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'......
www.baidu.com #键入内容(标准输入)
{"@timestamp" => 2024-04-11T05:54:11.432Z, #输出结果(处理后的结果)"@version" => "1","host" => "logstash","message" => "www.baidu.com"
}//执行 ctrl+c 退出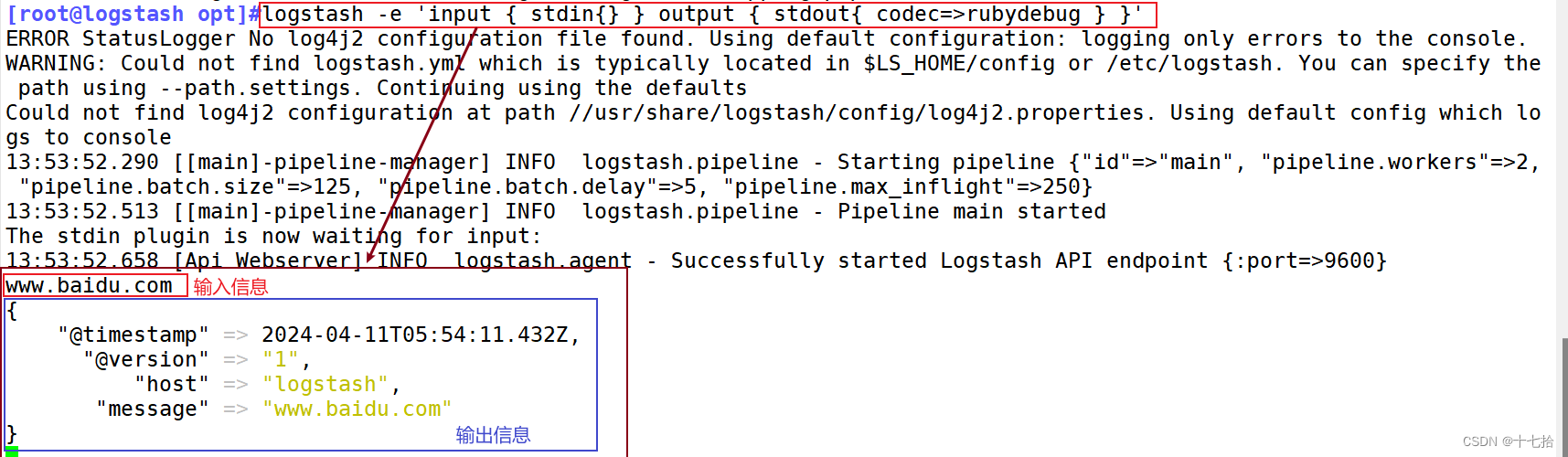
(3) 使用 Logstash 将信息写入 Elasticsearch 中
#使用 Logstash 将信息写入 Elasticsearch 中
[root@logstash opt]#logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["172.16.12.13:9200"] } }'输入 输出 对接......
www.baidu.com #键入内容(标准输入)
www.sina.com.cn #键入内容(标准输入)
www.google.com #键入内容(标准输入)//执行 ctrl+c 退出
3、ELFK Kiabana 部署
安装部署在es_node1节点上
3.1 安装 Kiabana
[root@es_node1 ~]#cd /opt #上传软件包 kibana-5.5.1-x86_64.rpm 到/opt目录
[root@es_node1 opt]#rpm -ivh kibana-5.5.1-x86_64.rpm
3.2 设置 Kibana 的主配置文件并启动服务
[root@es_node1 opt]#vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.10.13:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"[root@es_node1 opt]#systemctl enable --now kibana.service
[root@es_node1 opt]#netstat -natp | grep 5601 #查看5601端口进程
4、ELFK filebeat 部署
4.1 安装 filebeat + httpd
[root@filebeat ~]#cd /opt #上传软件包 filebeat-6.6.1-x86_64.rpm 到/opt目录
[root@filebeat opt]#rpm -ivh filebeat-6.6.1-x86_64.rpm
[root@filebeat opt]#yum install -y httpd
[root@filebeat opt]#systemctl start httpd4.2 设置 filebeat 的主配置文件
[root@filebeat opt]#vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- type: log # 指定 log 类型,从日志文件中读取消息enabled: truepaths:- /var/log/httpd/access_log #指定监控的日志文件tags: ["access"]- type: logenabled: truepaths:- /var/log/httpd/error_logtags: ["error"]......
--------------Elasticsearch output-------------------(全部注释掉)#添加输出到 Kafka 的配置
----------------kafak output---------------------
output.kafka:enabled: truehosts: ["172.16.12.16:9092","172.16.12.17:9092","172.16.12.18:9092"] #指定 Kafka 集群配置topic: "httpd" #指定 Kafka 的 topic#启动filebeat
[root@filebeat opt]#systemctl start filebeat.service
[root@filebeat opt]#filebeat -e -c /etc/filebeat/filebeat.yml#-e: 这是一个参数,表示以交互式模式(interactive mode)启动 Filebeat。在交互式模式下,Filebeat 会将日志输出打印到控制台,方便用户查看实时日志信息
#-c filebeat.yml: 这也是一个参数,指定了 Filebeat 的配置文件。通过指定这个配置文件,Filebeat 将会加载其中定义的配置选项和设置
三、部署Zoopkeeper + Kafak 集群
1、部署 Zoopkeeper 集群
1.1 部署 Zoopkeeper 集群
三台zookeeper+kafka节点服务器都要安装zookeeper
#下载安装包
官方下载地址:https://archive.apache.org/dist/zookeeper/下载apache-zookeeper-3.5.7-bin.tar.gz到本地的/opt目录下,进行二进制包解压,无需安装,能直接使用
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.71.2 设置主配置文件
三台节点服务器都要修改各自的配置文件
由于三台节点服务器配置文件需要修改的内容一样,修改完zk-kfk01服务器的主配置文件后,将其直接scp远程拷贝到另外两台节点服务器:zk-kfk02和zk-kfk03
[root@zk-kfk01 opt]#cd /usr/local/zookeeper-3.5.7/conf/
[root@zk-kfk01 conf]#cp zoo_sample.cfg zoo.cfg
[root@zk-kfk01 conf]#vim zoo.cfg #修改主配置文件tickTime=2000
#通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10
#Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5
#Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data
#修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs
#添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连:接端口
server.1=172.16.12.16:3188:3288
server.2=172.16.12.17:3188:3288
server.3=172.16.12.18:3188:3288#解释
server.A=B:C:D
# A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
# B是这个服务器的地址。
# C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
# D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。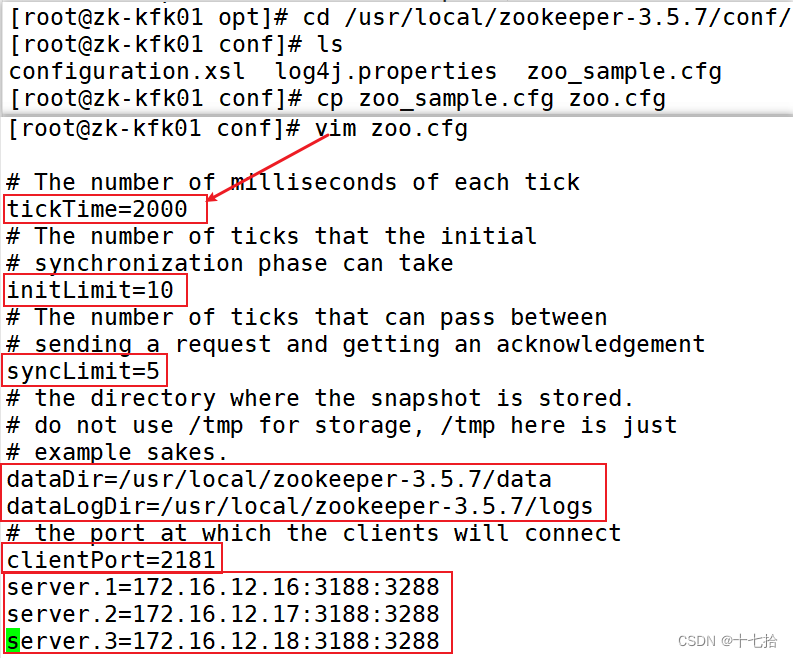
#拷贝配置好的 Zookeeper 配置文件到其他节点服务器上
[root@zk-kfk01 conf]# scp zoo.cfg 172.16.12.17:/usr/local/zookeeper-3.5.7/conf/
[root@zk-kfk01 conf]# scp zoo.cfg 172.16.12.18:/usr/local/zookeeper-3.5.7/conf/
1.3 创建数据目录和日志目录
在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
1.4 创建myid文件
在每个节点的dataDir指定的目录下创建一个 myid 的文件
[root@zk-kfk01 ~]# echo 1 > /usr/local/zookeeper-3.5.7/data/myid
[root@zk-kfk02 ~]# echo 2 > /usr/local/zookeeper-3.5.7/data/myid
[root@zk-kfk03 ~]# echo 3 > /usr/local/zookeeper-3.5.7/data/myid
1.5 配置 Zookeeper 启动脚本并设置开机自启
配置 Zookeeper 启动脚本:
[root@zk-kfk01 ~]#vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)echo "---------- zookeeper 启动 ------------"$ZK_HOME/bin/zkServer.sh start
;;
stop)echo "---------- zookeeper 停止 ------------"$ZK_HOME/bin/zkServer.sh stop
;;
restart)echo "---------- zookeeper 重启 ------------"$ZK_HOME/bin/zkServer.sh restart
;;
status)echo "---------- zookeeper 状态 ------------"$ZK_HOME/bin/zkServer.sh status
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac
#拷贝写好的zookeeper启动脚本到其他两台节点服务器
[root@zk-kfk01 ~]# scp /etc/init.d/zookeeper 172.16.12.17:/etc/init.d/zookeeper
[root@zk-kfk01 ~]# scp /etc/init.d/zookeeper 172.16.12.18:/etc/init.d/zookeeper
设置开机自启:
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
# 将 "zookeeper" 服务添加到系统的服务管理列表中,并且配置它在系统启动时自动运行
# 前提创建一个名为 "zookeeper" 的服务脚本(通常是放在 /etc/init.d/ 目录下)1.6 分别启动 Zookeeper
zk-kfk01服务器、zk-kfk02服务器、zk-kfk03服务器依次分别启动
#分别启动 Zookeeper
service zookeeper start#查看当前状态
service zookeeper status

2、部署 Kafak 集群
三台节点服务器都要安装zookeeper
#下载安装包
官方下载地址:https://archive.apache.org/dist/zookeeper/下载apache-zookeeper-3.5.7-bin.tar.gz到本地的/opt目录下,进行二进制包解压,无需安装,能直接使用
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.72.1 设置主配置文件
三台节点服务器都要修改各自的配置文件
由于三台节点服务器配置文件需要修改的内容一样,修改完zk-kfk01服务器的主配置文件后,将其直接scp远程拷贝到另外两台节点服务器:zk-kfk02和zk-kfk03
[root@zk-kfk01 opt]#cd /usr/local/zookeeper-3.5.7/conf/
[root@zk-kfk01 conf]#cp zoo_sample.cfg zoo.cfg
[root@zk-kfk01 conf]#vim zoo.cfg #修改主配置文件tickTime=2000
#通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10
#Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5
#Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data
#修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs
#添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连:接端口
server.1=172.16.12.16:3188:3288
server.2=172.16.12.17:3188:3288
server.3=172.16.12.18:3188:3288#解释
server.A=B:C:D
# A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
# B是这个服务器的地址。
# C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
# D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
#拷贝配置好的 Zookeeper 配置文件到其他节点服务器上
[root@zk-kfk01 conf]# scp zoo.cfg 172.16.12.17:/usr/local/zookeeper-3.5.7/conf/
[root@zk-kfk01 conf]# scp zoo.cfg 172.16.12.18:/usr/local/zookeeper-3.5.7/conf/
2.2 创建数据目录和日志目录
在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
2.3 创建myid文件
在每个节点的dataDir指定的目录下创建一个 myid 的文件
[root@zk-kfk01 ~]# echo 1 > /usr/local/zookeeper-3.5.7/data/myid
[root@zk-kfk02 ~]# echo 2 > /usr/local/zookeeper-3.5.7/data/myid
[root@zk-kfk03 ~]# echo 3 > /usr/local/zookeeper-3.5.7/data/myid
2.4 配置 Zookeeper 启动脚本并设置开机自启
配置 Zookeeper 启动脚本:
[root@zk-kfk01 ~]#vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)echo "---------- zookeeper 启动 ------------"$ZK_HOME/bin/zkServer.sh start
;;
stop)echo "---------- zookeeper 停止 ------------"$ZK_HOME/bin/zkServer.sh stop
;;
restart)echo "---------- zookeeper 重启 ------------"$ZK_HOME/bin/zkServer.sh restart
;;
status)echo "---------- zookeeper 状态 ------------"$ZK_HOME/bin/zkServer.sh status
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac
#拷贝写好的zookeeper启动脚本到其他两台节点服务器
[root@zk-kfk01 ~]# scp /etc/init.d/zookeeper 172.16.12.17:/etc/init.d/zookeeper
[root@zk-kfk01 ~]# scp /etc/init.d/zookeeper 172.16.12.18:/etc/init.d/zookeeper
设置开机自启:
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
# 将 "zookeeper" 服务添加到系统的服务管理列表中,并且配置它在系统启动时自动运行
# 前提创建一个名为 "zookeeper" 的服务脚本(通常是放在 /etc/init.d/ 目录下)2.5 分别启动 Zookeeper
zk-kfk01服务器、zk-kfk02服务器、zk-kfk03服务器依次分别启动
#分别启动 Zookeeper
service zookeeper start#查看当前状态
service zookeeper status
四、测试
1、定义 logstash 的配置文件
Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)
- input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等
- filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
- output:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。
#格式:
input {...}
filter {...}
output {...}#在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {file { path =>"/var/log/messages" type =>"syslog"}file { path =>"/var/log/httpd/access.log" type =>"apache"}
}设置 Logstash 配置文件,数据来源是kafak集群,logstash加工完数据后并将其输出到 elasticsearch 中
[root@logstash ~]# cd /etc/logstash/conf.d/
[root@logstash conf.d]# vim kafka.conf
input {kafka {bootstrap_servers => "172.16.12.16:9092,172.16.12.17:9092,172.16.12.18:9092"
# kafka集群地址topics => "httpd" # 拉取的kafka的指定topictype => "httpd_kafka" # 指定 type 字段codec => "json" # 解析json格式的日志数据auto_offset_reset => "latest" # 拉取最近数据,earliest为从头开始拉取decorate_events => true # 传递给elasticsearch的数据额外增加kafka的属性数据}
}output {if "access" in [tags] {elasticsearch {hosts => ["172.16.12.12:9200"]index => "httpd_access-%{+YYYY.MM.dd}"}}if "error" in [tags] {elasticsearch {hosts => ["172.16.12.12:9200"]index => "httpd_error-%{+YYYY.MM.dd}"}}stdout { codec => rubydebug }
}
[root@logstash conf.d]# logstash -f kafka.conf
# 启动 logstash;或者 filebeat -e -c filebeat.yml &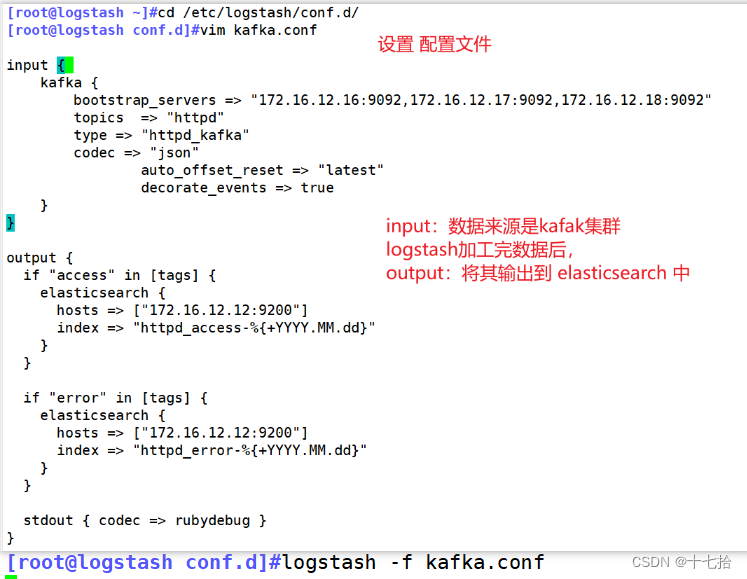
2、查看所有的索引
客户端浏览器先访问apache服务器,否则无法有httpd_access索引
http://172.16.12.15/生产黑屏操作es时查看所有的索引:
[root@es_node1 ~]# curl -X GET "localhost:9200/_cat/indices?v"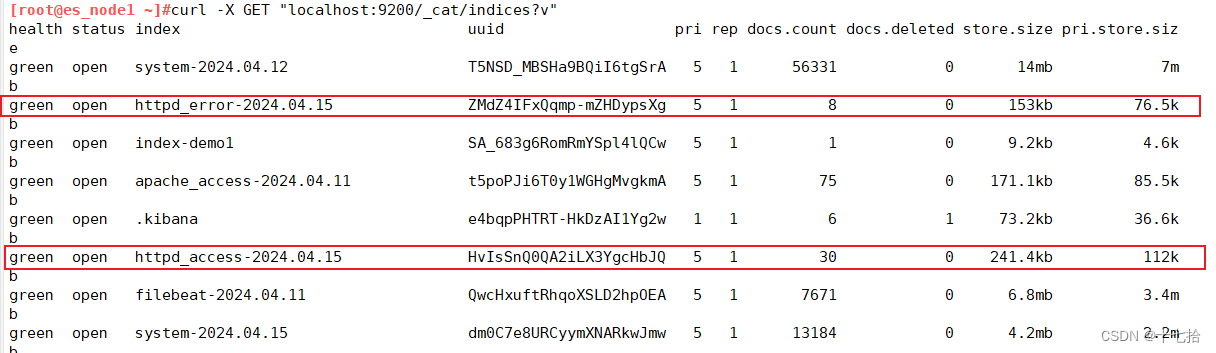
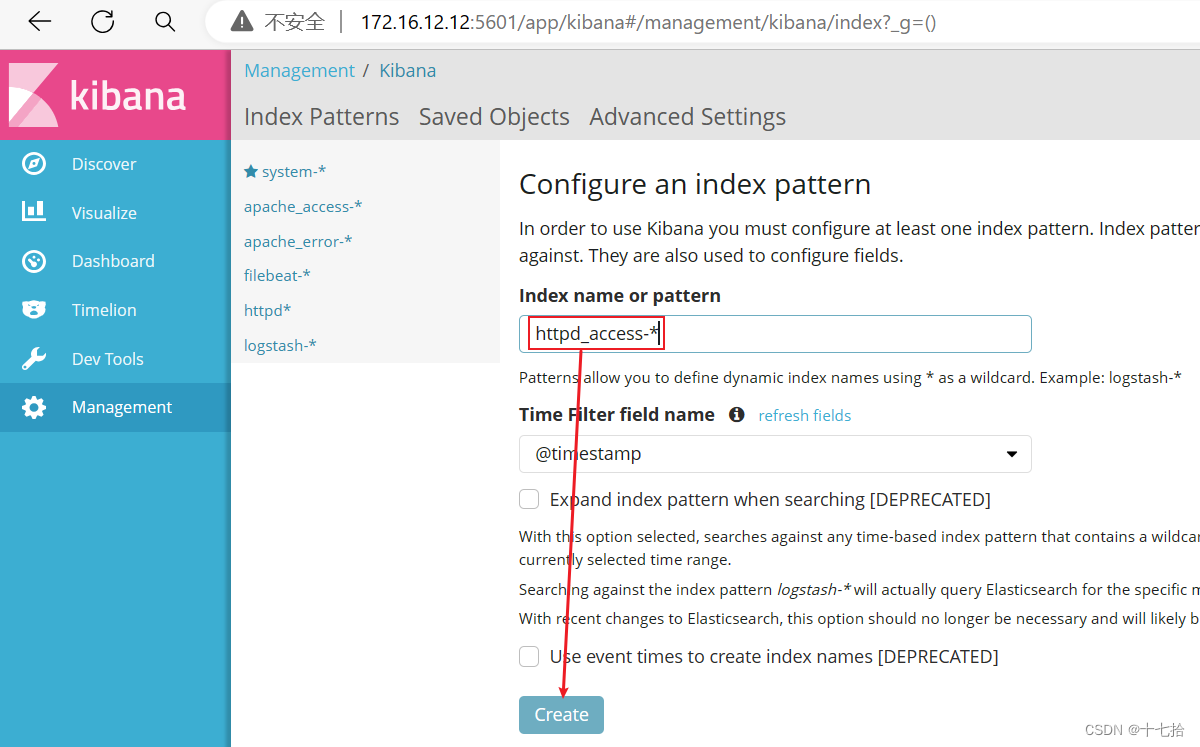
3、登录 Kibana 添加索引
浏览器访问 http://172.16.12.12:5601,添加索引“httpd*”,查看图表信息及日志信息
(1)添加索引“httpd_access-*”和“httpd_error-*”



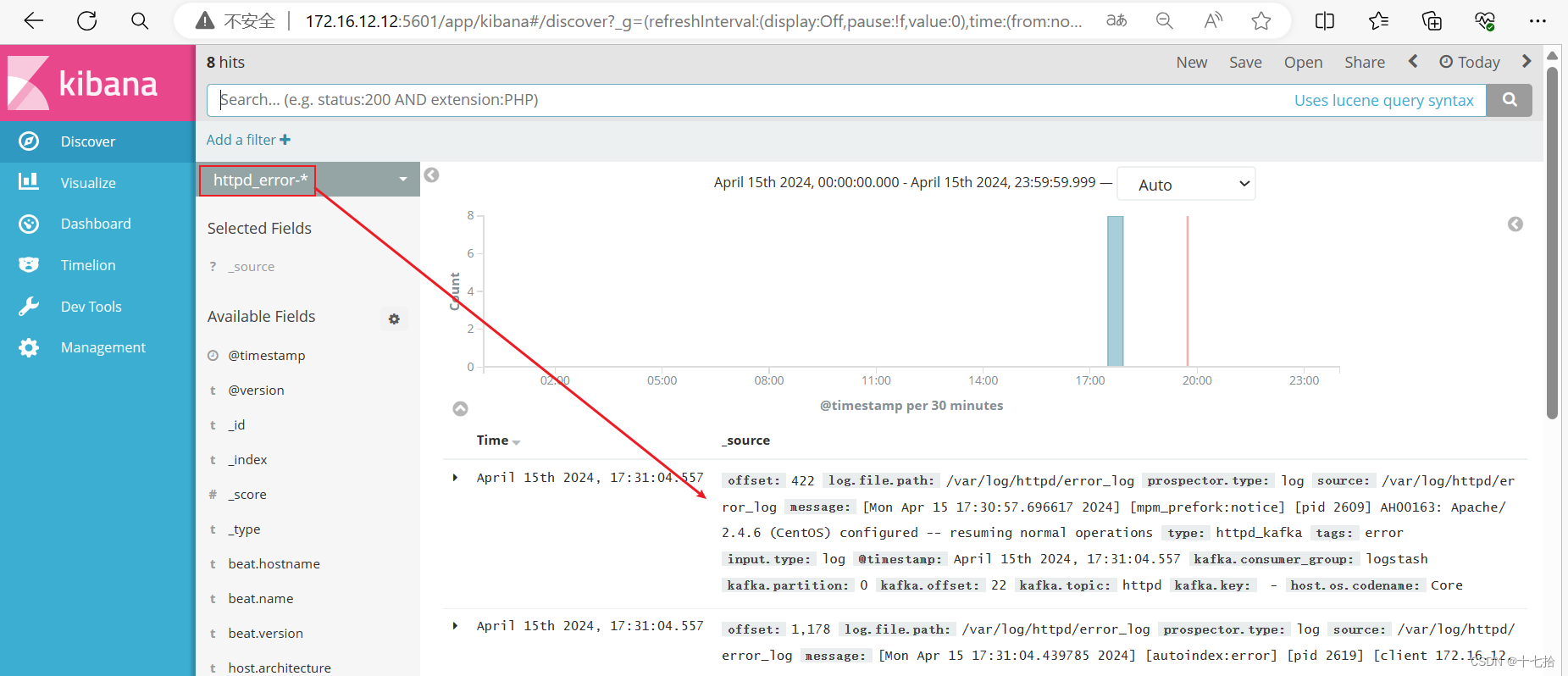
(2) 查看图表信息及日志信息

相关文章:
部署ELFK+zookeeper+kafka架构
目录 前言 一、环境部署 二、部署ELFK 1、ELFK ElasticSearch 集群部署 1.1 配置本地hosts文件 1.2 安装 elasticsearch-rpm 包并加载系统服务 1.3 修改 elasticsearch 主配置文件 1.4 创建数据存放路径并授权 1.5 启动elasticsearch是否成功开启 1.6 查看节点信息 …...

ActiveMQ 任意文件上传漏洞复现
一、使用弱口令登陆 访问 http://ip:8161/admin/ 进入admin登陆页面,使用弱口令登陆,账号密码皆为 admin,登陆成功后,headers中会出现验证信息 如: Authorization: Basic YWRtaW46YWRtaW4 # 二、利用PUT协议上…...

k8s实践总结
一、pod常用操作: 1、如何重启pod? 1.1 删除并重新创建Pod 这是最直接的方法。你可以通过kubectl命令行工具删除Pod,然后Kubernetes将基于其对应的Deployment、ReplicaSet或其他控制器自动重新创建它。 不建议并行删除全部pod,…...

前端从零到一搭建脚手架并发布到npm
这里写自定义目录标题 为什么需要脚手架?前置-第三方工具的使用1. 创建demo并运行-4步新建文件夹 zyfcli,并初始化npm init -y配置入口文件 2.commander-命令行指令3. chalk-命令行美化工具4. inquirer-命令行交互工具5. figlet-艺术字6. ora-loading工具…...

使用 git 提交项目到 github
文章推荐:https://zhuanlan.zhihu.com/p/193140870 连接失败:https://zhuanlan.zhihu.com/p/521340971 分支出错:https://blog.csdn.net/gongdamrgao/article/details/115032436...

SRE 与传统 IT 运营有何不同?
软件开发和部署方法的发展要求组织管理和维护 IT 基础设施的方式发生转变。站点可靠性工程(SRE) 是一门将软件工程的各个方面融入 IT 运营的学科,处于这一变革的前沿。随着专业人士和组织都寻求适应,对 SRE 认证和培训计划的需求激增。本博客探讨了 SRE …...
html公众号页面实现点击按钮跳转到导航
实现效果: 点击导航自动跳转到: html页面代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>跳转导航</title><meta name"keywords" conten…...

【算法】快速排序的基本思想、优化 | 挖坑填补法和区间分割法
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 更多算法分析与设计知识专栏:算法分析🔥 给大家跳…...

OSPF动态路由实验(华为)
思科设备参考:OSPF动态路由实验(思科) 一,技术简介 OSPF(Open Shortest Path First)是一种内部网关协议,主要用于在单一自治系统内决策路由。它是一种基于链路状态的路由协议,通过…...

EasyRecovery2024专业免费的电脑数据恢复软件
EasyRecovery数据恢复软件是一款功能强大的数据恢复工具,广泛应用于各种数据丢失场景,帮助用户从不同类型的存储介质中恢复丢失或删除的文件。 该软件支持恢复的数据类型非常广泛,包括但不限于办公文档、图片、音频、视频、电子邮件以及各种…...
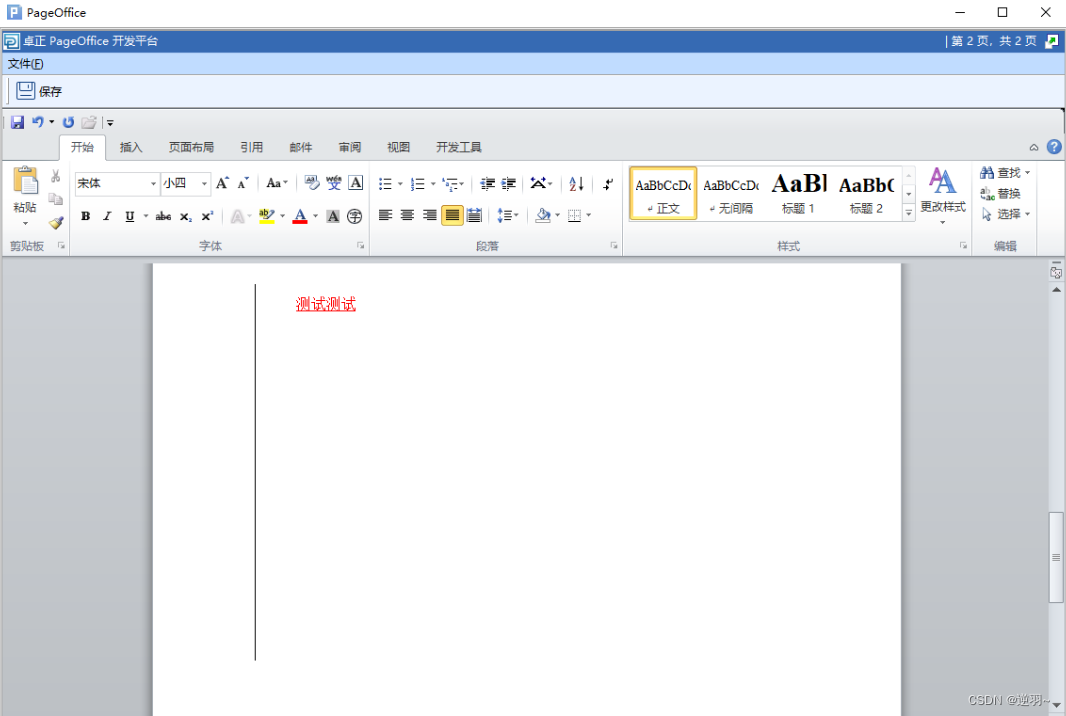
Vue集成PageOffice实现在线编辑word、excel(前端配置)
一、什么是PageOffice PageOffice是一款在线的office编辑软件,帮助Web应用系统或Web网站实现用户在线编辑Word、Excel、PowerPoint文档。可以完美实现在线公文流转,领导批阅,盖章。可以给文件添加水印,在线安全预览防止用户下载…...

IBM SPSS Statistics for Mac:数据分析的卓越工具
IBM SPSS Statistics for Mac是一款功能强大的数据分析软件,专为Mac用户设计,提供了一系列专业的统计分析和数据管理功能。无论是科研人员、数据分析师还是学生,都能从中获得高效、准确的数据分析支持。 IBM SPSS Statistics for Mac v27.0.1…...

python爬虫------- Selenium下篇(二十三天)
🎈🎈作者主页: 喔的嘛呀🎈🎈 🎈🎈所属专栏:python爬虫学习🎈🎈 ✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天…...
)
获取字符串的全排列(去除字符串中2个字符相同时造成的重复)
一、概念 现有一个字符串,要打印出该字符串中字符的全排列。 以字符串abc为例,输出的结果为:abc、acb、bac、bca、cab、cba。 以字符串aab为例,输出的结果为:aab、aba、baa。 二、代码 public class Permutation {pub…...

HTML5新增的多媒体标签
在网页中加入音乐 <audio></audio> src 设置音乐文件名以及路径,<audio>标记支持MP3、WAV及OGG 3种音乐格式 autoplay:是否自动播放,加入autopaly属性表示自动播放 controls: 是否显示播放面板,加入controls属性表示显示播放面板 …...

温湿度传感器(DHT11)以及光照强度传感器(BH1750)的使用
前言 对于一些单片机类的环境检测或者智能家居小项目中,温湿度传感器(DHT11)以及光照强度传感器(BH1750)往往是必不可少的两个外设,下面我们来剖析这两个外设的原理,以及使用。 1. 温湿度传感…...

ActiveMQ 04 Linux下安装
Active MQ 04 Linux下安装 下载 解压 在init.d下建立软连接 ln -s /usr/local/activemq/bin/activemq ./设置开启启动 chkconfig activemq on 服务管理 service activemq start service activemq status service activemq stopNIO配置 默认配置为tcp,使用的…...

.pyc 文件是什么?是否有必要同步到 GitHub 远程仓库?
git status 时发现有很多 .pyc 的没有被 add (env) username:~/path/to/project$ git status On branch main Your branch is up to date with origin/main.Changes to be committed:(use "git restore --staged <file>..." to unstage)new file: xxx.pyCha…...
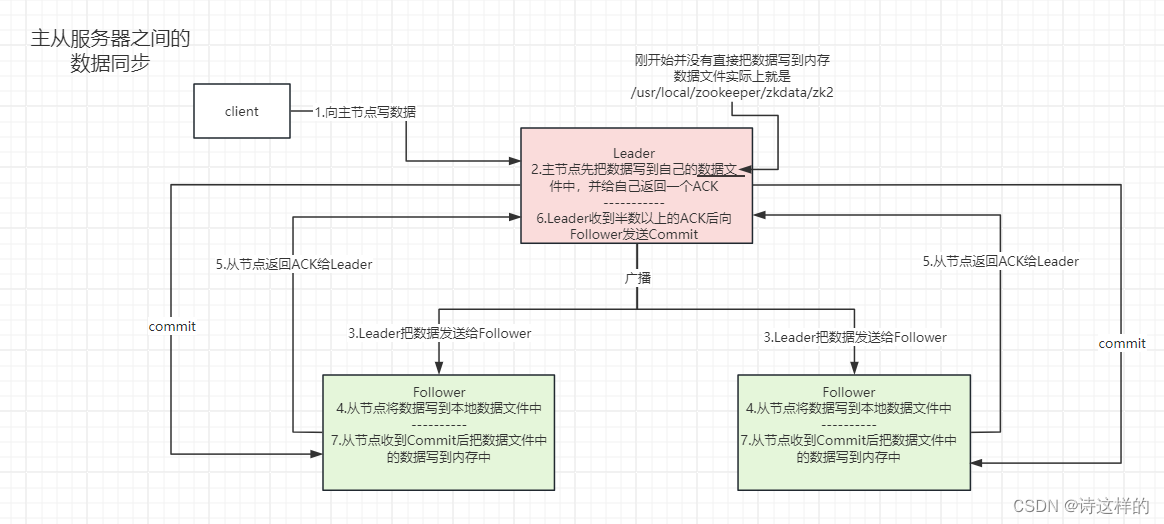
Zookeeper的集群搭建和ZAB协议详解
Zookeeper的集群搭建 1)zk集群中的角色 Zookeeper集群中的节点有三个角色: Leader:处理集群的所有事务请求,集群中只有一个LeaderFollwoer:只能处理读请求,参与Leader选举Observer:只能处理读…...

STM32 MPU配置参数
TXE LEVEL一般只用MPU_TEX_LEVEL0 1 - 1 - 1 -0性能最强(TEX - C - B- S). #define MPU_TEX_LEVEL0 ((uint8_t)0x00) #define MPU_TEX_LEVEL1 ((uint8_t)0x01) #define MPU_TEX_LEVEL2 ((uint8_t)0x02) 基于上表进行常用配置 ÿ…...

开发环境准备:Python、Node.js、Docker与Git
从“环境搞了两天”到“半小时开箱即用”,一个老油条的环境配置血泪史前几天团队来了个新同事,应届生,看着简历上写着“熟悉Python、Node.js、Docker、Git”。我心想,挺好,基本功扎实。然后给了他一个新电脑࿰…...

不只是问答:灵活定义你的聊天模型
上一篇文章,我们装好了第一条链——提示词模板串起模型与解析器,几句中文就变成了地道的英文。那一刻,你可能觉得一切都尽在掌握了。可一旦把链部署给朋友试用,新的问题就冒了出来:朋友说“多写一点”,模型…...

龙芯2k0300 - 智能车走马观碑组VL53L0X驱动移植
---------------------------------------------------------------------------------------------------------------------------- 开发板 :久久派开发板eMMC :8GBDDR4 :512MBu-boot :u-boot 2022.04linux :6.12roo…...

污水处理通气帽标准尺寸参数与国标通气帽定制要点
在好些个工程现场当中,人们往往会忽略掉一个看起来平常但是特别要害的小部件——通气帽。特别是在污水处理的体系当中,它承担平衡内部和外部的气压,阻止异味向外溢出,阻拦异物进入等好几个方面的功能。要是选择类型不适合…...
)
FPGA仿真入门:手把手教你配置Quartus Prime 21.1里的Questa Starter版(附12个月免费许可攻略)
FPGA仿真工具链实战:从Questa Starter许可申请到Quartus Prime深度集成 当数字逻辑设计从纸上谈兵进入硬件实现阶段,仿真验证便成为FPGA开发流程中不可逾越的质量关卡。作为Intel FPGA生态中的黄金搭档,Quartus Prime与Questa的协同工作能帮助…...
:含未公开的「因果推理引擎」与「合规沙盒模式」)
ChatGPT 2026功能清单泄露事件(OpenAI内部合规审查文档节选):含未公开的「因果推理引擎」与「合规沙盒模式」
更多请点击: https://intelliparadigm.com 第一章:ChatGPT 2026功能清单泄露事件概览 事件背景与时间线 2024年11月,一段标注为“OpenAI Internal – GPT-2026 Roadmap Draft v3.7”的加密ZIP文件在多个匿名开发者论坛意外传播。该文件包含…...

构建可靠AI编码代理:OpenClaw-Build工作流详解与实战
1. 项目概述:一个能“闭环”的AI编码代理工作流如果你用过市面上那些号称能自动编程的AI代理,大概率经历过这样的挫败感:你满怀期待地丢给它一个需求,它吭哧吭哧干了两三个任务,然后要么开始“神游”,写出来…...

告别照片管理烦恼:ExifToolGUI帮你3步搞定批量元数据处理
告别照片管理烦恼:ExifToolGUI帮你3步搞定批量元数据处理 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你是否曾为数百张旅行照片的整理而头疼?拍摄时间需要统一调整,版…...

从零构建智能Line机器人:基于ChatGPT API的即时通讯AI助手开发指南
1. 项目概述:一个能帮你“翻译”一切的Line机器人 如果你经常使用Line,并且对ChatGPT这类AI助手的能力感到好奇,那么“ChatGPT-Line-Bot”这个项目,可能就是为你量身定做的。简单来说,它是一个架设在Line平台上的聊天…...

5分钟快速上手:roop-unleashed AI换脸神器完全指南
5分钟快速上手:roop-unleashed AI换脸神器完全指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要在几分钟内制作专业级AI换脸视频吗&…...