【大语言模型】基础:TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) 是一种用于信息检索与文本挖掘的统计方法,用来评估一个词对于一个文件集或一个语料库中的其中一份文件的重要性。它是一种常用于文本处理和自然语言处理的权重计算技术。
原理
TF-IDF 由两部分组成:词频(TF),文档频率(DF)和逆文档频率(IDF)。每一部分的计算方法如下:
-
词频(TF, Term Frequency):指某一个给定的词语在该文件中出现的频率。这个数字通常会被标准化(通常是词频除以文章总词数),以防止它偏向长的文件。(即使某一特定的词语在长文件中出现频率较高,其实该词语可能并不重要。

-
文档频率(DF): 是文本挖掘和信息检索中的一个基本概念,特别是在计算 TF-IDF(词频-逆文档频率) 时经常被用到。尽管通常在TF-IDF计算中讨论DF的倒数,但单独理解它也同样重要。定义为包含词 t 的文档数目,在语料库 D 中。它衡量一个词在整个语料库中的普遍性或稀有性。
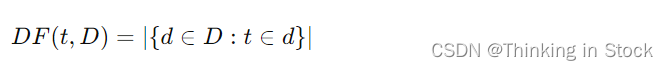
-
逆文档频率(IDF, Inverse Document Frequency):这是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

-
TF-IDF:然后将TF和IDF相乘得到一个词的TF-IDF分数,该分数即为词在文档中的重要性:

比较TF-IDF与余弦相似度(Cosine Similarity),TF-IDF 主要用于调整词在文档中的权重,而余弦相似度是一种衡量两个文本向量方向相似度的方法。
TF-IDF
目的:
- 权重调整:TF-IDF 通过增加罕见词的权重而降低常见词的权重,从而提供了一种评估词语在一个或多个文档中重要性的方法。
优点:
- 区分文档特有的重要词汇:对于只在少数文档中出现,但在这些文档中出现频率较高的词,TF-IDF 会赋予较高的权重。
局限性:
- 无法直接用于相似性度量:TF-IDF 本身是一个用于调整单词权重的统计方法,它需要与其他技术(如余弦相似度)结合使用,才能用于文档相似性度量。
余弦相似度
目的:
- 相似性度量:余弦相似度通过计算两个向量之间的角度余弦值来度量它们的相似度,用于比较两个文本向量的方向一致性。
优点:
- 规模不变性:余弦相似度衡量的是方向一致性而非向量的大小,因此它对文本长度不敏感,适用于比较长度不同的文档。
- 直观度量相似性:可以直接用于评估两个文本的相似度,特别是结合了TF-IDF后,可以有效反映出文本内容的语义相似性。
局限性:
- 依赖于向量表达:余弦相似度的效果很大程度上依赖于文本向量的构建方式(如使用TF-IDF或其他词向量模型)。
结合使用 TF-IDF 和 余弦相似度
在实际应用中,TF-IDF 通常与余弦相似度结合使用来提高文本相似性度量的准确性:
- 向量化:首先使用 TF-IDF 对文档中的每个词进行权重计算,生成文档的向量表示。
- 相似性计算:然后计算这些基于 TF-IDF 的向量之间的余弦相似度,以确定文档间的相似性。
下面看下TF-IDF代码实现:
import numpy as np
from collections import defaultdict
import math# 示例语料库
documents = ["the sky is blue","the sun is bright","the sun in the sky is bright","we can see the shining sun, the bright sun"
]# 计算词频的函数
def compute_tf(text):# 将文本分割为词项terms = text.split()tf_data = {}for term in terms:tf_data[term] = tf_data.get(term, 0) + 1# 按文档中的总词数进行标准化total_terms = len(terms)for term in tf_data:tf_data[term] = tf_data[term] / total_termsreturn tf_data# 计算逆文档频率的函数
def compute_idf(documents):N = len(documents)idf_data = defaultdict(lambda: 0)for document in documents:terms = set(document.split())for term in terms:idf_data[term] += 1# 计算IDFfor term, count in idf_data.items():idf_data[term] = math.log(N / float(count))return idf_data# 计算TF-IDF的函数
def compute_tfidf(documents):# 计算各个文档的TFtfs = [compute_tf(doc) for doc in documents]# 计算语料库的IDFidfs = compute_idf(documents)# 计算TF-IDFtf_idf = []for doc_tf in tfs:doc_tf_idf = {}for term, value in doc_tf.items():doc_tf_idf[term] = value * idfs[term]tf_idf.append(doc_tf_idf)return tf_idf# 为语料库计算TF-IDF
tf_idf_scores = compute_tfidf(documents)# 输出结果
for idx, doc_scores in enumerate(tf_idf_scores):print(f"文档 {idx + 1} 的TF-IDF分数:")for term, score in doc_scores.items():print(f" {term}: {score:.4f}")
创建Heatmap显示单词在各个文档中的权重:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Create a DataFrame from the TF-IDF dictionary
tf_idf_df = pd.DataFrame(tf_idf_scores)
tf_idf_df = tf_idf_df.fillna(0) # Fill NaN values with 0# Create a heatmap
plt.figure(figsize=(12, 8))
sns.heatmap(tf_idf_df, annot=True, cmap="YlGnBu", fmt=".2f")
plt.title('TF-IDF Scores Heatmap')
plt.xlabel('Terms')
plt.ylabel('Documents')
plt.show()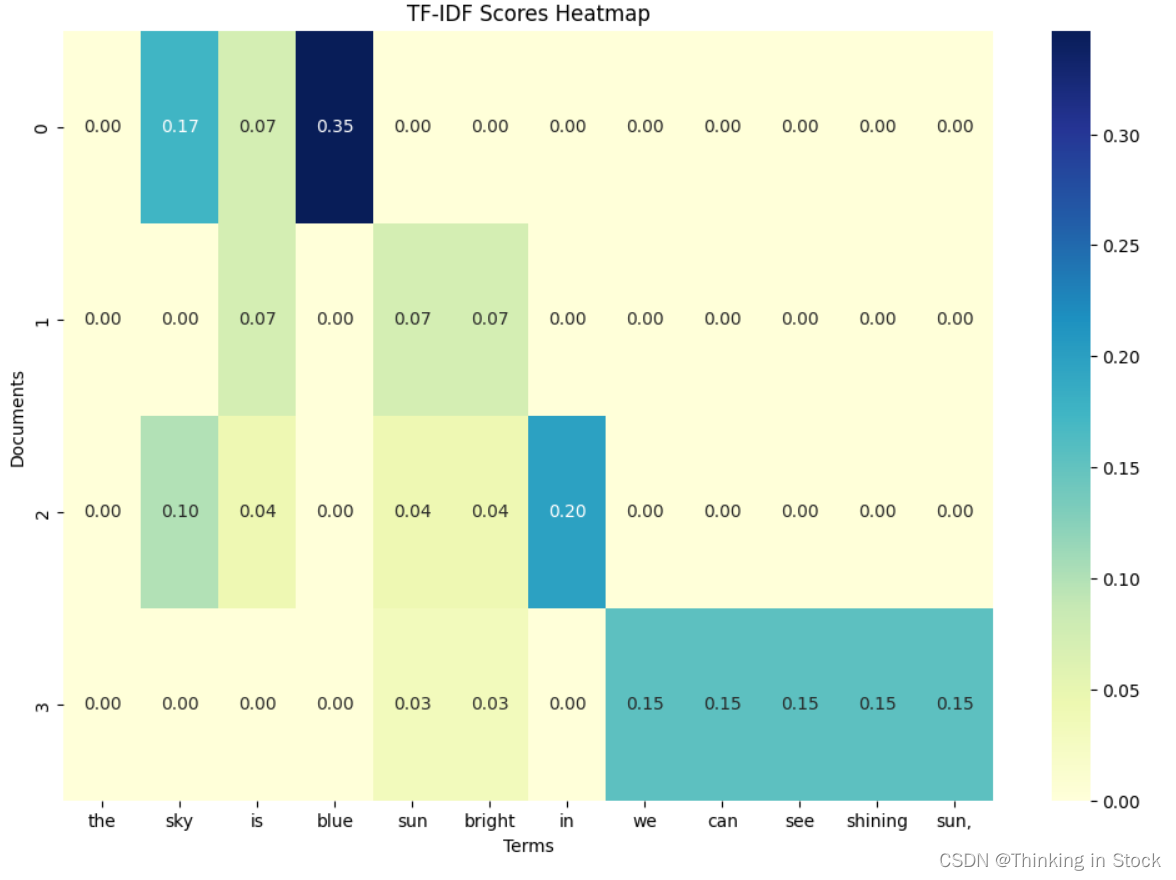
相关文章:
【大语言模型】基础:TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) 是一种用于信息检索与文本挖掘的统计方法,用来评估一个词对于一个文件集或一个语料库中的其中一份文件的重要性。它是一种常用于文本处理和自然语言处理的权重计算技术。 原理 TF-IDF 由两部分组成࿱…...
[开发日志系列]PDF图书在线系统20240415
20240414 Step1: 创建基础vueelment项目框架[耗时: 1h25min(8:45-10:10)] 检查node > 升级至最新 (考虑到时间问题,没有使用npm命令行执行,而是觉得删除重新下载最新版本) > > 配置vue3框架 取名:Online PDF Book System 遇到的报错: 第一报错: npm ERR! …...
蓝桥杯 — — 纯质数
纯质数 题目: 思路: 一个最简单的思路就是枚举出所有的质数,然后再判断这个质数是否是一个纯质数。 枚举出所有的质数: 可以使用常规的暴力求解法,其时间复杂度为( O ( N N ) O(N\sqrt{N}) O(NN )&…...
OpenCV基本图像处理操作(三)——图像轮廓
轮廓 cv2.findContours(img,mode,method) mode:轮廓检索模式 RETR_EXTERNAL :只检索最外面的轮廓;RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;RETR_CCOMP:检索所有的轮廓,并将他们组…...

比特币突然暴跌
作者:秦晋 周末愉快。 今天给大家分享两则比特币新闻,也是两个数据。一则是因为中东地缘政治升温,传统资本市场的风险情绪蔓延至加密市场,引发加密市场暴跌。比特币跌至66000美元下方。杠杆清算金额高达8.5亿美元。 二则是&#x…...

使用SpeechRecognition和vosk处理ASR
SpeechRecognition可以支持多种模型语音转文字,感觉vosk还不错,使用起来也简单一些;百度也有PaddleSpeech,但是安装起来太麻烦,不是这个库版本不对就是那个库有问题,用起来不方便; 安装SpeechR…...

【Go】通道:缓冲通道和非缓冲通道
目录 通道的基本概念 缓冲通道 非缓冲通道 总结 通道的基本概念 在Go语言中,通道是一种特殊的类型,用于在goroutine之间传递数据。你可以将通道想象为数据的传输管道。通道分为两种类型: 非缓冲通道(Unbuffered Channels&…...

Java中数组的使用
在Java编程中,数组是一种非常重要的数据结构,它允许我们存储相同类型的多个元素。对于初学者来说,理解数组的基本概念、初始化、遍历、默认值以及内存分配和使用注意事项是非常关键的。 一、数组的概念 数组是一个可以容纳多个相同类型数据…...

CAP5_Monday
A Set to Max (Easy Version) 给定数组 a 和 b,可以执行以下操作任意次 : 让 a l ∼ a r a_l\sim a_r al∼ar 中的所有所有元素变成 a i a_i ai ( l ≤ i ≤ r ) (l\leq i\leq r) (l≤i≤r), 其中 1 ≤ l ≤ r ≤ n 1\leq l \leq r \leq n 1≤…...
科大讯飞星火开源大模型iFlytekSpark-13B GPU版部署方法
星火大模型的主页:iFlytekSpark-13B: 讯飞星火开源-13B(iFlytekSpark-13B)拥有130亿参数,新一代认知大模型,一经发布,众多科研院所和高校便期待科大讯飞能够开源。 为了让大家使用的更加方便,科…...
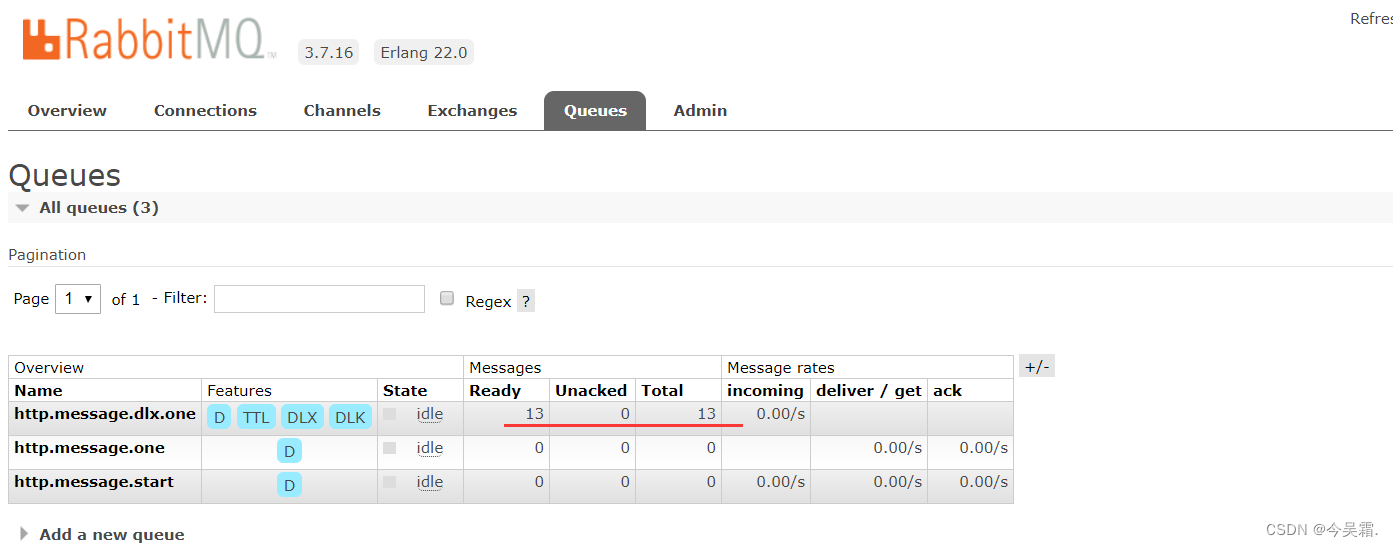
SpringBoot基于RabbitMQ实现消息延迟队列方案
知识小科普 在此之前,简单说明下基于RabbitMQ实现延时队列的相关知识及说明下延时队列的使用场景。 延时队列使用场景 在很多的业务场景中,延时队列可以实现很多功能,此类业务中,一般上是非实时的,需要延迟处理的&a…...

Go语言使用标准库时常见错误
Go的标准库是一组增加和拓展语言的核心包。然而,很容易误用标准库,或者我们对其行为理解有限,导致产生了bug或不应该在生产级应用程序中某些功能。 1. 提供错误的持续时间 标准库提供了获取 time.Duration 的常用函数和方法,但由于 time.Duration 是 int64 的自定义类型,…...

UE5不打包启用像素流 ubuntu22.04
首先查找引擎中像素流的位置: zkzk-ubuntu2023:/media/zk/Data/Linux_Unreal_Engine_5.3.2$ sudo find ./ -name get_ps_servers.sh [sudo] zk 的密码: ./Engine/Plugins/Media/PixelStreaming/Resources/WebServers/get_ps_servers.sh然后在指定路径中…...

Redis 常用数据类型常用命令和应用场景
首先先混个眼熟 Redis 中的 8 种常用数据类型: 5 种基础数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合࿰…...
ins视频批量下载,instagram批量爬取视频信息
简介 Instagram 是目前最热门的社交媒体平台之一,拥有大量优质的视频内容。但是要逐一下载这些视频往往非常耗时。在这篇文章中,我们将介绍如何使用 Python 编写一个脚本,来实现 Instagram 视频的批量下载和信息爬取。 我们使用selenium获取目标用户的 HTML 源代码,并将其保存…...
)
Canvas图形编辑器-数据结构与History(undo/redo)
Canvas图形编辑器-数据结构与History(undo/redo) 这是作为 社区老给我推Canvas,于是我也学习Canvas做了个简历编辑器 的后续内容,主要是介绍了对数据结构的设计以及History能力的实现。 在线编辑: https://windrunnermax.github.io/CanvasEditor开源地…...

阿里云Centos7下编译glibc
编译glibc 原来glibc版本 编译前需要的环境: CentOS7 gcc 8.3.0 gdb 8.3.0 make 4.0 binutils 2.39 (ld -v) python 3.6.8 其他看INSTALL, 但有些版本也不易太高 wget https://mirrors.aliyun.com/gnu/glibc/glibc-2.37.tar.gz tar -zxf glibc-2.37.tar.gz cd glibc-2.37/ …...

UE5数字孪生系列笔记(四)
场景的切换 创建一个按钮的用户界面UMG 创建一个Actor,然后将此按钮UMG添加到组件Actor中 调节几个全屏的背景 运行结果 目标点切换功能制作 设置角色到这个按钮的位置效果 按钮被点击就进行跳转 多个地点的切换与旋转 将之前的目标点切换逻辑替换成旋转的逻…...

品牌故事化:Kompas.ai如何塑造深刻的品牌形象
在这个信息爆炸的时代,品牌故事化已经成为企业塑造独特形象、与消费者建立情感联系的重要手段。一个引人入胜的品牌故事不仅能够吸引消费者的注意力,还能够在消费者心中留下持久的印象,建立起强烈的情感连接。本文将深入探讨品牌故事化对于构…...

5g和2.4g频段有什么区别
运行的频段不同 2.4G和5G频段的主要区别在于它们运行的频段不同,2.4G频段运行在2.4GHz的频段上,而5G频段(这里指的是5GHz频段)运行在5GHz的频段上。12 这导致了两者在传输速度、覆盖范围、抗干扰能力等方面的明显差异。以下是详…...

实现Degrees of Lewdity游戏本地化:完整中文补丁安装教程
实现Degrees of Lewdity游戏本地化:完整中文补丁安装教程 本教程将指导您完成Degrees of Lewdity游戏的中文本地化过程,通过系统的游戏本地化方法,帮助您顺利安装中文补丁,解决游戏界面语言障碍,提升游戏体验。我们将…...

ARMv8/v9异常处理与ESR寄存器深度解析
1. ARM异常处理机制概述异常处理是现代处理器架构的核心功能之一,它使系统能够响应硬件故障、软件错误和外部事件。在ARMv8/v9架构中,异常处理机制经过精心设计,为不同特权级别(EL0-EL3)提供了细粒度的控制能力。当处理…...

为什么你的Agent总在Adobe全家桶前卡死?:独家披露Adobe UXP沙箱逃逸+DOM Bridge双向通信协议逆向成果
更多请点击: https://intelliparadigm.com 第一章:Adobe UXP沙箱机制与Agent操作失能的根源诊断 Adobe UXP(Unified Extensibility Platform)为插件提供了强隔离的运行时沙箱环境,其核心设计目标是保障宿主应用&#…...

别再被代码劝退!用LilyPond 2.20.0写《铃儿响叮当》乐谱,5分钟搞定你的第一份五线谱
别再被代码劝退!用LilyPond 2.20.0写《铃儿响叮当》乐谱,5分钟搞定你的第一份五线谱 第一次看到LilyPond的界面,很多人会下意识皱眉——满屏的代码和符号,仿佛在劝退非程序员背景的音乐爱好者。但事实上,用LilyPond制…...

Arcgis制图进阶:比例尺参数深度解析与实战样式定制
1. 比例尺参数配置的核心逻辑 比例尺在ArcGIS中远不止是一个简单的标注工具,它直接影响地图的专业性和信息传达效率。我经手过上百个制图项目,发现90%的比例尺问题都源于对参数逻辑理解不透彻。比例尺参数系统其实是一个精密的视觉计算器,它…...

5分钟快速上手JD-GUI:免费Java反编译工具的完整实战指南
5分钟快速上手JD-GUI:免费Java反编译工具的完整实战指南 【免费下载链接】jd-gui A standalone Java Decompiler GUI 项目地址: https://gitcode.com/gh_mirrors/jd/jd-gui 你是否曾面对一个只有.class文件的Java项目,却急于想了解它的内部实现&a…...

Doramagic:AI助手开源项目专家技能提取引擎架构与实战
1. 项目概述:Doramagic,一个为AI助手注入项目“灵魂”的提取引擎如果你和我一样,每天都在和各种各样的开源项目打交道,从FastAPI到Home Assistant,从Next.js到LangChain,那你肯定也遇到过这样的困境&#x…...
2025_NIPS_Unveiling Induction Heads: Provable Training Dynamics and Feature Learning in Transformers
文章核心内容与创新点总结 核心内容 本文聚焦Transformer在n元马尔可夫链数据上的上下文学习(ICL)机制,通过分析含相对位置嵌入、多头softmax注意力和归一化前馈网络的双层Transformer训练动态,证明梯度流会收敛到实现“广义归纳头”(GIH)机制的极限模型。该模型中,第…...

从VMware嵌套虚拟化到NFS共享存储:一份给运维新人的FusionCompute平台搭建避坑实录
从VMware嵌套虚拟化到NFS共享存储:一份给运维新人的FusionCompute平台搭建避坑实录 刚接触云计算平台搭建的运维工程师,往往会被各种专业术语和复杂配置搞得晕头转向。华为FusionCompute作为企业级虚拟化平台,功能强大但入门门槛不低。本文将…...

LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换
LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为学术论文中复杂的数…...